re:Invent 2024: HelloFreshのデータ革命 - Data Meshから Tardisへの進化
はじめに
海外の様々な講演を日本語記事に書き起こすことで、隠れた良質な情報をもっと身近なものに。そんなコンセプトで進める本企画で今回取り上げるプレゼンテーションはこちら!
📖 AWS re:Invent 2024 - HelloFresh’s data journey: Insights from scaling to 1 billion meals (SEG207)
この動画では、HelloFreshのデータプラットフォーム構築の取り組みが紹介されています。急成長期に直面したHelloFreshが、中央集権的なデータチームのボトルネックを解消するためData Meshを導入しましたが、最初は失敗に終わりました。その後、異なるPersonaのニーズを理解し、Tardisと呼ばれるマルチモーダル統合データプラットフォームを構築。Backend EngineerやData Analystが簡単にデータを扱えるようになり、データアセットの作成が650%以上増加しました。AWS EMR、S3、EKSなどを活用し、Data Contractsの実装やコスト分析ダッシュボードの構築など、具体的な成果も上げています。分散化の目的を明確にし、プロダクトチーム全体を巻き込むことの重要性も強調されています。
※ 動画から自動生成した記事になります。誤字脱字や誤った内容が記載される可能性がありますので、正確な情報は動画本編をご覧ください。
※ 画像をクリックすると、動画中の該当シーンに遷移します。
re:Invent 2024関連の書き起こし記事については、こちらのSpreadsheet に情報をまとめています。合わせてご確認ください!
本編
HelloFreshのデータプラットフォーム革新:自己紹介と概要

みなさん、こんにちは。HelloFreshのセッションへようこそ。私はAWSのSenior Account ManagerのCornelia Patzlspergerです。HelloFreshとの統合データプラットフォームのプロジェクトは、私のAWSでの5年間の中で最もインスピレーションを受けたプロジェクトの一つだったので、本日は大変嬉しく思います。

本日のメニューをご紹介させていただきます。このトークでは、ビジネスを実際にサポートするデータプラットフォームの構築とスケーリングについての洞察を得ていただけます。また、Data Meshという概念を実際のData Mesh実装に変換する際のベストプラクティスもご紹介します。そして、HelloFreshのプラットフォームが、パーソナライズされた料理やロイヤリティプラットフォームといったビジネスユースケースをどのように実現したかについても一緒に見ていきましょう。それでは、大きな拍手でNuno CapetaとAnnie Meininghausをお迎えしましょう。

みなさん、こんにちは。Annie Meininghausです。HelloFreshでProduct Managementを率いています。データ駆動型プロダクトの構築に情熱を注いでいます。HelloFreshにとってここ数年は大きな挑戦の時期でした。急速な成長フェーズを経験し、その状況をコントロールし、お客様に本当に愛していただけるデータ駆動型プロダクトを継続的に構築できるようになった今日、その経験を皆様と共有できることを大変嬉しく思います。みなさん、こんにちは。私も今日のre:Inventで、私たちがどのようにしてデータプラットフォームを本当に使いやすく、ユーザー中心のものへと変革したかをお話しできることを大変楽しみにしています。
HelloFreshの急成長とデータ駆動型ビジネスへの挑戦

まず、HelloFreshをご存じない方のために、簡単に会社の紹介をさせていただきます。HelloFreshは2011年にベルリンでミールキット事業として設立されました。ミールキットでは、お客様が簡単に料理できるよう、計量済みの食材をご自宅にお届けしています。現在では、グローバルに統合された食品ソリューショングループとして、3大陸18の市場で事業を展開し、「人々の食生活を永遠に変える」というミッションを掲げています。

このスライドでは、HelloFreshの異なる事業分野をご覧いただけます。現在、HelloFreshは9つのブランドポートフォリオを運営しています。左端に見えるのが家庭料理で、これが私たちの原点であり、HelloFreshというメインブランドの始まりです。そこから隣接カテゴリーへと拡大していきました。例えば、ビーガンやケトダイエットなどのニッチな食事に特化したGreen Chefや、アメリカでより予算を抑えたブランドとしてEveryPlateを立ち上げました。そこからさらに新しい分野へと進出しています。利便性はHelloFreshが重視している最も重要な顧客ニーズで、FACTOR_のような会社は、すぐに食べられる食事をお届けすることで、その利便性を次のレベルへと高めています。これは現在、最も急成長している事業分野です。さらに、PET PLATEでペットフード分野にも進出し、FACTOR_FORMではサプリメントやプロテインシェイク、水分補給製品も手がけています。このように、私たちは家族全員の健康的な食生活のあらゆる側面をカバーする事業展開を進めています。

当社の規模感をより具体的にご説明させていただきますと、先ほど3大陸にまたがって展開していると申し上げましたが、このスライドは、私たちのビジネスがデジタルプロダクトとしての側面が大きい一方で、その背後には巨大なサプライチェーンと製造事業が存在することをよく示しています。現在、41のフルフィルメントセンターを運営しており、そこでは17,000人の従業員が働いています。このネットワークを通じて、昨年は76億ユーロの売上高を達成し、10億食分のミールをお客様にお届けすることができました。

このスライドを見ていただくと、2019年までは非常に安定した持続可能な成長率で順調に推移していたことがわかります。

しかし、その後にCOVIDの影響が明確に表れています。この時期に需要が急激に加速し、今日皆様にご紹介する多くのメカニズムやツールを迅速に導入しなければならなくなりました。 この期間を念頭に置いていただき、うまくいけば、また同じように成長できることを願っています。

先ほど触れましたが、Factor_は当社で最も急成長している事業部門です。2020年から2023年までの3年間で、米国でのマーケットシェアと事業展開を拡大し、さらにFactor_ブランドを6カ国に展開することで、売上を20倍に伸ばすことができました。 それでは、私たちのデータジャーニーについてご紹介させていただきます。急成長期に直面した際に、これらの学びを活用していただければと思います。
Data Meshの導入と課題:空っぽのキッチンからの学び

ビジネスが成長すると何が起こるのでしょうか? より多くのデータが生成されます。これは機会であると同時に課題でもあります。より多くのデータがあれば、より良いインサイトを構築でき、より良いインサイトがあれば、より良いプロダクトを作ることができます。より良いプロダクトは、より多くのお客様の獲得や維持につながり、それがさらにビジネスの成長を促進します。これは完璧なフライホイール効果です。しかし、このフライホイール効果を活用するためには、舞台裏でこの規模に対応できるメカニズムやスケーリングの仕組みに投資する必要があります。

これは私たちが直面した状況そのものでした。私たちには中央集権的なデータチームがありましたが、この急速な成長の過程で、この中央チームがボトルネックとなってしまいました。彼らは生成されるデータの膨大な量に圧倒されていただけでなく、先ほどお見せしたように、私たちは取扱カテゴリーを拡大し、新しいビジネスコンテキストを作り出し、毎日新機能をリリースしていました。これは、コンテキストを先取りし、データモデルを継続的に理解するという点で、このチームにとって大きな課題となりました。

では、どうすればよかったのでしょうか?Data Meshは、世界の平和とすべての問題を解決する解決策のように思えました。私たちは全てが整理できると考えていました。そこで、分散化を決め、チームにオーナーシップを与え、各チームが自分たちのデータ資産を所有し、自由に作業を進められるようにすれば問題が解決すると考えました。ちょっとお聞きしたいのですが - ライトで観客の皆さんがよく見えないのですが、同じような考えを持っていた方や、同じような問題に直面して同じ戦略を実施しようとした方はいらっしゃいますか?多くはありませんが、何人か手が挙がっていますね。そして、少なくとも最初の試みで成功した方はいますか?うーん、誰もいませんね。


これは興味深いですね。私たちも全く同じ経験をしました。分散化アプローチという素晴らしいアイデアを持っていましたが、実際に起こったのはこういうことでした。Data Meshの取り組みを始めた後、私たちは結局、データの混乱状態に陥ってしまいました。しかし当然ながら、失敗からは学びとチャンスが生まれます。私たちはこのアイデアを売り込むことには成功しました。特にリーダーシップレベルでは非常に成功し、強く推進され、皆が熱心でしたが、実装のためのプレイブックがありませんでした。私たちはレシピもないまま料理を作ろうとしているような状態で、手探りの状態でした。


二つ目の課題は投資に関する課題でした。私たちは社内プラットフォームを持っており、それがすべてをサポートし、成長をサポートできると考えていました。しかし、私たちはData Engineerのみをターゲットにしていました。これは大きな問題でした。というのも、同じボトルネックが続いていたからです。私たちは対象範囲を拡大できていませんでした。三つ目は主にオーナーシップとドメインの理解に関するものでした。私たちは主に、既存のものを分割して各ドメインに与え、人々がその場で学んでいくことを期待するというアプローチを取りました。これは完全な失敗に終わり、状況を改善するどころか、はるかに悪化させてしまいました。なぜなら、人々はコンテキストを持っておらず、自分たちが何をしているのかを本当に理解できていなかったからです。

そして最後の、私が最も重要だと考える点は、最初の段階で単純なリフト&シフトアプローチを取ってしまったことです。私たちは、ビジネスを本当に表現できるグローバルなデータモデルについて考えることなく、ただ今やっていることをそのまま続けて、どうなるか様子を見ようと考えていました。

そのアプローチはうまくいかなかったので、私たちは一歩下がって、もう一度考え直すことにしました。 社内には異なるPersonaが存在することに気づき、これまでの取り組みは一部のPersonaには効果的でしたが、他には効果的ではありませんでした。Data Engineers、Analytical Engineers、Data Analystsは、この分散型のアプローチの価値をすぐに理解し、取り組みを始めてくれました。
しかし、HelloFreshの全てのProduct Teamがこれらのデータの専門家にアクセスできるわけではないという事実を十分に考慮していませんでした。HelloFreshの多くのチームはFront-end Engineers、Analysts、Backend Engineersを含むフルスタック構成ですが、全てのチームがデータの専門家を持っているわけではありません。これは、Backend Engineersをもっとサポートする必要があることを意味していました。Backend Engineersは新しいサービスを作成し、新しいデータとビジネスコンテキストを生成していましたが、次に何をすべきかがよく分からないと言っていました。また、Product Ownersは本来、インサイトを得るまでの時間を短縮し、成功指標の作成を自律的に行う必要性があるはずですが、それを十分に理解できていないと感じました。彼らはスクワッドの優先順位付けを担当しているので、彼らが理解していなければ、どうやって物事を進められるでしょうか?

そこで、これらの人々をサポートし、全員がより自律的になれる方法、そしてデータをよりシンプルで簡単に公開する方法があるのではないかと考えました。 前述の通り、大きな問題の一つは、プラットフォームが全ての人向けではなかったことです。そこで、まずデータを利用可能にすることから始めました。最初に取り組んだのは、運用層から分析層へとデータをシームレスに移行する方法の確立でした。これは主要な障壁の一つでした - 運用層で生成されるすべてのデータにアクセスできなかったのです。



二番目の焦点は、以前過剰投資してしまったグローバルデータモデルに関する課題への対応でした。ビジネスの運営方法を表現するHelloFreshのグローバルデータモデルを作成し、注文とは何か、箱とは何か、そしてビジネスがどのように運営されているのかを本当に理解できるようにしました。それは改善につながり、人々がデータを持ち込んで分析し始めるのを目にするようになりました。しかし、まだ問題がありました。 私たちには空っぽのキッチンがありました - 誰も使っていないように見えるプラットフォームに投資していたのです。


そこで再び、なぜそれが問題だったのかを理解するためにProduct Thinkingを適用しました。問題の一つは、まだ統一されたソリューションではなかったことです。今日のほとんどのKeynoteで、統一化とグローバル化がキーワードとなっていました - ユーザーにとってシンプルにすることが最も重要です。異なるサービスをLegoのように組み合わせれば上手くいくというわけではなく、それらは一貫性を持つ必要があります。うまく機能させるためには、優れたPlaybook、ガバナンス、オーナーシップ、そして最も重要なのは、シンプルさが必要です。これが任意のプラットフォームにおける最も重要な要素です - ユーザーにどのように提示し、使いやすくするかということです。
Tardis:革新的なデータプラットフォームの構築と実装


ここで、私たちが現在どのような状況にあるのか、詳しく見ていきましょう。現在、私たちはTardisと呼んでいるData Kitchenを持っています。私たちは物事に名前を付けるのが好きで、少しギーキーなところがあるので、Tardisという名前を選びました。これは、内側の方が外側よりも大きい宇宙をうまく表現していると考えたからです。まず第一に、これによってデータの統合と取り込みが可能になり、複数のソースからデータを分析プレーンに取り込んで探索を始めることができます。二つ目の重要な点は、非常に簡単なオンボーディングプロセスを作ったことです。 開発者がローカルでテストできるCLIを作成し、現在は 組織内の誰もがData Productを作成できるUIを開発中です。三つ目のブレークスルーは、データアナリストやData Engineerの大半がTerraformやIAMのルールやパーミッションを扱いたくないという点でした。


この課題に対処するため、CLIとオンボーディングプロセスを通じて完全な抽象化を実現し、これらの複雑さを管理できるようにしました。 もう一つの重要な機能はコスト最適化です。マルチテナンシーアプローチを採用しているため、各AWSサービスの長所を活用してプラットフォームのコストを最適化できます。これについては後ほど詳しく説明します。


Data Analystを含む様々なペルソナをターゲットにしているため、モデル作成の自動化機能は非常に重要です。プラットフォームへのデータモデリングの統合を自動化する方法に多大な努力を投じました。そして最後に、しかし同様に重要なのが、トレーニングとドキュメントです。効果的に使用できないプラットフォームは役に立ちません。 そして、空のキッチンに戻ってきたわけです。



ここで、アーキテクトの方々に向けて、技術的なアーキテクチャを見ていきましょう。 Tardisはマルチモーダル統合データプラットフォームですが、これは実際には何を意味するのでしょうか?それは、複数の負荷と複数のタイプのデータワークロードを処理できるプラットフォームだということです。 最大の特徴は、その中でプレーンをどのように構築したかということです。まず、プラットフォームとの対話を可能にし、オンボーディングの自動化とモニタリングの主要な責任を担うManagement Planeがあります。


次に、オーケストレーションとユーザー管理が行われるControl Planeがあります。これはユーザーからは完全に抽象化されており、ユーザーはManagement Planeとのみやり取りを行います。これが私たちにとって大きな差別化要因となりました。そして、皆さんがよくご存じの典型的なデータプラットフォーム構造があります。これには、Ingestion、Processing、Serving レイヤー、そしてその上のStorageが含まれます。特に目新しいものではありませんが、使いやすさに重点を置いたことが本当の差別化要因となりました。


私たちのプラットフォームの活用事例について簡単にご説明させていただきます。ビジネスの大きな突破口となったのは、Event BusであるKafkaからデータを分析基盤に取り込めるようになったことです。以前は、Backend EngineerがKafka Connectorをセットアップし、ほとんどの人が理解していないStream Processorを扱い、S3 Bucketを作成し、さらにスキーマを理解するためにデータチームと調整する必要があったため、この作業には何週間も何ヶ月もかかっていました。非常に複雑だったのです。私たちは、この全てを1つのPRで実現できるように簡素化することを目指し、実際にそれを達成しました。

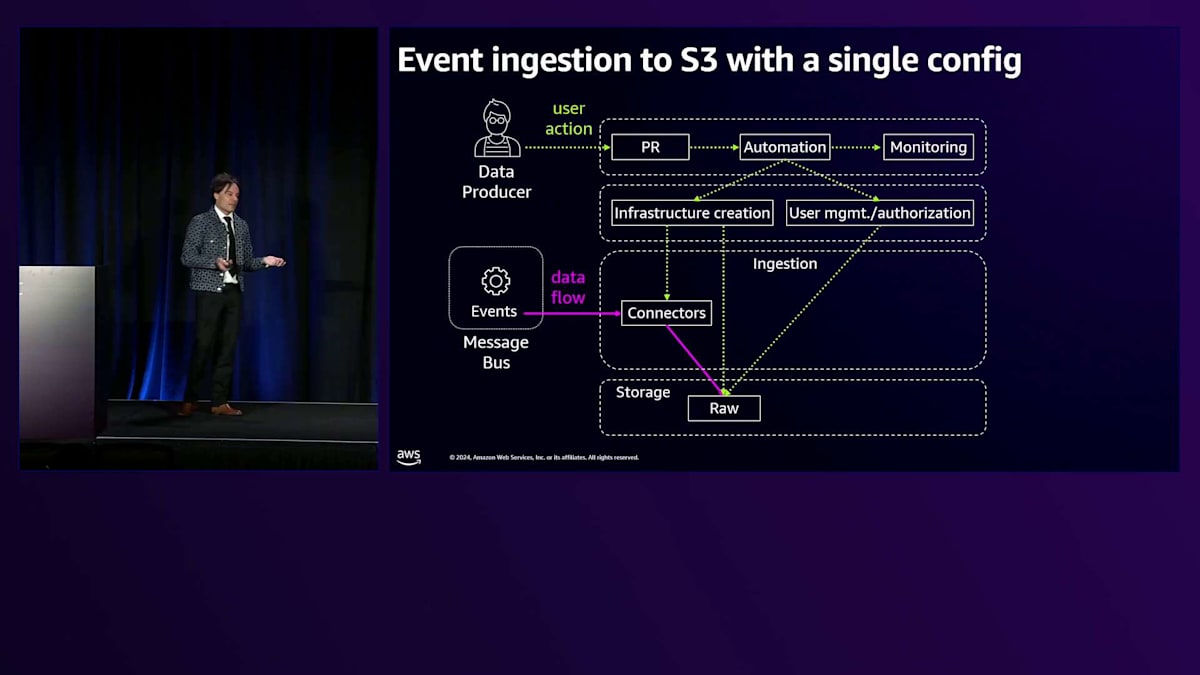
私たちは、Backend Engineerが誰でもSchema Registryと呼ばれるものを使用できる自動化を作成しました。また、その上にガバナンスを適用し、たった1つのPRでデータをData Lakeに同期させて即座にデータを取り込めるようにしました。これは本当に革新的で、何ヶ月もかかっていたプロセスを数日に短縮することができました。プロセスはシンプルです:PRを提出すると、S3 Bucket、Connector、Kafka関連のコンポーネント、管理ソリューション、ストレージなど、インフラに関連する全てが作成されます。データが流れ始め、数分以内に分析を開始できるようになります。

しかし、新たな課題に直面しました。S3にデータを取り込むという最初の問題は解決し、これは素晴らしいことだと思っていました - 誰もが分析を始められるはずでした。ところが、Backend Engineerから「データ処理について何も分からない。やはりData Engineerに相談する必要がある」という声が聞かれました。つまり、データは存在するものの、期待していたような加速は見られなかったのです。この気づきから、プロセスをさらに簡素化する方法について考え始めました。

データのオンボーディングを本当に簡素化してガイドできれば、それこそが私たちがまさに目指していることです。同じプロセスについて深く考えました。ワンクリックに戻れるなら - この場合、ProtoのJSONを何かに変換するのは少し複雑なのでワンクリックではありませんが、同じパラダイムです。Tardisとマルチレイヤーアーキテクチャーを通じて、私たちが実現しているのはまさにこのコンセプトです。Backend EngineerとData Engineerが、CLIまたは後ほどお見せするUIを使って、作成したいData Productを定義するだけで済むようにしています。その後は全てプラットフォームが処理してくれるので、オーケストレーション、ユーザー管理、データの同期、変換などについて考える認知的負荷から解放されます。


Rawデータを取得した後は、パイプラインを作成して実行するだけで、標準化されたデータが得られます。しかし、標準化されたデータだけでは十分ではありません。私たちのケースの大半はもっと複雑で、複数のソースからグローバルデータモデルへの変換が必要になります。ここでも私たちは、Data Vaultモデルの作成に通常何ヶ月もかかることについて深く考えました。モデリングに携わっている方は多くないかもしれませんが、おそらくその複雑さと、それに伴う課題の大きさはご理解いただけると思います。



私たちは同じコンセプトを活用して、アナリストたちにも同様のシンプルさを提供することを考えました。同じタイプのプラットフォームを使用し、同じツールを提供することで、同じ場所でデータの取り込み、変換、高度なモデリングを行えるようにしました。 これが私たちが実現したことです。同じインターフェース、同じタイプのツールを使用して、 同じプラットフォーム上で実行される高度なモデルを作成できるように、Analytical Engineerたちを支援しています。そして、データが流れ込み、 データが流れ出ていきます。

しかし、これで終わりではありません。ビジネスが加速する中で、よりリアルタイムに近い、あるいは完全なリアルタイムの機会にも対応する必要性が出てきました。全く新しいプラットフォームを作るのではなく、既存のものを活用し、発展させ、充実させて、ストリーミング機能を追加することを考えました。現在リリースして取り組んでいるのは、バッチやマイクロバッチから本当の意味でのストリーミングへの移行ですが、既存のコンセプトをそのまま活用しています。UIを通じて、 今では全てのData AnalystやBackend Engineerが、KafkaストリームからS3へとイベントをリアルタイムで取り込み、変換することができるようになりました。これは革新的で、ビジネス全体のコスト削減にも貢献しています。



では、これら全てをどのように実現しているのでしょうか?ご覧の通り、私たちはそれほど多くのAWSサービスは使用していません。 主に使用しているのは2、3のサービスです。その1つがAWS Identity and Access Managementで、これはもちろん、セキュリティの確保とPIIガバナンス、GDPR、その他の一般的なコンプライアンス要件のためのデータ分割に必要不可欠です。 AWS Glueは私たちのメインのテクニカルカタログです。ビジネスカタログも別にありますが、Glueは文字通り全てを繋ぎ合わせる役割を果たしています。全ての基盤となっているのが Amazon EMRです。EMRは数年間使用しており、大きな変革を経てきました。最初は一般的なEMR on EC2から始まり、AWSがEMR Serverlessをリリースした時は本当に嬉しかったです。これによって私たちのシステム構築方法が大幅に効率化されました。コストを跳ね上げる24時間365日稼働のクラスターを持つ必要がなくなったのです。最近ではEMR on EKSの導入を始めており、これは今までのどの方法よりも驚くほど低コストです。



もちろん、データの大部分はAmazon S3に保存されています。おそらくここにいる皆さんも同様にS3にデータを持っていることでしょう。そして、私たちのプラットフォームは全て Amazon EKS上で動作しています。私たちは「フォールトトレラントなクラスターアーキテクチャ」と呼んでいるものを採用しており、各チームにクラスターを分散配置し、必要に応じて素早く起動できる機能を提供しています。 かなり技術的な専門用語や情報が続きましたが、一つ強調したいのは、採用がなければどんなプラットフォームも意味がないということです。


数字をいくつか共有したいと思います。今日のKRを確認したところ、これらの数字はすでに古くなっていますが、今年は作成されたデータアセットが650%以上増加しました。 しかし、アセット数以上に重要なのは、組織全体でプラットフォームをどれだけスケールできたかということです。使用するチームが300%以上増加したことを、私たちは非常に嬉しく思っています。イメージをつかんでいただくために言うと、今年のKRでは組織全体のスクワッドの15%という目標を設定していましたが、今日確認したところ達成できていたので、とても嬉しく思っています。



さらに重要なのは、皆さんがこのプラットフォームに満足しているかどうかということです。プラットフォームに満足しているということは、そこで複数のケースが動いているということを意味します。ご覧のように、拡大と反復という数字が出ています。これらは本当に印象的な数字で、皆さんと共有したいと思い、私たちが構築してきたものに大変満足しています。 そしてもちろん、ユーザーからのフィードバックを見るのも嬉しいことです。 私たちが構築しようとしてきたのは、非常にユーザーフレンドリーなものであり、それを実現する方法について顧客からの支持を得るのに勝るものはありません。




それでは、実際にDataプロジェクトの構築方法をご覧いただきましょう。これは、私たちがBackstageの上に構築したばかりのUIです。社内プラットフォームと完全に統合されているので、ログインすると即座にSSOによる認証などにアクセスできます。 非常に簡単で、必要なのは主にチーム、Squad、 Tribeに関する情報、パイプラインを実行したいタイミング、作成したいテーブル名、そして必要なロードのタイプなどの情報を入力するだけです。 キーの重複がある場合は、もう少し情報が必要で、バージョンのタイプやテーブルをパーティション化するかどうかを指定します。




次に、インクリメンタルロードが許可されているため、プラットフォーム上で実行するデータのタイプを指定します。SQLを使用するか、SQLファイルをアップロードするか、独自のSQLを記述するかを選びます。これは非常に基本的な例で、要点を示すための単純なselect starです。 すべての情報が一箇所に集まり、それで完了です。 オンボーディングに使用している同じCLIがバックエンドで呼び出され、それで終わりです。ファイルが作成され、Pull Requestが作成されます。 Gitに移動して、すべてが正しいことを確認し、マージを押すと、データパイプラインの準備が整います。これはリアルタイムで、加速もしていません。



これが現在のHelloFreshでのDataプロダクトの構築がいかに簡単かということです。最後に強調したいことがあります。 Dataプロダクトを作成するだけでは十分ではありません。データを信頼できる必要もあります。そこで、私たちが実装しているもう一つの要素がData Contractsです。これは、プロデューサーとコンシューマーの間で、データを確実に利用できるという合意です。 私たちはPre-flight checksを使用してData Contractsを実装しており、これにより責任を左にシフトすることができます。誰かがDataプロダクトを作成するたびに、スキーマを破壊したり、アップストリームのコンシューマーに影響を与えたりしないかどうかを即座に検証できます。



プロダクトが公開されると、Post-published checksを実行します。これにより、データセットに問題があるかどうかを理解することができます。これは私たちのアラートシステム と監視プラットフォームに完全に接続されています。素晴らしい点が2つあります:データオーナーにアラートを送るだけでなく、データステークホルダーにもアラートを送ります。なぜなら、ビジネス側から間違ったデータがあると指摘されるほど嫌なことはないからです。このデモは何度見ても飽きません。 数週間や数ヶ月かかっていたものが、今ご覧いただいたようになったのは本当に印象的です。
プラットフォームの成果と今後の展望:CFOへの回答から学びまで
数週間や数ヶ月かかっていた作業が、ここで見てきたように改善されたのは本当に印象的です。今朝10時にCFOとミーティングがあり、私たちがかなり高額なチームとともに数ヶ月このプラットフォームの開発に取り組んでいることについて話が出ました。CFOは投資対効果について尋ね、すでに何か成果を示せるものがあるかを確認してきました。さて、どうでしょうか。期待通りの成果が出ていないと全員クビですね(笑)。私たちは今までかなり集中的に取り組んできましたので、社内でこのプラットフォームをどのように活用しているかをお見せしたいと思います。これは私たちが持つ重要なユースケースの1つです。

CFOの質問に答えるために、現在私たちはこのプラットフォームに様々なデータを取り込んでいます。自社製品は自分たちでも使用する方針で、実際に開発したものをテストしています。AWS Cost & Usage Reportsをはじめとするさまざまなデータを取り込んでいます。EKSクラスターからすべての情報を取得し、さらにユーザーレポートからKubecostのすべての情報も取得しています。これらをTardis に送り込むことで、CFOの質問に答えるためのCost Analysis Dashboardを簡単に作成できるようになりました。

私たちは主に年間計画のために使用しています。これにより、Tribe、Squad、さらにはクエリレベルで、インフラの各コンポーネントにかかるコストを正確に把握できるようになりました。これは運用の優れた点でもあります。なぜなら、単に実行コストだけでなく、もっと重要なパフォーマンスメトリクスも提供してくれるからです。パフォーマンスが良いか悪いかを判断でき、CFOに対しては、チームごとの2025年の 支出調整のための予測と予算を提示できるようになりました。


本日は HelloFreshのエンドカスタマーが、この新しいプラットフォームからどのようなメリットを得ているかをお見せせずには終われません。HelloFresh+のローンチにより、バックエンドで包括的な顧客プロファイルを活用した製品を作ることができました。私たちは顧客のロイヤリティと好ましい アクションに対して報酬を提供し、Tardisを活用しています。この詳細な顧客理解により、パーソナライズされた報酬を提供し、さらにアプリ専用の体験を発展させて、オンライン体験からオフラインのマーケティング資料、レポートボックス、プッシュ通知、メールまで、すべてが同期された形でオーケストレーションされるマルチチャネルエコシステムを作り出すことができました。



最後に、皆さんの今後の取り組みに役立つと思われるいくつかの学びをお伝えしたいと思います。最初の学びは、冒頭でお見せした空っぽのキッチンとそこで発生した問題に関連しています。分散化について考える際は、 単なるバズワードとしてではなく、目的を持って考える必要があります。そうでなければ何の助けにもなりません。コードを書かない人や、これまで関わっていなかった人も含めて、 プロダクトチーム全体を巻き込む必要があります。全員が新しい責任を理解しなければなりません。


3つ目の学びは、成功をどのように測定するかということです。私たちが採用したのは、Adoption(採用率)でした - 言葉遊びのつもりはありません。このタイプのプロダクトに関して言えば、1つのKPIを選ぶとすれば、Adoptionをお勧めします。 社内外のCustomerから実際のユースケースを見出し、そこからバックワードで考えることで、最終的にプラットフォームがポジティブなROIを示すことが保証されます。

ご清聴ありがとうございました。スピーカーの皆様に温かい拍手をお願いします。本日は皆様をお迎えできて光栄でした。ご質問がある方は、NunoとAnnieがここにいらっしゃいますので、お答えいたしますし、LinkedInでもコンタクトを取ることができます。1つお願いがございます。私たちは皆様のフィードバックを大切にし、それを基に改善を図りたいと考えておりますので、アプリで本セッションの評価をお願いいたします。 それでは、素晴らしい1日の続きをお過ごしください。皆様にも温かい拍手を送らせていただきます。
※ こちらの記事は Amazon Bedrock を利用することで全て自動で作成しています。
※ 生成AI記事によるインターネット汚染の懸念を踏まえ、本記事ではセッション動画を情報量をほぼ変化させずに文字と画像に変換することで、できるだけオリジナルコンテンツそのものの価値を維持しつつ、多言語でのAccessibilityやGooglabilityを高められればと考えています。
Discussion