hasura v3のチュートリアルを読む
概要
hasuraをしばらく使っていたが、改めてチュートリアルを読んで見る。
使い始めた頃はこんなにチュートリアルあったかな?
DBとしてneonを使うので、別途準備をしておく。
わかったこと
-
hasura consoleのアクセス
https://console.hasura.io/projects
build後のリリース前の状態にはbuild時に発行されるConsole Urlからアクセスできる -
hasura のメタデータをローカルに持ってくる手順
- hasura3 login
- ローカルプロジェクトの準備。プロジェクトがない場合は以下を実施
- hasura3 init --dir <PROJECT_DIRECTORY>
<PROJECT_DIRECTORY>は任意のPC上のディレクトリ - hasura3 metadata add-hub-connector pg_db --dir . --subgraph default --id hasura/postgres --url <DATABASE_URL>
<DATABASE_URL>はDBのconnection string
- hasura3 init --dir <PROJECT_DIRECTORY>
- メタデータ取得
- テーブル型定義更新
- hasura3 watch --dir .
- テーブルリレーション定義更新
- VS Code拡張機能を使う
Ctrl + Shift + P(またはCmd + Shift + PmacOS の場合) を押してコマンド パレットを開き、入力を開始してHasura track all collectionsを入力しEnterを押す。次に、Enterもう一度押して、データソースpg_dbからのすべてのコレクションを追跡することを確認する
- VS Code拡張機能を使う
- テーブル型定義更新
-
hasuraにメタデータを適応する方法
- ビルド
- hasura3 build create -d "some comment for build"
- リリース
- hasura3 build apply --project <PROJECT_NAME> --version <BUILD_VERSION>
- ビルド
-
権限
- モデル権限で、モデル(テーブル)毎、ユーザロール毎(admin,user等)、アクション毎(select,update,delete,create)に実行権限が設定できる。
- タイプ権限で、モデル(テーブル)毎に許可されたフィールドを指定できる。
分からなかったところ
タイプ権限でoutput以外のどのような設定があるのか分からなかった
まだOutPutPermissonしか無いっぽい。アルファー状態だから?
読んだところ
1.FullstackGraphQLTutorialSeries|LearnGraphQL&Hasura
チュートリアルのトップページ
1.CourseIntroduction|Hasurav3Tutorial
hasurav3のチュートリアル。v2しか使ったことはない。
hasurav3のチュートリアルを日本語訳し理解する
hasurav3のチュートリアル
CourseIntroduction|Hasurav3Tutorial
コース紹介
APIを構築したことがある人なら、APIの作成に費やされる時間のほとんどが、セキュリティとコンプライアンスの要件を満たすためのアクセスコントロールルールの作成に集中していることを知っています。Hasurav3は、本番環境に対応した、準拠したGraphQLAPIを数週間ではなく数分で構築できる強力なツールです。
Hasuraは、開発者がAPIをより迅速に構築できるようにするために作成されました。これは、本番環境に対応したGraphQLAPIを構築できる強力なツールです。Hasurav3はHasuraの最新バージョンであり、Hasuraアーキテクチャを完全に書き直したものです。これまで以上に高速、強力、そして柔軟になりました。
何を学べますか?
このチュートリアルは、Hasurav3とその機能の完全な概要を提供するように設計されています。このチュートリアルが終わるまでに、Hasurav3プロジェクトが、グローバルでほぼ即時のデータ配信ネットワークであるHasuraDDNにデプロイされることになります。
次の方法を学びます。
1.新しいHasuraプロジェクトを作成します。
1.API全体を定義する単一の宣言型メタデータファイルを作成します。
1.Hasuraのデータコネクタを使用してデータソースに接続します。
1.APIに対してきめ細かいアクセス制御ルールを構成します。
1.APIの開発ビルドをHasuraDDNにデプロイします。
1.Hasuraコンソールを使用してAPIをテストします。
1.APIの実稼働ビルドをHasuraDDNにデプロイします。
何を構築するのでしょうか?
ユーザーが注文と通知を管理できるようにするeコマースAPIを構築します。APIはPostgreSQLデータベースによってサポートされ、HasuraDDNにデプロイされます。
このチュートリアルを受講するには何が必要ですか?
次のセクションで詳しく説明しますが、次のものが必要です。
*新しいHasuraCLI
*HasuraVSCode拡張機能(オプションですが推奨)
*PostgreSQLデータベース(ホスト型またはローカル)
このチュートリアルにはどれくらい時間がかかりますか?
30分未満。
前提条件
このページを整理したら、レースに出発します。この一連の1回限りのセットアップ手順により、Hasuraプロジェクトの構築を開始する準備が整います。
HasuraCLIをインストールする
HasuraCLIをゼロから再設計し、使いやすく、より強力になりました。ご使用のプラットフォームのドキュメントに記載されているインストール手順に従ってください。これは新しいCLIであり、前のバージョンと同じではないことに注意してください。
M1macでのインストール例
cd/usr/local/bin
curl-Lhttps://graphql-engine-cdn.hasura.io/ddn/cli/latest/cli-hasura3-darwin-arm64-ohasura3
chmod+xhasura3
VSCode拡張機能をインストールする
VSCodeを使用し、HasuraVSCode拡張機能をインストールすることをお勧めします。OpenDataDomain仕様(OpenDD仕様)形式を使用してメタデータを即座にスキャフォールディングすることができます🚀
拡張機能はVSCodeMarketplaceからダウンロードできます。
##CLIを認証する
CLIをネットワークに対して認証するには、次のコマンドを実行します。
hasura3login
これにより、Hasuraアカウントでログインできるブラウザウィンドウが開きます。ログインしたら、ブラウザウィンドウを閉じて端末に戻ることができます。
サンプルデータをダウンロードする
最後に、このチュートリアルで使用するサンプルデータが必要になります。このチュートリアルではPostgreSQLデータベースを使用しており、初期up.sqlファイルを使用してテーブルを作成できます。
curlhttps://raw.githubusercontent.com/hasura/docs-sample-app/main/migrations/default/1669033533483_init/up.sql-oup.sql
次に、そのtables_seed.sqlファイルを使用してテーブルにサンプルデータを追加できます。
curlhttps://raw.githubusercontent.com/hasura/docs-sample-app/main/seeds/default/tables_seed.sql-otables_seed.sql
Hasuraでは、ホストされたデータベースまたはローカルデータベースのいずれかを使用できます。
ホスト型データベースを使用している場合は、プロバイダーの指示に従って、上記のファイルを使用してテーブルとシードデータを作成します。ローカルPostgreSQLデータベース(Dockerなど)を実行している場合は、テーブルとシードを作成してからデータベースを起動します。
psqlで設定する場合の例
$psql"コネクションストリング"-a-fup.sql
$psql"コネクションストリング"-a-ftables_seed.sql
メタデータ
Hasuraを使用すると、メタデータファイルの宣言セットを使用してデータモデル全体を定義できます。このメタデータはHML(YAMLのHasura固有のフレーバー)で記述され、テーブル、リレーションシップ、権限などの作成に使用されます。このメタデータはバージョン管理および繰り返し変更できるため、チームや他のチームと簡単に共同作業して、データ層への変更を追跡できます。
オープンデータドメイン(OpenDD)仕様
私たちはOpenDataDomain仕様(OpenDD仕様)を、データ層全体を定義するためのシンプルで信頼できるソースに依存しない方法として設計しました。OpenDD仕様では、データベース、RESTAPI、GraphQLAPIなどを含むすべてのデータソースのスーパーグラフを作成できます。この仕様に従って記述されたメタデータファイル内で、データソース間の関係を迅速かつ簡単に定義したり、権限を作成したりすることもできます。
私たちのデータモデル
このチュートリアルでは、電子商取引アプリケーションのデータ層を構築します。前提条件up.sqlページにある次のデータモデルを使用します。
| テーブル名 | 説明 |
|---|---|
| ユーザー | ユーザーの名前や電子メールアドレスなどのユーザーに関する情報を保存します。 |
| カテゴリ | 製品のカテゴリに関する情報(名前など)を保存します。 |
| メーカー | 製品のメーカー名などの情報を保存します。 |
| 製品 | 名前や価格などの製品に関する情報を保存します。 |
| レビュー | レビューを書いたユーザーやレビューされた製品など、製品のレビューに関する情報を保存します。 |
| 注文 | 注文を行ったユーザーや注文された製品など、注文に関する情報を保存します。 |
| カート | カートを所有するユーザーを含む、カートに関する情報を保管します。 |
| カートアイテム | カートを所有するユーザーやカートに追加された製品など、ユーザーのカート内のアイテムに関する情報を保存します。 |
| 通知 | 通知を所有するユーザーを含む、通知に関する情報を保存します。 |
| クーポン | クーポンコードや割引金額など、クーポンに関する情報を掲載しています。 |
新しいプロジェクトを作成する
すべてのプロジェクトは Hasura Data Delivery Network (DDN) でホストされます。 Hasura CLI を使用してプロジェクトを作成し、Hasura コンソールを使用して管理できます。プロジェクトはコンソールからも作成できますが、メタデータのバージョン管理を簡単に行えるように、CLI を使用してプロジェクトを作成することをお勧めします。
CLIを認証する
これまでに認証を行っていない場合は、次のコマンドを実行して CLI を認証します。
hasura3 login
新しいプロジェクトを作成する
次のコマンドを使用して、Hasura DDN 上にローカル プロジェクトとコンパニオン プロジェクトを作成できます。
hasura3 init --dir <PROJECT_DIRECTORY>
CLI では次のプロンプトが表示されます。
Use the arrow keys to navigate: ↓ ↑ → ←
Please choose how you would like to initialise Hasura DDN?
Create a new project | (Start building on a new DDN project)
From an existing project
Empty project
Create a new project を選択すると、CLI は次のように応答します。
Creating a new project
Creating hasura.yaml ...
Creating build-profile ...
Creating metadata.hml ...
Project <PROJECT_NAME> is created at <DIR>
プロジェクト< PROJECT_NAME >が< DIR >に作成されます
これにより、次のディレクトリ構造が生成されます。
├── build-profile.yaml
├── hasura.yaml
├── subgraphs
│ └── default
│ ├── commands
│ ├── dataconnectors
│ └── models
└── supergraph
├── auth-config.hml
└── compatibility-config.hml
ディレクトリ構造の詳細については、ドキュメントを参照してください。ただし、概要を説明すると、hasura.yamlファイルにはプロジェクトのメタデータが含まれ、build-profile.yamlファイルにはプロジェクトのビルド構成が含まれ、 ディレクトリsupergraphとsubgraphsディレクトリにはプロジェクト全体とサブグラフ固有のメタデータがそれぞれ含まれます。
次のステップでは、default/subgraphs/dataconnectors のディレクトリにデータソースを追加します。
次に、各テーブルをdefault/subgraphs/models のディレクトリに追加します。
データソースを追加する
Hasura はさまざまなデータ ソースに接続できます。お客様のデータは、さまざまな所有者とさまざまな形式で複数のソースに分散している可能性が高いことを理解しています。私たちは、単一の GraphQL API からすべてのデータに簡単にアクセスできるようにしたいと考えています。この概念をデータ スーパーグラフと呼びます。
データコネクタ
データ ソースに接続するために、Hasura はデータ コネクタを利用します。データコネクタは、Hasura がデータソースと通信するために使用する一連の API を公開する HTTP サービスです。データ コネクタは、データ ソースのネイティブ クエリ言語を使用して、Hasura エンジンに代わって実行される作業を解釈する責任があります。
データ コネクタは、PostgreSQL、ClickHouse、Qdrant など、さまざまなデータ ソースで使用できます。詳細については、コネクタ ハブをご覧ください。
このガイドでは、データ コネクタを使用してhasura/postgresPostgreSQL データベースに接続します。
データソースに接続する
Hasura CLI を使用すると、データ ソースへの接続が簡単になります。このコマンドを使用して、metadata add-hub-connectorコネクタ ハブからデータ ソースに接続できます。
以下のコマンドを実行すると、CLI は.envデータ ソースの接続文字列を含むファイルをプロジェクトのルート ディレクトリに生成します。次に、defaultサブグラフのディレクトリに新しいサブディレクトリが作成され、コマンドdataconnectors の直後に渡した値にちなんで名付けられたファイルに接続情報が含まれますadd-hub-connector(pg_db以下の例)。
neonの場合ダッシュボードから確認できる「Connection string」を<DATABASE_URL>に記載する。
hasura3 metadata add-hub-connector pg_db --dir . --subgraph default --id hasura/postgres --url <DATABASE_URL>
このコマンドにはいくつかのフラグを渡します。
- --dir .現在のディレクトリをプロジェクト ディレクトリとして使用するように CLI に指示します。
- --subgraph defaultデータ ソースをデフォルトのサブグラフに追加するように CLI に指示します 。
-
--id hasura/postgres hasura/postgresコネクタ ハブからのコネクタを使用するように CLI に指示します。
ホストされたデータソース
データベースがクラウド プロバイダーでホストされている場合は、次のような接続文字列をコピーすることでデータベースに接続できます。
postgresql://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<DATABASE_NAME>
ローカルデータソース(neonを使う場合は不要)
開発のためにローカル データベースに接続する場合は、新しい Hasura CLI を使用してローカル デーモンを作成し、データベースに安全に接続できます。これをSecure Connectトンネルと呼びます。トンネルを使用すると、ローカル データベースをインターネットに公開することなく、Hasura DDN 上の Hasura プロジェクトに接続できるため、有益です。
データベースを起動します
ローカルデータベースを起動します。たとえば、Docker を使用している場合は、次のコマンドを実行できます。
docker run -d --name <DATABASE_NAME> -e POSTGRES_PASSWORD=<YOUR_PASSWORD> -p 5432:5432 <DATABASE_IMAGE>
デーモンを起動する
次のコマンドで Hasura デーモンを起動しますdaemon start。
hasura3 daemon start
デーモンは実行中にこのウィンドウをブロックします。
セキュア接続トンネルを作成する
ターミナルの新しいタブまたはウィンドウを開き、次のcreateコマンドを実行します。
hasura3 tunnel create <SOCKET>
引数<SOCKET>はローカル データベースのアドレスです。たとえば、デフォルト ポートでローカル PostgreSQL データベースを実行している場合は、 を使用しますlocalhost:5432。
CLI は、データベースへの接続に使用できる URL を返します。この URL を使用して、次のようにデータベースの接続文字列を形成する必要があります。
postgresql://<USERNAME>:<PASSWORD>@<URL_RETURNED_BY_THE_CLI>/<DATABASE_NAME>
秘密(実施する必要はなし)
必要に応じて、シークレットを利用して接続文字列を保存できます。シークレットは、機密情報を安全に保存できるようにする Hasura の新しい概念です。CLI をキーと値のペアとして使用して、これらをすばやく作成できます 。
hasura3 secret set --project-id <PROJECT_ID_FROM_PREVIOUS_STEP> <KEY>=<VALUE>
次に、connection_uris配列内のキーを参照します。
connectionUri:
uri:
stringValueFromSecret: <KEY>
データソースをイントロスペクトする
データ ソースが接続されていると、CLI はデータ ソースを簡単にイントロスペクトし、メタデータを生成できます。これにより、型と関係を作成する定型的なタスクが不要になり、重要な作業に集中できるようになります。いくつかのコマンドを実行するだけで、データ層全体が定義され、API を使用できるようになります 🚀
このhasura3 watchコマンドは、プロジェクト ディレクトリの変更を監視し、変更を Hasura プロジェクトに自動的に適用します。これは、プロジェクトに変更を加え、手動で変更を適用することなく Hasura プロジェクトに反映されることを確認できるため、開発に役立ちます。
hasura3 watch --dir .
プロジェクト ディレクトリの変更を監視するデーモンが起動します。Ctrl + Cを押すとデーモンを停止できます。 重要な点に注意してください。トンネルを使用している場合は、hasura3 watchを開始する前にそのプロセスを強制終了する必要があります。これにより、watchトンネルの作成が自動的に行われます。
VS Code でのデータ ソースの更新
dataconnectors/pg_dbディレクトリ内のファイルpg_db.hmlに移動すると、CLI によってデータベース内のテーブルとビューに関する情報がメタデータに追加されたことがわかります 🎉
次に、default/subgraph/models のディレクトリに各テーブルのhmlファイルを作成します。
スキャフォールドのメタデータ
ここから、テーブル、ビュー、関係をすぐに追跡し、Hasura VS Code 拡張機能を使用してメタデータを迅速に構築できます。
モデルは、Hasura でデータを表現する新しい方法です。
OpenDD 仕様のモデルは、特定の OpenDD 仕様タイプのオブジェクト (リレーショナル データベースの行、NoSQL データベースのドキュメントなど) のコレクションを指します 。モデルはデータ ソースによってサポートされており、CRUD 操作をサポートできます。モデルについて詳しくは、こちらをご覧ください。
スキャフォールドのメタデータ
hasura3 watchバックグラウンドで実行し、ファイルを開いた状態でpg_db.hml、VS Code 拡張機能を使用してメタデータをスキャフォールディングできます。
Ctrl + Shift + P(またはCmd + Shift + PmacOS の場合) を押してコマンド パレットを開き、入力を開始してHasura track all collectionsを入力しEnterを押します。次に、Enterもう一度押して、データソースpg_dbからのすべてのコレクションを追跡することを確認します。
ビオラ!これでメタデータの足場が完成しました。 CLIがテーブルとビューごとに名前付きhmlファイルを生成し、それらをdefault/subgraph/modelsのディレクトリに追加したことがわかります。さらに、タイプがpg_dbディレクトリ内に作成されています。
Builds
ビルドはHasura の新しい概念であり、プロジェクトのメタデータを迅速に反復してプロトタイプ作成できるようになります。ビルドは、開発サイクルのマイルストーンを表す、不変で完全に機能する GraphQL API です。
ビルドを git コミットと考えるとわかりやすいかもしれません。それぞれHasura DDN上にデプロイされているため、他のユーザーと共有することができます。各ビルドは完全に独立しています。 1 つのプロジェクトに複数のビルドを含めることができ、そのうちの 1 つが運用環境に適用されます。
一般的なワークフローでは、ビルドを作成し、テストしてから実稼働環境に適用します。変更を加える必要がある場合は、新しいビルドを作成し、それを運用環境に適用することができます。このワークフローにより、本番環境でのロールバックが容易になり、開発中のコラボレーションが強化されます。
さらに、開発を容易にするために、このhasura3 watchコマンドはプロジェクト ディレクトリの変更を監視し、変更を検出すると新しいビルドを自動的に作成します。これにより、プロジェクトのメタデータをすばやく反復し、フィードバック ループを短縮できます。
ビルドを作成する
メタデータの状態に満足し、それをテストしたい場合は、ビルドを作成できます。
ウォッチモードを使用する
hasura3 watchを使用している場合、すべてのモデルをインポートしたときにビルドが生成されます。ビルドの出力は、hasura3 watchを実行したターミナルウィンドウで確認できます。以下のビルドのテストセクションに進んでください 。
注: 監視モードを使用していて、ビルドでエラーが発生した場合は、プロセスを強制終了して再起動してみてください。
ビルドを作成する
あるいは、ビルドの作成に関連する手動手順を確認したい場合は、メタデータ ファイルが含まれるディレクトリから次のコマンドを実行します。
hasura3 build create -d "Connect Datasource and track entities"
hasura.yamlここでは、で定義されたプロジェクトのビルドを作成し、「データソースに接続してエンティティを追跡する」という説明を使用するようにCLI に指示しています。この説明はコンソールに表示され、あなたとあなたのチームにとってこのビルドの目的がより明確になります。
CLI は次を返します。
+---------------+------------------------------------------------------------+
| Build ID | <BUILD_ID> |
+---------------+------------------------------------------------------------+
| Build Version | <BUILD_VERSION> |
+---------------+------------------------------------------------------------+
| Build URL | https://<PROJECT_NAME_AND_BUILD_ID>.ddn.hasura.app/graphql |
+---------------+------------------------------------------------------------+
| Project Id | <PROJECT_ID> |
+---------------+------------------------------------------------------------+
| Console Url | https://console.hasura.io/project/<PROJECT_NAME>/graphql |
+---------------+------------------------------------------------------------+
| FQDN | <PROJECT_NAME_AND_BUILD_ID_STUB>.ddn.hasura.app |
+---------------+------------------------------------------------------------+
| Environment | default |
+---------------+------------------------------------------------------------+
| Description | Connect Datasource and track entities |
+---------------+------------------------------------------------------------+
ビルドをテストする
CLI によって返されたコンソールURLに移動します。ログインするように求められます。ログインすると、GraphiQL Explorer が表示され、API に対してクエリを実行できます。以下を実行してみてください。
query OrdersQuery {
orders {
id
status
delivery_date
user {
id
name
email
}
product {
id
name
}
}
}
次のような応答が表示されるはずです。
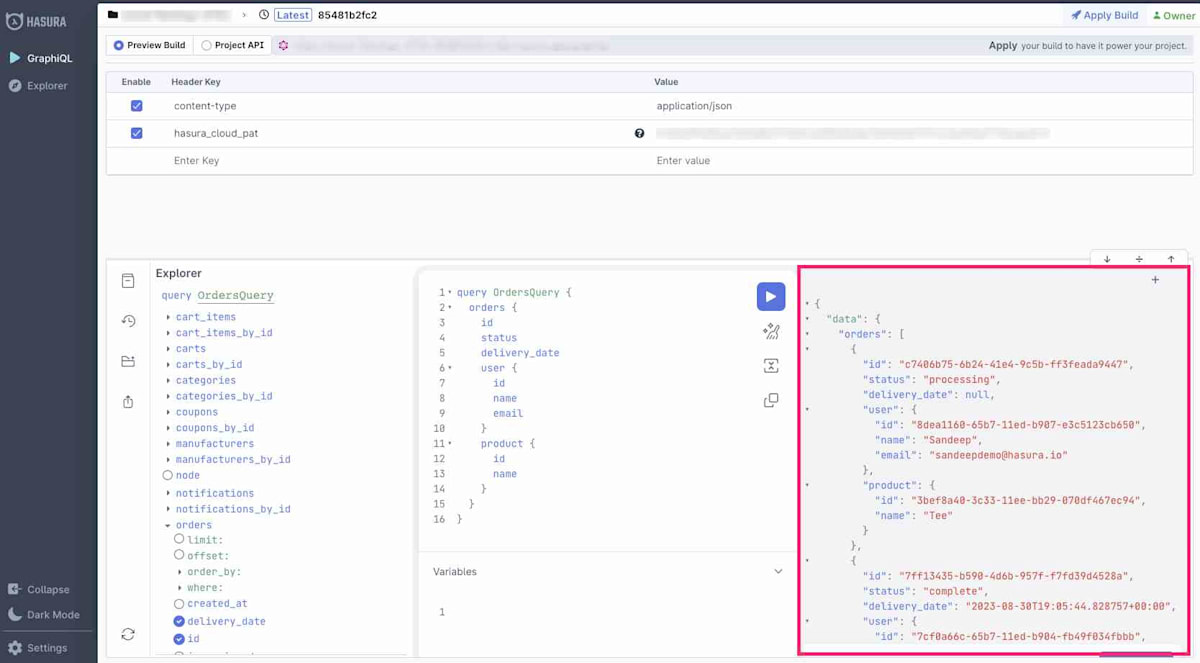
Hasura DDN コンソールの機能するクエリ
クエリで問題が発生した場合は、すべての関係が正しく定義されていることを確認してください。 GraphiQL エクスプローラーのフィールドの下にある赤い線は、メタデータに問題があることを示しています。
ここから、メタデータの反復処理を続けることも、このビルドをプロジェクトの実稼働エンドポイントに適用することもできます。
ビルドを適用する
ビルドを適用するということは、ビルドがプロジェクトの実稼働エンドポイントに昇格されることを意味します。これは Hasura の新しい概念であり、世界中のすべてのユーザーに対してプロジェクトのメタデータを迅速に反復し、必要に応じてロールバックできるようになります。
ウォッチモードを使用する
を使用している場合hasura3 watch、最新のビルドは常にプロジェクトのエンドポイントに自動的に適用されます。
ビルドを適用する
次のコマンドを実行してビルドを適用できます。
hasura3 build apply --project <PROJECT_NAME> --version <BUILD_VERSION>
例
$ hasura3 build apply --project handy-antelope-9906 --version 2178128312
+---------+----------------------------------------------------+
| API URL | https://handy-antelope-9906.ddn.hasura.app/graphql |
+---------+----------------------------------------------------+
このコマンドを実行すると、選択したビルドが運用環境に昇格され、プロジェクトのエンドポイント経由でアクセスできるようになり、ユーザーはほぼ瞬時に利用できるようになります 🚀
これをテストしたい場合は、プロジェクトのコンソールに移動し、ページを更新して、エンドポイントを適用したばかりのビルドに切り替えます。
認可
アプリケーションの構築で最も時間がかかる部分の 1 つは、承認の実装です。 Hasura では、メタデータ内でアクセス制御ルールを宣言的に記述できるため、これが簡単になります。これにより、データベース内のどのデータに誰がアクセスできるかを行および列レベルに至るまで定義できます。
承認は、次の 2 つの主要な権限セットに分類されます。
モデルの権限
モデル権限を使用すると、どのロールがデータ ソース内のどのコレクションにアクセスできるかを制御できます。これらを使用すると、匿名ユーザーが機密データにアクセスできないようにしたり、管理者のみが特定のコレクション (テーブル、ドキュメントなど) にアクセスできるようにしたりできます。
タイプ権限
タイプ権限を使用すると、モデルのどのフィールドをどのロールに返すかを制御できます。これらを使用すると、ユーザーが編集可能なフィールドのみにアクセスできるようにしたり、管理者だけが特定の種類の機密フィールドにアクセスできるようにしたりできます。
モデルの作成権限
まずはusersモデルのModelPermissions作成から始めます。userロールを作成し、ユーザーが自分の情報のみを表示できるようにするフィルターを追加します。
ユーザーロールを作成する
まず、/subgraphs/default/models/users.hml の次のセクションを見つけます。
kind: ModelPermissions
version: v1
definition:
modelName: users
permissions:
- role: admin
select:
filter: null
各モデルはModelPermissionsを持ち、どのロールがモデルにアクセスできるか、およびどのフィルターがモデルに適用されるかを定義するセクションがあります。
nullと評価されるadminロールの権限がすでに存在することがわかります。これは、admin ロールがusersモデルへの完全なアクセス権を持っていることを意味します。userという新しいロールを作成し、フィールドの値をチェックして、リクエストでヘッダーに含めて渡すidx-hasura-user-idというセッション変数と比較するuserフィルターを追加します。
usersモデルの完全なModelPermissionsセクションは次のようになります。
kind: ModelPermissions
version: v1
definition:
modelName: users
permissions:
- role: admin
select:
filter: null
- role: user
select:
filter:
fieldComparison:
field: id
operator: _eq
value:
sessionVariable: x-hasura-user-id
独自のモデルを操作する場合、Hasura VS Code 拡張機能を利用して、オートコンプリートを使用してこれらのアクセス許可を生成できます。
次に、ロールに基づいて特定のフィールドへのアクセスを制限する方法を確認します。
タイプ権限の作成
TypePermissionsを設定することで、ロールがアクセスできるフィールドの権限を設定することもできます。
ユーザーロールのフィールドを設定する
まず、/subgraphs/default/models/users.hml の次のセクションを見つけます。
kind: TypePermissions
version: v1
definition:
typeName: users
permissions:
- role: admin
output:
allowedFields:
- created_at
- email
- id
- is_email_verified
- last_seen
- name
- password
- updated_at
ご覧のとおり、このadminロールはすべてのフィールドにアクセスできます。userという新しいロールを作成し、id、name、emailフィールドへのアクセスのみを許可してみます。
TypePermissionsタイプの完全なセクションはusers次のようになります。
kind: TypePermissions
version: v1
definition:
typeName: users
permissions:
- role: admin
output:
allowedFields:
- created_at
- email
- id
- is_email_verified
- last_seen
- name
- password
- updated_at
- role: user
output:
allowedFields:
- email
- id
- name
新しいビルドでユーザー ロールをテストする
メタデータに変更を加えたので、監視モードを使用しない場合は新しいビルドを作成する必要があります。前と同様に、次のコマンドを実行して新しいビルドを作成します。
hasura3 build create -d "Set type permissions for users"
コンソールに移動し、最新のビルドを選択します。事前構成されたヘッダーを使用して、次のクエリを実行します。
query GetUsers {
users {
id
name
email
is_email_verified
created_at
updated_at
}
}
次のような応答が表示されるはずです。
{
"data": {
"users": [
{
"id": "7cf0a66c-65b7-11ed-b904-fb49f034fbbb",
"name": "Sean",
"email": "seandemo@hasura.io",
"is_email_verified": false,
"created_at": "2023-08-09T19:05:44.828757+00:00",
"updated_at": "2023-08-09T19:05:44.828757+00:00"
},
{
"id": "82001336-65b7-11ed-b905-7fa26a16d198",
"name": "Rob",
"email": "robdemo@hasura.io",
"is_email_verified": false,
"created_at": "2023-08-09T19:05:44.828757+00:00",
"updated_at": "2023-08-09T19:05:44.828757+00:00"
},
{
"id": "86d5fba0-65b7-11ed-b906-afb985970e2e",
"name": "Marion",
"email": "mariondemo@hasura.io",
"is_email_verified": false,
"created_at": "2023-08-09T19:05:44.828757+00:00",
"updated_at": "2023-08-09T19:05:44.828757+00:00"
},
{
"id": "8dea1160-65b7-11ed-b907-e3c5123cb650",
"name": "Sandeep",
"email": "sandeepdemo@hasura.io",
"is_email_verified": false,
"created_at": "2023-08-09T19:05:44.828757+00:00",
"updated_at": "2023-08-09T19:05:44.828757+00:00"
},
{
"id": "9bd9d300-65b7-11ed-b908-571fef22d2ba",
"name": "Abby",
"email": "abbydemo@hasura.io",
"is_email_verified": false,
"created_at": "2023-08-09T19:05:44.828757+00:00",
"updated_at": "2023-08-09T19:05:44.828757+00:00"
}
]
}
}
次に、コンソールの上部で、リクエストに 2 つのヘッダーを追加しましょう。
| ヘッダ | 説明 | 価値 |
|---|---|---|
| x-hasura-role | このリクエストに使用するロール | user |
| x-hasura-user-id | このロールに使用するユーザーID | 7cf0a66c-65b7-11ed-b904-fb49f034fbbb |
Hasura はこれらのヘッダーを確認すると、userロールを評価し、定義したフィルターを適用します。ヘッダーを追加し、ページを更新して、次のクエリを実行します。
query GetUsers {
users {
id
name
email
}
}
次のような応答が表示されるはずです。
{
"data": {
"users": [
{
"id": "7cf0a66c-65b7-11ed-b904-fb49f034fbbb",
"name": "Sean",
"email": "seandemo@hasura.io"
}
]
}
}
is_email_verified、created_atおよびupdated_atフィールドを再度追加しようとすると、これらのフィールドはuserロールでは使用できないことがわかります。これは、Hasura が指定されたロールでどのフィールドが使用できるかを反映する別のスキーマを自動的に生成するためです。
このようにして、モデルにアクセスできるユーザーusersとアクセスできるデータを定義しました 🎉
ネストされた権限の作成
GraphQL の最大の利点の 1 つは、複数の型にわたるネストされたクエリをすべて 1 つのクエリから実行できることです。このために、権限を実装することもできます。
次のクエリを実行するとします。
query GetUsers {
users {
id
name
email
orders {
id
created_at
status
delivery_date
}
notifications {
id
message
created_at
updated_at
}
}
}
これを行うには、ordersとnotificationsモデルの権限を設定する必要があります。
注文
モデル選択権限
まず、ModelPermissionsテーブルのordersを見つけます。
kind: ModelPermissions
version: v1
definition:
modelName: orders
permissions:
- role: admin
select:
filter: null
x-hasura-user-idセッション変数をテーブルuser_id上のフィールドと比較するフィルターをordersに追加します。
完全なordersのModelPermissionsは次のようになります。
kind: ModelPermissions
version: v1
definition:
modelName: orders
permissions:
- role: admin
select:
filter: null
- role: user
select:
filter:
fieldComparison:
field: user_id
operator: _eq
value:
sessionVariable: x-hasura-user-id
タイプ権限
ordersのTypePermissionsテーブルを検索します。
kind: TypePermissions
version: v1
definition:
typeName: orders
permissions:
- role: admin
output:
allowedFields:
- created_at
- delivery_date
- id
- is_reviewed
- product_id
- status
- updated_at
- user_id
ユーザーに注文のすべてのフィールドを表示できるようにするため、最終的なordersのTypePermissionsは次のようになります。
kind: TypePermissions
version: v1
definition:
typeName: orders
permissions:
- role: admin
output:
allowedFields:
- created_at
- delivery_date
- id
- is_reviewed
- product_id
- status
- updated_at
- user_id
- role: user
output:
allowedFields:
- created_at
- delivery_date
- id
- is_reviewed
- product_id
- status
- updated_at
- user_id
通知
notificationsテーブルに対してこのプロセスを繰り返します。
モデル選択権限
notificationsテーブルのModelPermissionsを変更すると、次のようになります。
kind: ModelPermissions
version: v1
definition:
modelName: notifications
permissions:
- role: admin
select:
filter: null
- role: user
select:
filter:
fieldComparison:
field: user_id
operator: _eq
value:
sessionVariable: x-hasura-user-id
タイプ権限
最後に、notificationsテーブルのTypePermissionsを変更します。
kind: TypePermissions
version: v1
definition:
typeName: notifications
permissions:
- role: admin
output:
allowedFields:
- created_at
- id
- message
- updated_at
- user_id
- role: user
output:
allowedFields:
- created_at
- id
- message
- updated_at
- user_id
新しい権限をテストする
ご想像のとおり、監視モードを使用していない場合は、新しいビルドを作成します 🚀
hasura3 build create -d "Set nested permissions for users"
次に、コンソールでクエリを実行し、x-hasura-roleとx-hasura-user-idヘッダーが設定されていることを確認します。
query GetUsers {
users {
id
name
email
orders {
id
created_at
status
delivery_date
}
notifications {
id
message
created_at
updated_at
}
}
}
ログインしているユーザーの注文と通知のみが表示されることがわかります。 🎉
Discussion