re:Invent 2024: AWSがOpenSearchで実現する生成AIの検索革命
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Revolutionize your search applications for generative AI (ANT340)
この動画では、AWSのSearch ServicesのDirector of TechnologyであるJon HandlerがAdobeとFreshworksの事例を交えながら、検索エンジンの進化について解説しています。従来の語彙ベースの検索から、Large Language Modelを活用した意味ベースの検索への移行や、OpenSearchを活用したVector検索の実装方法について詳しく説明されています。特にAdobeのAcrobat AI AssistantやFreshworksの事例では、1日50万RPM、1,500億のドキュメントを処理する大規模な実装例が紹介され、OpenSearchへの移行でレイテンシーが半減し、60以上のノード削減を実現した具体的な成果が示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
検索エンジンの進化:語彙ベースから意味ベースへ

本日はお越しいただき、ありがとうございます。皆様と今朝このような形でお会いできることを大変嬉しく思います。私はAWSのSearch ServicesのDirector of Technologyを務めるJon Handlerです。本日はAdobeのAbhijeet SinghとFreshworksのSreedhar Gadeにもご参加いただいています。この場でお話しできることを大変楽しみにしています。
さて、検索エンジンを使ったことがある方はいらっしゃいますか?そうですね、皆さん使ったことがあると思います。検索エンジンは、皆さんが持っている情報ニーズと、それを満たすことができる大量の情報源とを結びつける役割を果たします。製品を購入したい場合でも、宿泊するホテルを探す場合でも、研究文書を探す場合でも、何らかの情報ニーズを持って検索エンジンにアクセスすると、検索エンジンがその情報源との仲介役となってくれるわけです。

2年前まで、私たちはこのような方法で検索エンジンと対話していました。テキストボックスに文字を入力し、場合によってはFaceted Searchで属性や値をクリックして検索範囲を絞り込むという、一回ごとの反復的な方法でした。検索エンジンは単に、入力された単語とドキュメント上の単語とをマッチングして結果を返すだけでした。検索体験の核心は、それぞれのドキュメントが、ユーザーが検索エンジンにアクセスした際の意図にどれだけマッチしているかを判断することでした。
検索エンジンはデータベースの世界に属していますが、データベースがすべての情報を返すのに対し、検索エンジンは最適な情報を返そうとします。私たちは、このような語彙ベースの検索方法に慣れ親しんできました。例えば「青い靴」という検索クエリを入力すると、検索エンジンはリンクや画像などの結果を提供します。理想的なケースでは、一回の検索で欲しい情報が得られて終わりです。しかし実際には、完璧な結果が得られないことが多く、クエリを考え直したり、単語を追加したり削除したりして、この語彙的なサイクルを繰り返す必要がありました。なぜなら、私たちが入力する単語自体が意味を内包しているからです。
「青い靴」というテキストクエリは比較的簡単に解決できます。しかし、「暖炉の前でくつろげる居心地の良い場所が欲しい」というクエリの場合、頭の中では「8フィートの青いソファがあれば素敵だろうな」と思っていても、実際のクエリは「居心地が良い、暖炉の前でくつろげる場所」という言葉だけです。そうすると検索エンジンは単語だけに縛られてしまいます。確かに単語自体は意味を含んでいますが、意味と意味を結びつけることができるより広い方法があります。これこそが、この2年間で起きた革命的な変化です。今や私たちが情報とやり取りする方法は、単語主導ではなく、意味主導になってきているのです。
OpenSearchとVector検索の仕組み


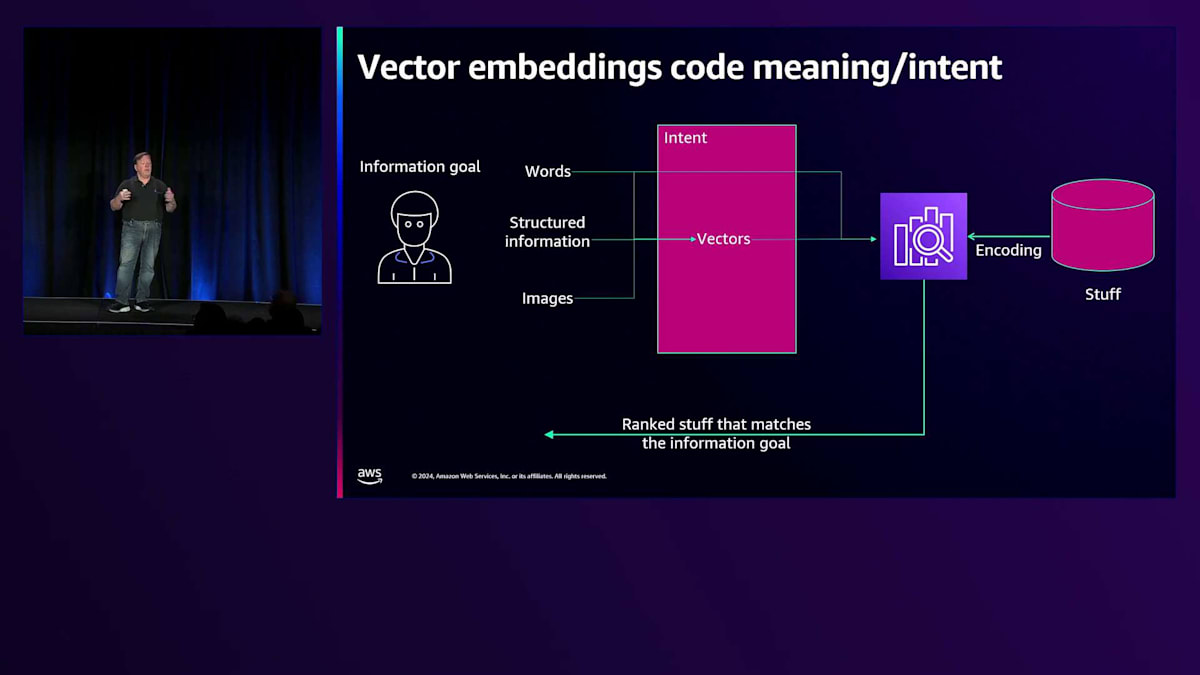
検索エンジンについて考えてみましょう。まず、検索エンジンに投入する情報の集まりがあります。ユーザーは、単語や構造化された情報、場合によっては画像を含むクエリを入力します。これらの情報は、Large Language Modelを使って多次元ベクトルにエンコードすることができます。少し分かりやすく説明すると、ベクトルとは、多次元空間を定義する浮動小数点数の大きな配列のことです。私たちは全ての入力情報をこの多次元ベクトル空間にエンコードし、Large Language Modelが学習した次元によって、意味的に関連するものが近くに配置されます。クエリを実行すると、同じ空間内でベクトルが生成され、意味的に関連する近いものを見つけることができます。最終的に、検索エンジンはそのベクトルを使って情報のベクトルとマッチングを行い、ランク付けされた文書の集合を結果として返します。
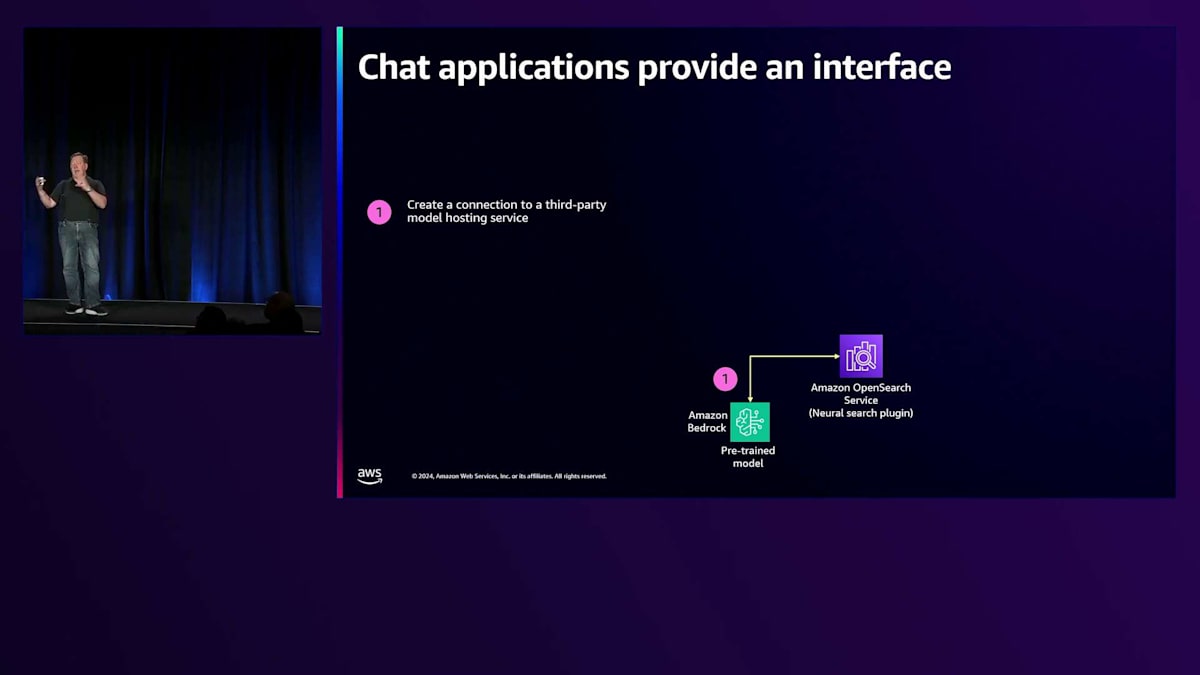
従来のテキストボックスインターフェースがありました。検索や情報検索が変化してきた別の方向性として、より会話的なインターフェースへの移行があります。以前は一回限りの反復的な語彙的クエリでしたが、現在のシステムは会話を取り入れることができ、検索の時間軸が拡張され、以前の質問内容が引き継がれて検索に活用される会話が可能になっています。
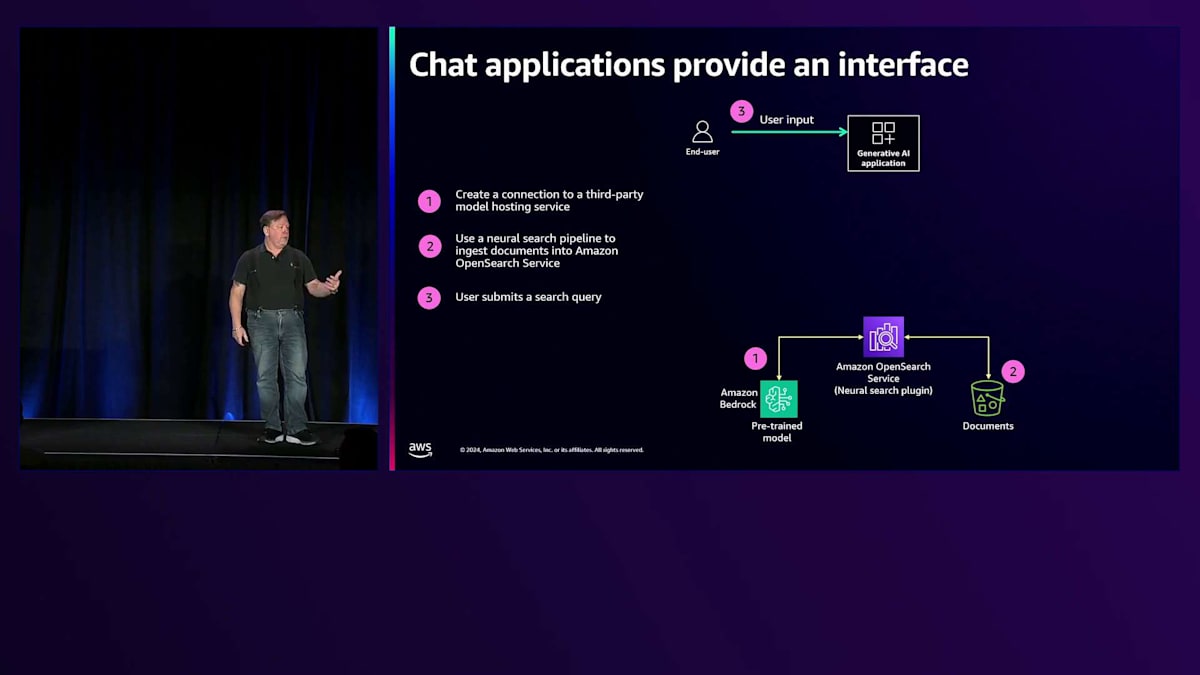
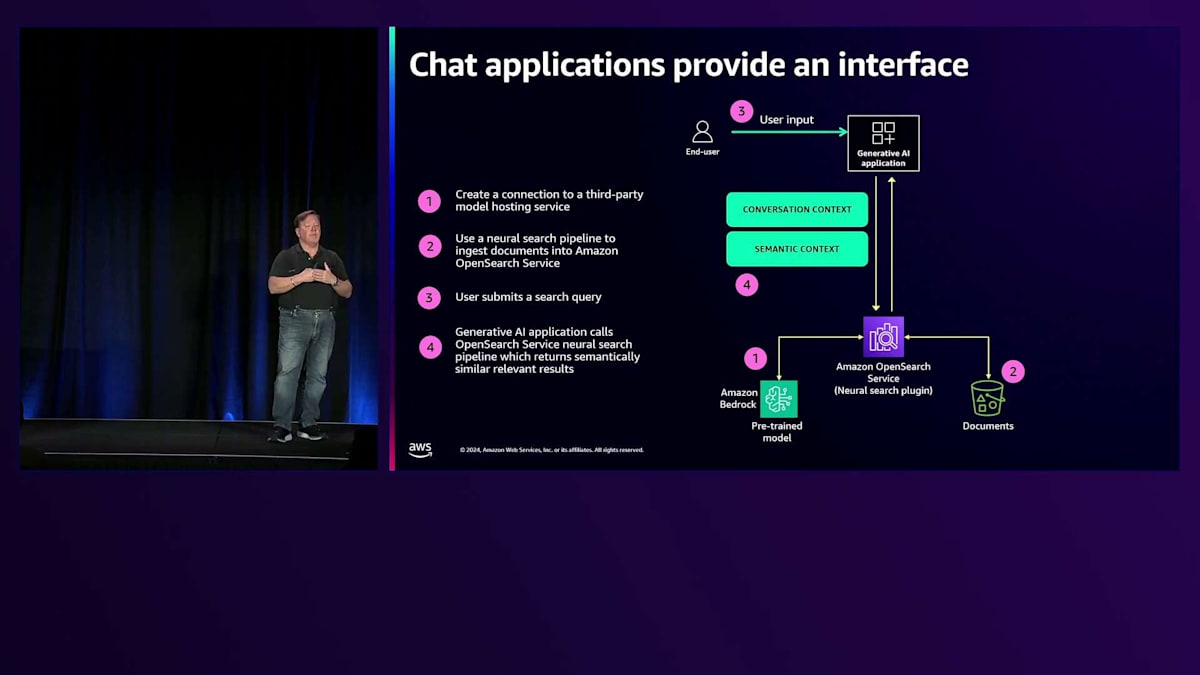
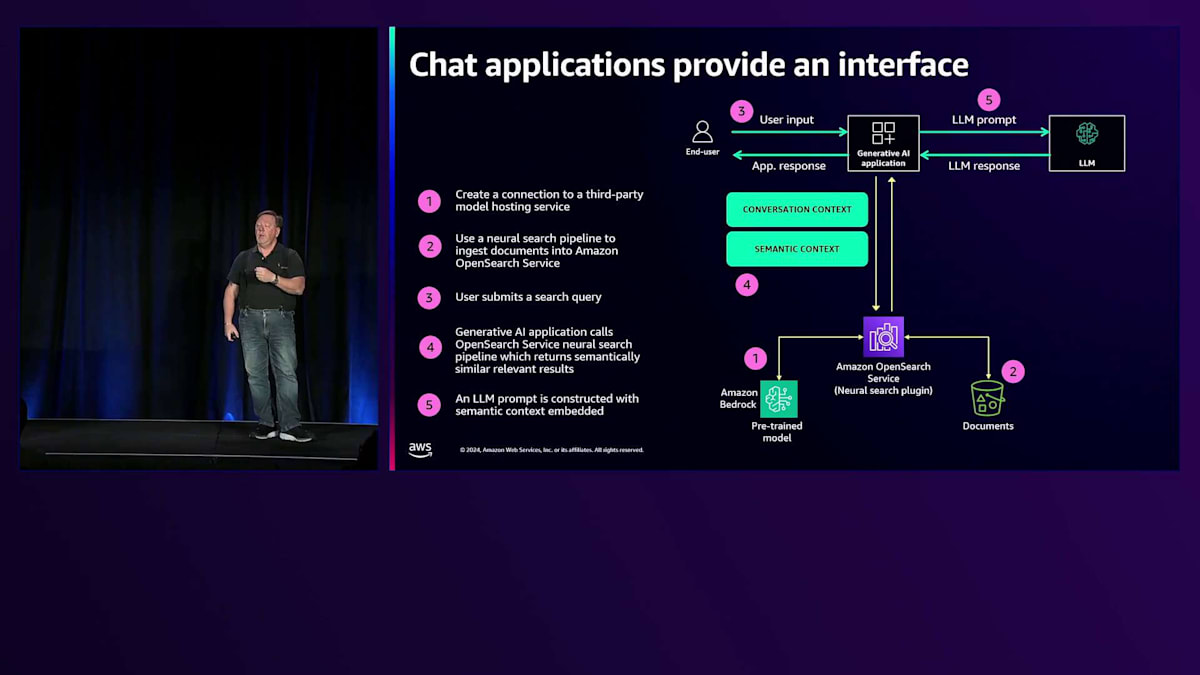
これがチャットインターフェースです。一般的な方法として、情報をAmazon Bedrockのようなllmに通して、それを検索エンジンに送ります。クエリ側では、ユーザーが「暖炉の前でくつろげる居心地の良い場所」といったテキストクエリを入力し、それがチャットアプリケーションに送られます。チャットアプリケーションは、会話のコンテキストと意味的なコンテキストの両方を活用して検索エンジンにクエリを実行し、チャットの生成部分に役立つ情報を取得します。


LLMには幻覚という問題があります。LLMは好き勝手に情報を作り出すことができます - 質問すれば何かしらの答えを作り出してしまいます。Generative AIにおける検索の目的は、LLMが取得する情報の正確性を確保することにあります。10個の青いリンクは完全になくなるのでしょうか?いいえ、そうは思いません。例えば、8インチから1/4インチの水道管に接続するためのXJ-57-R4コネクターを探している場合、そのような部品番号での語彙的なマッチングの機能は常に必要です。同時に、より会話的でチャットベースのインターフェースによって、より会話的で意味に基づいた情報検索の体験が可能になっています。
Amazon OpenSearch Serviceの特徴と活用事例


ここで話題を変えて、Amazon OpenSearch ServiceとOpenSearchについてお話ししたいと思います。OpenSearchは、検索、分析、ベクター処理のためのオープンソースのスイート製品で、オープンソースプロジェクトとして提供されています。数字で見ると、現在約8億ダウンロードに迫る勢いです。数千人のコントリビューターがおり、コミュニティの多くの方々がプロジェクトに変更を加え、協力してくださっています。9月には、プロジェクトがLinux FoundationのもとでOpenSearch Software Foundationに移管され、外部のコントリビューターとともにプロジェクトにオープンガバナンスがもたらされたことを、私たちは大変嬉しく思っています。




Amazon OpenSearch Serviceでは、OpenSearchのマネージドサービスを提供しています。 これは、マネージド型のオープンソースで、AWSクラウド上でOpenSearchの設定、デプロイ、利用を簡単に行えるようにしています。 セキュリティは最優先事項です。私たちは様々なセキュリティ制御を提供しています。OpenSearch自体が、きめ細かなアクセス制御、保存時の暗号化、通信時の暗号化、そして数多くのコンプライアンス基準への準拠を提供しています。検索が主要なユースケースです。 私たちは、字句検索、Semantic検索、そしてk-NNプラグインによる最近傍検索を通じたRAGのためのナレッジベースを提供しています。 Sparse、Hybrid、そしてMulti-modalなど、必要とされるあらゆる種類のSemanticモデルをサポートしています。


第二の主要なワークロードは、Observabilityです。OpenSearch Serviceは、大量のログデータを取り込み、インフラストラクチャ、アプリケーション、ビジネスメトリクスを監視するためのチャートやグラフを構築する機能を提供します。 Amazon DynamoDB、Amazon DocumentDB、そして最近ではCloudWatchやSecurity Lakeに対するクエリ機能など、他のAWSサービスとの多数の連携を実現しています。検索に関する主要なワークロードでは、ランキングの調整が可能な構造化・非構造化検索、ユーザー行動の捕捉、そして検索候補のパーソナライズ機能、タイプアヘッド、 ファセット検索を提供しています。分析面では、ログデータの取り込みが可能で、アプリケーションとセキュリティの監視、Observabilityの構築ができます。様々なアプローチを用意しています。

リアルタイムダッシュボーディングはコスト効率が高く、データの階層型ストレージを通じてコストを削減する様々な方法を提供しています。また、ログデータに対して自然言語でクエリを実行できる統合型AIアシスタントも備えています。

ベクトル面では、Dense VectorとSparse VectorによるSemantic検索を提供し、数十億のベクトルと1秒あたり数万のクエリをサポートしています。字句検索とVector検索の両方において、精度を若干犠牲にすることでVector処理のコストを管理できる様々な量子化オプションを用意しています。


OpenSearchはデータベース技術です。ソースデータをJSONとして構造化し、OpenSearchに送信します。OpenSearchは、すべてのJSONフィールドをインデックス化してそのデータを処理します。これは、インデックスが制限される他のデータベースソリューションとは対照的で、OpenSearchはインデックス化に特化しているため、すべてのデータに対してインデックス化を提供します。 クエリ側では、JSONリクエストとしてクエリを送信し、結果セットを取得します。ベクトルについては、k-Nearest Neighborプラグインを提供しており、ベクトルを送信して広大な空間内で近傍を見つけることができます。HNSWとIVF(Hierarchical Navigable Small WorldsとInverted File)という2つの異なるアルゴリズムをサポートしており、Facebook AIやNMSlib、さらにLuceneなど、多数のエンジンをサポートしています。


私たちは、簡単にスケーリングやデプロイが可能なマネージドクラスターを提供しています。使いやすいServerlessソリューションも用意しています。また、サードパーティのモデルホストに接続し、インデックス作成時のVector Embeddingの生成やクエリのVector Embedding生成プロセスを自動化できるNeural Pluginも提供しています。これは、Lexical検索、Vector検索、そしてHybrid検索をサポートしています。
Vector検索におけるデータ準備と評価の重要性



Vectorワークロードには、いくつかの共通するテーマがあります。その中から特に重要な2つを取り上げて、AdobeとFreshworksがこれらの課題にどのように取り組んでいるかをご紹介したいと思います。1つ目はデータの準備です。「Garbage in, Garbage out(入力の質が出力の質を決める)」という原則があるように、Vector検索のためにはドキュメントの準備が必要です。最初のステップはEntity Extractionです。これは、人物などのAIによるEntity Extractionかもしれませんし、テーブルから列に基づいて値を抽出してクエリ可能にすることかもしれません。テキストの正規化や、ユーザーが生成した不正操作要素のクリーニングも必要です。


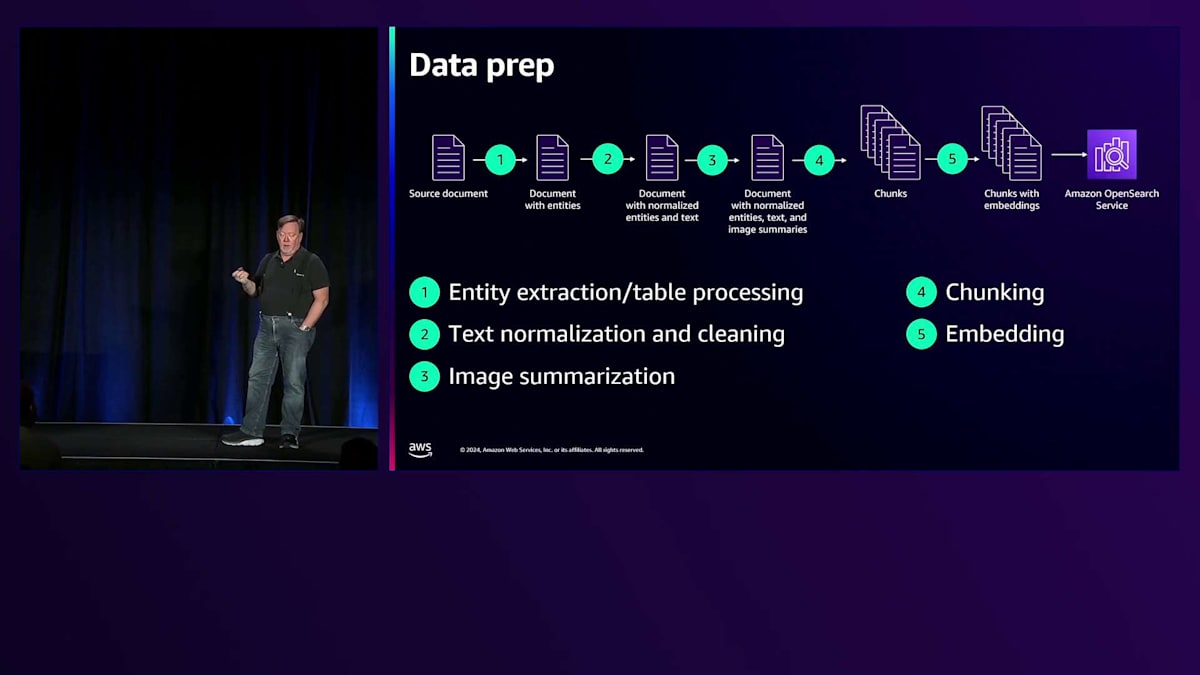
次に要約を行います。ドキュメントに画像が含まれている場合は、画像モデルやマルチモーダルモデルを使用して、キャプションや説明のテキストを抽出します。大きなテキストブロックを、Chunkと呼ばれる小さな部分に分割する必要があります。段落は通常、意味のある情報のまとまりなので、段落単位でChunkを作ることが一般的です。しかし、文書全体を見ると意味的なズレが大きくなりすぎて、正確な検索が難しくなります。そのため、小さな部分に分割し、それぞれの部分のVector Embeddingを生成してOpenSearch Serviceに送信します。


データの準備は、検索パズルの中であまり語られていない部分です。これは通常、バックグラウンドでオフラインで行われます。S3 Bucketのような元のドキュメントを格納するBucketがあり、データ準備アプリケーションがすべての処理を行って、準備されたドキュメントChunkを2つ目のBucketに格納するというのが一般的なパターンです。Amazon OpenSearch Ingestionを使用すると、S3 Bucketからデータを読み取り、OpenSearch Serviceにデータを配信する自動スケーリングパイプラインを構築できます。このようにして、データを準備してOpenSearch Serviceに取り込むためのオフライン処理メカニズムを構築できます。

もう1つの選択肢として先ほど触れたNeural Pluginがあります。OpenSearch Neural Pluginは、インデックス時とクエリ時の両方でドキュメント処理を自動化できるパイプラインを構築する方法を提供します。Remote Neural Pipelineと呼ばれるIngest Pipelineでは、一連のプロセッサーを定義します。この例では、特定のフィールドを取り出してEmbedding用のモデルに送信し、その結果をドキュメントに戻すという単純な処理を行っています。つまり、descriptionフィールドがdescription_vectorフィールドに変換されるわけです。このように、ドキュメントを送信するだけで、OpenSearchがEmbedding処理を行い、そのフィールドに結果を格納します。
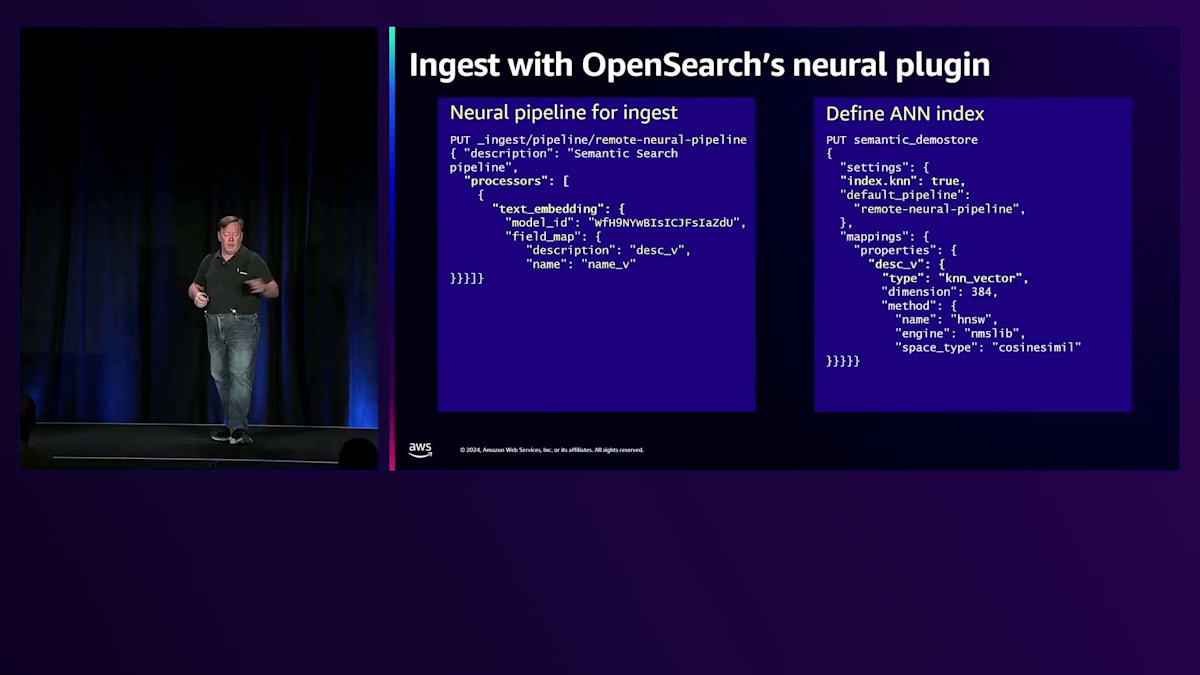
OpenSearchでインデックスを定義する際、インデックスはデータベースのテーブルに似たメインコンテナとなります。インデックスを定義し、index KNNをtrueに指定し、使用するパイプラインを示し、そしてfield description underscore vector type fieldを設定します。dimensionsがあり、HNSWメソッドがあり、ライブラリの仕様があります。このようにインデックスを定義するだけで、クエリ側でベクトル検索が可能になります。
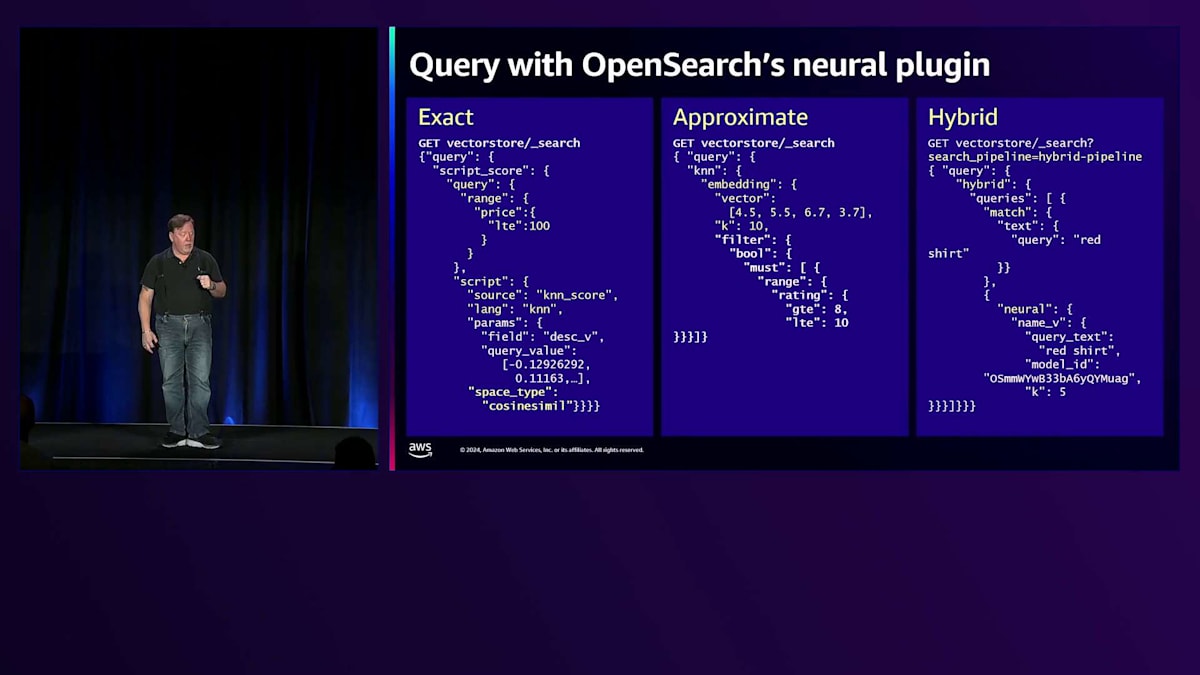
クエリの方法には、いくつかの異なるアプローチがあります。まず、Script-basedのスコアリングメカニズムでサポートされる完全一致(Exact)クエリがあります。完全一致のk-Nearest Neighborでは、クエリベクトルをインデックス内のすべてのベクトルと比較します。これは特にパフォーマンスが良いわけではありませんが、最高の精度を提供する正確な方法です。この例では、特定の値の範囲(価格が100未満)でフィルタリングし、クエリベクトルが埋め込まれたベクトルに対してKNNスコアリングを適用するクエリを示しています。
近似検索側では、完全一致は正確ですが計算コストが高いため、近似クエリを使用します。OpenSearchには、ベクトルグラフを走査する際にフィルタを適用できる効率的なフィルタリング機能があります。この場合、埋め込みをベクトルとして与え、フィルタリング方法を指定するだけで、OpenSearchが検索を実行します。最後の方法はHybrid検索で、複数のクエリを同時に実行し、結果を組み合わせることで両方の利点を活かします。一般的なモードは、Lexical検索とVector検索を実行し、結果を組み合わせて最適なパフォーマンスを得ることです。
この例では、Search Pipelineを定義します。パイプラインはプロセッサーとベクトルを組み合わせる方法を定義します。これはHybridクエリで、赤い物を見つけるMatch queryと、赤いシャツに対するNeural queryがあります。Neural queryは自動的にそのクエリテキストのベクトル埋め込みを取得して組み込みます。LexicalスコアとVectorスコアは異なるスケールにあるため、スコアを正規化する方法を定義するSearch Pipelineを設定します。正規化手法と組み合わせ手法を選択する必要があり、これらはSearch Pipelineにまとめられています。

2番目の大きなテーマは、評価に関するものです。特にコスト、精度、レイテンシーのトレードオフが重要です。量子化手法を使用すると、精度を犠牲にしてコストを大幅に削減できます。完全一致を使用すれば非常に高い精度が得られますが、レイテンシーも高くなります。このスペースでは常にこのようなトレードオフのゴールデントライアングルが存在します。この技術を採用する場合、それが機能しているか、うまく機能しているか、価値があるかを判断する必要があります。重要なのはGolden Setで、人手による評価や完全一致KNNの実行を通じて、正しい結果となるクエリと結果のペアのセットを作成します。そして、モデルのハイパーパラメータを調整し、レイテンシーとコストのトレードオフを行う際に、クエリをGolden Setに対してテストする反復サイクルを使用できます。
AdobeのAcrobat AI Assistant:PDFとの対話を革新する
OpenSearch Serviceでは、精度、レイテンシー、コストのトレードオフを制御することができます。ここで、AdobeのAbhijitに来ていただいて、Acrobat AI Assistantについてお話しいただきたいと思います。

ありがとうございます、John。皆さんの中で、PDFを使ったことがある方はどれくらいいらっしゃいますか?ほとんどの方が、PDFドキュメントを扱う際に素早く答えを得たいと思われたことがあるのではないでしょうか。そこで活躍するのがAcrobat AI Assistantです。私たちはその価値を提供することができ、現在は誰でも利用できるようになっています。


Acrobat AI Assistantを使えば、PDFドキュメントだけでなく、さまざまな形式のドキュメントとデスクトップ、Web、モバイルアプリなど、あらゆる環境で対話することができます。質問をして、出典付きの回答を得ることができるので、その回答に自信を持つことができます。Assistantがどこから回答を得ているのかを示してくれるのです。これがAcrobat AI Assistantのランディングページです。ログインする必要はなく、すぐに体験することができます。ドキュメントがそこにあり、その体験がいかに価値があるかをすぐに実感していただけます。

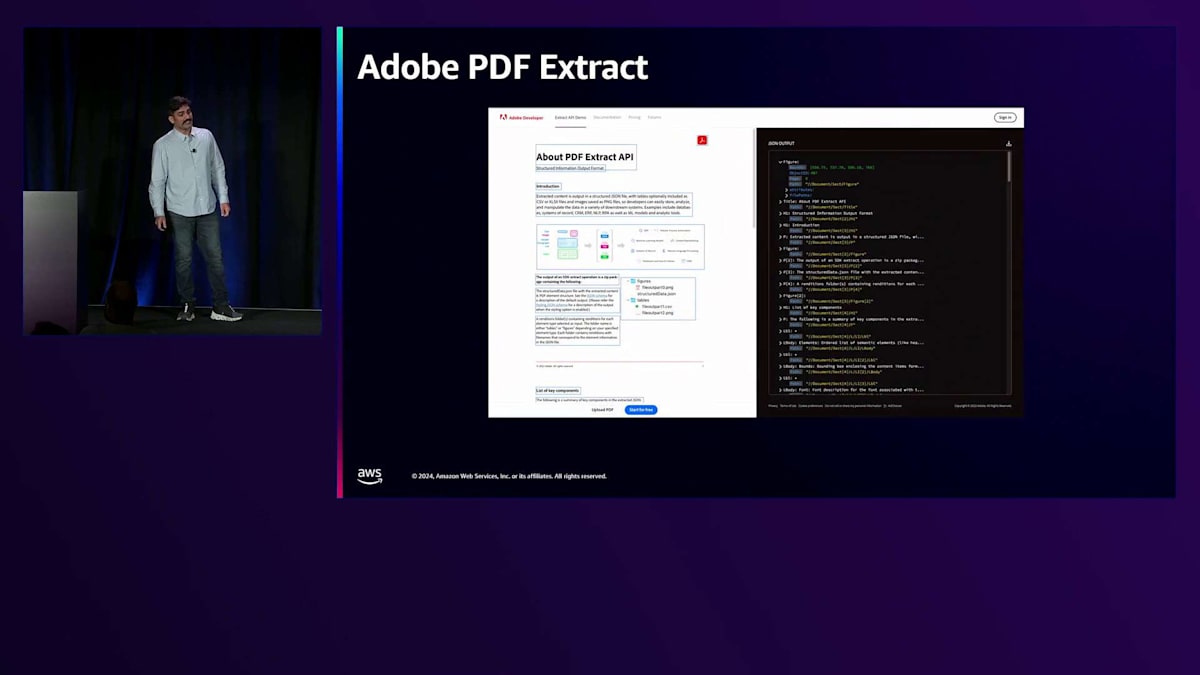
PDFドキュメントについては、コアエンジンを使用してPDFドキュメントのさまざまなコンポーネント、つまりテキストや画像を抽出し、それらをLLMに取り込んで、LLMに影響を与えるためのコンテキストを作成しています。このコアエンジンがAdobe Extractで、これも誰でも利用できます。Extract APIを使って独自のソリューションを構築することができます。
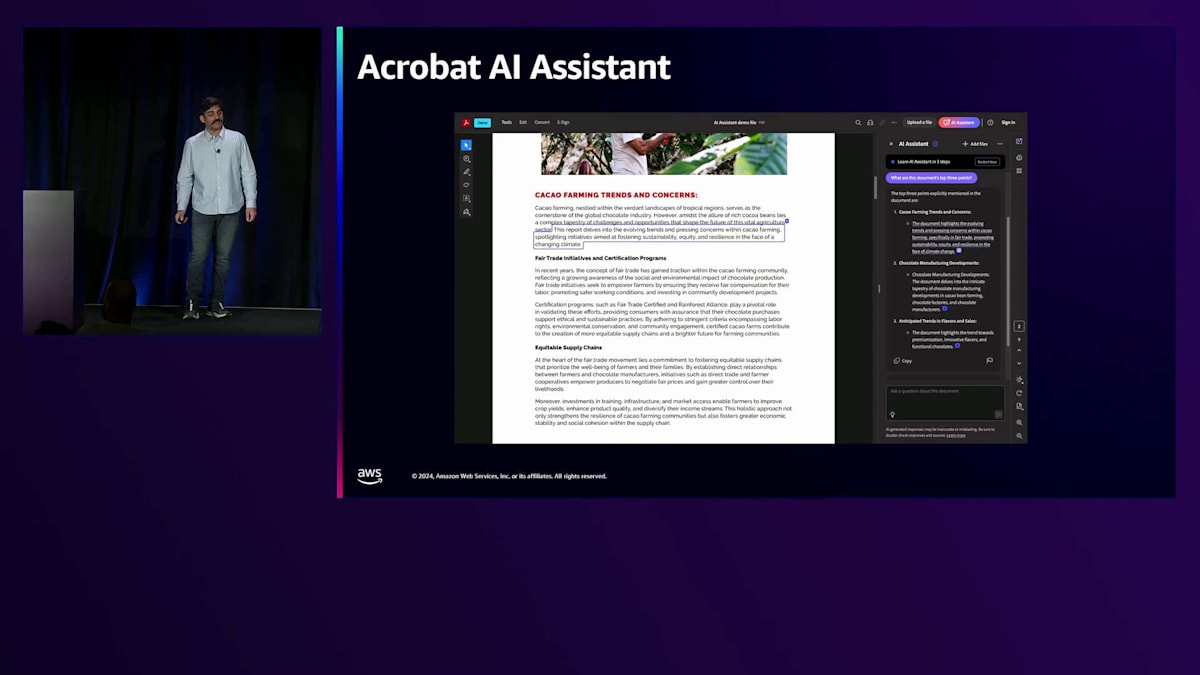
これがAcrobat WebとデスクトップでのAcrobat AI Assistantの動作方法です。右側のパネルに、質問を入力するAssistantがあります。回答を得ると、アクティベーションが表示されます。それらのアクティベーションをクリックすると、左側の元のドキュメントに、バウンディングボックス内にすべての出典が表示されます。回答が正しいかどうか、そしてLLMが誤った情報を生成していないかを確認でき、AdobeのAIに対する責任ある取り組みの方針に従っています。
右側のパネルに表示されているのが、Acrobat PDF Extract APIです。これは、JSONとして抽出したデータで、サーバー上でさまざまなバックグラウンド処理を実行しています。これらのAPIは利用可能で、その上にソリューションを構築することができます。私たちはその上にAcrobat AI Assistantソリューションを構築しました。様々な要素のバウンディングボックスを確認することができ、見出し、画像、段落など、ドキュメント内のさまざまなセマンティック要素を把握することができます。これがソリューションのデータ準備部分です - 情報を抽出し、加工・クリーンアップして、回答を得るためにLLMに送信します。


Johnが共有したように、属性の特定に関して多くの要件があり、多くのEmbeddingを扱う必要があります。Embeddingは回答のソースとなるドキュメントにたどり着くのに役立ちます。そこで私たちはOpenSearchを活用してきました。大まかに言うと、2つの主要なワークフローがあります。取り込みワークフローでは、ドキュメントをAcrobat Assistantのバックエンドに取り込みます。数秒以内にそれを利用可能にします。長く待つ必要はなく、ほとんどのドキュメントは1秒以内に操作可能になります。バックグラウンドでは、PDFをJSONに変換し、JSONからチャンクを抽出し、チャンクに対してEmbeddingを生成し、それらをOpenSearchに保存します。
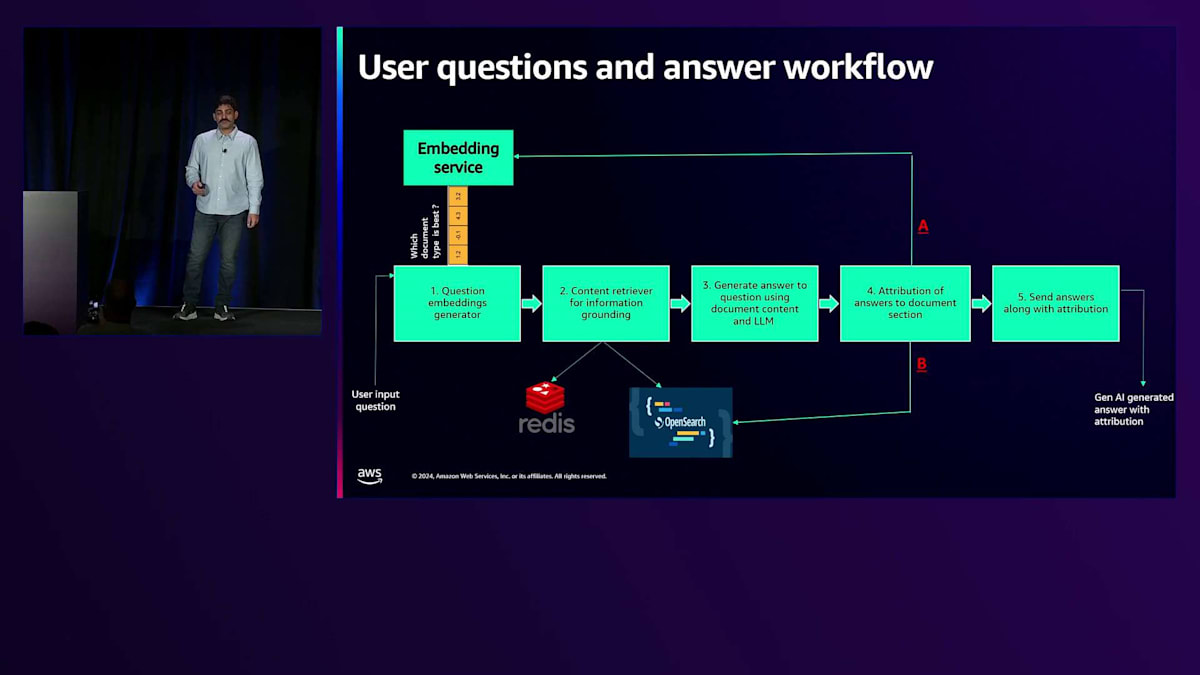
取り込みが完了したら、ユーザーにドキュメントとの対話を開始してもらい、関連する質問をして、実際に行いたい作業に取り掛かってもらいたいと考えています。これは私たちのパイプラインの非常に高レベルな概要です。ユーザーが質問を入力すると、システムから適切なコンテンツを取得します。
システムから質問に答えるために必要な適切なコンテンツを取得します。回答の推論を得るために言語モデルにそれを送信します。Attribution engineは、元のドキュメント内の適切なソースを見つけるためにそれを分解します。そこでOpenSearchの効率的なフィルタリングを使用します。利用可能なさまざまな類似性スコアリングメカニズムを使用します。1つのEmbeddingモデルに限定されないため、ベクトルは異なる次元を持ちます。複数の言語をサポートし、アシスタントは多言語対応です。これらすべての機能と柔軟性は、このVector Databaseを通じて利用可能です。



OpenSearchに関する規模と機能要件について説明させていただきます。何百万ものPDFドキュメントを扱う何億人ものユーザーが利用できるソリューションを構築したいと考え、それがスケールすることを確認したかったのです。ユーザーに数秒以内に作業を開始してもらいたかったため、インデックス作成ワークフローをバッチ処理にすることはできませんでした。そこでインデックス作成部分の時間を短縮することができました。ソリューション全体としてコスト効率が良くなければならず、これはコスト、レイテンシー、精度のトレードオフの三角形に関係します。




インデックス作成が完了すると、生成した属性情報についても確認します。この点でOpenSearchは全ての要件を満たしていました - 異なる次元のベクトルを扱うことができたのです。 適切なインデックスを作成してEmbeddingを取得し、類似性検索のための適切なアルゴリズムを適用することができました。 そして、私たちが求めるスループットにも対応できました。 私たちのユースケースは、ユーザーが自分のドキュメントを持ち込んで操作し、回答を得て、その日の作業を進めるというものです。






時間をかけてインデックスを作成して利用可能にできる静的なナレッジベースは持っていません。インデックス作成はリアルタイムで行う必要があり、属性情報を提供するためにほぼリアルタイムでのインデックス作成が必要でした。 これは興味深い課題をもたらしました:ドキュメントとの対話が終わればすぐに離れてしまうため、Embeddingを長期間保存する必要がないのです。 そこで、Embeddingの一時的な性質から、ローリングインデックスを使用し始めました。 1時間ごとに新しいインデックスに切り替わり、その時間中に開かれたドキュメントはその時のアクティブなホットインデックスにインデックス化されます。 このインデックスは12時間後に削除されます。これは私たちが導入したもう一つのコスト削減メカニズムです。 これにより、回答の迅速なクエリが可能になり、新しいEmbeddingモデルへのアップグレードや移行、またはOpenSearchのスケールアップをユーザーのダウンタイムなしで行うことができます。





これがOpenSearchにおける一時的なコンテンツの扱い方です - ドキュメントと対話して次に進むという形で、これは私たちにとって非常に有効でした。 1時間ごとのローリングポリシーも非常に役立っています。 大まかに言うと、これらが主な数値ですが、私たちの現在の規模と新機能の追加により、すでにこれらの数値を超えています。 私たちは数百万のEmbeddingを扱っており、各Embeddingのサイズも相当なものです。 インデックスの数とシャードは地域全体に分散されており、データの分散をサポートできています。



この分散により、必要に応じて異なる地域でのデータレジデンシーもサポートできます。 クリアリングとインデックス作成に必要なスピードのため、かなりの要件があります。 大量のメモリとコンピュートを使用しており、そのように各地域で利用可能なシャードをプロビジョニングしています。 これらのスループット数値は大幅に増加しており、私たちは何度もスケールアップする中で、これらの指標を達成し、さらに超えてきました。常に予想外の問題もなく、良好な経験を得ています。インデックス作成と検索のレイテンシーは管理可能なレベルに保たれており、システムの応答によってドキュメントとの対話体験が損なわれることはありません。
Freshworksの生成AI戦略:OpenSearchを活用した大規模検索システム
皆さん、こんにちは。Sreedhar Gadeです。私はFreshworksでクラウドエンジニアリングを率いる責任者を務めています。これまでOpenSearchという製品自体とドキュメント検索の実装について話してきました。これから10〜12分かけて、Freshworksでのバックグラウンドアーキテクチャと、特に生成AIアプリケーションを使用して顧客体験を変革しようとする中で、OpenSearchが私たちの生成AIストラテジー全体の中心にどのように位置づけられているのか、その実装に関する考え方についてご説明します。


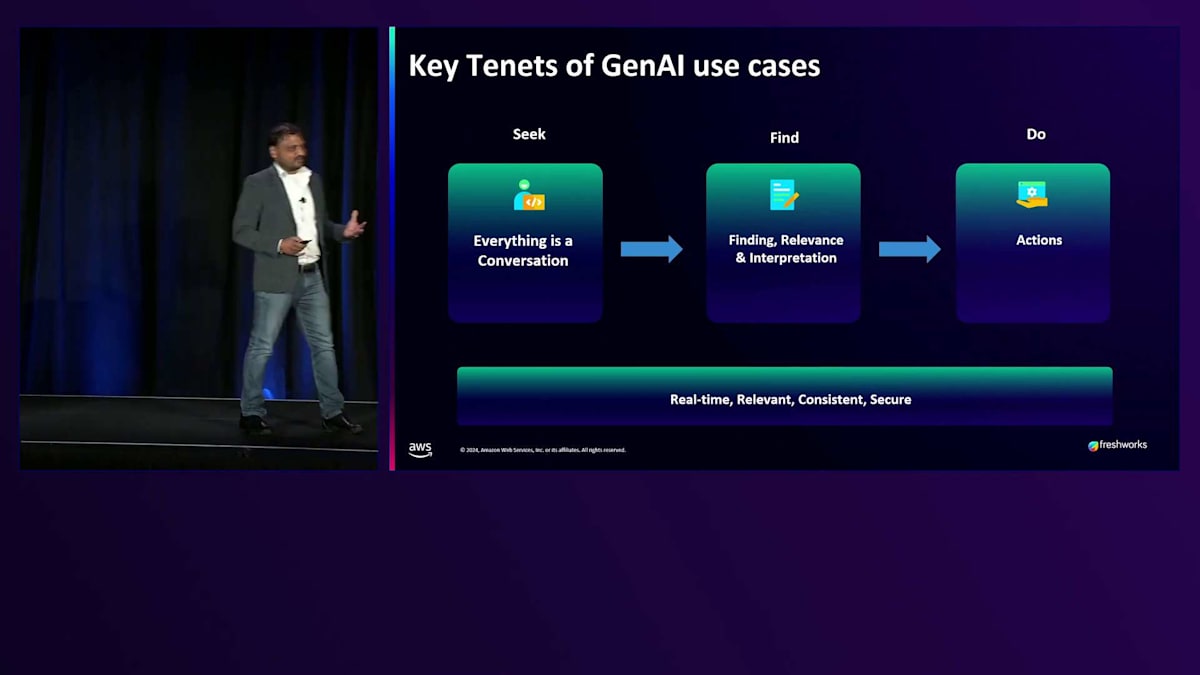
少し哲学的な話をさせていただきたいと思います。というのも、数年後に Generative AI が人間の活動の大半を担うようになった時、私たちは人生や目的について深く考える時間を持つことになるでしょう。歴史的に見て、人類は常に何かを探求し、追い求めてきました。第一段階は目的を探し、意図を見出すことです。そしてそれは、言葉が発明されて以来、常に会話を通じて行われてきました。コンピュータの時代になって、フォームに入力したりチケットを発行したりする話をするようになりましたが、結局のところ、それは会話なのです。探しているものが見つかった後、最も難しいのは「発見」という段階です。 言語の解釈や意図、その他の複雑な要素があり、私たちはそれらを OpenSearch を通じて解決しようとしています。 その後に来るのが「アクション」です。単に物事を見つけるだけでなく、実際に物事を動かして、その結果が満足のいく形で自分に戻ってくるようにしたいのです。これが私たちが考える検索の全体的な哲学であり、私たちの検索プラットフォーム構築の背後にある考え方の全体像を表しています。

Freshworks のアーキテクチャについての興味深い話に入る前に、Freshworks という会社について説明させていただきます。これにより、どのような組織で、どのような課題に直面しているかをご理解いただけると思います。 Freshworks は約14年の歴史があり、約70,000の顧客を抱えています。今後1、2年で10億ドルの売上に到達する見込みです。特筆すべきは、Freshworks がインドで設立され、米国で上場を果たした最初のソフトウェア SaaS プロダクトカンパニーだということです。
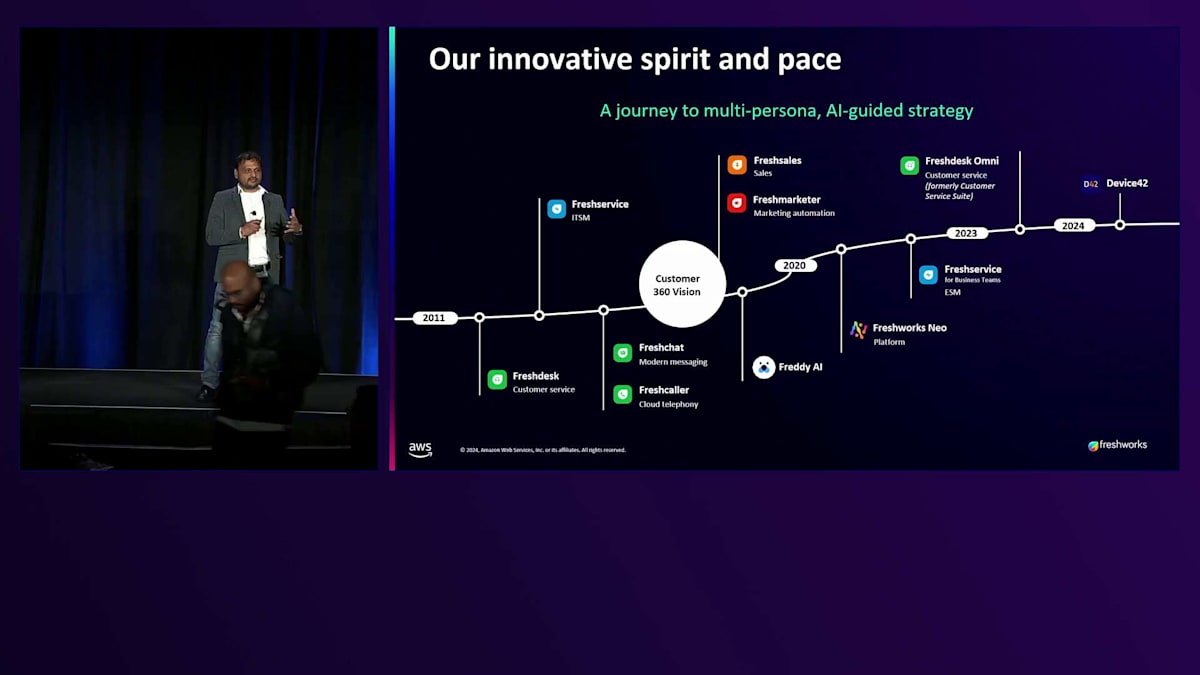
カスタマーエクスペリエンスの分野で単一製品の会社として Freshworks を立ち上げた時から、私たちは長い道のりを歩んできました。ご存知の通り、Generative AI を使って解決しようとしている最大の課題の一つがカスタマーエクスペリエンスです。時間とともに、カスタマーエクスペリエンスを向上させるため、より多くの製品を追加していきました。従業員エクスペリエンス向けの製品も加えました。私たちの Generative AI の取り組みは約6〜7年前の2018年頃に始まり、基本的なモデルの実験や自社データによる ML モデルのトレーニングを開始しました。2年前に GPT の波が来た時、私たちはその波に乗りました。Multi-agent フレームワークや Vector データベース、Action フレームワークの活用において、私たちは競合他社の多くを大きくリードしていると自負しています。では、これまでの課題と、私たちが解決しようとしているユースケースについて簡単に見ていきましょう。


第二部では、全体の配管とフード構造がどのように機能するのか、そのアーキテクチャと戦略についてより深く掘り下げていきます。 また、スケールについても話します。なぜなら Freshworks はスケールに関する全てだからです - 私たちは数兆のメトリクスとペタバイト規模のログを扱っています。 そして最後に、次のステップと機能について締めくくります。

Freshworks のユースケースを見ていきましょう。まず考えられる標準的なユースケースは、レキシカル(語彙的)なものです。歴史的に見て、私たちの全製品のホームページと検索ページは、バックエンドで OpenSearch によって支えられています。なぜなら、私たちは数十億の読み書きを処理しているからです。約120カ国に顧客を持ち、およそ45の異なる言語でサービスを提供しています。このスケールにおいて、レスポンスがリアルタイムで、関連性が高く、予測可能で、そして毎回セキュアであることが求められています。


Generative AIの登場により、私たちはマルチモーダルなデータソースを検証し、Semantic Searchを実装するベクトルの活用にも着手しました。Semantic Searchは、非AIのユースケースでも役立ち始めています。なぜなら、マルチモーダルな側面を統合することで、より良い関連性を実現しやすくなったからです。Observabilityは、Freshworksの戦略の中核です。私たちは、Synthetic監視、インフラストラクチャ、アプリケーションAPMをカバーする、GrafanaとOpenTelemetryベースの社内Observabilityシステムを構築しています。1日あたり約300テラバイトのデータ、約50テラバイトのトレース、そして1日に数兆のメトリクスを収集し、あらゆる段階での顧客行動を把握しています。これらすべてのデータはOpenSearchに送られ、分析されることで、すべてのトリガーが特定され、対処されることを確実にしています。
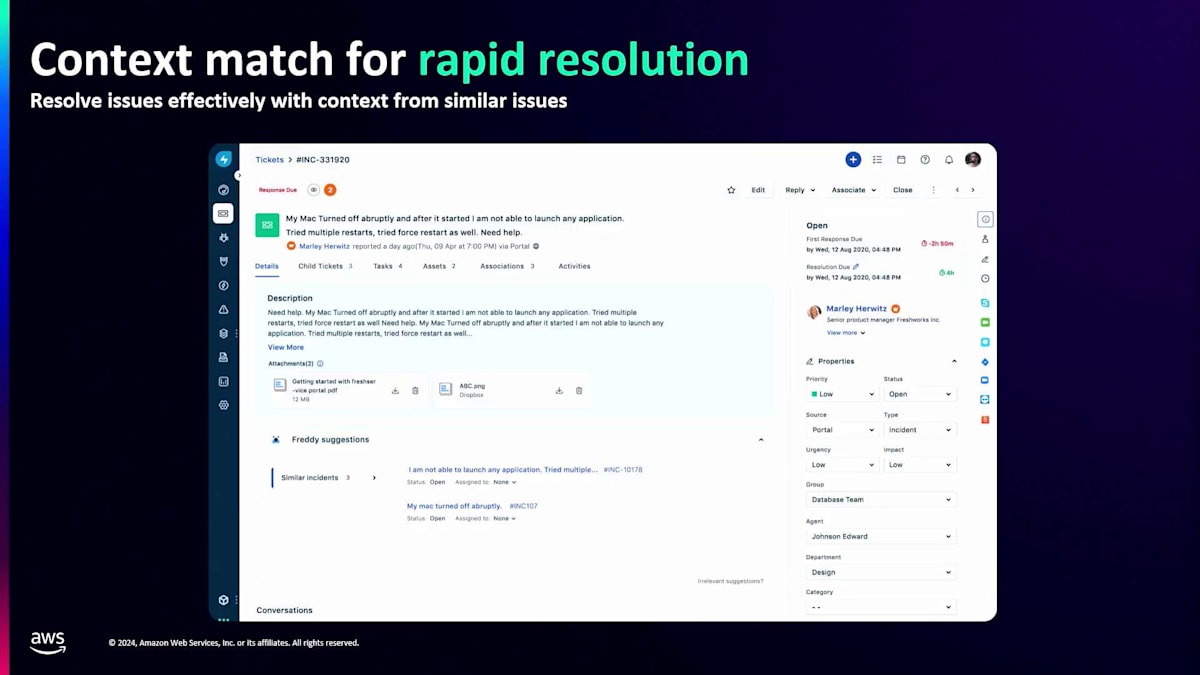
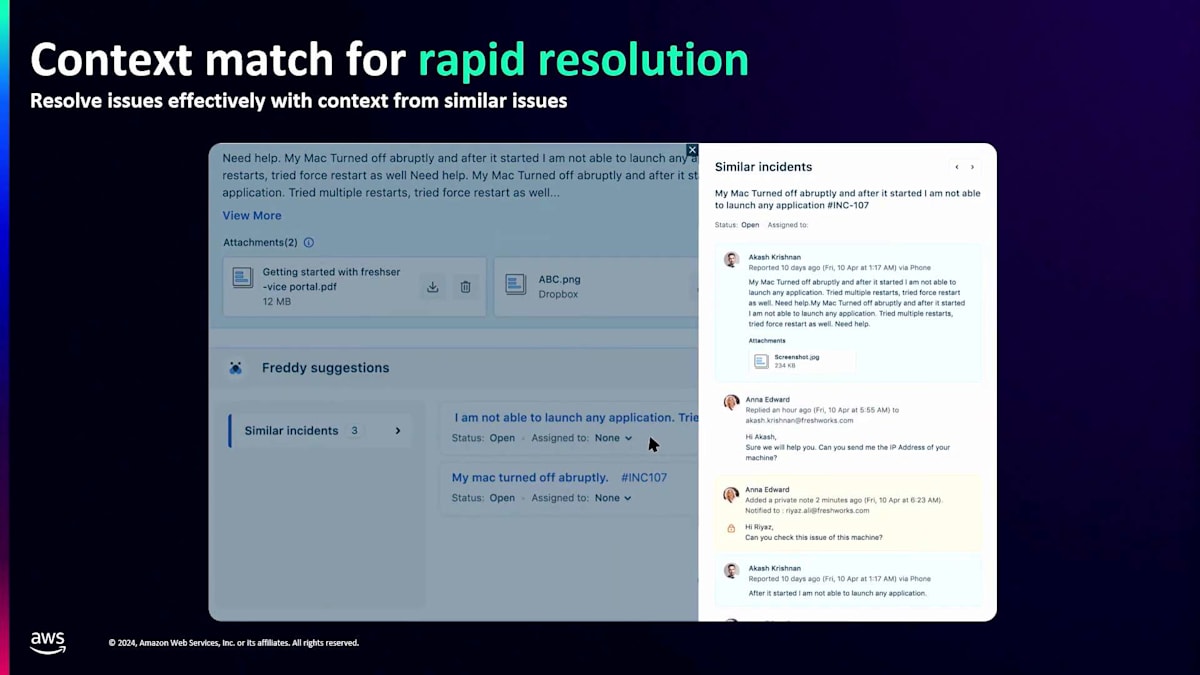
主要な2つのユースケースを詳しく見てみましょう。最初の例は、従業員エクスペリエンス領域のITSMプロダクトであるFreshserviceです。顧客がITの問題やインシデントを抱えた時、チケットを作成します。エージェントは問題解決のためのサポートを必要としますが、常に原因と結果の関係がある中で、顧客は結果の部分しか知らず、必ずしも裏で何が起きているかを理解していません。私たちにとって、特定の原因に対して顧客から10種類もの異なる解釈が寄せられることがあります。Semantic Searchと最近傍探索を使用して、複数の異なる属性を確認し、利用可能な解決策とともに類似度の高い上位3つのインシデントタイプを提案することで、エージェントは迅速に解決できます。これは基本的な例ですが、インシデントの予測、自己修復、さらにはインシデントの予防にまで拡張できます。
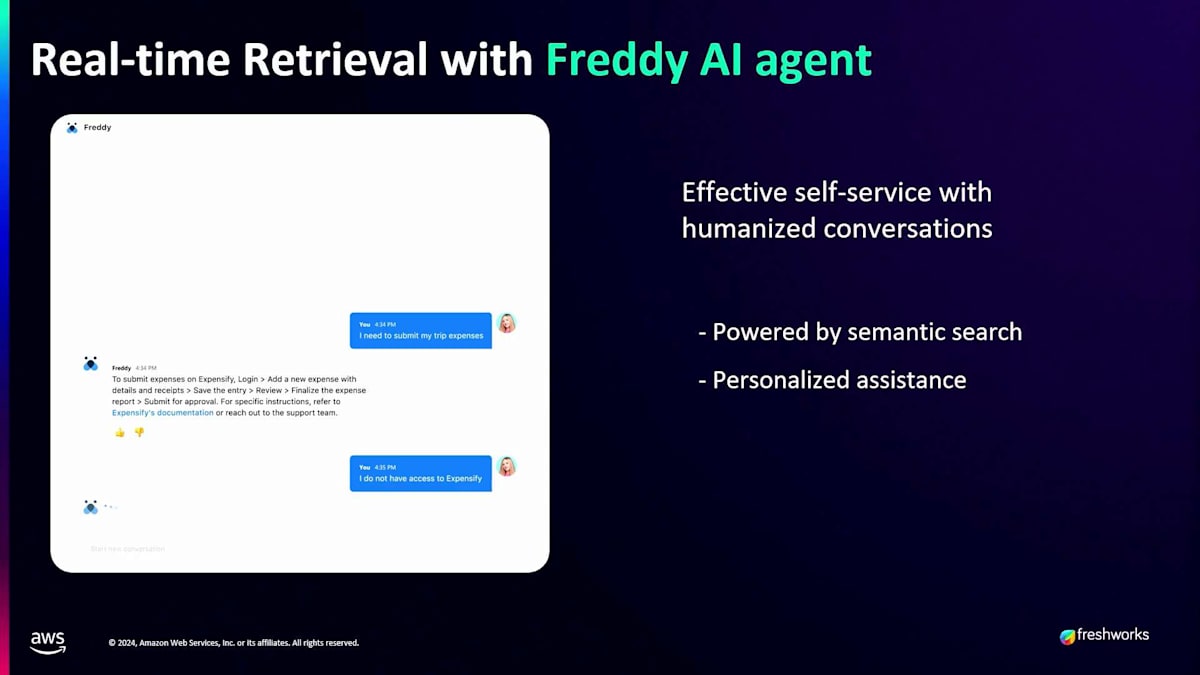

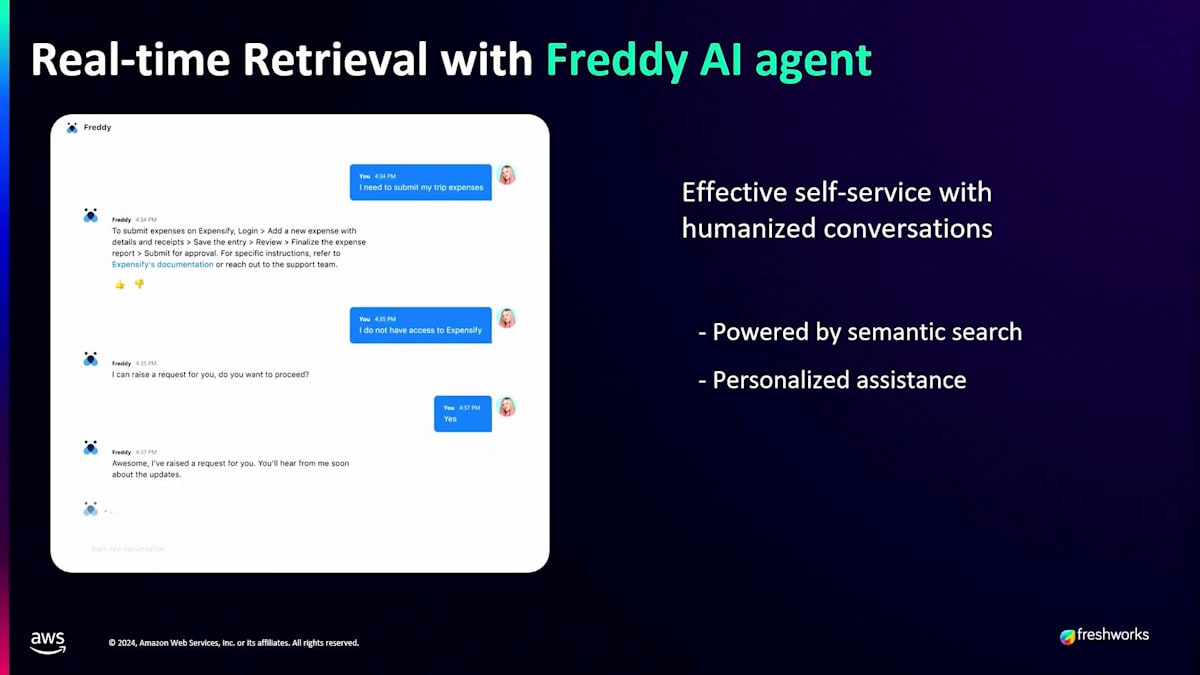

2番目のユースケースはGenerative AIに関するもので、Freshworksでは2つの領域で活用しています。1つ目は、私たちがCopilotと呼んでいるもので、エージェントの経験と知識へのアクセスを支援します。エージェントが勤務を開始し、特定の顧客の状況を理解したい場合、Copilotはその顧客との過去3ヶ月の履歴を分析し、成功に導くための包括的な分析を提供します。2つ目は自律型エージェントで、ユーザーが人間のエージェントではなくボットと対話するセルフサービス体験を提供します。このボットは、カスタマーサービスやIT領域に関するすべての知識を持っています。例えば、誰かが12月20日から1月3日までの休暇を申請するためにWorkdayのようなHRMSにアクセスしたい場合、ボットはWorkdayシステムに接続し、休暇残日数を確認し、休暇申請のアクションを実行するための接続を進める必要があります。
これは単純な例ですが、顧客の視点から見た返金処理や、フライト、ホテル、休暇、乗り継ぎなど、様々な日程を考慮する複雑な旅行予約まで対応可能です。これは将来の話ではなく、現在進行形で実際に行われていることです。これは私たちが実際にこの技術を使って解決している別の領域です。
では、システムの内部で何が起きているのか見てみましょう。私たちが考えている規模について考えてみましょう - 今はまだ50億、10億の収益について話し始めたばかりですが、そこから10倍に成長する可能性があります。すでに120カ国をカバーしていますが、これらの各地域で垂直的に成長したいと考えています。言語サポートが整い、これらすべてを考慮した上で、私たちは将来を見据えて何かを構築することを決めました。そのため、高性能で機能が充実したLuceneを選択しました。選択した理由の1つは、フィルタリングが非常に優れているからです。これは私たちの製品の基本的な機能です。なぜなら、顧客は事前フィルタリングや事後フィルタリングなど、フィルタで多くの異なる属性を扱うからです。


アルゴリズムに関して、 私たちは多層構造を持つHNSWを使用しています。最も近い近傍をすばやく見つけることに重点を置き、精度が一定の割合を超えている限り、精度よりも速度を優先しています。 ご存知の通り、基盤となるアルゴリズムまたは手法としてL2 spaceを使用しています。
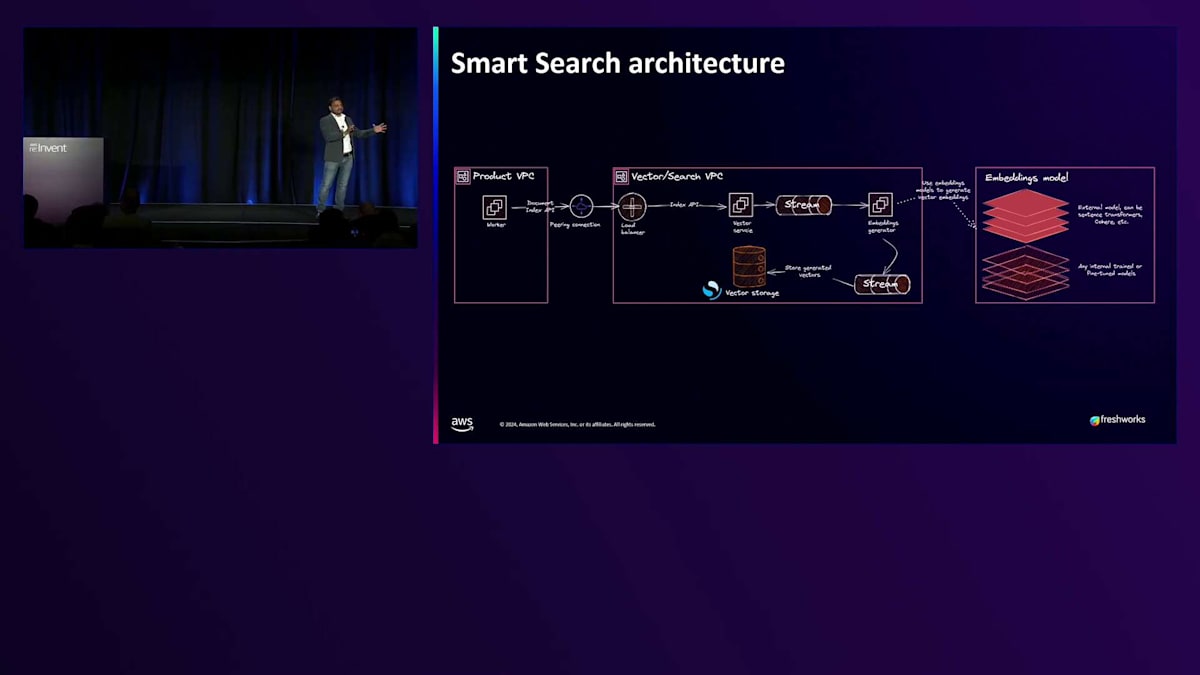
これが社内でのアーキテクチャの考え方です。 私たちはマルチプロダクト、マルチテナントの企業で、各製品には異なるVPC、独自のドメインがあり、通信も完全に異なる方法で行われています。しかし、アーキテクチャに関しては、ある種の集中型アプローチも採用しています。これらはVector Databaseとペアになっており、Vector Databaseにリクエストが届くと、Embedding modelのストリーミング部分にAmazon KISを使用します。複数の製品があるため、同じ手法を全社で使用できるよう、Embeddingの生成を一元化することにしました。これにより、各チームが一から作り直す必要がなくなります。Embeddingは一元的に作成されてストリーミングされ、製品VPCの左側に表示されているものは、Employee ExperienceとCustomer Experienceという2つの製品ラインの10の異なるコンポーネントを持つことができます。
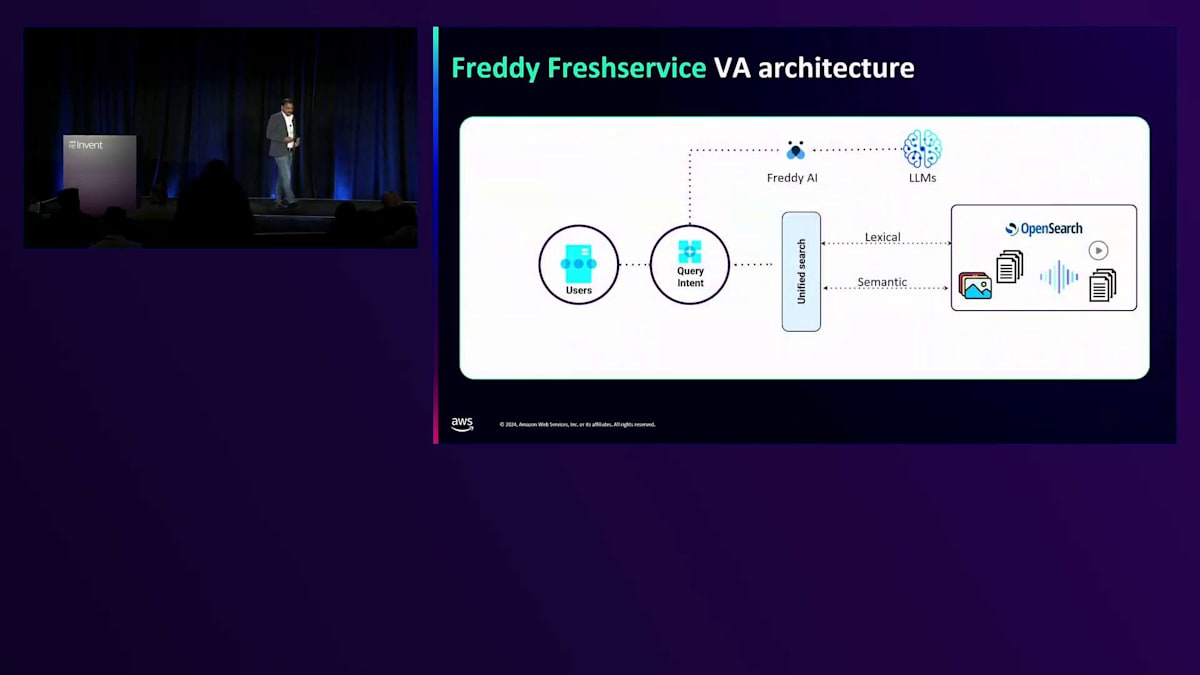
ここで、私たちの業務をより明確に理解していただくために、さらに高い視点から説明させていただきます。ユーザーのクエリは、コンテキストや背景が全くない、非常に会話的な方法で入力されます。ユーザーはまずFreddy AIに送信します。Freddyは、Freshworks内のGenerative AI製品群とプラットフォームのブランドです。Freddyは、私たちが裏で使用しているLLMにそれを送信し、そこからIntentを取得し、Unified Search Broker(ロードバランサー)と呼ばれるものに送ります。Unified Searchは、Lexical検索とSemantic検索を同時に分岐させます。両方からレスポンスが返ってくると、スコアリングに基づいて関連性を確認し、最終的な結果がUnified Search Brokerに返されます。そしてLLMと連携して、同様に会話的な方法で応答するようにします。

これら全ては、私たちが話している規模—数千の顧客が使用している—でミリ秒以下のレイテンシーで実行される必要があります。私たちは約1年前にこの取り組みを開始し、継続的に改善を重ねてきました。PineconeやさまざまなVector Databaseを検討しましたが、特に私たちの成長規模を考慮して、OpenSearchを選択しました。規模に関して言えば、 数十億単位の書き込みと読み取りを扱っており、これはまだ始まったばかりです。私たちは約25億回の読み取りを処理していますが、より重要なのは、OpenSearchで約700のノードを使用していることです。
現在、私たちは毎分約50万のRPMを処理しています。現在、中央データベースには約1,500億のドキュメントがあります。これが私たちの規模です。

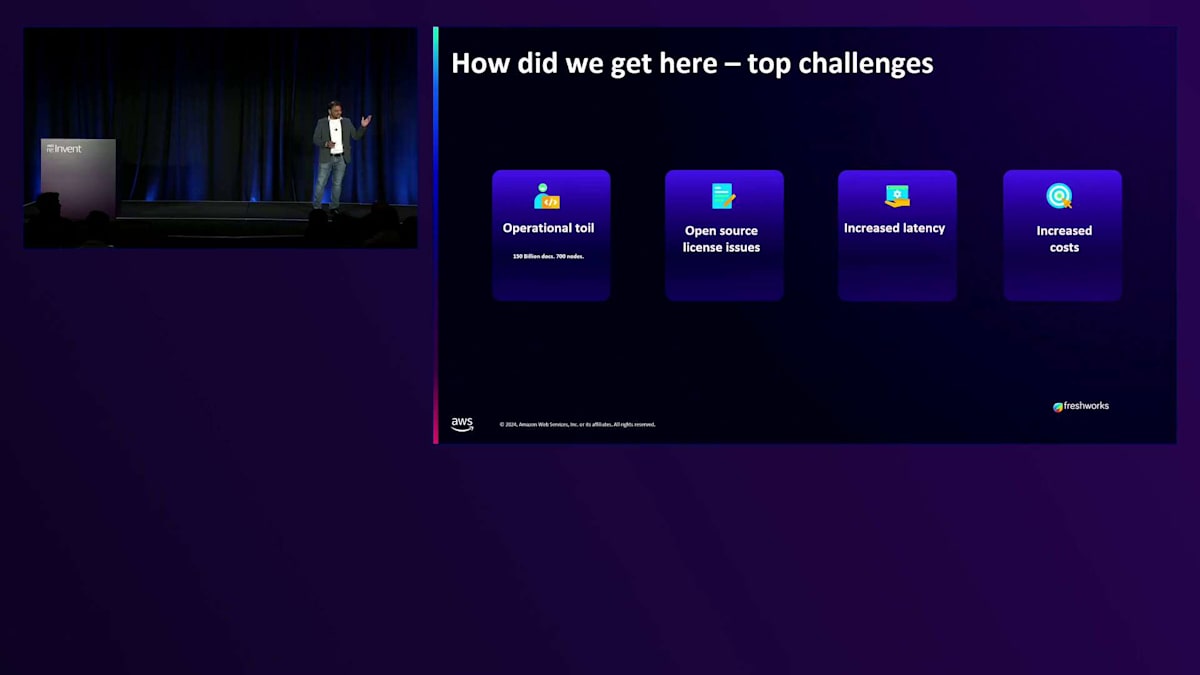
まず、OpenSearchが登場する以前の状況についてお話しします。そうすることで、皆さんがより理解しやすくなると思います。 以前のElasticsolutionから現在に至るまで、全体的な精度と性能、そしてレイテンシーにおいて、少なくとも30%以上の改善を達成しています。こちらが私たちが直面していた問題です - 皆さんの中で、まだElasticsearchを使用している方はいらっしゃいますか?何人かの方が手を挙げていますね。私たちも数年前まで使用していましたが、突然Elasticが商用化を決定し、その時点で行き詰まってしまいました。ライセンスが変更された時、私たちは複数のベンダーとPOCを開始し、どこに賭けるべきかを見極めました。そして、物事が本当にうまく進み始めたのです。


ここで、 OpenSearchに移行した際の様々なメリットをご紹介したいと思います。 レイテンシーが半分に削減され、ノード数も60以上削減することができました。これはAWS上で確実なコスト削減につながります。Searchable Snapshots、Hybrid Search、そしてコスト削減 - 特に現在の経済状況では、誰もが節約を歓迎しますよね。これらすべてが一つのパッケージとして提供され、私たちはこれを次のレベルにスケールアップし続けることを楽しみにしています。

SearchとOpenSearchについて話してきましたので、ここでQRコードをご紹介します。このコードを通じて、ITSMソリューションであるFreshserviceの製品を3ヶ月間無料でお試しいただけます。Freshworksの製品で、Change、Problem、Incident Managementにおける予測、検出、解決に関する私たちのGenerative AIソリューションをすべてお試しいただけます。
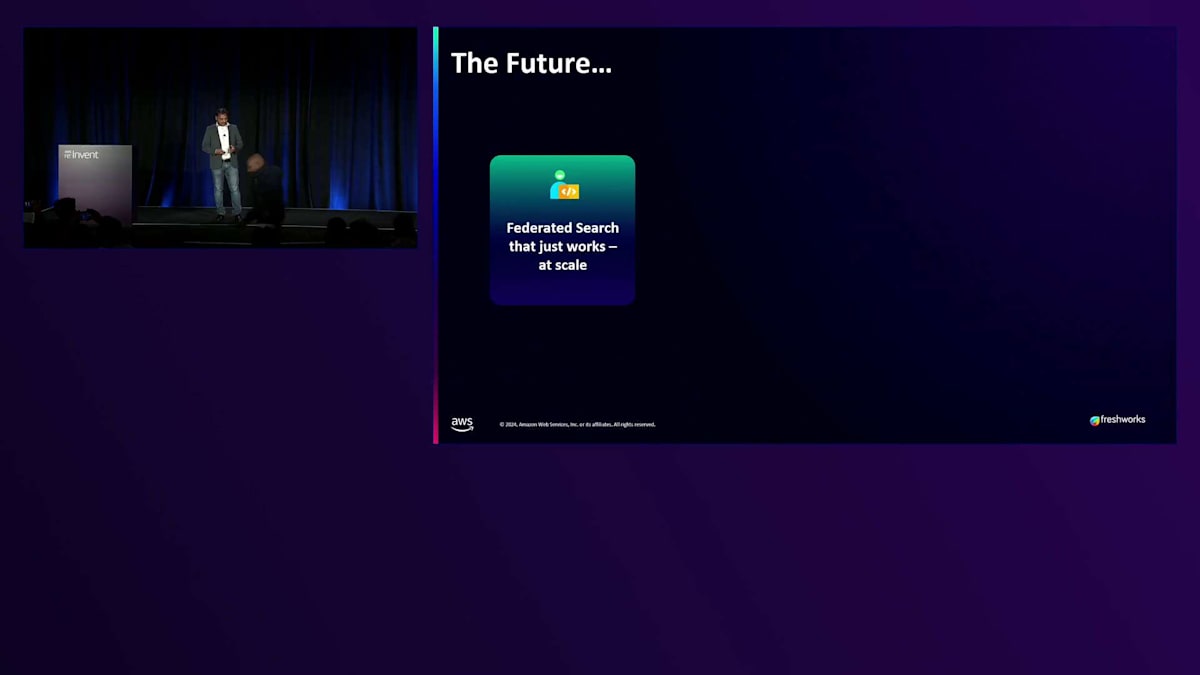
では、これからどこに向かっているのでしょうか?このシナリオを考えてみてください:例えばFreshserviceには10,000の顧客がいて、世界中のこれらの顧客は異なるIDP、異なるドキュメントソースを持っています - Google Drive、OneDrive、SharePointなどを使用している場合もあり、また異なる言語のサポートも必要としています。顧客やユーザーが質問をする際に、これら何千もの異なるデータソースを検索し、リアルタイムで結果を返すことができるようにしたいのです。特に、すべての異なるデータソース間のレイテンシーや統合の課題を予測できない場合、これは非常に困難な問題です。これこそが、私たちがAmazon、Microsoft、そして複数のハイパースケーラーと取り組んでいる課題です。なぜなら、クエリに対する回答の質は、利用可能なデータソースの質に直接依存するからです。
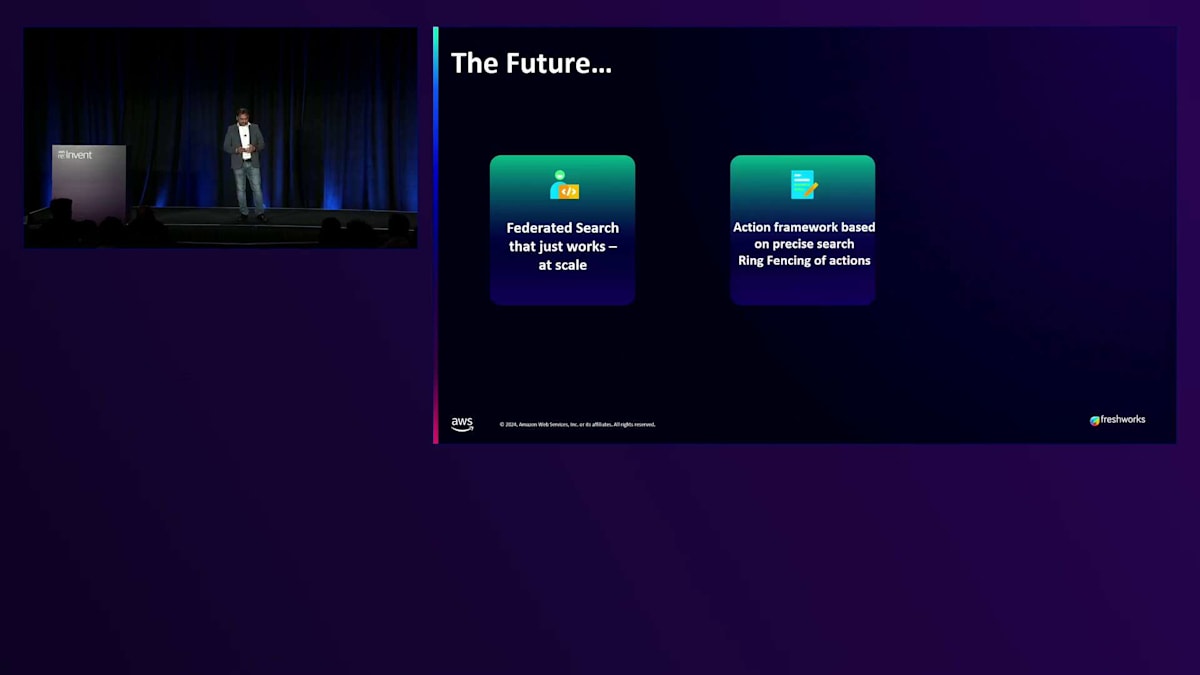
次はAction Frameworkです。誰もがRetrievalについて話します - Searchはその部分で素晴らしい仕事をしています。私たちは連携された情報源からデータを収集し、それらをリアルタイムで統合して、ユーザーにはその情報をどこから取得したのかを意識させないようにしています。しかし、Actionについてはどうでしょうか?今年はAction Frameworksの年でしたが、安全で確実な方法でActionを実行する必要があります。銀行のアプリケーションや旅行アプリケーションで、Actionが間違って実行され、間違った日付のフライトやホテルを予約してしまうことを想像してみてください。これは十分に起こり得ることであり、だからこそ安全なActionとガードレールが非常に重要なのです。
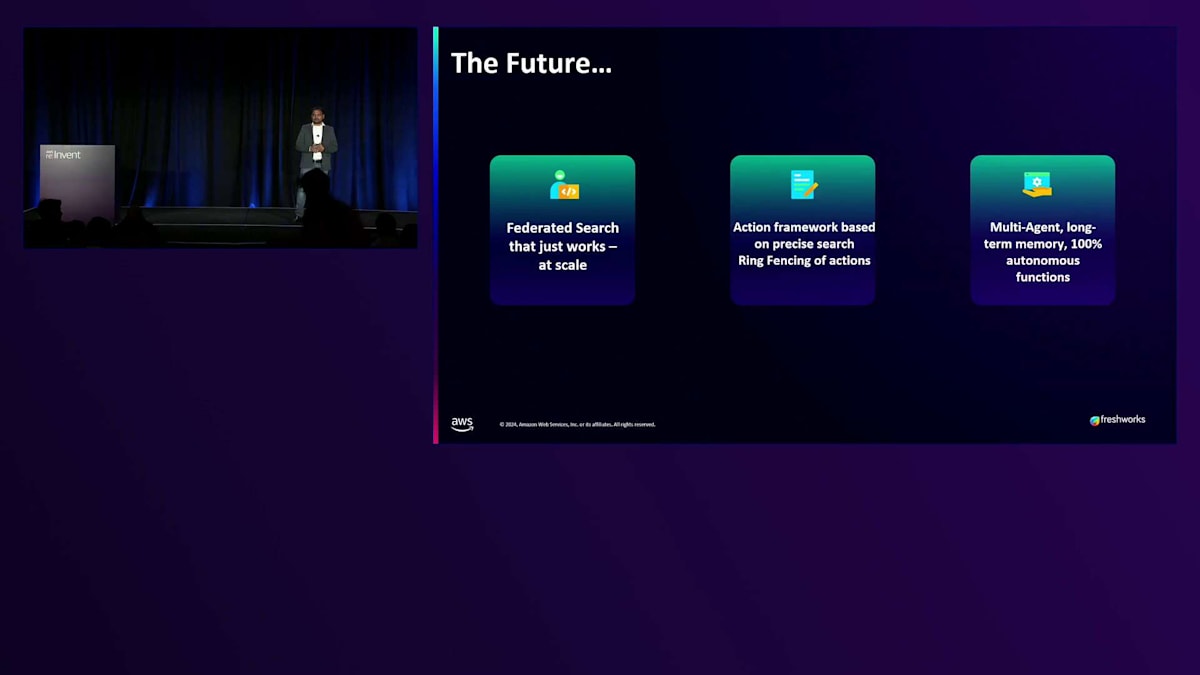
最後になりますが、2日前、Swamiがキーノートの舞台に立ち、複数の会場にまたがるre:Inventでの無料の食事を探すための複数エージェントについて実演を行いました。5つのエージェントが連携して働き、無料の食事を探すという目的を伝えると、彼らが解決策を見つけ出し、予約までしてくれるのです。これはまさに私たちが製品で構築しているものと同じで、10個のエージェントがあったとしても、目的を共有するだけで、彼らが1つのチームとして連携し、必要な解決策を提供してくれます。これが、Freshworksのストーリーとしてお伝えしたかったことです。素晴らしい聴衆の皆様に感謝いたします。それでは、Jonにバトンを渡したいと思います。
Generative AIとSemantic Searchが変える情報とのやり取り

基本的な検索の話に戻りますと、今日お話しした2つのワークロード - 長文のドキュメントとやり取りし、質問をして情報を出典と共に取得できる機能 - これが現在私たちが目にする中核的なワークロードの1つとなっています。

2つ目のワークロードは、Freshworksが示したようなチャットとヘルパーアシスタントです。今日では、より会話的になってきており、これらは検索が文字列の一致よりも意味に重点を置いている例です。ドキュメントの関連部分の特定、サポート担当者向けの支援、適切な製品の購入 - これらの領域で、Generative AIとSemantic Searchが重要な役割を果たしています。すべては、情報とのやり取りに意味をもたらすAIモデルによって改善されています。以上で私の発表を終わります。本日はご参加いただき、誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion