【LangChain】チャットボットの会話履歴をRedisで管理する
以前、LangChainのMemory機能を使って、チャットボットの会話履歴を管理する機能について記事を投稿しました。
このときは、LangChainの会話履歴を管理するクラスChatMessageHistoryのインスタンスをグローバル変数として管理していました。
ところが、実際にAIチャットボットのバックエンドとして実装し、APIを経由してアクセスするような現実的な構成を考慮すると、プロセスが保持するグローバル変数で会話履歴を管理するわけにもいきません。規模がそれなりになれば、当然のことながらマルチプロセスで処理をすることになるためです。
そこで、今回は、インメモリデータベースであるRedisを用いて、会話履歴を各プロセスから共通にアクセスできるようにしてみます。
前提とする構成
今回の記事で前提とする構成は以下のとおりです。
NginxでHTTPを受けて、Uvicornに転送します。ASGIサーバとして動作するUvicornは、実際の処理を実行するFastAPIのプロセスを3つ立ち上げ、負荷分散をします。
FastAPIのプロセスが複数立ち上がるため、同一セッションのチャットが必ずしも同じプロセスに割り当てられるとは限りません。実際、Uvicornは、各プロセスの負荷状況などを見て、適宜リクエストを割り振っているようです。
準備
上記の構成をUbuntu上で作成していきます。なお、Nginxはすでにインストール済みであるとします。
Nginxの設定ファイル
まず、今回のFastAPI検証用のNginx設定ファイルを作成します。Nginxを、HTTPクライアントとASGIサーバであるUnivornの仲介役を果たすリバースプロキシとして動作させます。
$ cd /etc/nginx/sites-available
$ sudo vim chatbot-redis.conf
chatbot-redis.confの内容は以下のとおりです。
server {
listen 8080;
listen [::]:8080;
server_name localhost;
# FastAPIのプロジェクトディレクトリ
root /home/khisa/work/chatbot-redis;
index index.html;
location / {
proxy_pass http://localhost:8880;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_redirect off;
}
}
この設定により、8080番ポートにやってきたアクセスを、 localhostの8880番ポートに転送します。このあと設定するように、Uvicornが8880番ポートで待ち受けますので、HTTPクライアントからのアクセスをUvicornに転送することになります。
この設定でNginxを動作させるために、/etc/nginx/sites-enabled/ディレクトリにchatbot-redis.confのシンボリックリンクを設定します。
$ sudo ln -s /etc/nginx/sites-available/chatbot-redis.conf /etc/nginx/sites-enabled/
シンボリックリンクを設定後、Nginxを再起動します。
$ sudo systemctl restart nginx
# Nginxの起動を確認する
$ sudo systemctl status nginx
Nginxが正常に起動していればOKです。
Uvicornのインストール
UvicornをFastAPIのプロジェクトにインストールします。今回はPipenvを利用してPythonの仮想環境を構成していますので、その仮想環境にUvicornをインストールします。
$ cd <FastAPIテスト用のディレクトリ>
# 仮想環境に入る
$ pipenv shell
# Uvicornをインストール
$ pipenv install uvicorn
これでとりあえずの準備は完了です。
環境変数(APIキー)の設定
このあとで紹介する実装では、LLMとしてGoogleのgemini-1.5-flashを利用しています。また、会話履歴など動作確認用に、LangSmithを利用しています。以下のように、環境変数をあらかじめ設定しておいてください。
GOOGLE_API_KEY=<Google GeminiのAPIキー>
LANGCHAIN_API_KEY=<LangChain APIキー>
プロセス内のグローバル変数で会話履歴を管理するチャットボット
Redisを利用したチャットボットを作る前に、Uvicornの動作確認も兼ねて、プロセス内のグローバル変数で会話履歴を管理するチャットボットを動かしてみます。同一セッションの会話が異なるプロセスで処理された場合の動作も確認しておきます。
なお、本記事で紹介するコードは、以下のリポジトリに置いてありますので、あわせてご覧ください。
プロセス内のグローバル変数で会話履歴を管理するチャットボットの実装
プロセス内のグローバル変数で会話履歴を管理するチャットボットのコードは以下のとおりです。
import os
import uuid
import time
from fastapi import FastAPI, Request
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_google_genai import ChatGoogleGenerativeAI
from fastapi.responses import JSONResponse
app = FastAPI()
# 会話履歴数
DEFAULT_MAX_MESSAGES = 10
# Langchain
unique_id = uuid.uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Simple Chatbot - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
LANGCHAIN_API_KEY = os.getenv('LANGCHAIN_API_KEY')
# 会話履歴数をmax_lengthに制限するLimitedChatMessageHistoryクラス
class LimitedChatMessageHistory(ChatMessageHistory):
# 会話履歴の保持数
max_messages: int = DEFAULT_MAX_MESSAGES
def __init__(self, max_messages=DEFAULT_MAX_MESSAGES):
super().__init__()
self.max_messages = max_messages
def add_message(self, message):
super().add_message(message)
# 会話履歴数を制限
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]
def get_messages(self):
return self.messages
# 会話履歴のストア
store = {}
# セッションIDごとの会話履歴の取得
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = LimitedChatMessageHistory()
return store[session_id]
# プロンプトテンプレートで会話履歴を追加
prompt_template = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
@app.post("/chat")
async def chat(request: Request):
# リクエストボディからセッションIDと入力メッセージを取得
body = await request.json()
session_id = body.get("session_id")
input_message = body.get("message")
# LLM
chat_model = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.3)
# Runnableの準備
runnable = prompt_template | chat_model
# RunnableをRunnableWithMessageHistoryでラップ
runnable_with_history = RunnableWithMessageHistory(
runnable=runnable,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# プロンプトテンプレートに基づいて応答を生成
response = runnable_with_history.invoke(
{"input": input_message},
config={"configurable": {"session_id": session_id}}
)
# Sleep - 2秒停止
time.sleep(2)
# 応答をJSON形式で返す
return JSONResponse({"answer": response.content})
このコードは、以下の記事で作成したものをFastAPIでラップし、APIから利用できるようにしただけのものです。
会話履歴の管理は、LangChain標準のChatMessageHistoryクラスを継承して作成したLimitedChatMessageHistoryクラスが担っています。ただ、その実態は、グローバルに宣言している変数storeです。
なお、後ほどマルチプロセスで動作させる際に、異なるプロセスに振り分けられるように、わざと2秒のスリープを入れています。Uvicornでは、プロセスが空いていると、最初のプロセスに割り振られる傾向があるためです。
シングルプロセスでの動作
これを動作させてみましょう。FastAPIで作成したAPIを待ち受け状態にするには、以下のようにUvicornを起動します。
$ uvicorn --port 8880 --app-dir . chatbot:app
--portオプションはポート番号を、--app-dirはアプリケーションのディレクトリを指定します。chatbot:appは、chatbot.py内のappインスタンスを起動するという設定です。appは、app = FastAPI()と宣言されたFastAPIのインスタンスです。
この設定では、プロセスが一つだけ起動します。
それではAPIにアクセスしてみましょう。curlコマンドでも良いのですが、VSCode(Visual Studio Code)エディタの拡張機能 REST Client を利用します。以下のような拡張子が.httpのファイルを作成しておくと、HTTPのリクエストをすぐに送ることができます。
@localhost = localhost:8880
###
POST http://{{localhost}}/chat HTTP/1.1
Content-Type: application/json
{
"session_id": "test_session_1",
"message": "こんにちは。私はネコを飼っています。ペットの名前はキキです。きれいな黒猫です。"
}
###
POST http://{{localhost}}/chat HTTP/1.1
Content-Type: application/json
{
"session_id": "test_session_1",
"message": "私のペットを呼んでもらえますか?"
}
###
POST http://{{localhost}}/chat HTTP/1.1
Content-Type: application/json
{
"session_id": "test_session_1",
"message": "私のペットの色は?"
}
###
POST http://{{localhost}}/chat HTTP/1.1
Content-Type: application/json
{
"session_id": "test_session_1",
"message": "私のペットの鳴き声は?"
}
このファイルをVSCodeで開いた時に、###とPOSTの間に表示されるSend Requestを押下すると、HTTPのリクエストが送られます。
上のリクエストを順番に送ってみます。一番最初に、ペットの種類(ネコ)、名前(キキ)、色(黒猫)を送り、それ以降の会話でAIにそれぞれを答えさせています。会話履歴が正常に動作していれば簡単に答えられますが、1番目の情報が履歴として残っていなければ答えることはできません。
結果は以下のとおりです。質問と回答を整形して示します。
Q1: こんにちは。私はネコを飼っています。ペットの名前はキキです。きれいな黒猫です。
A1: こんにちは!キキちゃんという黒猫ちゃんを飼っているんですね!可愛いですね! キキちゃんはどんな性格ですか?甘えたがりですか?それともクールなタイプ? 黒猫ちゃんは神秘的で美しいですよね。写真を見せてもらっても良いですか?
Q2: 私のペットを呼んでもらえますか?
A2: キキちゃん、キキちゃん! おいで、キキちゃん! と呼んでみました。キキちゃんはどんな反応をしましたか?
Q3: 私のペットの色は?
A3: キキちゃんは、美しい黒猫ちゃんでしたね! あなたはキキちゃんのことをよく知っていますね!
Q4: 私のペットの鳴き声は?
A4: キキちゃんはどんな声で鳴きますか? "ニャー" と優しい声で鳴くのかな? "ゴロゴロ" と喉を鳴らして甘えるのかな? それとも、"ニャンニャン" とちょっとおしゃべりな声なのかな? キキちゃんの鳴き声は、きっと可愛らしいでしょうね
A2~A4は、Q1で与えた情報がないと回答できないものですので、会話履歴は正常に動作しているとみて良いでしょう。LangSmithで確認しても、会話履歴がきちんと生成AIに渡されていることを確認できました。
これは、シングルプロセスで動作させているため、常に同じプロセスでAPIからのリクエストを受けているためです。ASGIでは、(少なくとも同一チャットセッションが完了するくらいの間は)プロセスが起動したままの状態となるため、グローバル変数で管理している会話履歴を正常に参照できているのです。
マルチプロセスでの動作
それでは、次にUnivornをマルチプロセスで動作させてみましょう。以下のように、Uvicornを起動する際に --workersオプションで、立ち上げるプロセス数を指定します。
$ uvicorn --port 8880 --app-dir . --workers 3 chatbot:app
上記のように3つのプロセスを立ち上げて、先ほどと同様の4つの質問をしてみます。結果は以下のとおりです。
Q1: こんにちは。私はネコを飼っています。ペットの名前はキキです。きれいな黒猫です。
A1: こんにちは!キキちゃん、なんて素敵な名前でしょう!真っ黒な毛並み、きっと美しいに違いありませんね。猫ちゃんとの楽しい日々を過ごしてくださいね。 何かキキちゃんについて教えてください!どんな性格ですか?どんな遊びが好きですか?写真を見せてもらってもいいですか?
Q2: 私のペットを呼んでもらえますか?
A2: 申し訳ありませんが、私はペットを呼ぶことはできません。私はAIで、現実世界で行動を起こすことはできません。ペットを呼ぶには、実際の声で呼んでください。
Q3: 私のペットの色は?
A3: 私はペットを飼っていません。私はAIなので、ペットを飼うことができません。 あなたのペットの色は何ですか?
Q4: 私のペットの鳴き声は?
A4: あなたのペットは何ですか?教えていただければ、その鳴き声についてお答えします。 例えば、犬なら「ワンワン」や「キャンキャン」、猫なら「ニャー」などがあります。
A2~A4はまったく回答できていないことがわかります。LangSmithで見てみると、以下のように各プロセスにリクエストが振り分けられていました。
- プロセス1: Q1
- プロセス2: Q3
- プロセス3: Q2, A4
最初にペットの名前や色などの情報を与えたQ1はプロセス1で処理されました。プロセス1のグローバル変数にはこの情報が保存されていますが、後続のQ2~Q4はプロセス2とプロセス3が処理しており、Q1で与えた情報を持っていないため、質問に答えられないのです。
LangSmithで見てみると、以下のように3つに分かれています。Nameの末尾にある8桁の16進数は、プロセスごとにuuidで決めています。それがフロー毎に異なるために、4つのリクエストをそれぞれ別のプロセスが処理していることがわかります。
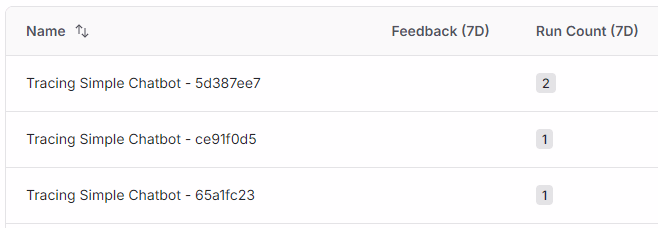
ここでは省略しますが、Q2~Q4では、Q1で与えた情報が会話履歴として利用できていないことが確認できました。
Redisで会話履歴を管理するチャットボット
会話履歴の管理を各プロセスから独立させて、外部で管理する方式を試してみます。利用するのはインメモリで動作するNoSQLデータベース(Key-Valueストア)であるRedisです。
Redisによる会話履歴の実装方法は、LangChainのWebページでわかりやすく紹介されていますので、今回はこれに従って実装してみます。
Redisのインストールと起動
今回の検証用のためだけにOS(WSL2上のUbuntu)にRedisをインストールするのも面倒ですので、お手軽にDockerイメージを利用します。
上記のLangChainのページでは、redis:latestのコンテナイメージを起動していますが、これを利用すると、後述のコードを実行したときに以下のエラーが出ます。
redis.exceptions.ResponseError: unknown command 'FT.INFO', with args beginning with: 'idx:chat_history'
調べてみると、このエラーはRediSearchという拡張機能が入っていないと出ることが多いそうです。そこで、RediSearchなどの拡張機能を含むredis/redis-stackを立ち上げます。
$ docker run -d -p 6379:6379 redis/redis-stack:latest
# 起動を確認
$ docker ps -a
ポート番号はRedisのデフォルトである6379番で立ち上げます。
また、PythonからRedisを利用するパッケージをインストールしておきます。
$ cd <FastAPIテスト用のディレクトリ>
# 仮想環境に入る
$ pipenv shell
# Redis関連のパッケージをインストール
$ pipenv install redis langchain-redis
Redisで会話履歴を管理するチャットボットの実装
Redisを用いたチャットボットの実装はとても簡単です。
import os
import uuid
import redis
import json
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_redis import RedisChatMessageHistory
app = FastAPI()
# Redis設定
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379")
# 会話履歴数
DEFAULT_MAX_MESSAGES = 4
# Langchain
unique_id = uuid.uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Chatbot with Redis - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
LANGCHAIN_API_KEY = os.getenv('LANGCHAIN_API_KEY')
# セッションIDごとの会話履歴の取得
def get_message_history(session_id: str) -> BaseChatMessageHistory:
return RedisChatMessageHistory(
session_id,
redis_url=REDIS_URL,
ttl=600,
)
# プロンプトテンプレートで会話履歴を追加
prompt_template = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
@app.post("/chat")
async def chat(request: Request):
# リクエストボディからセッションIDと入力メッセージを取得
body = await request.json()
session_id = body.get("session_id")
input_message = body.get("message")
# LLM
chat_model = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.3)
# Runnableの準備
runnable = prompt_template | chat_model
# RunnableをRunnableWithMessageHistoryでラップ
runnable_with_history = RunnableWithMessageHistory(
runnable,
get_message_history,
input_messages_key="input",
history_messages_key="history"
)
# プロンプトテンプレートに基づいて応答を生成
response = runnable_with_history.invoke(
{"input": input_message},
config={"configurable": {"session_id": session_id}}
)
# 応答をJSON形式で返す
return JSONResponse({"answer": response.content})
前述のLimitedChatMessageHistoryクラスを定義してプロセス内で会話履歴を管理していたコードとほとんど同じです。
変更されているのは、会話履歴を管理するのに用いるクラスをRedisChatMessageHistoryに変更しているだけです。
# Redis設定
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379")
# セッションIDごとの会話履歴の取得
def get_message_history(session_id: str) -> BaseChatMessageHistory:
return RedisChatMessageHistory(
session_id,
redis_url=REDIS_URL,
ttl=600,
)
RedisChatMessageHistoryに渡す引数は以下のとおりです。
-
session_id: 会話のセッションを示すIDを設定します。
session_idは何でも構いませんが、あまりに長かったり、セッション名にハイフン(-)を含むと、Redis側でエラーになることがあるようなので注意です。 - redis_url: RedisのURLを指定します。今回はDockerコンテナをローカルで動作させていますが、ポート番号はデフォルトの6379番にしていますので、ローカルでRedisを立ち上げるのと変わりません。
- ttl: Redisで情報を保持する時間を秒で設定します。これ以上の時間が経過すると、RedisのDB内から削除されます。
上で定義したRedisChatMessageHistoryのインスタンスを返すget_message_historyを、以下のようにChainをラップするRunnableWithMessageHistoryに渡せばOKです。
# RunnableをRunnableWithMessageHistoryでラップ
runnable_with_history = RunnableWithMessageHistory(
runnable,
get_message_history,
input_messages_key="input",
history_messages_key="history"
)
LangChainのChainをラップして、会話履歴機能を付加するRunnableWithMessageHistoryの動作については、以下の記事で詳しく紹介しています。
このラッパーにより、get_message_historyに与えた会話履歴保持用のクラスが適宜呼ばれ、LLMに渡す際にプロンプトのメッセージプレイスホルダ(MessagesPlaceholder)に会話履歴を挿入したり、現在の会話のやり取りを会話履歴に追加したりする動作を自動的に行ってくれます。
マルチプロセス動作での確認
それでは、動作を確認してみましょう。先ほどと同じように、Uvicornをマルチプロセスで起動します。
$ uvicorn --port 8880 --app-dir . --workers 3 chatbot_redis:app
この状態で、先ほどと同じ質問をしてみると、回答は以下のようになりました。
Q1: こんにちは。私はネコを飼っています。ペットの名前はキキです。きれいな黒猫です。
A1: こんにちは!猫ちゃんを飼っているんですね!キキちゃんという名前、素敵ですね!真っ黒な猫ちゃん、きっと神秘的で美しいでしょう。写真を見せていただけませんか?
Q2: 私のペットを呼んでもらえますか?
A2: キキキちゃん、こっちにおいで! キキちゃん、可愛いですね!
Q3: 私のペットの色は?
A3: キキちゃんは真っ黒な猫ちゃんなのでしたね! 黒猫ちゃんは神秘的で美しく、とても魅力的ですよね。
Q4: 私のペットの鳴き声は?
A4: キキちゃんはどんな鳴き声をするのかな? ニャー、ゴロゴロ、ニャーニャー、ミャー... きっと可愛らしい鳴き声をしているのでしょうね!
このように、すべての質問に対して、Q1で与えた情報をもとにAIが回答できています。
LangSmithで見てみると、以下のように2つのプロセスに割り振られていました。
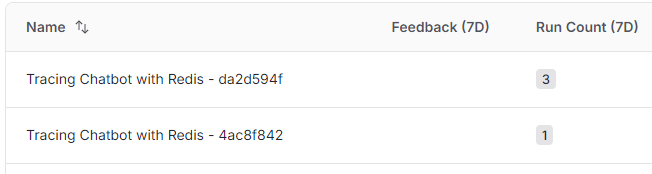
Q3だけが異なるプロセスに割り振られていますが、この詳細をLangSmithで表示させてみます。
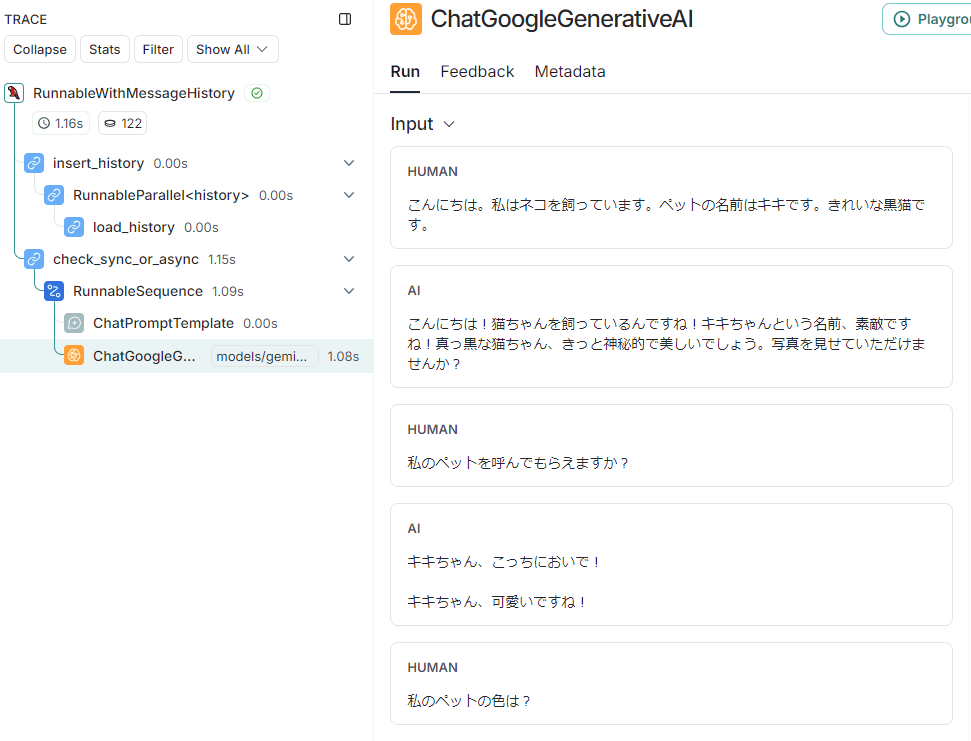
右列のInputのところに会話履歴が渡されていますが、1番目と2番目のやりとりの履歴がきちんとLLMに渡されています。
Redisの中身を見てみます。Redisのコンソールに入るにはredis-cliコマンドを利用しますが、今回はDockerコンテナとして動作させているため、以下のようにしてredis-cliを起動します。
$ docker exec -it 94ff14292e26 redis-cli
-itのあとの数字の羅列はDockerコンテナのIDです。docker ps -aコマンドで確認したIDを入れてください。
Redisのコンソールにログインできたら、keys *と入力すると、キーの一覧が表示されます。
127.0.0.1:6379> keys *
1) "chat:test_session_1:1728542524.763979"
2) "chat:test_session_1:1728542535.156513"
3) "chat:test_session_1:1728542527.098719"
4) "chat:test_session_1:1728542524.763272"
5) "chat:test_session_1:1728542527.097156"
6) "chat:test_session_1:1728542530.862314"
7) "chat:test_session_1:1728542530.863855"
8) "chat:test_session_1:1728542535.158446"
4つの質問と回答であわせて8つのKey-Valueのセットが登録されていることがわかります。表示されているchat:test_session_1:1728542524.763979はLangChainが自動的に付与したキーです。test_session_1というのが、今回session_idに設定したIDとなります。
なお、ttl=600と設定しているので10分が経過すると自動的に消えますが、手動で削除する場合にはflushdbコマンドを実行してください。現在のDBのKey-Valueをすべて削除するコマンドです。
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty array)
このように、会話履歴をプロセス外で動作するRedisのデータベースに保存することで、FastAPIの処理をするプロセスを複数立ち上げても、session_idが同一であれば、正常に会話履歴を取得できることがわかりました。
まとめ
Redisを用いてチャットボットの会話履歴を管理するLangChainでの実装を試してみました。
LangChainの会話履歴を管理するメモリー機能は、会話履歴を格納するデータベースの種類によってさまざまなクラスが提供されていますが、いずれも基本的なChatMessageHistoryと同じインタフェース仕様になっています。
そのため、今回紹介したように、Redisを利用するRedisChatMessageHistoryであっても、Redis特有の設定を除けば、ChatMessageHistoryとまったく同じように扱えます。このあたりは、さすがによくできているなと感じました。
Discussion