re:Invent 2023: AWSがフォーマルメソッドで分散システムの正確性を検証
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2023 - Gain confidence in system correctness & resilience with formal methods (ARC315)
この動画では、AWSのシニア応用科学者AnkushとPrincipal Transformation ArchitectのBikashが、フォーマルメソッドを用いて複雑な分散システムの正確性と耐障害性を検証する方法を紹介します。Pというフレームワークを使って、設計段階でカオスエンジニアリングを行い、従来のテストでは発見困難なバグを早期に検出する手法を解説します。実際のトランザクション処理システムの例を通じて、Pモデルの作成から不変条件の検証まで、具体的なプロセスを学べます。 ※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
本編
フォーマルメソッドの紹介とセッションの概要

みなさん、こんにちは。このセッションにご参加いただき、ありがとうございます。遅い時間にもかかわらず、お越しいただいたことに感謝します。私はAmazon Web Servicesのシニア応用科学者のAnkush Desaiです。そして、同じくAmazon Web ServicesのPrincipal Transformation ArchitectのBikash Beheraも一緒です。私たちは、フォーマルメソッドを使ってシステムの正確性と耐障害性に自信を持つ方法について、みなさんにお話しできることをとても楽しみにしています。
フォーマルメソッドという言葉を聞いて、多くの方が「この講演は数学的で難しく、自分が構築しようとしているシステムには適用できないのではないか」と思われたかもしれません。しかし、そのようなことは全くありません。この講演に数学は出てきません。フォーマルメソッドについて、とても分かりやすく紹介します。特に、正確性や耐障害性の推論が難しい分散アプリケーションを構築しようとしている場合、このセッションで紹介する技術はあなたのシステムや問題に適用可能です。
まず、フォーマルメソッドの紹介をし、その後、AWSの内部でシステムの正確性を推論するために使用しているPというフレームワークについてお話しします。そして、BikashがAWSのお客様としてこれらの技術をどのように使用し、自社のワークロードに自信を持つことができるかについて、詳しく説明します。それでは、問題自体から始めましょう。
分散システムの複雑さと正確性の課題


分散システムアプリケーションのプログラミングが難しいということは、私たちみんなが同意していることだと思います。それは、複雑なパズルのピースを組み合わせるようなもので、構築しようとしているシステムが信頼性が高く、耐障害性があり、正確で、回復力があるなどの特性を持つために、各ピースが完璧にフィットする必要があります。 分散システムを構築する際には、その分散アプリケーションが特定の望ましい仕様や要件を満たすことを確実に望むでしょう。これには、スケーラビリティ、高スループット、可用性、複数の9の可用性、マルチリージョンサポート、または一貫性などの正確性の特性が含まれます。


分散システムに存在するすべての非決定性の存在下で、分散アプリケーションがこれらの仕様を満たすことを望むでしょう。これには、障害、ノード障害、ネットワーク分断、メッセージ損失、メッセージ遅延などが含まれます。 アプリケーションや分散システムに存在するすべての非決定性の存在下で、望ましい仕様をすべて満たす分散システムを構築したい場合、結果として構築されるシステムは決してモノリシックなシステムにはなりません。それは、複数のサービス、複数のコンポーネント、複数のプロトコルが相互に作用し合って、アプリケーションが望ましい仕様を満たすことを一緒に保証する複合的なシステムになります。


このような複雑さがある場合、正確性と回復力について推論するのは困難です。 そのため、私たちの開発プロセスにはこれらのガードレールがあるのです。これらのガードレールは、設計レベルの論理的な正確性のバグを、開発プロセスのできるだけ早い段階で発見するためのものです。設計の論理的または正確性のバグを開発プロセスの後半で発見すると、多大なコストと労力がかかることは皆さんご存じでしょう。だからこそ、開発プロセスのできるだけ早い段階でそれらを発見したいのです。

では、私たちに何ができるでしょうか?この問題を解決するために、開発プロセスにどのような追加のガードレールを加えることができるでしょうか?それがこの講演のテーマです。 私たちは、formal methodsが、複雑な分散アプリケーションを構築する際にシステムの設計に自信を持つのに役立つ、開発プロセスに追加できる新たなガードレールになると強く信じています。
フォーマルメソッドの定義と利点




このセッションでは、まず、formal methodsとは何か、特にコーディングを超えて抽象的にシステムについて考え、推論することの意味について説明します。 次に、分散システムやアプリケーションにformal methodsを適用するためのフレームワークであるPを紹介します。 AWSがどのようにしてシステムの推論に利用し、開発プロセスに組み込んでいるかについて議論します。 その後、Bikashが登場し、AWSのお客様としてどのようにPを活用し、自身のワークロードに自信を持つことができるかについてお話しします。最後に、Pを使い始める方法について説明します。
このセッションから得ていただきたい重要なポイントの1つは、formal methodsのプロセスには多くの利点があるということです。言い換えれば、複雑な分散システムを構築しようとする際、formal methodsのプロセスを経ることには多くの利点があります。なぜなら、早い段階でバグを発見し排除し、システムの設計と正確性に自信を持つのに役立つからです。
早い段階でバグを排除し、長期的にシステムに自信を持つことは、堅牢なサービスを提供する開発者の生産性を向上させます。このセッションの終わりまでに、これが重要なポイントであることを皆さんに納得していただければと思います。これが重要なポイントです。



では、フォーマルメソッドについて簡単に挙手をお願いします。過去にフォーマルメソッドを使用したことがある方、あるいはチームで何らかのフォーマルメソッドを使用している方はどのくらいいらっしゃいますか? はい、何人か手が挙がりましたね。ただ、それほど多くないのは、フォーマルメソッドが人によって異なる意味を持つからかもしれません。プロトコルや分散システムを初めて設計する人にとっては、紙と鉛筆による証明を意味するかもしれません。 あるいは、program verifierやtheorem proverを使用して、システムの完全な正当性証明を得る、完全に機械化された数学的証明を意味するかもしれません。または、model checkingやTLA+、Pなどのような、より自動化されたものを指すかもしれません。 実際、property-based testingのようなテスト技法や、軽量フォーマルメソッドのような単純なものを指すこともあります。

フォーマルメソッドは、これらの技法のいずれかと考えることができますが、これらのツールや技法に共通しているのは、システムの形式的な仕様を記述し、システムがその仕様を満たしているかを確認するという部分です。これが、フォーマルメソッドに分類されるすべてのツールや技法に共通する点です。そこで、私がよく使うフォーマルメソッドの簡単な定義は、仕様を記述し、システムの動作がその形式的な仕様を満たしているかを確認するプロセスです。 このセッションでは、仕様の記述方法とその確認方法について具体的にお話しします。ここで重要なのは、私が強調している「プロセス」という部分です。複雑で理解が難しいシステムを構築しようとする際、フォーマルメソッドのプロセスを経て仕様を記述し確認することが、システム設計に対する信頼を得るのに役立つのです。
抽象的思考の重要性とシステム設計のアプローチ


これは私が初めて言及することではありません。 私たちのコミュニティの科学者や研究者たちは、抽象的に考えることの重要性や、考えていることを正確に書き留めることの重要性について、長年にわたって語ってきました。ですので、ここではその話はしません。では、抽象的かつ形式的に考えるとは、具体的にどういうことでしょうか?例えば、初めて複雑な分散システムを構築しようとしているとします。すぐに実装に取り掛かるわけではありませんよね?最初のステップは何でしょうか?最初のステップは、一歩下がって考えることです。私が構築しようとしているシステムは何か?システムのコンポーネントは何か?それらのコンポーネントはどのように相互作用するのか?あるコンポーネントが他のコンポーネントに対してどのような前提を置いているのか?そして特に重要なのは、システムが常に満たすべき顧客向けの正当性仕様は何か?障害が発生しても、メッセージの順序が入れ替わっても、決して違反してはならない仕様は何か?これが最初のステップです。システムのこの側面を明確に理解できたら、そこで初めて実装に移ります。

しかし、考えるだけでは十分ではありません。 重要なのは、適切な抽象レベルで考えることです。つまり、システム設計について考える際には、正当性の観点から重要な部分だけに焦点を当て、パフォーマンスや実装レベルの詳細のために存在する部分は無視することが重要です。例えば、分散システムの設計を理解しようとするときに私がよく行う簡単な実験があります。疑似コードを見て、「このコードの一部をコメントアウトしたら、顧客向けの仕様が破綻するだろうか?それとも、それは単にパフォーマンスや実装レベルの詳細のために存在しているのだろうか?」といった質問をします。プロトコル設計においてこのレベルの理解を得ることが、実装に移る前に重要なのです。


そしてもちろん、考えるだけでは十分ではありません。考えている間に、自分の考えを正確に書き留め、設計が望ましい仕様を満たしているかを確認できたら素晴らしいですよね?それが最終的な目標です。そして当然ながら、複雑なシステムを構築しようとする場合、設計は静的なものではありません。設計に変更を加えるたびに、このプロセスを経て、検討を重ね、変更を加えるたびに、新機能をリリースするたびに、一歩下がって変更について考え、それが正しいことを確認し、チェックできたら素晴らしいですよね?では、何が必要でしょうか?私たちに必要なのは、これらの反復、これらのステップを経ることができるフレームワークです。
Pフレームワークの紹介とAWSでの活用事例

私たちは Pを使用してきました。Pは、分散システムについて推論するためのオープンソースのプログラミングフレームワークで、GitHubで利用可能です。開発者やシステム構築者が、通信する状態機械としてシステム設計を表現できる、高レベルの状態機械ベースのプログラミング言語を提供します。これは、彼らが通常分散システム設計について考える方法と一致しています。システム設計を、メッセージを送り合って通信する状態機械として捉えることができます。
システム設計をPで状態機械として表現すると、Pはバックチェッカーを提供し、システムのあらゆる可能な動作を探索して、システム設計が望ましい仕様を満たしているかどうかをチェックします。システムの設計に自信を持てたら、設計レベルの仕様を実装に接続し、実装が設計レベルの仕様と一致していることを確認できます。これがPの3つの主要な部分です。ご覧のように、Pは前のスライドで議論したことを実現するフレームワークです:設計の反復を経て、実装に移る前に設計の正しさに自信を持つことができます。


Pは AWS 内で使用されており、コンピューティング、ストレージ、データベース全体のチームがサービスを駆動する分散プロトコルの正しさを推論するために使用しています。例えば、Pは最初に Amazon S3 の強力な一貫性プロトコルの正しさを推論するために使用されました。これは、S3 が結果整合性システムから強整合性システムに移行する際のことでした。サービスチームは、システムが強整合性プロパティを満たすことを確実にするために、プロトコルスタックにいくつかの変更を加える計画を立てていました。


S3チームはPを使用してプロトコルスタックの形式モデルを作成し、P状態機械でコンポーネント間の詳細な相互作用を記述し、システムが満たすべき正しさの仕様(この場合は一貫性)を指定しました。その後、P-チェッカーを使用してプロトコルスタックの設計空間を体系的に探索し、障害やメッセージの割り込みがある場合でも、システム設計が必要な仕様を満たしていることを確認しました。P-チェッカーは設計空間の体系的な探索を行うため、従来のテストアプローチよりもバグを見つける確率が高くなります。これにより、S3チームは開発プロセスの早い段階で設計上のいくつかのバグを排除し、強力な一貫性を保証するプロトコルスタックに自信を持つことができました。


P-チェッカーの内部で何が起こっているのか疑問に思うかもしれません。これを、状態空間を体系的に探索するエンジンだと考えることができます。例えば、あなたのシステム(この場合はPでモデル化されたシステムの形式モデル)が特定の状態にあるとします。同時に複数のアクション(障害やメッセージの送信など)が発生する可能性があります。P-チェッカーが行うのは、システム内のメッセージと障害のあらゆる可能な組み合わせを探索することです。到達可能な各状態について、システムが望ましい正しさの仕様を満たしていることを確認します。

複雑なシステムで、状態空間が膨大で、障害とメッセージの組み合わせが膨大になる場合、自動推論と数学の魔法が活躍します。バックエンドチェッカーは、複雑な分散システムの分析をスケールさせるために様々な技術を使用します。ここで数学的な部分が登場し、Pのバックエンドチェッカーを形成します。重要なポイントは、P-checkerが高度な抽象化レベルでシステムを推論するため、バグをより速く発見し、低確率のバグを見つけられることです。これにより、従来のテストアプローチと比べて、バグを発見する確率が大幅に向上します。
トランザクション処理システムのPモデル作成
この高度な抽象化のおかげで、P-checkerは、ストレステストや統合テストなどの従来のテストアプローチでバグを見つけようとするよりもはるかに効果的です。ここで理解すべき重要なポイントはこれです。

AWSでは、formal methodsを開発プロセスに統合してきました。従来の開発プロセスは、設計、コーディング、テスト、そして展開という流れでした。私たちが行っているのは、システムを実装する前にP validationを実施することです。 これにより、実装に進む前に設計に自信を持つことができ、望ましい仕様を満たすと確信できる設計に絞り込むまで、様々な障害や故障の下で設計自体を繰り返し改善します。


さて、formal methods、P、そしてAWSがどのようにそれを使用しているかについて知ったところで、Pの例を見てみるのにいいタイミングですね。百聞は一見にしかず、ですから。私の言っていることを信じ始めてもらえるように。 このために、two-phase commit protocolの非常にシンプルな例を使用します。これは分散システムでトランザクションのアトミック性を保証するためによく知られたプロトコルです。クライアントがコーディネーターに書き込みトランザクションを送信すると、このプロトコルは、そのトランザクションがシステム内のすべての参加者によってコミットされるか、どの参加者によってもコミットされないかを保証する必要があります。これは、オール・オア・ナッシングのプロトコルです。


このプロトコルは2つのフェーズで動作します。第1フェーズでは、コーディネーターが書き込みトランザクションリクエストを受け取ると、 システム内の各参加者に「このトランザクションをコミットできますか?」と尋ねます。参加者は自身のローカル状態に基づいて、トランザクションをコミットできるか拒否するかを応答します。第2フェーズでは、コーディネーターは各参加者から受け取った応答に基づいて、トランザクションをコミットするか中止し、 その結果をクライアントに送り返します。これが、2つのフェーズで動作するシンプルなtwo-phase commit protocolです。

さて、あなたが初めて2フェーズコミットプロトコルを考案したとしましょう。このプロトコルの正しさをどのように検証しますか?まず最初に、一歩下がってシステムのコンポーネントについて考え、それらをどのように推論するかを検討します。この場合、コーディネーターと参加者という2つのコンポーネントがあります。コーディネーターについてはどう考えますか?それを状態機械として捉えるでしょう。
Pモデルにおけるキューの状態機械設計



コーディネーターは最初、トランザクション待ち状態から始まります。トランザクションを受け取ると、すべての参加者に準備リクエストを送信し、準備レスポンスを待ちます。そして受け取ったレスポンスに基づいて、クライアントに応答を返します。 ここで伝えたかったポイントは、コンポーネントをメッセージを受信して進化する状態機械として考えるということです。 同様に、参加者もモデル化します。これが分散アプリケーションやシステムの高レベル設計を作成する方法です。

仕様についてはどうでしょうか?仕様とは、システムが常に満たさなければならない条件のことです。例えば、グローバル不変条件はシステムが常に維持しなければならない特性です。2フェーズコミットの場合、システムが常に満たすべき不変条件は原子性です。トランザクションがコミットされた場合、システム内のすべての参加者によって受け入れられていなければならず、また受け入れられた場合にのみコミットされなければなりません。これがグローバル不変条件です。


このグローバル不変条件をどのように考えればよいでしょうか?実行の観点から考える一つの方法は次のとおりです。システムで実行が行われ、書き込みトランザクションが入力されたとします。 そして、システムがその書き込みトランザクションをコミットされたと応答したとします。この場合、システムが満たさなければならない不変条件は、 過去のある時点で、システム内のすべての参加者が同じトランザクションをコミットすることに同意していたということです。同様に、トランザクションがアボートされた場合、システムが恣意的にトランザクションを拒否していないことを保証するために、少なくとも1つの参加者がそのトランザクションを受け入れられないと言ったはずです。

さて、システムの設計を状態機械として考え、グローバル不変条件について考える方法がわかりました。では、このようなシステムをPでモデル化する際に関わる部分は何でしょうか?最初のステップは、PでParticipantとCoordinatorの状態機械を作成することです。

次に、システムの正確性を確認したい状況下で、イベントを大量に送り込むクライアントマシンを作成します。これは、システムに入力や障害を送信する環境やモデルと考えることができ、システムの正確性を検証することができます。最後に、システムの状態を観察し、その正確性を主張する仕様を記述します。
Pを用いたシステムの不変条件検証とテストケース

これらが、Pを使用してシステムについて推論する際の3つの主要な部分です。では、Pプログラムの構造を見てみましょう。先ほど述べたように、3つの主要なコンポーネントがあります。PSrcフォルダにはシステムに関わるstate machineが含まれ、PSpecフォルダには不変条件が含まれ、PTstフォルダにはシステムに入力やイベントを大量に送り込む環境が含まれています。これらがPプログラムの3つの主要部分であり、システムについて推論しようとする際に使用します。


Pでは、state machineはイベントを送信することで互いに通信します。例えば、27行目ではtWriteTranReq型のペイロードを持つeWriteTranReqを宣言しています。Pは他のプログラミング言語と似ており、ユーザー定義型や複雑な型を記述して、複雑なプロトコルロジックを表現することができます。システム内の異なるコンポーネント間の通信に使用されるすべてのイベントを宣言し、これらがコンポーネント間のインターフェースとして機能します。この場合、これらはコーディネーターと参加者の間の通信に使用されるイベントです。


では、state machineを見てみましょう。具体的にはコーディネーターのstate machineです。Pの各state machineには、マシンの状態を保存するために使用されるローカル変数のセットがあります。例えば、コーディネーターは参加者のセット、現在処理中のトランザクション、過去に見たトランザクションのセットなどを保存するための変数を使用します。各state machineには開始状態(この場合はinit状態)があり、その状態に入ったときに実行されるエントリー関数があります。

これらのエントリー関数は、任意の命令型プログラムの一部になります。Pはfor文、条件文、関数呼び出しなどをサポートしており、複雑なプロトコルロジックを記述することができます。この例では、コーディネーターがすべての参加者にイベントをブロードキャストし、トランザクション待ち状態に遷移します。トランザクション待ち状態に入ると、2つのハンドラーが用意され、受信したイベントに応じて対応するイベントハンドラーが実行されます。


ここで強調したいポイントは、Pが他のプログラミング言語と似ていながらも、システム設計を状態機械として捉え、それらがメッセージを送り合うことでコミュニケーションを取る、という状態機械のためのシンタックスシュガーを提供していることです。Pは状態機械というこの高レベルな抽象化を提供し、そのレベルの抽象化でシステム設計を構築することを可能にします。これがコーディネーターの部分で、参加者の状態機械も同様に記述することができます。

次に、Pでの仕様の書き方を見てみましょう。Pでの仕様も他の状態機械と同じようなもので、数学は関係ありません。仕様を数学的な公式として書くのではなく、システムが実行されている際に発生するイベントを観察する特殊なタイプの状態機械として書きます。これらの機械はシステムのローカル状態を維持し、それによってグローバルな不変条件を主張することができます。この例では、参加者から送られた応答を格納するマップを維持します。システムの実行を観察しながら、その応答に基づいてマップを更新します。
カオスエンジニアリングとフェイルオーバーのシミュレーション



システム内で書き込みトランザクション応答イベントを受け取ると、見た応答に基づいて、成功だった場合は全ての参加者が成功を送信したはずであり、エラーがあった場合は少なくとも1つの参加者がトランザクションを受け入れられなかったことを示したはずだ、と主張します。ここでのキーポイントは、仕様が数学的な公式ではなく、プログラムだということです。システムの状態を観察し、システムに強制したいグローバルな不変条件を主張するプログラムを書くのです。このアプローチにより、開発者は仕様をプログラムとして考えやすくなります。

Pでアプリケーションをテストするには、テストケースを書いて実行します。P-checkerが裏で、システムでモデル化された状態機械とメッセージの可能な全ての組み合わせをチェックし、バグが見つかったかどうかを報告します。例えば、N人の参加者を待つ代わりにN-1人の参加者を待つようにした場合、システムはこれをバグとして識別します。
この修正でチェッカーを実行すると、アトミック性の保証に違反することになります。チェッカーは再び全ての可能な組み合わせを探索し、そのメッセージの違反につながるメッセージのシーケンスを見つけ出します。エラートレースを見ることで、コーディネーターと参加者の間でやり取りされるメッセージのシーケンスを確認し、それらのエラートレースを追跡できます。P-checkerでのテストと実行は、他のプログラミング言語でのテストと同じくらい簡単です。

私たちはまた、P easyを利用するためのフレームワークであるPeasy を提供しています。チェッカーが提供するエラートレースは、トレースビジュアライザーと共に使用して、分散システムのエラートレースをデバッグすることができます。さらに、システム設計のモデリングに使用されているステートマシンを可視化し、ドキュメントに追加する方法も提供しています。この時点で、Pプログラミング言語とは何か、Pでシステムをモデル化し仕様を書くとはどういうことか、そしてP-checkerを使用してそれらをチェックする方法について理解できたと思います。


残された明らかな疑問は、実装についてです。設計の正確性に自信を持てたとして、システムの実装に対してはどのように自信を持てばよいのでしょうか? 考え方としては、実装が設計レベルの仕様と同じものを満たしていることを確認したいということです。どのようにチェックすればよいでしょうか?ここでのキーインサイトは、システムの実装がサービスログを生成し、そのログがテスト時や本番環境での実行時の 動作を捉えているということです。

この問題を解決する方法は、 サービスログが望ましい設計レベルのP仕様を満たしているかをチェックすることです。P observeというサービスを提供しており、これを使用すると、分散システムの複数のノードから生成されたサービスログに対して、設計レベルのP仕様を適用することができます。テストインフラストラクチャや本番環境から生成されたログに対して、同じ仕様を適用することができます。これにより、実装に対して同じ設計レベルの仕様を検証し、システムが正しいという確信を得ることができます。
マイクロサービスの障害シナリオと回復力の向上

概要をお話しした今、Bikashさんをお招きして、Pの使い方の概要をお話しいただきます。ありがとうございます、Ankush。ソリューションアーキテクトとして、金融サービスのお客様向けにミッションクリティカルなワークロードを開発しています。 異なるお客様と仕事をする中で、よく同じような質問に遭遇します。まず、お客様は私が開発しているミッションクリティカルなワークロードが正しく動作することを検証してほしいと考えています。次に、キューやストリームの使用など、私たちが行っているアーキテクチャの選択がシステムの目標を正しく達成できるかを検証してほしいと考えています。第三に、お客様はカオスエンジニアリングを採用して、システムの様々なコンポーネントの一時的な障害から優雅に回復できることを検証したいと考えています。第四に、お客様はワークロードが様々な災害シナリオから回復できるほど十分に回復力があることを検証したいと考えています。

私はAnkushに連絡を取り、Pモデリングを使用してこれらの目標をすべて設計時に達成できるかどうかを確認しました。それがどれほど強力であるか想像してみてください。 設計時にこれらの活動をすべて行えるというのは、とてつもなく大きな意味を持ちます。私は形式手法のバックグラウンドはありません。普通のフルスタックエンジニアです。これらの目標をすべて達成するためにPを使用した経験を皆さんと共有したいと思います。私がよく遭遇するミッションクリティカルなワークロードの1つは、トランザクション処理システムです。支払い取引や株式取引を処理する場合でも、5つのコンポーネントを持つトランザクション処理システムの汎用アーキテクチャを作成しました。

受信コンポーネントは、インバウンドトランスポートからトランザクションを受け取ります。その後、前処理コンポーネントが検証やエンリッチメントなどの前処理を行います。次に、処理コンポーネントが決済処理や取引処理などの中核的なビジネスロジックを実行します。そして、後処理コンポーネントがエンリッチメントや監査などの後処理タスクを担当します。最後に、送信コンポーネントがアウトバウンドトランスポートにトランザクションを送信します。

システム内の各コンポーネントは、独自のデータベースを持つコンテナ上で動作するマイクロサービスです。これらのコンポーネントは、キューを介して互いに通信します。ここからは、このトランザクション処理システムの正確性と回復力に確信を持つために、どのようにPモデルを作成したかについて説明します。
Pの活用による学びと様々なステークホルダーへの利点
形式手法における中心的な概念の1つが不変性です。不変条件とは、システムが常に満たすべき条件のことです。このトランザクション処理システムにおける重要な不変条件は、ソースから発行されたすべてのレコードが5つのコンポーネントそれぞれに順序通りに配信され、最終的に宛先に届くことです。つまり、レコードを落とさず、順序通りに配信するという2つの条件を意味します。

Pのモデルでは、システムを協調する状態機械として記述します。このトランザクション処理システムのPモデルを作成する際、キュー、コンテナ、データベース、レコードソース、レコード宛先の状態機械を設計します。これらの状態機械は、レコードをペイロードとするイベントをやり取りすることで協調します。では、キューの状態機械を設計してみましょう。

状態機械なので、キューには正常状態と障害状態の2つの状態があると仮定しましょう。正常状態では、キューは送信者がレコードをペイロードとしてsend recordイベントを渡すことを許可します。レコードの処理が成功すると、キューは送信者にsend record completedイベントを返し、成功ステータスをtrueに設定します。また、キューは受信者がreceive recordイベントを渡して受信の意思を登録することを許可します。送信者からレコードを受け取ると、キューは受信者にreceive record responseイベントを渡し、そのレコードをペイロードとして含め、成功ステータスをtrueに設定します。

このシミュレーションは、キューの動作をできる限り忠実に再現し、図に示された3つのステートマシンが、レコードをペイロードとするイベントをやり取りしながら連携する様子を示しています。失敗状態では、キューの振る舞いが少し異なります。 送信者がsend recordイベントを渡すと、キューはsuccess statusをfalseに設定してsend record completedイベントを送信者に返します。同様に、受信者がreceive recordイベントをキューに送信すると、キューはsuccess statusをfalseに設定してreceive record responseイベントを受信者に返します。
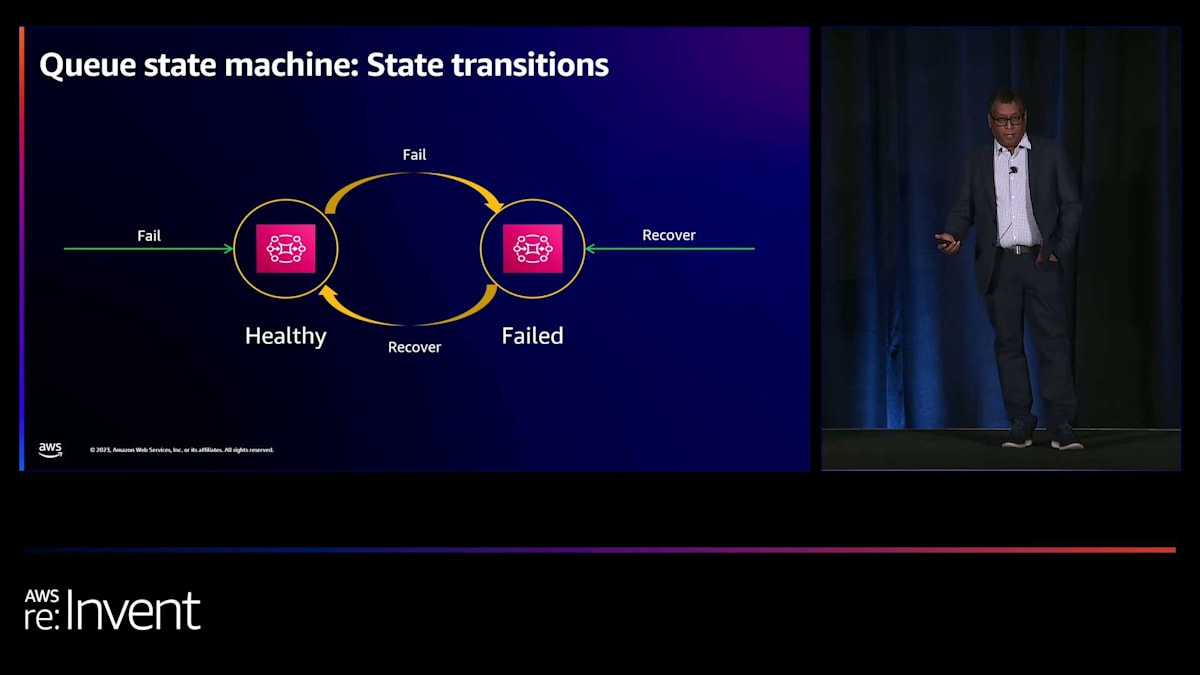
これは、JMSを使用してキューを操作する経験に似ています。JMSを使用してキューにメッセージを送信したり、キューからメッセージを受信しようとすると、何らかの理由でキューが利用できない場合、例外がスローされることがあります。 では、キューの2つの状態を、その間の状態遷移とともに見てみましょう。健全な状態のキューは、failイベントを受け取ると失敗状態に遷移します。失敗状態のキューは、recoveryイベントを受け取ると健全な状態に遷移します。
設計段階でのカオスエンジニアリングとPの教訓

ここで、キューの完全なステートマシンを見てみましょう。健全な状態と失敗状態の2つの状態があり、failイベントとrecoveryイベントに応じて互いに遷移します。また、両方の状態でキューがサポートするすべてのイベントも示されています。唯一の違いは、健全な状態ではキューがfailイベントをサポートし、失敗状態ではrecoveryイベントをサポートすることです。キューと同様に、コンテナのステートマシンも作成しました。
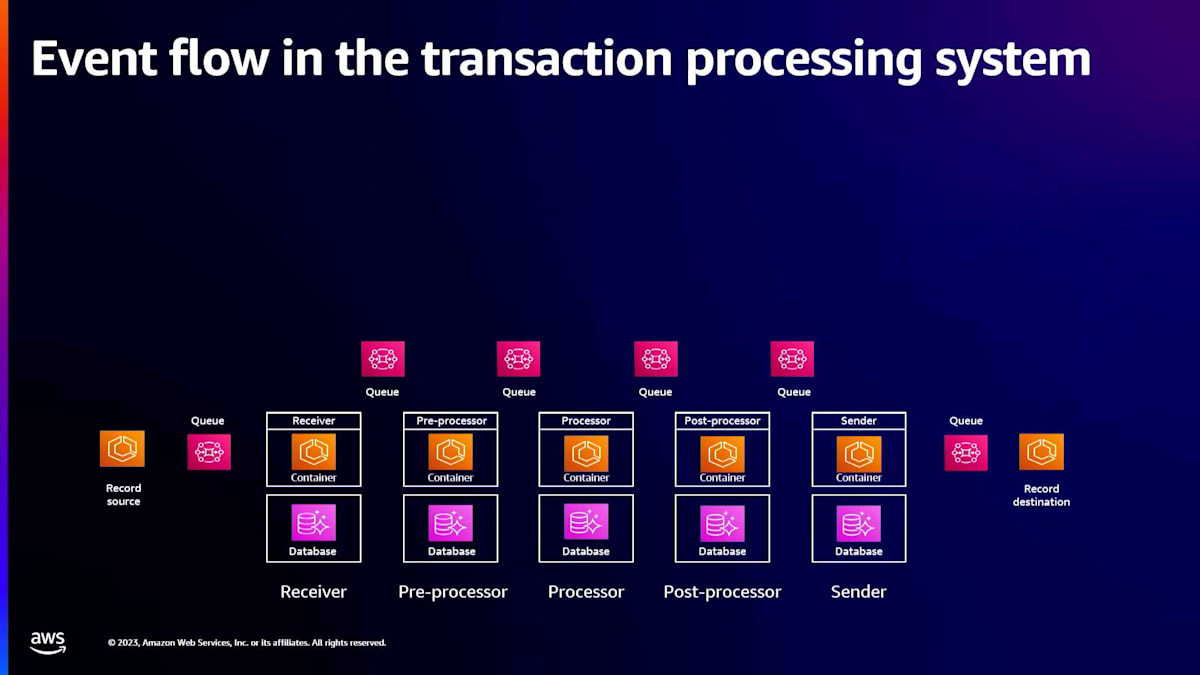


データベース、レコードソース、レコード宛先についても同様です。では、トランザクション処理システム全体を見てみましょう。 このシステムは、イベントが流れる協調的なステートマシンとして生き生きとしています。図に示されているように、トランザクション処理システムは 18のステートマシンで構成されています:1つのレコードソース、6つのキュー、5つのコンテナ、5つのデータベース、1つのレコード宛先です。これらのステートマシンは、レコードをペイロードとするイベントをやり取りすることで相互作用し、これによってレコードがトランザクション処理システムを通じて処理されます。

これらの協調的なステートマシンの主要な特徴をいくつか見てみましょう。 まず、各ステートマシンは独立しています。次に、各ステートマシンは異なる速度で並行して動作しています。そして、各イベントは非同期です。これらのステートマシンの非同期性により、従来の方法では発見が困難な興味深い障害シナリオや欠陥が生じる可能性があります。

さて、大きな疑問が浮かびます。システムの不変条件をどのように検証するのでしょうか?Pを使えば、イベントの流れを監視し、その可視性を利用してシステムの不変条件を検証するspecを定義できます。まず、specは関心のある特定のイベントの監視に登録します。次に、イベントがターゲットに配信されると同時にspecにも配信されます。そして、specがイベントを分析し、不変条件が満たされているかを検証します。

トランザクション処理システムのPモデルを作成したら、Pを使ってさまざまなシナリオをシミュレートし、システムの動作を検証するテストケースを作成できます。Pでは、実行したいイテレーション数と各イテレーションで公開するレコード数を指定できます。例えば、 各イテレーションで1,000レコードを処理する10,000回のイテレーションを実行することもできます。このように大量のレコードが並列で異なる速度で動作する非同期ステートマシンによって処理されると、他の方法では見つからないようなバグを発見できる可能性が高くなります。
私は3つのテストケースを実装し、それぞれを自動化して実行しました。最初のテストケースは、すべてのステートマシンが正常な状態での標準的な処理をシミュレートしました。実行時には、レコードソースから一連のレコードを公開し、すべてのレコードが順序通りにすべてのコンポーネントに配信されたことを検証しました。不変条件が満たされない場合は、調査して修正すべき欠陥として特定されました。これにより、設計したトランザクション処理システムが、すべてのステートマシンが正常な場合に期待通りに動作することを確認しました。

次に、 カオスエンジニアリングをシミュレートするテストケースを実装しました。このアーキテクチャのコンポーネントをランダムに障害発生させ、回復させ、その回復プロセス中のシステムの動作を監視します。このテストケースを実行すると、一連のレコードを公開し、正常なステートマシンによってすべてのレコードが正常に処理されることを確認します。次に、ランダムに選んだコンポーネントセットを障害発生させ、2つ目のレコードセットを公開します。ランダムに2つ、3つ、4つ、または5つのステートマシンを障害発生させます。その後、障害が発生したコンポーネントを回復させ、3つ目のレコードセットを公開します。3つのセットのすべてのレコードが正常に処理されたことを確認します。
不変条件が満たされない場合、特定のステートマシンまたはステートマシンのセットが障害を起こした障害シナリオを示します。このテストケースを何千回も実行すると、990回は正常に動作しますが、1回だけランダムに失敗し、特定のステートマシンのセットが特定の順序で障害を起こす非常に特殊なシナリオが浮き彫りになります。これにより、設計段階でカオスエンジニアリングを極限まで推し進めることができました。

このアプローチは、カオスエンジニアリングがいかに強力なツールになり得るかを示しています。

私が実装した3つ目のケースは、フェイルオーバーの検証でした。このテストケースを実行すると、文字列処理システムが2つのリージョン(プライマリリージョンとセカンダリリージョン)にデプロイされ、アクティブ-パッシブ構成で実行されます。図に示されているように、すべてのトラフィックがプライマリリージョンにルーティングされ、そこから処理されるため、システムはプライマリリージョンでアクティブモードで動作しています。テストケースでは、完全なレコードセットを発行し、すべてのレコードがプライマリリージョンで正常に処理されたことを確認しました。その後、テストケースはアプリケーションをセカンダリリージョンにフェイルオーバーさせ、そこで実行しました。2番目のレコードセットを発行し、それらのレコードがすべて2番目のリージョンで正常に発行されたことを確認しました。どの時点でも不変条件が満たされなかった場合、フェイルオーバープロセスに調査が必要な欠陥があると判断されます。

トランザクション処理システムのPモデルを作成する過程で、私たちは多くのことを学びました。ここでは、レジリエントなマイクロサービスを構築する上で学んだ重要な教訓をいくつか共有したいと思います。マイクロサービスには、内部障害と依存関係の障害という2種類の障害が起こりうることがわかりました。内部障害の場合、基盤となるコンピューティングリソースがダウンし、コンテナがダウンすることでマイクロサービスがダウンする可能性があります。しかし、オートスケーリングが設定されていれば、別のコンテナが立ち上がり、最初のコンテナが中断した箇所から処理を引き継いで続行します。これは自己修復アーキテクチャの一例です。
2つ目のシナリオである依存関係の障害は、さらに興味深いものです。このアーキテクチャでは、コンテナで実行されているマイクロサービスはQueue 1、Queue 2、およびデータベースに依存しています。これらはそれぞれ独立して障害が発生する可能性のあるステートマシンです。レコードが正常に処理されたと見なされるためには、コンテナで実行されているマイクロサービスがQueue 1からレコードを受け取り、データベースにレコードを書き込み、そしてQueue 2にレコードを送信する必要があります。これは図に示された6つのステップで表されています。依存関係のいずれかが失敗すると、6つのステップすべてを処理または実行することができず、レコードの処理は失敗します。この時点で、私たちはマイクロサービスにおいて決断を下す必要がありました。リトライするか、高速に失敗するかのどちらかを選択する必要があり、私たちは高速に失敗する方法を選びました。高速に失敗を実装した場合、障害が発生した依存関係を健全な状態に戻した後、マイクロサービスやコンテナを明示的に回復させる必要があることに気づきました。
要約すると、マイクロサービスは自己修復アーキテクチャを使用して内部障害からエレガントに回復できます。しかし、依存関係に障害が発生した場合、依存関係が回復したときにマイクロサービスを明示的に回復させる必要があります。これにより、依存関係との接続を再確立できます。カオスエンジニアリングから学んだもう一つの教訓を共有しましょう。私たちは非常に興味深いシナリオに遭遇しました。マイクロサービスがQueue 1からレコードを受け取り、データベースにレコードを挿入しましたが、Queue 2にレコードを挿入する前にマイクロサービスがダウンしてしまったのです。つまり、レコードは完全には処理されていませんでした。コンテナを復元したとき、特定のレコードが2回配信されていることに気づきました。そのため、これらの重複を処理するために、マイクロサービスにべき等性のロジックを実装する必要がありました。

前回のテストケースで行ったカオスエンジニアリングを通じて、マイクロサービス設計で考慮すべき多くの障害シナリオに遭遇しました。その過程で、私たちは各イテレーションごとにマイクロサービスを強化し、非常に回復力のあるものにしていきました。ここで、顧客ワークロードにPを使用した際の主な学びを共有したいと思います。
まず、Pの使用は簡単です。PはJavaやPythonなどのプログラミング言語に似ているので、学習曲線が急ではありません。次に、Pモデルの実装は速いです。先ほどお見せした取引処理システムのPモデルを実装するのに2週間かかりました。

3つ目に、発見が困難なバグを検出します。100回シミュレーションを実行すると、99回は問題なく動作しますが、1回の失敗で非常に見つけにくい欠陥が浮き彫りになります。私たちは、Pが多くの異なるステークホルダーにとって有用だと考えています。
CIOやCTOとして、設計時の厳密さの文化を促進できます。技術リーダーに対して、システムを設計するだけでなく、その設計が機能することを実証するよう要求できます。エンタープライズアーキテクトとして、繰り返し発生するアプリケーションパターンのリファレンスアーキテクチャを作成します。アプリケーションチームと共有する前に、Pを使用してこれらのリファレンスアーキテクチャを検証できます。ミッションクリティカルなアプリケーションを開発するアプリケーションアーキテクトとして、ドメインの観点から機能的な不変条件を表現し、アプリケーションの包括性を確保できます。
エンジニアとして、何千回もの反復を通じて検証済みのコンポーネントの擬似コードから始める機会が得られ、エンジニアリング作業を加速できます。最後に、テスターとして、技術面とドメイン面の両方からシステムの不変条件の明確な記述を得られます。また、すべてのコンポーネント、その状態、および動作の明確な記述も得られます。この情報を使用して、システムを徹底的にテストするためのテストケースを設計できます。


では、Ankushを再びステージにお招きしたいと思います。
フォーマルメソッドの利点と今後の展望
Pを使って設計段階でカオスエンジニアリングを行う方法について話しましょう。私たちは皆、実装段階でのカオスエンジニアリング、ゲームデイの実施などに慣れています。しかし、これは少し異なります。これは、実装に移る前に、カオスエンジニアリングの概念を通じて設計に自信を持つことです。AWSでこれらの技術を使って過去数年間に学んだ教訓をいくつか共有し、そしてこれらの概念を始める方法と開発プロセスに追加する方法についてお話ししたいと思います。

私たちが学んだ最初の教訓の1つは、Pの使用を始めると、それが思考ツールとして機能するということでした。システム構築者や開発者に、設計段階でいくつかの質問に答えることを強制します。これらの質問とは何でしょうか?まず、システムを形式的にモデル化しようとする際、システムがどのように期待される動作を行うかを答える必要があります。これらのコンポーネントはどのように相互作用するのか?どのように調整するのか?どのように目的を達成するのか?

設計段階で答えを強制される2つ目の質問は、システムが何をすべきかということです。システムが常に満たさなければならない仕様は何か?これは、すべての障害が存在する中で、システムが決して違反してはならない仕様を知ることが非常に重要です。最後の質問は、いつかということです。無限の障害やあらゆる種類のランダムな入力に耐えられる分散アプリケーションを設計することは不可能なので、システムは特定の種類の入力と特定のタイプの障害の下でのみ望ましい仕様を満たすことができます。



私たちが発見したのは、このプロセスには魔法があるということでした。Pがこのドメイン固有言語を提供するため、開発者に異なる方法でシステムについて考えることを強制します。 システム構築者や開発者にこの考える時間を与えると、彼らは非常に賢明で、システム設計のギャップを見つけ出すことができます。 私たちの経験では、バグや設計のギャップの大部分は、この設計時の思考プロセスを通じて発見されました。そのため、これには価値と魔法があるのです。

しかし、当然ながら、考えるだけですべてのバグを排除することはできません。そこで、P-checkerの威力が発揮されます。P-checkerは体系的な探索を行うからです。 非常に複雑なシナリオでしか顕在化しない、システム内のコーナーケースや低確率のバグを見つけることができます。


P Checkerは、設計段階でこれらを発見することができます。 本質的に、システム内の重大なバグを早期に発見する能力があり、私たちの経験では、従来のテストアプローチでは通常見つけられないようなバグを発見できます。これが2つ目の教訓です。しかし、ここでの重要な教訓は、最初の2つの教訓が 複雑な分散システムを構築しようとする開発者の全体的な速度向上につながるということです。なぜなら、設計をより速くイテレーションできるようになるからです。

通常なら試みないようなリスクの高い最適化を試すことができます。なぜなら、それらをテストする良い方法がなかったからです。しかし、Pがあれば、強力な検証方法があれば、設計段階でこれらのリスクの高い最適化を試し、その正しさに自信を持ち、実装に進むことができます。これが、Pを開発プロセスに統合した際に学んだ重要な最後の教訓です。

結論として、私たちが話したのは、 ミッションクリティカルな重要なワークロードや複雑な分散アプリケーションを構築しようとする際に、コーディングを超えて抽象的に考えることに大きな利点と重要性があるということです。Pは、システムの正確性と回復力について推論するためのフレームワークです。Pは使いやすく、AWS内で使用されており、Bikashが話したように、完全にオープンソースなのでPを活用できます。しかし、私が結論として強調したいのは、どのようなツールを使うにせよ、形式手法のプロセスを経ることには多くの利点があるということです。
行動の呼びかけとして、私たちはあなたと協力して、Pと形式手法をあなたの開発プロセスに統合したいと思います。 そのため、どのような手段でも、メールなどで連絡してください。PはGitHub上で完全にオープンソースであり、チュートリアル付きの完全なドキュメントが利用可能です。Bikashが話したモデルもオンラインで閲覧できます。以上で締めくくり、セッションにご参加いただきありがとうございました。セッションのアンケートにご協力ください。ぜひ連絡をください。ご参加ありがとうございました。
※ こちらの記事は Amazon Bedrock を様々なタスクで利用することで全て自動で作成しています。
※ どこかの機会で記事作成の試行錯誤についても記事化する予定ですが、直近技術的な部分でご興味がある場合はTwitterの方にDMください。
Discussion