re:Invent 2024: AWSがKarpenterとEKS Auto Modeで変えるKubernetes運用
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - Simplify Kubernetes workloads with Karpenter & Amazon EKS Auto Mode (KUB312)
この動画では、AWSのコンテナとサーバーレスを担当するプリンシパルソリューションアーキテクトが、Amazon EKSの採用とスケーリングについて解説しています。Karpenterの詳細な機能説明に加え、新しく発表されたEKS Auto Modeについても紹介しています。EKS Auto ModeはKarpenterの原則に基づいて構築され、クラスター機能の完全マネージド化、セキュアなBottlerocket OSのサポート、自動アップグレード機能などを提供します。また、General PurposeとSystemという2つのビルトインNode Poolがデフォルトで提供され、GPUやNeural系インスタンスなどのユースケースに対応するカスタムNode Poolも作成可能です。運用負荷を軽減しながら、800種類以上のEC2インスタンスタイプへのアクセスを維持する柔軟な設計となっています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
Amazon EKSとKarpenterの導入:セッション概要
皆様、ようこそお越しくださいました。このセッションにご参加いただき、ありがとうございます。カタログをご覧になっていた方はお気づきかと思いますが、セッションのタイトルが変更になりました。Karpenterのセッションにお申し込みいただきましたが、今回はKarpenterに加えて、さらに踏み込んだ内容をお届けします。私はRajと申します。AWSのコンテナとサーバーレスを担当するプリンシパルソリューションアーキテクトとして6年間勤めており、多くのお客様のKubernetesやサーバーレスへの移行をサポートしてきました。本日はShriと一緒に発表させていただきます。皆様、こんにちは。Shri Joshiと申します。AWSのコンテナ担当プリンシパルソリューションアーキテクトとして、主にEKSとKubernetesのお客様を担当しています。本日はRajと一緒に発表できることを大変嬉しく思います。


本日は、お客様がAmazon EKSをどのように採用されているかについてお話しします。これはKarpenterとEKS Auto Modeのセッションですので、お客様がアプリケーションをどのようにスケールしているかについて説明します。その後、いくつかの課題と、Karpenterなどによるその解決方法についてお話しします。最後に、さらに学習を深めていただくためのリソースもご紹介します。6年前を振り返ると、私たちはAmazon EKSをリリースしました。Kubernetesは素晴らしいツールです。私も長年Kubernetesに携わってきましたが、お客様からコントロールプレーンの自己管理が難しいというご意見をいただいていました。そこでAmazon EKSが誕生したのです。EKSは安定的で安全なKubernetesの実行環境であり、完全なアップストリームの認定適合Kubernetesを提供しています。
Amazon EKSの進化とKarpenterの登場
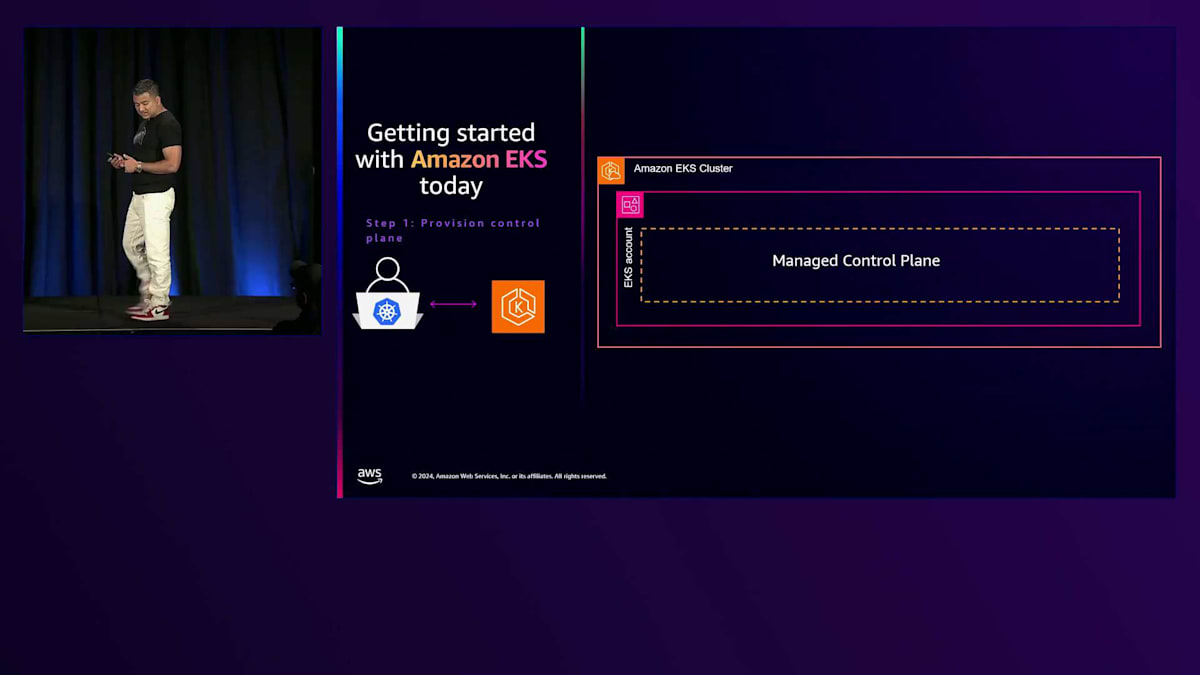

ここまでで、EKSは素晴らしそうだから始めてみたいと思われたかもしれません。現在の始め方をご説明しましょう。まず、クラスターを作成します。これにより、スケーラブルで高可用性かつセキュアなコントロールプレーンがAWSアカウントに作成されます。次に、ワークロードをデプロイしたいところですが、その前にもう少し準備が必要です。アドオンやコントローラーをインストールする必要があります。通常は、2台以上のEC2インスタンスからなるマネージドノードグループを作成し、Ingressコントローラーやストレージコントローラーなどのアドオンをインストールします。
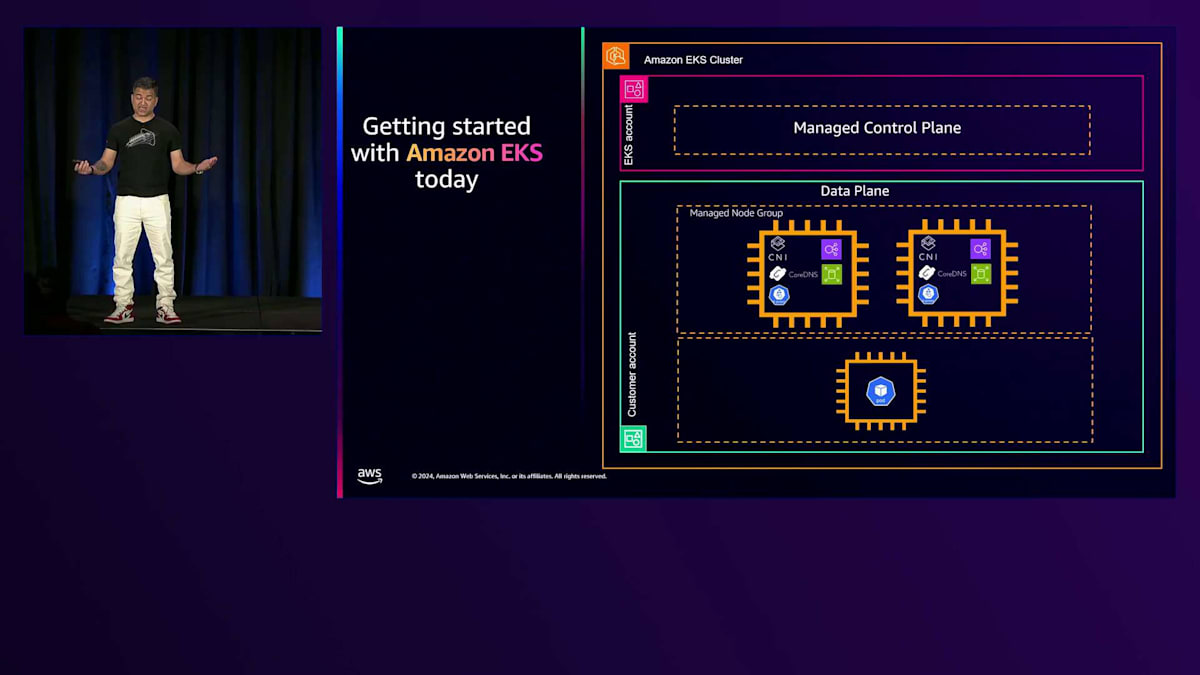

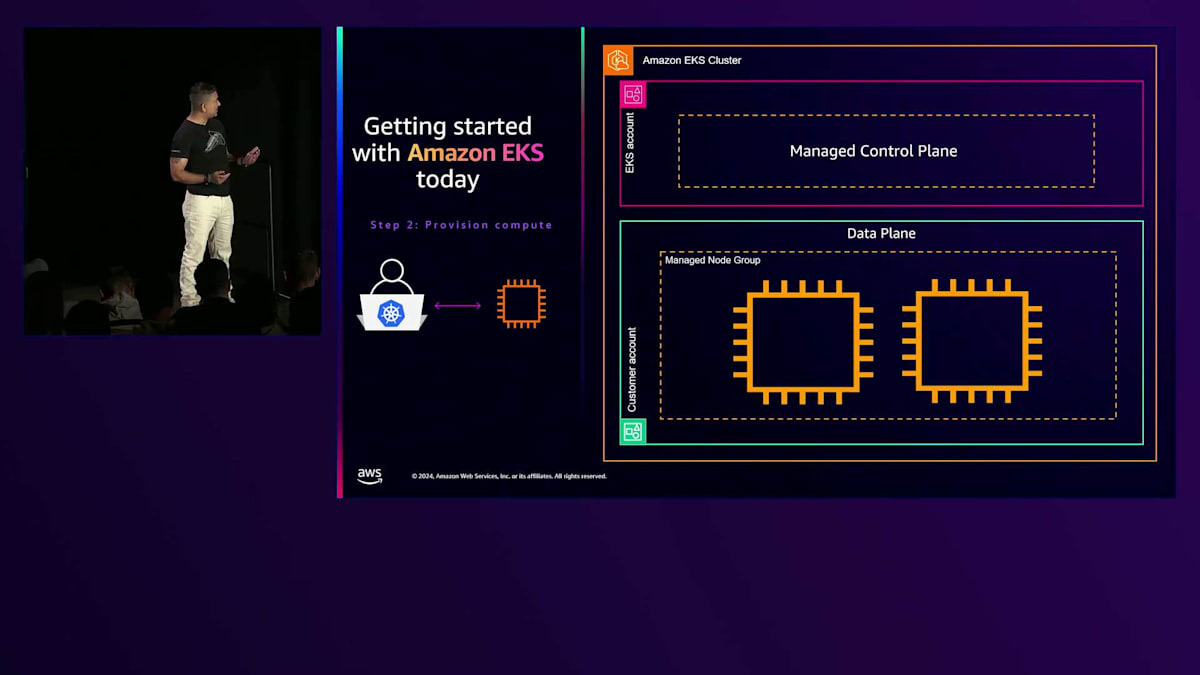
この時点で、すべてのアドオンとコントローラーがインストールされ、アプリケーションをデプロイできる状態になります。マネージドノードグループを作成し、そこにPodがデプロイされます。ただし、これはスケーリングに関するセッションですので、オートスケーリングについても触れる必要があります。アプリケーションが正常に動作している状態で、Cluster Autoscalerなどをインストールすると、Podが複数のEC2インスタンスにわたってスケールされます。Cluster Autoscalerは優れたツールですが、いくつかの課題があります。Cluster Autoscalerでは、マネージドまたはセルフマネージドのノードグループを作成する必要があります。これらのノードグループでは、使用するインスタンスファミリーとその優先順位を指定する必要があります。
また、Cluster Autoscalerを使用する場合、Auto Scaling Groupを作成する必要があります。Auto Scaling Groupは優れた機能ですが、いくつかの課題があります。各ノードグループに対して個別のAuto Scaling Groupが必要です。ワークロードを複数のアベイラビリティーゾーンに分散させたい場合は、複数のAuto Scaling Groupを作成する必要があります。最後に、AMIの選択と更新が面倒です。本番環境でCluster Autoscalerを運用されている方はご存知かと思いますが、起動テンプレートを管理する必要があります。AMIが変更されるたびに、テンプレートを変更し、リサイクルコマンドを実行するなどの作業が必要です。このような理由から、私たちはKarpenterを開発しました。

では、Karpenterはどのように動作するのでしょうか?まず、Horizontal Pod Autoscalerを使用してPodがスケールし、その後Podがペンディング状態になります。Cluster Autoscalerの場合、Auto Scaling Groupを使用しますが、Karpenterはそれらをすべてバイパスして、EC2 Fleetと直接やり取りします。これらのホップをバイパスすることで、Karpenterの方が高速になります。また、Karpenterを作成する際、私たちはKubernetesネイティブにすることを目指しました。Kubernetesファンとして、私たちはYAMLが大好きなのです。

Karpenterの動作は、NodePoolとEC2NodeClassという2つのYAMLファイルで制御できます。プロセスに戻りましょう。Cluster Autoscalerの代わりに、Karpenter add-onをインストールし、アプリケーションがスケールする際、マネージドノードグループは必要ありません。インスタンスがより速く起動され、すべてが順調に動作します。



スケーリングはKarpenterの基本的な機能ですが、それ以上の機能を提供します。Karpenterはすぐに使えるコスト最適化機能を備えており、機械学習や生成AIを含む多様なワークロードをサポートし、アップグレードとパッチ適用もサポートしています。そのため、Karpenterは完全なデータプレーンの実装となっています。KarpenterはAWSで愛情を込めて作られましたが、オープンソースコミュニティに寄贈され、現在はSIG Auto SCの下でCNCFプロジェクトの一つとなっています。Karpenterの成長と、お客様のような方々がKarpenterに貢献している様子を見るのは、とても誇らしく思います。
Karpenterの機能と利点:スケーリングから最適化まで

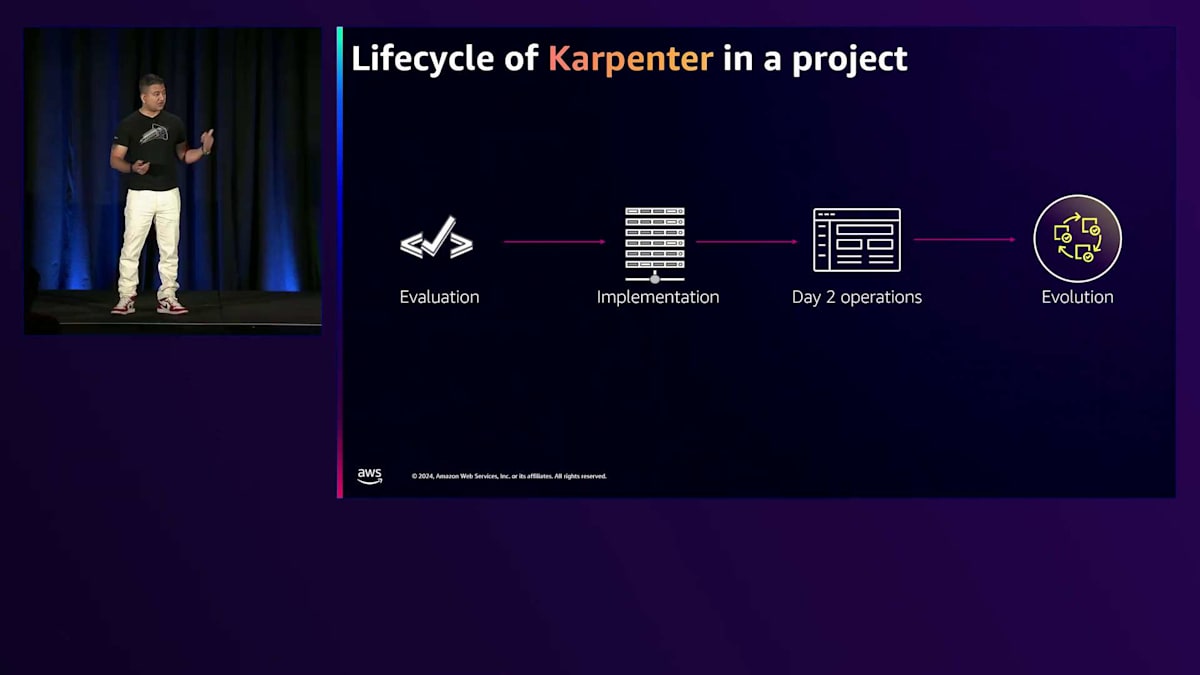
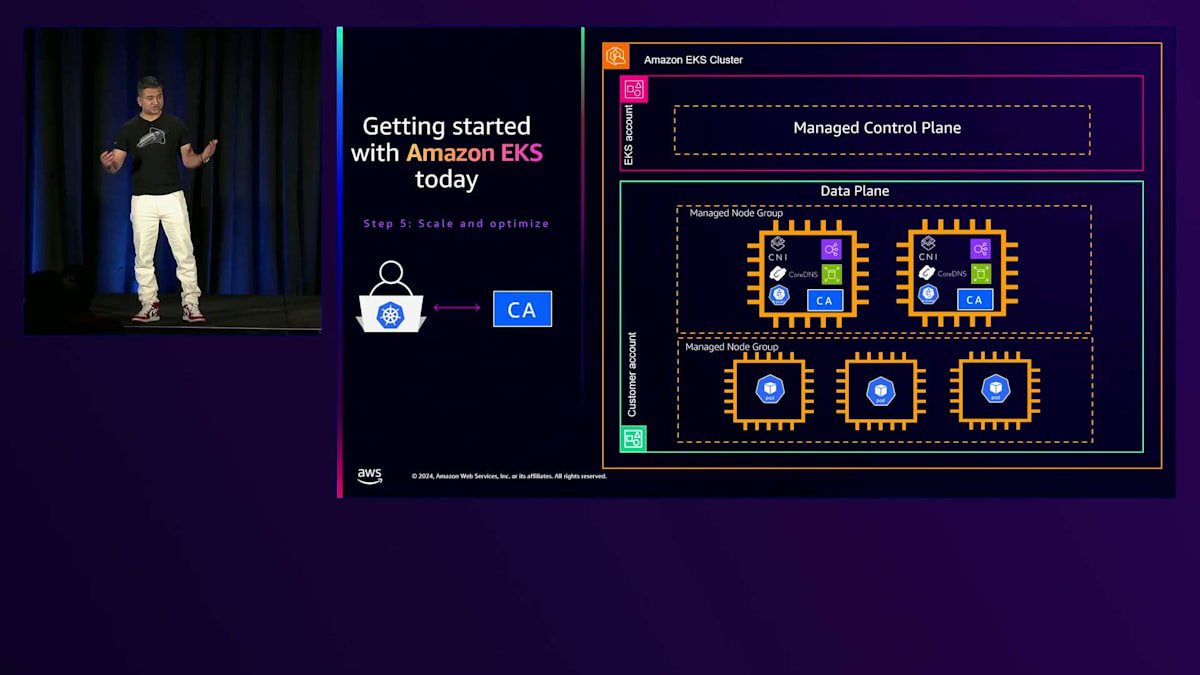
この時点で、「Karpenterは素晴らしそうだけど、どうやって始めればいいの?」と考えているかもしれません。私たちは、お客様の導入の流れをこのように見ています:まずKarpenterの機能を評価し、次に実装し、その後日々の運用を行い、最終的に進化させていくというプロセスです。このトークでは、同じプロセスに沿って説明していきます。




評価フェーズから始めましょう。コンテナを実行するには、CPU、メモリ、ストレージなど、さまざまなリソースが必要です。これらが異なるインスタンスにどのようにマッピングされるのでしょうか?私たちは多くの異なるインスタンスを提供しています。サイズが大きくなるほど、より多くのCPUが得られ、インスタンスファミリーによってCPUとメモリの比率が決まります。P4dのようなGPUや、最新世代のカスタムシリコンインスタンスであるInferentiaなど、800以上の異なるインスタンスタイプから選択できる柔軟性を提供しています。


最初の質問は、Karpenterがどのようなツールをスピンアップするかをどのように制御するかということです。先ほどNodePoolについて話しましたが、これはNodePoolのサンプルです。このNodePoolを使用して、Karpenterの動作を制御できます。例えば、上部では、インスタンスファミリーをC5、M5、R5の中から選ぶように指定しています。ちょっと自慢げに言いますが、「in」演算子だけでなく、「not in」も使えます。ワークロードに応じて、nano、micro、small、mediumのインスタンスを使用しないように指定することもできます。
800種類もの異なるインスタンスタイプから選ぶのは簡単ではないことは理解していますので、これらのフィールドはすべて空のままにしておくことができ、その場合AWSがデプロイされたPodのリソース要求に基づいて適切なインスタンスタイプを自動的に選択します。以前の私のような抜け目のないSREチームやアプリ開発者向けに、CPUやメモリをたくさん必要とする場合は、このNodePoolが提供できるEC2インスタンスの数を制限することもできます。下部では、CPUの制限が100となっているのが分かります。このNodePoolは、CPUの合計が100に達するまでEC2インスタンスをプロビジョニングし続けます。これはメモリでも同様に機能します。


Availability Zoneなどの制御も可能です。例えば、us-west-2a、us-west-2b、または特定のAZでスピンアップするように指定できます。Auto Scaling Groupとは異なり、これに対して異なるNodePoolを作成する必要はありません。また、アーキテクチャタイプも制御できます。ワークロードに応じてx86やGravitonのようなARMを使用できます。


ワークロードに応じて、多くの方がSpotインスタンスを混ぜたいと考えています。SpotインスタンスとOn-Demandインスタンスの両方を指定した場合、KarpenterはSpotを常に優先しますが、Spotのキャパシティが低下した場合には自動的にOn-Demandインスタンスにフォールバックするほど賢く作られています。Solutions Architect Associate認定試験を受けた方なら、Spotインスタンスは2分前の警告で終了する可能性があることを覚えておく必要があります。Karpenterはこの2分間の警告を処理してくれるので、自分で何かする必要はありません。バックアップのSpotインスタンスをスピンアップし、終了するインスタンスをCordonして排出し、ローリングデプロイメント方式でPodを移動します。Node Termination Handlerをインストールして管理する必要はありません。Spotの中断ハンドラーが組み込まれているからです。
Amazon EKS Auto Modeの紹介:簡素化されたクラスター管理


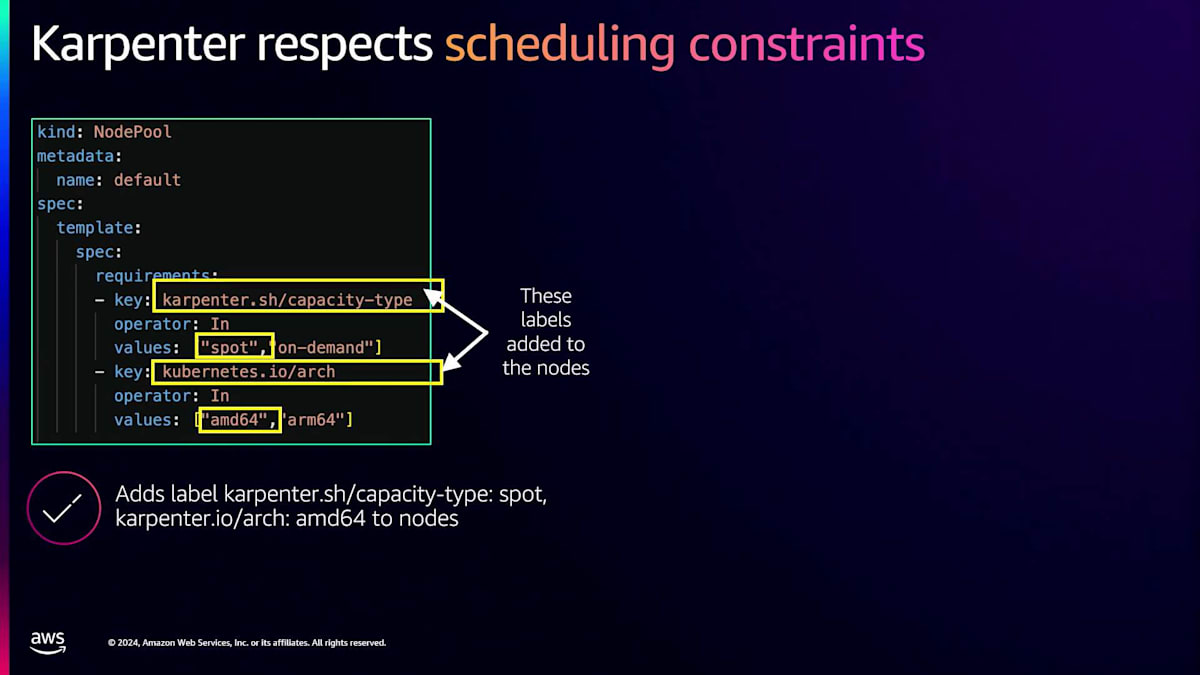
さらに、Kubernetesで実際の本番ワークロードを使用した経験がある方なら、Karpenterでスケジューリングの制約も必要になることをご存じでしょう。Node Selector、Node Affinity、TaintsとTolerations、Topology Spreadなど、さまざまなスケジューリングの制約を使用できます。これについて詳しく見ていきましょう。左側にNodePoolを示していますが、このNodePoolはCapacity TypeがSpotインスタンスで、Architecture TypeがAMD64のインスタンスをスピンアップします。このNodePoolがプロビジョニングするインスタンスには、Karpenterがすべてのキーと値のペアをラベルとしてノードに付与します。例えば、Karpenterは「capacity-type: Spot」、「kubernetes.io/architecture: AMD64」などを付与します。

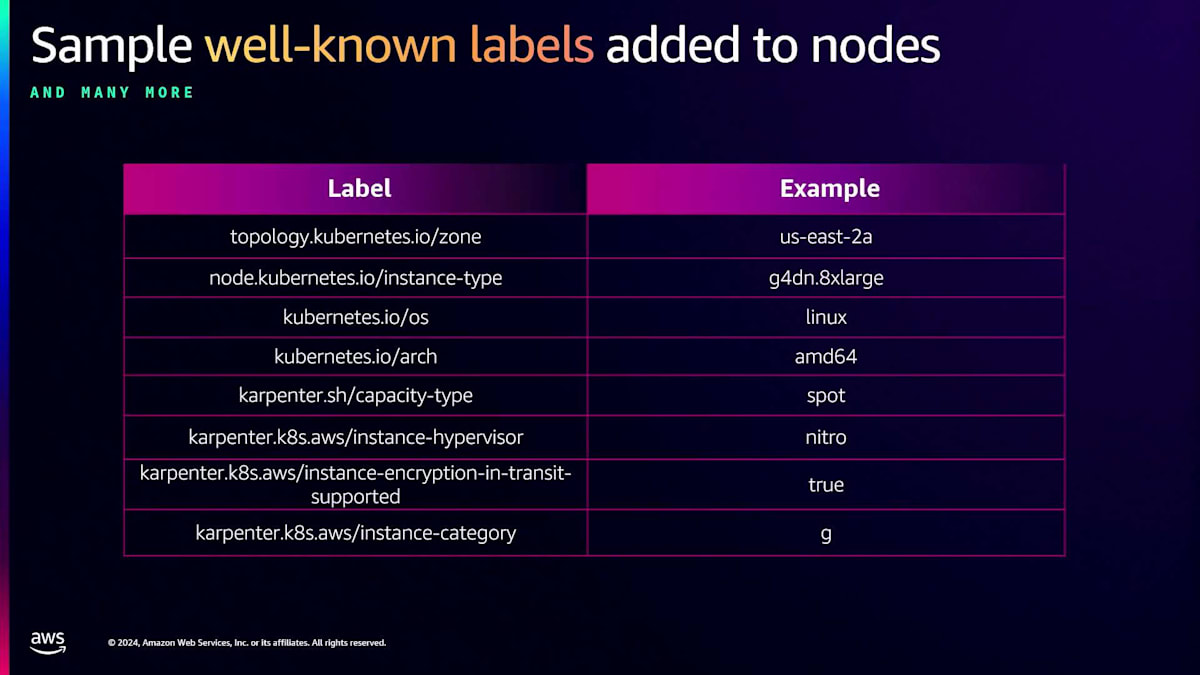
これはどういう意味でしょうか?右側に、サンプルのPod仕様ファイルを表示しています。これらのキーバリューペアを使用して、特定のインスタンスにPodをスケジュールすることができます。この場合、これをデプロイして、EC2がすでに実行中であれば、Podはそこにスケジュールされます。EC2が実行されていない場合、Karpenterはスケジューリング要件を満たすためにSpot Instanceをスピンアップします。また、Karpenterは自動的にノードに一般的なラベルを付与します。特別な設定は必要ありません。例えば、ゾーン、インスタンスタイプ、オペレーティングシステムなどのフィールドを、スケジューリングのための仕様ファイルで使用できます。

ユーザー定義のラベルについて疑問に思われるかもしれません。Karpenterはそれもサポートしています。この例では、左側でユーザー定義のアノテーション、テイント、ラベルをNodePoolで使用する方法を示しています。右側では、それらのラベル、テイント、アノテーションを使用してPodをスケジュールできます。これは異なるアプリケーションのPodをスケジュールする非常に一般的な方法です。異なるラベルを持つ複数のNodePoolを用意し、各チームがそれらのラベルを使用して自分たちのワークロードをスケジュールできます。




ここで良い質問が出てきます:いくつのNodePoolを定義すべきでしょうか?いくつかの選択肢があります。最も簡単なのは、すべてを単一のNodePoolに配置する方法で、各チームがそれらのフィールドを使用してPodを指定しスケジュールします。私のお客様の間で最も一般的なアプローチは、各チームが独自のNodePoolを持つ複数NodePoolの方式です。主な理由の1つは、あるチームが高価なGPUを使用している場合があり、そのNodePoolのlimitフィールドで特定のCPUやメモリ量に制限できることです。また、ノイジーネイバーの問題があったり、他のチームより多くのCPUやメモリが必要だったり、異なるタイプのインスタンスが必要な場合もあります。そのため、別々のNodePoolを使用してチームを分離できます。もう1つの高度な戦略は、重み付けNodePoolです。



重み付けNodePoolとは、特定のNodePoolに優先順位を付けることができる機能です。Reserved InstancesやSavings Planを他のインスタンスタイプより優先したい場合に使用します。この概念を明確にするために例を挙げてみましょう。この例では、2つのNodePoolを示しています - 上部のものは重みが60で、下部ではインスタンスタイプがCとRであることがわかります。これらの2つのインスタンスタイプについてReserved Instanceの契約があると仮定しています。Podがペンディング状態になると、最初のNodePoolを使用し、制限に達するまでインスタンスをスピンアップし続けます。例えば、特定の数のReserved Instance契約がある場合、CPUまたはメモリが1000に達するまでインスタンスをスピンアップし続け、その後、他のNodePoolが引き継いで異なるインスタンスタイプのプロビジョニングを続けます。
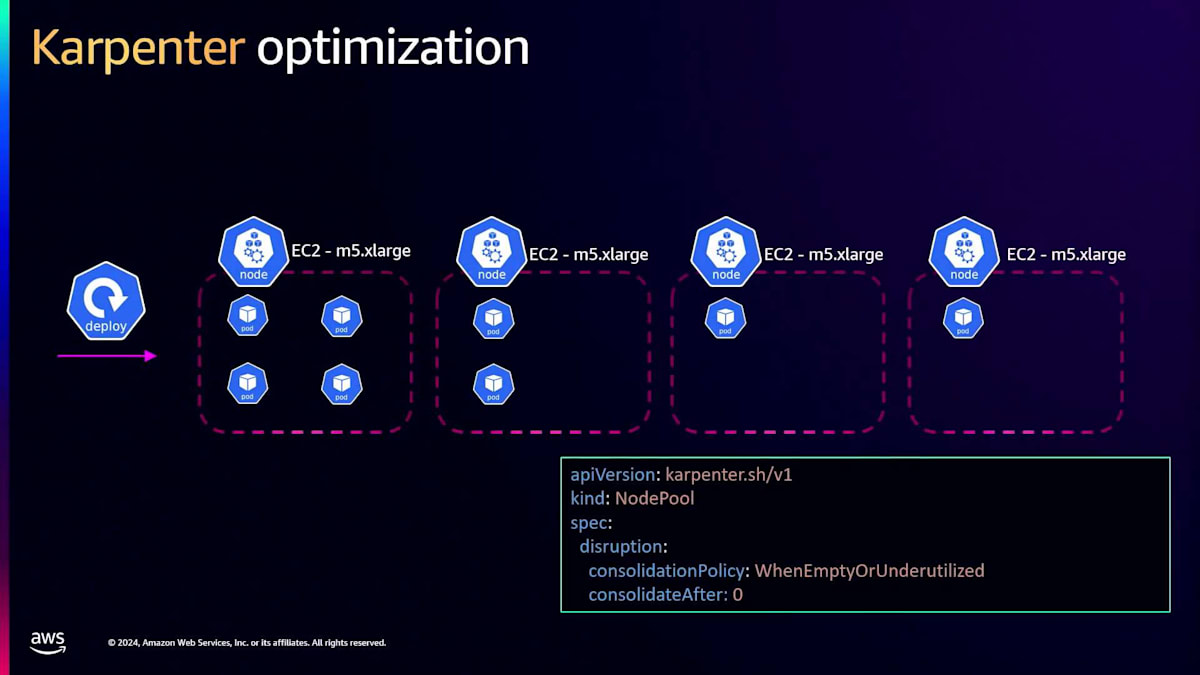
先ほど、Karpenterが最初からコスト最適化できると言及しましたね。この時点で、クラスターはKarpenterで実行され、適切なインスタンスタイプが選択されています。しかし、時間とともに、ワーカーノードは次のような状態になる可能性があります:最初のワーカーノードは適切に使用され、bin packingされていますが、残りの3つはそれほどでもありません。Karpenterでは、空または使用率の低い状態でのConsolidation Policyを指定でき、Karpenterは自動的にPodを戻し、不要なインスタンスを終了させてコストを削減します。ただし、お客様からのフィードバックとして、これは素晴らしい機能ですが、Karpenterはこのシミュレーションと統合を約10秒ごとに実行するため、多くのノードが立ち上がったり停止したりする可能性があるという指摘がありました。

このような理由から、私たちはこの動作を制御するための新しいパラメータを導入しました。 これはKarpenterバージョン1に含まれており、そのフィールドは「consolidateAfter」です。下の例で示すように、consolidateAfterを1時間と指定しています。このように、インスタンスがこのような状態になっていても、Karpenterは統合する前に1時間待機します。なぜなら、ワークロードの特性を最もよく理解しているのはあなただからです。5分後に新しいワークロードが来ることを知っている場合、これらのインスタンスに手を付けずに少し待つようKarpenterに指示することができます。新しいPodの追加や削除がない状態で1時間が経過した後にのみ、Karpenterは統合を行い、未使用のインスタンスを終了させます。


Karpenterは既存のインスタンスへの統合だけでなく、インスタンスの置き換えやサイズの最適化も行うことができます。この例では、2番目と3番目のインスタンスがm5.xlargeですが、これら2つのPodを1つのm5.xlargeにビンパッキングしても、まだ非効率な状態です。Karpenterはこのような状況を賢く認識します。 そして、これら2つのm5.xlargeインスタンスを終了し、代わりにインスタンスサイズが半分のm5.largeを起動することで、コストを削減します。これらはすべて設定不要で動作します。


よく受ける質問の1つに、日中に実行される重要なワークロードについて、顧客がKarpenterにこれらのインスタンスを中断させたくないというものがあります。そのため、Karpenterバージョン 1で disruption budget を導入しました。このdisruption budgetを使用することで、この中断動作を具体的にコントロールすることができます。このYAML設定を見てみましょう。これはnode poolのYAMLの一部で、最初のブロックではnodes zeroと指定しています。これは、 月曜から金曜の9時から8時間の間、driftedとunderutilizedの理由では0個のノードしか中断できないことを意味します。つまり、午前9時から午後5時までの間ということです。


ただし、空のノードの場合は、営業時間中や週末に関係なく、ノードの100%を中断することができます。 営業時間外では、driftedとunderutilizedの理由で、ノードの10%まで中断することができます。 これらはすべて累積的であることを覚えておいてください。つまり、これらをすべてまとめると、営業時間中は0%のノード、空のノードは営業時間中でも100%のノード、そして営業時間外ではdriftedとunderutilizedの理由で10%のノードまでが同時に中断可能ということになります。


driftの意味について説明させてください。KarpenterはKubernetesネイティブであり、Kubernetesのコア原則である望ましい状態と現在の状態の間の調整を行います。Karpenterも同様です。例えば、この場合、node poolではm5.largeのReserved Instancesの契約を使用しています。そのため、このnode poolが起動したすべてのEC2はm5.largeです。ここで、このm5.largeをc5.largeに変更したとします。 この場合、node poolの望ましい設定が、実行中のm5.largeインスタンスから逸脱することになります。そこでKarpenterは自動的に実行中のm5.largeをコードンして排出し、c5.largeインスタンスを起動して、Podを移行します。
EKS Auto Modeの詳細:コンピューティング管理とNodePool




Node Poolについて、そしてそれがインスタンスファミリー、Availability Zone、予算をどのように制御するのかを学んだところで、次はサブネットとセキュリティグループについて説明しましょう。これがEC2NodeClassの役割です。 例えば、EC2を起動可能なサブネットを選択したり、特定のセキュリティグループをEC2にアタッチしたりできます。 EC2用のAMIを選択したり、User Data、タグの付与、EBSの定義など、その他の設定も可能です。


特に重要なのがAMIの選択です。AMIセレクターを使用して、様々なAMIから選択することができます。AmazonはEKS最適化AMIを標準で提供しています。これらをEC2NodeClassで使用するには、 「alias@bottlerocket@latest」のような指定方法があります。これにより、KarpenterがプロビジョニングするすべてのEC2は、最新バージョンのEKS最適化AMIまたはBottlerocketで実行されます。同様に、「Amazon Linux 2@latest」という指定も可能です。 aliasでサポートされているファミリーには、al2、al2023、Bottlerocket、Windows 2019、Windows 2022があります。


新しいバージョンを最新版に移行する前にテストしたい場合、ワーカーノードを特定のバージョンに固定したいと考えるかもしれません。それも可能です。Karpenter v1では、 ワーカーノードを特定のAMIバージョンに固定できます。例えば、「alias bottlerocket@version 1.20.5」と指定すると、このNode ClassがプロビジョニングするすべてのEC2がこのバージョンのBottlerocketを使用します。同様に、Amazon Linux 2も 2024年7月29日のバージョンを指定できます。


KarpenterはカスタムAMIもサポートしています。 多くのお客様がカスタムAMIを使用しており、タグ名、所有者、IDを使用してカスタムAMIを選択できます。 これらの条件を満たすAMIが複数見つかった場合、Karpenterは最新のものを使用します。AMIが見つからない場合、ノードはプロビジョニングされません。この部分は注意が必要です - このような状況は避けたいところです。EC2NodeClassをデプロイしたら、AMIフィールドのステータスをチェックすることで、条件に合うAMIが選択されているかを確認できます。
これまでの流れをご覧いただくと、私たちがいかにカスタマーオブセッションであるかがわかります。最初はお客様自身がコントロールプレーンを管理していましたが、そこでEKSを作りました。そして、より良い体験を提供するためにKarpenterを作りました。では、Karpenterの次は何でしょうか?ここで、同僚のShitalをステージにお招きしたいと思います。

ありがとうございます、Raj。Karpenterについての素晴らしい詳細な説明でしたね。特に、その統合と最適化の仕組みを見るのは興味深かったです。Karpenterを使用している、あるいは使用していないお客様と多く関わっておられると思いますが、実際にKarpenterやCluster Autoscalerを運用しているお客様からどのような課題を耳にしていますか? よく耳にする課題の一つは「Raj、Karpenterは素晴らしいのですが、YAMLファイルにあまりにも多くのフィールドがあります。これらのフィールドをどのように選択すれば良いのでしょうか?インスタンスを最適化して適切なサイズにするにはどうすれば良いのでしょうか?」というものです。


これらのアプリケーションは、決して手間のかからないものではありません。 実際には、ネットワーキングやサービスディスカバリー、ロードバランシング機能などのいわゆるアドオンと呼ばれるコアクラスター機能に依存しており、さらにお客様のビジネス要件を満たすために必要なユーザー定義のアドオンにも依存しています。 最も重要なのは、クラスターのアップグレードとKubernetesクラスターの安全性維持が、このセッションに参加されている皆様の多くにとって最大の課題となっていることです。これには専門的な知識と継続的な時間投資が必要で、お客様が本当に求めているイノベーションのスピードを遅らせてしまいます。



これは素晴らしいですね。RajがKarpenterの詳細について説明し、今話した課題に対応しているように見えると、すでにお考えの方もいらっしゃるかもしれません。しかし、Raj、Karpenterを超えた課題にはどのようなものがあると思いますか? アドオンコントローラーを実行するためのベストプラクティスの推奨事項があり、それが組み込まれていると良いですね。 アドオンとそのバージョン、そしてこれらのコントローラーのライフサイクル管理も大きな課題です。Karpenterはそれらのニーズには対応しておらず、それ自体がコントローラーです。 すべてのベストプラクティスに従ってKarpenterを管理することだけでも、お客様にとって大きな課題となっています。そして使いやすさと即座に使える機能 - どうすればすぐに始められるのか?これは、お客様からよく寄せられる主要な質問の一つです。

素晴らしいですね。これらの答えと何か秘策をお持ちのようですね。では、ステージをお任せします。ありがとうございます、Raj。それでは、Amazon EKS Auto Modeをご紹介させていただきます。Amazon EKS Auto Modeとは何でしょうか? AWSのニュースブログをご覧になっている方はご存知かと思いますが、今や至る所で取り上げられています。技術的に言えば、Amazon EKS Auto ModeはKubernetesクラスターインフラストラクチャの管理を効率化するものです。

これから20分間で、EKS Auto Modeとは何か、そしてKubernetesクラスター上のアプリケーションデプロイメントをどのように簡素化するのかについて詳しく見ていきましょう。 第一のポイントは、Amazon EKS Auto Modeを使用すると、クラスター運用をAWSに委ねることで、俊敏性が向上しイノベーションが加速されるということです。これをどのように実現するのでしょうか?Amazon EKS Auto Modeの導入により、EKSは共有責任モデルの下で、これまで管理してきたKubernetesコントロールプレーンを超えて、Kubernetesデータプレーンにまで責任範囲を拡大しています。


アプリケーションが依存するコンピューティングリソースを動的にスケーリングすることで、パフォーマンスを向上させ、アプリケーションの可用性を維持します。さらに、デフォルトで安全性が確保されています。デフォルトで安全とは、どういう意味でしょうか?EKS Auto Modeは、ワーカーノードを自動的に更新し、セキュリティの修正を自動的に適用します。 また、自動容量計画と動的スケーリングにより、継続的にコストを最適化します。

どのようにしてこれを実現するのでしょうか? ご覧のように、クラスターを作成する際のAPIは変わらず、従来通りAmazon EKSを使用します。クラスターを作成すると、本番環境で必要となる全ての主要な機能が含まれます。つまり、クラスターを作成すると、マネージドコントロールプレーン、APIサーバー、そしてKubernetesインスタンスが一緒に提供されます。
これらのコア機能は、必要不可欠なコンポーネントと共に提供されます。アプリケーションをデプロイすると、クラスターインフラストラクチャが自動的にプロビジョニングされます。Amazon EKS Auto ModeはKarpenterの原則に基づいて構築されており、アプリケーションを監視し、デプロイ時にアプリケーションマニフェストで指定された要件に基づいてノードを起動します。アプリケーションのスケールに応じてリソースを動的にスケーリングし、継続的にコストを最適化します。最適化の原則と統合の原則は引き続き適用され、ノードとコアクラスター機能を自動的に更新します。
EKS Auto Modeの運用と自動更新メカニズム
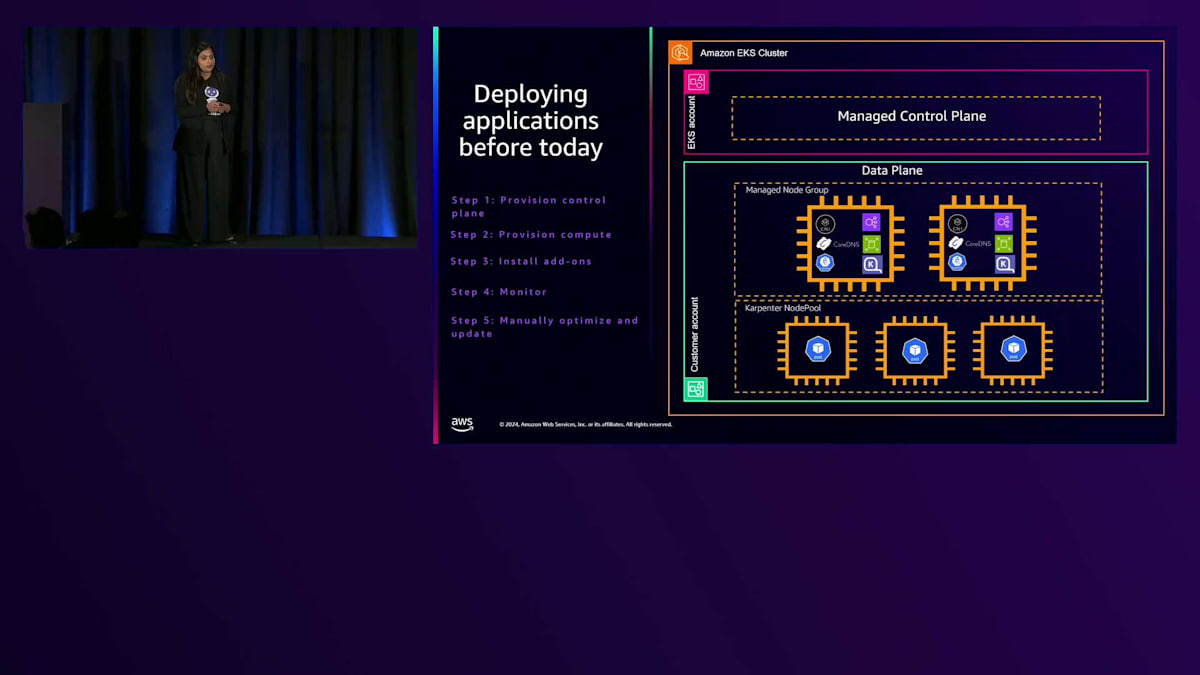

先ほど説明したスライドに戻ってみましょう。これまでのアプリケーションのデプロイ方法では、複数のステップが必要でした。ステップ1では、コントロールプレーンをプロビジョニングし、コンピューティングリソースをプロビジョニングし、さらにアドオンをインストールします。その後、リソース使用状況をモニタリングし、手動で最適化と更新を行います。今日からEKS Auto Modeを使用することで、アプリケーションのデプロイがはるかに簡単になり、これらのステップが大幅に削減されます。 まず、従来通りクラスターを作成し、コントロールプレーンをプロビジョニングします。 EKS Auto Modeでは、マネージドコントロールプレーンと共に、コンピューティング、ネットワーク、ストレージのためのマネージド機能を提供するコントローラーが自動的に提供されます。これらのコントローラーは、すべてAmazon EKSアカウントのAmazon EKSマネージドVPC上で実行されます。コントロールプレーンを更新する際に、これらのコントローラーのライフサイクルを自動的に管理するため、コンピューティングリソースのプロビジョニングや実行について心配する必要はありません。
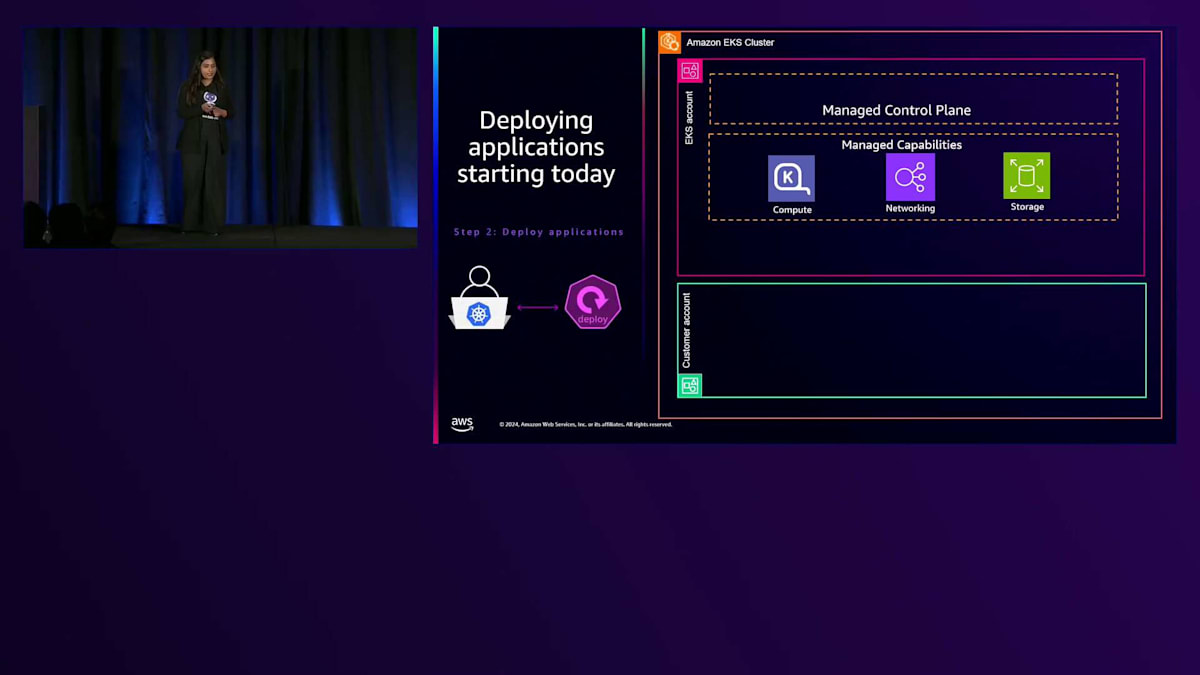

これでクラスターでアプリケーションをデプロイする準備が整いました。 では、アプリケーションを起動してみましょう。EKS Auto Modeは自動的にノードを起動し、 各ノードにはアプリケーションPodの機能に必要なすべてのノードエージェントやKubernetesエージェントが搭載されています。重要な点として、これらをEC2マネージドインスタンスと呼んでいます。これはAuto Mode自体の発表と同時に発表される特別な機能で、Amazonのようなサービスが内部で使用できるものです。これらは依然としてお客様のアカウント内で実行されるEC2インスタンスです。クラスターを作成する際には、アカウント内で実行されるこれらのインスタンスのライフサイクルを管理するための特別なIAMポリシーと権限を提供します。

Amazon EC2のマネージドインスタンスについて詳しく見ていきましょう。 Amazon EKS with Auto Modeは、引き続き特別なAMIを提供しています。Auto Modeでは、新しいAuto ModeマネージドAMIをリリースし、デフォルトでBottlerocket OSをサポートしています。ここで見ているAMIは、アップストリームのBottlerocket AMIの派生版です。EC2インスタンス内のコンポーネントについて理解する必要があります。Amazon EKS Auto Modeの登場により、運用モデルが変更されました。DNS、kube-proxy、CNIなどのすべてのノードエージェントとKubernetesエージェント、そしてPodアイデンティティ、ノードモニタリング、CSIノードエージェントがsystemdプロセスとして実行されます。クラスターを作成してkubectl get podsを実行すると、空のクラスターが表示されます。
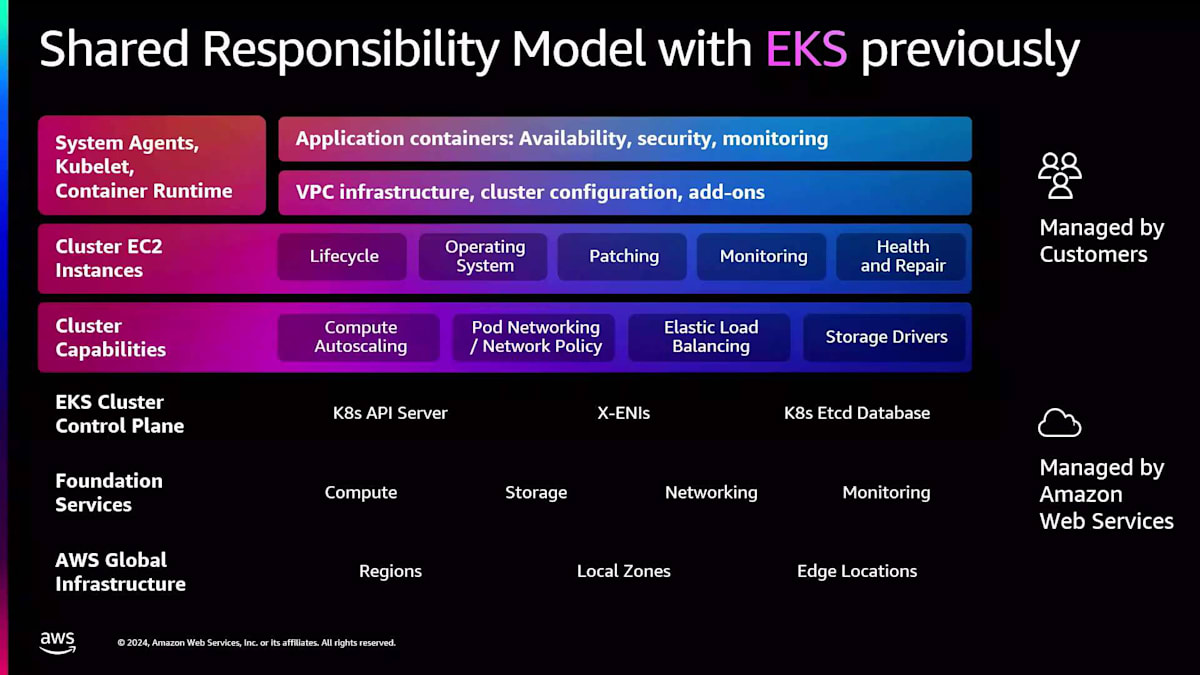
次に、 EKS Auto Modeをもう一つの視点から理解するために、共有責任モデルを見てみましょう。これまでは、AWSがグローバルインフラストラクチャーと基盤サービス全体に責任を持ち、EKSはKubernetesコントロールプレーン、APIサーバー、etcdインスタンスに責任を持っていました。お客様は、アプリケーション、可用性、セキュリティモニタリング、VPCインフラストラクチャー、クラスター設定に対して責任を持っていました。また、これらのインスタンスのライフサイクルとすべてのクラスター機能の管理も必要でした。

Amazon EKS Auto Modeにより、Amazon EKSの責任範囲が大幅に拡大しました。コントロールプレーンを超えて、クラスターインスタンスとクラスター機能の完全な管理にまで責任範囲が広がりました。お客様は、アプリケーションコンテナ、その可用性、モニタリングに対してのみ責任を持つことになり、クラスターインフラストラクチャーを心配することなく、イノベーションに集中できるようになりました。
お客様は引き続き、独自のVPCインフラストラクチャーやクラスター設定(マルチテナンシー要件のための設定やCNCFツールからのアドオンなど)を導入する柔軟性を持っています。これらはすべてEKS Auto Mode上で実行できます。基盤となるEC2インスタンスのパッチ適用、モニタリング、ヘルスチェック、修復など、差別化されていない作業の多くを私たちが担当します。

クラスター機能について詳しく見ていきましょう。まず、コンピューティングに関して、EKS Auto ModeはKarpenterの原則に基づいて構築されているため、オープンソースのKarpenterで得られるすべての利点がEKS Auto Modeでも利用できます。クラスターをプロビジョニングすると、パッチが適用されたKarpenterコントローラーが実行されます。コンピューティングの自動スケーリングと継続的な最適化が利点として挙げられます。また、デフォルトで読み取り専用ファイルシステムによってセキュリティが確保されたコンテナ最適化OSであるBottlerocket OSがサポートされています。
重要な側面の1つが、ヘルスモニタリングと自動修復です。Amazon EC2マネージドインスタンス上で動作するNode Repair Agentがヘルスステータスを監視し、Auto Modeにシグナルを送り返します。ノードが不健全な場合、そのノードを健全なノードに置き換えます。ストレージに関しては、Auto Modeを有効にしてクラスターを作成すると、デフォルトでBlock Store Controllerがインストールされます。多くの方々が課題を感じているネットワーキングについては、EKS Auto Modeの導入により、多くの面で簡素化を図っています。
これらのControllerには、ベストプラクティスが意見付きのデフォルト設定として組み込まれています。Auto Modeでは、現在多くの設定オプションを持ち、お客様にとって課題となっているVPC CNIに大きな変更を加えています。デフォルトでは、VPC CNIをPrefix Delegationモードで設定し、連続したIPブロックが利用できない場合はSecondaryモードにフォールバックします。Network Policyはすぐに利用可能で、完全マネージド型のクラスター内サービスロードバランシングと、クラスター外部へのアプリケーション公開機能も備えています。クラスターDNSについては、CoreDNSが各ノードで実行され、すぐに使えるスケーリング機能を自動的に提供します。

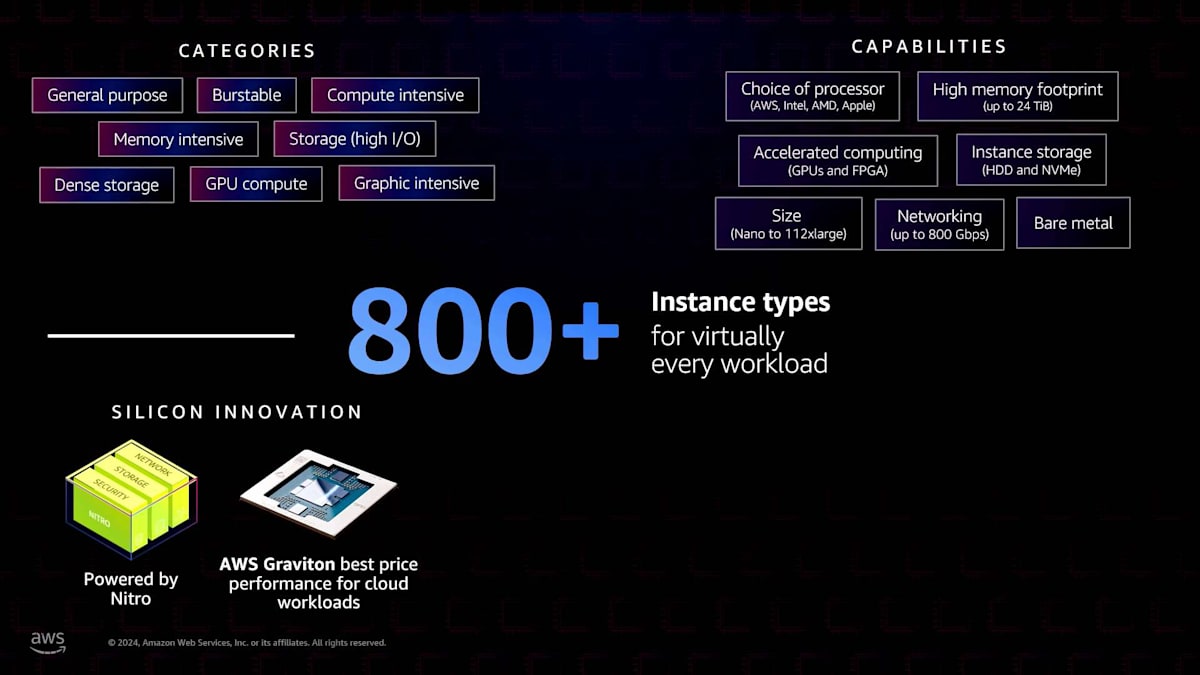
Auto Modeを使用する理由、またはAuto Modeを有効にしてクラスターを作成する理由をお考えの方に、主なメリットをご紹介します。より簡単かつ迅速に開始でき、完全マネージド型のクラスター機能を提供し、OSパッチングがすぐに利用可能でセキュアなデフォルト設定となっています。自動アップグレードに対応しており、Control Planeを更新すると、すべてのData Planeノードとコアクラスター機能も自動的にアップグレードされます。Kubernetesで動作するワークロードであれば、Auto Mode上でも動作するはずです。最も重要な点は、EC2インスタンスの機能を抽象化していないことです。現在ご利用のさまざまなカテゴリーのEC2インスタンスタイプのほぼすべてにアクセスできます。GPUやさまざまなインスタンス機能を利用でき、AWSのシリコンイノベーションにもアクセスできます。優れた価格性能と省エネ効率を提供するNitroやAWS Gravitonなど、これらのインスタンスタイプを引き続き使用できます。

購入オプションについては、Auto Modeでさまざまな選択肢を利用できます。On-Demandインスタンスやサービングプランなど、これらをAuto Modeで使用できます。 また、コストを重視し、Spotインスタンスのコスト効率の良さを評価される方は、Auto Modeでもそれを利用できます。
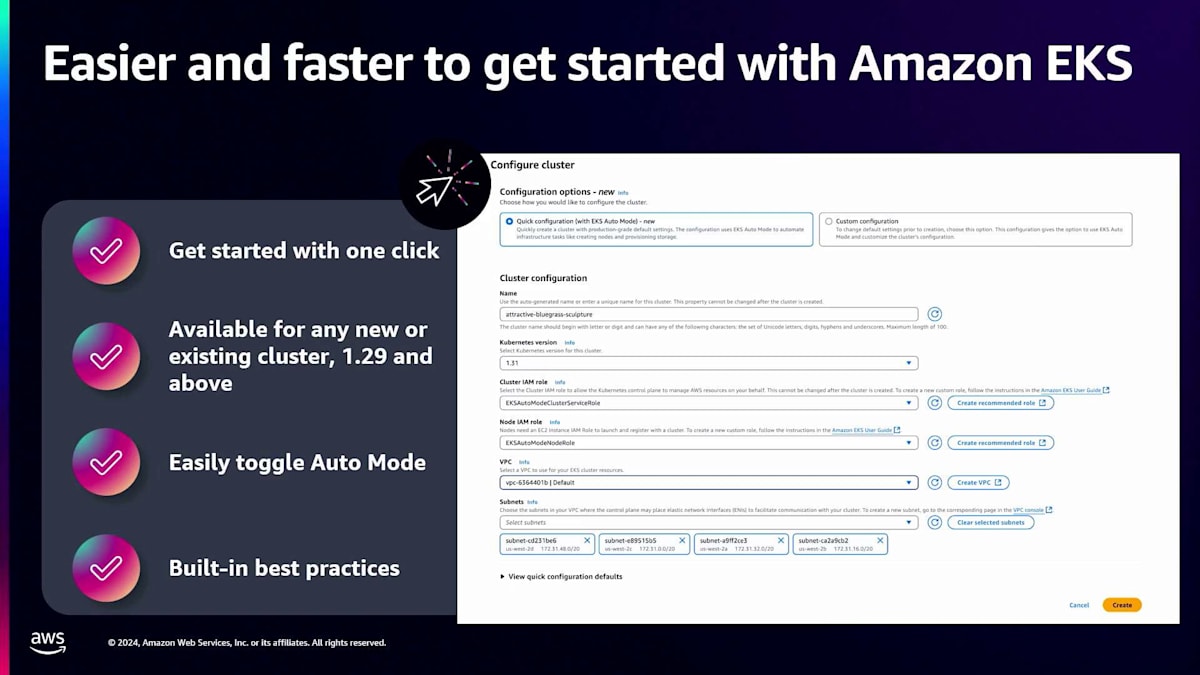

Auto Modeの導入に伴い、コンソールにもいくつかの改善を加えました。 AWS EKSクラスターの作成では、ワンクリックでEKSクラスターを起動できるクイック設定オプションを提供しています。Auto Modeはバージョン1.29以降で利用可能で、コンソールで簡単にAuto Modeの有効/無効を切り替えることができます。ベストプラクティスが組み込まれており、Auto Modeを有効にしてクラスターを作成すると、 General PurposeとSystemという2つのビルトインNode Poolがデプロイされます。これらは、先ほど説明したすべての機能をサポートするKarpenter APIです。

既存のクラスター作成方法を使用している場合、APIやコンソールを通じてのいずれの方法でも、Auto Modeを利用できます。また、ローンチ時にはTerraformのサポートも提供しており、eksctlを使って始めたい場合もサポートしています。重要な機能の1つとして、既存のクラスターでも簡単なトグルオプションでAuto Modeを有効にでき、運用の責任をEKSに任せることができます。
EKS Auto Modeのセキュリティと更新プロセス



コンピュートの管理面について詳しく見ていきましょう。まず、私たちは標準でビルトインNodePoolを提供しています。1つ目はGeneral Purposeです。これは、簡単に始められる環境を提供し、汎用的なワークロードをサポートするために作られました。On-DemandインスタンスタイプとGravitonおよびx86アーキテクチャの両方をサポートする組み合わせを備えています。設定には、デフォルトで有効化された統合機能、On-Demandキャパシティタイプ、最新世代のCおよびRインスタンスカテゴリの組み合わせが含まれています。デフォルトのノード有効期限は336時間(14日間)に設定されており、AMD64もサポートしています。


2つ目のビルトインNodePoolは、System NodePoolです。General Purposeワークロードも重要ですが、多くのアプリケーションが様々なアドオンに依存していることも理解しています。System NodePoolには重要なアドオンとno-schedule-onlyの設定が付属しており、既存のAWSアドオンファミリーを活用してEKS Auto Mode上で実行できます。AMDとARMの両方のアーキテクチャをサポートしています。System NodePoolには特別なTaintが追加されています。



これらのベストプラクティスと推奨設定は心強いものですが、柔軟性の必要性も理解しています。すでにself-managed Karpenterを実行している場合や、特定のユースケースがある場合は、独自のユーザー定義NodePoolを定義できます。ユーザー定義NodePoolの一般的なユースケースには、GPUやNeural系インスタンスなどのアクセラレーテッドインスタンス、Spotインスタンスの使用、異なる目的のための計算リソースの分離、チーム分離、ノイジーネイバーに対するテナント分離などがあります。重要な点として、General PurposeとSystem NodePoolは編集できません。編集を試みても、すぐに提供されているデフォルト設定に戻されます。

提供しているデフォルト設定の例に戻りましょう。ここでは、AI/MLチーム用に別のNodePoolを作成しています。インスタンスファミリーの値を指定すると、EKS Auto Modeは賢く、ファミリーを指定した際に、すべての機能を含むノードをプロビジョニングすることを理解します。つまり、ドライバーやKubernetesプラグインが組み込まれた状態で提供されるということです。
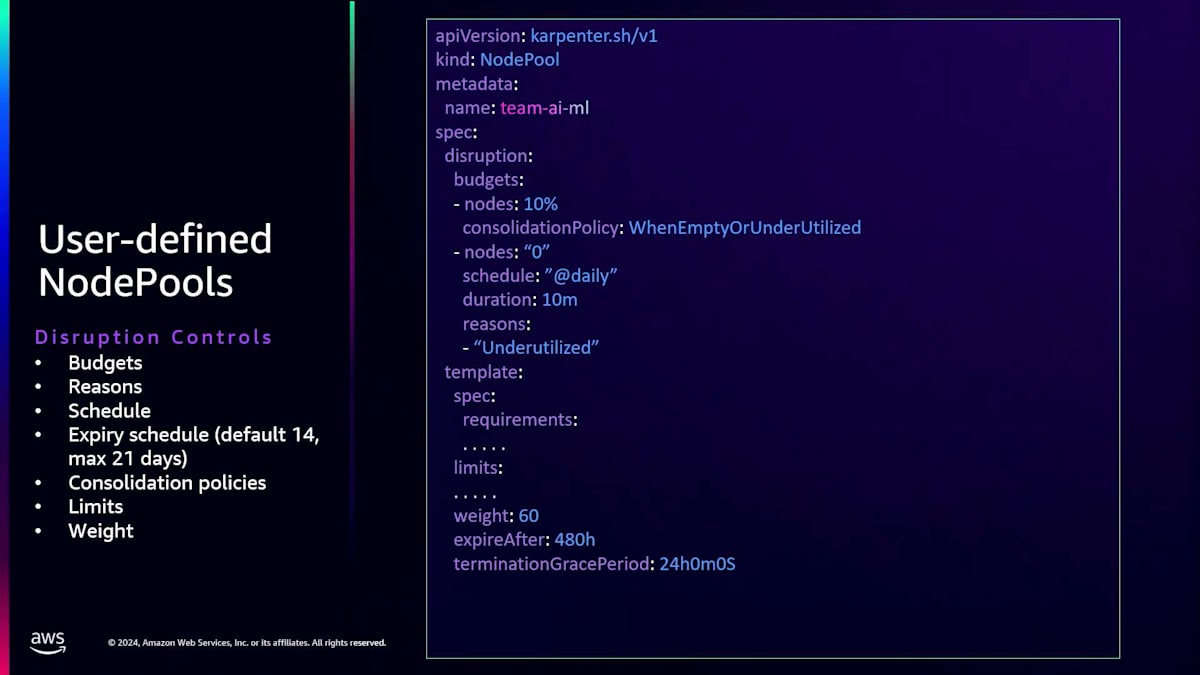


引き続き、すべてのDisruptionコントロールにアクセスすることができます。これまでに説明したBudget、理由、有効期限、制限、重み付けなどの設定が可能です。Auto Modeの導入に伴い、EKS NodeClassという新しいクラスを導入しています。NodeClassでは、SecurityGroupやSubnetをすぐに設定することができます。NodePoolと同様に、クラスター作成時に指定したクラスターSubnetとNodeのSecurityGroupをデフォルトとする、デフォルトのNodeClassが1つ提供されます。これは、GeneralPurpose NodePoolとSystem NodePoolの両方から、NodeClass参照を通じて参照されます。
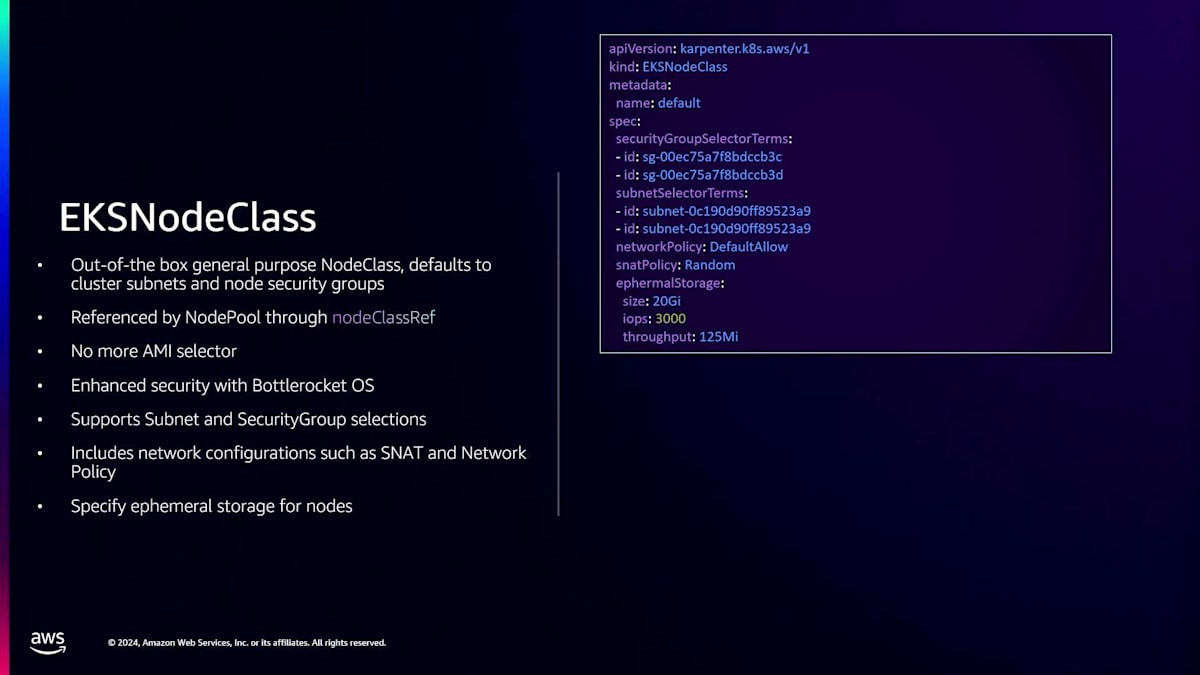
ここで重要な違いは、インスタンスのライフサイクルを完全に管理するため、EKS NodeClassが非常にシンプルになり、AMIセレクターが不要になることです。私たちがこれらを管理するため、AMIを指定する必要がなくなりました。Bottlerocket OSのサポートにより、セキュリティが強化されています。独自のSecurityGroupやSubnetを導入したい場合は、ユーザー定義のEKS NodeClassを作成することで可能です。SNATの設定やネットワークポリシーなどのネットワーク設定も含まれます。また、これらのインスタンスで使用するEphemeralストレージも指定できます。


ユーザー定義のNodeClassは、このように定義します。ここでは、先ほど作成したNodePoolで使用する「team-ai-ml」というユーザー定義NodeClassを定義しています。複数のNodePoolを定義する戦略は、EKS Auto Modeでも同様に適用されます。迅速に開始したい場合や、シンプルな開始エクスペリエンスを求めている場合は、GeneralPurpose NodePoolやSystem NodePoolを使用できます。これらのGeneralPurpose NodePoolと併せて、複数のNodePoolを使用することができます。GeneralPurposeとSystem NodePoolのデフォルトの重み付けは0で、独自のNodePoolでワークロードの優先順位を設定したい場合は、それに応じて重み付けを設定できます。



Auto Modeを使用する重要なメリットの1つは、運用の簡素化と運用オーバーヘッドの削減です。EKS Auto Modeが、コア機能とDataPlaneノードの自動更新をどのように処理するのか見ていきましょう。ここで共有責任モデルを理解することが重要です。昨日から、Auto ModeはControlPlaneを自動的にアップグレードするのかという質問を多く受けています。これは懸念されるかもしれませんが、そうではありません。ControlPlaneの更新は引き続きお客様の責任であり、更新前のベストプラクティスもすべて適用されます。下位環境でのテストや、最新バージョンのKubernetesでアプリケーションが動作することを確認するためのアップグレード健全性チェックの実行を強くお勧めします。



新しいバージョンのリリース時には、各バージョン向けの最適化されたBottlerocket AMIも公開されます。この最新のAMIがリリースされると、アクションが開始されます。ノードの更新の仕組みを見る前に、EKS Auto Modeのもう1つの特徴である、クラスター機能の自動アップグレードについて見てみましょう。ご覧のように、Karpenterバージョン1が実行されており、EBSストレージコントローラーも1.34.1が動作しています。Amazon EKSはコントローラーのバージョンをチェックし、これらのコントローラーの更新が必要かどうかを判断します。他のコントローラーは更新の必要がありませんでしたが、ネットワークコントローラーについては新しいバージョンがリリースされたため、Amazon EKS Auto Modeは必要なコントローラーのみを更新します。すべてのコントローラーの更新が常に必要というわけではないからです。

これらのコントローラーを更新する際に重要なのは、これらのコントローラーの更新がブロッキングされないということです。つまり、現在Control PlaneやAPI Server、etcdを更新する際と同様に、アプリケーションは継続して実行されます。同様に、これらのコントローラーを更新している間も、アプリケーションは正常に動作し続けます。



Data Planeの更新の仕組みについて説明させていただきます。完全にゼロタッチで、皆様が何かを行う必要はありません。 Amazon EKS Auto Modeは、Disruption Budgetを尊重します。Control Planeが1.31にアップデートされたことを検知すると、 古いWorker Nodeを最新のAMIに置き換えていきます。ここでご覧のように、古いノードが1.31のAMIに置き換えられており、 Node PoolのDisruption Budgetやマニフェストで設定したDisruption Budgetをすべて尊重しながら、ローリングデプロイメント方式で実行されます。





注目すべき点として、デフォルトでは10個のパーパスNodePoolには14日間の有効期限が設定されています。ただし、ユーザー定義の Node Poolの有効期限は最大21日まで設定可能で、更新されていない場合は21日目に強制更新されます。次に、 Auto Modeでのセキュリティアップデートの処理方法について説明します。ここでも同様の考え方が適用され、Karpenterのドリフト検出が機能します。 Amazon EKSは最新のパッチを含む最新のAMIを公開します。これには、ノード上で実行されているエージェントのパッチも含まれる場合があります。 ここでもDisruption Budgetを尊重し、ローリングデプロイメント方式でWorker Nodeを置き換えていきます。ご覧のように、古いノードが 最新のAMIバージョンに置き換えられ、21日間の強制更新ルールもここで同様に適用されます。
EKS Auto ModeとKarpenterの今後:まとめと展望

まだAuto Modeを 使用していない方や、Auto Modeでクラスターを作成していない方は、ぜひ始めることをお勧めします。KubernetesやAmazon EKSを初めて使用する方でも、モダナイゼーションの取り組みを加速させたい方でも、Amazon EKS Auto Modeは最適な選択肢です。運用の負担をAmazon EKSに任せたいとお考えの方は、ぜひAmazon EKS Auto Modeを本番環境で使用してください。Auto Modeはすべての商用リージョンで一般提供されており、まもなく中国やGovCloudでもサポートを開始する予定です。

ここで、締めくくりの考察のためにRajを再びステージにお迎えしたいと思います。Amazon EKS Auto Modeは皆様のより迅速なスタートを支援するようですが、Karpenterに情熱を持つ者として、オープンソースのKarpenterはどうなるのでしょうか?私たちはKarpenterを愛しており、AWSでは愛情を持って開発を続けています。そして、オープンな形での開発にコミットしています。Karpenterはなくなることはありません。繰り返し申し上げてきたように、Amazon EKS Auto ModeはKarpenterの原則に基づいて構築されているため、Karpenterで利用可能になる機能は、Auto Modeでも利用可能になります。

ご覧の通り、非常に柔軟な対応が可能です。Amazon EKSをより速く、より簡単に始めたいとお考えの方には、Amazon EKS Auto Modeがその答えとなります。クラスターを作成すると、すぐに多くの機能を利用できます。KarpenterやStorage、Ingressなどのアドオンの管理やアップグレード、そして先ほど説明したその他多くの機能を私たちが管理します。Amazon EKS Auto ModeとKarpenterのどちらを使用する場合でも、完全なアップストリームのKubernetes準拠で動作します。これは多くの情報であり、まだ始まりに過ぎないことは承知しています。 より詳しい情報は、様々なセッションを通じて入手できます。ここにいるSheetalは、明日と明後日の2つのBuilderセッションを担当しています。Amazon EKS Auto Modeについては、この講演の直前に彼女が公開したローンチブログを読むことでより詳しく知ることができます。また、Cluster AutoscalerからKarpenterへの移行ガイダンスもご用意しています。これからQ&Aの時間を設けますが、その前に、このセッションが良かった、あるいはフィードバックがある場合は、セッションサーベイの記入をお忘れなくお願いします - 私たちは皆様のご意見を真摯に受け止めています。本セッションにご参加いただき、誠にありがとうございました。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion