re:Invent 2024: AWSがAurora PostgreSQL Limitlessの性能を解説
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Achieving scale with Amazon Aurora PostgreSQL Limitless Database (DAT420)
この動画では、Amazon Aurora PostgreSQL Limitless Databaseの機能と仕組みについて詳しく解説しています。単一のデータベースを超えてスケールできるマネージド型の水平スケールアウトソリューションとして、1秒あたり数百万のWrite トランザクションまでスケールし、ペタバイト規模のデータを管理できる能力を持ちます。Bounded Clocksを活用した分散トランザクション処理や、Single Shard OptimizedやFunction Distributionなどの最適化機能により、高いパフォーマンスを実現。実際のus-east-1での実験では、100億行のテーブルに対して1秒あたり250万以上のUpdateとCommitを2.3〜0.4ミリ秒のレイテンシーで処理できることが示されています。PostgreSQLと同じセマンティクスを維持しながら、シャーディングの複雑さを隠蔽する設計思想が特徴的です。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon Aurora PostgreSQL Limitless Databaseの紹介

みなさん、こんにちは。今日のデータ量が指数関数的に増加する世界において、データベースを効率的にスケールする能力は、組織にとって非常に重要です。しかし、可用性や一貫性といったデータベースの基本的な機能を損なうことなく、どのようにして高いパフォーマンスとスケールを実現できるのでしょうか?私はAnum Jang Sherと申します。このセッションでは、Amazon Aurora PostgreSQL Limitless Databaseが、単一のデータベースが提供できる範囲を超えてスケールする方法についてお話しします。


これから45分から1時間ほどの時間で、以下のアジェンダに沿って進めていきます。 まず、モチベーションと直面するスケーリングの課題についてお話しします。その後、製品の概要、その特徴、使用方法について説明します。残りの時間では、アーキテクチャ、データの分散方法、トランザクションとクエリの仕組みなど、内部の動作について詳しく見ていきます。最後に、今日からどのように始められるかについてご説明します。

Limitless DatabaseはAuroraの機能の一つですが、今年は特別な年です。なぜなら、Auroraの10周年を祝う年だからです。私たちが皆様の課題を解決するために新機能や新しい能力を構築してきた、この旅に皆様と共に歩んでこられたことに感謝申し上げます。このタイムラインは、最新の追加機能であるLimitless Databaseを含む、これまでに提供してきた主要な機能を示しています。
データベースのスケーリングにおける課題



アプリケーションを構築する際、非常に大まかに言えば、必要なパフォーマンスとスケールのレベルを決定し、それに応じてリソースをプロビジョニングします。より多くのリソースが必要になった場合は、より大きなインスタンスサイズにスケールアップします。ビジネスが成長すると(これは素晴らしいことですが)、最終的にスループットやデータストレージの面で、単一のデータベースが提供できる限界に到達します。 この時点で、Shardingの世界に入ることになります。 スケールを実現するために、データベースを複数のコンポーネントに分割します。これは、必要なパフォーマンスとスケールを提供するための一般的な最適化手法です。




しかし、システムを複数のコンポーネントに分割すると、さまざまな課題が生じます。ここでは4つの主要な課題について説明します:クエリの実行、一貫性の維持、再シャーディング、そしてキャパシティ管理です。 クエリに関しては、システムを複数のコンポーネントに分割すると、クエリの実行がより複雑になります。アプリケーションは、データがどこに存在するかを把握している必要があります。 一貫性に関しては、カラムの追加や削除などのテーブルの変更を行う際、すべてのコンポーネントで一貫して変更が行われるようにする必要があります。 深夜のバックアップのような日常的な操作でさえ、各コンポーネントで実行時間が若干異なる可能性があり、システムの一貫性を維持するのはあなたの責任となります。



もう1つの大きな課題が再シャーディングです。データを単一のデータベースから分散させる際、それは一度きりの作業では済みません。 ノードのいずれかがホットになるたびに、データを再分散させる必要が出てきます。 この再シャーディングのプロセスは、使用パターンに応じて頻度は異なりますが、時間とともに継続的に発生します。


最後に取り上げたい課題が、データベースのキャパシティ管理です。単一の大規模データベースであれば、そのデータベースのキャパシティだけを管理すればよく、多少の変動に対して若干のオーバープロビジョニングが必要になるかもしれません。しかし、 システムを複数のデータベースに分割すると、システム内のどの部分でもホットスポットが発生する可能性があり、それは時間帯や年間の時期によって変動します。そのホットスポットがどこで発生するかを特定し、適切に対処しなければなりません。
通常、最終的にはこれらのノードすべてをオーバープロビジョニングすることになります。そうなると、運用の複雑さだけでなく、追加コストも発生してしまいます。これらの課題に対処するために...皆さんの中には頷いている方もいらっしゃいますね。この苦労を経験されたことがあるのがよくわかります。
Limitless Databaseの特徴と機能

これらの課題に対処するため、私たちは Amazon Aurora PostgreSQL Limitless Databaseをローンチしました。これは、単一のデータベースを超えて拡張できる、マネージド型の水平スケールアウトソリューションを提供するAuroraの回答です。基本的な考え方は、シャード化または水平スケールアウトソリューションのパワーを、単一クラスターのような使いやすさで提供することです。Limitless Databaseは、1秒あたり数百万の書き込みトランザクションまでスケールし、ペタバイト規模のデータを管理する能力を持ちながら、単一のデータベースクラスターのような運用の簡便さを提供します。課金に関しては、追加コストが発生しないよう、使用した分だけを支払う仕組みになっています。

通常、Auroraでは、 コンピュートリソースが必要な場合、インスタンスをプロビジョニングしてR7gを取得し、固定容量を確保します。2018年には Aurora Serverlessをローンチし、固定容量のプロビジョニングではなく、容量範囲を指定するモデルに変更しました。最小容量と最大容量を指定すると、データベースがその範囲内で自動的にスケールします。そして今回、Limitless Databaseで、水平スケーリングによってさらに一歩前進します。インスタンスについて考える代わりに、コンピュートに関してはDB Shard Groupについて考える必要があります。DB Shard Groupを作成し、容量範囲を設定し、コンピュートについてはRedundancyを指定できます。1つまたは2つのフェイルオーバーターゲットを持つことができ、開発環境の場合は、コンピュートのRedundancyをゼロに指定することもできます。Auroraと同様に、Limitless Databaseも99.99%の可用性SLAをサポートしています。

DB Shard Groupのキャパシティ管理についてお話しする際、私たちは既存のサービスの基本概念の上に構築を行っています。このDB Shard GroupのキャパシティはAurora Capacity Units(ACUs)で測定されます。1 ACUは2ギガバイトのメモリと、それに伴うCPUとネットワークリソースの組み合わせで、1対2の比率に従います。Limitless Databaseを作成する際、DB Groupの最小キャパシティと最大キャパシティをACUで指定すると、必要な計算リソースを提供するために、データベースはこれらの制限の間で自動的にスケールします。
Limitless Databaseのアーキテクチャと動作原理


簡単なシナリオを見ていきましょう。私がeコマース企業のデータベースエンジニアで、商品を販売しているとします。私たちが行っていることの1つに、都市に基づく売上税の計算があります。これは3つのテーブル(Customer、Order、Tax Rate)を持つサンプルスキーマです。CustomerテーブルとOrderテーブルのCustomer IDカラムに注目してください。では、このような例にLimitlessはどのように適合するのでしょうか?Limitless Databaseでは、通常のPostgreSQLテーブル、Shardedテーブル、Referenceテーブルという3つの異なるタイプのテーブルをサポートしています。



この例では、システム全体でシャーディングしたいOrderテーブルがあります。この例の異なる色は、Shard Keyに基づいて異なるノードに分散される異なるCustomer IDを表しています。この例では、Customer IDをShard Keyとして使用することを覚えておいてください。もう1つ、Customerテーブルがあります。多くのユースケースでは、CustomerテーブルのOrder Customer dataとOrders dataを一緒に持ちたいと考えます。システムが複数のノードにアクセスする必要がないよう、このデータを1つのノードに配置することが理にかなっています。


Limitlessには、Co-locatedテーブルという概念があり、同じShard Keyを共有することをシステムに指定することで、データが同じノードに配置されます。クエリを実行する際、複数のノードにまたがってJoinを実行する必要がなく、これらの異なるノードにデータを分散できます。

非常に小規模で書き込みが少ないテーブルについては、Referenceテーブルを使用し、各ノードに完全にコピーされます。この例では、Tax Rateテーブルがそれに当たります。この特定の例で示している3つのノードそれぞれにコピーされます。これが、この例を概念的に理解する方法です。



テーブルがShardedテーブルになるのか、Referenceテーブルになるのかを指定するために、セッションパラメータを使用します。 この具体例では、セッションパラメータを設定します。 これは、Limitlessで新しく作成したパラメータで、limitless_create_table_modeをshardedに設定します。Shardedテーブルの場合は、Shard Keyを指定する必要があります。Customer IDがこのケースで使用するShard Keyとなります。


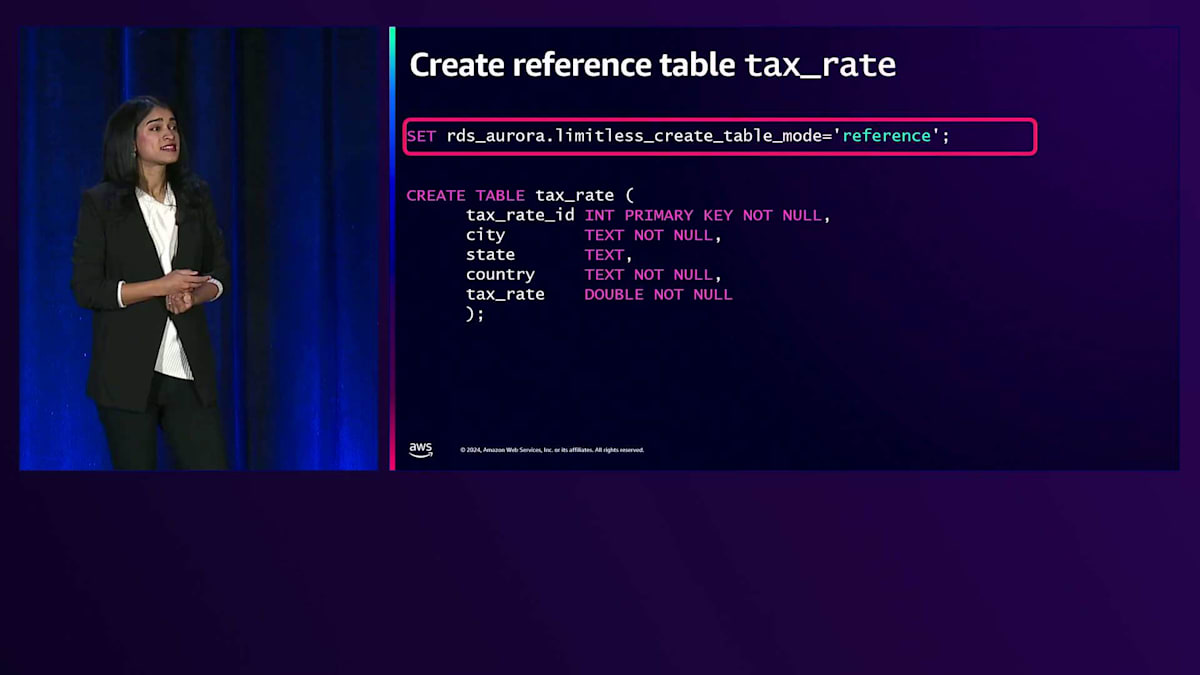
私たちは構文の変更を最小限に抑えることを重視しました。 CREATE TABLE文を見ていただくと分かりますが、そこには一切変更を加えていません。これは通常のCREATE TABLE文と同じです。Shardedテーブルを指定する必要がある場合は、セッションパラメータとして設定します。一度設定すれば、そのままCREATE文を使用できます。Co-locatedテーブルについても、同じように構文を変更しない方針を採用しています。以上がShardedテーブルの指定方法です。Co-locatedテーブルの場合は、このテーブルがCo-locatedであることを示す新しいセッションパラメータを追加します。Referenceテーブルについても同様に、セッションパラメータを使用して指定します。
トランザクション処理とクロック同期の仕組み

ここまで、なぜこの機能が重要なのか、Amazon Aurora PostgreSQL Limitless Databaseとは何か、そしてどのようにシンプルな例で使用できるのかについて簡単に説明してきました。次は、内部の仕組みや、アーキテクチャ、そしてデータベースがどのように分散されているのかについて詳しく見ていきましょう。この部分については、このプロジェクトのエンジニアリングリーダーの一人であるDavid Weinに説明してもらいます。
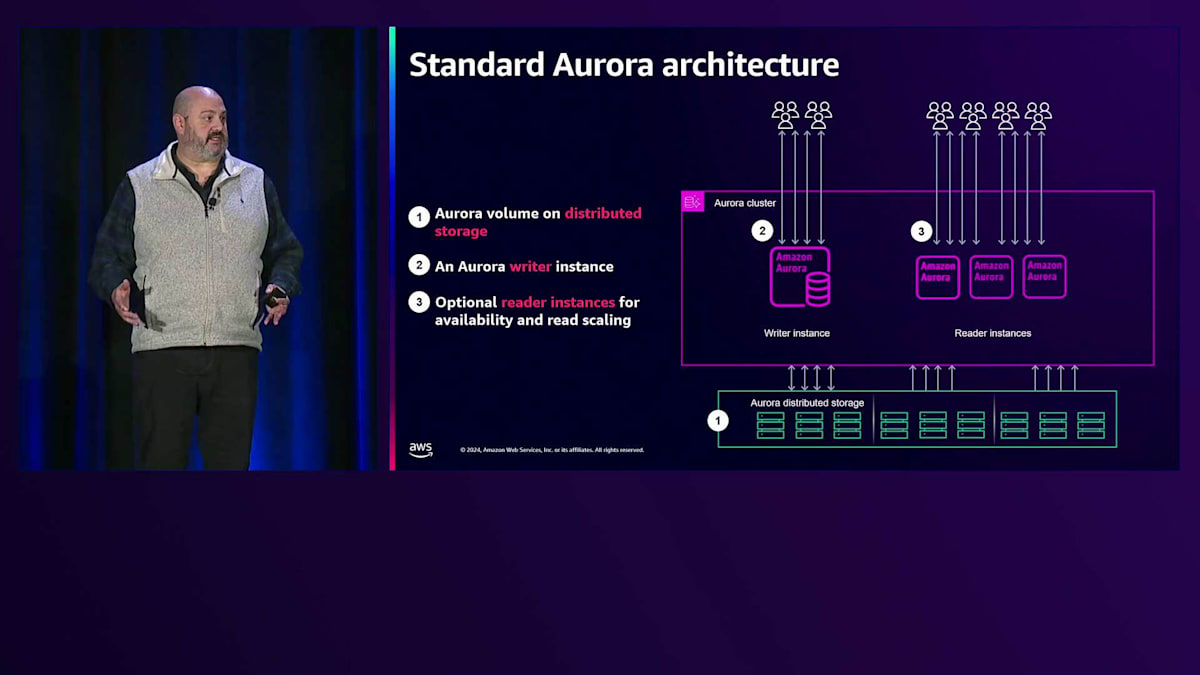
こんにちは、Senior Principal TechnologistのDavid Weinです。Aurora PostgreSQL Limitless Databaseの開発・提供を主導したエンジニアリングチームを率いてきました。これから、このシステムの内部構造と仕組みについて詳しくご説明させていただきます。従来のAurora PostgreSQLのトポロジーを見てみると、単一のWriterノードと、複数のReaderインスタンスを持つAuraクラスターがあり、これらはAuraの分散ストレージによってバックアップされています。Auraストレージは私たちの基盤となる重要なコンポーネントです。3つのアベイラビリティーゾーンにまたがる耐久性の高いストレージシステムで、保存するデータ量に応じて弾力的に拡大縮小し、実質的に無制限のIOPSを提供します。Auraの分散ストレージシステムでは、ストレージのプロビジョニングは不要です。先ほど触れたように、これは10年にわたって実戦で鍛え上げられたストレージアーキテクチャです。


書き込みを行いたい接続はWriterインスタンスと通信し、読み取りを行う接続はReadノードと通信します。Limitless Databaseでは、これらのWriterとReaderのコンポーネントを、Anaが説明したShard Groupと呼ばれるものに置き換えました。Shard GroupにはLimitless Databaseシステムを動かす実際のコンピュートが含まれています。重要なポイントは、基盤となるAuraストレージ、分散ストレージ、コンピューティングとストレージの分離、そして3つのアベイラビリティーゾーンによる耐久性は引き続き使用しているということです。では、Shard Groupの中身を見て、各レイヤーについて詳しく見ていきましょう。

重要なポイントは、Shard Groupが Aurora クラスター内に含まれているということです。APIレベルで言えば、RDS create DB clusterは、スナップショットの取得やポイントインタイムリストア、メンテナンス作業といった、現在行っている通常のクラスターレベルの操作と同じように機能します。これらの操作には1つのAPIだけで対応できます。Shard Groupは必要なインフラストラクチャをカプセル化し、アプリケーションが接続するための単一のエンドポイントを提供します。エンドポイントは1つだけなので、さまざまなコンポーネントのエンドポイント接続について心配する必要はありません。


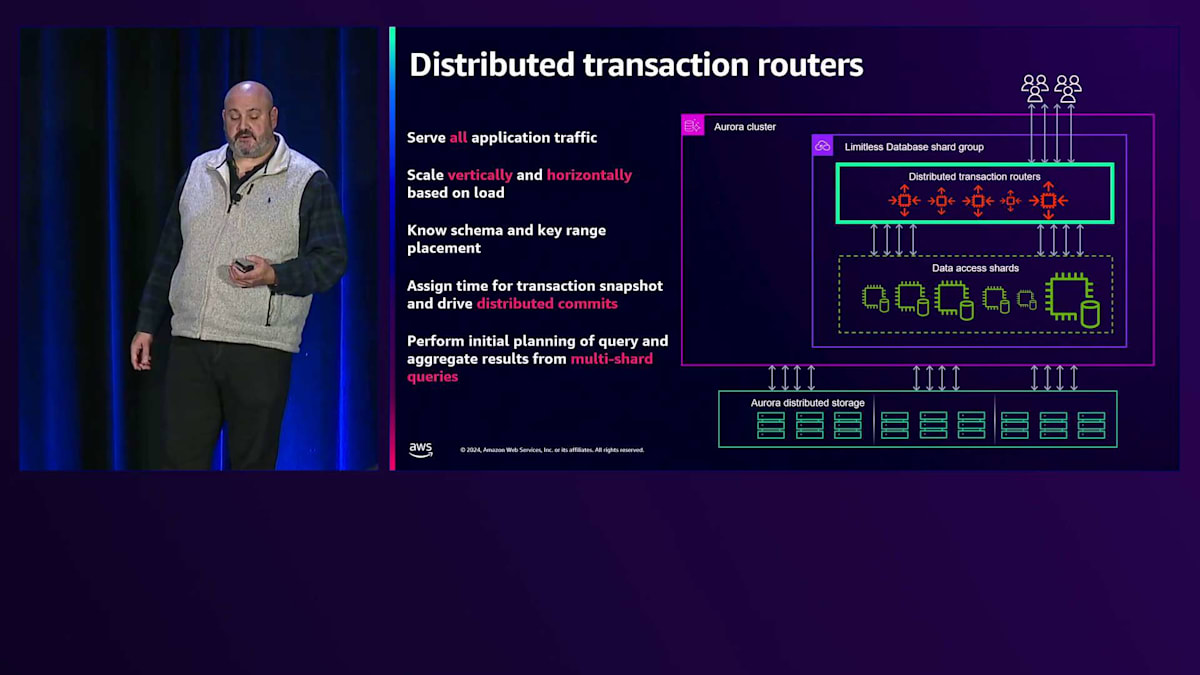
Shard Groupは、設定された最小・最大ACU範囲内で、アプリケーションの負荷とデータサイズに基づいて自動的にスケールします。Shard Group内の最初のコンポーネントは、Distributed Transaction Router(略してRouter)と呼ばれるものです。Routerはすべてのアプリケーショントラフィックを処理し、アプリケーションからのユーザー接続は特定のRouterに割り当てられます。Routerは他のコンポーネントと同様に、負荷に応じて垂直方向にスケールアップ・ダウンしたり、すべてのRouterが既に負荷状態の場合は水平方向にスケールしたりします。
Routerはスキーマとデータの配置をすべて把握しており、ユーザーからは通常のPostgreSQLノードのように見えます。ただし、データは保存せず、スキーマのみを持ち、すべてのRouterは同一です。どのRouterに接続しているかは関係なく、どのRouterからでもあらゆる操作やDDLを実行できます。実際にクエリを実行すると、RouterはPostgreSQLクエリエンジンでクエリを受け取り、解析して初期プランニングを行い、データの場所に基づいてクエリをどこに送信するかを決定し、単一のShardからの結果や複数のShardからの結果を集約できます。これらのRouterは単なるプロキシではなく、完全なデータベースエンジンなのです。

次に、Data Access Shard(略してShard)があり、これらが実際のデータの一部を保持します。各ShardはShard Keyテーブルスペースの一部を所有し、Reference Tableの完全なコピーを持っています。Reference Tableは各Shardに完全な形で存在し、Shardはデータの一部を保持します。クライアントからクエリが来ると、Routerに渡され、Routerが最初の処理を行って必要なShardを決定し、そのShardにデータを送信します。Shardはローカルでプランニングを行い、インデックスの選択とクエリフラグメントの実行を行います。すべてのローカルトランザクションロジックはShard内で実行・処理され、Shardに保存されたデータは分散Aurora ストレージシステムによってバックアップされます。

トポロジーと可用性の観点から、実際のレイアウトを簡単に見てみましょう。従来のAuraクラスターでは、Subnet GroupとAvailability Zoneを指定し、インスタンスを作成して特定のAvailability Zoneに配置していました。LimitlessとShard Groupではそうする必要はありません。クラスター作成時にSubnet Groupは指定しますが、Shard Group作成時には、ノードを1つのAvailability Zoneに集中させるのではなく、複数のAvailability Zoneに分散配置します。RouterもShardも、Availability Zone全体に分散配置されます。これはより地域的なアプローチだと考えてください。単一のAZに集約すれば低レイテンシーが実現できますが、一度でもそのAZからフェイルオーバーが発生すると、すべてが1つのAZにあることを前提としていたシステムの一部が別のAZで動作することになってしまいます。
さて、想定していたよりもレイテンシーが若干低下した状況に陥っているわけですが、これは現実的な話です。カオスは起こるものです。エントロピーは増大します。時間の経過とともにフェイルオーバーは必然的に発生し、ノードが別のAvailability Zoneに移動する可能性は十分にあります。すべてを単一のAvailability Zoneで計画して機能が低下した状態になるよりも、最初からRegionレベルで設計しましょう。つまり、コンポーネントをAvailability Zone全体に分散させて計画するのです。そうすれば、Availability Zone間でフェイルオーバーが発生しても、アプリケーションは単一のAvailability Zoneのセマンティクスやレイテンシーを期待していないため、影響を受けません。


これが設計における考え方です。Auroraノードについては、シャード用のWriterノードがあり、さらに私たちが「Compute Redundancy」と呼ぶものがあります。これは、各シャードに対して別のAvailability Zoneにある冗長なフェイルオーバーターゲットを提供します。この図では、Compute Redundancyが2となっており、各シャードに対して2つの冗長ノードが別のAvailability Zoneに配置されていることを示しています。そのため、Availability Zone 1が失われた場合、シャード1はAvailability Zone 2かAvailability Zone 3のいずれかにフェイルオーバーできます。 Routerには特別なデータが保存されていないため、Availability Zone 1にあったRouterについては心配する必要はありません。Zone 2と3のRouterのスケールアップで負荷を処理するか、さらなるスケールが必要な場合は追加のRouterを配置します。

では、データの分散について説明しましょう。先ほど既にシャードテーブルの作成方法とCustomerテーブルの例を示しましたが、セッションレベルの変数を設定し、シャードテーブルを作成することを指定し、シャードキーとしてCustomer IDを使用します。その後、Customersテーブルを作成してシャード化します。実際には、同じシャードキーを持つ複数のテーブルを作成することができます。セッションでこれを一度設定すれば、スキーマ内のテーブルを作成する際にそれが適用されます。PostgreSQLで確認すると、Customerテーブルを説明した際に、これがPostgreSQLのパーティションテーブルであることがわかります。



ここでのパーティショニングには、いくつかの側面があります。私たちは「Hash Range Partitioning」と呼ぶものを追加しました。1つまたは複数のカラムで構成されるシャードキーを64ビット空間にハッシュ化し、その64ビット空間の範囲を異なるシャードに割り当てます。下部を見ると、パーティションのリストがあり、これは4つのシャードそれぞれにおけるこのテーブルのハッシュキー範囲を示しています。 私たちは範囲を割り当て、それらを各シャード上のテーブルフラグメントと呼んでいます。つまり、Customersテーブルがあり、各シャードにそのフラグメントがあり、そのフラグメントにはハッシュ値の範囲が含まれています。 Routerにはデータは保存されませんが、テーブルフラグメントへの参照を持っており、異なるキー範囲に対応する全シャードへの参照を保持しています。これによってRouterはクエリを計画し、適切な場所に実行を振り分けることができます。



このシステムが水平方向のスケールアウトを提供することについて説明してきましたが、シャードの1つが処理しきれないほど忙しくなったり、保存されているデータが多すぎる場合はどうなるのでしょうか?これを「Shard Split」と呼んでいます。1つのシャードを取り、そのシャード上のキー範囲の一部を新しいシャードに分割します。ここでは、最後のシャードが2つの小さなシャードに分割されているのが分かります。分割の方法として、Aurora Storageに組み込まれているテクノロジーを活用しています。皆さんがご存知かもしれないAuroraの機能として、既存のボリュームの高速なCopy-on-Write方式のコピーを作成できるVolume Cloningや、ストレージレベルでレプリケーションを行うGlobal Databaseがあります。これらの機能をここでも活用しており、Shard Splitを実行する際には、分割対象のシャードのCopy-on-Writeクローンを作成します。ストレージレベルのレプリケーションを使用して同期を保ち、その後、古いシャードと新しいシャードを分割し、それぞれのシャードに該当しないデータ部分を削除します。
私たちは、シャード分割プロセス中にストレージレプリケーション機能を活用することができます。また、Routerが大きくなるにつれてRouterを追加することができ、すべてのデータReference Tableへの参照を持つことになります。

Reference Tableとは、シャードテーブルと頻繁に結合したいものの、スケールアウトする必要のないテーブルを指します。Reference Tableでは、より大きな集約ストレージやスループットを実現する必要はありません。主に読み取り用ですが、書き込みも可能で、強い整合性のある書き込みを実現できます。シャードテーブルと同様に、RouterからReference Tableへの参照が存在します。シャードテーブルとは異なり、すべての行が各シャードに存在するため、より高速な操作のためのJoin Push Downが可能です。強い整合性を持つACID書き込みを実現しており、書き込み時にレプリケーションラグは発生せず、すべて強い整合性が保たれます。


では、トランザクションについて説明しましょう。このシステムの設計目標は、READ COMMITTEDやREPEATABLE READ、 つまりSnapshot Isolationにおいて、単一システムであるかのような一貫したビューを持つ、従来のPostgreSQLと同じセマンティクスを提供することでした。私たちはAurora PostgreSQLのセマンティクスをできる限り維持しようと努め、分散コミットの処理や分離の問題について考える必要なく、分散システムでありながら同じトランザクション動作を提供することを目指しました。

これには複数の課題がありました。分散システム内のすべてのノードがトランザクションを調整する場合、スケーラビリティが大きく制限されてしまいます。システムは適切にスケールせず、通信が多くなり、ノードを追加するほど状況は悪化します。リレーショナルデータベースでは何でもできるため、データベースエンジンはコミット時まで、そのトランザクションで何が起こるかを知ることができません。APIでヒントを提供することもできますが、それは互換性の問題を引き起こすでしょう。トランザクションは複数のステートメントで構成される可能性があるため、あるシャードで開始したトランザクションが、別のシャードに対するステートメントを送信することがありますが、その両方で同じトランザクションの一貫したビューを維持する必要があります。これは、部分的な実行が異なるタイミングで行われ、ノードとトランザクション間の順序を維持する必要があるため、困難です。さらに、バックアップとリストアを行う際も、単一システムと同様の一貫性を確保したいと考えます。独自のシャードシステムを運用した経験がある方なら、これがいかに困難かご理解いただけるでしょう。

これらがAurora PostgreSQL Limitless Databaseで提供されるACIDプロパティです。単一ノードのPostgreSQLと同じセマンティクスで、READ COMMITTEDまたはSnapshot Isolation(REPEATABLE READとしても知られる)を提供します。また、External Consistencyという利点も備えています。これは、トランザクションをコミットし、システムの外部からそのコミットを確認した後に発生する実時間上のイベントが、システム内でも必ず同じ順序で発生することを保証する特性です。これは多くの分散データベースが持っていない、分散システムならではのユニークな特性です。
PostgreSQL Limitless Databaseには注目すべき特徴がいくつかあり、External Consistencyについて説明した優れた論文や事例がオンラインで公開されています。マルチシャードの書き込みはアトミックで、コミット時にアトミック性が保証されるシャード間での書き込みやトランザクションを実行できます。あるシャードが失敗した場合でも、分散コミットの下で通常のACIDプロパティが得られるため、書き込みの不整合を心配する必要はありません。また、DDLはPostgreSQLと同様に、すべて強い一貫性を持ち、トランザクショナルです。
PostgreSQLでは、DDLは常にRead Committedで実行されますが、これはLimitless Databaseでも同様です。また、任意のSQL接続からDDLを開始できます。特別なコーディネーターに接続する必要はなく、どこからでも開始できます。現在のAuroraと同様に、クラスターレベルでスナップショットを取得し、クラスターレベルでリストアを開始できるシングルシステムバックアップを提供しています。これはすべてのシャードで完全に一貫性があるため、個々のシャードでバックアップやリストアを管理する必要はなく、単一のクラスターレベルで実行するだけです。

では、トランザクションが実際にどのように実装されているかについて説明しましょう。まず、PostgreSQLがMVCC(Multi-Version Concurrency Control)をどのように実現しているかを簡単に確認してみましょう。これは簡略化した例で、実際にはもっと複雑ですが、十分な理解を得るためにはこの程度で構いません。PostgreSQLのスナップショットは常に「現時点」として取得されます。これから説明する中で「現時点」と「その時点」について触れますが、PostgreSQLのトランザクションスナップショットは「現時点」、つまりPostgreSQL内でトランザクションが開始された瞬間が、スナップショットが取得される時点となります。

これは、PostgreSQLが現在のXID(トランザクションID)を把握していることで実現されています。XIDは単なるシーケンス番号です。システムは実行中のすべてのトランザクションのトランザクションIDを記録します。システムをロックしてコミットが通過できないようにし、実行中のトランザクションをすべて記録した後、非常に素早くロックを解除します。行を確認する際には、行に記録されているトランザクションIDと、現在のトランザクションID、および実行中リストに含まれる任意のトランザクションを比較します。
PostgreSQLの行を参照する際、それらは見えるか見えないかのどちらかです。見えない行は、あなたのトランザクションからは参照できないはずのものです。例えば、あなたのトランザクションの後に書き込まれた行や、まだコミットされていないトランザクションによって書き込まれた行、あるいはあなたのトランザクション開始時に実行中だったトランザクションによって書き込まれた行などです。それ以外の行はすべて参照可能です。これには自分自身のコミットされていない書き込みも含まれます。これが現在の仕組みですが、同じトランザクションスナップショットが異なるノードで異なるタイミングで必要となり、かつ一貫した視点を維持したい分散システムでこれを実装するのは非常に困難です。

Limitlessでは、現在時点ではなく、その時点でのスナップショットを取得します。Transaction Routerはクライアントからクエリを受け取り、スナップショット時間を確立します。Routerがクエリを受け取った時点が「現在時刻」となります - Routerはシーケンス番号ではなく実際の時刻を設定し、このタイムスタンプをクエリフラグメントと共にShardsに送信します。Shardsは受け取った過去の時点でローカルスナップショットを作成します。これにより、複数のShardにまたがるスナップショットが可能になり、各Shardが全く同じ時点でスナップショットを設定できるため、単一システムと同様のデータの一貫したビューを得ることができます。トランザクションの可視性はシンプルになります - その時点より前にコミットされたかどうかだけです。コミット済みなら見えますし、そうでなければ見えません。これにより、いくつかの興味深い考慮点が浮かんでくるかもしれません。

そのような考慮点の1つは、これらのシステムそれぞれが異なるクロックを持っているという事実です。誰のクロックも完全に同じではありません。ここにいる皆さんは携帯電話や腕時計を持っていますが、 ドリフトや不正確さのために、誰一人として全く同じ時刻を示していません。歴史的に見ても、複数システム間でWall Timeに依存することは、クロックが同期していないため機能しませんでした。しかしAWSは、データセンターのクロックインフラストラクチャに多大な投資を行い、ドリフトが制限された高い信頼性を持つクロックを実現しました。
これが意味するところは、次のスライドで詳しく説明しますが、マシンは自身が考える時刻を把握しており、さらに重要なのは、実際の時刻が特定の時点より確実に後であり、別の時点より確実に前であることを知っているということです。例えば、今この瞬間の正確な時刻は分かりませんが、このトークが1:30に始まり2:30に終わることは分かっているので、おそらく2:00頃だと推測できます。人間の世界では1時間の幅は精度が良くありませんが、EC2内ではこの幅がマイクロ秒レベルまで縮小されます。

EC2のBounded Clocksは、皆さんも利用可能なEC2の一部である Amazon Time Sync Serviceに基づいています。これは非常に高品質な時刻ソースを提供します。TimeチームはClockBoundというオープンソースのユーザースペースデーモンを提供しており、最早時刻と最遅時刻の範囲内で時刻を提供します。EC2システム内では、通常p99で1ミリ秒以内の差に収まり、実際の時刻がそのミリ秒以内であることを保証します。
Peter DeSantisが昨年のMonday Night Liveで話したように、一部のリージョンとホストで利用可能な新しいアーキテクチャがあります。これは屋上のアンテナからインスタンスのNitro Cardのクロックソースまでの特別な配線を使用し、グローバルなマルチリージョンで数十マイクロ秒以内の時刻の制限を実現します。この不確実性の幅が非常に狭いため、時刻に関して高い信頼性を持つことができ、データベース内で非常に小さな追加レイテンシーでエラーのない分散時間ベースのトランザクションを実行するアルゴリズムを構築できます。



それでは、Clockを使用した分散型の Repeatable Read transactionの実際の動作について、例を使って説明させていただきます。Transaction oneが Repeatable Read isolation levelで開始され、customer IDとorder IDを使ってorder tableからorder statusを選択します。Routerは時刻(例えば時刻100)を取得し、 customer ID 619を持つShardに対してtime 100のスナップショットを使用してクエリを実行します。そこでのorder statusは「filling」となっています。





次にTransaction twoが開始されます。Routerは時刻103を取得し、異なるShard上の別のcustomer(customer 801)のorder statusを選択します。orderが「filling」であることを確認し、そのcustomerとorderのstatusを「shipped」に更新します。RouterはそのShardに対してone-phase commitを実行し、commit時刻として110を取得し、通常のTransactionと同様に、ディスクに永続化された時点でcommitをクライアントに通知します。Clock error boundは、マルチAZのディスクレイテンシーよりもはるかに小さいため、自然と解決されます。Clockの正確性を待つ必要は一切ありません。実際、非常に大規模なノードで250万の同時commitを実行していますが、Clock weightは全くありません。Clock driftが非常に大きい場合はweightを使用しますが、実際にはその必要性は見られていません。
Transaction threeが開始され、先ほど更新したこの行を選択すると、shippedになっていることが確認でき、Transaction時刻は100と25を取得します。
ここで、スナップショット時刻100で開かれたままのTransaction oneに戻ります。このorderをもう一度選択します(customer 801のorder 80)。これは801に触れる初めての機会であり、このShardに触れる初めての機会です。受け取るstatusは「filling」です。他のTransactionの結果は見えません。なぜなら、まだ古いTransactionスナップショットの中にいるからです。これはPostgreSQLの標準的な動作ですが、重要なポイントは、PostgreSQLと同じ動作を分散システムで実現したということです。

複数のShardに対して書き込みを行う場合、すべての参加者間でのdurabilityを確保するためにtwo-phase commit protocolを使用します。これはTransactionを発行したRouterによって調整されます。このアルゴリズムにより、すべてのShardが同じcommit時刻でcommitすることが保証されるため、commit時刻に基づく可視性チェックを行う場合、複数のShardへの書き込みはすべて同時に可視化されます。複数のShardに触れるTransactionでcommitを行う場合、commit時のレイテンシーは単一のShardへのcommitと比べて2〜3倍高くなります。単一のShardへの更新の場合は1回分のレイテンシーで済みますが、複数のShardにまたがる更新の場合、two-phaseプロトコルを実行する必要があるため、commit自体のレイテンシーが2〜3倍になります。

トランザクションについてまとめますと、PostgreSQLと同じセマンティクスを維持しており、読み取りは常に一貫性が保たれています。クロックによる読み取りの遅延は発生しません。単一シャードへの書き込みを含むコミットは、クロックの関係でノード間の調整が不要なため、毎秒数百万件という線形なスケーリングが可能です。また、分散コミットはアトミックです。
クエリ実行とパフォーマンス最適化

次にクエリとパフォーマンスについて説明しましょう。基本的に、これはAurora PostgreSQLです。PostgreSQLのワイヤー互換性を持ち、PostgreSQLのパーサーとセマンティクスを備えています。SQLの広範な機能をカバーしています。分散システムでは利用できない機能が若干ありますが、かなり広範なカバレッジがあり、GAの時点で厳選されたExtensionをサポートしています。これにはPostGIS、pgvector、その他多くの人気のExtensionが含まれており、今後もさらに追加していく予定です。

クエリ実行の基本について、私たちはPostgreSQLのテクノロジーを活用しています。メタデータのセットアップには、パーティショニングとPostgreSQLのForeign Tableを使用しています。PostgreSQLのForeign Tableは、他のノードのデータにアクセスできるフェデレーションシステムです。ただし、一般的なPostgreSQLのForeign Data Wrapperをそのまま使用しているわけではありません。より良いパフォーマンスを実現するためにクエリエンジンと実行エンジンのコア部分を強化し、トランザクション機能や通常のPostgreSQLを大幅に改善した独自のカスタムForeign Data Wrapperを開発しました。

クエリフローについて、Routerはクライアントからクエリを受け取り、どのシャードに何を送信し、どのようなJoinを行う必要があるかを計画します。トランザクションコンテキストと共に部分的なクエリをシャードに送信します。シャードはRouterからクエリを受け取り、ローカルで計画を立て、結果をRouterに送り返します。単一シャードのクエリであれば、Routerは結果を直接クライアントに転送できます。マルチシャードの場合は、結果を送信する前にローカルでのJoin、フィルタリング、集計が必要になることがあります。

このシステムのアーキテクチャで特に強調したい点が一つあります。シャード化されたシステムで最高のスケールとパフォーマンスを得るために考慮すべき点として、Localityが挙げられます。Localityは最高のパフォーマンスを実現するための鍵となります。そのため、各シャードに存在するReference Tableについて説明してきたわけです。
同じShard keyの値を共有するテーブルを同じノードに配置する、Co-locatedテーブルについて説明します。データに可能な限り近い場所で実行を行い、データを実行場所まで引き上げることを避けたいため、Localityを維持することで最高のスケーラビリティと最低のレイテンシーを実現できます。
Customer、Order、Tax rateテーブルを使用した簡単な例を考えてみましょう。特定のCustomer IDに対してCustomerとOrderのJoinを行い、さらにTax rateとJoinする場合、Customerレコードが1つのShardに、そのOrderが別のShardに、さらにTaxが別のShardにある場合、3つのノードにクエリを実行してデータを集める必要があります。これではノードを追加してクエリを増やしても、良好なスケーラビリティは得られません。しかし、それらのCustomerレコードをTax rateテーブルと一緒にCo-locateすると、単一のShardにプッシュできるため、1つのShardのみが関与することになります。多くのShardで多くのこのようなクエリを実行する場合、それらは独立してスケールします。これによりノード間のメッセージングが減少し、データの移動が減り、キャッシュを効果的に活用できるため、Localityを維持するようにスキーマを設計すれば、優れたパフォーマンスを実現できます。

PostgreSQLのいくつかの機能を強化しました。クエリプランを表示するExplain出力を強化し、これをRouterで実行すると、Shardが生成したプランが表示されます。プランナーは、クエリが単一のShardに向かうことを認識した場合、特定のショートカットと高速な実行パスを実行します。Explain出力では、最高のパフォーマンスを示す「Single Shard Optimized」が表示されます。これはExplain出力やPG Stat Activityなどの機能で確認できます。システム全体で実行されているすべてのクエリを表示するLimitless Stat Activityを強化し、どのクエリがSingle Shard Optimizedであるかどうかを示すようにしました。また、単一のシステムのように1つのSQL接続から管理できるようにツールを強化し、システム全体のロック、クエリ、Wait Eventを確認できるようにしました。


これはZip CodeとOrdersのJoinを行うJoin Push Downの例です。Join全体がRemote SQLにプッシュダウンされ、Single Shard Optimizedとなっていることがわかります。追加したもう1つの重要な機能がFunction Distributionです。Shard keyの例として同じCustomer IDで操作する10個のステートメントからなるトランザクションを考えてみましょう。これらのステートメントを1つずつRouterに送信すると、プランを立て、Shardに送信し、結果を受け取るという処理を繰り返します。これらをFunctionやStored Procedureの中に入れたとしても、Routerで実行されるそのStored Procedureは依然として1つずつステートメントを実行し、Shardとの往復が発生します。

Function Distributionでは、FunctionのパラメータとしてShard keyを使用して、Functionをプッシュダウン用にマークできます。AWSのドキュメントには、Function DistributionとLimitless_distribute_functionについての説明があり、これを使用してSQL Functionをプッシュダウン用にマークします。ここでもLocalityが重要です - Function全体をShardにプッシュできれば、このトランザクションに10回の往復が必要なくなります。私たちはTPC-Cベンチマークでこれを広く使用しており、トランザクションをFunctionに分解し、Function Pushdownを行うことで、1分間に数百万のNew Orderを達成しています。Function Distributionは並列処理に不可欠です。Single Shardで得られる速度について多く話してきましたが、Multi Shardについてはどうでしょうか?実際、一部の操作はMulti-Shardクエリの場合に非常に印象的なパフォーマンスを示します。なぜなら...
Limitless Databaseの実性能デモンストレーション
大量のデータに対して何らかの処理を実行する必要があり、その処理が並列実行に適している場合があります。例えば、インデックスの作成などがそうです。1つのPostgreSQLノードに30テラバイトのテーブルがあり、そこにインデックスを作成する必要がある場合、1〜2分かかります。しかし、そのテーブルを多数のShardに分割すると、実際には多数の小さなインデックスを並列で作成することになり、ほぼ線形のスピードアップが得られます。同様のことがAnalyze、Vacuum、Count、Sum、Min、Maxなどの集計にも当てはまります。これらは並列実行が可能で、ほぼ線形のスピードアップが得られます。通常のSelect文で複数のShardにまたがる必要がある場合もありますが、そのような場合も可能な限りShardを跡って並列実行します。

スケールにおける低レイテンシーの例を1つご紹介したいと思います。これは、us-east-1のGA版システムで実運用環境において実施した実験です。PG Benchを使用してワークロードを生成していますが、これは100億行のテーブルを多数のShardに分散させた上での単一のランダムなUpdate文です。システムに十分な負荷をかけるために、24 XLホストを3台使用する必要がありました。ここでは3台の大規模なクライアントドライバーが稼働しており、それぞれが1秒あたり80万以上のUpdate、Commitを実行しています。全て合わせると250万以上になり、観測されたレイテンシーは約2.3〜0.4ミリ秒でした。
これは非常に大規模な負荷です。1秒間に数百万のトランザクションを処理することは簡単ですが、多くの場合それは読み取りトランザクションや単純なKey-Value検索です。大量のデータのUpdateやInsertは、1つの大きなバッチで実行し、最後に1回だけCommitすることで実現できます。しかし、同期的なCommitこそが、実際のパフォーマンスとどれだけの作業ができるかを決定づけます。ここで強調しておきたいのは、これらは実際にデータベース内で独立したCommitが行われているということです。これらの3つのクライアントがエンドポイントに接続し、1秒あたり250万のCommitを実行しているのです。
まとめと今後の展開

それでは、Anumさんにバトンを渡します。ありがとうございます、Dave。では、今日から何ができるのでしょうか?これは現在一般提供されているので、APIを使用するか、コンソールを開いて今すぐLimitless Databaseクラスターを作成することができます。本日のまとめとして、システムをそのレベルまでスケールする際の課題についてお話ししました。Limitless Databaseは、Daveが説明したように、1秒間に数百万のWrite トランザクション(これらはCommitです)を処理し、ペタバイト規模のデータを管理するのに役立ちます。このシステム全体を支えるスケーラブルなアーキテクチャ、データ分散の仕組み、クエリとトランザクションの動作について説明しました。今すぐドキュメントにアクセスして詳細を確認し、コンソールで始めることができます。


そして、関連するセッションをいくつかご紹介します。一部はすでに終了していますが、YouTubeで動画を見ることができます。写真を撮る時間を少し設けさせていただきます。そして最後に、セッションのアンケートにぜひご協力ください。皆様、ご参加ありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion