re:Invent 2023: Amazon TextractとCenteneが語るAIドキュメント処理の革新
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Enhance your document workflows with generative AI (AIM213)
この動画では、Amazon TextractチームのNavneethとCenteneのRoshaが、AIを活用したドキュメント処理の革新について語ります。従来の手作業やOCRの限界を超え、Amazon TextractやAWS Bedrockを用いた最新のインテリジェントドキュメント処理システムの構築方法を紹介します。Centeneの事例では、処理時間の93%短縮や99%以上の精度を達成。さらに、ヘルスケア分野におけるgenerative AIの可能性と課題にも踏み込みます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
Amazon Textractによるドキュメント処理の革新

ドキュメント処理は、従来、時間がかかり、高コストで、非常にエラーが発生しやすいプロセスでした。本日は、AIを、特にgenerative AIを使用して、ドキュメント処理のワークフローをどのように強化できるかについてお話しします。私はAmazon TextractチームのプロダクトマネージャーのNavneethです。今日は、CenteneのMachine Learning DirectorであるRoshaも同席しています。後ほど、CenteneがAIを使用してドキュメント処理のワークフローをどのように革新したかについて彼女からお話があります。それでは始めましょう。

なぜドキュメント処理はこれほど面倒なのでしょうか?これを理解するには、お客様が従来どのようにドキュメント処理を行ってきたかを知る必要があります。私たちは、お客様がドキュメント処理に対処する3つのテーマまたは方法を見出しました。多くのお客様は依然として手作業のプロセスに依存しており、これは非常に労働集約的で、人的要素のために、エラーが発生しやすく、高コストで面倒です。お客様はすでに何十年も前からあるOCRなどのレガシー技術を使用してドキュメントから生のテキストを抽出しています。しかし、この技術には一定の制限があります。ドキュメントから生のテキストのみを抽出し、構造のすべての要素を取り除いてしまうため、テキストやドキュメントから洞察を得て、ビジネス上の意思決定に簡単に利用することができません。
第三に、一部のお客様はOCRなどの技術とカスタムの後処理コードを組み合わせて、ドキュメントから洞察を得ています。このコードはルールベースですが、後処理コードのルールベースの性質により、スケーラビリティがありません。ドキュメントは様々な構造やレイアウトで存在し、これらのバリエーションすべてをカバーするルールベースの後処理コードを書くことはほぼ不可能です。これは何を意味するのでしょうか?単純なローン申請書や請求書パッケージの処理でさえ、数時間から数日かかる可能性があり、誰もそんな時間はありません。また、純粋にドキュメント処理のために何百万ドルもの運用コストがかかることを意味します。


先ほど述べたように、ドキュメント処理は面倒で、何百万ドルものコストがかかる可能性があります。これは特定の業界に限った問題ではありません。金融サービスからヘルスケア、ライフサイエンス、公共部門まで、ドキュメントはこれらの業界すべての生命線であり、ビジネスプロセスの中核です。そして、私たちが聞いているのは、業界を超えてお客様が共通の課題に直面しているということです。
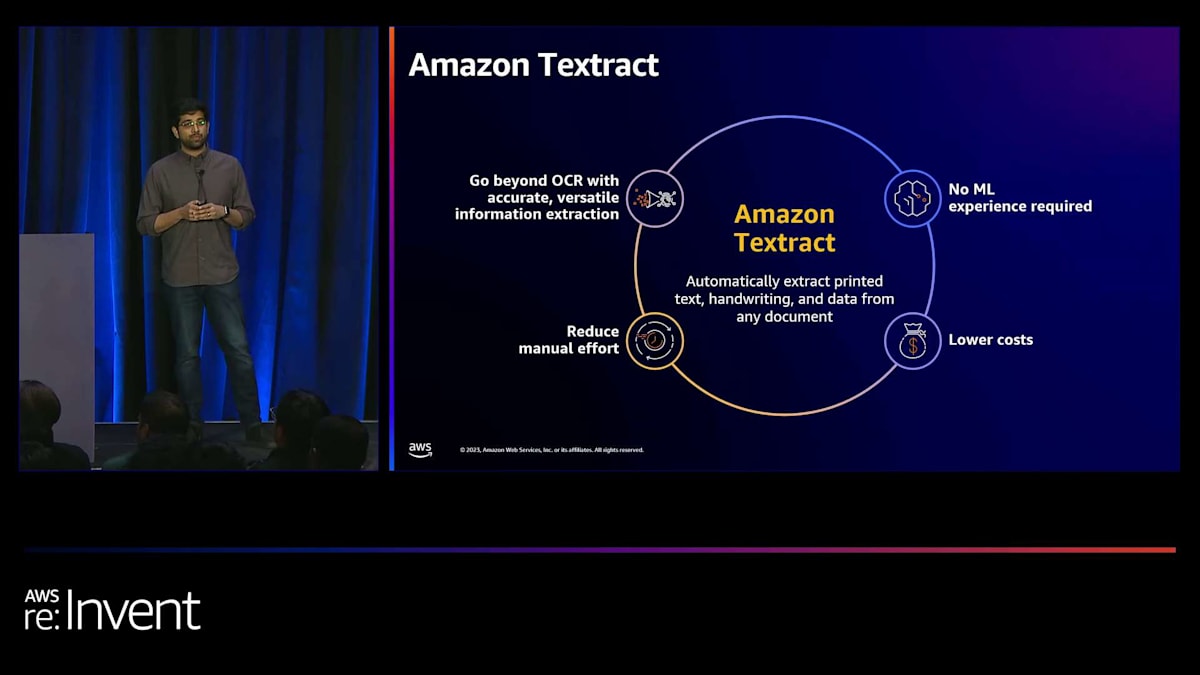
ここでAmazon Textractの登場です。Amazon Textractは機械学習サービスで、事実上あらゆるドキュメントから印刷されたテキスト、構造化データ、手書き文字を抽出するのに役立ちます。これは、先ほど話した課題にどのように対処するのでしょうか?まず、Textractは単純なOCRを超えて、表形式の情報やキーバリューペアなどの構造化された情報をドキュメントから実際に抽出し、直接洞察に活用できるようにします。これは、コンピュータビジョン、NLP、その他のML技術の組み合わせを使用して行いますが、完全に裏側で行われるため、お客様はこれらの技術を使用する専門知識や経験を必要としません。Textractが提供する複数のグローバルに利用可能な完全管理型APIの1つと統合するだけです。そして、これはドキュメント処理に関してコストの削減と手作業の軽減につながります。
Amazon Textractの主要機能と活用事例

その背景を踏まえて、Amazon Textractが提供するいくつかの主要な機能と、AWSが提供する他のIDPサービスについてお話ししたいと思います。このスライドには多くの機能や特徴が記載されていますが、そのうち3つか4つに焦点を当てたいと思います。まず最初に、先ほども申し上げたように、TextractはOCRを超えたものです。構造化された情報を抽出するのに役立つ特定の機能があります。その最初の機能が、Tablesです。ほとんどの文書には、表形式の情報が含まれています。財務文書や、皆さんが見たことのある検査報告書などを思い浮かべてください。そこには多くの表形式の情報があります。その構造が表であることを認識し、抽出するのが、私たちのTables機能です。
Formsは、キーと値のペアとして構造化された情報を自動的に認識する機能です。IDカードや、実際にある任意のフォームを見てみると、通常、顧客名のようなキーがあり、その後に実際に記入する値があります。これがキーと値のペアであることを認識し、抽出するのが、私たちのForms機能です。最近では、先月のことですが、Layout Detectionという新機能をリリースしました。Layout Detectionは、ヘッダー、タイトル、フッターなどの構造要素を抽出する機能で、
文書をより詳細に分析し、その情報を下流の処理に活用するのに役立ちます。もう一つ注目したい機能は、昨年リリースされたqueries機能です。これは実際に顧客に人気の機能です。なぜなら、queriesは自然言語で質問し、必要な情報を必要な形式で正確に抽出する機能を提供するからです。必要な情報に関するコンテキストを提供し、ほぼ文書とチャットして特定の質問をすることができます。
今年、私たちはqueriesをさらに進化させました。先月、Custom Queriesという新機能をリリースしました。これにより、お客様は完全にセルフサービスで、わずか5つのサンプル文書を使用して、queries機能の出力をカスタマイズできるようになりました。この講義の最後には、これらの機能を詳しく見て、すぐに始められるようにするためのリンクがいくつか記載されたスライドがあります。
Generative AIとAmazon Textractの統合

こちらは、Amazon Textractの公開リファレンスとなっているお客様の一部です。これらは、すでにTextractを使用してドキュメント処理ワークフローを自動化しているお客様です。これは網羅的なリストではなく、あくまで代表的なものであり、スライドに収まる範囲のものです。ここで強調したいポイントは、これらのお客様が多様な業界から来ているということです。つまり、この製品やサービスは特定の業界に限定されるものではなく、さまざまな業界の課題に対応できるということです。

では、少し視点を変えてみましょう。これまで、ドキュメント処理の課題や、それらの課題に対応する既存のAIサービスについて話してきました。しかし、generative AIは文字通りあらゆる分野を変革しています。generative AIとIDPがどのように連携するかについて詳しく見ていく前に、generative AIが注目される理由について話しましょう。大まかに言えば、お客様がgenerative AIに関して特に興奮している特徴が3つか4つあります。
まず第一に、膨大な量の非構造化データで事前学習されているため、さまざまな文脈の問題を解決する能力があります。第二に、これらのモデルとパラメータの規模が大きいため、従来のAIモデルよりも複雑なタスクを自動化できます。第三に、学習に使用された膨大なデータの文脈とモデルの規模により、より優れた汎化能力を持ち、これまでは不可能だった長尾の使用例やドキュメントの処理が可能になりました。最後に、お客様は、これらの大規模モデルがもたらすカスタマイズ機能に非常に興奮しています。わずかなデータで、この大規模モデルを特定の使用例に合わせてカスタマイズし、高い精度を達成することができるのです。
Generative AIを活用したドキュメント処理の実装例

では、生成AIはドキュメント処理にどのように適合するのでしょうか?私たちが発見したのは、生成AIはAI機能に関して補完的で強化的な性質を持っているということです。従来、お客様はすでにAIを採用してドキュメントを自動化する道を歩んでいました。例えば、フォームのフィールド値や表の構造要素を抽出するためにAIを使用しています。特定の自然言語クエリを使ってドキュメントとチャットし、情報を抽出するのにも使われています。これらのモデルが提供する信頼度スコアを使って、人間を介在させるプロセスを最適化しています。さらには、ドキュメントの分類や、ドキュメントから特定のビジネスエンティティを見つけ出すところまで行っています。
しかし、生成AIはこれを補完し、その上に層を追加することで、お客様に新しいユースケースを解放しています。特定の情報を抽出するだけでなく、これらの大規模モデルを使用して情報を正規化し、変換して、実際にダウンストリームのデータベースやシステムに合わせて情報を保存したり利用したりすることができるようになりました。Q&Aを通じて非常に具体的な抽出的な質問をするだけでなく、モデルにドキュメントを短い段落や数行の形で要約させたり、データに対して複雑な推論タスクを実行したりするなど、より複雑なタスクを行うことができるようになりました。
人間を介在させるプロセスで信頼度スコアを使用するだけでなく、ドキュメントが期限切れかどうかを自動的にチェックしたり、特定のフィールドがカスタムビジネスフォーマットに一致するかどうかを自動的にチェックしたりするなど、スマートな検証を追加することができます。例えば、SSNが8桁形式であることは許可されるべきではありません。最後に、これらの生成AIモデルの汎用性により、既存のモデルでは一般化して情報を抽出できなかったために、これまでオンボーディングできなかったロングテールの非常にビジネス固有のドキュメントを処理することができるようになりました。

これらの機能を基に、実践的な実装を探ってみましょう。より詳細な情報をお求めの方のために、これはAWS Intelligent Document Processing (IDP)サービスと、Bedrockサービスを通じて利用可能な大規模言語モデルの一部を使用して、これらのユースケースを自動化する方法を今すぐ始められるサンプルアーキテクチャです。このアーキテクチャは、左から右に3つの明確なステップに分かれています。最初のステップでは、Amazon Textractを使用して情報を抽出し、ドキュメントを分類します。このステップは重要です。なぜなら、大規模言語モデルはテキストを入力として必要とし、OCRや生のテキスト抽出がここで行われるからです。また、通常このステップでドキュメントを分類したいと思います。なぜなら、ドキュメントタイプを知ることで、必要なタスクを実行するために大規模言語モデルに特定のプロンプトを調整するのに役立つからです。
この最初のステップを経た後、2番目のステップである主要なワークハブステップに移ります。ここでは、これらのモデルを使用して実際に情報を抽出し、正規化し、要約などの高度なタスクを実行します。ここでは、既存のサービスをそのまま使用するか、そのデータをAWS Bedrockにチャネリングして、Bedrockサービスを通じて利用可能なLLMのいずれかを使用することができます。最後に、この2番目のデータ抽出と強化のステップが完了したら、人間を介在させるプロセスを追加して、これらのモデルの出力を検証し、必要な精度が得られていることを確認してから、下流のアプリケーションに送信することができます。
Amazon Textractを用いたドキュメント処理のデモンストレーション
では、デモビデオをお見せしましょう。このデモでは、ドキュメントを処理するためのシンプルなアーキテクチャを設定しています。このドキュメントに対して3つのことを行います。まず、どのような種類のドキュメントかを理解し、大まかに分類します。次に、特定の情報を抽出し、さらに目的の形式に正規化します。最後に、large language modelを使用して要約などの高度なユースケースを実装します。


デモで処理するドキュメントは、このような収入明細書、一般的にはpay stubと呼ばれるものです。これは誰もが使用し、おそらく馴染みのあるものです。事前に知ることなく、これが実際にpay stubであることを特定したいと思います。モデルにそれを識別させたいのです。また、赤い枠で囲まれた特定の情報を抽出したいと思います。そこには収入の表と総支給額が表示されています。これらを識別するだけでなく、 このドキュメントを2行の文章で要約し、誰もが知りたいと思う重要な情報をすべて含めたいと思います。

これを実装するために、Step Function Workflowを設定しました。次にそれをお見せします。 Step Function Workflowにはいくつかのステップがあり、順を追って説明します。最初のステップは実際にはdocument splitterステップです。ここでのポイントは、複数ページのドキュメントを個々のページに分割し、次のステップで見られるAmazon Textract Sync APIに送信することです。ここでのAmazon Textract Sync APIの目的は、アーキテクチャの最初のステップである、ドキュメントからの生のテキスト抽出を行うことです。抽出された生のテキストは保存できます。ここでは、その生のテキストをお見せします。これをテキストファイルにコピーしただけです。これがpay stubのドキュメントに表示されている正確な生のテキストです。
これが完了すると、並列で2つの分岐を実行します。左側の分岐では、この情報をAmazon OpenSearchにインデックス化します。これは単なるインデックス化なので、ここでは詳しく説明しません。私が注目したいのは右側の分岐で、ここで実際に分類の2つのステップを実装します。分類後には、特定の抽出と強化のステップが実装されています。これらの分類と強化のステップはすべて、Amazon Bedrockサービスとその下にあるLLMによって駆動されています。これらのモデルには、お見せした抽出したテキストだけでなく、この分類と抽出タスクを実現するための特定のプロンプトが必要です。

これらのプロンプトは実際にはDynamoDBテーブルに保存されています。基本的に、ワークフローはステップに基づいてプロンプトを選択し、特定のモデルを呼び出してそれを入力として送信します。ここでDynamoDBテーブルをお見せしますが、分類用のプロンプト、pay stub用のプロンプト、銀行取引明細書用のプロンプトなど、実際に入力したものが表示されています。これらがStep Flowで使用したものです。

それでは、これらの手順を一つずつ説明し、各ステップがどのように影響を与え、中間出力を生成するかをお見せします。
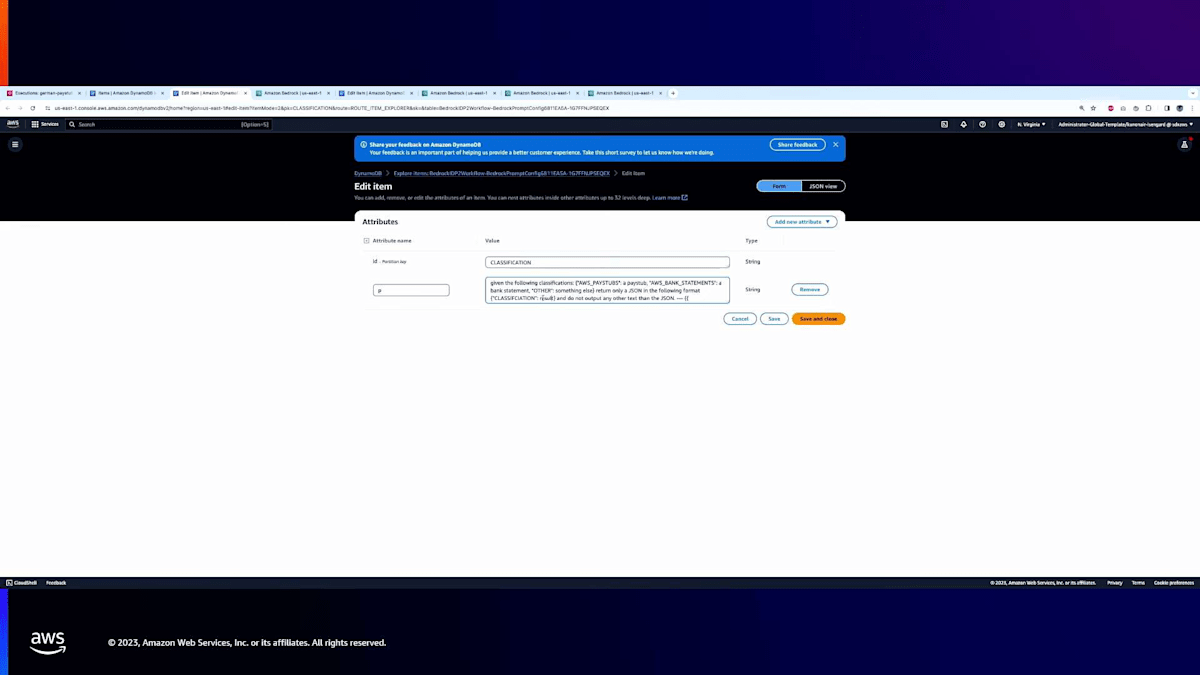
まず、分類ステップから始めましょう。私はプロンプトを作成しました。このプロンプトは、モデルに3つの文書タイプ(銀行明細書、給与明細書、またはその他)から選択させ、JSONフォーマットで返すように指示しています。キーは「classification」で、結果は希望する結果となります。これを実演するために、Bedrock Playgroundを使用します。このツールでプロンプトの動作を示すことができます。プロンプトをこちらにコピーします。Bedrock Playgroundに貼り付けると、分類を要求する同じプロンプトが表示されます。最後に、文書テキストを提供する場所があります。そこでテキストファイルから文書テキストをコピーし、ここに貼り付けて「Run」をクリックします。これは実行中ですが、Step Function Workflowで起こるのとまったく同じプロセスです。ただ、ビジュアル形式で示しているだけです。

ご覧のように、Bedrockモデルはそのプロンプトを受け取り、分類を識別することができます。これはAWSの給与明細書です。ここで素晴らしいのは、文書を見ると「pay stub」や「AWS」という言葉がどこにも記載されていないことです。特定のタイプに一致するよう指示しただけで、収入が基本的に給与明細書を示すことを自動的に理解できています。
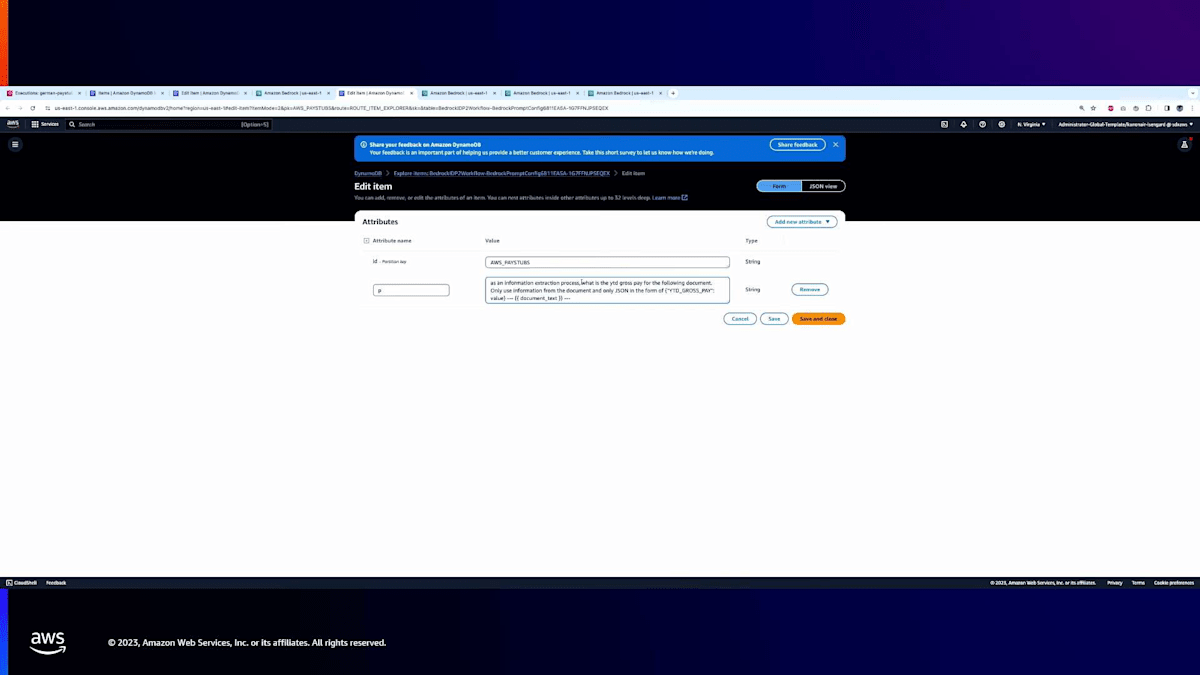

次のステップに進みましょう。給与明細書であることがわかったので、実際にいくつかの情報を抽出してみます。ここに抽出用のプロンプトがあり、文書から総給与、特に年初来の総給与を抽出したいと思います。同じように、このプロンプトをコピーしてBedrock Playgroundに移します。ご覧のとおり、YTD総給与を求める同じプロンプトです。具体的に「YTD_Gross_Pay」というキー名を探していて、その値を埋めるよう指示しています。文書テキストを入力します。実行すると、ご覧のように「YTD_Gross_Pay」とそれに関連する値が表示されます。

下の赤い枠を見ると、「gross pay」という行があり、列の上部に「year-to-date」があります。1億3400万ほどの総給与の値を三角測量しています。これはとても興味深いですね。YTDがこの場合「year-to-date」と同じであることを理解し、その値を抽出できているのです。
では、上にある収入表を抽出してみましょう。これについても、すでに抽出に役立つプロンプトを用意しています。Bedrock Playgroundに移動します。ご覧のように、このドキュメントに対して、収入表を取得するプロンプトがありますが、特定の2つの列、つまり収入の説明とYTD支払いのみをCSV形式で取得するようにしています。CSVだけが欲しいので、LLMが通常提供する説明やその他のテキストは不要です。非常に厳密な形式を指定しているわけです。ドキュメントのテキストを再度入力して実行します。

値が入力され始めるのがわかります。収入の説明の列があり、そしてYTD支払いの列があります。そして、通常の収入、ウェルネス、AWDなどの項目を拾い出すことができています。これら2つの情報を抽出できるのは、かなり素晴らしいですね。
最後のステップである要約に移りましょう。ここでは要約を生成するよう依頼し、「主要な情報、つまり総支給額、純支給額、控除額、この給与明細が生成された日付、およびその他の重要な情報を探しています」と指示します。実際に実行してみましょう。ご覧のように、モデルは非常に簡潔な要約を提供することができました。総支給額はいくら、純支給額はいくら、控除額はいくらと述べています。また、給与明細の期間の開始日と終了日、さらには連邦税や401(k)の拠出額などの情報も提供しています。


これが正確かどうか確認してみましょう。ご覧のように、総支給額については6,300ドルであることを突き止めています。純支給額は4,405ドルを抽出しています。控除額は実際にはこのドキュメントに存在する正確なフィールドではありません。6,300から4,405を引いた計算結果であり、自動的にその計算を行って控除額の値を提供しています。つまり、ここでは単なる抽出を超えて計算まで行っているのです。また、給与期間を見つけ出し、関心のある具体的な連邦税と社会保障税を特定しています。
要するに、私が行ったのは、ドキュメントを入力し、AWS Bedrockを使用して給与明細書に対する分類、抽出、要約などのさまざまなタスクを実行できることを実証したということです。

私は文書の種類を特定しました。非常に具体的な情報を抽出し、generative AIモデルを使って、その上に知性を加えることで、非常に簡潔な要約と具体的なデータポイントを生成しました。これは、generative AIの最新の進歩がなければ実現できなかったことです。お客様はこれを即座に活用して、さまざまなビジネスワークフローを強化しています。

次に、マイクをRoshaに渡します。Roshaは、CenteneがAIを使って文書処理ワークフローをどのように革新しているかについて話します。
Centeneのマシンラーニングディレクター、Rosha Pokharel氏の紹介
ありがとう、Nav。皆さん、こんにちは。Rosha Pokharel(ロシャ・ポカレル)と申します。Centene CorporationのマシンラーニングおよびAIディレクターを務めています。ここに来られてとてもワクワクしています。素晴らしい聴衆の皆さんですね!今日は、CenteneにおけるAIとマシンラーニング、そして私たちの取り組みについて、そしてAWSのさまざまなAIサービスやその他のサービスを活用して、CenteneでのAIの進展をどのように加速させたかについてお話しします。
その前に、会場の皆さんに簡単なアンケートを取らせていただきます。ヘルスケア業界の方はどのくらいいらっしゃいますか?素晴らしい。データサイエンティスト、マシンラーニングエンジニア、クラウドエンジニア、実務者の方は?素晴らしい。そして、経営幹部の方は会場にいらっしゃいますか?素晴らしい。
このセッションでは、3つの主要なポイントについてお話しします。最初のポイントは、ヘルスケア業界における文書の取り込み処理システムの自動化に関して、現在存在する大きな機会についてです。これはCenteneに限ったことではありません。2つ目のポイントは、Centeneに入ってくる文書の自動化においてAIの進展を加速させるために使用した戦略についてです。1年間で発表した2つの主要製品について、それらがプロバイダーとメンバーのエクスペリエンスを大幅に向上させていることをお話しします。
3つ目のポイントは、generative AIについてです。当然、このバズワードについて触れないわけにはいきませんよね。Centeneだけでなく、ヘルスケア業界全体でのgenerative AIの将来性について、そして私たち自身がどのようにgenerative AIを使用すべきか、またヘルスケアで使用する際にどのような注意が必要かについて、私の考えをお話しします。
Centeneの概要とヘルスケア業界における文書処理の課題

まず、Centeneをご紹介しましょう。私たちは、地域社会の健康を一人ひとり変革しています。それを可能にしているのは、米国最大のMedicaid管理ケア組織の一つであることです。米国の約15人に1人に、手頃な価格で質の高い製品を提供しています。これはすごいことですよね。ここで、当社のいくつかの興味深い統計をご紹介します。私たちはFortune 25の企業の一つです。従業員数も非常に多く、現在67,800人を数えます。大規模な収益を上げており、2022年のプレミアムとサービス収益は1,385億ドルでした。Centeneについては他にも興味深い統計がありますが、私たちは会員やプロバイダーの体験に大きな影響を与えることができるのです。

ここで少し話を戻しましょう。まず、私の信頼性を確立したいと思います。これから話すことが全くの嘘ではないことをご理解いただくためです。私のAIと機械学習の旅は約13年前に始まりました。University of Floridaで機械学習に焦点を当てたPhDを取得することを決意し、ニューラルネットワークが主要なトピックの一つでした。私は教育指導型機械学習アルゴリズムとカーネル法に焦点を当てた論文で卒業しました。
その後、アカデミアを離れ、データサイエンティストとして業界に入ることを決めました。当時、これは最もセクシーな職業の一つでしたが、データサイエンティストが具体的に何をすべきかは誰も正確には知りませんでした。
私はWeather Companyでキャリアをスタートし、その後IBMに買収されました。そこで、IBM Watson製品に携わり、いくつかのAI製品をリリースする機会を得ました。その中には今でも市場に出ているものもあります。エンジニアやデータサイエンティストを含む素晴らしい人々から学び、一緒に働きました。ユーティリティや航空分野での経験を積んだ後、ヘルスケアに移行することを決意し、Centene Corporationに入社しました。
Centeneでは、約3年前にAIと機械学習の分野に参入しました。データサイエンスを洞察のためだけでなく、自動化のための機械学習製品の開発へと移行し始めました。私は素晴らしい機械学習エンジニア、データサイエンティスト、ビジネスシステムアナリスト、クラウドエンジニアのチームと協力しています。私たちの焦点は、会員やプロバイダーにサービスを提供する世界クラスのオンデマンドAIアプリケーションを構築することです。 私たちは、ヘルスケアプロセスを改善するための自動化、推奨、リアルタイムの洞察を提供するAI製品およびAI駆動型製品を開発しています。また、CenteneのAI Center of Excellenceにも貢献しています。
Centeneのインテリジェント文書処理システム構築への道のり
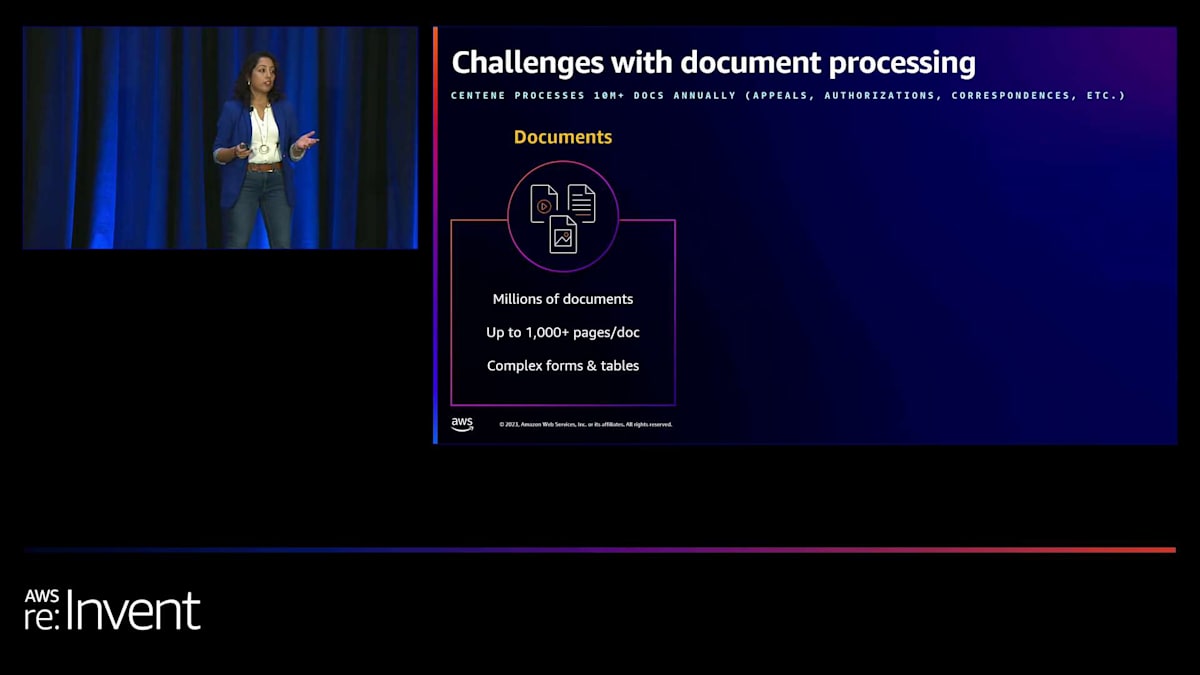
私たちの仕事は、構造化データと非構造化データの両方を扱います。構造化データはさまざまなデータベース、テーブル、スプレッドシートに存在し、非構造化データにはファックス、画像、郵便物、写真からのテキストが含まれます。将来的には、音声やビデオデータにも拡張する予定です。 他のヘルスケア企業と同様に、Centeneも文書処理に大きな課題を抱えています。毎日膨大な量の文書を受け取っており、これには異議申し立て、承認、その他の通信文が含まれます。これらの文書はさまざまな形式で届き、しばしば複雑なフォームや表が含まれています。

現在、これらの文書を意味のある情報に変換するには、大変な労力が必要です。従業員は手作業で郵便物を開封し、文書を読み、すべてのページと内容をシステムに手入力しています。このプロセスは、他の場所でより良く能力を発揮できると感じている従業員にとってストレスとなるだけでなく、高い離職率にもつながっています。さらに、手作業のプロセスはエラーが発生しやすく、深刻な結果を招く可能性があります。

文書量の増加に伴い、処理時間が長くなり、サービスレベル契約(SLA)に影響を与えるため、課題はさらに複雑になっています。これは結果として、会員やプロバイダーに悪影響を及ぼします。さらに、ヘルスケア業界に属しているため、厳格なコンプライアンス要件を遵守しなければなりません。現在のプロセスは、私たちの業務と効率性に大きな影響を与えています。

これらの課題を踏まえ、私たちはCentene内で独自のインテリジェント文書処理システムを開発する必要性を認識しました。ゼロからシステムを構築するなど、いくつかの選択肢を検討しました。このアプローチは、私たちの特定のニーズに合わせてソリューションをカスタマイズする柔軟性を提供します。私たちには素晴らしいスキルを持つ素晴らしい人材がいるので、自分たちでできると確信していました。しかし、そのような取り組みに必要な時間、リソース、スキルも考慮しなければなりませんでした。

私たちが検討した2つ目の選択肢は、既製品を購入することでした。これにより、一から構築する必要がなくなるため、スピードが得られます。既存の機能をそのまま使用できるからです。しかし、ヘルスケア業界にいる私たちには、多くのカスタマイズが必要です。そのような既製のモデルやソリューションを微調整することは難しいでしょう。
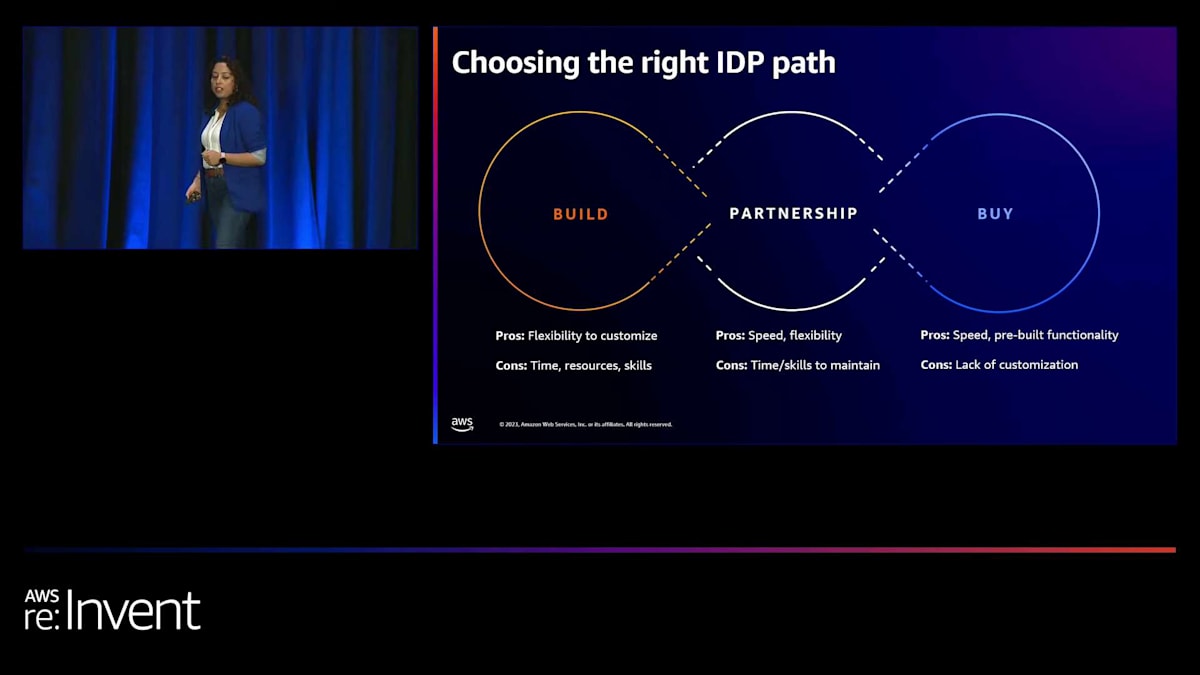
最終的に、私たちはAWSとのパートナーシップを選択しました。AWSから提供されているものを、サービスやインフラ面だけでなく、機械学習の分野からも活用し、それに独自のカスタマイズを加えることにしました。これにより、AWSからさらなるカスタマイズが提供されていない部分については、独自のモデルを構築することができます。これによって、スピードと柔軟性を得ることができました。もちろん、長期的なメンテナンスが必要になりますが、それはこのソリューションの性質上避けられません。
Centeneのインテリジェント文書処理システムの6層構造

そういうわけで、次に私たちが行ったことをお話しします。Centeneでは、AIサービスを活用してインテリジェントな文書処理システムの構築を開始しました。まず、このシステムの最初の層に取り組みました。ここでは、イベント駆動型アーキテクチャとLambda関数を使用したサーバーレスアーキテクチャに焦点を当てました。このアプローチにより、使用していない時の支払いやサーバーのメンテナンスを心配する必要がなくなり、管理が容易になります。

次に焦点を当てたのはセキュリティの層です。Lambdaに対する最小権限ロールなどの機能を使用しました。データの暗号化は非常に重要なので、保存時と転送時の両方でデータを暗号化しています。高度なコンプライアンスとセキュリティが求められるヘルスケア業界にいる私たちは、Amazon S3のサーバーサイド暗号化を使用しています。すべてのトラフィックがVPCエンドポイントを通過するようにし、脆弱性と制御のためにSynchronizationとPrismaスキャンを使用しています。
3番目の層は信頼性で、システムの長期的な側面において重要です。文書を処理するためのスケーラビリティと、負荷に応じて必要に応じて拡大縮小できる能力を確保しました。ある日は一定量の文書があり、翌日にはその2倍の量になることもあります。私たちはGitLabのCICDパイプラインを使用してデプロイメントを自動化し、将来の信頼性のために堅牢な製品サポートシステムを実現するためにServiceNowと統合しています。

インテイクも私たちのソリューションの大きな部分でした。Centene内でさえ、異なる種類のビジネスには文書を受け取る異なる方法があります。多くは郵便、FAX、または電子メールを通じて来ます。ビジネスパートナーから、電子メールから直接文書を取り込めるものを構築できないかと尋ねられました。そのため、インテイクメカニズムの定義が私たちにとって重要でした。電子メールを直接取り込めるインテイクメカニズムを実装し、10メガバイト未満の文書にはAPIゲートウェイを活用し、5GB以上のものにはS3 presigned URLを使用してS3を通じて取り込むようにしました。
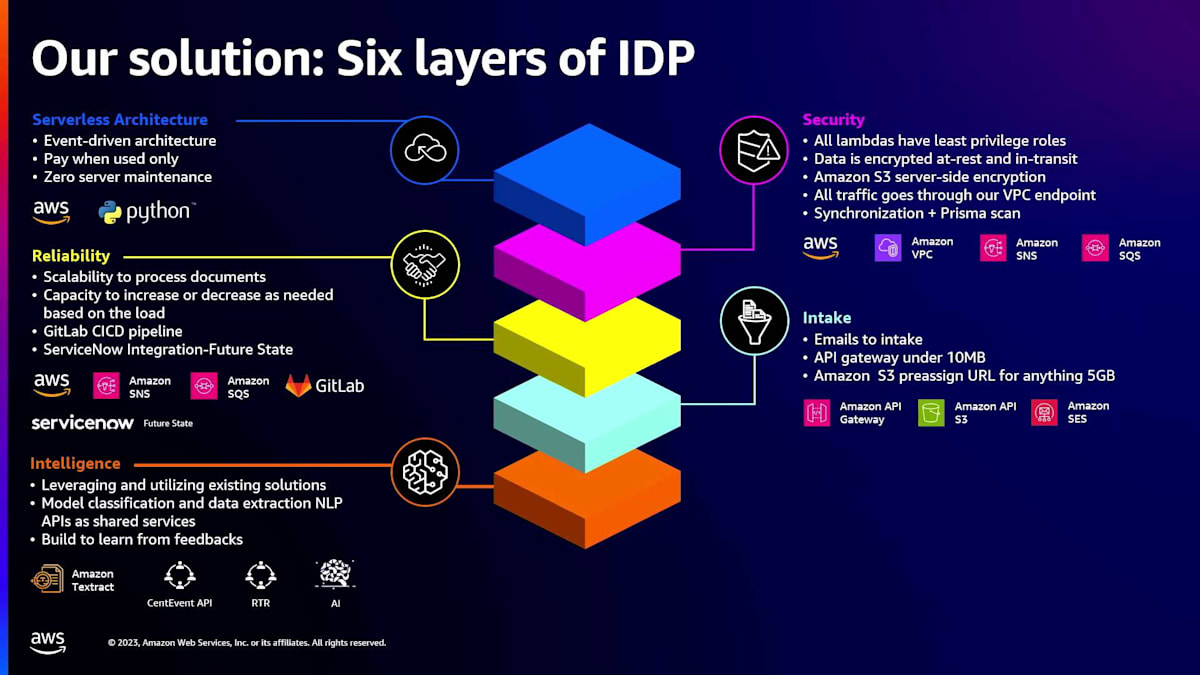
最後に、インテリジェンス層があります。これがシステムの心臓、というよりむしろ頭脳があるところです。私たちはAWSの既存のソリューションを活用・分析し、Textractがその主要コンポーネントの1つでした。Textract Forms、OCR、Textract Tables and Queriesを使用しました。しかし、さらなるカスタマイズが必要だったため、社内で機械学習モデルを構築しました。これらのモデルを自社のデータセットで訓練し、特定の文書をCenteneとそのプロバイダーおよびメンバーに関連するタイプに分類しました。フィードバックから学習する能力が非常に重要でした。ユーザーが結果を得るたびに、そのフィードバックを収集してシステムを改善できる必要があります。

このフィードバックは、モデルに戻されて再訓練に使用されます。生成AIについて議論し、これらの生成AI機能の一部を使い始める場合、これがそれを追加する層になるでしょう。
最後に、最適化層があります。すべてはソフトウェアの考え方で構築されており、ソフトウェアコンポーネントだけでなく、機械学習モデルのコンポーネントもモニタリングできる必要があります。Lambda、サービス、モデルに関連する様々な種類のメトリクスを追跡する必要があります。過剰使用を防ぎ、境界や制限を超えないようにさまざまなポイントでアラートを設定し、アラートの形で通知を送信する必要があります。また、より模块化されていることを確認する必要があります。
私たちがCenteneで構築したインテリジェント・ドキュメント・プロセッシング(IDP)システムの6つの層は、全体として、一度に1つの製品を強化する方法で開発されました。そうすることで、私たちはシステムを一から構築していきました。これから数枚のスライドで、CenteneのIDPの構築を可能にしたユースケースについてお話しします。
Centeneのインテリジェント文書処理システムの成功事例

最初のユースケースでは、勢いをつける必要がありました。そこで、あまり量の多くないユースケースを選びました。具体的には、プロバイダーとメンバーの体験に関連する、1日60〜80ページまたは60〜80通のメールの受信量でした。 以前は、ビジネスパートナーがデータをスプレッドシートに入力するために手動でコピー&ペーストを行っており、多くの時間を費やし、SLAを満たすのが困難で、結果としてペナルティが発生していました。
私たちはCenteneのIDPシステムを使用して、文書の取り込みと読み取りを自動化しました。これらのメールは直接Amazon S3バケットに送られます。Amazon Textractソリューションと追加の機械学習ソリューションを適用して、プロセスを自動化し、結果をビジネスパートナーに返しました。ビジネス側の人間の専門家がチェックを行い、ミスがないことを確認しました。結果は顕著で、手作業と処理時間を80%削減し、これらのスプレッドシートを手で入力するタスクを100%自動化しました。このプロセス全体を通じて、精度を99%以上に保つことに注力しました。

2番目に選んだユースケースは、はるかに大規模なものでした。システムが機能し、価値を生み出すことを証明した後、1日2,000件の文書を受け取り、各文書が最大1,000ページを含む大量のユースケースに適用しました。前の例と同様に、多くの手動処理が含まれており、メールセンターの個人が手でこれらの文書を入力していたため、エラーが発生し、重要な情報を見逃す可能性がありました。これによりSLAが増加し、メンバーエクスペリエンスに悪影響を与えていました。
再びCenteneのIDPシステムを使用して、これらの文書の取り込みを自動化し、精度が十分でないことが分かっている場合にのみ人間の介入を使用しました。この実装の結果も驚くべきものです。この文書の取り込みの最大80%を自動化する計画があり、現在50%近くの自動化を達成しています。テストと検証を通じて、99%以上の精度を達成していることを確認しています。処理時間が93%も大幅に短縮され、SLAが大きく改善されています。
この改善により、メンバーとプロバイダーの体験が大幅に向上しています。素晴らしいですよね?この成功を受けて、私たちは多くの新しいユースケースを特定しました。ビジネスパートナーとさらに議論を重ね、このシステムを使ってインテークプロセスを自動化できる機会がいくつもあることがわかりました。
ヘルスケア業界におけるGenerative AIの活用と課題




では、generative AIについて、そして私たちのシステムでどのように使用する予定かについてお話しましょう。 私たちは、Centeneのヘルスケア分野に現在存在する多くの冗長なプロセスの自動化に注力しています。自動化に重点を置いていますが、精度と人間の介在(human-in-the-loop)の必要性を見失ってはいけません。 つまり、信頼度が非常に低いか、精度基準を満たさない結果を人間が検証することが重要です。 generative AIを適用するプロセスにおいて、戦略的に人間の介入を配置することが私たちにとって極めて重要になります。
generative AIについて話すとき、私の観点からは、ヘルスケア分野で価値を生み出し始める3つの領域があります。1つ目は検索です。私たちは皆、generative AIが非常に速く情報を検索し、ほとんどの場合関連情報を提供する能力を持っていることを知っています。何千ページもの文書を読み、重要な情報を解読しなければならない膨大な文書セットがあります。そこでgenerative AIを使用できます。
2つ目の領域は要約です。私たちは皆、generative AIがさまざまな形で持つこの能力について知っています。ヘルスケア業界では、適切な文書セットから関連情報を得ることが個人にとって重要であり、要約はこれに大きな役割を果たすことができます。最後に、3つ目の領域はground truthの側面です。文書からground truthを生成し、それに基づいてモデルをトレーニングすることも、generative AIの良いユースケースになるでしょう。私たちのニーズに合わせてカスタマイズする機械学習モデルには、ground truthが必要です。generative AIを使用してエンドユーザーに結果を推奨し、ユーザーがそれを検証して文書のアノテーションを速く行うのを助けることができれば、そのようにしてground truthを作成し、モデルをトレーニングすることができます。

しかし、これらすべてを行う際に、ヘルスケア業界はハイリスク・ハイリワードの分野であることを考慮する必要があります。不正確な決定を下さないよう注意しなければなりません。なぜなら、それはメンバーとプロバイダーの体験に影響を与えるからです。たった1人のメンバーの悪い体験でさえ、そのリスクを冒す価値はありません。したがって、ヘルスケアにおいては精度が鍵となり、human-in-the-loopを確保することが、メンバーとプロバイダーにより良いサービスを提供するために不可欠です。
2つ目の考慮事項は、ヘルスケア特化型の大規模言語モデル(LLM)です。自社のニーズに合わせたLLMを構築できれば、それは有益でしょう。そのためには、ハルシネーションを減らすためのフレームワークを構築するのに時間と労力、そして資金を投資する必要があります。異なるLLMの結果を比較し、検証し、精度を確保できるフレームワークを作る必要があります。これも私たちにとって非常に重要な側面となるでしょう。
最後に、コストとリスクの管理が重要です。独自のLLMを構築したり、生成AIテクノロジーを使用したりするのは安くありません。そのため、このスペースのリスクを軽減しながら、価値を創造し続ける必要があります。これも私たちにとって重要な考慮事項となるでしょう。
セッションの締めくくり


ここに最後にリソースへのリンクがいくつかあります。Navをステージに呼び戻して、皆さんからの質問をいくつか受け付けたいと思います。 モバイルアプリにあるアンケートへの回答をお忘れなく。素晴らしい聴衆の皆様、ありがとうございました。
皆様、ご参加いただきありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion