はじめに
こんにちは!KGモーターズ株式会社でエンジニアをしている中村です。
KGモーターズは、広島を拠点に1人乗り小型 EV mibot を開発しているスタートアップです。

現在は量産に向けてmibotそのものの作り込みやアプリケーション開発、クラウドインフラの開発をメインに行なっていますが、将来の仕込みも内部では行なっています。直近研究開発チームが自動運転AIチャレンジに参加しておりますので、結果などは別途発信したいと思っています。
アプリ開発について興味がある方は以下をご覧ください!
そんな中、少し前に見つけたオープンなVLMの論文があり、いつかまとめておこうと思っていたのでテックブログにまとめます!(CVPR2025のBest Paperノミネート論文になっています)
工場内で自動走行する際には「目」を持っていることが重要なのと、このモデルはデータセットの関係で認識や数を数えるという特徴が非常に強いので、KGモーターズの工場内を散策する際に使えるかもしれないと思っています...
またこの中ではプロプライエタリというワードが出てきますが、非公開くらいの意味だと考えてください。
何がすごいか?
忙しい方のためにまとめます。
- 完全オープン
- モデル重み・学習データ・コードまで公開
- 合成データをプロプライエタリVLMから蒸留せずに到達した性能がポイント
- PixMo
- 汎用VLMを作るために必要な巨大なデータセットを集め切った
- 以下のようなデータを含む
- 超長文キャプション
- 自由形式Q&A
- 2Dポインティングなど、汎用VLMに直結するデータ設計。
- SOTA級の成績
-
Molmo-72Bは学術ベンチマークで最高水準(当時) - 人手評価でも
GPT-4oに次ぐと主張 - 小型の
MolmoE-1Bも強力
-
- 実運用適性
- 数を数える(point-and-count)
- OCR/ドキュメント・チャート理解
- UI操作系まで幅広く対応
PixMoは以下を見ると色々データが載っています。また後ほど紹介します。
前提とやったこと
前提
この論文を読む前に、簡単に今どういう時代なのかを外観しておきましょう。
GPTをはじめとするVLMはAPI経由の「ブラックボックス」になっていて、学習データも非公開となっています。
結果として「ゼロから強いVLMをどう作るか」という基礎知見がコミュニティ溜まりづらいという問題があります。
Molmo はこの状況に対し、公開データと公開重みで最先端に迫る実例を出してコミュニティへの貢献をしようとしています。
やったこと
そして実際に何をしたか?ですが...
Molmoというモデルを作って公開した
既存のViT系のVision Encoder + LLMを組み合わせたVLMファミリーを作り、サイズ別に公開。
PixMoというデータを作って公開
人手主導で高品質に集めたマルチモーダルデータ群(キャプション/物体座標点/文章/VQAなど)を作って公開。
評価して結果良好
11ベンチマークと人手評価で比較。結果も良かった
データ: PixMoについて
よく学習データにプロプライエタリの出力を混ぜてデータ拡張したりしますが、これをしてしまうと本当の意味で1から作り上げたことになりません(一部ブラックボックス化してしまう)。
しかしデータを大量に用意するのは非常のコストがかかり、かつ制約もあるのですが、PixMoのデータの作り方は非常に面白いです。
ここでは全てを取り上げるわけではありませんが、紹介するPixMoデータセットにより、Molmoで可能になる機能の関係図です。
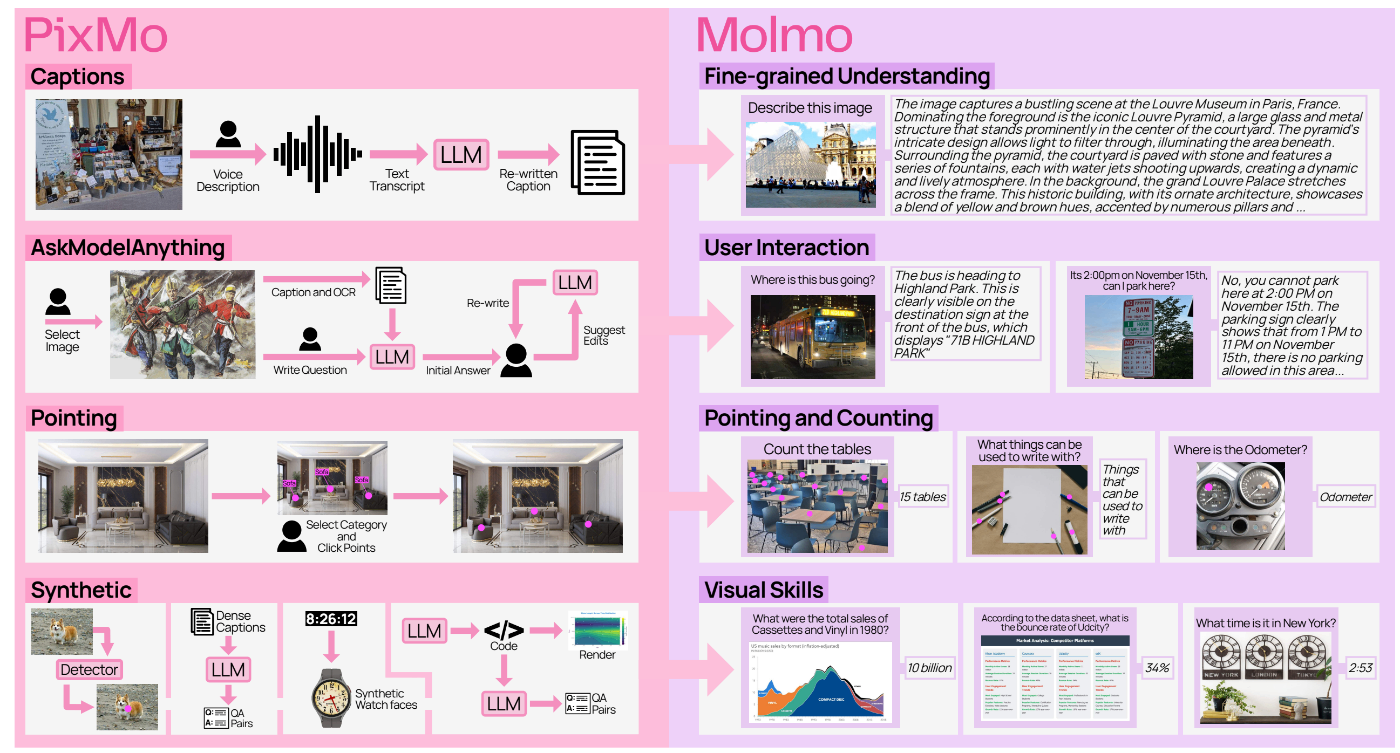
https://arxiv.org/pdf/2409.17146
PixMo-Cap
多様な画像と詳細なキャプションを対にしています。
1個見てみましょう。
| 画像 | キャプション |
|---|---|
 |
This photograph depicts a striking black bird, possibly a grackle or similar species, perched on a white cement wall with red stains. The bird's sleek, elongated body is adorned with iridescent feathers that shimmer with shades of blue, purple, and green, most prominently on its wings and back. Its piercing yellow eye and long, sharp beak lend it a fierce, almost aerodynamic appearance. The bird's dark, slender legs and short talons grip the edge of the cement structure, which resembles a divider or barrier, possibly in an outdoor setting like a park or building patio. The background is a blur of green and white hues, hinting at lush tropical plants and tall trees, setting a serene, natural scene. The bird is poised, looking towards the upper right-hand corner of the frame, with its long tail feathers trailing elegantly to the left. |
日本語だと
この写真には、黒く美しい鳥が写っており、おそらくグラックル(ムクドリ科の一種)やそれに似た種と思われます。鳥は赤いシミのついた白いセメントの壁にとまり、体はスリムで細長く、翼や背中を中心に青・紫・緑の光沢を放つ羽毛に覆われています。その鋭い黄色の目と長く鋭いくちばしは、精悍で流線型の印象を与えます。細い黒い脚と短い爪でセメントの縁をしっかりとつかんでおり、その構造は仕切りや障壁のようで、公園や建物のパティオなど屋外の一角と思われます。背景は緑と白がぼんやりと混じり合い、熱帯の豊かな植物や高い木々を思わせ、落ち着いた自然の風景を演出しています。鳥は右上を見つめるように構え、長い尾羽を左側へ優雅にたなびかせています。
めちゃめちゃ詳細です。
Webから集めてきた画像に対してこのようなキャプションをつけていったわけですが、直接テキスト入力だと
- 長文を書かせると品質が低くなりがち
- 目立つ要素に偏りがち[1]
- 長文記入は時間がかかるのでアノテーターがプロプライエタリVLMからのコピペをしてしまう可能性がある
上記のような懸念があるため、Pixmo Capではアノテーターに 60〜90 秒間音声で画像を説明してもらう手法を採用し、短時間で効果的にデータを収集しています。
こうして約70万件の画像、約130万件のキャプションを構築しています。
PixMo-AskModelAnything
要するにQA形式のデータセットで、画像-質問-回答の組みを作ります。
近年の自動運転システムはLLMが状況を理解し、制御するという仕組みが多く存在し、それらのモデル構築や評価の際にQAデータセットは非常に重要です。
また一つ見てみましょう。
| 画像 | 質問 | 回答 |
|---|---|---|
 |
what type of plant is this? | The plants in the image are artificial. The main one is a faux "string of pearls" (Senecio rowleyanus), featuring cascading strands with small, bead-like structures. There's also an artificial baby rubber plant (Peperomia obtusifolia) with thick, rounded leaves.These artificial plants combine different textures and shapes, creating an attractive display for indoor decoration without the need for maintenance. The string of pearls provides a trailing effect, while the baby rubber plant adds a fuller, upright appearance. |
日本語だと以下です。(眼鏡のおっさんみたいなものは触れないのか...と思ってしまいました)
これは何の植物ですか?
画像の植物は人工のものです。主なものはフェイクの「グリーンネックレス」(Senecio rowleyanus)で、小さなビーズ状の粒が連なったつるが垂れ下がる姿をしています。さらに、厚く丸みのある葉を持つ人工のベビーローズ(Peperomia obtusifolia、ベビールバーとも呼ばれる)もあります。
これらの人工植物は、異なる質感や形状を組み合わせることで、メンテナンス不要で室内装飾に適した魅力的なディスプレイを作り出しています。グリーンネックレスは垂れ下がる効果を与え、ベビーローズはよりボリューム感のある直立した印象を加えています。
さて、このデータセットをどのように作成したかというと、
- アノテーターがデータの中から画像を選んで質問を作成する
- VLMではない標準的なOCRモデルと、PixMo-Capで学習したモデルにそれぞれ画像を入れて推論する
- 出力結果と質問を「言語のみのLLMモデル」に入力し、回答を生成する
- アノテーターは回答が受け入れられるものかどうかを判断。もし却下した場合は問題点を指摘し、再度実行を繰り返す
このようなサイクルを回し、7.3万枚の画像に対して16.2万件のQAペアを収集しました。
PixMo-Points
これは画像に対して対象のラベルがどの座標にあるかが格納されたデータセットです。
このデータは以下を目的にしています。
- テキストで述べた対象を指し示せること
- さし示して数えられること
- 回答時に視覚説明として指し示せること
いくつかデータを見てみましょう。
| 画像 | ラベル | 座標 |
|---|---|---|
 |
Book | [ { "x": 29.583, "y": 11.834 }, { "x": 35.566, "y": 95.978 }, { "x": 38.392, "y": 96.424 }, { "x": 40.719, "y": 96.424 },.. |
|
Book on right bookshelf | [ { "x": 52.353, "y": 97.469 }, { "x": 55.178, "y": 96.913 }, { "x": 58.668, "y": 96.468 },... |
|
Person | [] |
このように指定されたラベルがどの座標にあるかがJson形式で記載されています。
一応ほんとに合ってるのか?が気になったので可視化してみました。
...ピッタリ点が打たれています。
| Book | Book on right bookshelf |
|---|---|
 |
 |
import cv2
import json
import matplotlib.pyplot as plt
CIRCLE_SIZE = 20
img = cv2.imread("path to image file")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
height, width = img_rgb.shape[:2]
with open("path to json file", "r") as f:
coordinates = json.load(f)
for coord in coordinates:
x = int(coord['x'] * width / 100)
y = int(coord['y'] * height / 100)
cv2.circle(img_rgb, (x, y), CIRCLE_SIZE, (255, 0, 0), -1)
plt.figure(figsize=(12, 8))
plt.imshow(img_rgb)
plt.axis('off')
plt.show()
PixMo-Docs
いわゆる図やグラフを読み取って回答するデータセットです。
これは1から作り上げたわけではなく、図を作るコードをLLMに生成させ、コードをもとにLLMにQAペアを作らせています。
これにより効果的に大量のペアを生成することができます。
25.5 万枚の画像、230 万のQAペアを構築しています。
実際は質問と回答は1個のJSONファイルになっていますが、わかりやすいように分けています。
| 画像 | 質問 | 回答 |
|---|---|---|
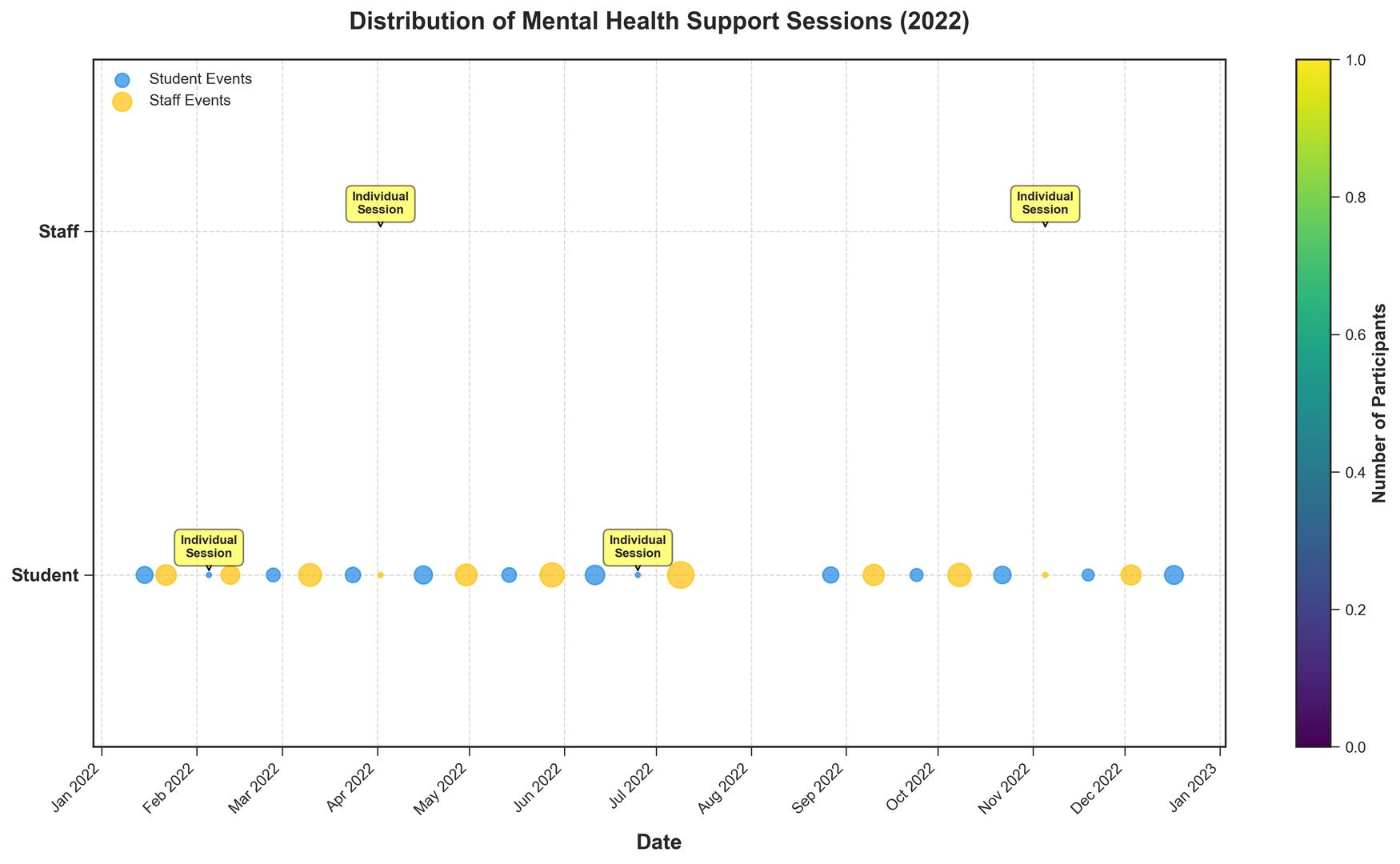 |
"question": [ "Which month had the highest number of participants in mental health support sessions?", "What is the total number of participants in staff events over the year?", "Compare the number of participants in individual counseling sessions for students versus staff. Which is higher?", "What is the average number of participants per event for student events?", "Which event had the maximum number of participants and how many?", "Are there more student events or staff/teacher events over the year?", "Do student events tend to have participants more or less than staff events?", "What month had the highest diversity of event types (student and staff events)?", "Which quarter of the year saw the highest number of student events?" ], |
"answer": [ "August", "219", "Equal", "Approximately 9.46", "Summer Staff Wellness Retreat, 30", "Student Events", "Less", "April", "Q4" ] |
モデルアーキテクチャ
このモデルのアーキテクチャは、事前学習済みの言語モデルとVisionモデルを組み合わせています[2]。
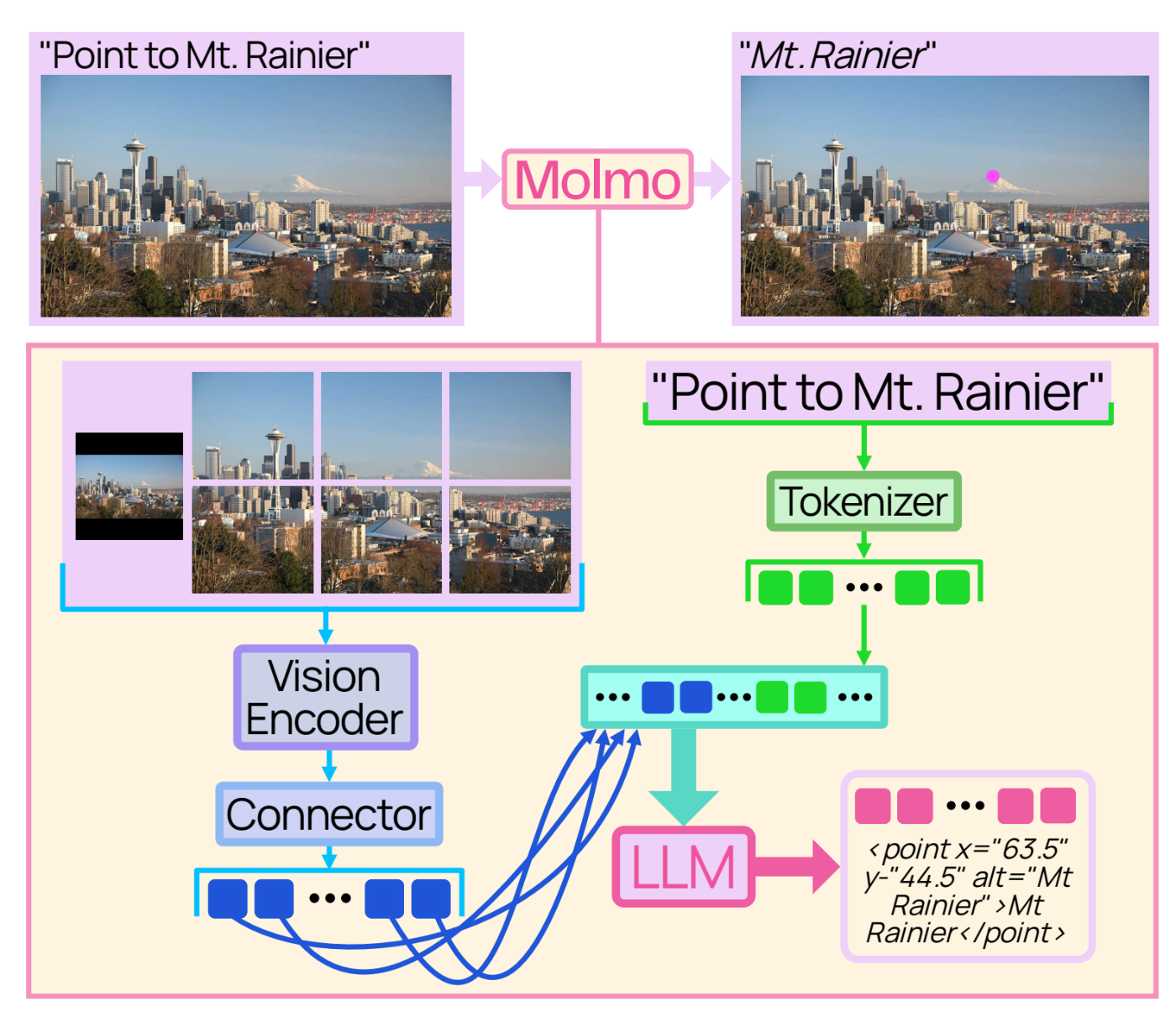
アーキテクチャとしては非常に典型的で、Vision Encoderから得られた特徴量をコネクターを通してTokenに落とし、後段のLLMに入れて出力を得るというモデルです。
PixMo-Pointsデータのラベルと座標もTokenにしてLLMで合流させることで、モデルが位置も含めた特徴を学習できる、ということみたいです(論文で出てくる「指し示す能力」というものだと思います)。
アーキテクチャは典型的ですが、いろいろ工夫をしています。
- 入力画像をマルチスケール・マルチクロップ画像へ変換する前処理
- 各画像を独立にパッチ特徴へ変換する ViT 画像エンコーダ
- パッチ特徴をプーリングしてLLMの埋め込み空間へ写像するコネクタ
あとでピックアップしてこの特徴を見てみます。
このテンプレートを用いて、Vision EncoderとLLMを選び、学習データと学習方法は一定のままでモデルファミリーを構築しています。
Vision Encoder
最初にOpenAI の CLIP[3]を使いましたが、SigLIP [4] やオープンモデルである MetaCLIP [5] でも同等の結果が得られることが後の評価セクションで示されています。
LLM
LLM は以下のモデルを使っています。
- OLMo-7B-1024-preview
- OLMoE-1B-7B
- Qwen2 7B
- Qwen2 72B
この中で、OLMoE-1B-7Bでもっとも効率のよいモデル(モデル規模、精度の面で論文の中でそう言われている)、Qwen2 72Bで最高性能モデルができています。
マルチスケール・クロップ
多くのVision Transformer(ViT)は固定解像度の画像にしか対応しないことが多く、OCRや詳細なキャプションといった細かなタスクには弱い傾向があります。
近年の研究[6][7] をもとに、画像を複数の正方形クロップに分割してタイル状に並べます。さらに、画像全体をViTの解像度にリサイズした低解像の全体像も用意します。各クロップはViTで独立に処理されていきます。
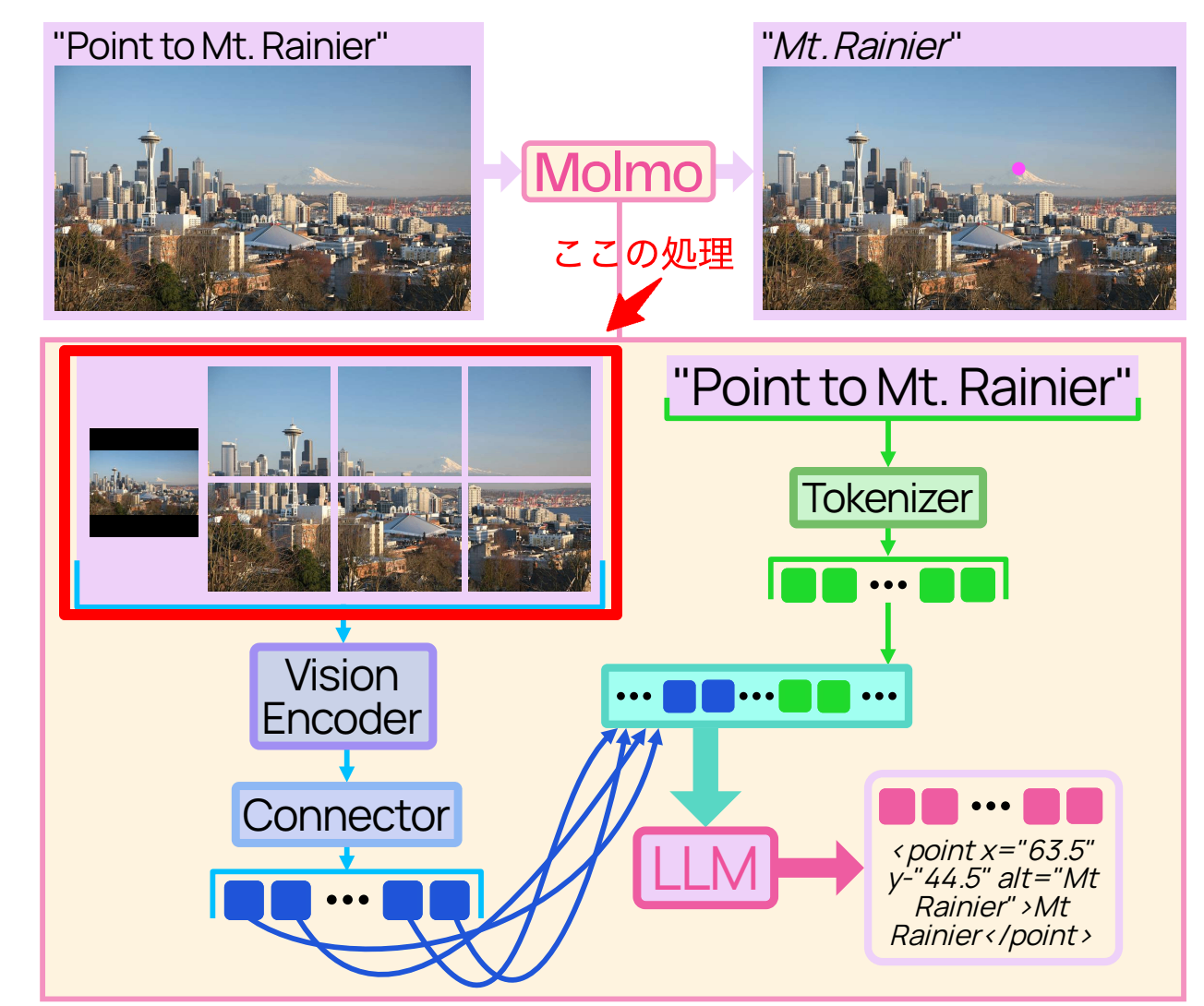
クロップすると画像中の細かな表現まで獲得できるというメリットがありますが、画像全体のコンテキストが得られないというデメリットがあります。そこで元の画像をリサイズして入力するんですね。
また境界付近のパッチが隣接パッチの文脈を欠きやすいため、オーバーラップしながらクロップし、各パッチが少なくとも一部の隣接パッチの文脈を持つようにします。
これをすると精度がしっかり上がります。評価セクションで実験結果が載っていました。

Vision-languageコネクタ
クロップ画像がビジョンエンコーダでエンコードされた後、パッチの特徴をある程度まとめるための仕組みとして、2x2のパッチを1つのベクトルにまとめます。
イメージとしてはこんな感じだと思います。ViTで特徴量を作ると、25個出てきますが、隣り合う2つのパッチでまとめた特徴量を算出します。

さらにここから、算出した特徴量にマルチヘッドアテンションを適用することで、どこのパッチに重きを置いて学習するか、パッチ間の関係性も学習することができます。
実験によると、単にコネクタで連結するより上記の仕組みを入れた方が精度が上がります。

Visionトークンの並べ方
これはLLMが登場してから比較的メジャーになった特別トークンに関する話ですが、Visionエンコーダから得られたパッチ特徴は、左から右、上から下の順で並べます。
最初に低解像の全体画像のパッチ、続いて高解像クロップのパッチを行優先(row-major)順で配置していきます。低解像・高解像それぞれの開始・終了には特別トークンを挿入し、行の切れ目には行終端トークンを入れて行遷移を示します。
評価
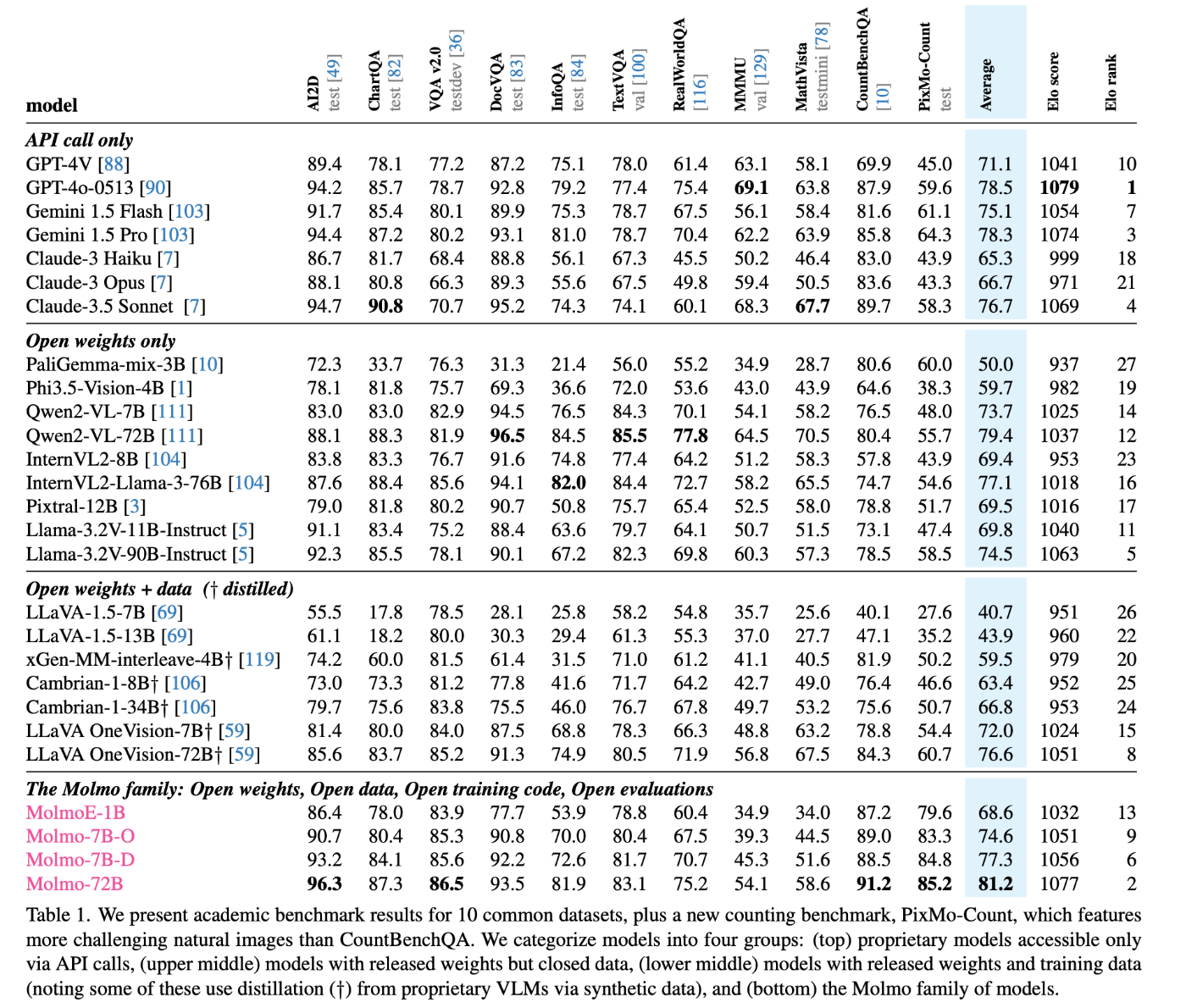
11の学術ベンチマークおよび人間の評価でテストされています。
今となってはGPT-4o、Claude-3.5 Sonnetなどは少し前のモデルとなってしまっていますが、それでもQwen2 72BがベースとなったMolmo-72Bは学術ベンチマークにおいて最高スコアを達成しています。
実際どれくらいのものか、は以下のREADMEを見れば実行はできると思いますが、そのまま動かすとそこそこの計算資源は必要だと思います。
おわりに
KGモーターズでは小型EVのソフトウェア領域を一緒に開発する仲間を募集していますので、興味のある方は気軽にカジュアル面談も歓迎ですのでご連絡ください!!

Discussion