re:Invent 2024: AWSが学んだ大規模システムのResilience戦略
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Failing without flailing: Lessons we learned at AWS the hard way (ARC333)
この動画では、AWSのVP of ResilienceのAlec Peterson氏らが、大規模システムにおけるResilienceの課題と解決策について解説しています。Persistent Connectionsがシステムの信頼性に与える影響、スケーリング時の状態管理の重要性、そしてボトルネックの測定方法が主要なトピックとして取り上げられています。特に、Little's Lawを活用したシステムの並行性の測定や、Route 53での実践例など、具体的な経験に基づく知見が共有されています。また、システムの問題に対する即効性のある対処法として、ゼロ値の記録によるメトリクス管理や、再起動を活用した迅速な障害復旧など、実践的なテクニックも紹介されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Re:Invent 2024:AWSで学んだ苦い教訓


こんにちは。Re:Invent 2024へようこそ。私たち3人は本日、「Failing without flailing:AWSで学んだ苦い教訓」についてお話しさせていただきます。私はAlec Petersonで、AWSのVP of Resilienceを務めています。Resilienceの担当に加えて、皆さんの多くがご利用されているであろうRoute 53も担当しています。本日は、VP兼Distinguished EngineerのBecky Weissも参加しています。彼女は現在IAMチームにいますが、S3、EC2、DNS、Professional Servicesなど、様々なチームを経験してきました。また、EC2チームのSenior Principal EngineerであるMike Furrも参加しています。

今回のトークは、実は私たち3人が昨年行った「Five Things We Wish Everyone Knew About Resilience at Scale」というセッションの続編です。今年は新たなトピックを追加していますが、セッションの目的は同じです。小規模なアプリケーションと比べて、大規模なシステムにおけるResilienceがいかに異なる様相を見せるのか、その意外な学びを皆さんに持ち帰っていただければと思います。本日のトピックとしては、私がPersistent Connectionsについて、Beckyが信頼性の高いスケーリングについて、そしてMikeがボトルネックの測定について、それぞれお話しします。
Persistent Connectionsがレジリエンスに与える影響



私がResilienceとPersistent Connectionsを選んだのは、これがAWSの大規模分散システムだけでなく、多くのお客様のシステムでも見られるパターンだからです。このパターンを頻繁に目にするため、Persistent Connectionsがなぜ潜在的にResilienceにマイナスの影響を与えうるのか、その根本原理について詳しく説明する価値があると考えています。まず最初に、これは300レベルのセッションであることをお伝えしておきます。マイクロサービスについて話していきますが、まず使用する用語について説明させてください。マイクロサービスについて話す際、私は水平分散システムを想定しています。これは複数の個別のビルディングブロックで構成される論理的なサービスです。インスタンス、タスク、コンテナなどで構成され、必要に応じて容量を増減できるシステムです。


この前提を踏まえた上で、これらの分散システムは一般的に、障害が発生することを想定しています。今回の議論で使用するモデルはシンプルなもので、フロントエンドのマイクロサービスが認証サービスを使用してリクエストを保護するというものです。フロントエンドサービスの各インスタンスは、認証サービスの各インスタンスに接続を確立します。これらの接続は、DNSレイヤーなどのロードバランサーによって制御されますが、その詳細は重要ではありません。認証サービスの1つに問題が発生した場合、フロントエンドはその中間メカニズムを通じてそれを検知し、フロントエンドサービスはその問題のあるサービスとの通信を停止します。そして残りの2つのサービスとのみ通信を行うようになります。



これは単純化しすぎています - 何かが欠けています。実際のメッセージそのものが欠けているのです。実際にはもう少し複雑です。このようなフロントエンドと認証の構成でマイクロサービスアーキテクチャを最初に構築する場合、2つのマイクロサービスがあり、フロントエンドサービスには認証サービスと通信する必要があるというメッセージがあります。接続を確立し、そのメッセージを認証サービスに送信すると、認証サービスがそれに応答します。


しかし、規模が大きくなると、これはコストがかかるようになります。TCP接続のオーバーヘッド、TLSハンドシェイクのオーバーヘッド(すべての接続を暗号化しているため)など、接続に関するオーバーヘッドが発生します。これはコストと遅延の原因となります。そのため、サービスの規模が大きくなると、コスト改善の余地があることに気付きます。そこで、Persistent Connectionsを実装することになります。リクエストごとにTCPやTLS接続を確立するのではなく、フロントエンドサービスが最初に起動したときに接続を確立します。そして、その接続を通じて認証サービスに複数のメッセージを送信します。これにより、接続のコストを何百万というメッセージで分散させることができ、実質的に接続コストはほぼゼロになります - めでたしめでたしというわけです。

しかし、接続が失敗したらどうなるでしょうか?ここから話が面白くなってきます。というのも、毎回接続を作成して破棄するのではなく、サービスは起動時に一度だけ接続を確立し、その接続が維持されることを前提としているからです。複数のメッセージをその接続を通じて送信しますが、いつどの時点でも、認証サービス側のインスタンスの1つが失敗する可能性があります。そうなると接続が失敗し、不確定な状態で止まってしまうメッセージが発生します。これは大規模システムでよく見られるパターンです。両側に3つのインスタンスがある場合、接続の確立が行き詰まる可能性があります。

フロントエンドサービスを再起動するというプロセスがあるかもしれませんが、これはある程度の影響があります。Persistent Connectionsが維持されている間は回復するので大きな問題ではありませんが、これは規模が大きくなるにつれてより重大なレジリエンスのリスクとなります。
大規模システムにおけるレジリエンスの課題



可用性のパーセンテージに関する計算を見てみましょう。これは、すべてのシステムコンポーネントがオンラインである時間の割合として定義され、個々のコンポーネントの稼働時間を、コンポーネント数で累乗した値として計算されます。各コンポーネントの可用性が99.99%だと仮定しましょう。これは実際にはインスタンスの可用性としてはかなり良い数値です - 通常はもっと低いでしょうが、出発点としては良い仮定です。システムに10個のコンポーネントがある場合、99.99%の10乗で、システムの可用性は99.9%になります。しかし、10,000個のコンポーネントがある場合、それは36.8%まで低下します。実際にはこのような単純な計算にはならないことは分かっています - これは数学的に各障害が独立していると仮定した場合ですが、障害が発生する機会が多いため、かなり大きなレジリエンスの問題があることがわかります。


私たちの経験では、このような状況に気付かないうちに陥り、システムが徐々に悪化していくことがあります。規模が大きくなるにつれて、Instance Impairmentの機会が増えるため、システムの信頼性に根本的な問題が生じます。さらに、インスタンスが増えるほど、より多くのネットワークが範囲に含まれることになります。ネットワークは、地球上で最大の分散システムの1つと考えることができます。ネットワークのコントロールプレーンとルーティングプロトコルは、あらゆる目的地のペア間でポイントAからポイントBへの経路を見つける方法をネットワークに提供します。


ネットワークに変更が生じた場合、ルーティングプロトコルは再計算を行う必要があります。これはパケットごとに行われるのではなく、ネットワークが変更されたときに実行されます。ネットワーク内のデバイスが多ければ多いほど、問題が発生する可能性も高くなり、接続が中断されるリスクも増加します。デプロイメントによってシステムが破綻することもあります。実際、システムで何かが壊れる場合、その多くはデプロイメントが原因です。システムのコンポーネントが多ければ多いほど、デプロイメントが失敗する可能性も高くなり、障害が発生するリスクも増加します。負荷スパイクも別の課題となります。

これは、私たちがシステムの運用方法や、お客様とレジリエンスについて話し合う際に適用している仮説につながります。アプリケーションのレジリエンスは、そのリカバリーワークフローが実行される頻度に比例するという考え方です。これはマイクロサービス間の接続だけの話ではありません。スタックのどのレイヤーでもレジリエンスイベントは発生する可能性があります。リカバリーワークフローを実行する頻度が高いほど、システムのスケールに対するレジリエンスも向上します。


これはインフラストラクチャの置き換えにも当てはまります。先ほどの認証サービスの障害に対するワークフローを覚えていますか?そのサービスは常にこの作業を行っているため、インスタンスの置き換えをより効率的に実行できます。つまり、定期的にこのワークフローを実行することが重要なのです。同様に、Message BusやEvent Busの接続も重要です。最近の分散システムの多くは、システム内で状態を交換するためにMessage Bus接続を使用しています。Message Busに問題が発生したり、ネットワークの問題で接続が損なわれたりした場合、それらの接続を再開する能力が非常に重要になります。



リーダー選出も考慮すべき点の一つです。分散システムでは、リーダー選出アルゴリズムが必要な場合があります。障害が発生する可能性のあるシステムが多ければ多いほど、リーダー選出を実行する頻度も高くなる可能性があります。また、AZ evacuationは、インフラストラクチャの問題によってAvailability Zoneから退避する必要がある場合の障害クラスの一つです。これは定期的に実行できるようにしておく必要があります。他にも考慮すべき点が多くあります。
Route 53の高い回復力を支える設計思想

接続の再利用に話を戻すと、先ほどの全ての接続を毎回作成するアーキテクチャを思い出してください。それはコストがかかりましたが、非常に高いレジリエンスを持っていました。しかし、これらは唯一の選択肢ではありません。ここでの解決策は、定期的に接続を再確立することです。接続の寿命を設定し、数分以上は維持しないようにします。これにより、システムの負荷に応じて、数百から数千のメッセージにわたって接続コストを分散させることができます。さらに、システムに接続の置き換えを強制的に行わせることで、実際のインフラストラクチャイベントが発生した際も、接続の再確立は日常的に行っている処理となり、お客様にシームレスな体験を提供できます。

このアプローチは、私たちのスタック全体で適用しているものです。先ほど私が担当しているサービスの1つとしてRoute 53について触れましたが、 Route 53の権威DNSサービスではAnycastというネットワーク技術を使用しており、これによってネットワーク上でトラフィックをどこに送信するかをネットワーク自体が決定します。私たちはRoute 53のネットワークを意図的に設計し、クエリを処理するエッジロケーションであるRoute 53 POPの個々の回復性をそれほど重視していません。現在は複数のルーターを持っていますが、システムを最初に構築した時は、各Route 53 POPにはルーターが1台しかありませんでした。これは、ルーターがダウンした時や、デプロイメントが必要な時に、システムをサービスから切り離す必要があるような事態が定期的に発生していたため、許容できる設計でした。
私たちはシステムをサービスに組み込んだり、サービスから切り離したりすることに非常に長けるようになり、その結果、お客様への影響を最小限に抑えることができました。サービスの規模が拡大するにつれて、この能力はさらに向上しています。これがRoute 53が最も回復力の高いサービスの1つとなっている理由の1つです。なぜなら、私たちは定期的にリカバリーワークフローを実行しているからです。予期せぬ事態が発生しても、システムをサービスから切り離すというリカバリーワークフローは、ここ数日の間にも何度も実行している可能性が高いため、完全に対応できます。そのワークフローが有効であり、システムがそれを許容できることを私たちは知っています。

ここから得ていただきたい教訓は、回復力のあるシステムは、すべてのレイヤーで障害を受け入れ、予期しているということです。お客様がこの考え方を受け入れていない最も一般的な例として、アプリケーション内での接続管理の方法が挙げられます。このような場でお客様とこの話題について議論することが重要なのは、私たちにはインフラストラクチャは見えても、より上位レベルでの接続管理の方法までは必ずしも把握できないからです。
接続の管理方法について考えることも重要ですが、同時に、起こりうる障害シナリオが発生した際に影響を受ける可能性のあるシステムのあらゆる側面についても考える必要があります。夜も眠れないような心配の種となっているものは何か、そしてそれらを日常的な作業として重点的に取り組むことを考えてください。そうすることで、予期せぬ事態が発生した時に、より迅速に回復できるようになります。では、Beckyに引き継ぎたいと思います。
ステートフルサービスのスケーリングにおける課題




ありがとう、Alec。私は1つの側面について掘り下げていきたいと思います。Alecはこれらのリカバリーワークフローについて、めったに実行しない場合、現状を乱す要因となり、回復力を危険にさらす可能性があると話しました。 私は、日常的に発生するそのような状況の1つであるスケーリングについて掘り下げていきたいと思います。良い議論はすべて極端な例から始まります。 では、クラウドで効果的でない方法を紹介しましょう:クラウドで動作しているアプリケーションが壊れていないから、修正しない。これらのサーバーをずっと動かしたままにして、置き換えることもなく、スケールアップもスケールダウンもしない。 クラウドではそれが正しい方法ではないことは、皆さんご存知でしょう。re:Inventというクラウドカンファレンスに参加されている皆さんは、正しい方法がこれとは異なることをご存知のはずです。AWSには、そのためのサービスがあります - Auto Scalingがあり、その前にLoad Balancerを配置することができます。



どのようなアプリケーションでも、必ず何らかのデータを扱っています。私たちAWSは、ストレージのスケーリング、可用性、そしてレジリエンスの管理において、皆様をしっかりとサポートします。ObjectストレージやFileストレージ、リレーショナルデータベース、非リレーショナルデータベースなど、様々な種類のストレージを提供しています。そして嬉しいことに、これらの可用性とスケーリングは、ほぼ全てが自動で管理されています。



しかし時には、ホスト上に状態(state)を持つサービスを運用しなければならない状況に遭遇することがあります。なぜそのような構成を選ぶのでしょうか?実は、これにはいくつかの優れた特徴があります。これらのホストがユーザーやカスタマーからリクエストを受け取った時、データがすぐそこにあるため、依存関係を追加してレイテンシーを増やす必要がありません。ホスト上にCacheを持っている場合、まさにこの状況に該当します。このようなFleetをスケールアップする際、新しいホストを稼働させるだけでは不十分で、そのホストにデータをロードする必要があります。つまり、このホストが完全にトラフィックを処理し、期待通りのパフォーマンスを発揮できるようになるまでには、もう少し時間がかかるのです。

このような状況に直面した時、特に注意を払って最適化する価値があると私は考えています。その理由をお話しします:クラウド上で普段通りシステムを運用している時に、想定以上の負荷が突然やってくることがあります。ある程度の負荷は想定し、少し余裕を持って準備していたとしても、私が話しているのは、それをはるかに超える負荷のことです。
DDoS攻撃のような状況を想像されるかもしれませんが、これは良いニュースの結果として起こることもあります。例えば、提供しているサービスが突然人気を集め、想定以上のトラフィックが発生する場合です。このような状況下では、ホストが過負荷となり、Brownoutが発生して期待通りのパフォーマンスが得られなくなってしまいます。


このような状況からどのように脱出すればよいのでしょうか?できるだけ早く対処する方法を考える必要があります。そこで私たちが持っている強力なツールの一つが、スケールアップです。通常は余裕を持った構成にしていますが、想定以上の負荷がかかっている場合、スケールアップが即効性のある解決策となることが多いのです。しかし、この状況を改善するまでには、新しいホストに状態をロードする時間が必要です。これは避けて通れない重要な考慮事項なのです。
EC2 DNSサービスの進化:デプロイメントと問題の区別


その考えをちょっと待っていただいて、実際にこの問題に直面して対処した時の話をさせていただきます。この話のタイトルは「デプロイメントなのか、それとも問題なのか?」です。これは約10年前に私が携わった実際のサービスについての話です。 これはEC2の一部で、EC2インスタンスを持つお客様のDNSクエリを解決するのを支援するものでした。2024年の現在、そして既に数年前から、この機能セットはRoute 53 Resolverと呼ばれており、10年前にはできなかったことが多くできるようになっています。当時は名前すらなく、単にEC2のDNSという扱いでした。
私たちは、異なる種類のリクエストを分類し、適切な場所に転送してDNSレスポンスを取得できるようにする、これらの第一ホップシステムを運用していました。EC2は10年前と比べて根本的に異なるスケールになっているため、ここで言及するシステムのほぼすべてが、今では存在していないか、あるいはテセウスの船のように、大幅にスケールアップされて基本的に別物になっています。

お客様がVPC(Virtual Private Cloud)内でEC2インスタンスを起動する際、パブリックIPv4アドレスを持つパブリックにルーティング可能なインスタンスであることを前提として、EC2は親切にもこのDNS名を割り当てます。 このDNS名にはパブリックIPアドレスが埋め込まれています。インターネット上のVPCの外からこのDNS名を解決すると、まさに想定通りのものに解決されます。これが正しい答えです。なぜなら、このパブリックIPアドレスは、VPCのインターネットゲートウェイを通じてインターネットからこのインスタンスにアクセスする正しい方法だからです。


VPC内の別のEC2インスタンスやコンピュートから接続する場合、そのパブリックIPアドレスは他のインスタンスへの望ましいアクセス方法ではありません。なぜなら、それだと外に出て再び中に戻る必要があるからです。実際にはインスタンスはネットワーク上にプライベートIPアドレスを持っており、このEC2インスタンスの同じDNS名がそのプライベートIPアドレスに解決されることが望ましいのです。これがまさにEC2のDNSが当時も今もお客様のために行っていることです。


では、これはどのように機能するのでしょうか?異なるAvailability Zone内に2つのEC2インスタンスがあるとします。最初のAvailability Zoneにある1番目のEC2インスタンスがDNSクエリを発行すると、最初のホップはこれらのフォワーダーで、どのような種類のクエリか、誰が尋ねているのか、何について尋ねているのか、そしてどう対応するのかを判断する必要がありました。このDNSホストは、EC2ではAvailability Zoneレベルで可用性を考えるため、インスタンスと同じAvailability Zone内にありました。Availability Zone内にはこのようなホストが多数存在します。 そこで、インスタンス1がインスタンス2のDNS名について問い合わせる際、このDNSフォワーダーはどのような質問に答える必要があるでしょうか?


同じVPC内の誰かについて問い合わせているのかどうかを判断する必要があります。 もしそうであれば、プライベートIPアドレスを提供することになります。つまり、DNSではステートが必要になるため、ステートについて話していることになります。 ホスト上では、レイテンシーを非常に良好に保つ必要があり、DNSの可用性は、お客様の視点から見るとネットワークの可用性そのものと言えます。



私たちの多くのDNSホストには、 かなりの量のステート情報が保持されています。これには、どのEC2インスタンスが存在し、どのVPCに属していて、そのプライベートIPアドレスは何かという情報が含まれます。これは大量のステート情報です。 では、このステート情報はどこから来るのでしょうか?それはEC2コントロールプレーンから来ています。お客様がEC2インスタンスを起動し、 EC2 APIを呼び出してネットワークのさまざまな側面を変更すると、これらはEC2コントロールプレーンに保存され、その後、必要な作業を行うためにさまざまな場所に伝播されます。

ここで継続的に起きているのは、お客様がEC2インスタンスを変更したり、起動したり、終了したりしているということです。コントロールプレーンに入ってくるこれらの更新は、すべてのDNSホストに伝播されています。このように、非常にステートの多いホストを抱えているわけです。この伝播システムについてさらに詳しく見ていきましょう。各Availability Zoneには、 多くのホストを持つこの伝播サービスがあり、同様に多くのホストを持つDNSフォワーダーがあります。これから説明するのは、約10年前に機能していた設計方法についてです。



この仕組みは、各伝播ホストが、リースベースのシステムで、最終的にお客様からの更新をDNSにプッシュする責任を持つというものです。これは インクリメンタルなラウンドで行われます。担当するDNSホストにそれをプッシュします。これが1ラウンド、次のラウンド、そしてさらに次のラウンドと続きます。おそらく既にいくつかの疑問をお持ちでしょう。最初の疑問は、このプロパゲーターが担当している ホストの1つが遅い場合はどうなるのか、ということだと思います。何が起こるでしょうか?そのラウンドは時間がかかり、そのラウンドが長引いている間も、外のお客様は依然として EC2で作業を続けています。そのため、次のインクリメンタルラウンドはより大きくなり、遅いホストはそれをより遅く処理し、次のラウンドはさらに大きくなっていきます。

スケールアップに関するもう一つの考慮事項は、これらの新しいホストをサービスに投入する際に何が起こるかということです。これらは非常にステートの多いホストであることを覚えておいてください。ステートフルなホストをサービスに投入する場合、ステートを持つまでは仕事ができません。そのため、サービスに投入する際、他のホストはインクリメンタル同期を受けますが、この新しいホストは完全なステート、つまりリージョン内のすべてのEC2インスタンスの状態を受け取ります。この数は増え続けています。たとえ新しいホストのパフォーマンスが良好でも、この完全同期にはかなりの時間がかかります。その間に、次回のためのインクリメンタルが非常に大きくなります。これは、お客様がEC2で何かを実行してから、 それがDNSデータプレーンに反映され、DNSクエリで表示されるまでのラグが長くなることを意味します。

これが私たちのお客様にとって重要な理由です: DNSが機能していなければ、ネットワークも機能しません。お客様が2台目のEC2インスタンスを起動し、1台目のEC2インスタンスが名前で2台目にアクセスしようとした場合、その名前を必要とする一般的なユースケースがありました。インスタンスは実行中かもしれませんが、誰も見つけることができないため、まだアクセス可能な状態ではありません。

これらのホストをデプロイする際、私たちはラグタイムを示すグラフを取得します。お客様にとって重要なことは測定すべきだと考えているからです。 このグラフは、EC2インスタンスの起動からDNSが完全に伝播するまでの時間を示しています。このデプロイメントはあまりきれいには見えません - 問題との区別がつかないのです。デプロイメントの最中には全体像が見えないため、問題なのかデプロイメントなのか判断できないという問題があります。デプロイメントはこのような形になるはずだと思って終わりを期待しますが、実際にそれが終わるかどうかは分からないのです。

これで私たちは痛い目に遭いました。こんなことが起きたのです: 通常通りデプロイメントを行い、先ほどのようなグラフを期待していました。ところが、このデプロイメントで問題が発生しました。同期は機能していてデータプレーンも動作していたのですが、データプレーンのプロセスが再起動に失敗し、古いデータで動作し続けていたのです。

すべてが順調に見え、デプロイメントの最中でグラフも良好に見えました。しかし問題は、グラフが想定通りに収束しなかったことです。これは私たちにとって非常に深刻な事態を意味しました。なぜなら、このデプロイメントは実際には問題であり、デプロイメントと問題を区別する手段がなかったため、長時間にわたって問題を引き起こしていたからです。

この出来事の後、私たちは修正が必要だと認識しました。運用上のイベントを考える際、障害の継続時間は私たちにとって最も重要な要素です。お客様にとって重要なことは私たちにとっても重要であるため、迅速に終息させる必要があります。 ここにいらっしゃる皆様お一人お一人が、私が説明したものよりも優れた伝播システムをすでに設計されているのは承知しています。そして朗報があります。私たちは皆様からのご提案をすべて取り入れ、現在では完全に異なるサービスになっています。
私たちは10年前にこれについて素晴らしいアイデアを持っていましたが、この問題に悩まされていました。「これはデプロイメントの問題なのか、それともシステムの問題なのか」という状態は好ましくないことを認識していました。そこで、システム全体を設計する前に、ホストの起動時間を徹底的に分析し、ローカルでの最適化を行いました。ローカルデータベースファイルと、追加・削除の処理に関するビジネスロジックを変更しました。当時、EC2インスタンスを起動すると、そのインスタンスが到達可能になりOSが動作するまでに30〜40秒かかっていました。今日ではもっと速くなっていますが、DNSがその制限時間内に動作する限り、顧客は問題ないと分かっていました。

これが私たちが克服しなければならなかった課題でした。デプロイメントが問題のように見えなくなるまで最適化を続けました。デプロイメントは、成功し続けているように見えるようになりました。これこそが目指すべき状態です。ホストのスケールアップと起動時のデプロイメントは、のサブケースのようなものです。ステートフルなホストがある場合、サービスに組み込むまでの時間が長すぎると感じたら、考慮すべき点がいくつかあります。AWSでよく見られるパターンとして、チームがS3に保存された状態をスナップショットとして保存し、素早くダウンロードできるようにすることがあります。Cellularアーキテクチャは、状態の最大サイズを制限してテストできるため、ここで役立ちます。チームによっては、ホストをサービスに組み込む前に模擬トラフィックを送信し、コネクションプールを含むすべてをウォームアップすることで、デプロイメントの影響を軽減しています。

私はたった今、この一つの事項に注目し、それを徹底的に測定して最適化することについて話しました。ここでMike Furrを招いて、システムの測定について話してもらいましょう。私は長年にわたって数多くのシステムに携わってきましたが、十分な負荷をかければ、ほぼすべてのシステムにスケーリングのボトルネックが存在します。十分なトラフィックを送信すると、どこかで必ず何かが破綻します。システムが無限にスケーラブルでないことは許容できますが、ボトルネックに気付かないまま突っ込んでしまうことは許容できません。
VPCのボトルネック測定:Little's Lawの応用

VPCについてお話ししたいと思います。これは私が長年携わってきたサービスです。多くのAWSサービスと同様に、VPCはコントロールプレーンとデータプレーンで構成されています。コントロールプレーンは、すべてのAPIトラフィックを受け付ける場所です。SubnetやVPCのRoute Tableを変更する場合、それらのAPI呼び出しはコントロールプレーンに送られ、コントロールプレーンがデータプレーンに指示を出します。データプレーンは、パケットを適切な場所に流すことを担当します。VPCを構築する際に解決する必要があった問題の一つは、コントロールプレーンからデータプレーンへの状態の配信方法でした。

ここでは、一般的な手法である追記専用のキューを使用しています。これにより、いくつかの優れた特性が得られますが、その一つは、DNSフリートと同様に、VPCフリートにも多数のデータプレーンがあるため、この追記専用キューで更新を送信すると、すべてのデータプレーンノードが自分のペースで読み取ることができるという点です。そのため、左側のノードが更新番号4で止まっていても問題ありません。
データプレーンの他のオブジェクトは、レートに関する5番目のアップデートを読み続けることができます。コントロールプレーンは、データプレーン専用にフォーマットされた事前計算済みの状態を送信することで、データプレーンの負担を軽減しようとします。データベースの経験がある方なら、これは非正規化されたビューに似ていると理解できるでしょう。つまり、顧客向けに一つの方法で配置されているオブジェクトを、データプレーン向けに異なる方法で配置し直すのです。

例えば、VPCルートテーブルの場合を考えてみましょう。個々のルートアップデートを送信する代わりに、すべてのルートの最長プレフィックスマッチを事前に計算し、最終的なルートテーブルをデータプレーンに送信します。これは、この追記専用ログの末尾にどのように追記するかを考え始めるまでは、うまく機能します。通常、これは簡単なことだと思われるでしょう。図には5つのボックスがあり、それぞれにバージョン番号またはシーケンス番号が付いています。次のシーケンス番号である6を選んで、キューの末尾に追加するだけです。

通常であれば、これは単純な解決策ですが、この事前計算された状態のステップを実行しているため、実際にはより微妙な問題があります。VPCルートテーブルに対する2つのアップデートが同時に発生し、データプレーンに送信するための非正規化を行う場合、両方のアップデートは互いを認識する必要があります。最初に書き込まれたものは、その後に発生する2番目の書き込みから見えている必要があります。これは複雑な状況ではなく、ロックを使用するという標準的な手法があります。最初に来た処理がロックを取得し、2番目のAPI呼び出しはその後でロックを取得します。

もちろん、ロックがあれば必然的にクリティカルセクションが生まれます。私たちの場合、それは比較的シンプルです。VPCルートテーブルの例を続けましょう。ロックを取得したら、VPCルートテーブルの現在の状態を確認し、新しいルートを追加し、データプレーン用の最終状態を再計算し、キューに追加して、最後にロックを解放します。並行プログラミングの経験がある方なら、パフォーマンスの問題が発生した際に最初に確認すべき場所がクリティカルセクションであることをご存知でしょう。

具体的にどのような状況になるのか、時系列で見てみましょう。このマゼンタ色のボックスは時間の単位として考えることができます - 1秒かもしれませんし、1分かもしれません。緑色のボックスは、クリティカルセクションであるロックを保持している時間を表しています。時間が経過するにつれて、コントロールプレーンにAPI呼び出しが到着するたびに、このロックを取得します。API呼び出しがない期間もあるので、この時間枠のすべてのスロットが埋まるわけではありませんが、やがて2番目の呼び出しが来て、別のクリティカルセクションが発生します。



同時に2つのコールを受けた場合、このロックで衝突が発生しますが、実はそれは問題ありません。 一方が先にロックを取得し、もう一方はほんの少し待ってから順番に処理を書き込むことになります。このパターンはかなりうまく機能します。 Beckyが言っていたように、突然大量のトラフィックが押し寄せるフラッシュモブのような状況も想定できます。 それらは最終的に時系列に沿って順番に処理されていきます。


しかし、さらに考えを進めると問題が見えてきます。 リクエストの到着レートが処理能力を上回った場合、どうなるでしょうか?実は、深く考える必要もありませんでした。私たちが実際に経験したからです。 これは、その時に見られたグラフです。Brownoutが発生しました。Y軸はエラーの数を示していますが、比較的少数でした。これらのエラーは、ロックの取得を試みたものの、取得の機会が得られずタイムアウトしたリクエストによるものでした。興味深いことに、システムは私たちが特に対策を講じることなく、自然に回復しました。

当初、私たちは過去最大規模のフラッシュモブに遭遇し、それを処理する余裕がなかったのではないかと考えました。しかし、ログを詳しく調査していくうちに、状況が少し違うことが分かってきました。実は最近、 Critical Sectionの処理時間を増加させる機能をリリースしていたのです。この機能のリリース後、突然システムの余裕が減少したのです。この図の上部を見ると、Critical Sectionを追加で配置できるスペースがありますが、下部ではそのスペースが消失しています。実は、リクエスト負荷は過去最高ではなく、私たちが気付かないうちにCritical Sectionが長くなっていたのです。コードの最適化と変更によってこの問題を解決した後、次の課題は、今回のように不意打ちを食らわないようにするにはどうすればよいかということでした。

私たちは、どのようなメトリクスを導入すべきか考え始めました。 APIエラーのメトリクスは既にあり、それによってこの問題を検知できましたが、それは事後的で受動的なものでした。つまり、問題が既に発生してからの対応になってしまいます。そうではない方法が必要でした。


APIのレイテンシーを計測することも検討しましたが、Critical Sectionの時間がAPIコール全体の主要な時間要素ではないことが判明し、ノイズに埋もれてしまうため、適切な指標とはなりませんでした。システムの余裕がどれだけ残っているかを測定する別の方法が必要でした。そこで、この図が示すように、ロックを保持できる時間を正確に測定することにしました。 点線のボックスで示したように、7つの塗りつぶされたボックスと3つの点線のボックスがあります。視覚的に見て、10個のスロットのうち7個が埋まっており、 直感的に容量の70%まで使用されているということが分かります。


これは単純な説明例です。実際には、これらのボックスのサイズは固定されておらず、単純に単位として数えることはできません。しかし、形が異なっていても、それらを数えることは可能です。このロックを保持している時間を計測し始めると、メトリクスを投稿して、そのメトリクスの合計を取ることで、どれだけの時間ブロックでロックを保持しているかを知ることができます。これにより時間の合計、つまりレイテンシーの合計が得られます。これは多くの人がダッシュボードに表示しない珍しいメトリクスですが、この状況で教えてくれるのは、私たちのタイムバジェットのうちどれだけをこのロックの保持に使用したかということで、ボトルネックにどれだけ近づいているかを知る指標となります。

長年進化してきたものの、基本的に同じままのシステムについて、今日でもこのロックを計測するメトリクスがあります。これが現在のグラフの様子です。このレイテンシー合計のグラフは、数週間にわたる日周パターンを示しています。このグラフで興味深いのは、前半は比較的フラットで成長の面では特に何も起きていませんが、中盤あたりから徐々に上昇し始めることです。グラフには赤い線がありますが、これは影響線ではなく、「何かを修正すべき」という線です。

このグラフに基づいてアラートを設定していますが、人間をページングするアラートではありません。チームのスプリントタスクとして修正を行うためのものです。同様のものをお持ちの場合、セルラーアーキテクチャであれば、より多くのセルを構築したり、データをさらにパーティショニングしたり、このロックを保持している間に小さな最適化を行ったり、アーキテクチャの変更を実装したりする必要があるかもしれません。これにより、世界が炎上して人間をページングする事態に対処するのではなく、早期警告システムを手に入れることができます。単位は少し変わっているかもしれません - 時間の合計とは何を意味するのでしょうか?1分間のデータポイントのグラフでは、単位を均一化できます。ミリ秒を計測している場合、ミリ秒を1000で割って秒に、60で割って分にします。これで、分あたりの時間合計(分)が得られ、0はロックをまったく保持していないことを、1は1分間の期間全体でロックを保持していることを意味します。

このテクニックは特に目新しいものではありません。私が説明してきたことの一般的なバージョンを示す、とても興味深いLittle's Lawという方程式があります。Little's Lawは、システム内の平均同時実行数(同時に発生できる事象の数)が、平均到着率とレイテンシーの積に等しいと述べています。今日、食堂で昼食を食べた方は、これを実際に目にしたはずです。レイテンシーは一定でした - 入って、すぐにテーブルに着けます - そして人が増えてくると、より多くのテーブルを開放して、同時実行性を増やしていきました。

私はレイテンシーの合計について話していましたが、Little's Lawの方程式には合計が出てきません。では、それはどこから来たのでしょうか?Little's Lawはさまざまなシナリオに適用できますが、1分間のデータポイントのような離散的なメトリクスポイントの観点で考えると、方程式についていくつかの仮定を立てることができます。1分間のデータポイントにおける到着数は、その分に得られたデータポイントの数、つまりNにすぎません。平均レイテンシーを計算するには、合計を観測数で割りますので、それらのNは相殺されます。メトリクスデータポイントのような離散的な時間単位では、システムの平均同時実行数はレイテンシーの合計に等しくなり、既存の可観測性ツールを使って簡単にグラフ化できます。

この概念を説明するために、もう一度視覚的な例に戻って詳しく見ていきましょう。ここに7つのブロックがあり、それぞれが0.1秒かかるとします。これは1秒のブロックで、合計すると、ボトルネックの70%に達することが分かります。左側の並行性は1であり、これは排他的ロックがあるためです。このロックを使用してシステムを構築したため、一度に1つのタスクしか実行できません。

しかし、Little's Lawは実際にはもっと一般的で、排他的ロックを使用する場所だけに限定されるわけではありません。例えば、Worker Poolがあり、必要なワーカー数を知りたいものの、システム内部から並行性を測定する良い方法がない場合を考えてみましょう。このような場合、システムを流れるすべてのタスクのレイテンシーの合計をグラフ化することで、必要な並行性の平均的な感覚をつかむことができます。合計が毎秒142秒の作業量になっているとすれば、そのワークロードを処理するには少なくとも142のワーカーが必要だということになります。

もちろん、これらは対象期間の平均値です。1分間のデータポイントであれば、それは1分間の平均値なので、ピーク時にはもっと高くなるでしょう。明らかに142よりも多くのスケールアップが必要ですが、時間とともにグラフ化することで、どの程度の余裕があるかを把握することができます。新機能を追加したばかりの場合、大幅に余裕が減っていないか?パフォーマンスの最適化を見直す必要があるか?といったことを確認できます。
AWSでは、Scaling Cliffsについて多くの検討を重ねています。私たちは常にそれらを測定する方法を探しており、同じテクニックを使用している様々なシステムがあります。EC2インスタンスの配置場所を見つける際のEC2 Placementアルゴリズムや、WorkflowシステムやVPCシステムでも使用しています。システムを通過する並行性を測定したい場合は、時間の合計をグラフ化することは、ダッシュボードに追加するのが非常に簡単な方法です。
運用イベントにおける即時対応策:メトリクスの活用

最後にボーナスセクションと呼んでいる部分をお話しします。今年のこのトークに何を含めるかについて話し合っていた際、よく出てくる話題の1つが、常に緩和策に焦点を当てたいという願望です。運用上のイベントが発生した場合、大小に関わらず、ニアミスであれ大きな問題であれ、常にできるだけ早くお客様の問題を解決するよう努めています。多くのチームで繰り返し出てくるテクニックがいくつかあり、それらはかなり普遍的なものであることが分かってきました。
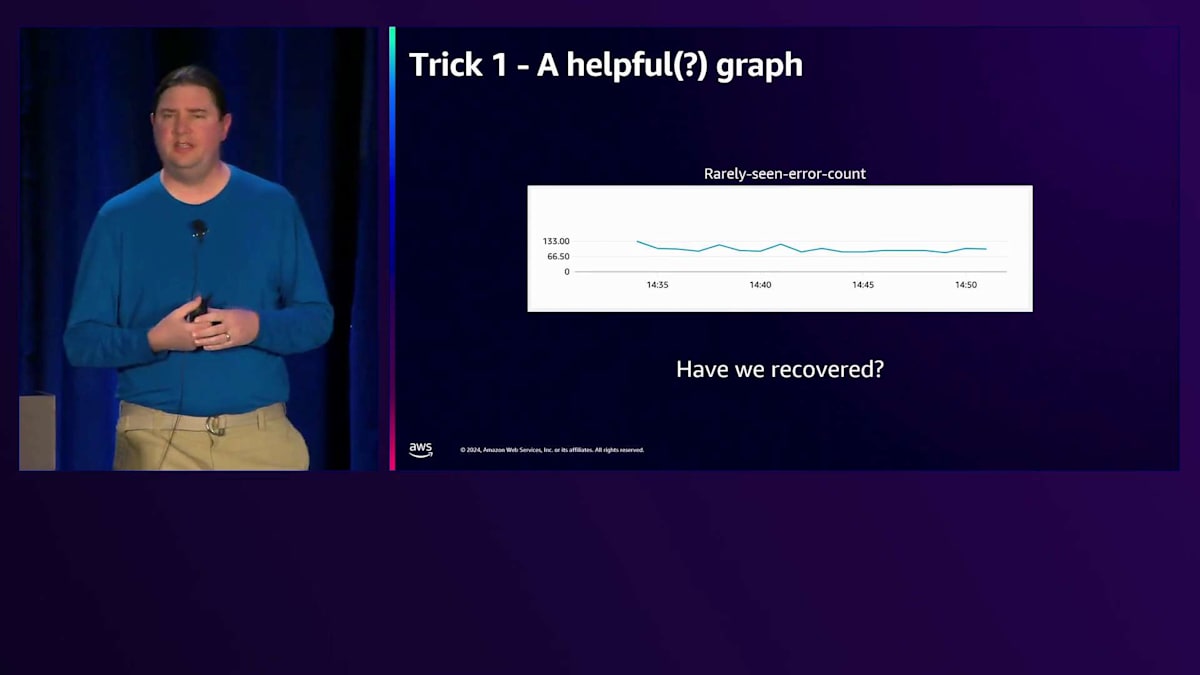
最初の例は単純なメトリクスグラフです。このグラフは、あまり頻繁には発生しないエラーを示しています。おそらく、コードの奥深くにある不変条件が違反された時にメトリクスとして記録されるようなものでしょう。ところが今日、目が覚めてみると、その不変条件が実際に違反されており、このメトリクスがエラー数を記録しているのです。ダッシュボードを確認して、影響を軽減するための作業を試みたり、出血を止めるために何ができるか考えたりし始めます。そしてもう一度ダッシュボードを見たとき、問題は「本当に回復したのか?」ということです。

これら2つのグラフの違いは一目瞭然です - 側面に線が下がっているのです。これが意味することは、このメトリクスを記録する際、すべてが正常で不変条件が違反されていない場合は、常にゼロを記録しているということです。エラー数がゼロだと示しているわけです。この利点は、問題を修正した瞬間にすぐわかるということです。右側で数値が下がっているという事実により、メトリクスがまだ伝播していないのではないかという疑問が完全に解消されます。

このやり方にはもう1つ利点があります。それは、これらに対して非常に簡単にアラームを設定できるということです。これが本当に稀なエラーである場合、アラームや適切なしきい値について考えていなかったかもしれません。しかし、いざ発生してみると、根本原因の特定やデプロイメントの完了までに1、2日必要かもしれません。その間、アラームを設定しておけば、全く同じ状況が再発した場合に、すぐに把握して同じ対策を適用できます。このゼロを記録するという利点がなければ、メトリクスアラームは、問題が修正されたのか、それともシステムが悪化してメトリクスを記録できなくなったのかを判断できないでしょう。
これは、メトリクスのエチケットを守った、適切な振る舞いを示す別のエラーカウントです。以前はゼロを記録していて、今は数値が上がっています。ここで質問です。この影響を軽減するために即座に取れるアクションは何でしょうか?バグを修正する?いいえ、バグは修正しません。なぜですか?今すぐ修正したいのですか?一秒一秒が大切です。では、どうしますか?Rollbackという声や、Restartという声が聞こえてきましたね。

少し異なるグラフをお見せして、皆さんの回答が変わるか見てみましょう。これは次元性のあるグラフで、その次元はInstance IDによるものです。 Instance IDやNode ID、Availability Zoneに一致する次元を持つグラフがあるという事実だけで、すべきことは一つだとすぐにわかります。そのホストをサービスから外し、VPCから外し、DNSから外す、必要なら軌道上から破壊してでも排除するのです。そうすれば回復は完了で、その後で原因を究明できます。実は面白い話があって、このプレゼンの練習セッションをしているときに、私たちのチームの一つでまさにこの出来事が起きたんです。彼らは「あ、このグラフ、このホストのCPUが異常に高いな」と気付いて、サービスから外して、その後で何が起きていたのか調べました。このアプローチは本当に何度も効果を発揮するんです。
トラブルシューティングの基本:再起動から始める

このようなグラフを見たことがある方は多いと思います。これはメモリ使用率が右上がりに上昇しているグラフですが、決して喜ばしいものではありません。では、このような状況に対して即座にどのような対策が取れるでしょうか?誰かが今おっしゃいましたね - そう、再起動です。単純に電源を切って入れ直すのです。この「電源を切って入れ直す」というテクニックは、実に広く使われています。私たちは常にこの方法を使用していますが、ここで強調したいのは、これを定期的に実践すべきだということです。これを行い、非常に高い確信を持てるようになれば、このようなグラフが示されるようなトラブルチケットやアラームを受け取った際の標準的な対処方法として、まず再起動を実行してから、他の要因を調査すればよいのです。

単純にクリック数回で再起動を実行し、その処理が完了するまでの間(それほど長くはかからないはずです)、私は他に何が起きているのかを調査することができます。ページングやアラームを受け取った最初の数秒で、とにかく再起動すればいいんです。本当にシンプルです。 この方法は様々な場面で活用されています - Cacheが適用されない時や、Config fileが変更されない時などです。これを見て「そういったケースは全てテストすべきだ」と思うかもしれません。確かにその通りです。しかし、多くの場合、奇妙なエッジケースが存在します - 例えば、Rollbackを実行したものの、新しいConfigが適切に元に戻らなかったり、新バージョンでは想定していなかった方法でCredentialがキャッシュされてしまったりするケースです。


単純に再起動を実行し、Fleetを再起動するだけで問題は解決します。そのバグが発生した理由は後で調査すればいいのです - とにかくFleetを再起動し、これを頻繁に行いましょう。 では、次のコーヒーブレイクでサービスをチェックする簡単な方法をご紹介します:ゼロを投稿する、Dimensionを使用する - これは必ずしもInstance IDだけでなく、サービスに適した境界なら何でも構いません - そして、まず再起動してから質問する。常に緩和策を考えましょう。 このセッションを楽しんでいただけたと思います。この後、私はここか廊下にいる予定です。また、Peer Talkでも参加していますので、今後数日間、Resiliencyについて話し合いたい方はご連絡ください。時間は取れると思います。ご清聴ありがとうございました。アンケートへのご協力もお願いします。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion