re:Invent 2024: AWS DynamoDBのデータモデリング基礎と実践テクニック
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Data modeling core concepts for Amazon DynamoDB (DAT305)
この動画では、DynamoDBのPrincipal Solutions ArchitectのJason HunterとSean Shriverが、DynamoDBのデータモデリングについて解説しています。電話帳のアナロジーを用いてPartition KeyやSort Key、LSI、GSIの概念を分かりやすく説明し、Write Unitsの最適化やコスト削減のテクニックを紹介しています。特に、String Setを使った正確なカウンティング手法や、Point-in-time Recoveryでのインクリメンタルエクスポート機能による復元コストの大幅削減など、DynamoDBならではの実践的なテクニックが語られています。また、OpenSearch Serviceとのゼロ ETL連携機能による検索機能の実装方法など、DynamoDBの活用における具体的なソリューションが示されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
DynamoDBデータモデリングの基本:電話帳のアナロジー


皆さん、月曜の朝からお時間をいただき、ありがとうございます。私はDynamoDBのPrincipal Solutions ArchitectのJason Hunterです。そして、こちらがSeanです。皆さん、こんにちは。私はSean Shriverと申します。DynamoDB Solutions Architectをしています。AWSには11年半在籍しており、 最初はPremium Supportから始めて、約10年前にDynamoDB SAになりました。これはAWSの認定資格の一つです。DynamoDB SAとしては8年半の経験があり、世界で最も長くDynamoDB SAを務めている者です。私たちが行き詰まった時は、彼に相談するんです。つまり、最終的な判断はSeanに委ねられているというわけです。

本日は、DynamoDBの基本的なデータモデリングの概念についてお話しし、皆さんと認識を合わせたいと思います。これまでにDynamoDBでデータモデリングをされた方は何人いらっしゃいますか?すごいですね。およそ半数の方がご経験があるようです。それでも、きっと有益な情報をお伝えできると思います。 毎秒数千件のリクエストを処理するような本格的なスケーリングを実現するための、より高度なテクニックについてもご紹介していきます。まずは、たとえ話から始めましょう。


このような講演で最も難しい部分は、DynamoDBを初めて使う方が途中で置いていかれないようにしながら、かつDynamoDBに詳しい方が最初の15分を退屈に感じないようにする、そのバランスの取り方です。 そこで、私なりの工夫をご紹介します。DynamoDBのデータモデリングを電話帳に例えて説明してみましょう。 図書館にある電話帳のようなものです。電話帳、覚えていらっしゃいますよね。

スマートフォンに全ての連絡先が入っている時代の前は、本を手に取ると側面に都市名が書かれていて、中は姓でソートされていました。例えば、San Joseを開いても「Jason」ではなく、姓の「Hunter」で探すことになります。そしてそこに電話番号が載っているわけです。ここで、DynamoDBについて多くの著作のあるAlex DeBrieに感謝を述べたいと思います。彼が電話帳のアナロジーを思い出させてくれたので、私はそのアナロジーを更に発展させてみました。
DynamoDBの構造と機能:Partition Key、Sort Key、LSI、GSIの解説
電話帳では、前の方にホワイトページがあり、本の外側には都市名が書かれています。ここでは例としてLas Vegasを挙げていますが、これがDynamoDBでいうPartition Keyに相当します。次にSort Keyがありますが、これは名前に当たります。電話帳は通常、姓でソートされていましたね。ここではHunter Jason、JW Marriott、Shriver、The Venetianといった具合です。その後に実際のデータ、つまり電話番号や郵便番号、事業者タイプなどの情報が続きます。
このような形式の場合、DynamoDBのデータ保存方法とよく似ています。なぜなら、データの検索が非常に高速だからです。では、できることとできないことは何でしょうか?都市と姓名が分かっていれば、その人を素早く見つけることができます。これは二分探索のようなもので、とても速いのです。全てのHunterさんや、全てのShriverさんを見つけることができます。また、HやHUで始まる姓も全て見つけられます。でも、全てのJasonを見つけることはできるでしょうか?それはできません。なぜなら、その順序では並んでいないからです。もちろん、本全体を探せば見つかりますが。郵便番号で探せますか?いいえ。この電話番号の持ち主は誰か分かりますか?それもできません。このPartition KeyとSort Keyの組み合わせでは、できることとできないことがあるのです。

電話帳にもこの課題があったので、Yellow Pagesが追加されました。本の後ろの黄色いページを覚えていますか?あれは業種別インデックスで、名前ではなく配管工や便利屋といった業種で並べられていました。同じ本の中で、Vegasというこのpartition keyの構成で、カジノというエンティティタイプがあり、全てのカジノが載っている。あるいはホテルというタイプで全てのホテルが載っている。これはDynamoDBのLocal Secondary Indexesの仕組みとよく似ています。同じPartition Keyを使いながら、異なるSort Keyで一緒に保持されているのです。


DynamoDBには電話帳に似た別の機能もあります。それがGlobal Secondary Indexです。本の背表紙が都市名ではなく、例えば郵便番号になっているようなものです。この場合、ある郵便番号に対して全てのエントリーが含まれているわけではありませんが、GSIのPartition Keyとして郵便番号を使い、GSIのSort Keyとして名前を使っています。 これで何ができて何ができないのでしょうか?都市は分からないけれど郵便番号は分かっている場合(郵便番号と都市が完全に一致しないこともありますから)、その人を見つけることができます。
ただし、これは別の本になります。背表紙が異なるからです。一方は都市で分類され、その都市に関する全ての情報が中に入っていて、もう一方は郵便番号で分類されています。この考え方はDynamoDBのGlobal Secondary Indexesにも当てはまります。別の保存場所、つまりデータが保持される別の場所があるのです。

これがDynamoDBの検索の仕組み、つまりPartition KeyやKey、LSI、GSIなどの理解に役立つ例えです。では、これらのエントリーを変更する必要がある場合のアップデートはどうでしょうか?ベーステーブルで更新を行います。LSIにも反映させたい、GSIにも反映させたい。でも簡単にするために、一箇所だけ、つまりベーステーブルだけを更新して、他の二つへの伝播は自動的に行われるようにするのがベストです。皆さんは専門家なので、LSIはすぐに反映されることをご存知でしょう。同じ本の中にあるからです。GSIは最終的には反映されます。速いですが、最終的にという意味です。別の本にあるからです。つまり、LSIは同じ、GSIは別、そして更新すると矢印が示すように、小さなストリームで伝播していきます。通常は1ミリ秒程度ですが、様々な理由でもっと長くなることもあります。
DynamoDBのスケーラビリティと分散アーキテクチャ




これが本の仕組みですが、本の保管方法について考えてみましょう。図書館にいることを想像して、これらの電話帳を探しに行くとします。 もし1つの図書館にだけ保管すると、問題が発生します。火事が起きれば、すべての電話番号を失ってしまいます。道路工事があった場合は、データは失われないかもしれませんが、アクセスできなくなってしまいます。 そこで、複数のコピーを保管するべきです。物理的に離れた3つの場所に、3つの図書館を設置し、それぞれ異なるAvailability Zoneに配置しましょう。 これで3つの図書館ができ、どの図書館でも電話番号にアクセスできるようになります。



3つのコピーを更新する必要がある場合、どのように対処すればよいでしょうか?各本のリーダーコピーを選出します。図書館全体でリーダーを決めるのではありません。なぜなら、そうすると全ての書き込みが1つの図書館に集中してしまうからです。その代わりに、各本が図書館間でそれぞれのリーダーを選出します。 実際の世界では、本を棚に置く必要があります。DynamoDBがこのような検索を行う場合、バックエンドに物理的な実体が必要になります。 これらを「棚」、あるいはPartitionと呼びます。図書館では、異なる組織方法を採用します。西棟は都市別の組織で、東棟は郵便番号別の組織というように、それぞれ異なる本の配置方法を取ります。

各棚にはサイズ制限があるので、最初に必要な棚の数を決める必要があります。デフォルトでは4つから始めます。これはDynamoDBでOn-demandテーブルを作成した場合のデフォルト値と同じです。この本棚には4つの棚があり、時間とともに分割されて変化していく様子に注目してください。これはAdobe Illustratorで作成したグラフィックで、私はとても気に入っています。時間が経つにつれて分割され、変化が見られるようになります。

これらの本を棚にどのように配置すればよいでしょうか?都市名があり、簡単に見つけられるようにする必要があります。自然な方法としては、アルファベット順に並べることでしょう。San Joseは「S」の領域に、Santa Claraも「S」の領域に、San Franciscoも「S」の領域に、San Mateoも「S」の領域に入れます。ここで問題が見えてきました。これは偏った組織方法です。アルファベット順以外に、どのような方法が考えられるでしょうか?Partition Keyのトポロジーに関係なく、均一な分布が望ましいのです。

解決策は、名前をハッシュ化して、そのハッシュに基づいて保存することです。入力の微細な違いが出力を大きく変えるため、ハッシュ値は非常に均一な分布になります。4つの棚があれば、Partition Keyがどれほど似通っていても、4つの棚にほぼ均等に分散されます。この作業は司書に任せることにしましょう。そのため、都市名をPartition Key(UIでの呼び方)またはHash Key(CloudFormationでの呼び方)と呼びます。


シェルフにはそれぞれ容量の限界があるため、人や都市を追加し続けると、いずれシェルフが一杯になってしまいます。そうなったらどうすればいいのでしょうか? 最も簡単な解決策は、適切な位置で分割することです。

容量制限によって拡張が必要な場合は、ちょうど実際の図書館のように真ん中で分割します。本を2つのシェルフに移動させて中間点で分割すれば、十分な成長の余地が生まれます。そして、DynamoDBのキー空間でも範囲が調整されていることに注目してください。これがパーティションが大きくなった時のDynamoDBの対応方法です。


では、ある都市やZIPコードがシェルフの容量を超えてしまったらどうでしょう?ニューヨークなどの大都市ではすでにこの問題に対処しています。その都市用に複数の本を作り、Sort keyである姓でアルファベット順に並べるのです。同じ都市のデータを異なる本に分けて複数のシェルフに分散させることができ、システムが適切な分割ポイントをSort keyから選択します。 実際の世界に置き換えて考えると、各シェルフには利用者が訪れることのできるスペースに限りがあります。そのシェルフへの読み書きのトラフィックが多くなりすぎた場合はどうするでしょうか?そんな時は、Seanにイラストをさらに拡張してもらうようお願いします。

はい、それは可能です。この場合、容量ではなくスループットの問題で、各シェルフがサポートできる処理量を超えたため、再度シェルフ間で分割を行います。これによってスループットは大幅に向上します。 DynamoDBは個々のアイテムレベルまで分割することができます。つまり、特定の名前だけを含む電話帳1冊分という小ささまで分割できるのです。必要に応じて、パーティションごとの最大読み書き容量を個々のアイテムに対して確保することができ、そのような分割も自動的に行われます。
このような仕組みのため、DynamoDBのパフォーマンステストは少し厄介です。最初の1分間で試したパフォーマンスは、10分後には異なる結果になっているでしょう。システムが拡張を続けるからです。これは毎日上腕二頭筋の強さをテストするようなものです。「結果が悪くなる一方だ、数値が上がり続けている」と思うかもしれませんが、それはまさにトレーニングを続けているからです。データベースをトレーニングすれば、データベースはより大きく、より強く、より良くなっていくのです。
DynamoDBのパーティション管理とキャパシティ制限

復習として、DynamoDBのパーティションを本棚のように考えてみましょう。これが3つのAvailability Zoneにレプリケーションされています。設計時には、すべてのテーブルにPartition KeyとオプションのSort Keyが必要です。Sort Keyは必須ではなく、都市名を数字で表すだけでも構いません。ただし、今回の電話帳のアナロジーではSort Keyを使用しています。また、イエローページのようなLSIと、図書館の別フロアのような異なる検索キーを持つGSIがあります。書き込みは常にベーステーブルに対して行われ、そこからインデックスに伝播します。

テーブルは、必要に応じたパーティション数で開始されます。Provisionedモードで10,000回の書き込みを要求した場合、その処理能力をサポートするために最低10個のパーティションが提供されます。最近、Warm Throughputを発表しました。これにより、On-Demandテーブルの作成時に必要なサイズと読み書きのレートを指定できるようになりました。つまり、必要な容量を備えた状態でテーブルが作成されます。これは図書館に何個の本棚が必要かを指定するようなものです。
パーティションには望ましいサイズがあります。大きすぎないようにする必要があり、ユーザーが気付かないうちにノード間を移動できる程度の小ささを保つことが重要です。10 GB程度を目安にし、それ以上大きくなりすぎないようにします。現在、パーティションには3,000 Read Units、1,000 Write Unitsという制限があります。読み込みの場合、1 Read Unitは4 KBで、Eventually Consistentな読み込みはその半分です。つまり、1つの本棚に対して、4 KBのEventually Consistentな読み込みを6,000回、1 KBの書き込みを1,000回行うことができます。
Partition Keyはパーティションへの割り当てに使用されますが、1対1の割り当てではありません。同じPartition Keyが異なる場所に分散される可能性があります。例えば、New Yorkが異なる本棚に配置されるようなイメージです。また、複数のPartition Keyが自然に同じパーティション上に共存することもあります。これが本棚の始まりで、1つの本棚には多くの都市が収納されています。DynamoDBをよく使用している方々にとっては楽しい話題だったと思います。そうでない方々も、これでSeanのコアデータモデリングの概念に向けて準備ができたのではないでしょうか。
DynamoDBのコアデータモデリング:Partition KeyとSort Keyの設計
皆さん、こんにちは。私はDallasを拠点としており、DynamoDBのコアデータモデリングの概念についてお話しできることをとても嬉しく思います。このプレゼンテーションの大部分を私が担当しますが、Jasonはいつでも割り込んで構いません。最後に時間が残れば、会場の皆さんからの質問も受け付けたいと思います。おそらく、会場から退出を求められる前に、ステージ前で質問を受け付けることになるでしょう。PKとSKについて話しますが、このプレゼンテーションの時点で、PKがPartition Key、SKがSort Keyを指すことはよくご存知だと思います。

Partition KeyとSort Keyを使ってテーブルを作成する場合、必ずSort Keyをアイテムに含める必要があることを明確にしておきたいと思います。この2つを組み合わせると、特定のPKとSKが行セレクターとなり、一意に行を特定することができます。DynamoDBを初めて使用する方は、この2つを組み合わせることで、DynamoDBのテーブル内の行を一意に特定できるということを覚えておく必要があります。

このプレゼンテーションを作成する際、PKとSKについて説明し、それらの適切な値について説明するというアイデアがありました。私のアプローチとしては、PKは2048バイト、Sort Keyは1024バイトという制限があることを文字通り説明しようと考えていました。しかし、Jason Hunterさんから、もっと意見を述べて具体的なガイダンスを提供すべきだとアドバイスを受けました。これらの制限に基づいて、Partition KeyとSort Keyに関する事実についてお話ししていきます。
従来、DynamoDBでデータをモデル化する際は、Partition KeyとSort Keyには文字列データ型を使用します。これをお勧めする理由は、キーのプレフィックスにエンティティ情報(人、グループ、役割などの名詞)を含めることができるからです。PKとSKの値を選択する際、UUIDを使用することもできますが、ラベルに関連付けられた一意の識別子を使用する方がはるかに良いでしょう。例えば、CIDのような装飾された名前を使用すると、123が顧客IDであることがわかります。

マネジメントコンソールを見るとき、これらの属性の名前を決める際に何を見ているのかを正確に知る必要があります。これはDynamoDBではKey Schemaと呼ばれています。PKとSKを使用することをお勧めします。これはテーブル全体で固定されます。これはテーブル作成後に変更できない要素の1つです。これらの属性名がDynamoDBテーブルのプライマリキーを定義します。これにより、バイトを節約することができます。これは、各Write Unitを最大限に活用し、短い属性名を使用してアイテムをできるだけ小さくする方法についてお話しするこのプレゼンテーションの一部です。前述のように、DynamoDBテーブルのエクスポートとインポートを必要とせずにこれらを変更することはできないので、最初の段階で適切な名前を付けることが重要です。

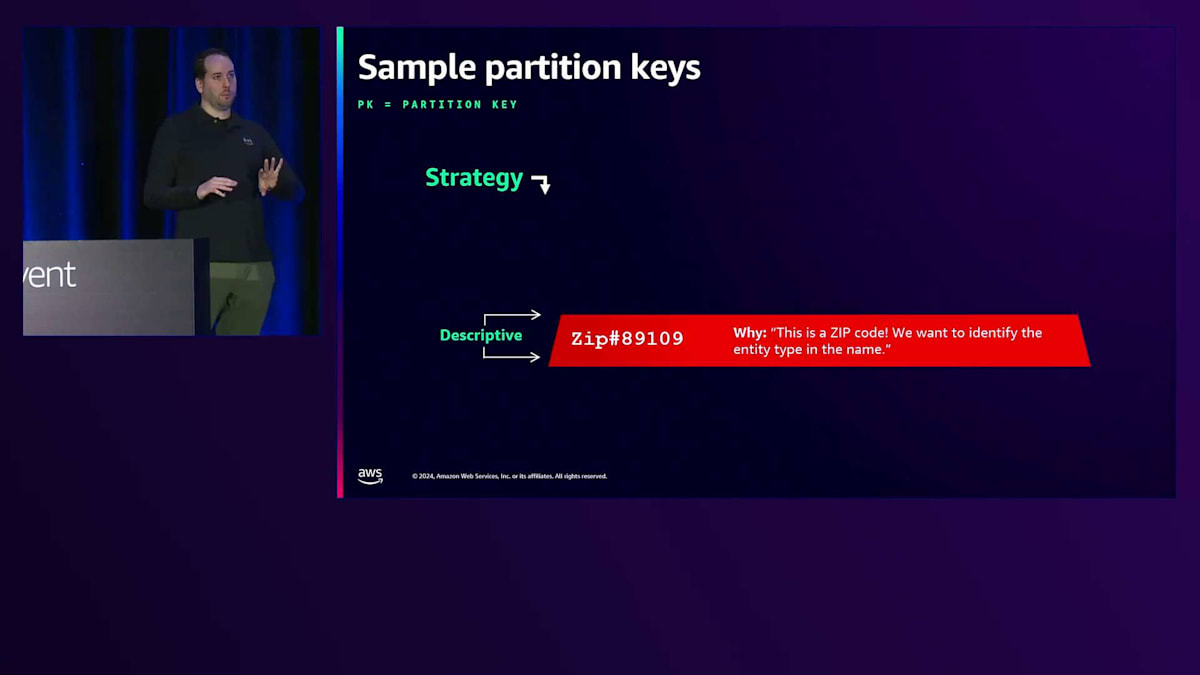

いくつかのサンプルPartition Keyについて話しましょう。オフィスに戻ってから会話で使用できる用語を紹介します。まず、より説明的なPrimary Key、Partition Keyについて説明します。エンティティタイプはラベル付けされ、PKのプレフィックスにそのタイプを使用します。そうすることで、89109がMGMグランドの裏口のドアコードではなく、郵便番号であることがわかります。これが最も伝統的なPKの構築方法です。
また、Primary Keyの末尾にShardを含めることもできます。一般的な設計パターンとして、ベーステーブルやGlobal Secondary Indexに対して「Write Sharding」と呼ばれる手法を使用します。これは、Keyの末尾に一定範囲の数字を付加し、書き込み時にそれを選択する方法です。0からNまでの数字をランダムに選ぶことも、計算されたSuffixを使用することもできます。この詳細については、計算されたSuffixの使い方や適切なKeyの選び方について解説しているドキュメントをご確認ください。
DynamoDBのデータモデリング最適化:アイテムサイズとWrite Unitsの削減

また、複数の値を持つKeyを使用することもできます。Primary Keyは関連データをまとめてコレクションを作成するのによく使用されます。この例では、郵便番号の下にMGM Grandのプロパティに関する情報を保存できます。ただし、DynamoDBでプロパティを更新する場合は、完全なPrimary Key値を知っている必要があります。つまり、そのプロパティがMGMに所有されており、89109に位置していることを知っている必要があります。なぜなら、DynamoDBではPartition Keyに対する完全一致の条件が必要だからです。
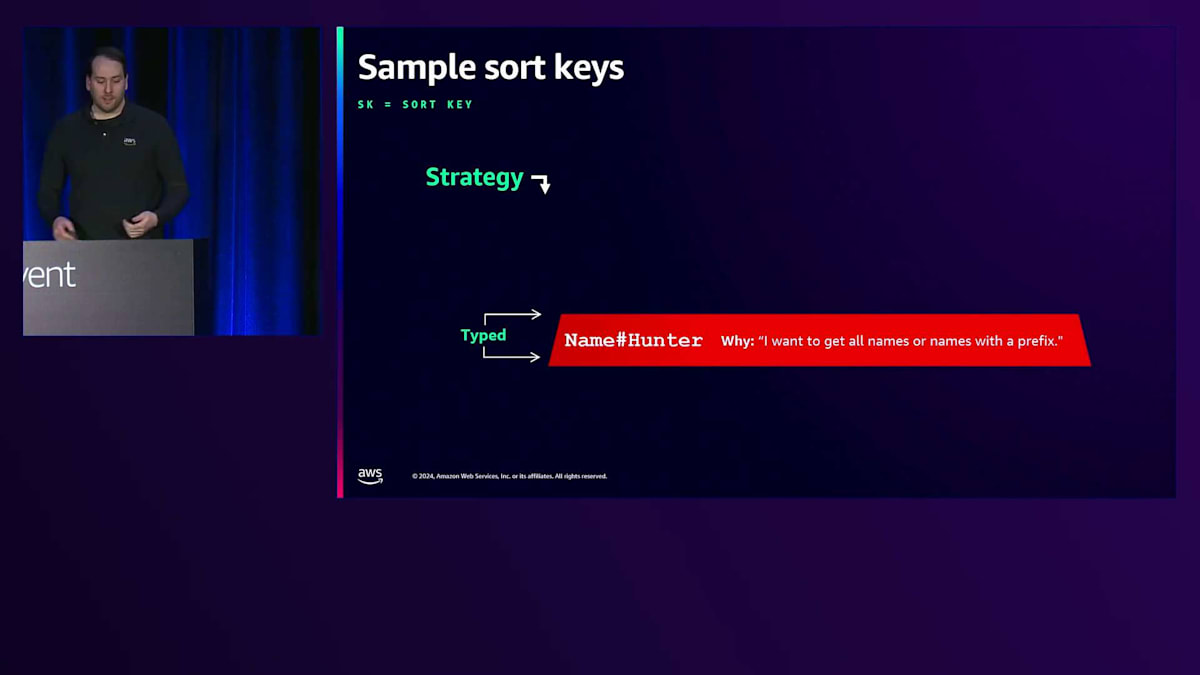
次に、Sort Keyについて、どのような形態があるのか見ていきましょう。Primary Keyを特定したら、その下のアイテムには一意のSort Key(SK)が必要になります。Sort Keyには多くの場合、タイプ情報を含めます。DynamoDBではこのKeyによってデータがソートされるため、Sort Keyと呼んでいます。APIではRange Keyと呼ばれていますが、Sort Keyの方が適切な名前だと思います。SKにタイプを含める場合、属性タイプをプレフィックスとして追加します。これにより、Partition Keyが郵便番号89109に等しい、かつSort Keyが「name_H」で始まるものを検索すると、Jason Hunterの情報を見つけることができます。
名前以外の属性でも異なるSort Keyを持つことができるので、郵便番号内のすべての名前を取得したり、その郵便番号内の他の情報を取得したりして、同じPartition Key下でまとめることができます。つまり、事前にグループ化してコレクションを作成し、そこには人だけでなく、ビジネスやプロパティなども含めることができます。

個人的に最もよく見かけるSort Keyの値は、タイムスタンプです。1970年1月1日からの経過秒数であるエポック値などがタイムスタンプとして使用され、これはデータのソートに最適です。2週間前から1週間前までのデータを取得したいという場合、DynamoDBはPartitionからそのデータを取得することができます。

Sort keyを構築するもう1つの方法として、階層的に作成することができます。関連データを一緒に保存する必要がある場合、例えば地理情報のように、アメリカ合衆国があり、その中に州があり、そしてメトロエリアがあるというような場合、Las Vegas, Nevadaのような形でキーの下に在庫情報を書き込むことができます。同じデータをUSA Nevadaのような、より広い範囲のキーの下に保存して、州レベルでの集計を作成することもできます。ただし、これらを維持し、最新の状態に保ち、データが確実にコピーされるようにすることは難しい作業です。これは1つのSort keyで3つの値を持つようなものです。USAの全て、Nevadaの全て、Las Vegasの全てを取得することができます。

では、新しいSQLデータモデルについて順を追って見ていきましょう。ここにいる皆さんに参加していただきます - Example Corpと呼ぶことにしましょう。皆さんにはチャットサービスのデータベーススキーマを構築することを考えていただきます。これはChatGPTのようなものかもしれません。会話やスレッドを持つデータモデルを見つけたいと思います。各チャットには、Temperature、Max tokens、使用しているモデル、バージョンなどの情報があります。私たちは、どのようなスループットレベルにも対応できる拡張性と低レイテンシーを実現したいと考えています。これら2つが必要な場合、DynamoDBがそのサービスとなります。

こちらが要件です。すべてのデータをユーザーベースで保存したいと考えています。ユーザーは複数のスレッドを持つことができます。私がモバイルデバイスで会話を始め、電話をポケットに入れ、ラップトップを開いて最新のスレッドを表示したいと思うかもしれません。これらのスレッドには、先ほど言及したような情報のメタデータがあります - 例えば、元のSystem promptが何だったのかを知りたいかもしれません。これはAWSなので、確実にスケールすることを確認したいと思います。特にスタートアップに関わっている場合は、最初からスケールを計画したいと考えています。とはいえ、このプロダクトを早く市場に出す必要があるので、最も基本的な設計から始めて、そこから改良していくことにします。
チャットサービスのデータモデル設計:スケーラビリティとコスト最適化

最初に、ユーザーIDの下にデータを保存します - これをPKにします。Sort keyには、最も一般的な情報から最も具体的な情報まで含むISO 8601形式の日付を使用します。これにより、各ユーザーの作成日でスレッドを見つけることができる自然なSort keyが得られます。同じ日に複数のチャットが存在することが予想されるため、各スレッドには一意のThread IDも持たせます。まずは、メタデータを独自のアイテムとして分割します。これには、先ほど言及したSystem promptやモデルタイプ、そしてTemperature、Max tokens、Top K、Top Pなどの設定が含まれます。

まとめると、作成日でソートされているため、最新のスレッドを取得するのは簡単です。しかし、Thread IDで何かを見つけようとすると、それがその中に埋め込まれているため、実際にはかなり複雑です。Thread IDで情報を検索する方法を考えてみてください - Global Secondary Indexを使用するかもしれません。メタデータを取得することができ、DynamoDBでメタデータを取得するいくつかの方法について話し合う予定です。
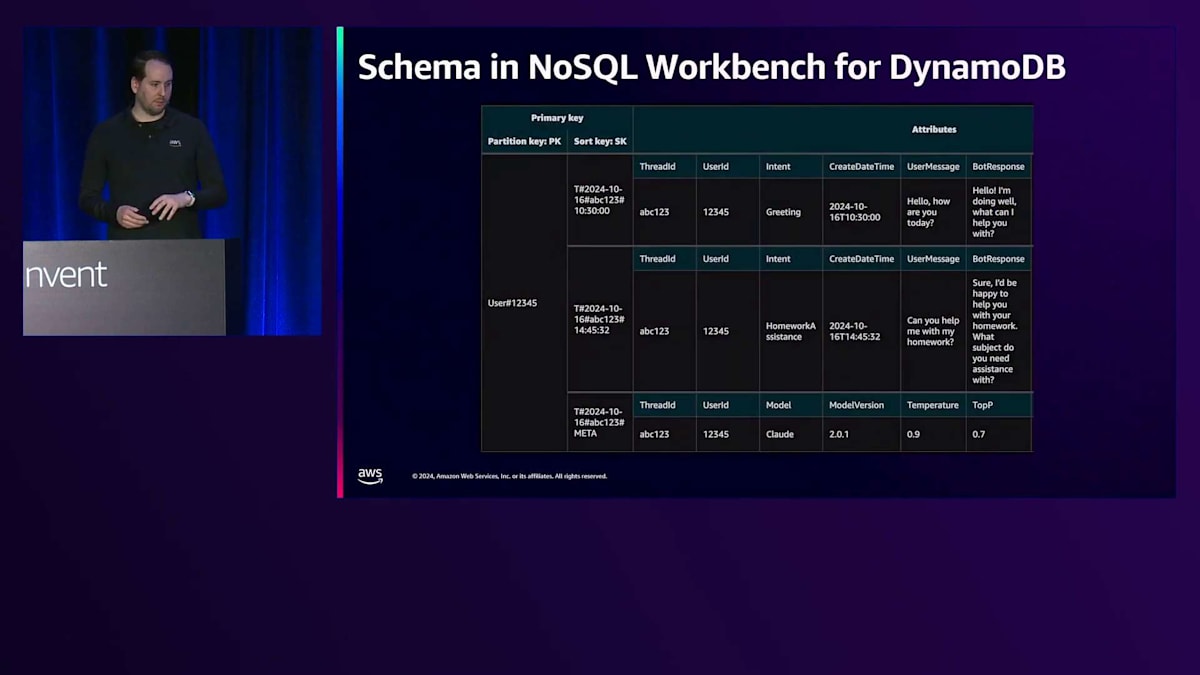
DynamoDB用のNoSQL Workbenchでこのモデルをどのように設計したか見ていきましょう。ここにPartition Key (PK)があり、これはuser123456のようにユーザー番号を含む形式になっています。PKはエンティティタイプを含むように記述的になっています。一番下には先ほど言及したメタデータの行があります。あまり変更されないけれども会話全体で共通するデータをここで分割しています。実際、その中の1つの要素はかなり頻繁に変更されますが、それについては後ほど説明します。
もう1つのデータタイプは、スレッド内の会話でメッセージが発生するたびに、それが個別のアイテムとして表示されるものです。潜在的な弱点として、フォームの回答で大量のテキストが貼り付けられる可能性があり、DynamoDBでのアイテムサイズの制限を考慮する必要があります。対策としては、gzipを使用してデータを圧縮し、バイナリデータタイプとして保存する方法があります。あるいは、そのデータをS3に保存し、DynamoDBのアイテムにS3のURIを保存する方法もあります。
現時点では、このデザインを実装して提供することを始めたばかりです。リレーショナルデータベースと比較して興味深い点は、ユーザーハッシュの扱い方です。これは、後でこのテーブルに、Partition Keyがユーザーだけではない何か別のものを追加したい場合があるかもしれないからです。現在はこれがユーザーIDだとわかりますが、将来的に異なるプレフィックスで他のものをこのテーブルに追加することもできます。このようにテーブルを再利用することは一般的な手法です。
Sort Keyにはスレッドを表すTハッシュを使用しています。しかし、このユーザーに関して、住所や設定など、他の情報も必要になるかもしれません。それらを同じテーブルの同じPartition Keyの下に配置することができます。なぜ複数のテーブルを使わずに、同じユーザーに関する異なる情報を同じテーブルに入れるのでしょうか?それは、ラウンドトリップタイムを削減できるからです。ユーザーに関するすべての情報を取得する必要がある場合、Sort Keyの条件なしで1回のクエリですべてのデータを取得できます。
もう1つの利点は、アクセスコントロールの面です。モバイルクライアントがDynamoDBと直接通信する場合、ユーザー12345へのアクセス権を読み取り専用で付与することができます。一時的な認証情報を使用して、DynamoDBから直接情報を取得できます。これは主要なアクセス経路ではないかもしれませんが、データ取得のバックアップオプションとして有効です。ここでは、PK/SKを使用して将来の拡張性を確保しています。将来的にPartition KeyとしてユーザーIDを使い続けるかどうかわからないため、単純にユーザーIDと呼ぶこともできますし、多くの人がそうしていますが、PKと呼ぶことで将来の選択肢を残しておくことができます。

SKについても同様で、特にThreadなどの具体的な名前は付けていません。将来的に別の用途で使いたくなるかもしれませんからね。また、各アイテムで属性が異なることにも気付くと思います。これは問題ありません。各アイテムが独自のスキーマを持っているからです。メタデータはモデルを持っていますが、他はその時点ではIntentであり、もはやリレーショナルではないのでそれで問題ないのです。 メタデータアイテムであるThreadメタデータだけを取得したいというユースケースがあります。新しいメッセージを追加するたびにタイムスタンプ(つまりupdate datetime)を更新するというのが基本的な考え方です。
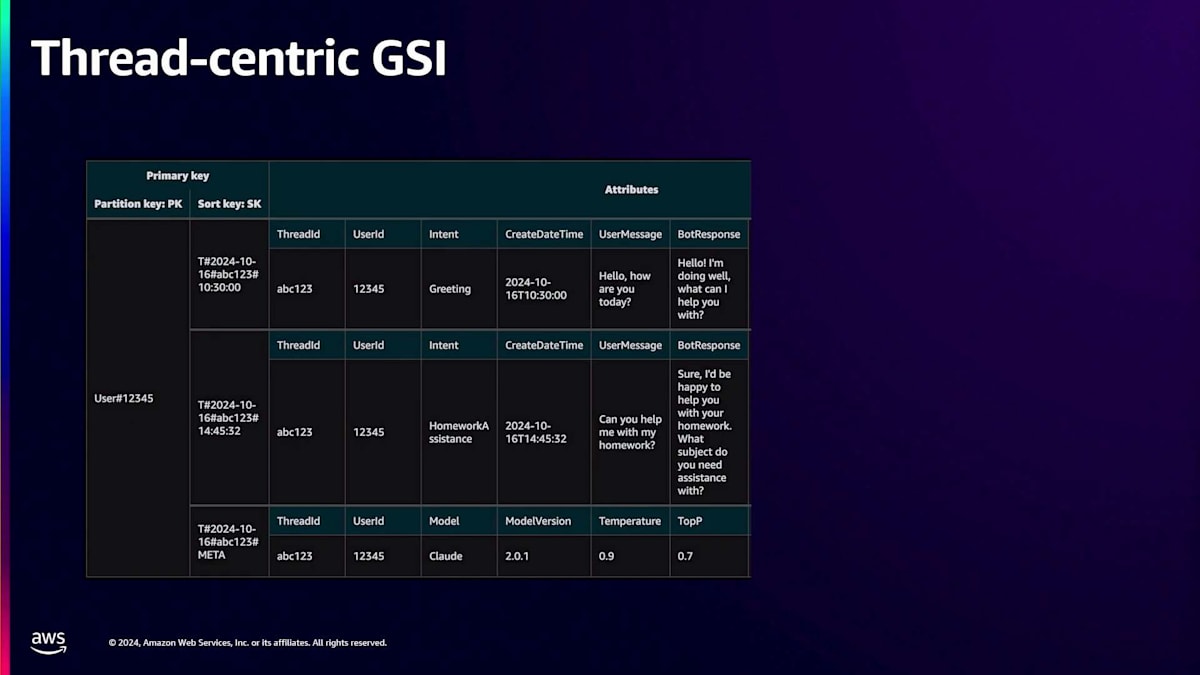
よくあるのは、最新のチャットを取得する必要があるケースです。GSIでタイムスタンプをインデックス化し、Partition KeyとしてUser ID、Sort Keyとしてタイムスタンプ(Tハッシュを含む)を使用します。電話帳や電話番号の話をしているので、ハッシュ記号は恐らくポンド記号と呼ぶでしょう。これによって、そのユーザーのGSIにある他のデータと区別することができます。そして、limit 10などと指定してアイテムを取得できます。 GSIの利点は、ベーステーブルからキャパシティの消費を分離できることです。
DynamoDBテーブルで代替のSort Keyが必要な多数の書き込みがある場合、LSIオプションを選択すると、最大スループットが半分、あるいはそれ以上に削減されます。これは、ローカルエントリを更新するためにキャパシティを消費する必要があるためです。例えば、単一のPartition Keyを持つDynamoDBテーブルで通常1秒あたり1000回の書き込み(1キロバイトの変更)が可能な場合、LSIでは500回に制限されます。さらに、LSIのエントリを変更する場合、古いエントリを削除して新しいエントリを挿入する必要があるため、333.3...回の書き込みに制限されます。つまり、LSIにはこのような制限があるため、私たちはGSIを優先しますが、妥協点があることも理解しています。

このデザインを見ると、このようなGSIを作成できます。注意すべき点は、GSIは結果整合性があるということです。つまり、書き込みがGSIに反映されるまでに多少の遅延があります。これはミリ秒、あるいは数十ミリ秒のオーダーであることがわかっています。インデックス名「GSI1-PK-GSI1-SK」はとても良いですね。これは私たちのデザインでよく使用されます。これが最初のGSIなのでGSI1とし、名前にPKとSKを含めています。カスタマイズが必要なケースももちろんありますが、一般的には、インデックスオーバーロードと呼ばれるこの戦略を使用できるGSIを作成したいと考えています。

GSIについて、他にどのような選択肢があり、そのトレードオフは何だったのでしょうか?これについて考えることには大きな価値があると思います。なぜこの方法を選んだのか、そしてユーザーのThreadの最新の状態を把握して、どこから再開すべきかを判断するという問題を、他にどのように解決できたのでしょうか?まず第一に、GSIは数十ミリ秒の遅延があるとはいえ、結果整合性で十分だと言えます。なぜなら、モバイルデバイスからWebクライアントに切り替えるなど、クライアントがデバイスを切り替える頻度はそれほど高くないからです。
LSIについては既にお話ししましたが、いくつかの欠点があります。先ほど触れたように、LSIは2つまでしか作成できないという制限があります。また、多くのお客様は10ギガバイトのパーティション制限がLSIにも適用されると考えがちです。少し説明させていただきますと - LSIのコレクションが10ギガバイトに制限されているのです。つまり、同じPartition keyで異なるSort keyを持つ場合、例えばUser IDがPartition keyで、スレッドのメタデータやタイムスタンプ、作成・更新時間がSort keyである場合、特定のユーザーに関連するコレクション全体が10ギガバイトに制限されます。さらに、LSIはテーブルの内部的な動作も少し変更します。
一般的に、お客様はGSIを使用することになります。DynamoDBテーブルを作成した後にLSIを追加することはできません。意外なことに、多くのお客様は、このようなインデックスが必要な場合、LSIやGSIを使用したくない場合、実際に2回の書き込みを行い、書き込みが完了するまで待機します。Put itemを2回実行して待機し、DynamoDBから書き込みが永続化されたという応答を受け取ってから、上流に成功を返します。
これを実現するより簡単な方法として、Transaction APIがあります。これは少し興味深い方法です。Transact write items呼び出しを使用してTransaction Write APIを利用できます。これはACIDトランザクションとしても知られており、一度に最大100アイテムまで変更でき、すべての操作が成功するか失敗するかのどちらかです。また、Client Request Tokenを提供することでべき等性も確保され、10分間の期間内で同じ操作が繰り返されないようにできます。ただし、Transaction Writeを使用する場合のデメリットは、コストが2倍になることです。1つのWrite Unitではなく、各フェーズに1つずつ、計2つ必要になります。


さて、トレードオフを検討してプロダクトをリリースしたものの、スケーリングの問題に直面し始めたとしましょう。誰かが請求書を確認し始めたり、収益を上げる必要があってメタリングを有効にしたい場合もあるでしょう。アイテムサイズの縮小、Capacity Unitの最大活用、そしてDynamoDBでは少し難しい可能性のあるカウンティングなど、これらの追加機能を実現するために何ができるでしょうか?幸いなことに、これについて説明するブログがあります。 DynamoDBの興味深い点の1つは、アイテムサイズを33%小さくできれば、コストも潜在的に33%削減できることです。
DynamoDBのコスト削減を望まない人はいないでしょう。データが頻繁に変更されない場合、アイテムに変更を加えると、アイテム全体を書き直すためのコストが発生することを、お客様は必ずしも認識していません。8KBのアイテムで1バイトの変更を行う場合でも、更新には8 Write Unitが必要です。Amazonではない小売業のお客様の例では、カタログに80,000の商品があり、毎日800,000の変更(主に価格情報の変更)が発生していました。アイテムサイズを16KBから10KBに縮小できれば、Write Unitのコストを大幅に削減できることになります。


メタデータの属性について見ていきましょう。モデルバージョンを圧縮処理にかけると、gzipやlz4などを試すことで、最終的なアイテムサイズをどこまで小さくできるか確認できます。この例では、5.1キロバイトまで圧縮できたとしましょう。これはかなり良いサイズですが、それでも6 Write Capacity Unitsが必要になります。圧縮処理はすべてクライアントサイドで行われるため、AWSから提供されるクライアントを使用してこれを実現することはできません。データを保存する際は、バイナリデータ型として保存し、基本的にはbase64エンコードされたオブジェクトとして扱います。コード内での表現形式を圧縮し、base64エンコードして、DynamoDBのバイナリデータ型として保存するという流れになります。


Write Unitsの数を削減するためにデザインをさらに改善していく中で、先ほど説明した「小さな変更でもアイテム全体を書き直す必要がある」という点を考慮すると、静的データと動的データを分離することができます。メッセージを投稿するたびにdatetimeを更新するという状況があります。これを別のアイテムとして分離すれば、メタデータの更新には約6 Write Unitsが必要ですが、これは頻繁に行う必要はありません。一方、動的な情報の更新には1 Write Unitだけで済みます。このように、Write Capacity Unitsを大幅に節約することができます。

重要なのは、多くの人が「1KB未満の数値を変更する場合は1 Write Unitで済む」と考えがちな点です。しかし、100KBの大きなアイテムで数値を変更する場合、100 Write Unitsが必要になります。アイテムの更新や削除の場合、変更前の状態のサイズが基準となります。更新の場合は、変更前と変更後の状態のうち、大きい方のサイズが基準となります。そこで、頻繁に変更する動的な部分を分離し、多くのWrite Unitsではなく1 Write Unitだけで済むようにしましょう。これだけでも大きなコスト削減になります。これはコスト最適化の話になってきましたが、データモデリングは高度なコスト最適化でもあるのです。
DynamoDBでのデータ削除とアーカイブ:GSIとShardingの活用
「忘れられる権利」を定めた法律が多くあり、スレッドを削除する際には、確実に削除されることを確認したいものです。何年も使用しているアカウントの場合、データベースにメガバイト、あるいは数十メガバイトのデータが存在することもあります。1回のAPI呼び出しで、データが最終的に削除されることを確実にしたいと考えます。ユーザーが自分のスレッドを削除できるようにするという新しい要件がありますが、特に時間が経つにつれて、これは大量の情報になる可能性があります。
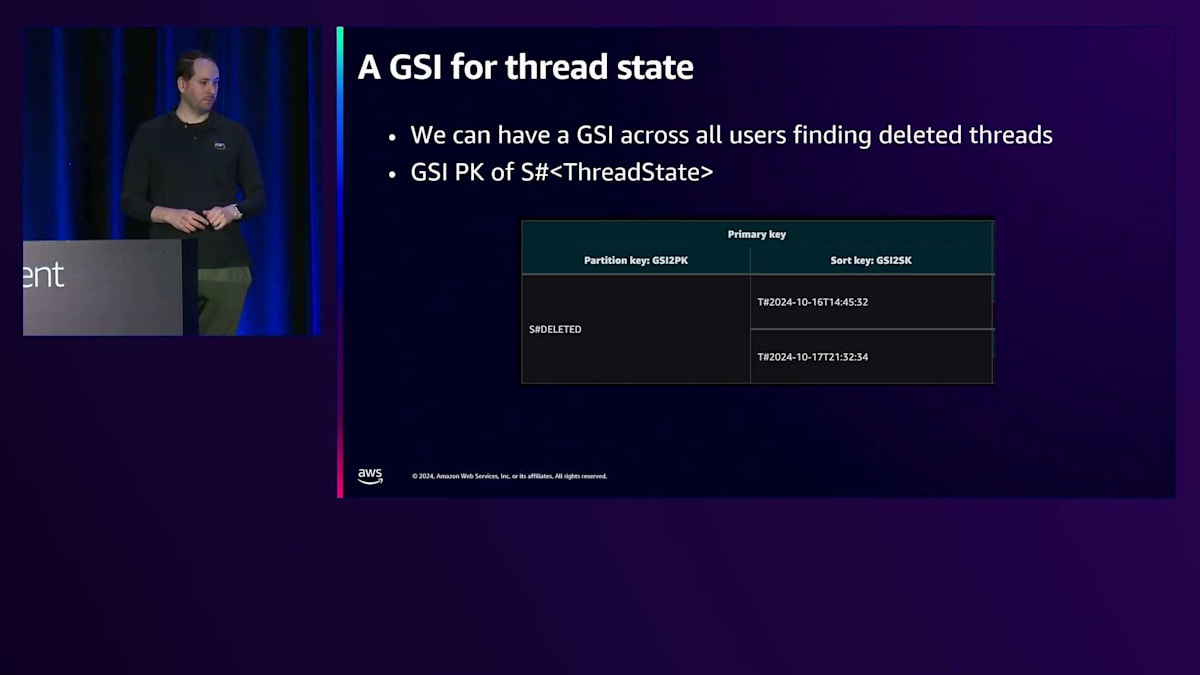
この問題に対するアプローチの1つは、Soft Deleteを使用することです。アイテムを実際に削除する代わりに、スレッドやユーザーに属性を設定するだけです。これは、膨大なデータの中から特定の情報を見つけ出す必要があるため、課題となります。先ほど説明したデザインでは、システムのスケーラビリティを維持しながら、設定された単一の属性を見つける必要があります。この解決策がGlobal Secondary Indexです。これは、定期的に実行されて削除されたスレッドを見つけ、完全に削除するスイーパースレッドです。テーブル全体をスキャンする代わりに、このGSIを作成してクエリを実行することで、特にオーバーロードされたインデックスGSI2を使用する場合には、はるかに効率的に処理できます。

ここでは、アイテムのステータスを削除済みとしてマークする方法を説明します。アイテムに対して、GSI2 PKにハッシュハッシュdeleted(##deleted)とマークすることで、ソフトデリートとして扱います。これにより、スパースGSIに表示されるようになり、永続的に削除する必要のある削除済みスレッドIDをすぐに特定できます。これはフラグを立てたり、センチネル値を設定したりするようなものです。このインデックスに表示されることで、削除が必要だとわかるのですが、1秒間に多数の削除が必要な場合にスケーラビリティの問題が発生します。
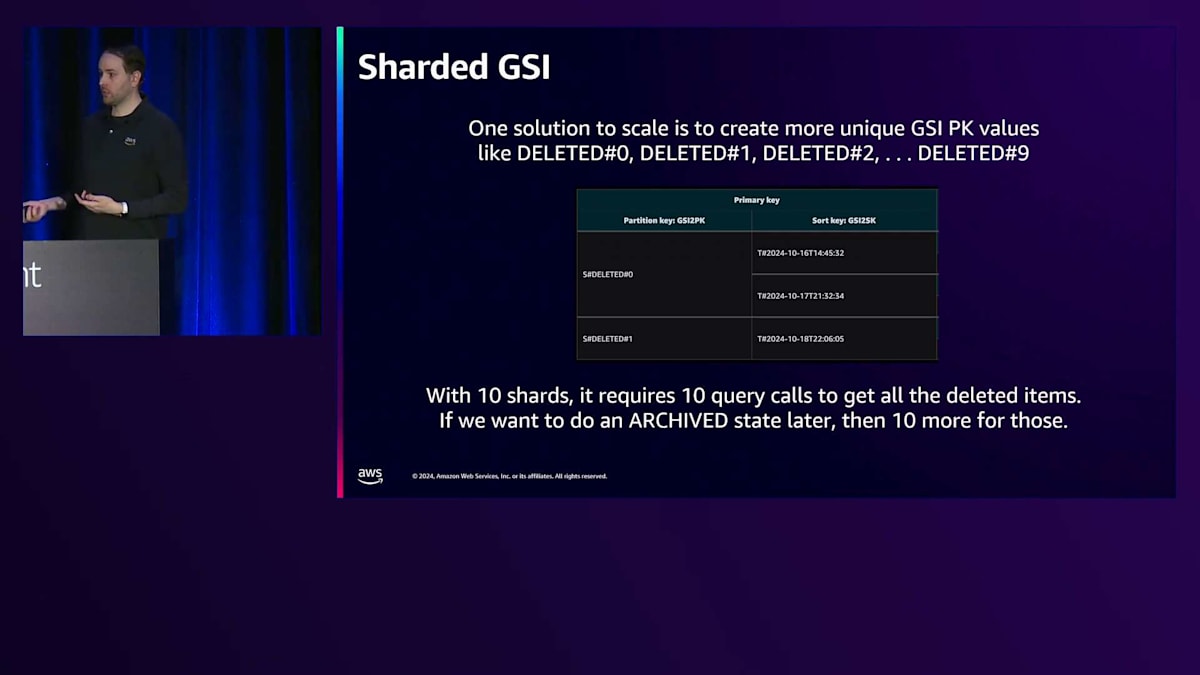
ご説明ありがとうございます。この問題に対して、Shardingという手法が使えます。Shardingを使用する場合、設定された範囲から値を選択し、それをPartition Keyの末尾に付加します。この場合、スレッドの状態を削除済みとしてマークし、0、1、2を付加することができます。ここで対処しようとしている問題は、GSIでPrimary Keyを選択する際、実際にはDynamoDBテーブルの下層で処理が行われているということです。インデックス名は見えますが、私たちには見えないテーブルIDやパーティションが存在しています。GSIにはCloudWatchメトリクスがあるため、高度にユニークなキーを選択することが非常に重要です。
前のデザインを採用した場合、潜在的に何百万もの行が更新され、削除済みとマークされる可能性があり、それらがすべてGSIの1つのパーティションに集中してしまいます。しかし、Shardを使用する場合、10個の異なるShardを持つことができます。1つの領域に集中させる代わりに、書き込みを分散させることで、潜在的なボトルネックを解消できます。これは電話帳に例えると、死亡した人を追跡したい場合、「死者の書」を作成するようなものです。しかし、Partition Keyが「死者の書」だけの場合、1秒間に1000件の死亡しか処理できません。1秒間に10,000件処理したい場合は、10個のShardが必要になります。

他にどのような方法があるでしょうか?設計を作成する際、多くの場合、望ましい状態は削除だけだと考えがちですが、アーカイブしたり、より穏やかな方法を取ったりすることもできます。私たちは選択肢を提供することを重視しているので、ここで別の方法をご紹介します。これは規範的な設計方法というわけではなく、オプションの1つとしてご提案するものです。ここでは、GSIのPartition Keyにスレッドの状態を入れる代わりに、Sort Keyに入れることができます。S0、S1といった値を選択するだけです。
ここで、Calculated Suffixesについて説明するのが良いでしょう。Calculated Suffixesの考え方は、設定された範囲からランダムに値を選ぶのではありません。ランダムという言葉を聞くと、ベーステーブルでアイテムを更新するたびに、GSI Shard Keyの新しい値をランダムに選ぶと思われがちです。しかし、Calculated Suffixesはそうではありません。この方法では、User IDなどの既知の値を取り、ドキュメントに記載されているハッシュ関数を使用します。これは常に同じ決定論的な出力を生成します。例えば、User ID 1は常にS0に、User ID 2はS1になるといった具合です。

ベーステーブルのアイテムを変更する際に、GSI上の異なるパーティション間でアイテムが分散してしまうことについての懸念について説明したいと思います。既知の情報に基づいて固定のシャード番号を設定することができ、これはCalculated Suffixと呼ばれています。詳しくはドキュメントをご覧ください。これは300レベルのプレゼンテーションです。私たちが避けたいのは、ベーステーブルのアイテムを更新する際に、書き込みごとにGSIのシャードを変更することで発生するWrite Amplificationの問題です。その場合、GSI上で古いエントリを削除して新しいエントリを挿入することになります。私たちは、DynamoDBの各アイテムに対して選択するシャード値を同じにしたいのです。 更新時にそれを変更すると、GSIはそれを削除と挿入の2回の書き込みとして認識します。これがAmplificationです。GSIのパーティションキーを同じに保てれば、同じアイテムを書き込むだけでAmplificationは発生しません。
明確にしておきますと、削除が必要なこれらのアイテム、これらのスレッドをすべて見つけるために、10個の異なるQueryコールを並列で実行することになります。最も遅いものが全体の操作速度を遅くすることになります。Queryレスポンスがいっぱいになった時点で、より多くのシャードが必要だと判断した場合は、最大値を0-9から0-20など、必要に応じて増やすだけです。DynamoDBテーブルに適切なシャード数を選択する方法については、ブログで説明しています。DynamoDBは多くの機能をすぐに使えるため、シャーディングをよく目にします。1000回の書き込みはかなりの量ですが、特定のフラグ(この場合は削除やアーカイブなど)を監視するGSIを持ち、それが1秒あたり1000回以上必要な場合は、単純に複数のパーティションキーを使用します。
そこで、必要な数のパーティションキーを用意します。適切な数の選び方については私のブログを参照してください。十分な数を確保しておけば、1秒あたり10万回でも問題ありません。100個のシャードを使用する場合、読み取り時に100箇所を確認する必要があるというデメリットはありますが、このユースケースでは、1件読んで削除、次を読んで削除という形でバックグラウンドワーカーとして動作させると、うまく機能します。実際、規模の制限はほとんどありません。リレーショナルデータベースでインデックスを使用した場合、多くの場合シャーディングができないためボトルネックになってしまいます。
DynamoDBでの正確なカウンティング:String Setと条件付き更新の活用

どんなデータベースでも本当に難しい問題は何でしょうか?私が思うに、それはカウンティング、そして正確にカウントすることです。これから、カウントの方法と、カウントを進める際に重複を避ける方法をお見せします。DynamoDBテーブルでこれを実現する斬新な方法だと思います。多くの人はこの方法を知りません。このプレゼンテーションの準備でJasonと話した際も、彼にとって新しいアイデアだったようです。会場の皆さんにとっても新しい情報になることを願っています。
要件はこうです:収益化の時期なので、アカウントの使用状況を把握する必要があります。すべてのインタラクションに対して確実に課金するにはどうすればよいでしょうか?メタデータアイテムで追跡することもできますが、私としてはDynamoDB Streamsを利用した非同期処理の方が好ましいと考えています。DynamoDB Streamsは、DynamoDBテーブルの変更を最大24時間保持するChange Data Captureサービスです。このカウンティングはできるだけ早く行いたいと考えています。なぜなら、同じデータを使って不正利用を防ぎたい場合があるからです。時には、これらのフィルターを回避しようとして、1秒間に数十回や数百回の操作を送信する人がいます。そのため、できるだけ早くこれを処理できることが望ましいです。ただし、そのような要件がある場合は、上流でのTPSの制限を設けるなど、APIを呼び出す側に対して別の方法でレート制限を行うことを検討し、データベースだけに依存しないようにすることが重要です。

具体的な例を見てみましょう。スレッドにメッセージを投稿する際、企業アカウントでは1日に5,000件までという制限を設ける必要があります。DynamoDBテーブルで変更を行う場合、putやdeleteを実行した時ではなく、実際にデータを変更してタイムスタンプが更新されるような操作を行った時に、その変更がDynamoDB Streamsに記録されます。そこにLambda関数を紐付けることができます。Lambdaにはフィルター機能があり、これは非常に便利です。特定のモデルが使用された場合にのみLambda関数を呼び出すように設定できます。つまり、ClaudeとSort keyが出現した場合にLambda関数を呼び出すことができます。このように、ある程度のカウントが可能です。アトミックな増分操作を使用すれば、操作を大まかに追跡することはできますが、制限があります。

より正確なカウント方法について説明しましょう。DynamoDBのAPIで書き込み操作を行う際、メッセージIDのString Setを含めることを検討できます。DynamoDBにはString Setというデータ型があり、これは文字列の集合で、各文字列は一意である必要があります。書き込み操作時に、String Setにその文字列が含まれていない場合に限り、条件付きで文字列を追加することができます。小規模なカウント、特にメッセージIDが短い場合で、数百から数千回程度の処理を確実に行いたい場合に有効です。最終的には、アイテムはできるだけ小さく保つことが重要です。このデザインでメッセージIDを追加していくと、String Setにどんどん追加されていくためアイテムが大きくなってしまい、それは避けたいところです。
これはユニークで斬新なアイデアです。String Setに含まれていないという条件で、条件付き更新を使用してString Setに追加します。また、Jasonが書いたブログ(a.co/dynamodbcounters)もあります。DynamoDBでカウントする際の課題は、大規模なカウントを行うことを想定していないことです。DynamoDBは高速性を重視しています。基本的な考え方は、カウントを事前に計算して保持しておき、何回発生したかを確認する時にはそれを参照するだけです。ただし、そのためにはカウンターを保持し、変更を監視してトリガーを発火させ、カウントを更新し続ける必要があります。これは、Lambdaがクラッシュした場合に再度呼び出される可能性があることに気付くまでは上手く機能します。そこで、最近発生したことをメッセージIDで追跡することで、Lambdaが二重に呼び出された場合でも二重カウントを防ぐことができます。カウンターの正確性の要件によって対応が変わってきます。このブログでは、より高い精度が必要な場合のカウンターを維持する7つの方法について探求しています。ElastiCacheを使用したり、好みのエンジンを選んだり、ElastiCache Falsiを使用してメモリ内で追跡したりする方法もあります。私たちはDynamoDB Solutions Architectsなので、このデータベースに少し偏っているため、DynamoDBでの実現方法をお見せしています。
DynamoDBの拡張機能:OpenSearch連携とPoint-in-time Recovery
AWSでは他のサービスについても考慮していることをお示ししたいと思います。ここで新しい検索要件について説明しましょう。

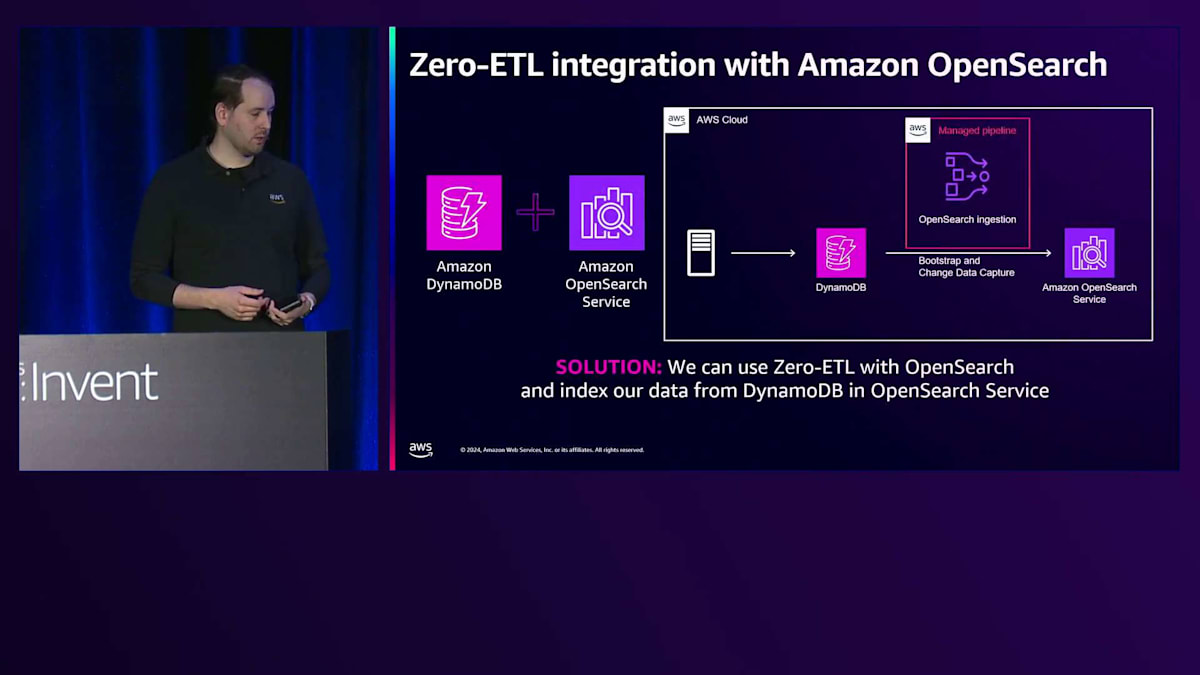
クライアントサイドの検索の仕組みについて話す中で発見したのは、その実装方法です。例えば、re:Inventのトークで5つ星評価を獲得する方法について言及した箇所を探したいけれど、どこだったか忘れてしまった場合。多くの検索はクライアントサイドで行われており、ElasticsearchやOpenSearchにアクセスするのではなく、メタデータをダウンロードしてローカルで検索を行っています。顧客が異なるパターンで検索する必要がある場合によく発生します。DynamoDBでは常にGlobal Secondary Indexを追加できますが、 OpenSearchと統合するという方法も試すことができます。
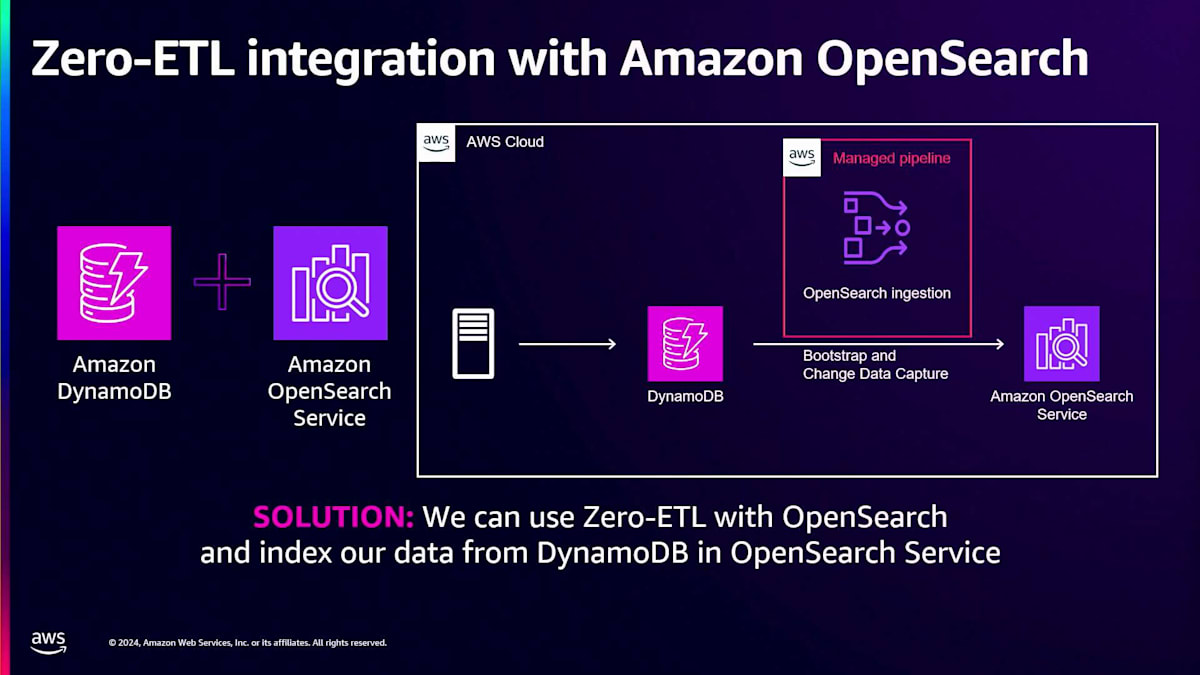
DynamoDBはOpenSearch Serviceとのゼロ ETL連携機能を備えています。例えば、過去のチャットをすべて検索する必要がある場合、それらをインデックスに入れることができます。私はOpenSearchの専門家ではありませんが、この機能はOpenSearchのインジェストサービス用プラグインを使用して、DynamoDBテーブルからAmazon OpenSearch Serviceにデータを取り込むことができます。複数のDynamoDBテーブルから複数のインデックスへ、1対1の関係で、あるいは1つのDynamoDBテーブルから複数のインデックスへと、様々な構成が可能です。Data Prepperに完全にアクセスできるため、属性を組み合わせたり分割したりすることもできます。DynamoDBのシングルテーブル設計戦略を使用していて、2つの値を連結している場合でも、Data Prepperを使って修正することができます。
まず、インデックスを構築するために完全エクスポートを使用し、既存のS3エクスポートサービスを利用して完全に管理された状態で実行されます。その後、DynamoDB Streamsを使用してCDCの変更をキューに入れ、インデックスに送信します。これは昨年発表された機能ですが、Lambdaコードを書く必要がなくなり、統合がより簡単になりました。デプロイボタンを押すだけで、YAMLファイルで変換方法を定義でき、Data Prepperを使用することで非常に強力な機能となっています。これにより、DynamoDBに対して検索を実行できるようになりました。

次の話題はデータモデリングとは少し異なりますが、多くのコストを節約できる方法なので、ぜひ共有したいと思います。DynamoDBのPoint-in-time Recovery(PITR)についてご存知かと思いますが、これを有効にすると、すべての変更のログが保持されます。もし何か問題が発生した場合 - 誤ってアイテムを削除したり、上書きしたり、アプリケーションレベルの破損が発生した場合 - そのログがあるため、損害を元に戻すことができます。

従来の方法では、損害が発生する前の時点に復元を行い、破損する前のテーブルのコピーを取得します。その間に有効な書き込みもあったはずなので、最終バージョンを作成するために2つのテーブルをマージする方法を見つける必要がありました。テーブルが大きければ大きいほど、復元はギガバイト単位で課金されるため、コストが高くなります。ここで、コストを大幅に節約できる素晴らしい方法をご紹介したいと思います:インクリメンタルエクスポート機能を追加しました。PITRを有効にしている場合、特定の時間枠内で発生した変更を確認できます。15分という短い期間から1日という長い期間まで、その時間枠内でアイテムがどのように変更されたかの前後の状態を確認できます。

特定の時間帯に問題が発生したことがわかっている場合、テーブル全体を復元してギガバイト単位で支払う代わりに、問題が発生した時間内の変更だけを確認でき、処理されたログのギガバイト数に応じて料金が発生します。これはごくわずかな量です。1テラバイトの場合、ギガバイトあたり15セントの復元では150ドルかかり、復元に何時間もかかる可能性があります。エクスポートの場合、変更は約1ギガバイトで、費用は10セントです。これは、テーブルからすべての変更をリアルタイムで取得できるDynamoDB StreamsやDynamoDBのKinesis Data Streams連携の代替にはなりません。StreamsはリアルタイムであるためOpenSearchとのゼロETLのように変更をすぐに適用できます。ただし、より粗い粒度でも問題ない場合は、この方法を使用して15分ごとに最新の更新を取得し、下流のコンシューマーに適用することもできます。
このアプローチは実はコスト削減が目的ではありません。ライブストリームを常時稼働させる必要がないのは確かに良い点で、毎日ボタンを押して次の日次アップデートを実行できます。ただ、このユースケースでは、Point-in-time Recovery(PITR)の方がはるかに価値があると考えています。PITRを導入していない場合は、ギガバイトあたりの月額コストがかかりますが、検討する価値はあるでしょう。テーブルが10テラバイトや100テラバイトと大きくなってくると、データの損傷に対するリカバリーのコストはもはやテーブルサイズに比例しなくなります。これは素晴らしいコスト削減策なので、私は全ての講演の最後にこの話を入れるようにしています。質疑応答の時間を3分取りますので、アンケートへのご記入もお願いします。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion