re:Invent 2024: AWSのライフサイクルを通じたアーキテクチャ最適化と Accor の事例


はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Architectural best practices throughout the lifecycle (ARC206)
この動画では、クラウドのライフサイクルを通じたアーキテクチャのベストプラクティスについて解説しています。Cloud Optimizationの概念とその実践的なアプローチを説明し、Exploration、Foundation、Intermediate、Advanced、Autonomousの5つのフェーズでの成熟度向上プロセスを詳しく解説します。Well-Architected Tool、AWS Trusted Advisor、AWS Healthなどの具体的なツールの活用方法も紹介されています。後半では、Accorの事例として、COVID-19の影響下でのクラウド移行、Cloud Business Office (CBO)とCloud Platform Engineering (CPE)の新体制への移行、Architectural Decision Records (ADRs)の導入など、大規模組織での実践的な取り組みが共有されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
クラウド最適化の基礎:セッション概要と背景

ご参加ありがとうございます。本日は、ライフサイクルを通じたアーキテクチャのベストプラクティスについてお話しします。これはレベル200のセッションですので、非常に深い内容ではなく、長期的な成功のための基礎的なガイダンスとなります。



では、本日の内容についてご説明します。 まず最初に、スピーカーの紹介をさせていただきます。次に、Cloud Optimizationとは何かについて説明します。これは人によって異なる意味を持つ可能性がある言葉だからです。そして、Cloud Optimizationの journey(道のり)について、時間の経過とともにどのように進んでいくのかを説明します。ワークロードのライフサイクルやベストプラクティスの採用と共有の過程などをカバーします。 その後、スピーカーを交代して、利用可能なツールとその具体例をいくつか紹介し、最後にお客様の成功事例をご紹介します。本日は幸運にも、お客様にもご参加いただいています。


まず簡単にスピーカーをご紹介させていただきます。私はBradley Acarです。AccorのJeffがCharlesと一緒にフランスから来ています。Charlesは私たちのSolution Architectの一人で、これから私がお話しする内容を、どのように彼らなりのものにしていったかをお話しいただきます。 始める前に、Cloud Optimizationの説明に入る前に、クラウドへのワークロードの移行や新規構築を検討する際に、皆さんが自問する質問について考えてみましょう。かなり大きな聴衆の方がいらっしゃいますので、すでに成熟した知識をお持ちの方もいれば、AWSやクラウドテクノロジーの初期段階を検討されている方もいらっしゃると思います。両方のグループに向けてお話ししたいと思います。なぜなら、そのジャーニーを通じて成熟していく中で、考慮すべき部分がそれぞれにあるからです。
Cloud Optimizationの本質と継続的改善の重要性




標準化をどのように推進するか、自問されていますか?大規模な組織でも小規模な組織でも、異なるチームが異なることを行っているかどうかを考えてみてください。 コストをどのようにコントロールするか?これはCloud Optimizationが示す重要な部分です。 システムの障害への耐性をどのように強化するか?つまり、レジリエンスや障害に耐えられる能力を求めているということです。 そして、チームが組織全体のガバナンス、コンプライアンス、管理フレームワークをどのように遵守するようにするか?

では、Cloud Optimizationとは実際何なのでしょうか?これは異なるビルダーによって異なる意味を持つ可能性があることを私たちは理解していますが、これが私たちの考え方です。私の肩書きにCloud Optimizationという言葉が入っていることにお気づきかもしれません。クラウドジャーニーを最大限活用するためのガイダンスを提供することが、私たちチームのフルタイムの仕事なのです。長期的なビジョン、長期的な成功を考える必要があります。これは、目的に対して最高の価値をもたらすようにワークロードを設計、構築、運用する行為です。ここでいう目的とは、ビジネス目的を指します。そしてこれを可能にするのは、トレードオフを行うことです - 行うことすべてが、一つのものと他のものとのトレードオフになります。

それは、コスト、信頼性、あるいは顧客に適切な機能を提供するために市場投入までの時間を調整するといったことかもしれません。つまり、ここでの目的は、自社のビジネスニーズに合わせてトレードオフのバランスを取ることです。時として見落とされがちなのは、これがテクノロジーだけでなく、人材とプロセスにも当てはまるということです。

本日お話しする内容は、Cloud Optimization FrameworkとWell-Architected Frameworkという2つのフレームワークに基づいています。また、Well-Architected Tool、Trusted Advisor tool、AWS Healthなどのツール群もあります。後ほど、別の講演者がこれらのツールとその使い方についてご説明します。私が何度か申し上げているように、これは一つの旅路なのです。なぜ旅路なのか?なぜライフサイクルとして考える必要があるのでしょうか?それは、ベストプラクティスが時とともに変化し、何も静的ではないからです。業界のトレンドが新しいイノベーションを促し、新しいサービスの採用を促進し、そしてワークロードは自然と進化していきます。お客様のために機能を追加し、変更を加え、継続的にローンチを行っていく中で、これらすべての変化にどう対応していくのかを考えてみてください。時間の経過とともに、クラウドの利用を継続的に最適化することが非常に重要です。これは段階的なプロセスであり、ビジネス成果をサポートし、得られる利点を最大限に活用するために、成熟度を徐々に高めていくのです。先ほど言及した2つのフレームワーク、Well-ArchitectedとCloud Adoption Frameworkのガイダンスに従えば、段階的な改善のフェーズで構成されています。

階段状に描かれているのをご覧いただけると思いますが、これは一度に一つずつ、小さな単位で段階を上っていくというイメージです。時々見かける間違いやアンチパターンは、すべてを一度に実行しようとすることです。そうする必要はありません。小規模から始め、ゆっくりと進め、小規模で実験してください。組織全体でスキルと成熟度が向上するにつれて、改善の階段を上っていき、最終的に目指すのは継続的な改善です。繰り返しになりますが、これはテクノロジーだけでなく、人材とプロセスにも当てはまります。

これらのフェーズについて、もう少し詳しく見ていきましょう。クラウドの成熟度への道のりは段階的なアプローチです。私の今日の話では、フェーズとステージという言葉を互換的に使用しているかもしれません - 同じ意味です。今日の私の講演では、用語の定義は厳密ではありません。しかし重要なのは、一つのステージで学んだことが次のステージの土台となるということです。時間とともに学び、スキルを向上させることで、その時点での技能、専門知識、知識が向上していきます。
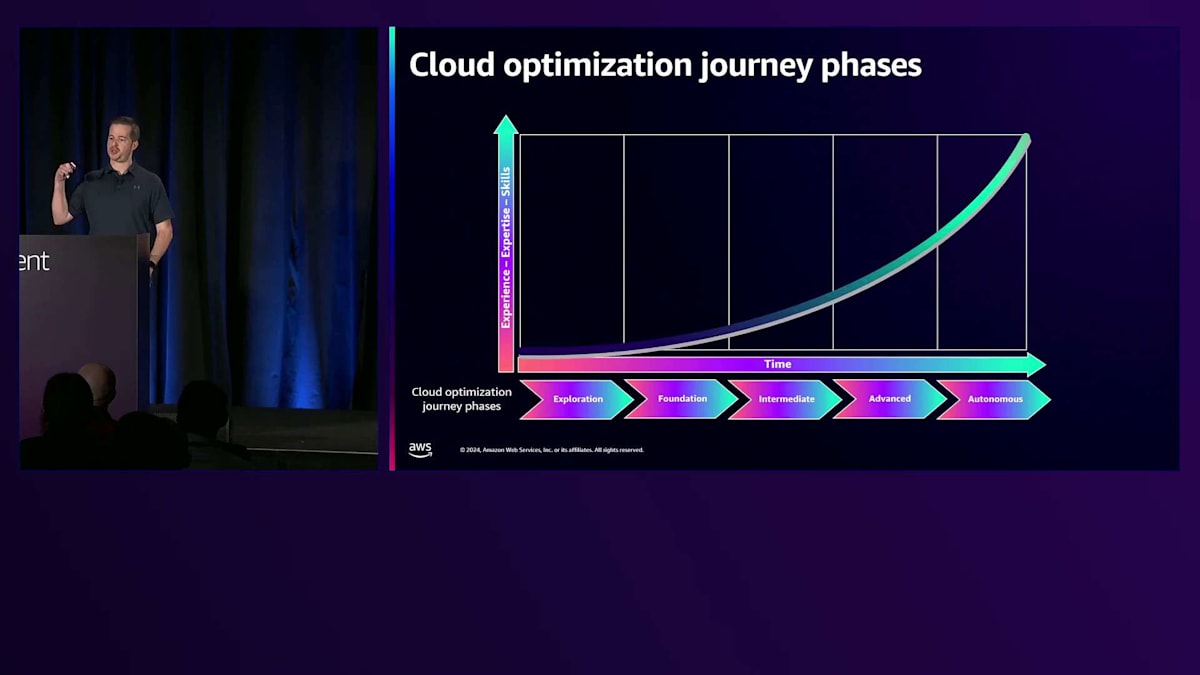
ビジネス全体のビルダーについて考えてみましょう。この会場にいらっしゃる方々かもしれませんが、何人かはアプリケーションの直接の所有者かもしれませんし、Cloud Center of Excellenceのようなところから来られた方もいるかもしれません。また、ビジネスの意思決定者として参加されている方もいるでしょう。本日のクラウド最適化について最も重要なポイントは、すべてのビルダーを巻き込む必要があるということです。CTOや経営陣といったトップから現場まで、リーダーからの支援を得る必要があります。時間をかけて着実に進めることで、進歩とともにスキル、専門知識、経験を積み上げていきます。つまり、時間とともに能力を向上させていくという推進力が生まれ、自律的なステージに達すると、私たちが継続的改善と呼ぶものを推進していくことになります。
Well-Architected Frameworkとクラウド最適化の実践的アプローチ
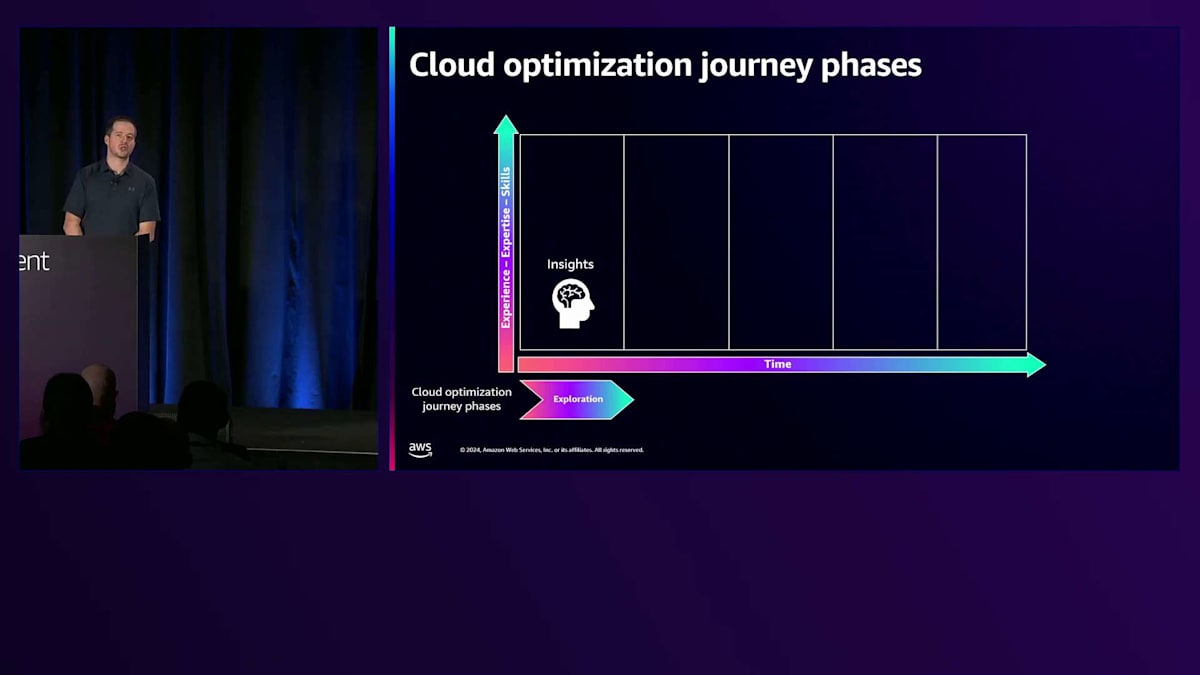
これらのフェーズの詳細についてお話ししますが、これは完全な内容ではありませんので、フレームワークを読んで詳細を学んでいただければと思います。各フェーズで考慮すべき点をいくつかご紹介します。まず最初のExplorationフェーズですが、なお、ここでの用語にはあまりこだわる必要はありません。これからお見せするスライドのフェーズ名は、そこまで重要ではありません。重要なのは、フレームワーク自体を参照し、ガイダンスを読み、自社に適した形で実装することです。ここでは5つのステージを示していますが、3つでも7つでも構いません。この講演から自社に適用できる部分を取り入れ、カスタマイズしていただければと思います。要は、長期的な考え方や取り組み方についてのガイダンスを提供することが目的で、それを自分たちなりにアレンジしていただければいいのです。
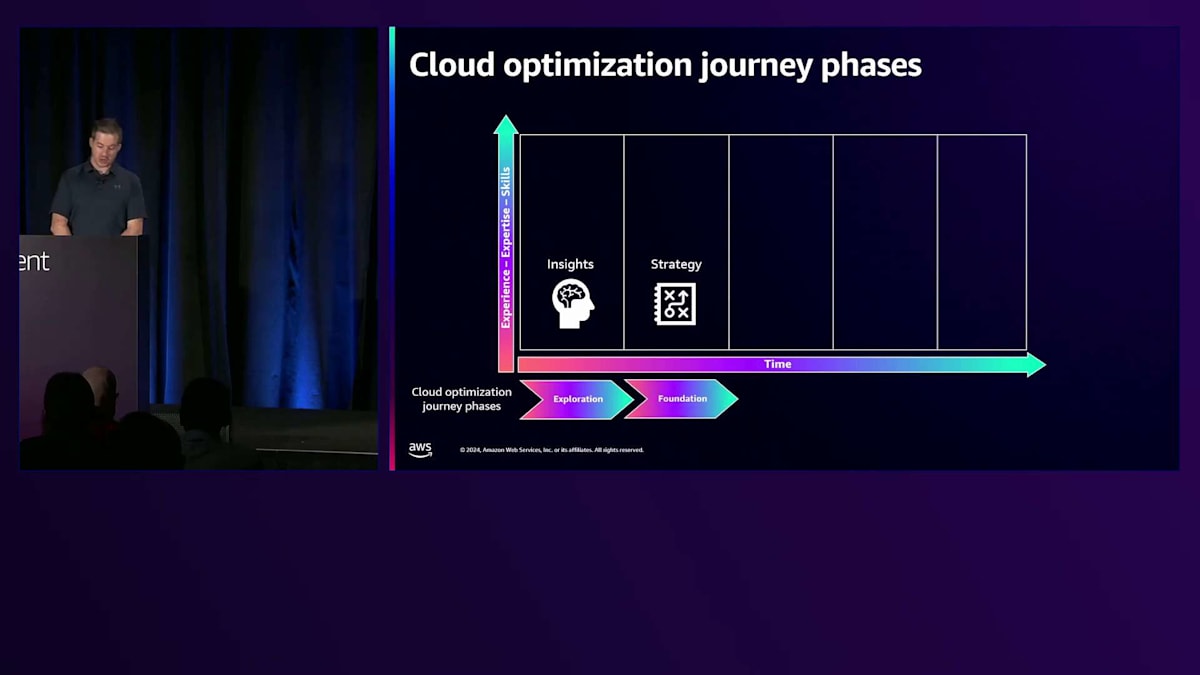
Explorationフェーズの初期段階では、必ずしも会社全体に適用する必要はありません。1つのチーム、1グループのビルダーから始めても構いません。大規模な企業では、最適化の journey の異なるフェーズにいるチームが混在していても問題ありません。このExplorationフェーズでは、クラウドコンピューティングの概念を学び、小規模なプロジェクトで実験したり、POCを実施したりします。そしてすでにこの段階で、サービスのコストについても検討を始める必要があります。最初に行うのは、AWS Cost Calculatorを使って、POCに必要だと思われる項目を入力し、組織全体への展開を考える際のコストの概算を把握することです。また、この段階ですでにガバナンスについても考え始める必要があります。クラウドガバナンスモデルをどのように構築するか、組織のポリシーは何か、すべてのチームやビルダーに考慮してもらいたい譲れない重要な事項は何かを考える必要があります。制約を緩くしたい場合もあれば、イノベーションに重点を置いてビルダーにある程度の裁量を与えたい場合もあるでしょう。それは業界や規制によって異なります。つまり、POCや初期段階から、チームに対してどのような制約を設けるかを考える必要があるのです。
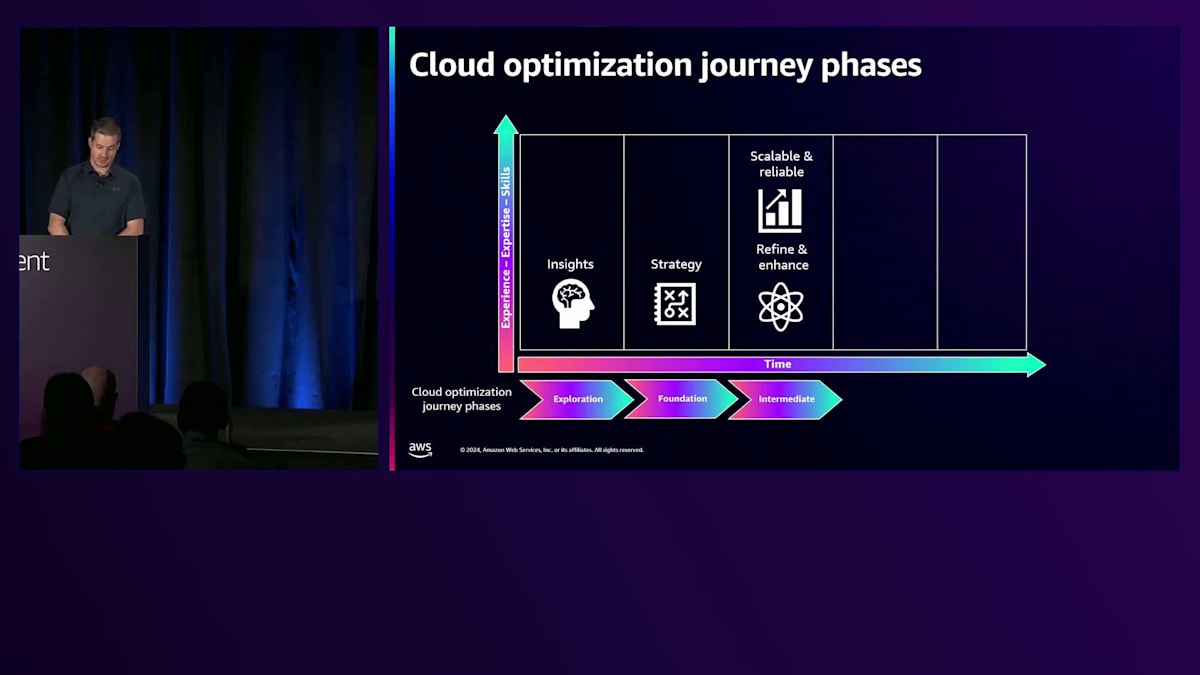
Foundationフェーズに移ると、ここではクラウド戦略に本格的に焦点を当てます。戦略の策定を開始し、組織全体でのクラウド利用に関する構造を作り始めます。基盤となるインフラを整備し、この早い段階で考慮すべきことには、共有ログ、共有ネットワーク、アプリケーション間やチーム間、リージョン間で提供が必要なサービスなどがあります。例えば、中央認証などです。CloudWatchやCloudTrailを使用するかどうかも検討し始めます。今すぐに実装する必要はありませんが、利用が本格化した際のプランは持っておく必要があります。次のステージは、Intermediate フェーズと呼ばれるもので、ここで実際にクラウド上での設計やアーキテクチャの構築を始めます。ベストプラクティスを積極的に読み、構築を始めながらアーキテクチャのレビューを行います。
ガバナンスの観点から、これら2つのステージでは、コスト管理ポリシーとリソースタグ付けポリシーに重点を置きます。繰り返しになりますが、これらについて早期に考え始めるほど、長期的な成功につながります。今日、AWS環境で複数のアカウントを持ち、コストセンターに基づいて会計の突き合わせやコストの帰属を試みている方々がどれくらいいるかを尋ねると、多くの方が該当するようです。そのため、タグ付けのような仕組みを使用し、早い段階でポリシーを実装して遵守を確保することが重要です。
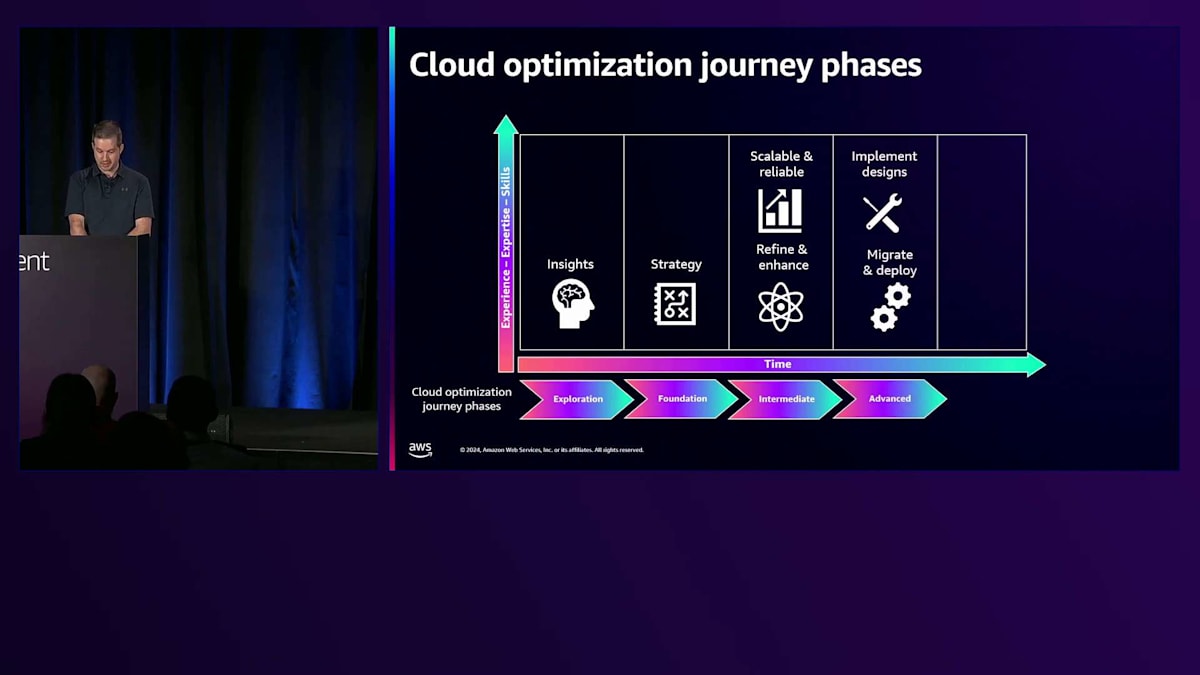
次のステージは、Advanced(高度)な段階で、ここではCI/CDパイプラインの構築・展開を考え、自動化されたセルフサービスのデプロイメントツールを導入するかもしれません。ビジネスユーザーが新しいアカウントをリクエストできる社内のLanding Zoneを用意しているかもしれません。ベストプラクティスとの整合性を確保するため、定期的なアーキテクチャレビューを実施します。この部分は非常に重要で、後ほど詳しく触れますが、人、プロセス、テクノロジーに関するベストプラクティスの理解は、一時点で完了するものではありません。継続的に行う必要があります。ワークロードに変更がある場合や新しいものがローンチされる場合は常に、アプリケーションの状態についてある程度のレビューや発見が必要です。
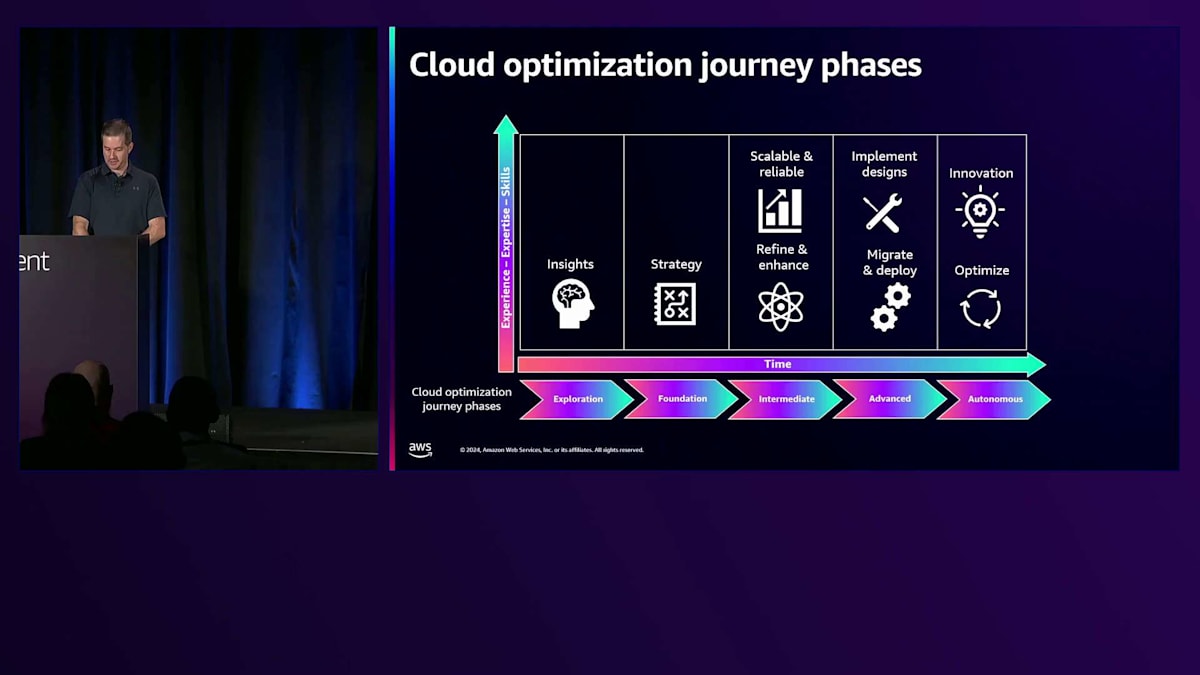
Autonomousステージに進むと、ここで私たちが「継続的な最適化の準備が整った」と判断します。継続的な最適化とは、成熟したプロセスと継続的な改善によってクラウドオペレーションを最適化し、イノベーションを推進することを意味します。このステージでは、システムが適切に機能することに重点を置き、お客様自身のイノベーションのために、機能や展開のTime to Marketに注力することができます。
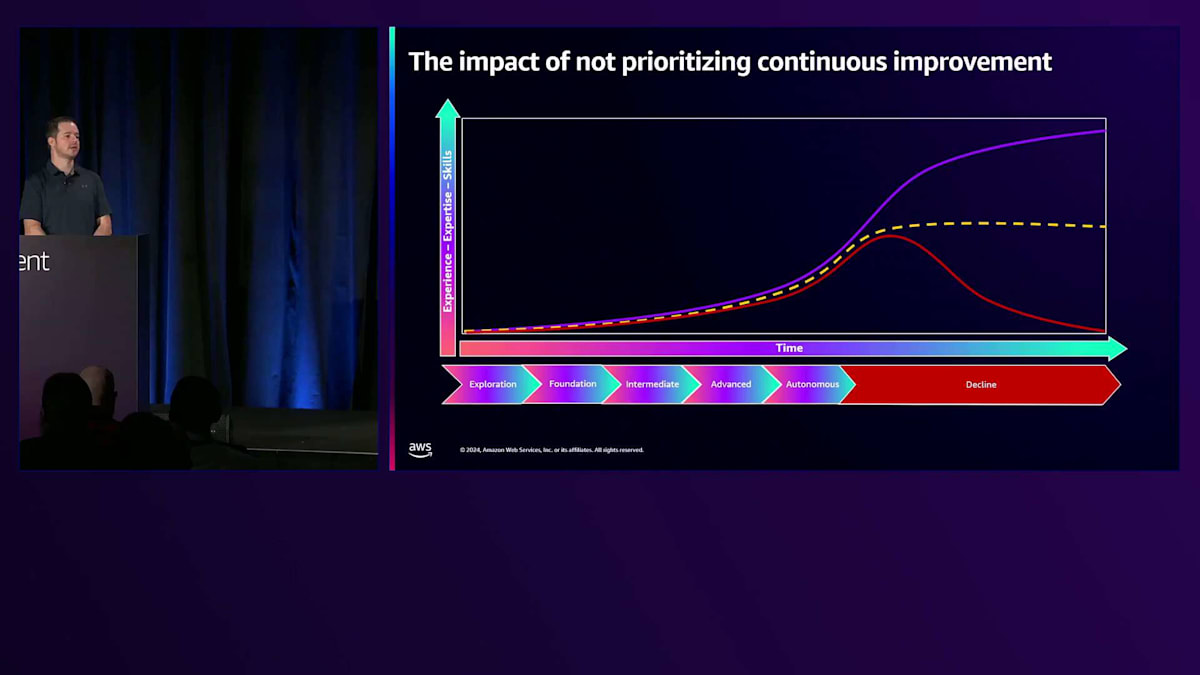
これらのフェーズを経て、継続的な最適化の段階に到達します。 Autonomousステージを通過した後も、継続的な改善を優先することが重要です。一般的に、フェーズを進めていく中で、チームのスキルや専門知識、経験が成長すると、プラトー(安定期)に達しつつも業界の変化やワークロードの変更に対応し続けると考えられます。私たちが皆さんに目指していただきたいのは、このブルーラインです。ご覧の通り、ブルーラインは多少減速しても上昇傾向を維持しています。継続的な改善に向けて積極的に取り組んでいただきたいのです。

これらすべてのステージを経て継続的な最適化の段階に達すると、それは繰り返しのライフサイクルとなります。Well-Architected Frameworkからのガイダンスを参考にすると、複数のチーム間で学びを共有することが重要です。クラウドに関するすべての作業を単一のチームで行っている企業は何社ありますかと尋ねると、おそらく1、2社程度でしょう。しかし、複数のチームがアプリケーションの構築などすべての作業を行っているケースは、皆さんの大多数に当てはまります。


ここで重要なのが、優れたナレッジ共有です。小規模な企業であれば、メンバー間での知識共有は比較的容易です。実際に作業を行うビルダーが意思決定を行い、実務を担当します。 しかし、大規模な組織ではどうでしょうか?クラウドで新しいアプリケーションの構築を始め、ビジネスとクラウドの利用が拡大し、大規模な連携組織となった場合、あるいはすでに大規模な組織で移行を進めている場合はどうでしょうか?企業の成長に伴い、運用、ガバナンス、知識共有の複雑さも増していきます。顧客との対話でよく見られるパターンとして、非常に革新的な1つのチームが存在することがあります。そのチームは革新的な取り組みを独自に進めていますが、他のチームは取り残されてしまいます。最も重要なのは、これらのチームの1つがこのライフサイクルを通じて学んだことを、他のチームと共有することです。つまり、継続的な改善とライフサイクルなのです。これは、非常に進んでいて自律的なチームの一例かもしれません。

環境に変更が生じるたび、それがチケットの発行であれ、新しいワークロード、機能の変更、機能のローンチであれ、このライフサイクルの要素を考慮する必要があります。ここには多くのフェーズがありますが、これから詳しく見ていきます。 3つのフェーズだけを使用したいと決めた場合でも、それで構いません。まずは何かを始め、小さな部分から取り組み、自分たちに合うものを取り入れて独自のものにしていってください。
自動化と対話:クラウド最適化のための二つの発見プロセス
これは一時的なものではなく、継続的な取り組みなのです。最初のレビューだけでは不十分です。なぜなら、新しいWorkloadのレビューを行って展開した後、時間が経過してBuilderの変更があったり、メンバーの入れ替わりがあったり、Workloadの状態が変化したりした場合、それを把握できているでしょうか?私たちが考える最初のフェーズは「Learn(学習)」フェーズと呼んでいますが、これは見過ごされがちな部分です。スピードを優先してトレードオフを行う際、BuilderにはLearningよりも機能のローンチに注力させたいと考えるかもしれません。しかし、Learningは最も重要な基礎的な部分です。ここで実際にベストプラクティスを理解するからです。

AWS Well-Architected Frameworkを読んだことがある方はどれくらいいますか?Cloud Adoption Frameworkはどうでしょうか?Well-Architected Frameworkをまだ読んでいない方は、今週の後にアクションアイテムとして取り組んでいただきたいと思います。今週は忙しく、たくさんのアクションアイテムがあることは承知していますが、まずOperational Excellenceピラーを読んでいただきたいと思います。その理由は、次の講演者であるCharlesが紹介するツールと自動化に関連する内容があるからです。 集中ログ管理を実施し、成熟度のステージを進めていけば、環境のスナップショット的なビューを得るのは比較的簡単です。しかし、人に関するAPIコールは存在しません。人に関するAPIコールができるようになるまでは、人を中心としたプロセスとオペレーションの構築を優先する必要があります。
最初に行うべきことは、Operational Excellenceピラーを読むことです。このピラーの最も重要な2つのベストプラクティスは、外部顧客のニーズの評価と内部顧客のニーズの評価です。主要なステークホルダーを巻き込み、ビジネス、開発、運用チームを集めて、フォーカスすべき領域を決定します。次はSecurityピラーかもしれません。ここでビジネス目標に基づいて、フォーカスと優先順位を決定します。トレードオフを行う際、最初は速度を重視してCostを犠牲にすることもあるでしょう。サイクルを繰り返す中で、次のフェーズでCostの最適化を行うことができます。

次は「Measure(測定)」です。 ベストプラクティスについて学び、理解したところで、実際にWorkloadの状態を評価し、ベストプラクティスと比較します。Securityチームは、Workload、アカウント、組織全体で発生する不正アクセスや意図しない変更を示す可能性のあるイベントを分析するために、ログやFindingsなどを活用することが多いです。通常、「今日、効果的にイベントをログ記録していますか?」といった観点でレビューを行います。自動化された発見と対話型の発見を組み合わせる必要があります - これについては後ほど詳しく説明します。
ベストプラクティスが守られているか否かにより、特定のベストプラクティスに従わないことで発生するアンチパターンやリスクが存在します。例えば、Reliabilityピラーを例に取ると、よく見られるアンチパターンの1つは、サービスの特定にドメイン名ではなくIPアドレスを使用することです。これを経験したことがある方はどれくらいいますか?オンプレミス時代のIPアドレスの使用から移行してきた記憶があると思います。私も自宅のネットワークではまだこのアンチパターンを使用していますが、自宅での障害リスクは大規模な本番システムと比べてはるかに低いものです。

特定のベストプラクティスを実装する、あるいは実装しないことのリスクを確実に特定する必要があります。 それが完了したら、優先順位付けの段階に入ります。優先順位を付け、実装、構築、アーキテクト、または改善を決定するものは、ビジネスの優先事項に基づいています。すべてを実施する必要はありません - あなたやお客様に何らかの痛みをもたらすもの、またはアプリケーションをよりコスト効率の良いものにするものを実施する必要があります。例えば、特定のWorkloadの構築方法を変更する機会を見出したかもしれません。そして、データ分類のような事項について、組織全体により具体的なガイダンスを提供できるかもしれません。Day Oneの時点で - もちろん、常にDay Oneであることを願いますが - データ分類について考えていた方はどれくらいいますか?はい、銀行のお客様が見えますね。素晴らしいです。
残りの方々にとっては、それは最優先事項ではありませんでした。ビジネスをフェデレーション化し、チームにより多くの自律性を与え始めるにつれて、データ分類やネットワーキングなどについて考える必要があるかもしれません。私たちは中央集権的なネットワーキングやIPアドレスのアンチパターンについて話してきました。ここで、データ分類ポリシーやガバナンスルールのようなものを実装する必要があるかもしれません。そして、組織内の他のビルダーに代わってネットワーキングが確実に管理されるようにする必要があります。
また、パフォーマンスの改善点を特定したとしましょう。ここで優先順位付けが重要になります。今すぐに対処または実装すべき最も重要なことは何で、後回しにできることは何でしょうか?最高のお客様の中には、新機能のリリースよりもセキュリティパッチの適用を優先する方々もいます。それがあなたにとって適切かもしれません。それが良いかもしれません。あなたのビジネスに何が適しているかを判断すべきです。

最後に、これらの優先順位を決定したら、改善を実行します。測定フェーズから改善フェーズに移行する際の重要な部分は、これらのリスクを理解し、リスクについて学び、ベストプラクティスとその理由について学ぶことです。ここでの大きな要因は、 このテクノロジーを使用する上での知識、スキル、専門性です。リソース、人員、予算が必要であることは認識しています。ビジネスの運営において、トレードオフが発生しています。

この優先順位付けを推進するメカニズムを持つことが重要です。また、他のチームに学びを共有することが非常に重要です。なぜなら、実施した改善は時間とともに他のWorkloadにも適用できますし、 他のチームにも適用できるからです。すべてを行い、他のチームよりも速く革新を進めている高スキルのチームが1つあるかもしれません。彼らは知識を共有すべきです。Jeffから聞くことになりますが、彼らのコアには、実際に互いに公開し共有するアーキテクチャパターンという概念があります。知識の共有は非常に重要で、他のチームから得られた教訓も元のチームに還元することができます。
AWS Health:プロアクティブなクラウド管理ツール
私たちがこれらのステージを進めていく中で、常にお客様とお話しできることは非常に幸運なことです。本日ご参加いただいた皆様、お話を聞かせていただき、ありがとうございます。時々、お客様から「Well-Architectedは非常に有用だが、ワークロードの特定の部分を理解するのに時間がかかる」というお声をいただきます。ここで申し上げたいのは、ワークロードの状態を理解するためにどれだけの時間を費やすかは、皆様次第だということです。これには2つのアプローチ方法があります。

通常、誰が何をしているのか、セントラルロギングを使用しているのか、メトリクスから即座に目立つものは何か、Observableのベストプラクティスに従っているのかなどを把握するための調査が必要です。しかし、APIコールでは把握できない部分、つまり「人」についてはどうでしょうか?私たちにとって、環境とワークロードの調査は、テクノロジー、人、プロセスをカバーするものですが、これには2つの方法があり、常に両方を実施すべきです。もちろん、状況に応じてどちらかを優先することもできます。
1つ目は、私たちが「Automated Discovery」と呼ぶものです。これは、AWS Trusted Advisor、Service Screener、その他ワークロードの状態を自動的に可視化してくれるツール全般を指します。アラート、CloudTrail、あるいはCloudWatchからカスタムQuickSightダッシュボードにデータを送るようなものかもしれませんが、本質的にはイベントと自動化に関するものです。アカウントで何かが発生した際に、組織内の担当者にアクションを促すイベントをトリガーするのは、優れたパターンの一例です。

しかし、それだけでは完全な全体像は把握できません。なぜなら人的要素があるからです。これが私たちが「Conversational Discovery」と呼ぶものです。両方の実施が非常に重要です。Conversational Discoveryは、特定のワークロードに関わる全てのステークホルダーを集めることです。セキュリティチームのメンバーや、セントラルネットワークチームのメンバー、そしてそのワークロードやアプリケーションのオーナーかもしれません。一定レベルで彼らを集め、一連の質問を通じて特定の決定が下された理由を理解する必要があります。通常、お客様には、そのワークロードをサポートするチームの組織構造を確認し、エスカレーションパスやどのようなサポートプロセスがあるかを理解し、その流れに沿ってビルダーたちを集めることをお勧めしています。それでは、ツールについて説明する次の講演者にバトンタッチしたいと思います。


ありがとうございます。では、クラウド最適化の journey で使用できるツールについて詳しく見ていきましょう。これには自動化されたアプローチと従来型のアプローチという2つの方法があります。従来型のアプローチは、先ほど議論したテクノロジーではなく、人とプロセスに重点を置いています。人とプロセスが、ここでの重要なトピックとなります。

AWSが「あなたのアーキテクチャは適切に設計されていますか?」という問いかけを始めたのは2012年のことで、かなり以前になります。これが、先ほどBradleyが説明したWell-Architected Frameworkの出発点となりました。これは、私たちの社内の働き方、インシデントへの対応方法、そして特にインシデントをいかに可能な限り回避するかという方法に触発されて生まれました。Well-Architected Toolは2018年からConsoleで利用可能になっています。 それ以来、Consoleで誰でも無料で利用できるようになってから、約1000回のアップデートが行われています。このツールは、質問、回答、原則を通じて、ステークホルダーとの対話をサポートするものです。Operational Excellence、Security、Reliability、Performance Efficiency、Cost Optimization、Sustainabilityという6つの柱に基づくベストプラクティスにアクセスできます。
Well-Architected Toolの主なメリットには、アーキテクチャのガイダンス、ワークフロー内のベストプラクティス、改善の測定、チーム内のコラボレーション強化が含まれます。Well-Architectedで私が特に気に入っている機能が4つあります。1つ目はLensで、すでにご存じの方もいらっしゃるようですね。Lensは、特定のドメインや業界に合わせた質問とベストプラクティスを提供します。サービス分析のようなドメインや、金融や医療のような業界固有のものなど、環境に応じて異なるLensを利用できます。
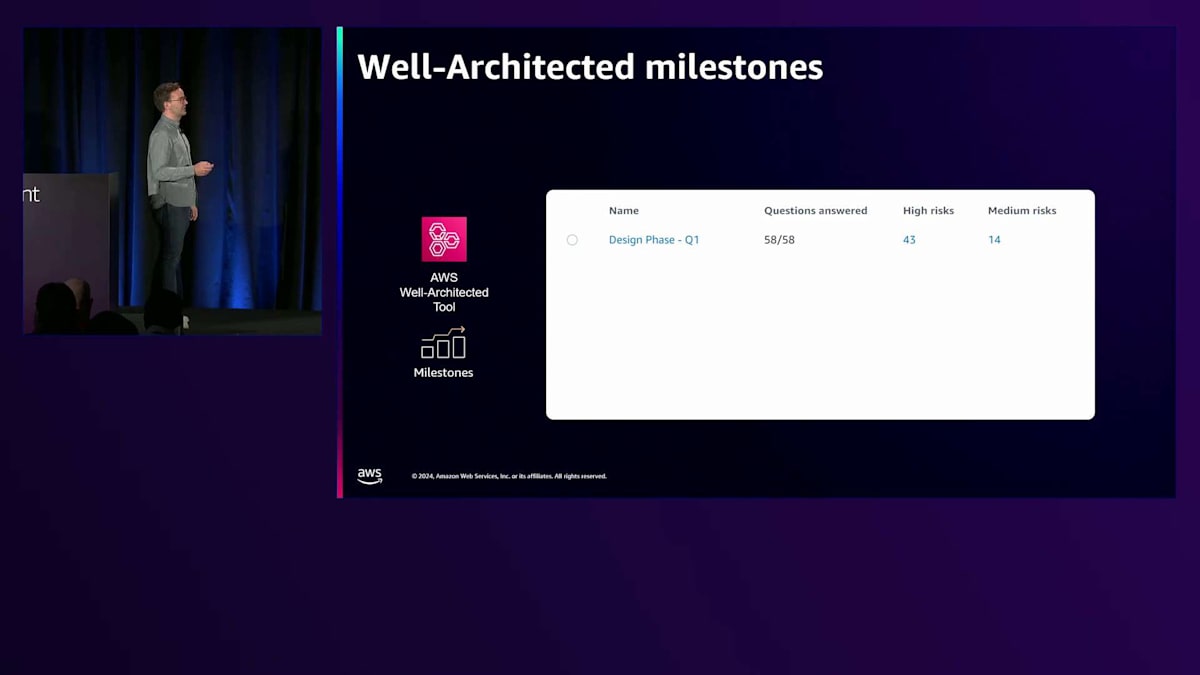
2つ目の機能はCustom Lensで、これは通常のLensに似ていますが、独自のビジネスニーズを取り入れることができます。独自の質問やベストプラクティスを追加して、組織全体で共有することができます。3つ目の機能は、ProfilesとReview Templatesを組み合わせたもので、これらの機能は組織内のレビューを加速させるのに役立ちます。4つ目の機能はMilestonesです。 Milestonesは、対話型の発見プロセスにおける改善を時系列で追跡するのに役立ちます。これは常にライフサイクルであることを忘れないでください。そのため、頻繁にレビューを行う必要があります。Milestonesを使用して、これらのライフサイクルを通じた進捗を測定し、改善を追跡できます。アーキテクチャやアプリケーションの変更点を簡単に振り返ることができ、チーム間で学びを共有することができます。


これにより、リスクが減少し、運用が最適化されます。 これが私たちが目指す姿ですが、時間がかかる可能性があります。完全なWell-Architectedレビューには最大8時間かかる可能性があるため、スピードと、許容できるリスクの最小数との間でどのようなトレードオフを行うかを検討する必要があります。その効果が表れるまでには数ヶ月かかる可能性があります。


では、自動化された発見についてと、ここでどのようなツールを使用できるのか、技術面に焦点を当てて見ていきましょう。 まず最初はAWS Trusted Advisorです。Trusted AdvisorはAWS環境を最適化するためのすぐに使えるサービスで、Cost Optimization、Security、Performance、Resilience、Service Limitsという5つの主要な領域にわたってAWSのベストプラクティスに沿うためのリアルタイムのガイダンスを提供します。


AWS アカウント内のビジネスサポート以上のプランで、最大482の異なるベストプラクティスを自動的にチェックします。デフォルトでは、アカウント内の56の異なるベストプラクティスをチェックします。これらのベストプラクティスは有効化されているため、実装するためのデータと推奨事項を得ることができます。AWS Well-Architected Toolに基づいて自動的に処理を行い、ツール内にデータが格納されるためWell-Architectedレビューの実施もサポートします。実用的な推奨事項を提供し、リスクを軽減するために各アプリケーションで必要な対応を理解する手助けとなります。

Trusted Advisorによって指摘されたリスクに基づいて、自動化を実装する方法を提供します。例えば、アカウント内のサービス制限などのイベントに自動的に対応することができます。制限に達した場合、その制限値の引き上げリクエストを自動的に行うプロセスを設定できます。
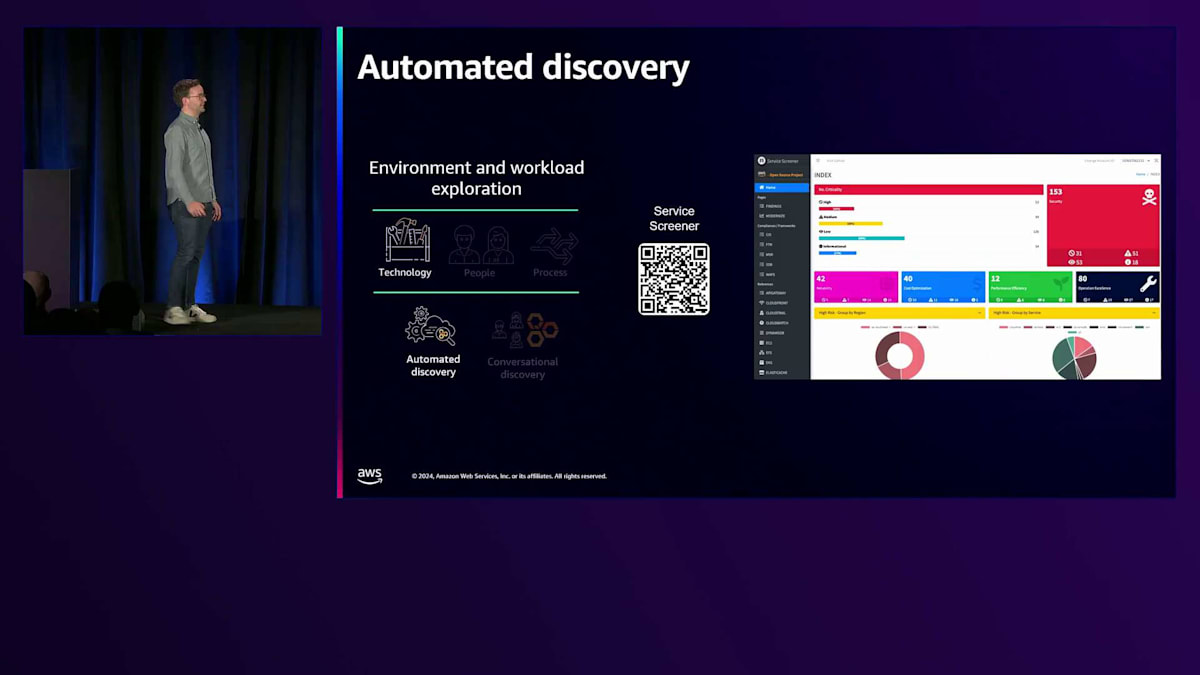
自動化された発見とテクノロジーについて続けると、Service Screenerがあります。これは2021年からAWSのチームによって開発されたオープンソースツールで、AWS環境内で自動チェックを実行し、Well-Architected Frameworkに基づいたAWSの推奨事項を提供します。PythonとAWS SDKをベースに構築されており、RDS Aurora、S3などの環境設定を判断するために複数のAPIコールを実行します。このダッシュボードでAWS環境の最終的なスナップショット分析が得られます。ただし、マネージドサービスではないため、自分でビルドする必要があるというトレードオフがあります。


自分でビルドして実行することで、ツールに独自の自動化や統合を組み込むことができます。これまで手動または自動化された方法でワークロードを発見する方法を見てきましたが、次は自動化された方法でプロアクティブなモデルを活性化する方法を見ていきましょう。
AWS Healthについてお話ししましょう。AWS HealthはAWSサービスの健全性に関するリアルタイム情報を得るための信頼できる情報源です。AWS Healthから取得できるイベントには2種類あります。1つはアカウント固有のイベント、もう1つはパブリックイベントです。アカウント固有とは、AWSアカウントまたはAWS Organizationsに特化したイベントのことを指します。AWS アカウント内の影響を受けるリソースについて正確な詳細情報を提供し、パブリックイベントは全てのAWSカスタマーに影響する可能性のある、より広範なサービスの問題をカバーします。これは、インシデントを素早く効果的にトラブルシューティングし、大規模なサービス管理に役立つ実用的な洞察を提供することを目的としています。
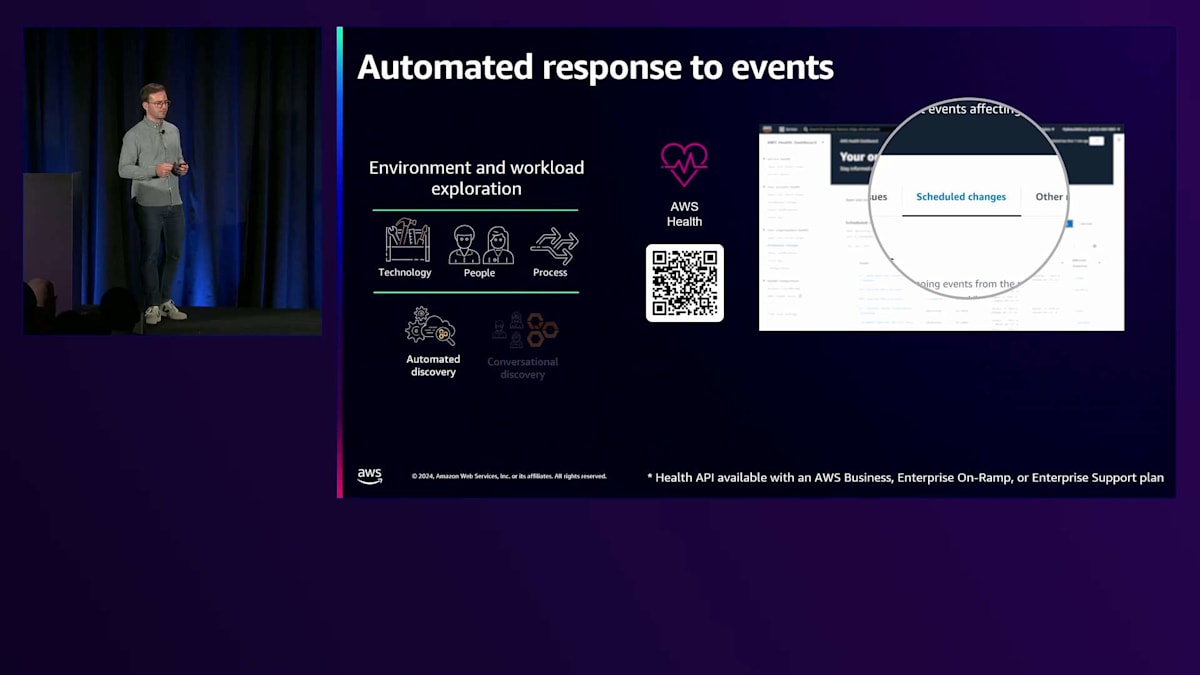
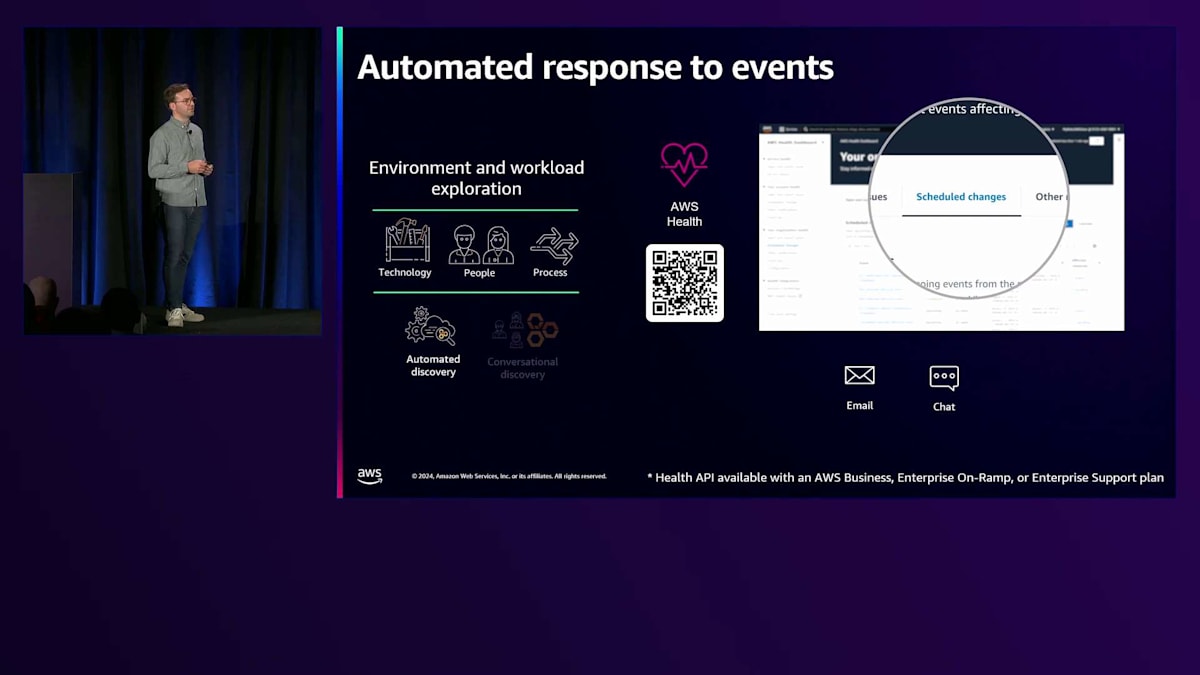
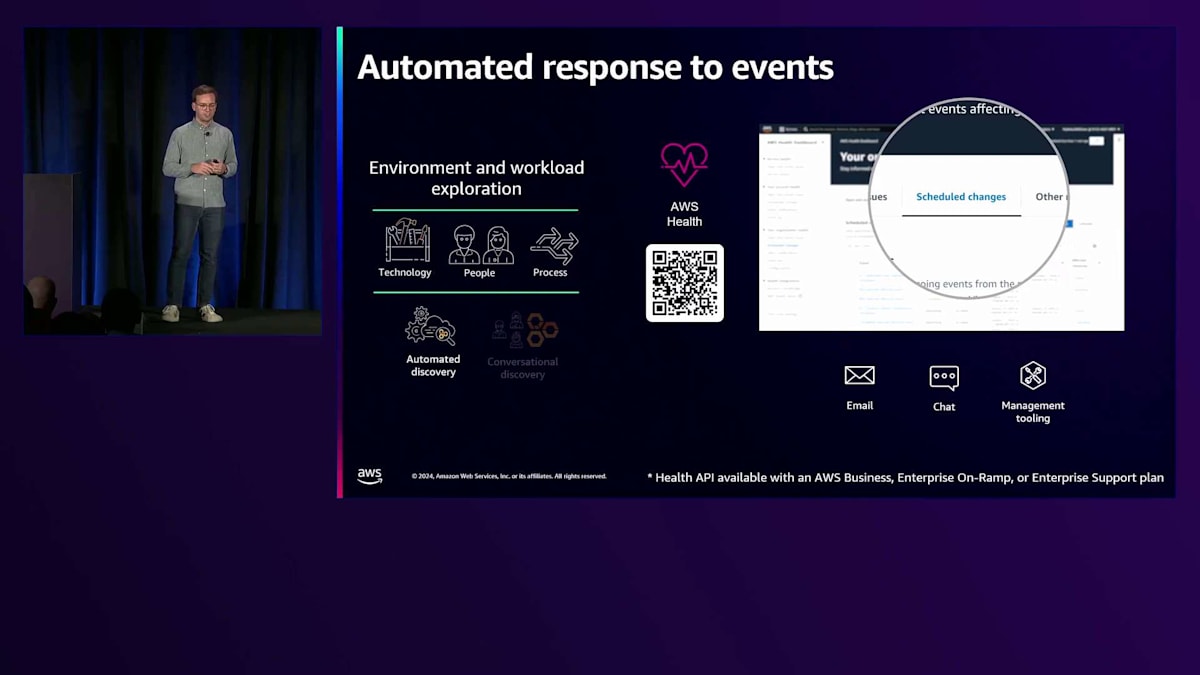
例えば、 AWS Healthで確認できるスケジュールされた変更があります。スケジュールされた変更とは、例えばMySQLエンジンのサポート終了や、 EC2エンジンのサポート終了などが該当します。このような場合、AWS Healthからアラートを受け取り、自動的にメールを送信したり、適切なチームとチャットを開始したりすることができます。例えば、Kubernetesの場合、サポート終了が近づいているためKubernetesデザインを更新する必要があることをチームに通知できます。また、管理ツールと連携して、適切なチームにチケットを自動的に発行し、大規模に管理することもできます。
Accorのクラウドジャーニー:COVID-19後の変革と Well-Architected の実装

ここで、AccorでのOperationsについてお話しいただくGeoffroy(米国の同僚にはJeffとして知られています)をご紹介したいと思います。Bradley、Charlesの皆様、このBreakout Sessionにお招きいただき、ありがとうございます。本日皆様とご一緒できること、そして私たちのCloudジャーニーについて共有できることを大変嬉しく思います。私はAccorに11年間在籍しており、最初はSecurity Engineerとして、そして過去3年間はCloud Principal Architectとして働いています。Accorはフランスの企業で、ホスピタリティ業界のグローバルリーダーとして、5,700以上のホテルと10,000以上のレストラン・バーを展開し、ラグジュアリー、ミッドスケール、エコノミーセグメントにわたる45以上のブランドポートフォリオを持っています。Fairmont、Raffles、Pullman、Sofitelなど、私たちのブランドをご存知の方もいらっしゃるでしょう。私たちは持続可能で責任ある観光に取り組んでいます。

これらの質問に対して、適切な回答をどのように確保すればよいのでしょうか?皆様の多くがこれらの疑問をお持ちだと思います。大企業、特にAccorの実際の経験を共有させていただきます。

まだ進行中ではありますが、皆様の共感を得られることを願っています。当社におけるCloudのコンテキストについてお話ししましょう。COVID-19のパンデミックは、旅行の停止、予約のキャンセル、数千件の返金要求により、ホスピタリティ業界を一夜にして混乱に陥れ、アジリティの必要性が浮き彫りになりました。私たちの注力分野は、適応性の構築、実行可能性の確保、効率的なスケーリング、そして持続可能性となりました。これは、テクノロジーとビジネスの両面で大きな変革を表しており、ホスピタリティの運営方法を見直し、その仕組みを変更し、よりイノベーションの余地のある目的地を受け入れることを意味します。

AccorにおけるWell-Architectedの始まりについてお話しさせていただきます。私たちも皆様と同様、単一のAWSアカウントを使用したProof of Conceptから始め、Cloudが私たちの働き方にいかに大きな影響を与えるかを発見しました。最初は、Big Dataの移行という小規模なワークロードから始めました。この段階で、AWSが主導するAWS Well-Architected Frameworkを発見し、Solution Architect向けの独自ツールを使用してグローバルなインタビューを実施しました。これは非常に有意義な学習経験となり、アプリケーションを360度の視点で見ることができた最初の機会となりました。
次に私たちは、クラウドへの移行を希望するプロジェクトやメンバーを受け入れるため、"Welcome Cloud"と呼ばれるCloud Center of Excellence (CCoE)を立ち上げ、第2フェーズに移行しました。この段階では、共有責任モデル、ライフサイクル、大規模運用が、あらゆるミーティングで私が共有する日常的なキーワードとなりました。ロイヤリティスタックやコールセンターなど、複数のMigration Acceleration Programを実施しました。Well-Architected Frameworkは依然として重要な問題を見落とさないためのゲートとして認識され、MAPパートナーによって実施されました。私たちは自社用に簡略化したバージョンの作成を試みましたが、効果的な実装やデータの収集・フォローアップはできませんでした。

2021年、私たちはEnterprise Architectureとともに初のCloud-Firstストラテジーを策定しました。アプリケーションのランドスケープを維持し、様々な移行戦略を通じて私たちの目標をサポートするため、Application Portfolio Management システムを導入しました。年末までには、クラウドへの移行を開始することができました。 クラウド移行のリセットフェーズは2022年から2023年にかけて行われました。当初はコスト削減と回避を目的とした大規模なLift and Shift移行として始まりましたが、このプログラムを、クラウド成熟度を向上させ大規模運用に備えるための最初の変革プログラムとして位置づけを高めました。
技術面では、世界中の45以上のヘッドクォーター、本社サーバールーム、複数のデータセンターの移行が必要な、非常に異なるITシステムに対してLift and Shiftアプローチを実施しました。数ヶ月のうちに、Paris、Bahrain、Singapore、Sydney、Sao Paulo、Ohioの6つの新しいリージョンを確立しました。現行のホテルテクノロジーとの互換性を維持しながらクラウド運用に備えるため、ハイブリッドバージョンで同じ共有サービスを提供しました。組織面では、Cloud Center of ExcellenceとNinjaチームに限界が見えてきました。
これらの制限に対処するため、Cloud Business Office (CBO)とCloud Platform Engineering (CPE)と呼ばれる新体制への移行とアップグレードを行うよう助言を受けました。この移行により、ビジネスのためのクラウド導入を加速することができました。さらなる進展のため、週次ミーティングと集中型のArchitecture Review Board (ARB)を設立しました。これは単なるアーキテクチャレビューではなく、すべてのステークホルダーが参加し、学び、議論し、目標達成方法を決定できる運用レビューの場となりました。

最初に構築したすべてのプラットフォームから始め、その後各アプリケーションのレビューへと移行しました。最終目標を達成できない場合もあり、そのためにセキュリティ免除プロセスを作成し、アプリケーションオーナーとともにセキュリティ例外を適切に管理しました。これにより、目標期待値を満たすための詳細な計画を維持しながら、データセンターの閉鎖という目標を達成することができました。Well-Architected Frameworkを使用しましたが、各アプリケーションを個別にレビューするのではなく、レビュー時間を短縮するため、類似したアプリケーションパターンごとに作業を進めました。
効果的なディスカッションを管理するため、私たちはArchitectural Decision Records (ADRs)を導入しました。ADRsは、ワークロード用のデータベースの選択、ネットワークトポロジーの実装方法、パートナーがアプリケーションに接続する方法など、チームが行った決定を記録するものです。適切なオプションリストとその根拠を確立する必要がありましたが、さらに重要なのは、私たちの選択がもたらす結果を考慮することでした。ADRsはArchitecture Review Boardとリンクすることで、より良いコミュニケーションと方向性の統一を支援する強力なツールとなります。これらは、ライフサイクル中に変化する可能性のあるコンテキストに紐づいており、レガシーに関する質問への対応や、類似のコンテキストに対して類似のパターンを再利用することでスケールを管理しやすくなります。
Accorの今後:知識共有、データ活用、そして継続的な改善へ

知識というトピックは、特に教育とコーチングに関して非常に重要です。これは、アーキテクチャをスケールさせるために、知識の共有と学習の促進を確実にする必要があるためです。同じ方向性に向かって取り組むチーム間で、共通の知識と価値観を確立することが不可欠です。これは、Well-Architected Frameworkの教材を使用したトレーニング、ソーシャライゼーション、認定から始めることができます。この共通のマインドセットができると、ライブラリが重要になりますが、同時にイベントを作成し、Sandboxを通じてチームが成長するための自由なスペースを提供することも同様に重要です。
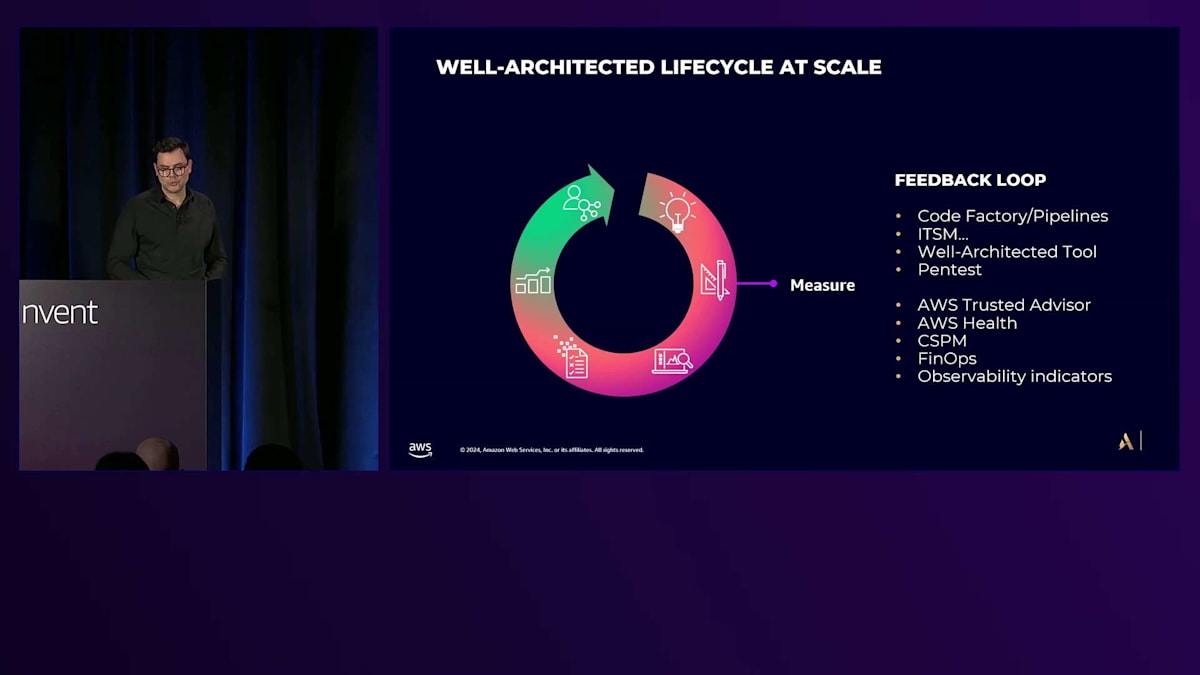
効果的なフィードバックループを作るには、できるだけ多くのデータを収集する必要があります。私たちは、Code FactoryとInfrastructure as Codeを使用して、ビルドフェーズでの情報を特定する取り組みを行っています。大企業では、変更管理情報についてIT Service Managementとも確認を行います。私たちは、Well-Architected Tool、AWS Trusted Advisor、AWS Health、そして私たちのCloud Security Posture Managementシステムからのデータを統合するツールを作成し、実行フェーズでこれらの情報を収集・分析しています。Health Assessmentは、Cloud Security Posture Managementと統合され、すべてのセキュリティ情報とアセスメントを一箇所に集約することで、可視性を向上させています。
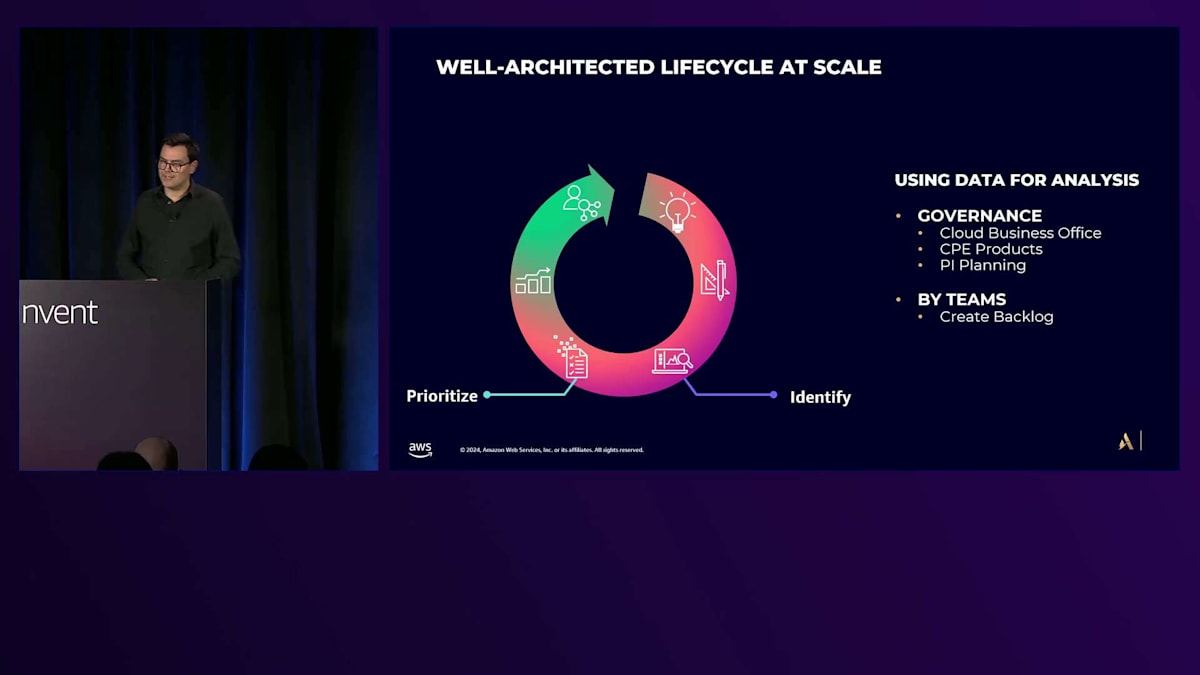
Service Level Objectivesは極めて重要で、何がうまくいっているか、何を改善する必要があるかを判断する必要があります。 分析フェーズでは、問題を特定することが不可欠です。Cloud Business Officeは、Cloud Platform Engineeringと緊密に協力して、この特定されたデータを活用し、ロードマップの優先順位付けに進むことができます。ビジネスとのロードマップの整合性はPI Planningで行われますが、考慮すべき2つの側面があります:クラウドのガバナンス監督と、チームが自身のパラメータを確認し、独自のバックログを作成できるようにするセルフサービス化です。
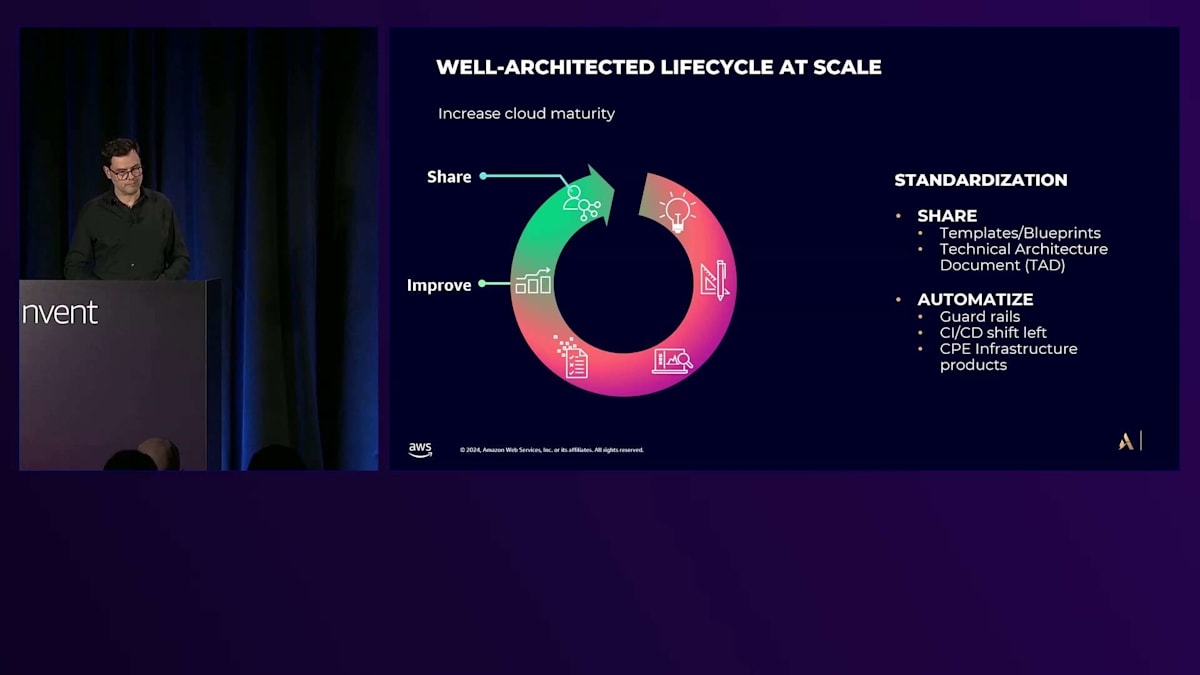
標準化を通じた改善に関して、私たちの成果物はクラウドの成熟度を一貫して向上させることに焦点を当てています。これには、新規または更新されたテンプレート、Blueprint、Technical Architecture Documentの共有、そしてそれらを自動化と消費を通じてスケールで実装することが含まれます。これは、CI/CDでのShift-leftアプローチで可能な限りのことをGuardrailを通じて実現できます。もちろん、Cloud Platform Engineering Productsがある場合は、それらを各チームが直接利用することができます。

今後の展望について、私たちはビジネスを効果的にサポートするため、Cloud Business Officeの成熟度向上に重点を置き続けています。ガバナンスと自律性のバランスを適切に保ちながら、十分な構造化を図り、チームにより多くの裁量を与えつつ、適切なレベルでのアーキテクチャ上の意思決定を管理していきます。ワークロード用のPKIの選定など、グローバルに影響を及ぼす決定はガバナンスレベルで対処し、一方で製品内でのローカルな影響を持つ決定については、Well-Architected Frameworkを通じてセルフサービス方式で対応できるようにします。Charlesとの取り組みでは、チームの教育とサポートを継続していきますが、重要なのは、私たちの役割を監査役から指導者へと転換し、自律性と説明責任を促進することです。

改善点の測定、特定、優先順位付けのため、より多くのダッシュボードを作成しています。私たちは、Accor Cloud Platform(ACP)Advisorという製品を開発しました。具体的なダッシュボードは今日はお見せできませんが、このツールはパターンとアンチパターンの特定に役立ちます。チームディスカッションと収集したデータを組み合わせることで、実際のパフォーマンスと自己評価の間の現実確認を行うことができます。ご清聴ありがとうございました。ご質問がありましたら、個別にディスカッションさせていただき、より詳しい情報を共有させていただきたいと思います。 ありがとうございました。皆様、ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion