LMStudioとLangChainでlocalチャットボットを作る
はじめに
本記事では、大規模言語モデル(LLM)とMLOpsの連携を学ぶ第一歩として、ローカル環境でLLMを活用したチャットボットの構築に焦点を当てます。特に、LM StudioとLangChain、Streamlitを組み合わせた実践的なアプローチを紹介します。
既存のチュートリアル記事(約2年前のもの)を参考にしつつ、ツールのインストール方法やライブラリのAPI変更点など、現在の環境に合わせた具体的な手順と技術的な考察を加えて解説します。最新の環境でスムーズにローカルLLMアプリケーションを構築できる実践的な情報の共有を目指します。
環境
本記事の動作確認は以下の環境で行いました。
- MacBook Pro
- 14インチ 2021
- チップ:Apple M1 Pro
- メモリ:32GB
- macOS:15.5(24F74)
ゴール
PythonでローカルLLMとチャットするアプリケーションを構築する
LM Studioを使ってみる
LM Studioは、ローカル環境で大規模言語モデル(LLM)を簡単に実行するためのデスクトップアプリケーションです。このツールは、特にプライバシー要件が高い場合や、インターネット接続が不安定な環境でのLLM利用において非常に有用です。本セクションでは、LM Studioのインストールから基本的なチャット機能の利用までを解説します。
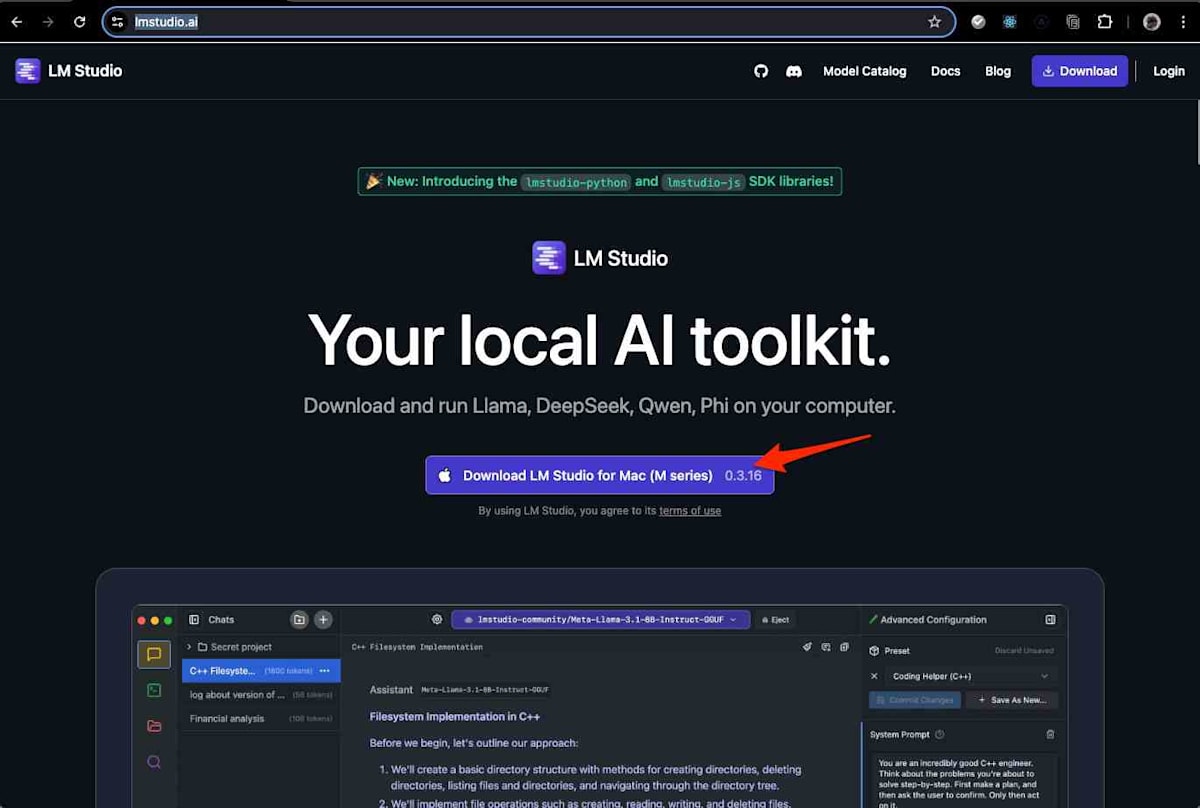
以下の公式ページからLM Studioをダウンロードし、インストールを進めます。
アプリのダウンロード後、一般的なmacOSアプリケーションと同様にD&Dでインストールします。このプロセスは直感的であり、特別な設定は不要です。
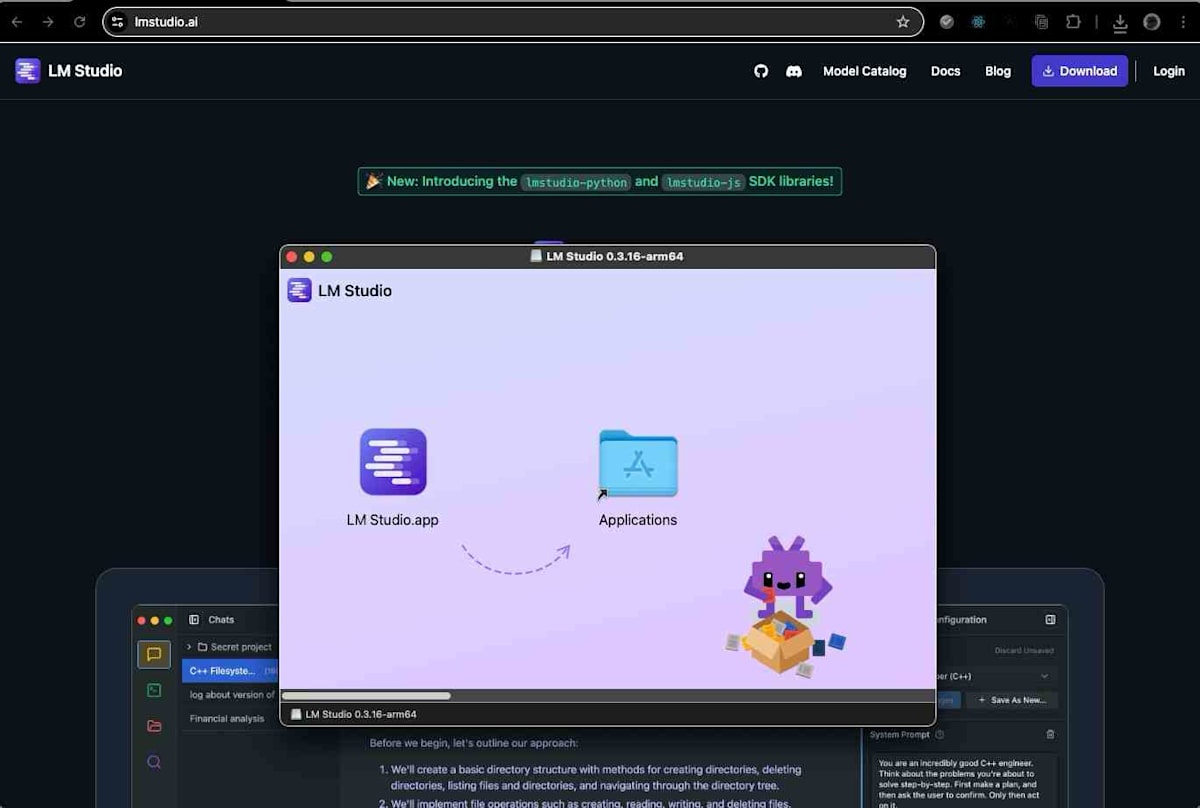
LM Studioを起動する
インストールが完了したら、LM Studioアプリケーションを起動します。
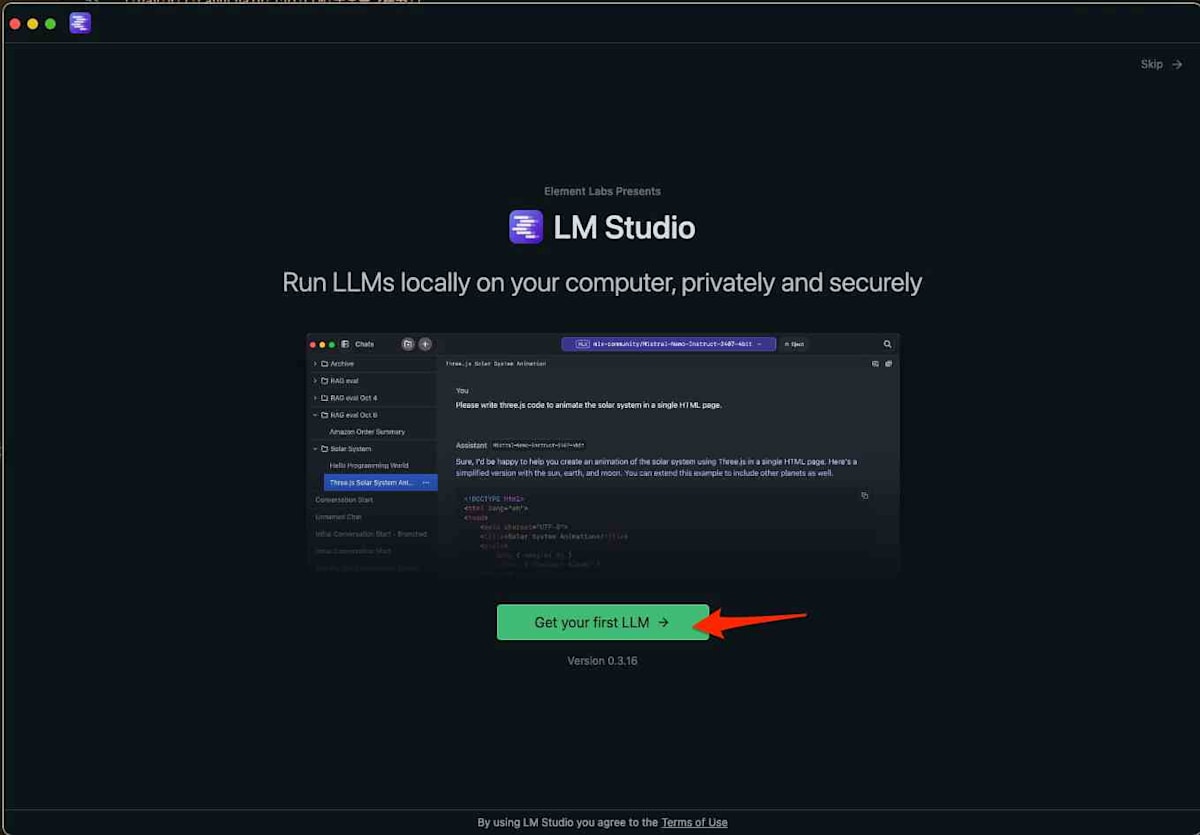
起動後、LLMモデルのダウンロード画面が表示されるのでダウンロードします。今回はgemma-3-12bモデルをダウンロードします。LM Studioは様々なモデルをサポートしていますが、この時点では特定のモデルが推奨される場合があるようです。他のモデルは後から追加でダウンロードすることも可能です。
なお、今回は「Enable local LLM service on login」のチェックは外しておきました。これは、LM Studioがログイン時に自動起動するのを防ぎ、必要な時に手動で起動できるようにするためです。これにより、システムリソースの無駄な消費を抑えることができます。
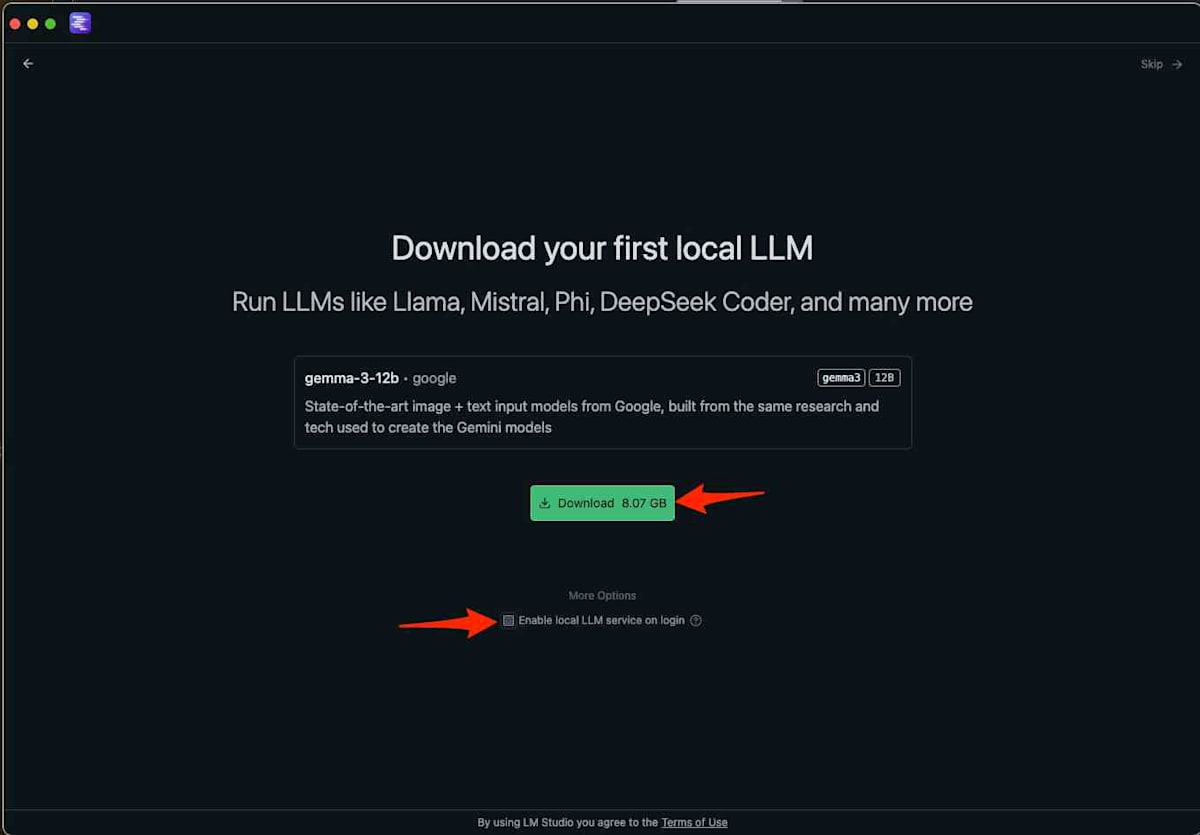
モデルのダウンロードが完了したら、「Start New Chat」をクリックしてチャットインターフェースに進みます。
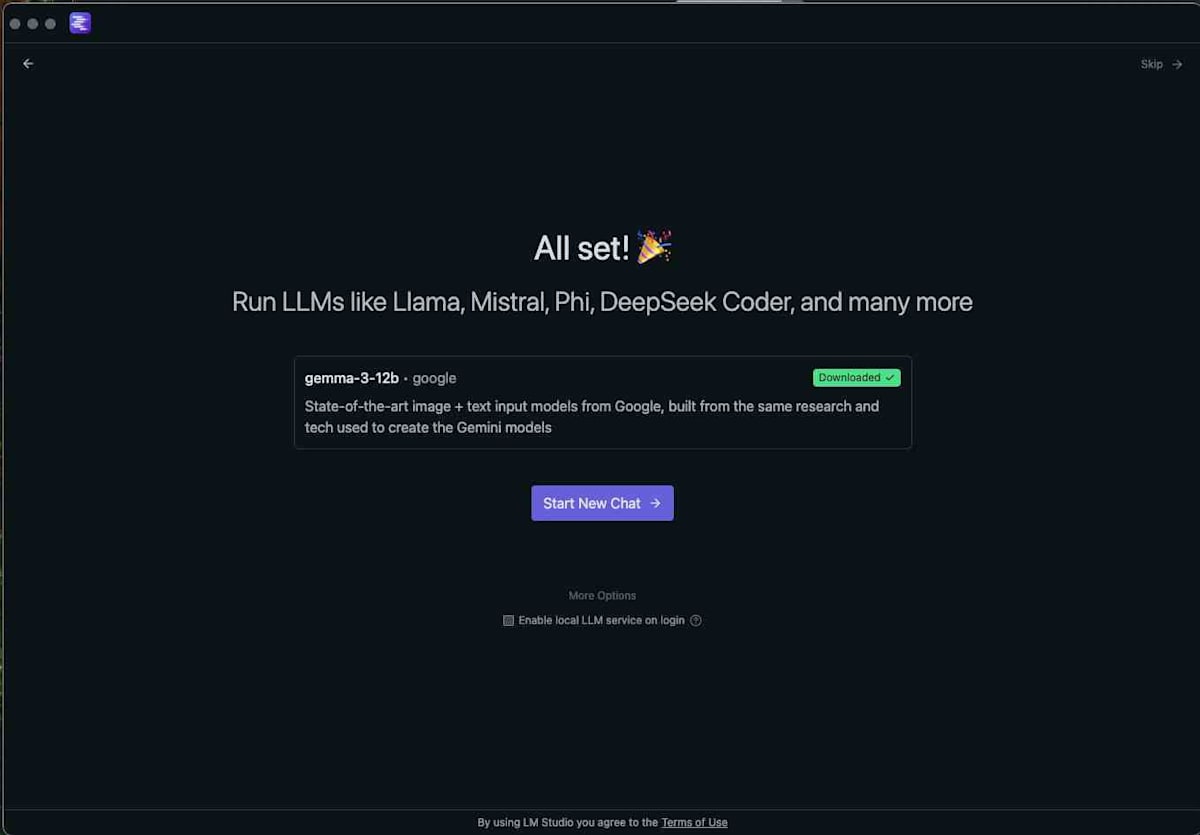
LM Studioでチャットを試す
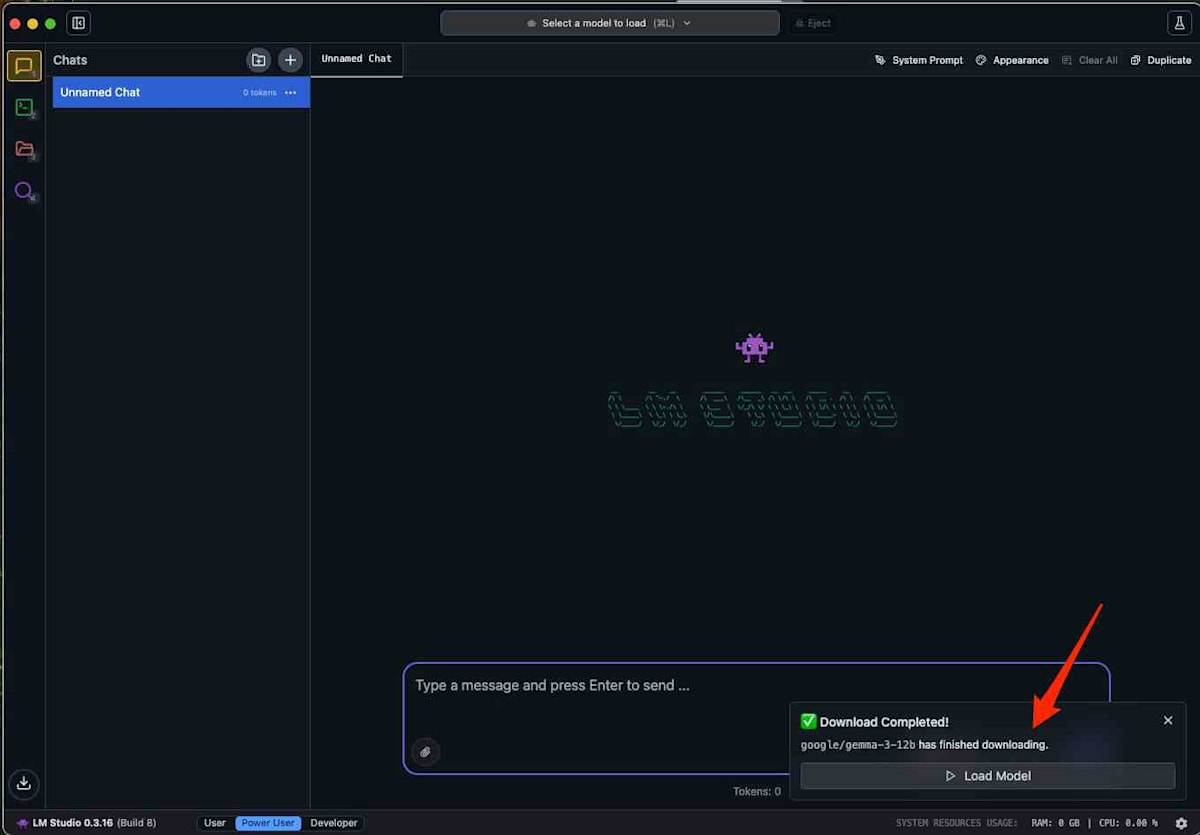
チャット画面で「Load Model」をクリックし、ダウンロードしたgemma-3-12bモデルを選択します。これにより、選択したモデルがチャットセッションにロードされ、応答の準備が整います。
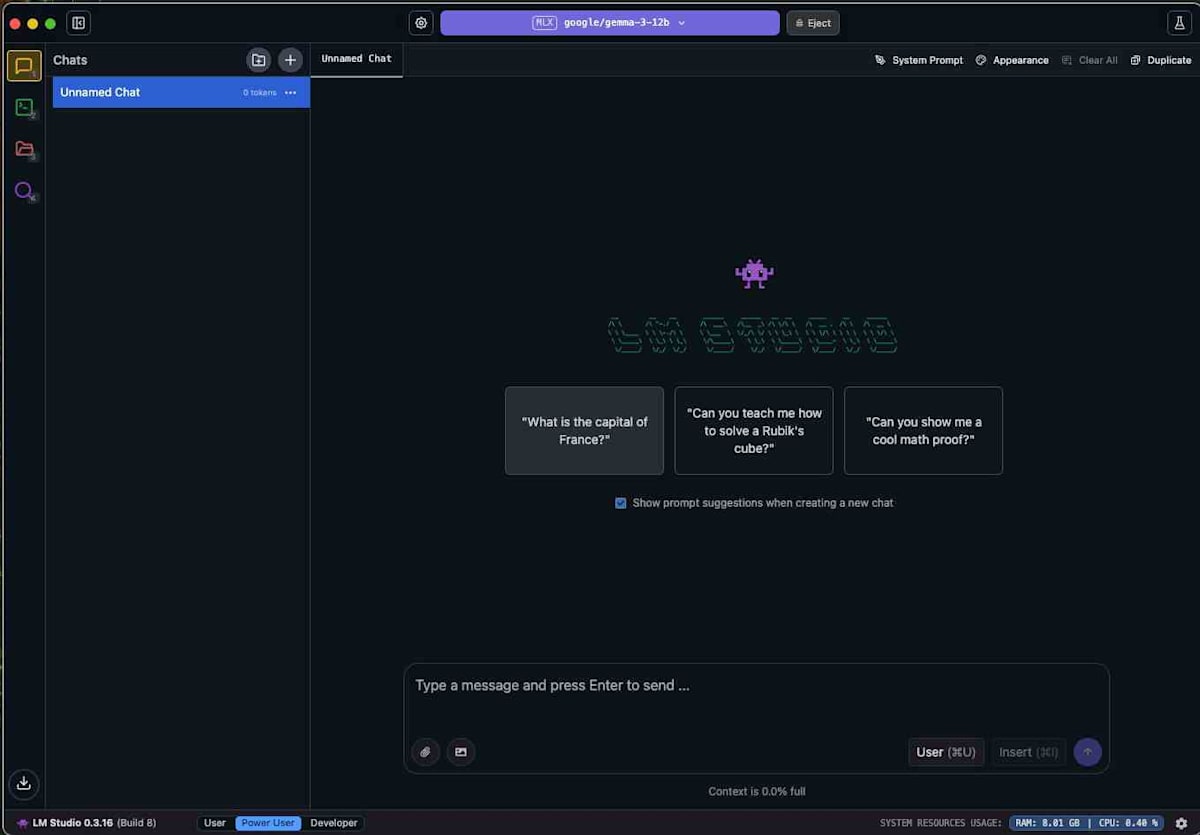
モデルがロードされたら、チャットボックスに質問を入力して応答を確認します。例として「フランスの首都は?」と入力してみましょう。
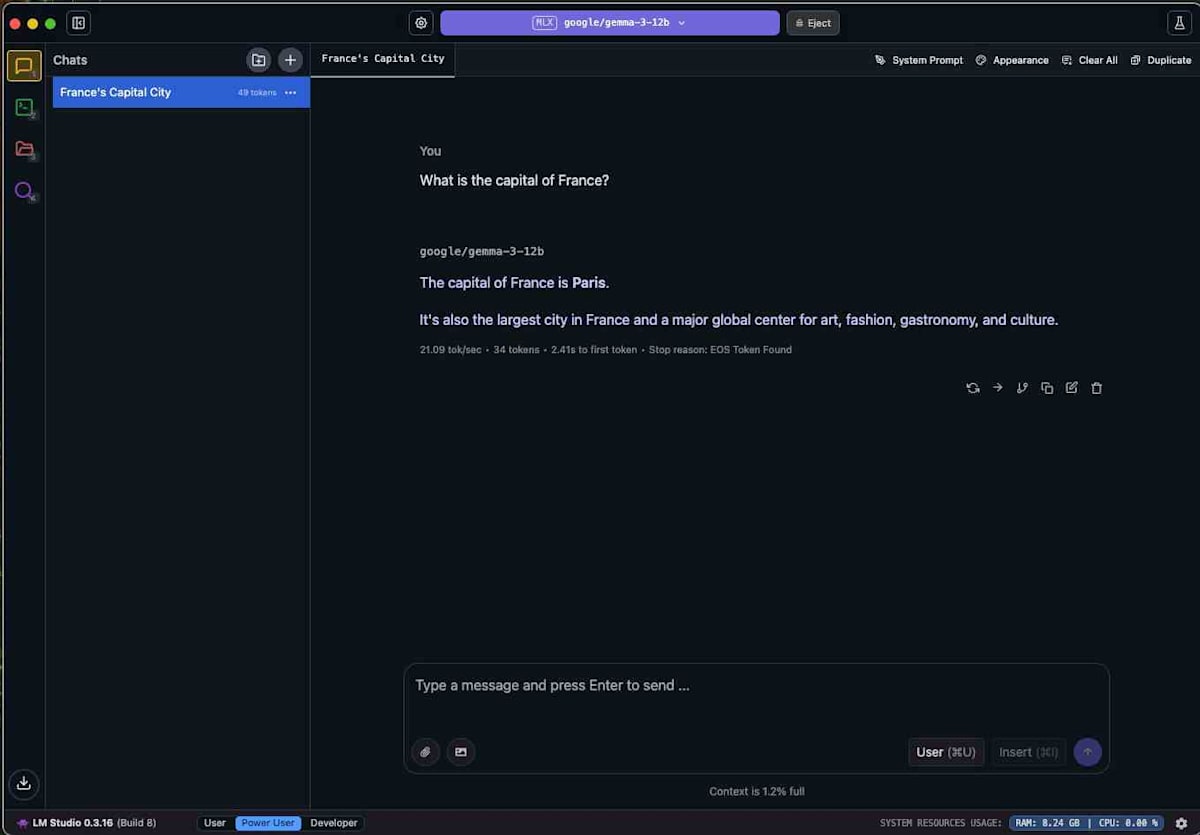
モデルからの回答が表示されれば、LM Studioの基本的なセットアップとチャット機能の動作確認は完了です。この手軽さがLM Studioの大きな利点です。
LangChainとStreamlitを使ってみる
LangChainは、LLMを活用したアプリケーション開発を効率化するPythonフレームワークです。複雑なプロンプト管理、外部データソースとの連携、エージェントの構築などを抽象化し、開発者がLLMの能力を最大限に引き出すことを支援します。本セクションでは、LangChainとStreamlitを組み合わせて、ローカルLLMと連携するシンプルなチャットアプリケーションを構築します。Streamlitは、PythonでインタラクティブなWebアプリケーションを迅速に構築するためのフレームワークであり、プロトタイピングに非常に適しています。
開発環境の構築
pipenvは、Pythonプロジェクトの依存関係と仮想環境を管理するためのツールです。これにより、プロジェクトごとに独立した環境を構築し、依存関係の衝突を防ぐことができます。今回は pipenv を使用してPython 3.12をベースとした仮想環境を構築し、必要なパッケージをインストールします。
pipenv --python 3.12
必要なパッケージのインストール
以下のコマンドで、Streamlit、OpenAI(LangChainのOpenAI互換APIを利用するため)、およびlangchain-openaiをインストールします。
pipenv install streamlit openai langchain-openai
チャットアプリケーションの作成
アプリケーションを実行する前に、LM StudioでLLMサーバーが起動していることを確認してください。LM Studioの画面で、サーバーが稼働中であることを示す表示を確認できます。LM Studioは、ローカルでLLMのAPIエンドポイントを提供するため、このサーバーが稼働していなければLangChainからのリクエストを受け付けることができません。
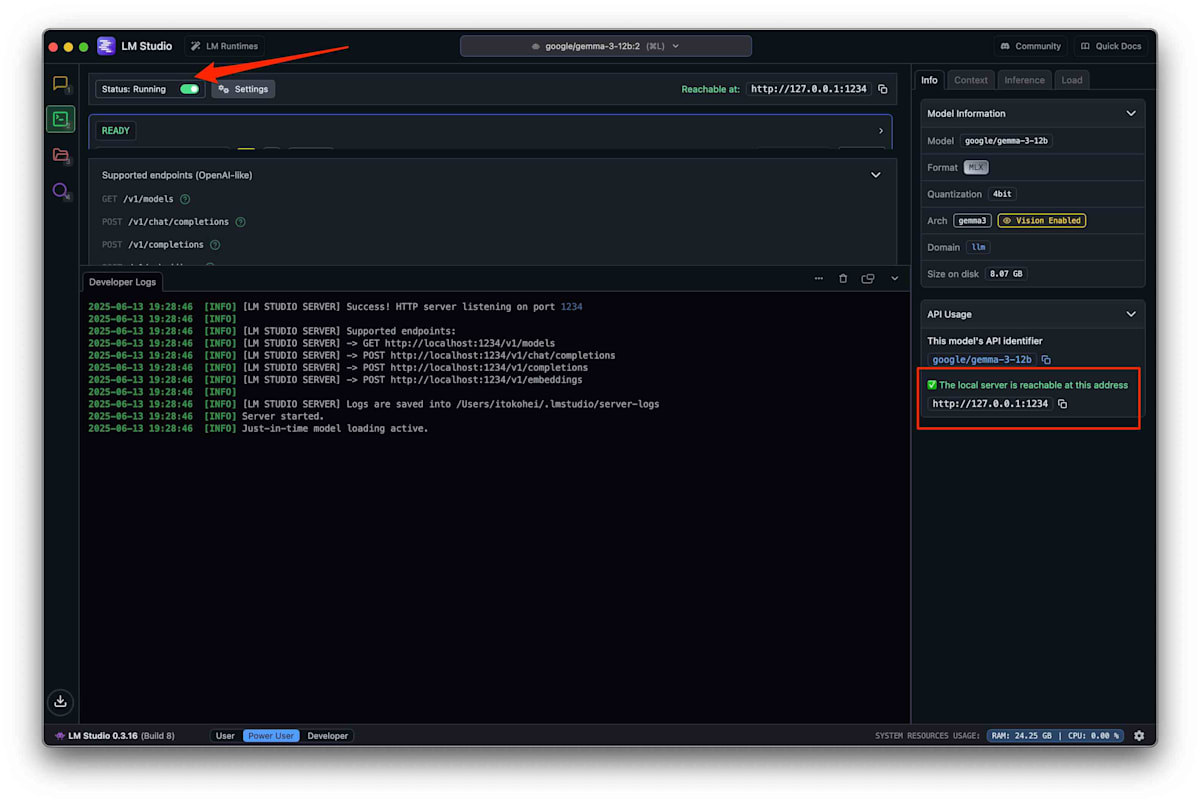
以下のPythonコードは、参照記事のコードをベースに、ローカルLLM(LM Studio)と連携するために以下の3点を変更しています。これらの変更は、LangChainの最新のAPI仕様とローカルLLMの利用に合わせたものです。
-
LLMエンドポイントのローカル設定: LM Studioが提供するローカルAPIエンドポイント(
http://localhost:1234/v1)を使用するようにbase_urlを設定します。これにより、LangChainが外部のOpenAI APIではなく、ローカルで稼働しているLM StudioのAPIにリクエストを送信するようになります。 -
OpenAI APIキーの無効化: ローカルLLMを使用するため、OpenAI APIキーは不要になります。
api_key="not-needed"と設定することで、形式的な要件を満たしつつ、実際のキー認証をスキップします。 -
OpenAIからChatOpenAIへの変更: LangChainの最新バージョンでは、チャット形式の対話モデルにはChatOpenAIクラスを使用することが推奨されています。これは、従来のOpenAIクラスが主にテキスト補完モデルを対象としていたのに対し、ChatOpenAIはメッセージの履歴を考慮した対話に特化しているためです。
import streamlit as st
from langchain_openai import ChatOpenAI
st.title("🦜🔗 Quickstart App")
# OpenAI APIキーの入力欄はローカルLLMでは不要なため、コメントアウトまたは削除を検討
# openai_api_key = st.sidebar.text_input("OpenAI API Key")
def generate_response(input_text):
# LM Studioのローカルエンドポイントを指定
llm = ChatOpenAI(
base_url="http://localhost:1234/v1",
api_key="not-needed", # ローカルLLMではAPIキーは不要
temperature=0.7,
model_name="google/gemma-3-12b", # 使用するモデル名を指定
)
# 元のOpenAIモデルの呼び出しはコメントアウト
# llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key)
st.info(llm.invoke(input_text).content)
with st.form("my_form"):
text = st.text_area(
"Enter text:",
"What are the three key pieces of advice for learning how to code?",
)
submitted = st.form_submit_button("Submit")
# APIキーのチェックも不要なためコメントアウト
# if not openai_api_key.startswith("sk-"):
# st.warning("Please enter your OpenAI API key!", icon="⚠")
if submitted: # and openai_api_key.startswith("sk-"): # 条件からAPIキーチェックを削除
generate_response(text)
アプリケーションの実行
以下のコマンドを実行してStreamlitアプリケーションを起動します。これにより、ローカルのWebサーバーが立ち上がり、ブラウザでアプリケーションにアクセスできるようになります。
$ pipenv run streamlit run ./streamlit_app.py
ブラウザでアプリケーションが起動し、ローカルLLMとのチャットが可能になります。
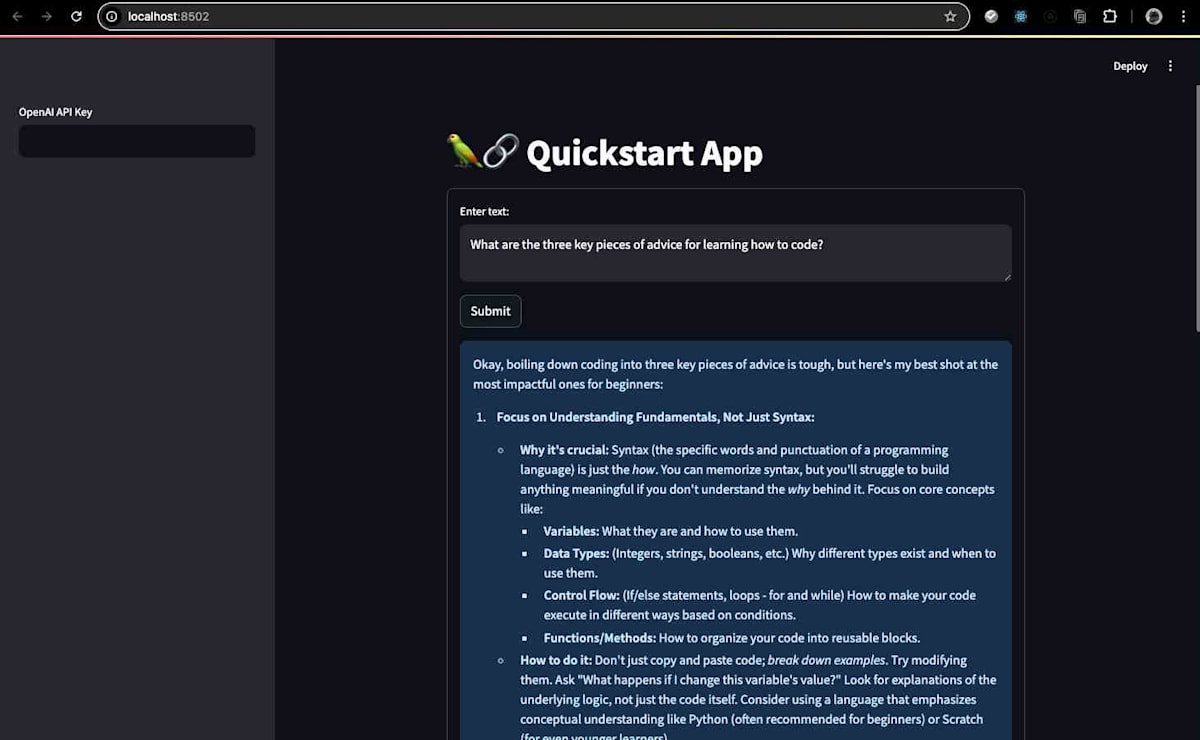
おわりに
本記事では、LM StudioとLangChain、Streamlitを組み合わせることで、ローカル環境でLLMを活用したチャットアプリケーションを構築する手順を解説しました。特に、参照記事の公開時と比べてPythonパッケージの実装に変更があった点に焦点を当て、その点を踏まえた調整と技術的な背景を詳細に説明しました。
ローカルLLMの活用は、クラウドベースのLLMサービスと比較して、プライバシー保護、コスト削減、オフラインでの利用可能性といった多くの利点があります。これにより、機密性の高いデータを扱うアプリケーションや、開発・テスト段階での迅速なイテレーションが可能になります。
今後は、異なるLLMモデルの性能評価(例: 推論速度、精度、リソース消費)や、より複雑なLangChainの機能(例: エージェント、チェーン、Retrieval-Augmented Generation (RAG))を組み込んだアプリケーション開発に取り組んでいきたいと考えています。ローカルLLMの技術は日々進化しており、その可能性は広がり続けています。本記事が、皆様のLLMアプリケーション開発の一助となれば幸いです。
Discussion