はじめに
プロジェクトの目的と背景
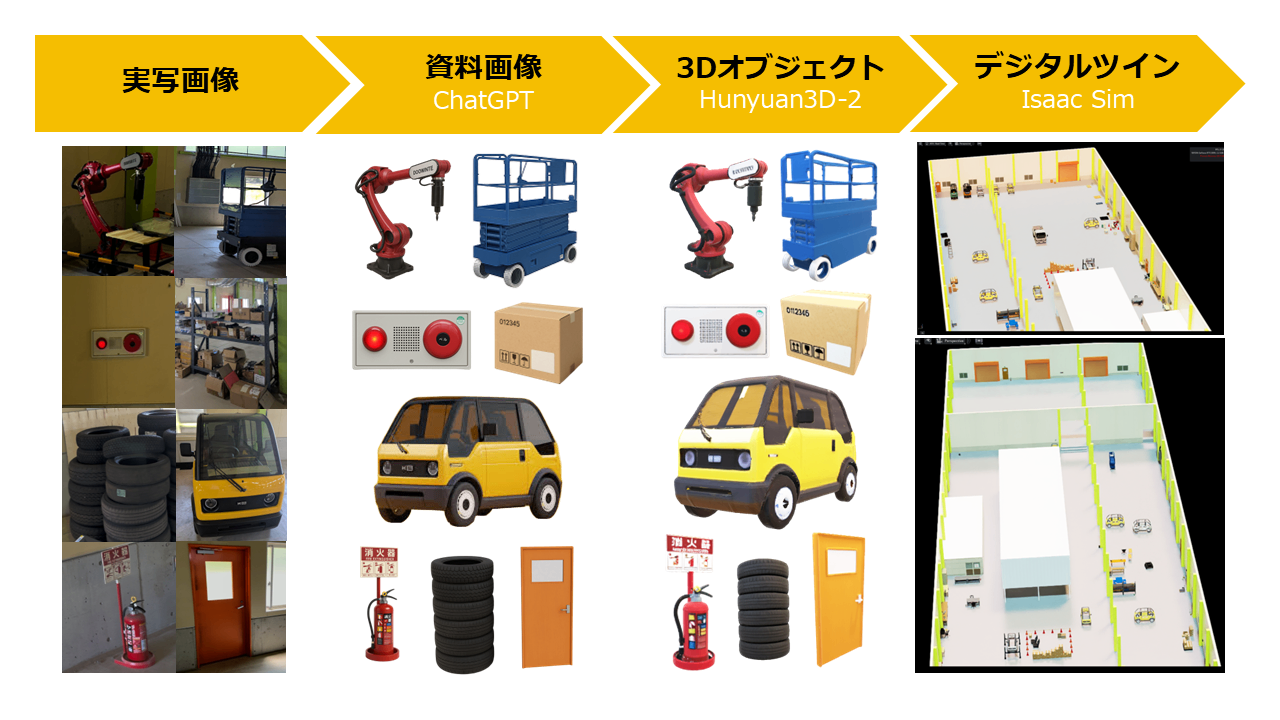
この記事では、ChatGPTとHunyuan3D-2という生成AIを組み合わせて、複数の画像からデジタルツイン用の3Dオブジェクトを作成する方法を紹介します。
私は現在工学系の学部3年生で、この春から一人乗りの超コンパクトな電動マイクロカー『mibot』を開発する会社「KGモーターズ株式会社」でインターンをしています。
将来的にmibotは自動運転車としての実用化を目指しています。
その一環として、工場のデジタルツインを作り、mibotを工場内で走らせるシミュレーションに取り組みました。
今回の記事では、その目標に向けた第一弾として、KGモーターズ株式会社の拠点である Mibot Core Factory(MCF) の内部を再現する過程を紹介します。
本記事の対象読者
- 生成AIやデジタルツインに興味はあるけれど、まだ何から始めればいいかわからない初心者の方
- ChatGPTや画像生成AIを研究・開発以外でも試してみたい方
- ROSやロボットシミュレーションに取り組んでみたい学生・エンジニア
私自身初心者なので、「入門者がつまずいたところを含めて正直に書く記事」として参考にしていただければと思います。
参考にした記事
今回の取り組みでは、以下の記事を大いに参考にしました。
推奨環境
今回の推奨環境は以下の通りです。
| Hunyuan3D-2推奨環境 | |
|---|---|
| OS | Windows |
| GPU | NVIDIA製、VRAM8GB以上 |
| Driver | 550以降 |
| システムメモリ | 24GB以上 |
| CUDA | 11.8 |
| Isaac Sim推奨環境 | |
|---|---|
| OS | Linux |
| GPU | NVIDIA製、VRAM 8GB以上 |
| Driver | 535.129.03以降 |
| システムメモリ | 32GB以上 |
手順
1.ChatGPTによる実写画像から資料用画像の生成
ChatGPT UIを使用する場合
 最大10枚ずつChatGPTに画像を入力
最大10枚ずつChatGPTに画像を入力
10枚ずつChatGPTに画像を渡し、次のようなプロンプトを書きます。
#プロンプト
この写真の中の小物を3Dモデルとして再現したいです。
それぞれを分けて、1枚のシートの上に並べた状態で表示してください。
各パーツは3Dモデリングの参考になるように、形状が分かりやすいようにしてください。
テクスチャは元の写真を反映させ、背景は白にしてください。
すると以下のような出力が得られます。
 出力結果
出力結果
2.資料用画像の整理
3Dオブジェクトの出力精度を上げるため、オブジェクトごとに切り分け、背景を除去しておきます。
3.pinokioによるHunyuan3D-2の環境構築
pinokio
pinokioは画像から3Dオブジェクトを生成するライブラリHunyuan3D-2を手早くインストールするための補助ツールです。Hunyuan3D-2は初心者には依存関係が複雑なので、Pinokioはライブラリのインストールを自動的に行ってくれる便利なツールです。
pinokioの公式ページ から「Download」ボタンを押し、各OSごとの手順にそってインストールします。今回はWindows環境にインストールするため、「Download for Windows」ボタンを押してUnzipします。
このとき、以下のような警告が出ますが、「詳細情報」をクリックして「実行」すると、インストールできます。
Hunyuan3D-2
Hunyuan3D-2は画像から3Dオブジェクトを生成するライブラリです。こちらのページで、Mesh生成を体験することができますが、テクスチャをつけるならローカルで実行する必要があります。
手順の説明に戻ります。
-
先ほどインストールしたpinokioを起動し、「Visit Discover Page」をクリック

-
「Download from URL」を選び、https://github.com/pinokiofactory/Hunyuan3D-2をgit URLとして入力
-
左のバーからInstallを探しクリック、Startボタンを押す
-
下の画像のような画面になれば完了
トラブルシューティング
しかし、私が手順通り実行すると、4.の画面にならずにエラーを起こしてしまいました。
エラーの原因は以下のようなものでした。
- PyTorch2.5以前はセキュリティ上の結果により原則使用禁止に
→PyTorch2.6以上でないためエラー - PyTorch・torchaudio・torchvisionはCUDAのバージョンと依存関係あり
→PyTorch2.6以上を実現できるCUDAを選ぶ必要があった
今回は以下のような対応をすると解決することができました。
- cuda × PyTorch・torchaudio・torchvisionの依存関係の特定
コマンドプロンプトに以下を入力し出力を得て、今回はtorch-2.7.1+cuda118の組み合わせがあることが判明しました。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
>Successfully installed sympy-1.13.3 torch-2.7.1+cu118 torchaudio-2.7.1+cu118 torchvision-0.22.1+cu118
- pinokioの上書きを阻止
pinokioが自動でCUDA 12.1 × PyTorch2.5.1にしてしまうのを防ぐため、pinokio>api>Hunyuan3D-2.git>app>requirements.txtに以下のように書き加えました。
--extra-index-url https://download.pytorch.org/whl/cu118
torch==2.7.1
torchvision==0.22.1+cu118
torchaudio==2.7.1
また、pinokio>api>Hunyuan3D-2.git>torch.jsに"message": 以降を付け加えました。
// windows nvidia
{
"when": "{{platform === 'win32' && gpu === 'nvidia'}}",
"method": "shell.run",
"params": {
"venv": "{{args && args.venv ? args.venv : null}}",
"path": "{{args && args.path ? args.path : '.'}}",
"message": "uv pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 {{args && args.xformers ? 'xformers' : ''}} --index-url https://download.pytorch.org/whl/cu118"
}
},
4.資料用画像→3Dオブジェクトの生成
いよいよHunyuan3D-2を使用して3Dオブジェクトを生成していきます。
- コマンドプロンプトを起動
- C:\pinokio\api\Hunyuan3D-2.git\appに移動
cd C:\pinokio\api\Hunyuan3D-2.git\app
- 仮想環境を起動
.\env\Scripts\activate
- ローカルサーバーを起動
python api_server.py --enable_tex --host 0.0.0.0 --port 8080

この画面になれば成功です。
- scriptを用意しpinokio>api>Hunyuan3D-2.git>app>generates.pyを配置
このとき、input_dir = 'assets/input_img'にChatGPTで生成した資料用画像を配置しておきます。以下のソースコードは一気に複数の3Dオブジェクトを生成することが可能です。
なお、このスクリプトはこちらの記事を参考にしました。
import base64
import json
import time
from pathlib import Path
from typing import Union
import requests
def send_image_to_api(
image_path: Union[str, Path],
output_path: Union[str, Path],
retries: int = 3,
timeout: int = 600
) -> None:
"""
指定された画像をAPIに送信し、結果を保存する。
Args:
image_path (Union[str, Path]): 入力画像のパス。
output_path (Union[str, Path]): 出力GLBファイルの保存先。
retries (int): リトライ回数(デフォルト: 3)。
timeout (int): タイムアウト時間(秒)(デフォルト: 600)。
Returns:
None
"""
image_path = Path(image_path)
output_path = Path(output_path)
print(f"\n--- 処理開始: {image_path} ---")
start_time = time.time()
with image_path.open('rb') as image_file:
img_b64_str = base64.b64encode(image_file.read()).decode('utf-8')
url = "http://localhost:8080/generate"
headers = {"Content-Type": "application/json"}
payload = {
"image": img_b64_str,
"texture": True
}
for attempt in range(1, retries + 1):
try:
print(f" → API送信中 (試行 {attempt}/{retries})...")
response = requests.post(url, headers=headers, json=payload, timeout=timeout)
if response.status_code == 200:
with output_path.open('wb') as f:
f.write(response.content)
duration = time.time() - start_time
minutes = int(duration // 60)
seconds = int(duration % 60)
print(f" ✅ 成功: {output_path} に保存(処理時間: {minutes}分 {seconds}秒)")
return
else:
print(f" ❌ ステータスコード: {response.status_code}")
except requests.exceptions.Timeout:
print(" ⚠️ タイムアウトが発生しました。")
except Exception as e:
print(f" ⚠️ エラー発生: {e}")
time.sleep(5)
duration = time.time() - start_time
minutes = int(duration // 60)
seconds = int(duration % 60)
print(f" ❌ 最終的に失敗: {image_path}(処理時間: {minutes}分 {seconds}秒)")
def process_all_images() -> None:
"""
入力ディレクトリ内のすべての画像ファイルを処理し、
出力ディレクトリにGLBファイルとして保存する。
Returns:
None
"""
input_dir = Path('assets/input_img')
output_dir = Path('assets/output_glb')
output_dir.mkdir(parents=True, exist_ok=True)
image_files = sorted([
f for f in input_dir.iterdir()
if f.suffix.lower() in ('.png', '.jpg', '.jpeg')
])
total = len(image_files)
print(f"=== 全{total}枚の画像を処理します ===")
for idx, image_path in enumerate(image_files, 1):
base_name = image_path.stem
output_path = output_dir / f'{base_name}.glb'
print(f"\n📄 [{idx}/{total}] {image_path.name} を処理中...")
send_image_to_api(image_path, output_path)
print("\n=== 全処理が完了しました ===")
if __name__ == "__main__":
process_all_images()
6.別のコマンドプロンプトでプログラム実行
python環境が整っていれば、仮想環境内でも外でもどちらでも実行できます。
python generates.py
7.app>assets>output_glbに出力
'assets/input_img'の中身がdoor.pngとfireextinguisher.pngだった場合、コマンドプロンプトには以下のように表示されます。
(env) C:\pinokio\api\Hunyuan3D-2.git\app>python generates.py
=== 全2枚の画像を処理します ===
📄 [1/2] door.png を処理中...
--- 処理開始: assets/input_img\door.png ---
→ API送信中 (試行 1/3)...
✅ 成功: assets/output_glb\door.glb に保存(処理時間: 1分 5秒)
📄 [2/2] fireextinguisher.png を処理中...
--- 処理開始: assets/input_img\fireextinguisher.png ---
→ API送信中 (試行 1/3)...
✅ 成功: assets/output_glb\fireextinguisher.glb に保存(処理時間: 1分 18秒)
=== 全処理が完了しました ===
すると以下のような3Dオブジェクトが生成されます。
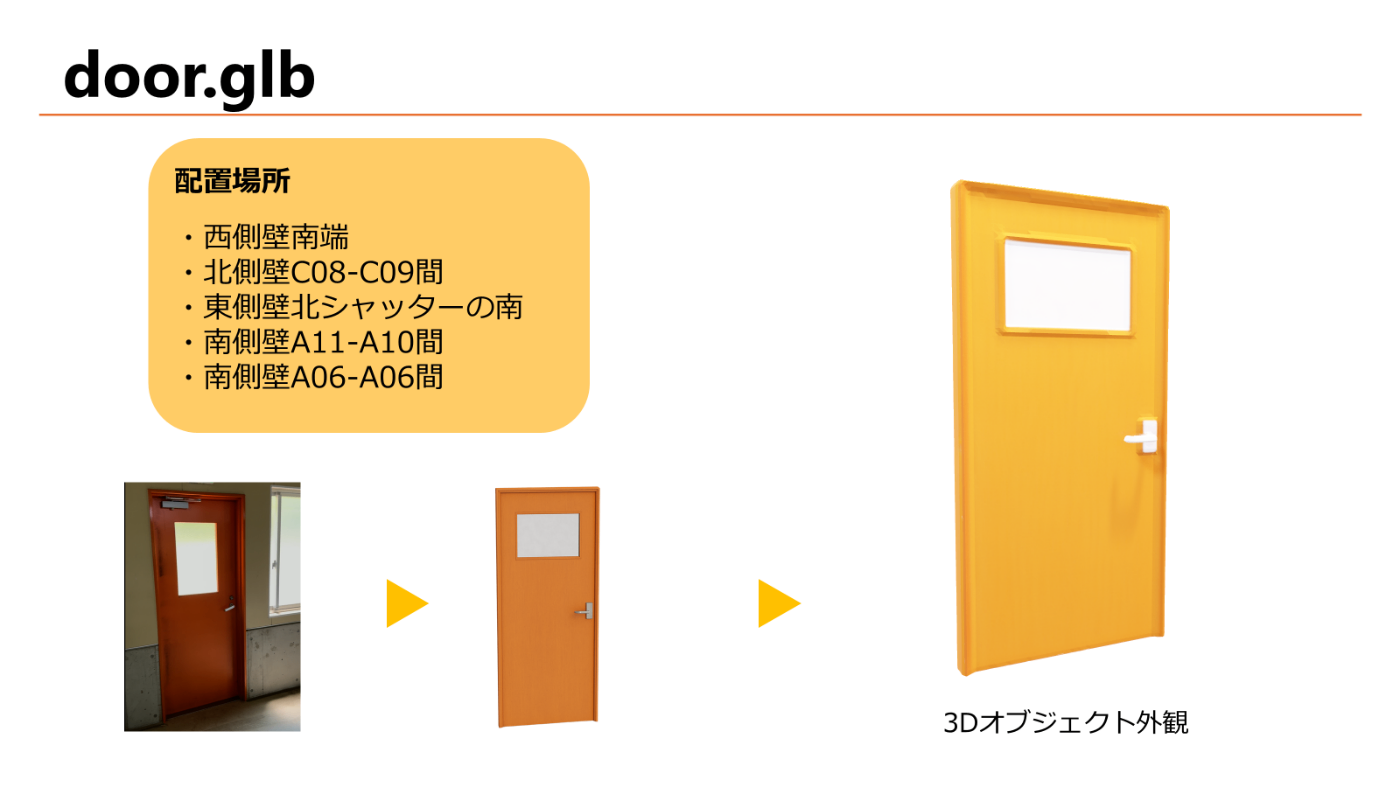 非常口
非常口
 消火器
消火器
 フォークリフト
フォークリフト
今回は計236枚の実写画像と実写動画のスクリーンショットから、84種類の3Dオブジェクトを生成しました。
5.Isaac Simでデジタルツイン構築
続いてLinuxのPCを起動します。
Isaac Simは、高精細で美しい描画と現実的な物理・センサー挙動を備え、ロボットをPC上の仮想空間で検証できるシミュレーターです。
からダウンロードし、Workstation Installationのチュートリアル通りにインストールします。
床や壁は工場の図面をもとに、Isaac Sim内のCreate Meshで作成、その中に生成した3Dオブジェクトを配置しました。壁の窓や質感は、ChatGPTに実写画像を取り込んで扱いやすい画像を出力させ、Materialにして張り込み、再現しました。


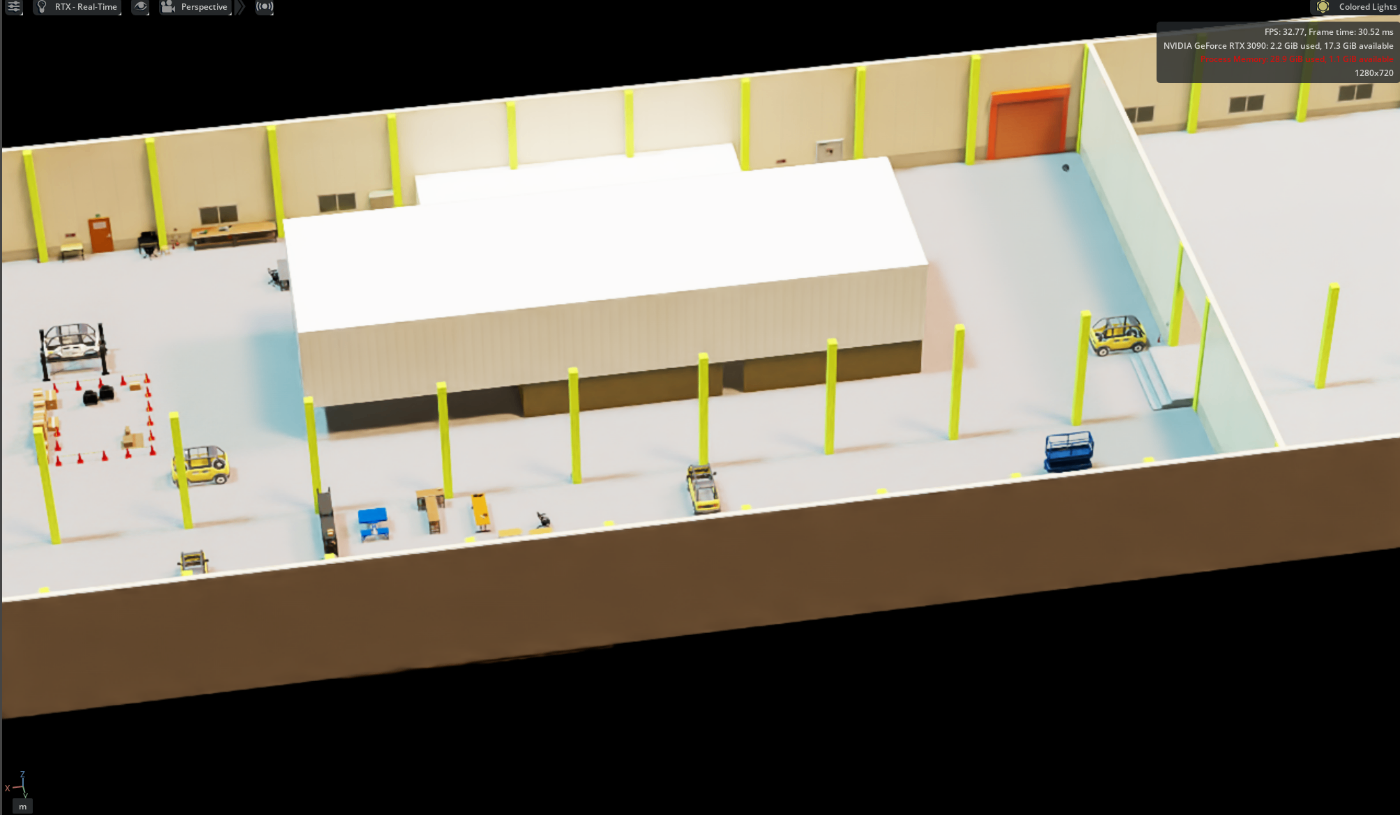


まとめ
本記事では、ChatGPTとHunyuan3D-2を組み合わせて、複数の実写画像からデジタルツイン用の3Dオブジェクトを生成し、Isaac Sim上で配置する方法を紹介しました。
生成AIを活用することで、従来はモデリングに時間がかかっていたパーツを、初心者でも効率よく作成できることを実感しました。一方で、環境構築や依存関係の調整など、実際に試してみないと分からない課題も多くありました。
今回の成果は、「mibotを工場内で自動運転シミュレーションするデジタルツイン構築」への第一歩です。次回はAckermannステアリング車両をIsaac Sim上でナビゲーションする方法をご紹介しようと思います。
初心者の記録ではありますが、同じように「生成AIを使ってデジタルツインを作ってみたい」という方の参考になれば幸いです。

Discussion