re:Invent 2023: Amazon LexとBedrock Agentsの新機能で顧客体験を変革
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Amazon Lex reshapes CX with conversational workflows and generative AI (AIM222)
この動画では、Amazon LexとBedrock Agentsの最新機能が紹介されています。Generative AIを活用した新しいスロット解決機能や、Conversational FAQ intentなど、開発者の生産性向上とエンドユーザー体験の改善に焦点を当てた革新的な機能が解説されています。さらに、Lockheed Martinの事例を通じて、これらの技術が実際のビジネスにどのように適用され、製造プロセスの効率化や契約管理の迅速化にどう貢献しているかが具体的に示されています。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Lexと生成AIが顧客体験に与える影響

皆さん、こんにちは。ご参加いただき、ありがとうございます。素晴らしい機会です。皆さんに見つめられているこの部屋は少し緊張しますが、今日は会話型AIと、generative AIが日々の顧客体験構築にどのような影響を与えているかについてお話しします。私はMarcelo Silvaと申します。Amazon Lexのプロダクトマネージャーです。共同発表者はAmazon LexとBedrock AgentsのGeneral ManagerであるGanesh Gella、そしてLM FellowでMFC Enterprise Chief ArchitectのGregg Doppelheuerです。


それでは、始めましょう。アジェンダを手短に説明します。まず簡単な導入をします。generative AIについては 説明しません。皆さんはもうお疲れでしょうし、会話型AIやgenerative AIについては十分ご存知だと思います。ただ、これからの話の展望をお伝えしたいと思います。特にGaneshがgenerative AIを活用するために大規模言語モデルを使って実装されたAmazon Lexの新機能を紹介し、さらに重要なのは、GreggがLockheed Martinがこれらの機能をどのように活用してユースケースを実現したかを説明することです。
Amazon Lexの進化と大規模言語モデルの活用
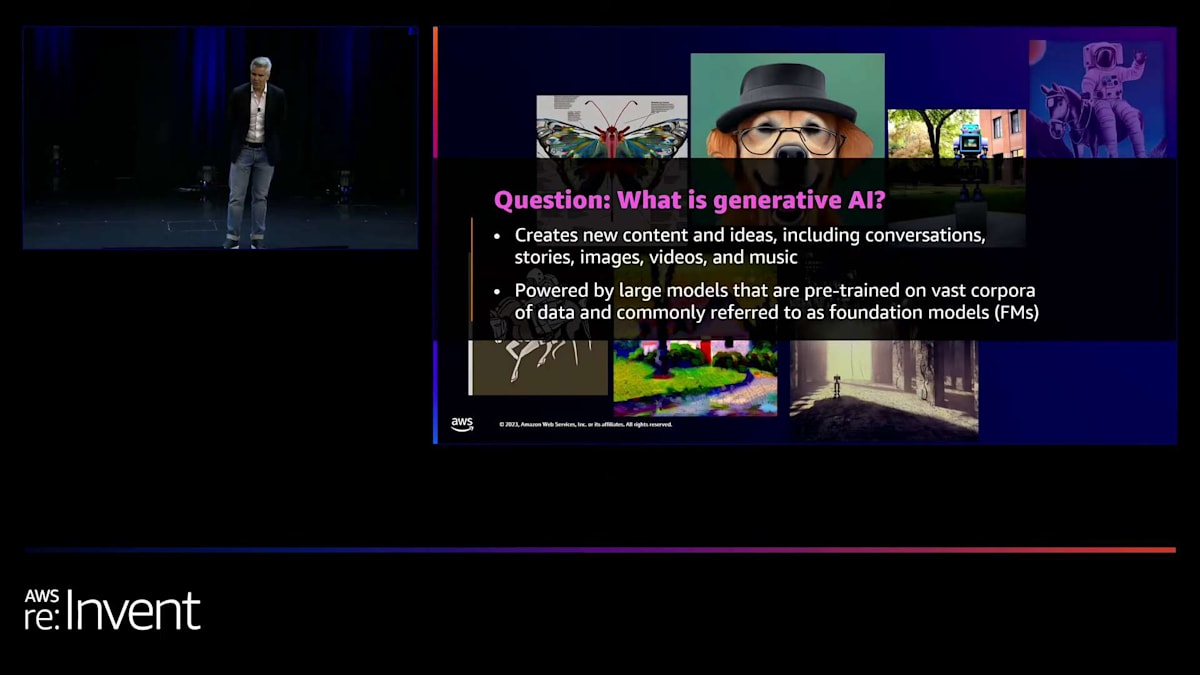
繰り返しますが、generative AIとは何かを説明するのではなく、Amazon Lexサービスの文脈でgenerative AIを位置づけます。新機能の開発内容と、Greggが紹介するユースケースの両方をお見せします。Amazon Lexユーザーの方や、何らかの会話型AI体験を利用している方はどれくらいいらっしゃいますか?素晴らしいですね。まず、ありがとうございます。こんなにたくさんの方がAmazon Lexを使っていただいているのを聞いて、見られて本当に嬉しいです。私たちはこのサービスに非常に情熱を注いでいます。多くの作業を行ってきました。
generative AIが私たちにとって何を意味するのか、簡単にお話ししましょう。大規模言語モデルの文脈でgenerative AIについて話すとき、これはLexにとって新しいものではありません。製品の発足以来、Lexでは数億のパラメータを持つ事前学習済みの教師なしモデルを使用してきました。皆さんは大規模言語モデルで遊んできたわけです。今日ほど大規模ではありませんでしたが、皆さんはこの種の革命の一部でした。そして今、generative AIについて、私と同じことが皆さんにも起こっているかもしれません。今年の初めから、家族が私の仕事を理解するようになりました。「ああ、あなたはこれをしているのね」と言って、あらゆる種類のアドバイスをくれます。私が知らなかったことをたくさん知っていて、様々な提案をしてくれますが、私たちはみなこれをやってきたのです。

だから、今みんながこれについて話しているのは本当にクールです。Lexで言語モデルとして使用してきたモデルは大規模で、会話体験のためのコンテキストを目的として構築されています。そして、皆さんが構築するボット、ボット定義を使用して、その体験に合わせてモデルの微調整を行います。例えば、ホテルを予約するボットを構築している場合、私たちは実際にintents と皆さんのボット定義に関連するモデルにバイアスをかけて、皆さんの体験に合わせて大規模モデルを微調整するモデルを作成します。
このスライドから理解していただきたい重要なポイントが2つあります。1つ目は、皆さんはすでに長い間、大規模言語モデルを使用しているということです。会話型エクスペリエンスを構築する際には、文脈を考慮することが不可欠です。2つ目は、これらのモデルが学習データに基づいているということです。今日は、過去数ヶ月間にLexで行ってきた取り組みをご紹介します。大規模言語モデルから得たデータを活用して、開発者体験とエンドユーザー体験をより迅速かつ優れたものにする方法をお見せします。
会話型AIの課題と Amazon Lexの特徴


以前、foundation modelsについて話しました。 foundation modelsとは何でしょうか?これについては多くの講演で耳にされたことがあるでしょう。 従来の機械学習モデルと、現在BedrockやTropicで使用されているfoundation models、そしてBedrock ecosystemの一部である他のパートナーのモデルとの唯一の違いは、過去の機械学習モデルが不正検出や感情分析といった非常に特定の目的のために構築されていたことです。
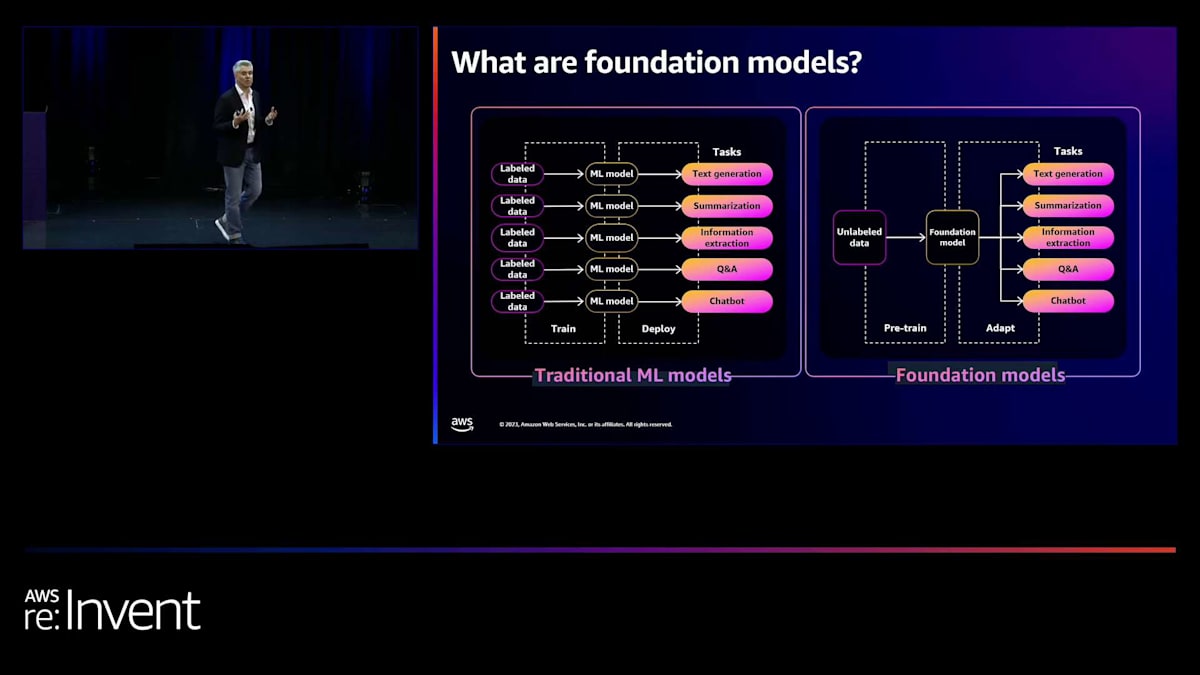
今日の大規模言語モデルははるかに広範囲をカバーしています。データの corpus はより大きく、 より多くのタスクをこなすことができます。会話型エクスペリエンスとその課題について話しましょう。これらのエクスペリエンスを構築するのは非常に難しいのです。Lexを使用している方や使用を検討している方、あるいは他のツールを使用している方は、これらのエクスペリエンスを作成することがいかに困難かご存知でしょう。
言語のニュアンスや対話戦略、対話状態の概念を理解し、言語のニュアンスをどのように明確にし、再試行するかを知る会話デザイナーが必要です。規制や法令遵守が求められる業界では、予測可能な対話管理が必要な場合もあります。例えば、私が医師に電話をしてコレステロール検査の結果を尋ねたとき、「やあ、あなたは320です。ワオ!」というような返事は望みません。そうではなく、与えられる情報の種類に応じた適切な性格と文脈を持った回答が必要なのです。これらの概念は非常に重要です。
時には制御が必要であり、時には不要な場合もありますが、雑談や比較的オープンな性質のエクスペリエンスを作成する場合でも、誰もが電話をかけたりボットとチャットしたりするだけで、あなたの費用負担でセラピーセッションを行えるようなボットを作りたくはないでしょう。金融機関であれば、数日後に出発する人のためにホノルルの天気について話すボットは望まないでしょう。ビジネスに関連し、ユーザー層とのやり取りで提供したい種類の金融情報に焦点を当てたいはずです。
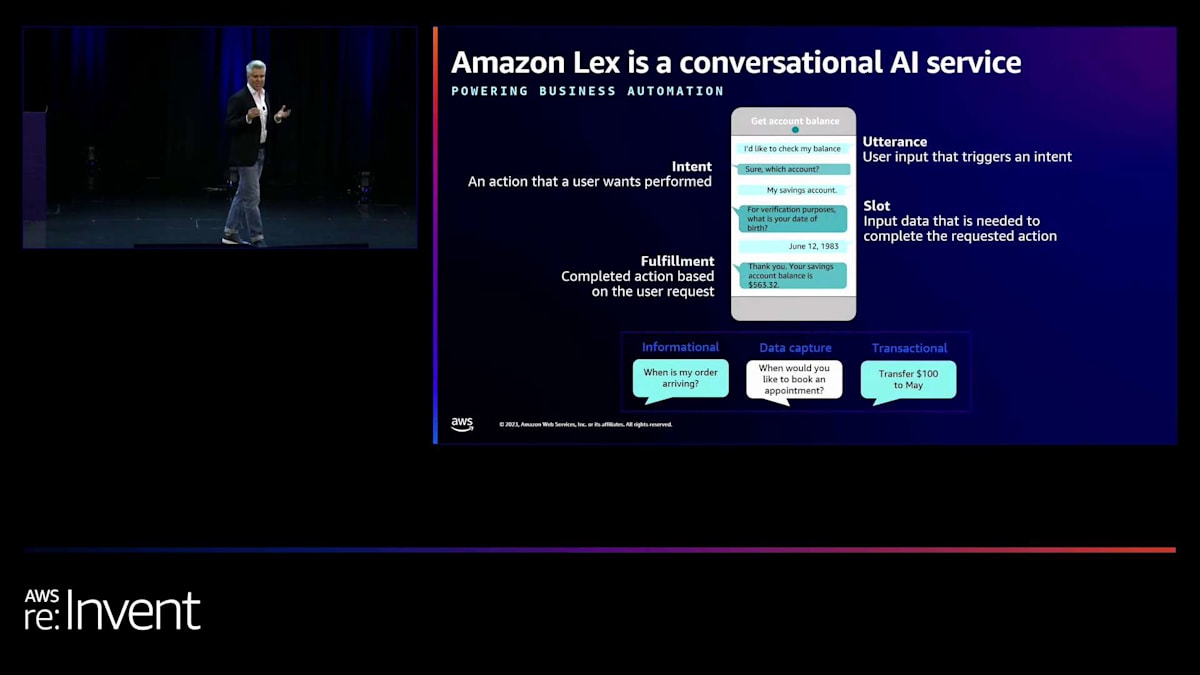
Amazon Lexについて簡単に説明しましょう。Lexを経験したことがない方のために、これから出てくる用語について少し解説します。特に音声チャンネルでの体験を、私たちは「発話」と呼びます。これはタイピングに似ています。Amazon Lexはアプリケーション向けの音声およびテキストインターフェースです。LexをAmazon Connectと組み合わせてコンタクトセンターの担当者の前に置くことで、テキストと音声の両方に対応したフロー(IVRと呼ばれるもの)を作成できます。また、Lexをウェブページに組み込んで、ユーザーがチャットできるチャットボットとして使用することもできます。
Lexをモバイルアプリに追加することもできます。これは後ほどGreggがLockheed Martinで行った素晴らしいユースケースでご覧いただけます。彼は自社の幹部向け生産性向上アプリにLexを使用しています。その仕組みについてもお見せします。Lexは、ユーザーが実行したいアクション、つまり「インテント」を特定するためのユースケースに対応しています。ユーザーの発話からそのインテントを理解し、時にはその発話に基づいて「スロット」と呼ばれる入力データを収集する必要があります。
例えば、航空会社に電話をして「ホテルを予約したい」と言った場合、航空会社側は2分前にあなたがパートナーと「ハワイに行こう」と話したことを知りません。そのため、「どちらへ行きたいですか?」と尋ね、あなたが「ハワイ」と答えるといった具合です。専門家に適切に転送するため、あるいはフライトやホテルの予約などの取引を完了するために、時にはいくつかのデータを収集する必要があります。そして最後に、バックエンドシステムに接続して「予約が確認されました。他に何かできることはありますか?」といった具合に処理を完了します。つまり、テキストと音声の両方でのユーザー入力である「発話」、ユーザーのアクションや意図を表す「インテント」、そしてそれらのインテントを実行するために必要なデータ入力である「スロット」という概念があるのです。
生成AIがもたらす会話AIの革新
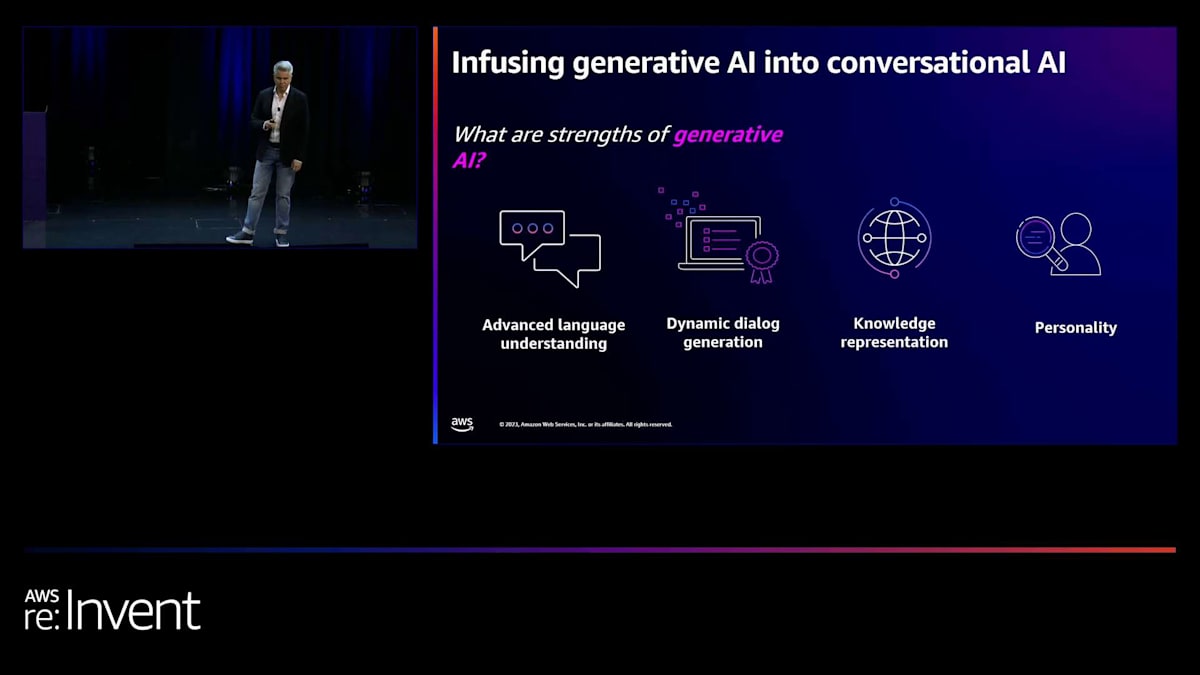
今年に入ってから、生成AIが大きな話題になっています。これは会話AIにどのような影響を与えるのでしょうか?その影響は、ボットの構築方法とエンドユーザーのボット体験の両面で非常に大きいものです。高度な言語理解の例を今日はたくさんご覧いただきます。私たち人間は時として異なる用語を使うので、非常に厄介です。
例えば、「あなたの生まれた都市は?」と尋ねたときに、「ホワイトハウスの近く」と答える人がいるかもしれません。ボットや他のシステムにとって、文脈に応じて「ホワイトハウス」がワシントンDCを意味するのか、あるいはあなたの町近くにある大きな白い建物(生まれた病院)を指しているのかを理解するのは難しいかもしれません。文脈は非常に重要ですが、同時に世界に関する一般的な知識を持ち、このデバイスとどのような対話をしているかを理解することも極めて重要です。
ダイナミックな対話生成は非常に素晴らしいものです。Generative AIの生成能力により、私たちが構築したボットの意図を超えて、このようなチャットや会話をボットと行うことができるようになりました。ボットが取るべき様々な経路について考える必要はありません。私たちの知識、FAQや Q&A に基づいて作成することができます。インターネット黎明期にウェブサイトを構築していた頃を思い出してください。ウェブサイトを立ち上げると、誰かが「質問と回答のようなものを入れてみたらどうだ?荷物の返品に関する特定のポリシーなどの情報を入れてみたらどうだ?」と言います。それと同じことです。対話を構築しようとしているのです。
Generative AIは、この一般的な世界の能力も提供します。旅行の予約をしていて、「ホワイトハウス」と言えば、おそらくワシントンDCに行きたいのでしょう。「ビッグベン」に行きたいと言えば、ロンドンに行こうとしていることを理解します。そして、パーソナリティを持つ必要があります。Generative AIの素晴らしい点は、プロンプトエンジニアリングやその他の様々な手法を通じて、ボットにパーソナリティを与えられることです。悪いニュースを伝える際に、明るいボットは望ましくありません。同時に、金融取引を作成した後に顧客から同意を得ようとする場合、コンプライアンスや規制の観点から特定の言葉遣いを使用しなければならないかもしれません。

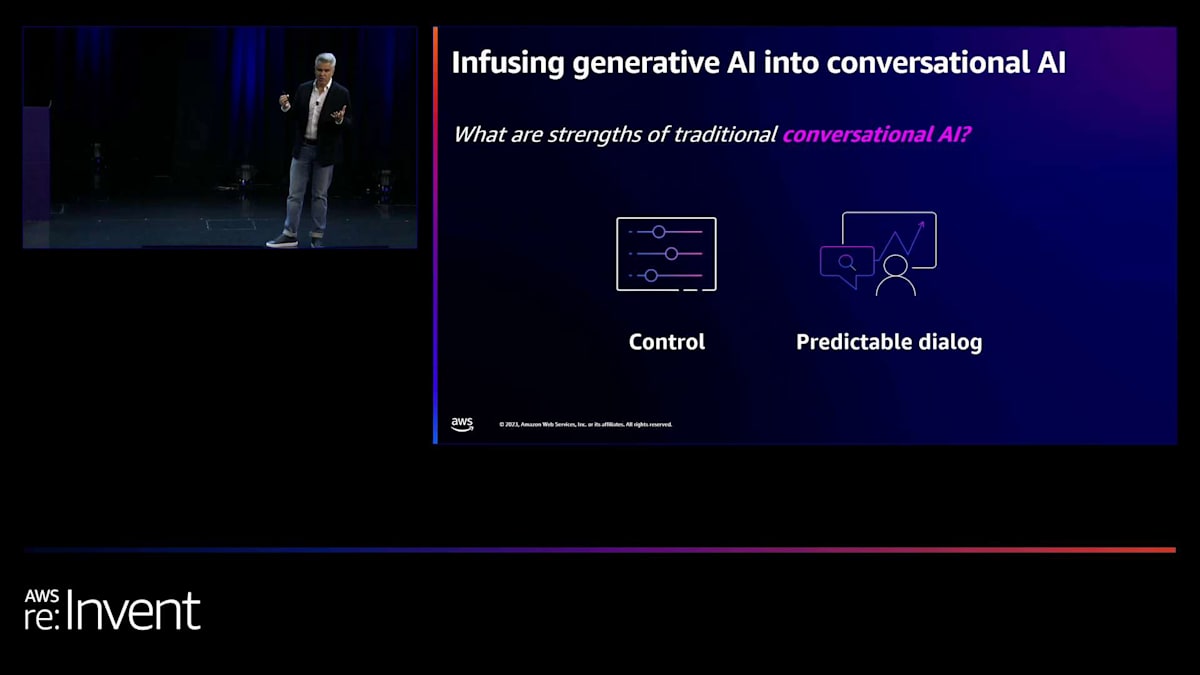
では、Amazon Lexに搭載されている従来の会話AIの良い点は何でしょうか?それは予測可能であることです。パスを設定すれば、顧客にこの一連のインテントとスロットをどのように辿ってほしいかを正確に知ることができます。非常に自由度が高いのです。Lexでは、インテントの切り替えができ、あるインテントから次のインテントに移ることができますが、その体験を特定の方法で行いたいと思います。完全なコントロールがあります。コントロールから始まるのです。今日存在する生成モデルでは、逆です。非常に広範囲から始まり、ガードレールやその他の様々な技術を使用してパスを絞り込む必要があります。Lexでは、望むものを構築し、ユーザーをパスに乗せ、そこからGenerative AIで開放します。Amazon Lexに大規模言語モデルを導入することで、私たちがどのようにこれを実現しているかをご覧いただけます。
2017年の発足以来、Lexの構想は企業と会話を大規模にパワーアップすることでした。AWSインフラストラクチャに支えられ、ASR(自動音声認識)とNLUシステムを使用して、何千もの顧客とのやり取りに対応する高度な会話を大規模に行うことができます。1件の電話から、Taylor Swiftが Sphere で公演し、10万人が予約の電話をかけてくるような状況まで、弾力的に対応できます。私が Sphere で公演する時はそこまでの量にはならないでしょうが、今夜、皆さんが行った後に確認してみましょう。私がステージに立つことはご存知ですよね?歌うんです。いや、冗談です。そんなことになったら大変です。

繰り返しになりますが、私たちは企業向けの体験を構築しています。そこで、Lex と Bedrock の GM である Ganesh Gella を紹介したいと思います。Ganesh は、Generative AI に関する私たちの取り組みと、Lex を素晴らしい製品にする方法について話をします。
Amazon Lexの新機能:Descriptive Bot BuilderとUtterance Generator
皆様、ありがとうございます。本日は、今週Amazon Lexに追加した生成AIの機能についてお話しできることを大変嬉しく思います。私はAmazon LexとBedrock Agentsのゼネラルマネージャーのガネーシュ・ゲラです。2017年のLexのローンチ以来、携わってきました。
今週リリースした機能の詳細に入る前に、ここ数年でLexに加えた進歩を簡単に振り返ってみましょう。Natural Language Understanding (NLU)とAutomatic Speech Recognition (ASR)の精度向上のため、コンテキストの引き継ぎ、マルチバリュースロット、カスタム語彙、ランタイムヒントなどの機能を追加しました。これらの機能をご存知の方、または使用したことがある方は、手を挙げるか何か音を出してください。

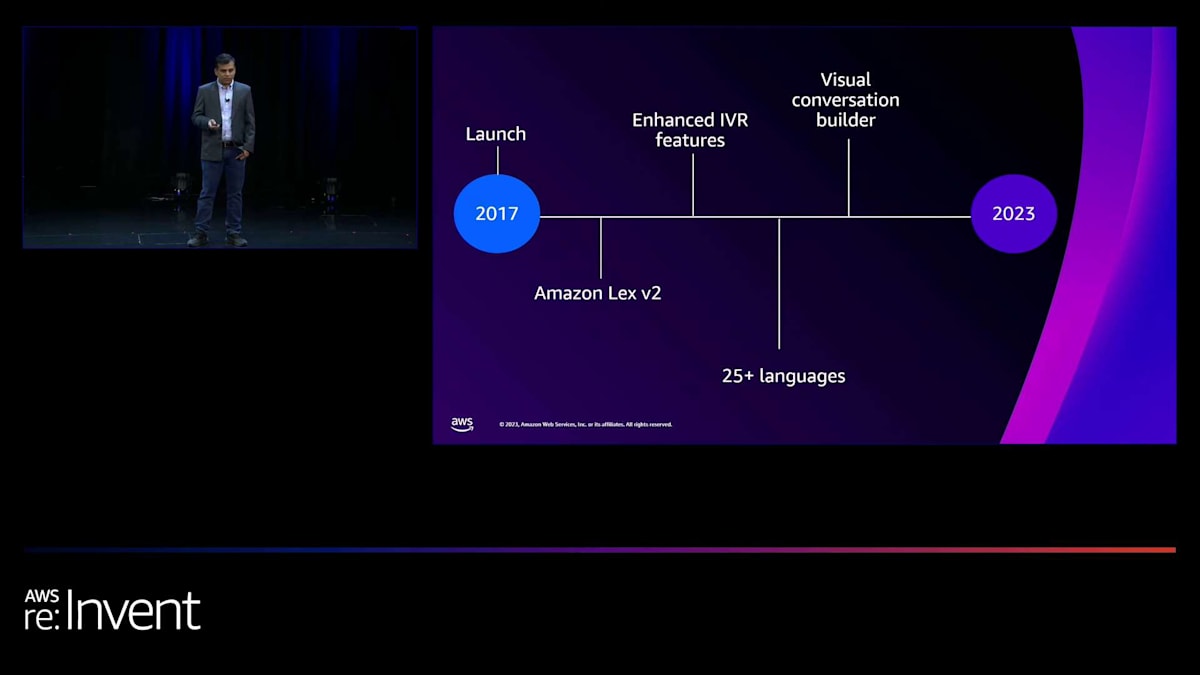
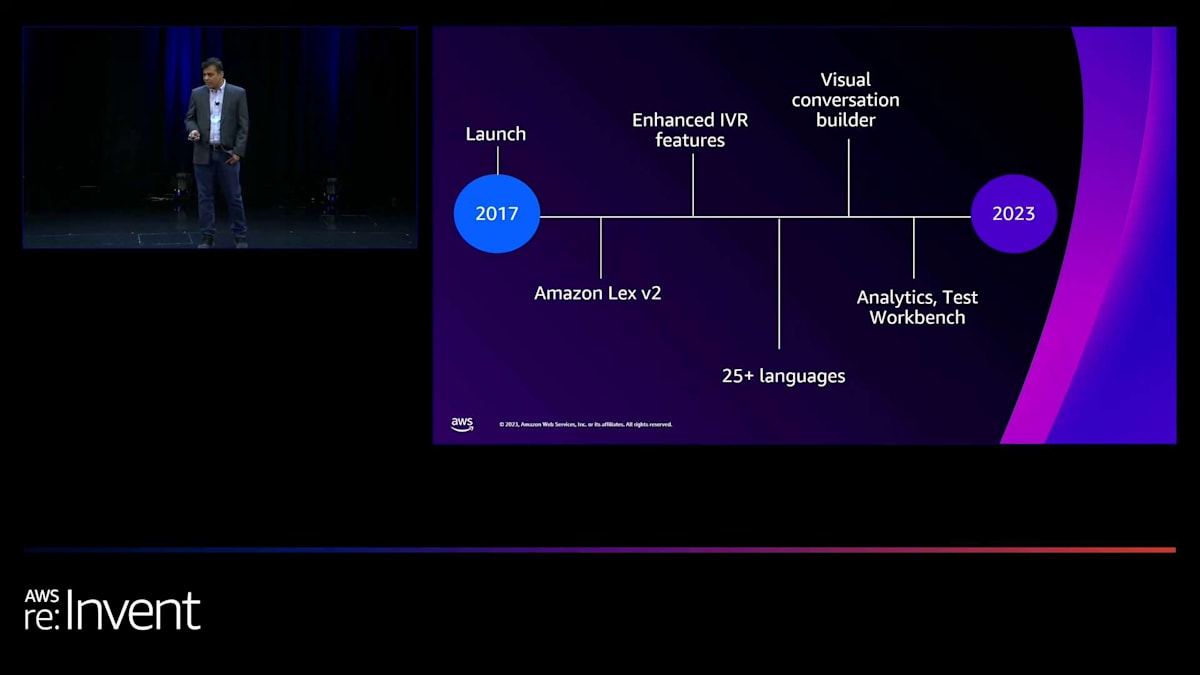
botのスキーマを簡素化し、v2 APIセットで双方向ストリーミングを追加しました。Amazon Connectとの連携でIVR自動化を効率的に行えるよう、目的に特化したInteractive Voice Response (IVR)機能を追加しました。 新しい言語の追加を始めてから、ほぼ年間10言語のペースで25言語以上を追加しました。 その後、開発者がビジュアル会話ビルダーの助けを借りて効率的にインテントを作成できるよう、ノーコードのキャンバスを提供しました。使用したことがある方はいらっしゃいますか?手が挙がっているのが見えますね。 さらに、開発者のデプロイ後の体験を向上させるため、分析機能とテストワークベンチを追加しました。

そして2023年、Lexに複数の生成AI機能を追加しました。 Amazon Bedrockの大規模言語モデルを使用した生成AI機能により、Lex開発のライフサイクル全体をサポートします。大まかに言えば、これらの機能は2つのスペクトラムに分類されます。1つは開発者の生産性を向上させ、botの構築とプロダクションへの展開を迅速化するもの、もう1つはエンドユーザーのエクスペリエンスを向上させるものです。
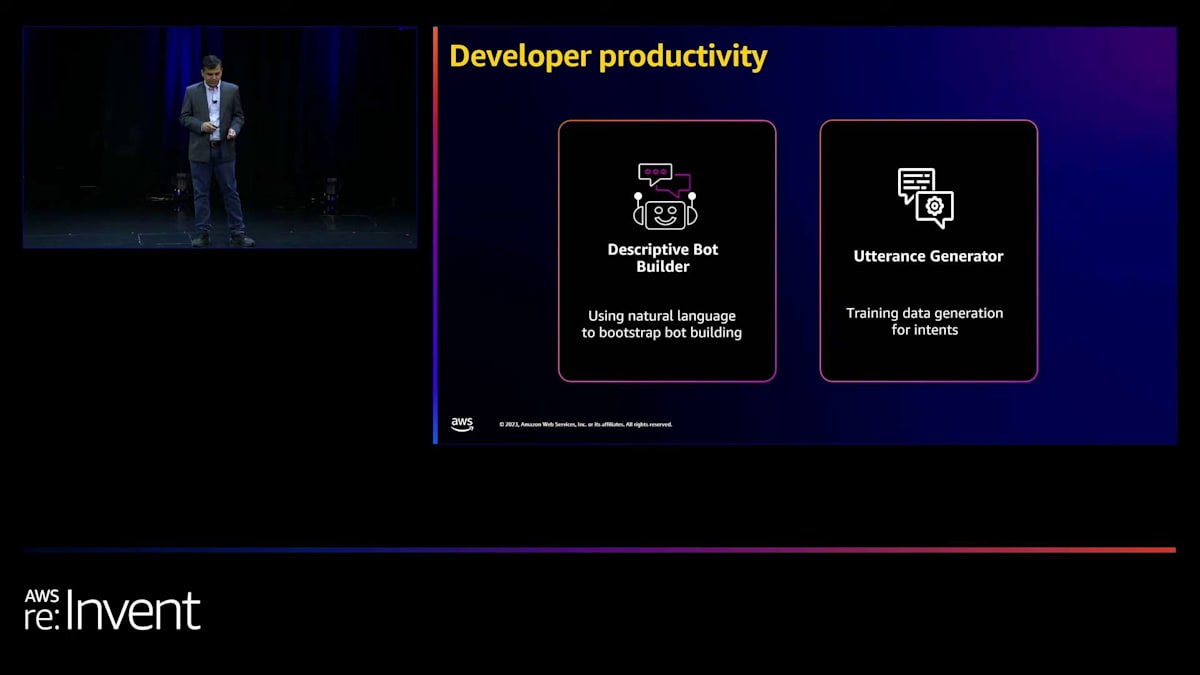

開発者の生産性向上機能について詳しく見ていきましょう。今日は、descriptive bot builderとutterance generatorについてお話しします。 descriptive bot builderとは何でしょうか?ほとんどの方、あるいは一部の方がすでにLex botを構築されたことがあるようですね。 そのため、この概念をご存じだと思います。現在のLex botの構築は、一連のインテントを考え出し、会話から抽出したいエンティティを特定し、これらのエンティティをスロットタイプにマッピングする作業から成り立っています。
例えば、位置情報を取得したい場合、ボットの要件に応じてこの位置エンティティを AMAZON.City や AMAZON.Address、AMAZON.ZipCode などのデータタイプにマッピングする必要があるかもしれません。さらに、これらのインテントに必要なトレーニングデータを用意する必要があります。私たちがトレーニングデータと呼ぶこれらの発話の質と一貫性が、ボットの精度に大きな役割を果たします。開発者が今日、これらのインテントのトレーニングデータを確実に準備することに多くの時間を費やしているのは間違いありません。

しかし、descriptive bot builder を使えば、ボットの目的から始めて、その目的を自然言語で簡単に指定し、Amazon Bedrock 上でこの目的のために使用したい large language model を選択するだけです。そうすると、インテントとすべてのスロットタイプ、そしてこれらのインテントに必要なすべてのトレーニングデータ を含む完全な Lex ボットが生成されます。以前は、シンプルなユースケースでもボットの作成に何時間もかかっていました。中程度のユースケースなら数日、複雑なユースケースなら数週間かかっていたかもしれません。しかし今では、数分で目的から始めてテストを開始できるボットを手に入れることができます。


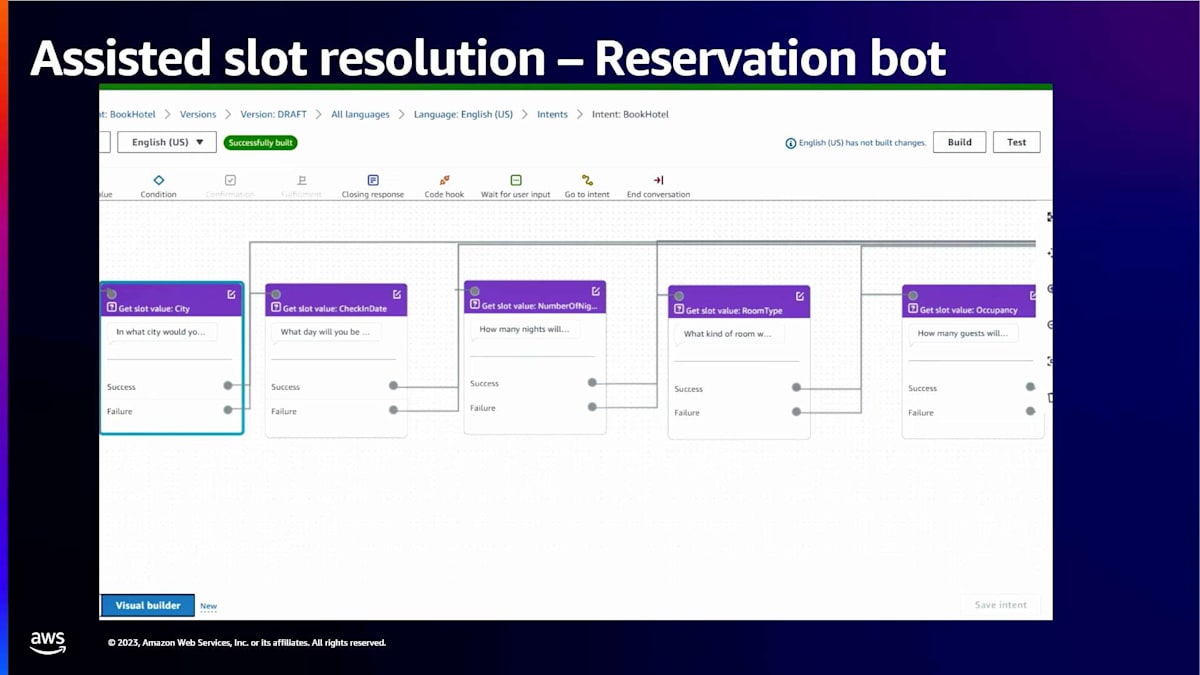
この機能の動作をより詳しく見てみましょう。 ここでホテル予約ボットの説明を自分で追加します。「ホテル予約用のボットを作成してください。ボットには以下のインテントとスロットを含めたいです:book hotel インテント(スロット:city、check-in date、number of nights、room type)」。Done を押すと、Amazon Bedrock を使用してこの説明に基づいてドラフトボットが生成されます。Review を選択すると、生成された結果を確認できます。説明に基づいて提案されたインテントとスロットタイプのリストが表示されます。
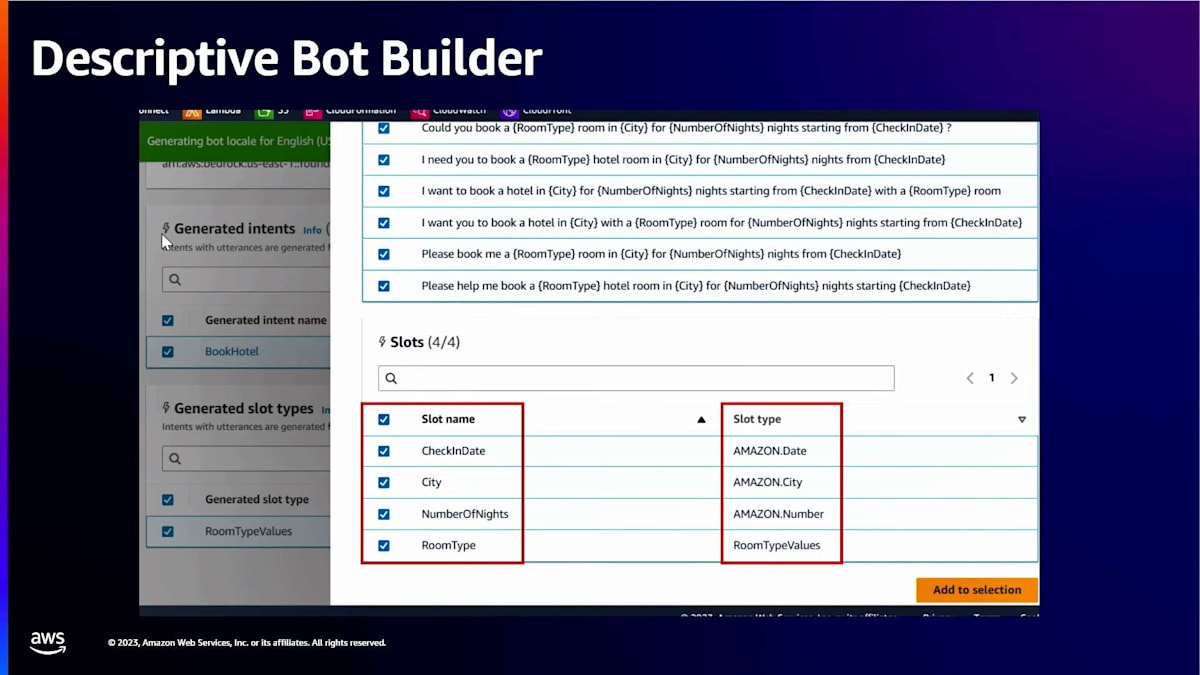
book hotel インテントを選択すると、インテント用に生成されたサンプル発話も確認できます。少し下にスクロールすると、提案されたスロットとスロットタイプが表示されます。descriptive bot builder が check-in date、city、number of nights に対して正しい built-in スロットタイプを自動的にマッチさせていることに注目してください。また、room type 用のカスタムスロットタイプも作成されています。

これで良さそうなので、「Confirm intents and slot types」を選択します。
生成AIを活用したスロット解決とConversational FAQ Intent

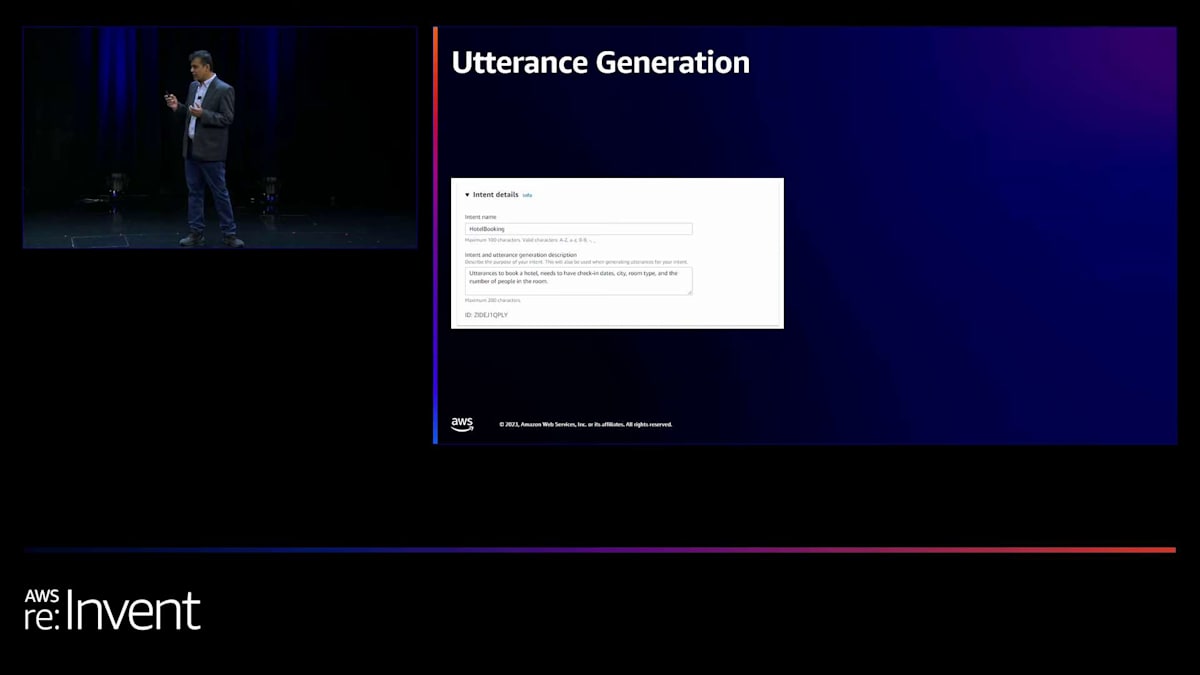
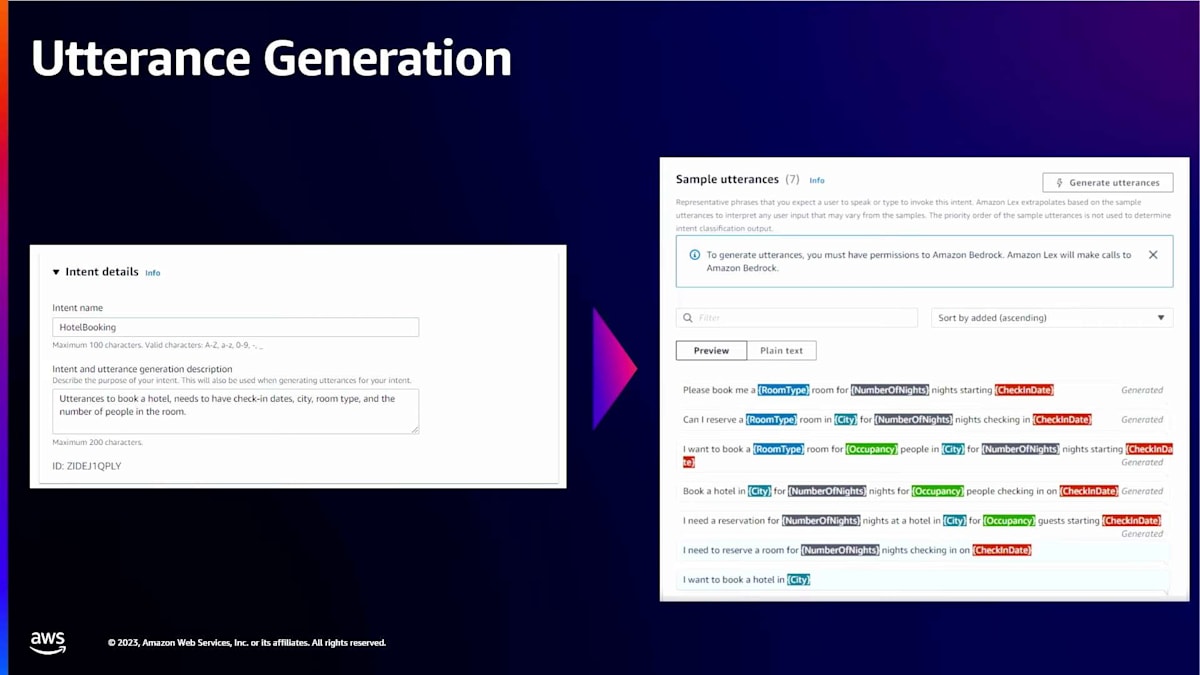
では、発話生成に移りましょう。ボットを作成したら、新しいインテントを追加してその機能を拡張したいと思うかもしれません。そこで発話生成が重要になってきます。発話生成は、ボットの目的から始める記述的ボットビルダーと似ています。発話生成機能では、インテントの作成に取り組んでいて、単にインテント名とインテントの説明を提供するだけです。発話生成は、必要なスロットに注釈を付けながら、そのインテントに必要なすべての発話を生成します。

では、エンドユーザー体験を向上させる機能に話を移しましょう。最初に紹介するのは、生成AIを活用したスロット解決です。この機能の説明に入る前に、スロット解決とは何かについて基本的なことを押さえておきましょう。スロット解決とは、ユーザーの入力(音声または文字)を受け取り、プログラマーがビジネスロジックで直接使用できるデータ型や値に変換する作業です。例えば、ユーザーが「明後日」や「今度の月曜日」と言った場合、スロット解決の役割は、この入力を変換して、APIに直接入力できる具体的な日付を提供することです。


先ほどの例では、チェックイン日、場所、宿泊人数などのエンティティがありました。これらは日付、都市、数字などのスロットタイプにマッピングされます。一見単純に見えるかもしれません。入力を受け取り、プログラマーがAPIで直接使用できるデータ型に変換するだけです。しかし、自然言語の表現力の広さは、時として最も洗練された文法さえも凌駕することがあります。
例を挙げてみましょう。このホテル予約ボットがユーザーに「何名様でご予約ですか?」と尋ねたとします。ユーザーは「4名です」や「4名で来ています、4名が必要です」と答えるかもしれません。素晴らしい。現在、Lexはこれを4という値として受け取り、APIに渡します。しかし、ユーザーが「旅行がとても楽しみです。家族と一緒に旅行します。私と妻、そして2人の子供がこの予約に含まれます」と言ったらどうでしょうか?この生成AIを活用したスロット解決により、Lexは今やこれを4と解決でき、エンドユーザーは会話をスムーズに進めることができます。

まとめると、開発者がこの機能をコントロールします。開発者はスロットごとにこの機能を有効にでき、既存のLex NLUが値の解決を試みます。私が挙げたような例で既存のNLUが失敗した場合に、生成AIを活用したスロット解決が機能します。開発者は、この目的のためにAnthropic ClaudeまたはClaude Instantのいずれかを選択できます。ここでも、短い動画を使って、このようなケースをいくつか見てみましょう。
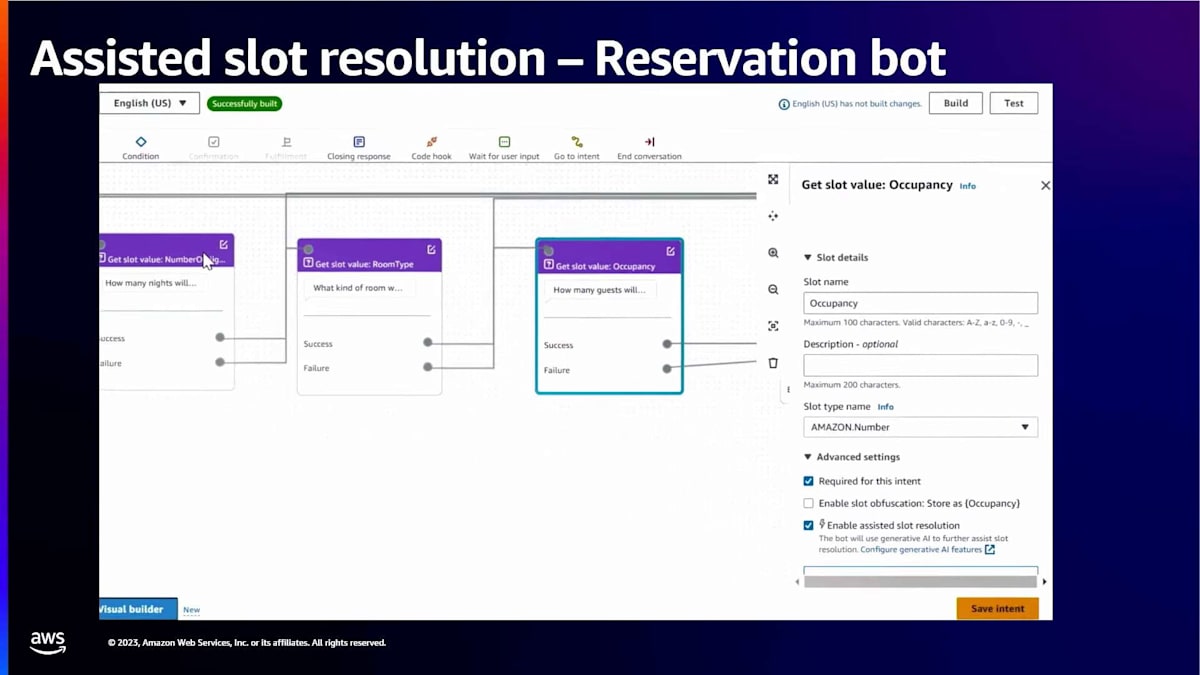





今回は、情報がより適切に解釈されているのが分かります。「I'm heading to London for a conference」はすぐに「London」と解釈されています。 「The first of next month」は10月1日と解釈されており、 これは録画時点では正確です。「Friday, Saturday, and Sunday night」は3泊と解釈され、 「me, my wife and our two kids」は4人と解釈されています。この新機能を有効にすることで、お客様はより人間らしい方法でボットと会話できるようになり、 再プロンプトやエラー処理をあまり必要としません。この機能がチャットボットやコンタクトセンターのカスタマーエクスペリエンスをどのように向上させるか、ぜひ確認してみてください。ありがとうございました。




最後に、さらに強力な機能についてお話しします。それは、Conversational FAQ intentです。CFAQは、ボットに追加できる新しい組み込みintentです。CFAQとは何でしょうか?このConversational FAQ intentを使用すると、事前に予想していなかったり、intentを定義していなかったりするユーザーからの質問に対応できます。これらは、情報は持っているものの、どこかの文書に埋もれているかもしれない情報に関する、お客様からの質問です。CFAQ intentは、RAG技術を使用して文書を読み取り、要約された回答をユーザーに提供できるようになりました。

RAGはRetrieval Augmented Generationの略です。RAGの仕組みは、一連の文書を取り、入力を分割し、対応するベクトル埋め込みを作成し、それらの埋め込みをベクターデータベースに保存します。そして実行時に、ユーザーのクエリが入ってくると、関連するベクトルと対応する文書を取得し、その情報をエンドユーザーに要約して返します。CFAQ intentを使用すると、この複雑さがすべてカプセル化されます。単にS3フォルダーのデータを指定するだけで、CFAQ intentがユーザーに回答を提供します。さらに、CFAQ intentはクエリと既に持っているコンテキストを組み合わせ、ユーザーにより適切な回答を提供します。
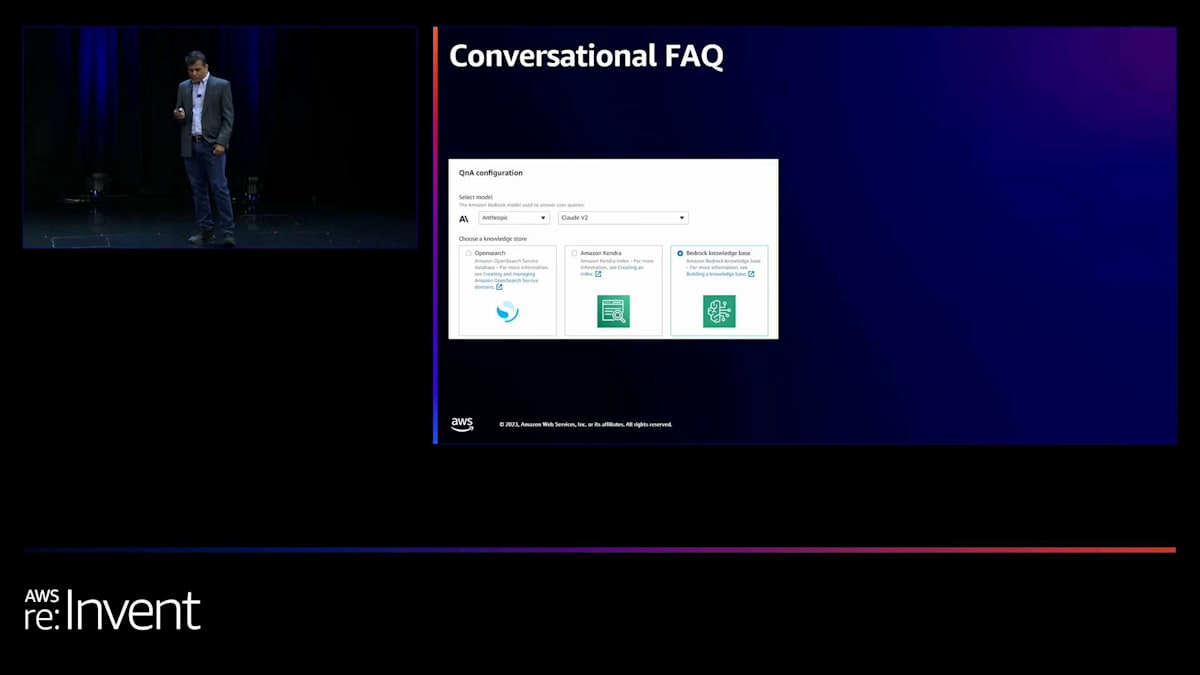
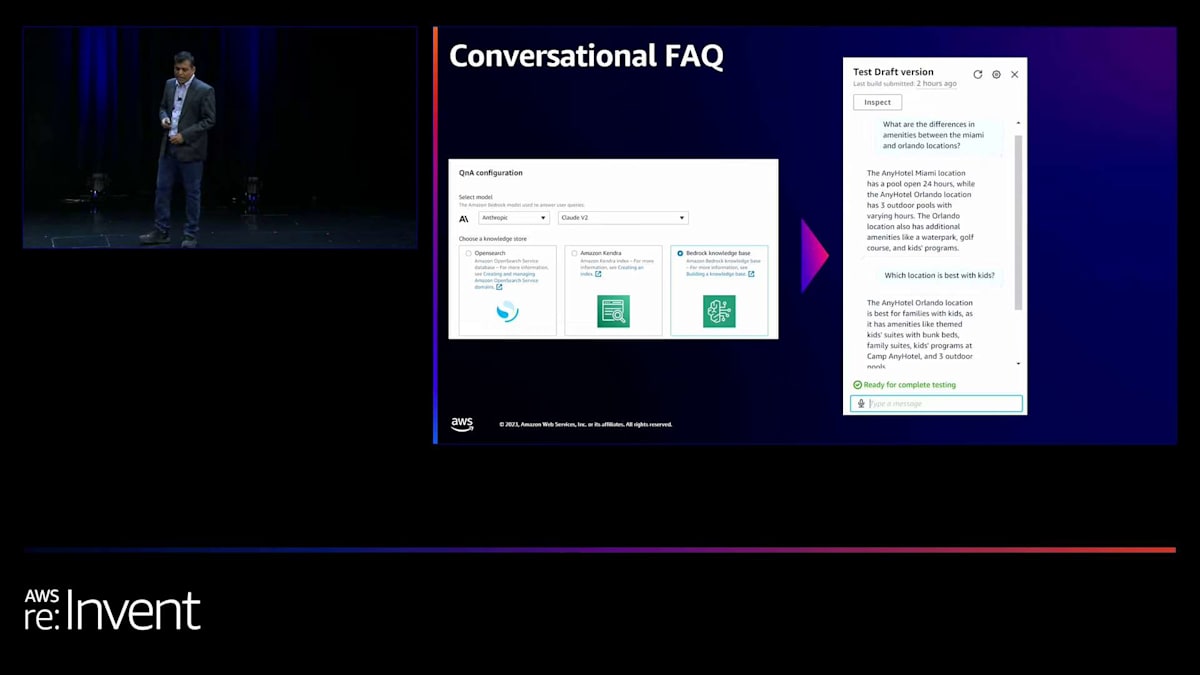
CFAQ intentは、最近発表されたAmazon Bedrock knowledge basesと連携しますが、KendraやOpenSearchなど他の検索システムに情報がある場合でも、CFAQ intentはそれらの検索システムと連携します。この機能では、Bedrock上で使用したい大規模言語モデルのタイプを選択し、knowledge baseのソースを提供するだけで、CFAQの準備が整います。CFAQが可能にするシナリオをいくつか見てみましょう。
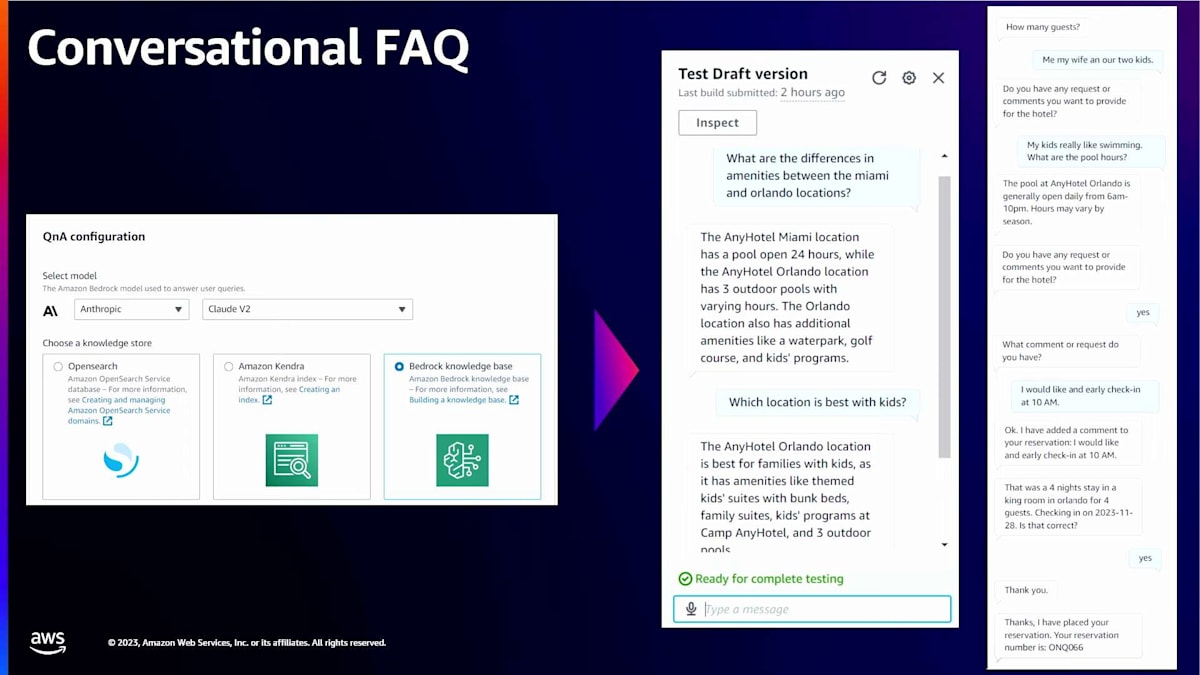
このシナリオでは、顧客が異なる場所にある2つのホテルの比較について尋ねています。文書にはプロパティAとプロパティBに関する情報がありますが、これらを比較して保存したことはありません。CFAQ intentは、これら2つのプロパティに関する情報を取得するだけでなく、それらを比較し、要約をエンドユーザーに提供します。もう1つの強力なシナリオを見てみましょう。ここでは、顧客がホテルの予約プロセス中に、「このプロパティのプールの営業時間は?」と尋ねています。CFAQ intentは、そのプロパティに関連する情報を取得し、ユーザーに情報を返すと同時に、コンテキストを維持して、ユーザーが予約の完了に戻れるようにします。

以前は、CFAQインテントがなかったため、これは顧客満足度の低下やビジネスの損失を引き起こす可能性がありました。しかし、CFAQインテントがあれば、ドキュメントに基づいて関連情報を提供するタイミングを知ることができます。 これらの機能についての詳細は、今週月曜日に公開したブログ記事でご覧いただけます。ありがとうございました。
Lockheed MartinにおけるAmazon Lexの導入経緯
それでは、Gregg Doppelheuerさんをお招きしましょう。Greggさんは長年Lexのユーザーです。GreggさんはLockheed Martinの方で、Lockheed MartinでLexを社内の従業員の生産性向上にどのように活用しているかについてお話しいただきます。


Ganeshさん、Marceloさん、ありがとうございます。 本日皆様の前でお話しする機会をいただき、大変光栄です。この引用は重要だと思います。 これはMissiles and Fire Control全体のProduction Control DirectorであるJason Menicucciの言葉です。Lockheed Martinについては後ほど詳しくお話ししますが、Lexのようなツールを開発した理由は、Jasonが朝出勤したときに何に集中すべきかを把握するのに役立つからです。私たちには9つの主要工場と、おそらくさらに12ほどの小規模な製造支援施設があります。
世界の地政学的な状況に注目されている方ならご存じでしょうが、MFCで製造している製品の一部は非常に高い性能を発揮しており、どちら側に立つかに関わらず必要とされています。そのため、Jasonは今や、米国だけでなく世界中の顧客のために製造している製品の生産を支援するために、どこに時間を集中すべきかに注力できるようになりました。Lockheed Martinがグローバル企業になるにつれて、ご覧の通り、世界は変化しつつあります。

では、Lockheed Martinについて少しお話しさせてください。ここにいる皆さんがLockheed Martinについてどれだけご存知かわかりませんが、私たちには4つの事業部門があります。逆順になりますが、aeronautics、missiles and fire control、rotary and mission systems、そしてspaceです。おそらくアメリカのすべての州に拠点があります。従業員の20%が退役軍人で、私たちはそのことを誇りに思っています。個人的にはこの数字がもう少し高くなればいいと思っています。そしてもう一つ私が誇りに思っているのは、100年にわたるイノベーションの歴史です。私たちは「クールなものを作り、本当に難しい問題を解決する」と言っています。そしてそれらは必ずしも大量破壊に関するものばかりではありません。ですから、働くには面白い会社だと思います。私自身、キャリアを通じてこの4つの事業部門すべてで働いてきました。Lockheed Martinでの勤続35年を先日祝いました。本当にクールな技術企業で働きたいと考えている方には、ぜひ検討していただきたい会社です。

では、Lexに至るまでの経緯についてお話しましょう。約6年前、私はLockheed Martinの企業IoTアーキテクトでした。私たちは、工場をどのように接続し、工場の運営を理解し、そして資本資産をより効率的に使用するかを模索する旅の途中にいました。私たちが製造する製品を作るのが安くないことは想像できると思いますし、それを行う機械も簡単に既製品で買えるものではありません。そこで、私たちはIFF(Intelligent Factory Framework)と呼ぶものから始めました。私はAmazonと協力してデモンストレーター製品を構築しました。そのデモンストレーター製品が私に本当に考えさせるきっかけとなり、「もしこれをトピックやキューなどで制御できるなら、なぜAlexaや音声を使えないのだろう?」と思いました。そこで、生産オペレーションの人々に、音声で機械のオン・オフを制御できることを示し始めました。想像できると思いますが、彼らはそれにかなり驚きました。10万ドルの部品を切削している最中に、機械を停止させたり、一時停止させたりするのですから。彼らはそれを本当に喜んでいませんでした。
しかし、本当に興味深かったのは、企業のCTOに見せたときのことです。彼は私に「この音声機能を使って、どのようにして私たちの企業全体を音声対応し、ビジネスを運営できるようにするのか」と言いました。私はそれがとても面白いと思いました。彼は「世界中のどこにいても、一日中いつでもプログラムのステータスを確認できるようにしたい」と言いました。そこで、ターボナードの私は座って考え、プロジェクトやプログラムのための企業報告システムを管理しているチームに連絡しました。企業プログラムと言っても、企業全体にわたるものです。そして、そのチームの人々に「どうすればあなたたちのデータにアクセスできるか」と尋ねました。もちろん、最初の質問は「なぜ?」で、2番目の答えは「ノー」でした。最初の質問が「なぜ?」で、2番目の答えが「ノー」だったのです。そして、小規模な概念実証を行っているだけだと説明すると、少しのデータセットを得ることができました。

そして、それは本当にAlexaでスキルを開発する方法を探る道を開いてくれました。Alexaの両端のaを取れば、Lexになりますよね。2週間以内に、企業プログラム報告(EPRS)と呼ばれるものをデモンストレーションするスキルを構築し、企業のCTOに見せました。その月曜日の朝9時、彼は私に「一週間が素晴らしいものになった」と言いました。そこで彼は、これを企業全体で実現する方法を見つけるよう私に指示しました。皆さんご存知かもしれませんが、Alexaは既存の商用クラウドです。防衛産業基盤として、私たちはより政府クラウド側、IL4、IL6タイプのものが必要です。そこで、私はAmazonと協力して、まず第一にAlexaをGovCloudに導入する方法を模索し始めました。それは興味深い会話でした。その後、会話は「Lexを使えないか?」に変わりました。当時、LexもGovCloudにはまだ導入されていませんでした。
そこで、皆さん、どうやって私を助けてくれるのでしょうか?2020年頃、私たちは行き詰まっていました。COVIDが私たちを苦しめ、誰もが在宅で、私はビジネスのペースで進む必要がありました。そこで、Ganesh Kumar Gellaさんが当時担当していたかどうかわかりませんが、Lexを製品として所有していた別の人物と会話が始まりました。その人は私に「3ヶ月以内にGovCloudに導入できたら、あなたのプロジェクトを移行してデモンストレーションしてくれますか?」と言いました。もちろん、「問題ありません」と答えました。そうして、私たちはLexをGovCloudに導入しました。その後、彼らはAlexa 2.0について私に話し始めました。私にとって唯一残念だったのは、Alexaほど簡単ではなかったことです。Alexaスキルを開発したことがある人なら知っていると思いますが、スキルビルダーがあり、インテントを構築し、すべてがそこにあります。
今日彼らが発表したものがあれば良かったのですが。10ヶ月前にそれがあればよかったです。2021年から2022年にかけて、ようやくAWS GovCloud (US)でAmazon Lexを手に入れました。そして、それのデモンストレーションを始めました。
Lockheed MartinでのAmazon Lexの活用と今後の展望
今年の4月、私のチームはAmazon Lexを使用したiOSアプリの開発に着手しました。チャット体験を構築するためです。というのも、Lockheed Martinの全従業員が企業のMDMプラットフォームとしてiPhoneを使用しているからです。第3四半期に、MFC Lex Program Management Applicationと呼ばれるベータ版をMFCの上級リーダーシップチームにリリースしました。現在、Jasonのような方々や製造部門の副社長たちがこのアプリケーションを使用し、ベータテストを行っています。すでにかなりの良いフィードバックを得ており、それを開発チームに持ち帰っています。私はアイデアマンで、実際の困難な作業は開発チームが行っています。これまでのところ、非常に前向きな反応が得られています。
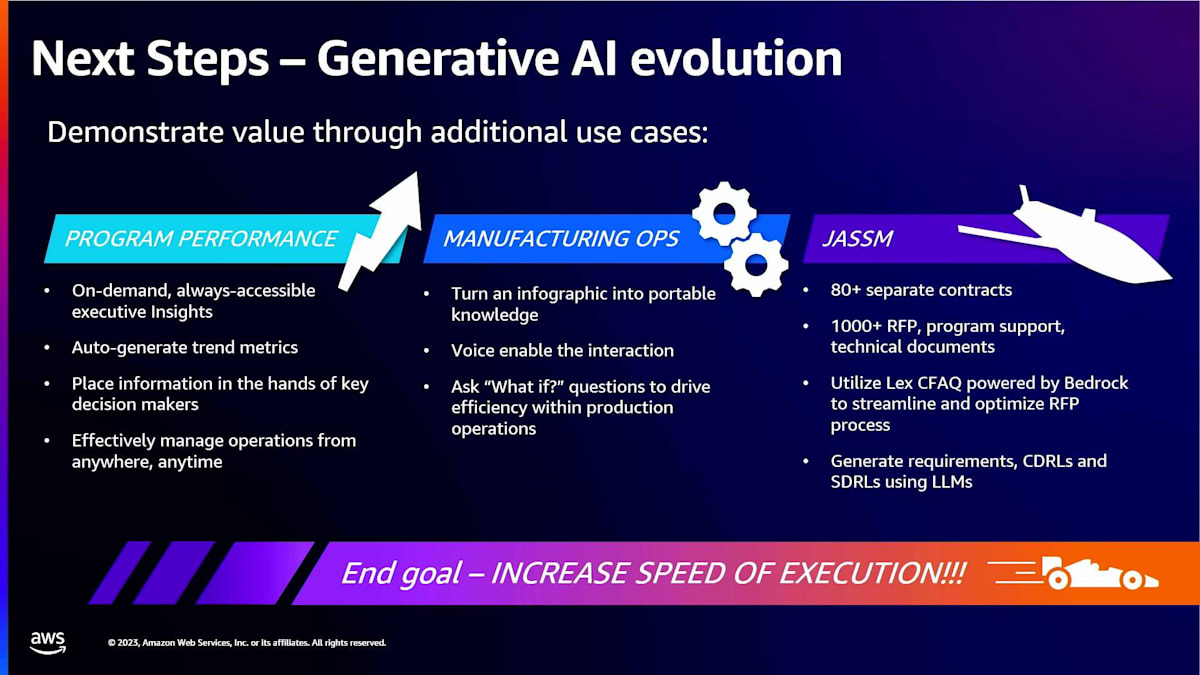
しかし、次にどこへ向かうのかをお話ししたいと思います。Lockheed Martinは興味深い企業です。 私たちには膨大なデータがあります。プログラムのパフォーマンスが見えますよね?オンデマンドで、常に利用可能です。トレンド指標を自動生成する能力など、そういった良いものはすべて今日のモデルに含まれています。一部はHANAデータモデルで、一部は小規模な生成トレンドモデルです。しかし、次に向かいたいのは製造オペレーションチームです。私たちには9つの主要サイトと、おそらく12の小規模サイトがあると言いました。彼らはそのデータの可視化を望んでいます。今日何人が働いているか、作業指示書はいくつあるか、生産がどれだけ遅れているか、IOPはどうなっているか、といったことです。
製造オペレーションチームに「もし〜だったら」という質問をする能力を提供したいと考えています。もしHellfire製造をOcalaからOrlandoに移したらどうなるか?もしそのラインを2倍にしたらどうなるか?そこで、現在はそれに取り組んでいます。これが、大規模言語モデルの機能を導入している方法です。
本当に重要なのは、そこに見える3つ目のユースケースだと思います。JASSMという特定のプログラムがあります。これは非常に大きなミサイルですが、政府の空軍は80の別個の契約でそれを私たちに提供しました。81番目、82番目、83番目、84番目と続きます。しかし、最初の80から何を学んだでしょうか?そこで、最初の80とすべての成果物 - RFP、RFP回答、CDRLs、SDRLsなど - そういったものすべてを大規模言語モデルに取り込んでいます。81番目の契約を受け取ったとき、どうすれば6〜12ヶ月の要件フェーズと要件定義フェーズを省略できるでしょうか?過去の実績に基づいて、81番目の契約の要件は何でしょうか?そして81番目の契約から、前の80で見逃したものはありませんでしたか?前の80での間違いからどのように学ぶことができるでしょうか?間違いを犯したことは間違いありません。
そして、LexとそのVoice体験を、RFP、契約チーム、プログラムチームだけでなく、製造チームと顧客の前に置きたいと考えています。顧客が「Lockheedは最初の80の契約をどれくらい上手く構築したか?」「Lockheedは81番目の契約をどれくらい上手く消化しているか?」と尋ねることができる力を想像してみてください。悪いとは言っていないことに注目してください。すべてはスピードに関することです。私たちの顧客、主に国防総省は、昨日必要だったものを求めていると言っています。最終目標は、実行のスピードを上げることです。
防衛産業では面白いことに、私の30年の経験の中で、私たちは快適な状態に慣れてしまいました。新しい航空機の開発には6年から14年かかるのが普通でした。Air Forceは、それを5年に短縮するよう私たちに挑戦を投げかけています。Missiles and Fire Controlでは、設計から低率初期生産(LRIP)と呼ばれる段階までのプログラム実行を7年から18ヶ月に短縮するよう求められています。
大規模言語モデルのようなツールを使用し、Lockheed Martin内の文化を変え、新しいツールを使って異なる思考と実行をしない限り、これを達成することは不可能です。ですから、JASSMという1つの契約に対してこれを行うことができれば、80以上の個別契約や何千もの成果物がある中で、他のすべてのプログラムに対しても同じことができるのではないでしょうか。
MFCで私たちが行うこと、そして私のチーム(その一部がここにいます)が行うことはすべて、エンタープライズ規模を念頭に置いています。つまり、Lockheed Martin Missiles and Fire Controlで問題を解決すれば、企業全体の問題を解決することになるのです。そういうアプローチを取っています。残念ながら、今日はアプリケーションの詳細をすべてお話しすることはできませんが、後ほど、アプリケーションの仕組みや機能、そして財務業務や生産業務に対してこれまでに得られた洞察について、喜んでお話しさせていただきます。
ITソリューションと文化変革の重要性
ITに携わる人々が、ビジネスの洞察力を失わないことが非常に重要だと思います。私たちが製品を作るのに何が必要か、そしてITソリューションがどのように最終的な結果に影響を与えるかを理解することが大切です。これらの質問については、この後でお答えできます。最後に、ITソリューションとLockheed、AWS、そして私たちの従業員とのパートナーシップが重要だということを強調したいと思います。まず従業員から始まり、そして本当に文化を変えたいと思う人々を巻き込んでいくのです。
私はリーダーシップに常々言っています。文化の変革は法律で強制できるものではありません。私たちがそれを実践し、体現しなければならないのです。そして、これが私たちが実践を始める方法です。AlexaやGoogleのデバイスが家にあって質問できる時代を知らない若い従業員や、認知アシスタントが存在しない時代を知らない従業員が、どれだけ入社してきているでしょうか。ですから、私たちはそういった体験をオフィスにも取り入れ始めなければなりません。

以上で私の発表を終わります。皆様、お時間をいただきありがとうございました。ご質問がありましたら、喜んでお答えいたします。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion