re:Invent 2024: Georgia-PacificのGenerative AIによる技術継承
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Empowering the next-generation industrial operator with generative AI (MFG201)
この動画では、Georgia-Pacificが人材流出と知識損失の課題に対してGenerative AIを活用した取り組みを紹介しています。北米全域に140の製造施設を持つGeorgia-Pacificは、Amazon Bedrockを活用して「Operator Assistant」を開発し、熟練オペレーターの知識をAIで継承する仕組みを構築しました。特筆すべきは、約90,000個の振動センサーと500,000個のプロセスセンサーからのデータを30,000以上のMachine Learningモデルで分析し、設備の異常を検知して具体的な是正措置を提案できる点です。また、Subject Matter Expertsへの音声インタビューから自動的にドキュメントを生成する機能も開発し、暗黙知の継承を実現しています。AWSとの密接な協力関係のもと、ハルシネーションを起こさない安全性の高いシステムを実現しました。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Georgia-Pacificの人材課題とGenerative AIの活用

ようこそ。本日はご参加いただき、ありがとうございます。re:inventは非常に大規模なイベントで、様々な見どころがあることは承知しています。皆様には貴重なお時間を割いてご参加いただき、大変感謝しております。ここで質問させていただきたいのですが、人材の流出や高い離職率による知識の損失に悩む組織で働いている、もしくは関わっている方は手を挙げていただけますでしょうか?多くの方がいらっしゃいますね。そうであれば、まさに適切な場所にいらっしゃいました。これから1時間、まさにその問題に対してGenerative AIを活用してどのように取り組んでいるかについてお話しさせていただきます。

私はErin Dunlopと申します。AWSのSenior Enterprise Account Executiveを務めております。本日は、Georgia-PacificからRoshan ShahとCarter Smithをお迎えできることを大変光栄に思います。Roshan ShahはGeorgia-PacificのVice President for Applied Analytics and Applied AI and Productsとして、AI関連のすべての取り組みを統括されています。Carter SmithはGeorgia-PacificのGenAI Product Leaderを務めており、現場のオペレーターの業務改善についてこのランチタイムにお話しできることを大変楽しみにしています。

本日は、まず当社の概要について説明し、私たちが直面している独自の課題、そして学習と能力開発におけるギャップを埋めるためにテクノロジーをどのように活用しているかについてお話しします。従業員の退職や異動が進む中、施設運営に必要な能力を確実に維持していく必要があります。これまでに構築してきたものの開発サイクルと改善の過程、そして今後の展望についてもご紹介させていただきます。
Generative AI導入の背景とGeorgia-Pacificのデジタル変革

この取り組みは約2年前から始まりました。2023年初頭、Generative AIが世界的に注目を集め始めた頃です。当時、Generative AIが重要な技術であり、組織に大きな影響を与えることは誰もが認識していました。しかし、具体的に何をすべきか、どのように始めるべきかは、多くの組織にとって未知の領域でした。RoshanがGenerative AIによってGeorgia-Pacificのビジネスのあり方が変わると私に連絡してきた時、私はいくつかの提案をしましたが、Roshanは明確でした - 彼らは既に開始地点を把握しており、従業員の生活をどのように変えるか、そしてAWSと共に構築したいという明確なビジョンを持っていました。
AWSの人間として、これは私たちが望むすべてでした - 明確に定義されたユースケース、エンドユーザーへの影響力、そして私たちと共に構築する意欲です。しかし、この2年間でテクノロジーの状況は大きく進化しました。2023年初頭を振り返ると、Amazon Bedrockは年後半まで一般提供されていませんでした。これはGeorgia-PacificとAWSにとって、LLMやFoundation Modelを使った経験のないメンバーと共に、プレGA段階のサービスを使用して、前例のないソリューションを構築するユニークな機会となりました。
少し時間を巻き戻して考えてみると、Georgia-Pacificの過去10年間の歩みについて触れることが重要です。2023年初頭にGenerative AIを素早く活用できた背景には、すでに10年にわたるクラウドトランスフォーメーションを進めており、その上に構築できる強固な基盤があったからです。2016年にAWSへの最初の移行を行って以来、Georgia-Pacificはデータ基盤の構築に多大な投資を行い、それが自然とデータ駆動型ソリューションへと発展していきました。現在、Georgia-Pacificには何十万ものセンサーが設置され、IoTデータをAWSにストリーミングしており、毎秒実行される30,000以上のMachine Learningモデルが本番環境で稼働しています。ここ数年で、それによってGPは人材とプロセスに焦点を当て、ITとビジネスの間のサイロを橋渡しすることが可能になりました。この技術的な journey の詳細に入る前に、組織としてのGeorgia-Pacificについて少しお話しさせていただきます。
Georgia-Pacificの事業概要と技術活用の必要性
ありがとう、Erinさん。今Erinが言及したように、私たちは長年この取り組みを続けてきましたが、具体的にそれが何を意味し、どのように実現してきたのかについて話す前に、Georgia-Pacificとは何か、私たちは誰で、事業を展開するコミュニティで何をしているのかについてお話ししましょう。

ただし、これらについてお話しする際に一つ申し上げておきたいのは、私たちが全てを完璧にこなしてきたように見えるかもしれませんが、実際にはいくつかの失敗もありました。それについても後ほどお話しします。Georgia-PacificはKoch Industriesの完全子会社です。GPは特に約30,000人の従業員を抱え、売上高は200億ドルを少し上回り、北米全域に140の製造施設があります。当社は買収を通じて成長してきた企業です。これは、私たちが各施設で同じ設備を見つけることは稀で、様々な種類の設備を持っているということを意味します。そのため、設備の多様性と異なるヴィンテージの機器が存在しています。
当社は3つの事業部門で構成されています。最初の、そして多くの人々になじみのある部門がConsumer Products事業部です。これは、WalmartやスーパーマーケットでBrawnyやDixie Angels Softを購入する際の製品を製造している部門です。また、トイレで見かけるenmotionペーパータオルディスペンサーも製造しています。もう一つの事業部門がBuilding Productsで、2×4材、合板、OSB、石膏ボードなどを製造しています。3つ目はPackaging & Cellulose事業です。Amazonで何かを購入した際に届く茶色の箱、私たちはそれらの箱を非常に大規模かつ高速に製造しています。また、大人用失禁製品に使用される吸収材も製造しています。これら3つの事業部門で年間売上高200億ドル強を生み出しています。

では、これが皆さんにどう関係するのでしょうか?アメリカの世帯の約3分の2が当社の製品を使用しており、ビジネスの観点からは、全企業の約40%が当社の製品を1つ以上使用しています。このように、私たちはアメリカ経済に不可欠な存在となっています。

なぜ私たちはテクノロジーを活用してこの変革の旅を進めているのでしょうか?単にテクノロジーがクールだからとか、その分野で遊びたいからでしょうか?いいえ、そうではありません。ここにビジネスケースがあります。第一に、Erinが先ほど述べたように、この会場にいる皆さんの多くと同様、私たちも複雑な設備における熟練人材とその知識の流出に苦心しています。これは文書化があまりされていない大規模な古い設備に関してです。経験ベースのアプローチからデータ駆動型アプローチへの移行を可能にする能力を構築する必要があり、これは必須です。第二に、先ほど申し上げたように、私たちは長年にわたって事業を展開しており、多くの古い資産を抱えています。設備の再投資という選択肢もありますが、その価値は見合いません。そのため、既存の資産からより多くの価値を引き出す方法、言い換えれば、資産自身がメンテナンスの必要性を知らせてくれるようにすることが、非常に重要で経済的となります。そして第三に、テクノロジーは日々より安価になり、より多くの機能を備えるようになっているため、それを活用する方法を見出すことができれば、市場での競争力を維持できます。
Operator Assistantの開発と進化
資産の寿命をテクノロジーで延ばすことを考えると、私たちの仕事がより楽になります。これら3つの要素を考えると、それらは相互に積み重なっており、それが私たちの組織にとって重要な変化となっています。これらが具体的に何を意味するのかについて話す前に、Carterにその意味するところを少し説明してもらいましょう。明らかに、私たちはこの問題について話していますが、それが実際のオペレーターにどのような影響を与えるのか、つまり毎日この問題を実際に経験している人々について考えるために、Bowling Green DixieのファシリティでLearning and Development Trainerとして働いているClayというスタッフへのインタビューがあります。彼は、自身が見てきた課題と、なぜこれを私たちの主要なユースケースとして取り組んできたのかについて話してくれます。私の名前はClayです。ここKentucky州Bowling GreenのDixieで働いており、Dixieでの勤務は12年になります。

従業員の研修においてどのような課題がありますか?トレーナーとして私が直面している課題の1つは、従業員に適切な研修教材やリソースを提供することです。

文書化が不足している場合、これまでどのように補ってきましたか?現在、研修の多くは、長年勤務している経験豊富な従業員からの実地指導を通じて行っています。彼らは、研修マニュアルには記載されていないかもしれないショートカットやコツを知っています。しかし、これらの経験豊富な従業員が退職したり部署を異動したりすると、その知識も一緒に失われてしまい、ほとんど一からやり直しになってしまいます。

理想的な学習と能力開発とは、どのようなものでしょうか?シフトやチーム、場所に関係なくアクセスできる一元化されたリソース、つまり、学び、研修を受けたい人なら誰でもこの情報を集めて利用できる場所があれば有益です。人材は私たちにとって最も価値のある資源です。

どのようにして彼らの成功を支援できるのでしょうか? 具体的なソリューションについて話す前に、私たちのアプローチと、これまでの成功事例・失敗事例についてお話ししたいと思います。先ほどClayが言及したように、考慮すべき重要な側面がいくつかあります。例えば、情報にできるだけ早くアクセスするにはどうすればよいのか?訓練を受けた従業員が退職した際の知識の損失をどのように防ぐのか?私たちはその知識を保持し、アクセス可能にし、システムに保管する必要があります。その方法についてこれから説明していきます。
これまでの学びについて少しお話ししましょう。ユースケースを考える上で最も重要なのは、重要な問題に取り組まなければならないということです。誰かのペットプロジェクトを追いかけていては、その価値とP&Lへの影響を誰かが疑問視するのは時間の問題です。私たちは意図的に重要な問題、特に環境衛生と安全性に影響を与える問題に焦点を当ててきました。その次に、生産性と品質の向上を通じてP&Lへの影響が見える問題を、スケールを考慮して優先順位付けしています。
スケールについて話す際、私たちは北米全域に展開する140の製造施設を指しています。1,000万ドル規模の問題に取り組み、ソリューションを施設全体に展開できれば、50の小さな問題を解決するよりも価値提案ははるかに魅力的になります。チームとして活動してきたこの6~7年間で、私たちは6つの大規模なユースケースにのみ焦点を当ててきました。それぞれが8桁から9桁の価値提案を持つものです。
2つ目の学びは、綿密な計画よりも実験的な発見を重視するという考え方です。何週間も何ヶ月もかけて詳細な計画を立てるのではなく、小規模に始めて、ソリューションを展開し、そこから学び、素早く適応していくことを学びました。この方法は、すべてを事前に予測しようとするよりも効果的であることが証明されています。
3つ目の学びは、特にMachine LearningモデルとGenerative AIに関して、ゼロ・ハルシネーション(誤った情報の生成を一切許さない)へのこだわりです。製造業では誤った情報を許容できないということを、私たちは苦い経験から学びました。オペレーターが誤った情報に基づいて判断を下し、怪我をしてしまうようなことは絶対に避けなければなりません。さらに、情報の誤りによって作業者が定時に仕事を終えられないような遅延が発生すれば、彼らはそのシステムを二度と使わなくなってしまいます。
私たちはAWSと密接に連携し、ソフトウェアやモデルの構築、チューニングの方法について検討してきました。モデルが答えを知らない場合、フェイクニュースを提供して問題を引き起こすよりも、「分かりません」と言ってほしいと考えています。この「ゼロ・ハルシネーション」という考え方は非常に重要な要素でした。そして、AIを活用して問題を解決することが収益につながった場合、この建物ほどの大きさの機器と複雑なAIを意図的に統合し、AIにこれらのレガシー資産を制御させることができました。これは私たちにとって非常に重要で有益でした。なぜなら、AIがこれらの機器を制御することで、私たちは他のことに集中できるようになったからです。これによって他の問題に注力する余裕が生まれ、それが重要な成果となりました。
AIを活用した製造プロセスの最適化

では、ユースケースについてCarterに説明を譲りたいと思います。これが私たちが歩んできた道のりです。 基本的に、技術から始めてその技術に合う何かを見つけようとするのではなく、問題を見つけてその技術が解決に役立つかどうかを確認したいと考えています。使用する技術自体にはこだわりません。問題解決のために技術を活用しているのです。しかし、最終的には、オペレーターにとっての価値とサポートを最優先事項として考えています。6月に開始し、2023年7月にProserveとの連携を確立し、MVPの開発に取り組みました。年末までにWisconsin州Green Bayの2台のペーパーマシンで本番稼働を開始し、オペレーターから素晴らしいフィードバックを得ることができました。
構造化データと非構造化データの両方のレスポンスを提供することで、包括的なトラブルシューティングのアドバイスを提供することができました。これは「今どこにいるのか」「どこにいるべきか」「どうやってそこに行くのか」という、オペレーターが業務プロセスを通じて学んでほしい本質的な部分です。このように、私たちはスケーリングに移行し、成功を収めました。しかし、多くの施設でドキュメントが不足しているという問題に直面しました。ベストプラクティスが文書化されておらず、Job Aidやサポート資料が完全に更新されていないなど、通常モデルに入力したい情報が不足していたのです。
では、これはもう使えないということでしょうか?価値があると考えていたので、解決策を見つける必要がありました。後ほど詳しく説明しますが、私たちは「Doc Gen」つまりDocument Generationと呼ぶものを作成しました。その目的は、Subject Matter Expert、ベテランオペレーター、上級スタッフから迅速に情報を収集し、その施設や特定の機器に固有のデータを取得して、Chatbotに情報を提供することです。このChatbotを私たちは「Operator Assistant」と呼んでいます。基本的に、これは決して忘れることのないオペレーターになることを目指しています。一度教えれば、土曜日の午前3時でも常にそこにいて、24時間365日稼働する施設がヘルプを必要とする時には、いつでも正しい答えを提供できるようにしたいのです。
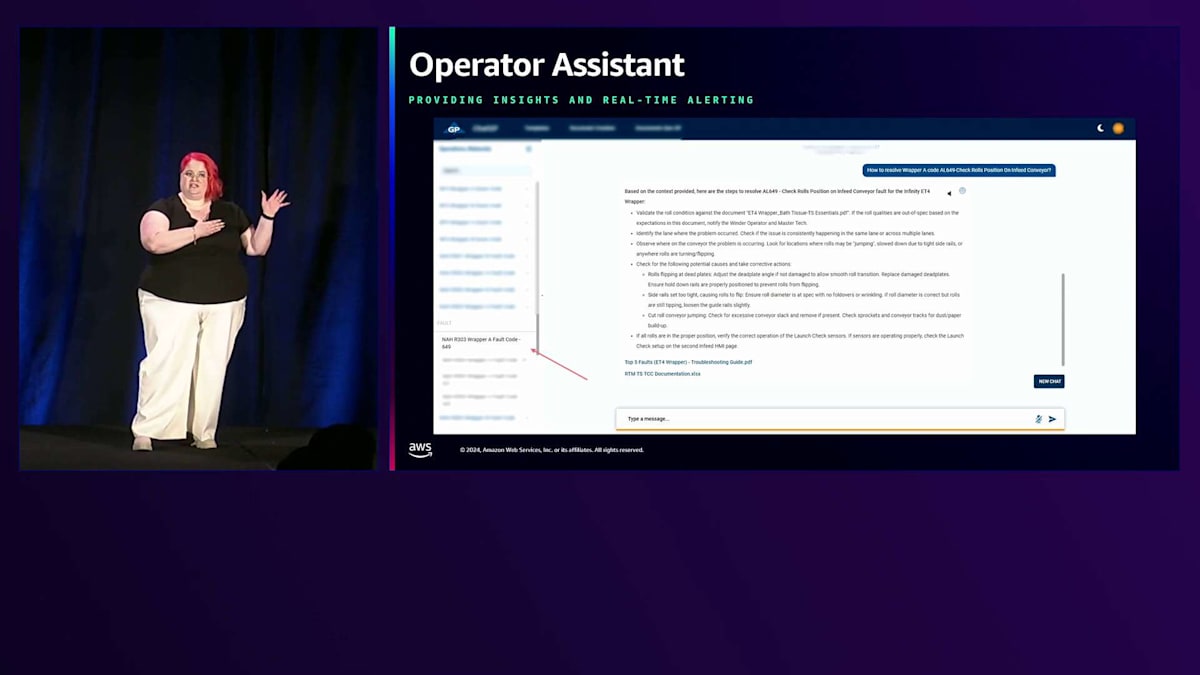
このように、私たちは機能を継続的にスケールしています。現在、20以上のインスタンスが本番環境で稼働しており、さらにスケールを続けています。これが私たちのOperator Assistantの画面の一例です。 質問と回答が表示されていますが、これは最初のバージョンからかなり進化しています。特に強調したいのは、これが反復的なプロセスだということです。一度作って終わりではありません。毎日改良を重ね、カスタマーからフィードバックを得て、彼らが必要とする価値を確実に提供し続けることが重要なのです。
画面の左側にアラートが表示されているのがお分かりいただけると思います。「この問題に遭遇したらどうすればいいですか?」という質問をする状況を想定していましたが、もし機器が停止していて、その問題が今まさに起きているとしたら、わざわざコンピューターまで走って行って質問を入力することを覚えているでしょうか?それは必要な情報を得るための障壁となってしまいます。Roshanが先ほど述べたように、私たちにとって重要なのは、オペレーターができるだけ早く情報を得て、素早く行動できるようにすることです。この例では、アラートが強調表示されています。これはラインが停止した際の障害で、バックエンドで自動的にPrompt Engineeringがトリガーされ、私たちが基本的に推奨アクションと呼んでいる、完全なトラブルの原因と対策を提供します。
オペレーターはこれを見て、「現場で見ているのはこれで、推奨されている対応はこれだから、これに従って進めればいい」と判断できます。私たちはフィードバックを非常に重視しています。この journey を始める方々には、誰もが質問を記録できる場所を用意することをお勧めします。回答が優れていたのか、改善が必要なのかを示すことができます。返される質問すべてにフィードバックを設けており、それを確認して継続的な改善を行っています。
Carterが今述べたことに付け加えると、このアラート機能は極めて重要です。よくあるのは、このようなChatbot環境をエンドユーザーの前に置いて、「質問があったら聞いてください」と言うことです。しかし、これは人々が何を期待すべきか、どんな質問をすべきかを知っているという前提に立っています。これらのオペレーターの多くは、経験年数が長くありません。私たちが何年もの経験を持っているのに対して、彼らは数ヶ月の経験しかありません。そのため、どんな質問をすべきかを知ることが大きな壁となっています。Carterとチームが実現したのは、エンドユーザーに対して「これらの事象が発生しています」と知らせることです。問題の概要を示し、異なる色を使って注意を引き、クリックすると、オペレーターが気付いていないかもしれない問題について順を追って説明します。

先ほど述べたスケーリングに関連して、これらの工場の多くの設備がかなり古いことに気付きました。元の機器マニュアルはタイプライターで打たれたものかもしれません - 紛失したり、誰かの引き出しに埋もれたりしている可能性があります。長年の間に失われた情報が多く、その多くはオペレーターの頭の中に存在しています。Roshanが言及した、短期間で職位が上がってきた人々の課題に対応するため - シフトの上級職というのは、従来であれば30~35年かけて到達するポジションでした。現在では、8年で到達する人もいます。
もちろん、機器を運転できるように認定を受けるための研修は行っていますが、めったに起こらない異常な事態 - 3年に1回真夜中に起こるような事態があります。短期間で昇進した場合、そのような状況に対処した経験がありません。トラブルシューティングにかなりの時間がかかっていることが分かったので、経験豊富なベテランから若い世代への情報の伝達が重要でした。私たちはSubject Matter Expertsに連絡を取ります - これは企業の人材かもしれませんし、シフトのベテランや、プロセスを本当によく理解している最も経験豊富なオペレーターかもしれません。

エンジニアとして文章を書くのが苦手なので、タイプ入力なしで口頭インタビューができるプロセスを作りました。これにより、LLMに情報を提供できるだけでなく、トレーニングや通常のワークフローのためのスタンドアロンドキュメントとしても使える完全な文書を生成することができます。 これらの文書は、画像を含めて完全にAIによって生成されたものです。左側は、自動的に生成されたフォーマットとタイトルで、ステップバイステップで進んでいく、マニュアルで読むような本のフォーマットです。左側には、Standard Operating Procedure(標準作業手順書)があります。製造業に詳しくない方のために説明すると、ポンプの停止や機器の起動など、あらゆるプロセスには従うべき手順書があり、それをStandard Operating Procedureと呼んでいます。
これらのStandard Operating Procedureは非常に重要なプロトコルです。危険性、直面する可能性のある問題、リスクに対処し、ステップバイステップのガイダンスを提供することを目的としています。これらの要素を文書化し、プロセスに関連する安全リスクを理解できるように、最前面に配置しています。
Georgia-PacificとAWSの協力関係がもたらす成果
この取り組みを始めた当初は、とても興味深い経験でした。ベテランのオペレーターの方々と一緒に座り、ポッドキャストで見かけるようなマイクを用意しました。テーブルの中央にマイクを置いてインタビューすると言ったとき、彼らはとても不安そうでした。特定の問題への対処方法についてマイクに向かって話すのは、彼らにとって異例のことでした。しかし、彼らの情報が見栄えの良い文書にまとめられ、自分たちの知識が記録されているのを見たとき、彼らは感心していました。自分たちがいかにプロフェッショナルで知識豊富に聞こえるかを実感し、それが彼らの心を開くきっかけとなりました。
これは私たちの導入プロセスのもう一つの重要な側面となっています。単に本やリストを与えて方法を指示するのではありません。私たちには、異なるヴィンテージやメーカーによる多くの複雑なプロセスがあります。私たちのビジネスには数多くのユニークな課題があります。実際に操業を行っている人々によって作成された情報は、私たちのモデリングにおいてより正確な視点を提供するだけでなく、人々が求めることが正しい答えをもたらすという確信を彼らに与えます。上から解決策を押し付けられるのではなく。
Carterの言葉に付け加えると、会話を録音して文書に変換できることは非常に大きな影響力があります。私たちは退職した従業員にも連絡を取り、時間と材料ベースで報酬を支払い、電話で特定の問題をどのように解決するかを尋ねています。彼らはTeamsコールを通じて簡単に知識を共有でき、AIシステムは雑談をフィルタリングして、プロフェッショナルな文書を作成できるほど賢くなっています。

この概念についてもう少し詳しくお話ししましょう。私たちは人々と対話し、文書を作成していますが、依然として人々がこれらの情報をすべて読むことを期待しています。製造施設では、様々な情報を表示する50もの異なる画面があるかもしれません。では、これらすべての情報をどのように実用的なガイダンスにまとめることができるでしょうか? これはLas Vegasを運転して回るのと似ています - 間違った行動をしようとしているときや、間違った曲がり方をしたときに、Siriが教えてくれて、正しい道に戻してくれる方が良いですよね。道順について電話と20の質問ゲームをしたいとは思いません。むしろ、今何をしているのか、そして代わりに何をすべきかを積極的に教えてくれる方が望ましいのです。
さらに、これを単独の機能にしたくありません。スマートフォンで、下にスワイプして質問するだけで、別のウェブサイトにアクセスする必要なく、メールやその他のアプリケーションを検索して回答を見つけてくれる機能を考えてみてください。これは私たちにとって重要な推進力となってきました。先ほど述べたように、私たちは長年かけて改良してきた30,000のMachine Learningモデルを開発しました。これらのMachine LearningモデルをGenerative AIと統合することで、常に何が起きているか、どの要素が正常な状態から外れているか、どれがアラート状態にあるかを認識できます。そしてこの情報をオペレーターに提供し、代替行動を提案し、状況が正常に戻るまでモニタリングを続けます。

私たちは意図的に、人々が質問するのを待つことを避けたいと考えています。そしてその点を踏まえて、これらを別々のシステムにしたくありません。 私たちは、これらを統合したいと考えています。では、基礎的な側面について話しましょう。

Asset Healthは非常に重要なコンポーネントです。組織として、どの資産が故障しているかを把握することは9桁規模の機会です。私たちは過去数年間で、約90,000個の振動センサーが常時データを収集するアプリを構築しました。これらのセンサーは日々天文学的な量のデータを生成します。私たちはAWSとのパートナーシップも含め、社内で多くのMachine Learningモデルを構築しました。このシステムは日々兆単位のデータレコードを処理し、何が故障しているかを教えてくれます。その異常検知を具体的な是正措置に変換する方法を理解するためのモデルを構築し、現在では資産の残存信頼性も判断できるようになりました。今では何がなぜ故障するのかを教えてくれる機能を持っています。

さらに発展させましょう。私たちにはProcess Healthという概念もあります。 資産は機械的または電気的に故障することは分かっていますが、人々が不注意で間違いを犯した場合はどうでしょうか?それらすべてをどのように組み込むのでしょうか?私たちには別のモデルセットがあります - 約500,000個のセンサーからリアルタイムでデータを消費する約30,000のMachine Learningモデルがあり、誰かが間違った行動をしているかどうか、そして彼らが何をすべきかを判断しています。このダイアグラムは、期待される状態、過去の状態、そして彼らが何をすべきかを意図的に示す異なる色の曲線を表示しています。これは構造化データに対する別のモデルです。

この1年間、Generative AIの力を活用することで、どの設備が故障するのか、残り寿命はどのくらいか、なぜ故障するのか、そして作業者が適切に、あるいは不適切に、または最適ではない方法で何を行っているのかを把握できるようになりました。そして、作業者が気付かないうちにその情報を伝えることができるようになりました。では、製紙業務における推奨アクションについて、Carterに説明してもらいましょう。
先ほど申し上げたように、私はエンジニアリングのバックグラウンドを持ち、製紙の専門教育を受けました。ここでは、シフトに入る朝の様子を説明させていただきます。最初に確認するのは、逸脱、アラーム、問題の有無です。通常、何か異常があった場合、エンジニアがそれを見つけ、なぜ正常範囲から外れているのかを理解するプロセスを進めます。エンジニアは、プロセスに関する知識をもとに、その項目に影響を与える可能性のある3、4の要因を考え、どれが根本原因かを探ります。これはデータに基づいて行われ、正常範囲内か範囲外かを確認します。
ここで、Roshanが話したような他のMLモデルを活用しているのです。プロセスの動きを理解できるようになっているからです。振動、温度、圧力など、プロセスに関するあらゆる情報を持つストリーミングセンサーがあります。エンジニアがこれを調査し、データを詳しく見ていくには、毎朝1件の問題に対して1時間から1時間半かかることもあります。つまり、その間、問題が正常範囲から外れたままで、プロセスが適切に動作していない可能性があり、品質、安全性、または生産全般に影響を与えかねません。
この時間を短縮できることは大きな節約になり、施設のスタッフをサポートできます。画面の一番上を見ると、分散制御システムで通常見られるようなセンサーの異常を示すのではなく、根本原因と考えられる内容を実際に説明しています。単に「これが問題だから、これをしなさい」と言うこともできます。しかし、Generative AIに懐疑的な人々の経験からすると、コンピュータが言うからといって信用できない、プロセスを台無しにしたくないと考えるかもしれません。ここで信頼と理解を得るために重要だと考えたのは、なぜそう判断したのかという論理を提供することです。
システムは実際にベストプラクティスの文書を確認し、プロセスがどのように動作すべきかを調べ、その施設に関する重要な文書をすべて参照して、現在の状況に基づいて、これらの項目が範囲外であるため、これが根本原因だと判断します。これは、現場で作業者からよく聞かれる「これが異常だけど、どうすればいいの?」という質問に答えるためのものです。このシステムは、この逸脱に至った一連の出来事を示し、それを制御下に戻すために取るべき詳細な推奨アクションのリストを提供します。
重要なポイントの1つとして、2番目の箇条書きに注目していただきたいのですが、フード圧力バルブの位置が上限値60%を超えて、センターラインから78%上方にあることを示しています。一見些細なことに思えるかもしれませんが、これは非常に重要な意味を持っています。というのも、この情報はGenerative AIに質問することなく自動的に生成されたものだからです。センサーがデータを送信し、その上のモデルがセンサーからの情報が望ましくないことを検知し、これらすべてが舞台裏で自律的に行われているのです。これこそが、構造化データと非構造化データを組み合わせ、AIに20の質問を投げかけて待つのではなく、AIから直接推奨事項を得られる力なのです。Carterが指摘したように、下部に表示される推奨アクションが具体的に何が起きているのかを説明し、どう対処すべきかを提案できることが、まさにAIの直感的な活用方法と言えます。

私たちの考えや用語では、AIに期待することは、ナビゲーションシステムが曲がり損ねた時に教えてくれて、次にどうすべきかを提案してくれるように、是正措置を提示してエンドユーザーに促すことです。これらすべてを実現するため、私たちはAWSの大規模ユーザーとして、すべてをAWS上に構築しています。Carterが話した何兆もの記録データとすべての知識を私たちのシステムに組み込み、これらのプロセスモデルをすべてPythonで構築し、SASとAWS上で実行しています。その上にSAS Intelligent Decisioningという機能があり、さらにその上でAmazon Bedrockが動作しています。上向きの矢印より下のすべてが自律的に動作し、エンドユーザーに是正措置を促します。そしてこれらはすべて、ハルシネーションを一切起こすことなく実現されています。

これらすべてがどのように組み合わさっているかを示す概要図がこちらです。私の同僚のManishが主催する別のセッションに参加されることをお勧めします。そこでは、これらすべてがどのように実際に組み合わさっているかについて、詳しく見ることができます。これが私たちにとっての全体的な概要図となります。
AWSとGeorgia-Pacificのパートナーシップの本質

私たちはこれまでの成果とすべての構築してきたものに大変興奮しています。私たちにとって最も重要なのは、ドキュメント生成機能の継続的な開発です。施設から失われつつある貴重な知識を確実に捕捉できるようになっており、これは計り知れない価値があります。また、北米全体で約140の施設があり、このテクノロジーの恩恵を受けられる施設がさらに多くあるため、スケーリングにも取り組んでいます。その実現の重要な部分として、Generative AIを私たちが実装した他のすべてのAIと直接統合することが挙げられます。エッジとクラウドの両方でモデルに常時フィードを送り続けている数百台のカメラによるComputer Visionがあります。私たちはこれらすべてを統合し、シームレスにすることで、ユーザーが複数の環境にアクセスする必要がないようにしたいと考えています。1つの質問に答えるために5つのアプリケーションを開かなければならないのは誰も好みませんから、私たちが提供するものをユーザーのネイティブアプリの中に組み込み、特別な操作を要求しないようにできれば、それは非常に強力なものとなります。つまり、AIの存在を意識させることなく、バックグラウンドで動作させるということです。
かつて私たちは車にGPSナビゲーション装置を取り付けていましたが、今では携帯電話を接続するだけで、Android AutoやApple CarPlayを通じて既存のダッシュボードにネイティブに統合されて表示されます。これが私たちが目指している考え方とプロセスです。AIを明示的に示すことなく、ユーザーの環境に直接統合することです。単に推奨事項を提供するだけなので、新しいアプリやリンクへの移動が不要となり、変更管理が容易になります。オペレーターが普段使用しているHMI(Human Machine Interface)やオペレーター画面を使用することに慣れているのであれば、大きな違いを感じることはないはずです。

私たちは、この10年間で開発してきた機械学習モデルの構築を継続しています。複数の異なるモデルを使用できるAmazon Bedrockの中にいることは、私たちにとって非常に強力な武器となっています。先週ちょうど展開した具体例の一つは、FAXやメールで届く注文に関するものです。これらは様々な機械学習モデルとOCRを通じて処理できますが、Generative AIと組み合わせることで、特定のフィールドを物理的にコーディングすることなく、Generative AIにFAXを読ませて適切な情報を抽出させることが可能になりました。お客様によって注文の送り方は様々で、手書きでe-FAXを送ったり、メールに添付したりします。以前は人手で行っていたり、扱いにくいOCRプロセスを通じて行っていた作業を、異なる機能を組み合わせることでスムーズに処理できるようになりました。ここで私たちは、Amazon Bedrockに組み込まれている多くのFoundational Modelを活用しています。
このプロセス全体で非常に重要なことの一つは、これは必ずしも購入するものではなく、構築するものだということ、そしてパートナーとして構築することが重要だということです。私自身とチームにとって非常にやりがいがあるのは、AWSが真のパートナーとして、私たちのチームの一員として機能してくれていることです。私たちは共に成功し、共に失敗し、部屋の中で誰もが平等な発言権を持つようにすることで、私たちが目指すものにとって本当に最適なものを構築できるようにしています。
私たちはテクノロジービジネスというわけではなく、まったく異なるビジネスを展開しています。そのため、パートナーと「これが私たちが解決しようとしている課題です。あなたならどう解決しますか?」と話し合い、一緒に取り組めることは非常に大きな意味を持ちます。先ほど述べたように、Generative AIやずっと前からのAmazon SageMakerで行ってきた多くの作業により、一般提供される前に機能にアクセスすることができ、AWSと共にそれを改良することができました。これらすべては、私たちが正確に何を解決したいのかわからないという視点から行われています。私たちは課題を提示し、テクノロジーの発明というビジネスには携わりたくないため、AWSが技術面での解決策を見出してくれるのです。
最も重要なのは、私たちが24時間365日稼働の製造会社だということです。真夜中に何か問題が発生した時、私たちはAaronたちに電話をかけますが、「チケットを提出してください。営業時間内に対応します」というような対応はほとんどありません。AWSは私たちが24時間365日稼働していることを理解した上で、これらの問題の解決に協力してくれます。あなたと共に働き、あなたの痛みを理解してくれるパートナーを持つことは非常に価値があります。AWSの観点からすると、Georgia-Pacificをサポートするすべての機会において3つの譲れない条件があります。1つ目は相互利益です。GPはAWSをテクノロジーベンダーとは考えておらず、そのように扱うこともありません。私たちは単にテクノロジーを売りに来る存在ではなく、単なる金銭的な取引でもありません。私たちは、Amazon BedrockのプレGA(一般提供前)リリースでGPにパートナーになってもらうような、協力を通じた相互利益のある機会を探しています。サービスがまだ本番環境に完全に対応していない少し扱いにくい状態であることを承知の上でです。
Georgia-Pacificにとっての利点は、非常に早い段階で構築を開始でき、AWSから多くのサポートを受けられたことです。AWSにとっての利点は、手を汚すことを恐れない意欲的なパートナーから、非常に価値のあるフィードバックを得られたことです。
2番目は知的誠実さです。Georgia-Pacificは私たちに対して、もしAWSがある用途に対して優位性のある機能を提供できない場合は、「素晴らしいアイデアですが、それは私たちの領域ではありません」と率直に伝えることを期待しています。少し極端な例を挙げてポイントを説明させていただきます。もしGeorgia-Pacificが、AWSのネイティブサービスを使ってERPシステムを一から構築したいと言ってきた場合 - 実際にはそんなことは絶対にありませんが - 彼らは私たちが「それは良いアイデアですが、まずはパートナーをご紹介させていただきましょう」と言うことを期待しています。私たちには、一から新しく構築するよりも、その機能を提供するのに適したパートナーを推薦することができます。
3番目は比較優位性を活かすことです。これは、ビジネス成果をできるだけ早く達成するために、より良く、より速く、より安価に実現できる適切な人材を投入することを意味します。この会場にいる多くの方々はAWSと仕事をされた経験があり、Amazonianが何人いるかご存知でしょう。私たちは大勢おり、プログラムも多いため、プログラムやプロジェクトの各側面で誰に連絡し、誰を起用すべきかを把握するのは大変です。そこでアカウントチームの出番となります - 私たちは、Georgia-Pacificができるだけ早くビジネス成果を実現できるよう、適切な人材、プログラム、資金、技術者など、必要なものを提供することが求められています。
この特定のユースケースでは、AWS内の2つの特定のグループを活用することができました。1つ目はGen AI Innovation Centerです。2023年初頭を振り返ると、LLMsに関する深い経験を持つ人材プールはかなり限られていました。Gen AI Innovation Centerは非常に深い技術的専門知識を持つグループで、その知識をGeorgia-Pacificに提供し、実用的なプロトタイプの立ち上げを支援しました。そこから、Georgia-Pacificと二人三脚で進める私たちのコンサルタントであるProServeに移行しました。
このビルドの最も強力な点の1つは、チームが常にGeorgia-PacificとAWSだけで構成されていたことです。AWSが構築して引き渡すということも、Georgia-Pacificが構築してAWSに必要に応じて随時支援を求めるということもありませんでした。まさに一つのチームモデルでした。昨日も冗談で話していましたが - Amazonでは「Two Pizza Teams」と呼んでいますが、Georgia-Pacificでは「Ten Tacos and Tequila」、特に少し遅くなる時はそうです。私たちは共に勝ち、共に失敗し、「頑張ってね、Georgia-Pacific」と言って終わるようなベンダー関係ではありません。
このアプローチは、このユースケースで大きな違いを生み出し、信頼を獲得してエンドユーザーにインパクトを与えることで、さらなる機会への道を開いたと思います。念のため申し上げますと、時には「Ten Tacos and Tequila」でしたが、遅くなるときは「Ten Tequila and Some Tacos」になることもありました。質問がありましたら、後ほどお答えできますので、よろしくお願いします。お話しできて光栄でした。明日MGMで、アーキテクチャについてより詳しい技術的な説明をする同僚がいます。そのセッションの情報を得るためのQRコードがありますので、スキャンしてください。ぜひ参加されることをお勧めします。ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion