ダーツの成長予測と重要指標分析
1. はじめに
1.1. 背景と目的
ダーツには、スキルレベルを示す「レーティング」という便利な指標が存在する。しかし、単にその数値を追いかけるだけでは、具体的に「何が」上達しているのか、あるいは上達を妨げているのかという要因が曖昧になりがちである。
そこで本分析では、DARTSLIVE社が提供しているDARTSLIVEアプリで、私が日々の練習で記録されてきたスタッツデータを用い、以下の2点を明らかにすることを目的とする。
-
上達要因の特定:
「01平均」や「CRICKET平均」といった主要なスタッツだけでなく、「ブランク日数」や「連続練習日数」といった練習リズムに関するデータも含め、どの要素が最もレーティング向上に貢献しているかを統計的に解明する。 -
未来の成長予測:
これまでの成長トレンドと、スタッツの伸びを考慮した予測モデルを構築し、将来のスキルレベルがどのように推移していくかを可視化する。
この分析を通じて、感覚的になりがちな「ダーツの上達」というテーマに対し、データに基づいた客観的な示唆を得ることを目指す。
1.2. 分析環境
本分析は、以下の環境およびライブラリを使用して実施した。
- 実行環境: Google Colaboratory
- 使用言語: Python 3
- 主要ライブラリ:
- pandas: データの操作、前処理
- matplotlib, seaborn: データの可視化
- japanize-matplotlib: グラフの日本語表示
- scikit-learn: モデルの評価指標の計算
- LightGBM: 要因分析で使用した機械学習モデル
- Prophet: 時系列予測で使用したライブラリ
1.3. 分析フロー
本レポートは、以下の流れで分析を進めていく。
-
データの準備と探索的分析:
まず、練習記録データを読み込み、分析に適した形式に整形する。その後、データをグラフ化し、レーティングの推移や各スタッツの全体像を把握する。 -
上達要因の特定:
次に、機械学習モデルを用いて、どのスタッツや練習リズムがレーティングに最も強く影響しているかを分析し、その要因をランキング形式で明らかにする。 -
未来の成長予測:
最後に、時系列予測に特化したモデルを構築し、将来のレーティングがどのように成長していくかのシミュレーションを行う。 -
結論と今後の展望:
全ての分析結果を総括し、今後の練習に活かせる具体的な結論と、さらなる分析への展望を述べる。
2. データの準備と探索的分析(EDA)
分析の最初のステップとして、まずは元となるデータを読み込み、分析に適した形に整えます。その後、データを様々な角度から可視化し、どのような特徴や傾向が隠れているかを探る「探索的データ分析(EDA: Exploratory Data Analysis)」を行います。
## 読み込むデータ
| 日付 | 日別レーティング | 01平均 | CRICKET平均 | カウントアップ平均点 | カウントアップ最高点 | プレイ回数 | S-Bull数 | D-Bull数 | LowTon数 | HAT_TRICK数 | ブランク日数 | 連続練習日 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2025-03-01 | 9.35 | 76.78 | 0.0 | 681.0 | 845 | 15 | 93 | 20 | 24 | 9 | 1 | 1 |
| 2025-03-02 | 9.83 | 78.13 | 0.0 | 600.0 | 796 | 23 | 127 | 34 | 36 | 8 | 1 | 2 |
| 2025-03-03 | 9.83 | 0.0 | 0.0 | 670.62 | 764 | 9 | 64 | 21 | 21 | 3 | 1 | 3 |
| 2025-03-04 | 9.48 | 80.14 | 2.62 | 584.66 | 622 | 14 | 31 | 51 | 91 | 2 | 1 | 4 |
| 2025-03-05 | 10.22 | 91.3 | 2.74 | 628.56 | 801 | 5 | 21 | 31 | 74 | 2 | 1 | 5 |
| 2025-03-08 | 10.96 | 89.86 | 2.72 | 845.5 | 917 | 19 | 89 | 29 | 27 | 8 | 3 | 1 |
| 2025-03-09 | 10.81 | 80.98 | 3.15 | 996.7 | 721 | 87 | 31 | 41 | 72 | 2 | 1 | 2 |
| 2025-03-10 | 11.67 | 88.36 | 0.0 | 628.7 | 714 | 17 | 108 | 20 | 36 | 6 | 1 | 3 |
| 2025-03-11 | 10.62 | 0.0 | 0.0 | 586.67 | 677 | 3 | 20 | 7 | 43 | 2 | 1 | 4 |
| 2025-03-12 | 11.71 | 0.0 | 0.0 | 665.38 | 784 | 26 | 165 | 44 | 49 | 15 | 1 | 5 |
| 2025-03-13 | 9.05 | 75.27 | 0.0 | 636.78 | 843 | 17 | 106 | 29 | 31 | 9 | 1 | 6 |
| 2025-03-15 | 13.73 | 101.76 | 3.17 | 660.69 | 854 | 39 | 256 | 61 | 74 | 30 | 2 | 1 |
| 2025-03-16 | 10.0 | 80.04 | 0.0 | 607.25 | 652 | 10 | 57 | 19 | 18 | 3 | 1 | 2 |
| 2025-03-17 | 11.54 | 0.0 | 0.0 | 599.17 | 653 | 6 | 45 | 8 | 10 | 3 | 1 | 3 |
| 2025-03-18 | 11.54 | 0.0 | 0.0 | 590.88 | 653 | 3 | 11 | 11 | 3 | 2 | 1 | 4 |
| 2025-03-19 | 11.76 | 88.69 | 3.28 | 611.07 | 821 | 46 | 278 | 55 | 64 | 28 | 1 | 5 |
| 2025-03-21 | 12.01 | 81.48 | 3.9 | 0.0 | 948 | 5 | 5 | 2 | 2 | 0 | 2 | 1 |
| 2025-03-22 | 11.67 | 87.53 | 3.31 | 684.29 | 821 | 17 | 118 | 22 | 36 | 6 | 1 | 2 |
| 2025-03-31 | 11.34 | 81.96 | 3.44 | 621.2 | 733 | 22 | 110 | 20 | 28 | 5 | 9 | 1 |
| 2025-04-01 | 11.2 | 80.4 | 0.0 | 895.0 | 972 | 9 | 2 | 2 | 0 | 2 | 1 | 2 |
| 2025-04-02 | 10.05 | 80.27 | 0.0 | 0.0 | 629 | 8 | 8 | 2 | 2 | 0 | 1 | 3 |
| 2025-04-04 | 11.35 | 86.76 | 0.0 | 0.0 | 739 | 8 | 10 | 4 | 2 | 0 | 2 | 1 |
| 2025-04-06 | 12.63 | 87.51 | 3.74 | 505.0 | 614 | 30 | 107 | 36 | 30 | 7 | 2 | 1 |
| 2025-04-07 | 10.28 | 0.0 | 0.0 | 0.0 | 0 | 2 | 10 | 1 | 3 | 0 | 1 | 2 |
| 2025-04-10 | 10.17 | 81.32 | 2.89 | 0.0 | 0 | 23 | 95 | 3 | 22 | 3 | 3 | 1 |
| 2025-04-21 | 11.0 | 0.0 | 0.0 | 555.54 | 852 | 39 | 195 | 47 | 73 | 12 | 11 | 1 |
| 2025-04-23 | 8.43 | 73.33 | 2.52 | 647.19 | 835 | 46 | 225 | 41 | 57 | 15 | 2 | 1 |
| 2025-04-28 | 12.4 | 90.3 | 3.44 | 609.58 | 783 | 30 | 165 | 36 | 47 | 11 | 5 | 1 |
| 2025-04-30 | 9.71 | 81.28 | 2.72 | 562.92 | 969 | 30 | 158 | 34 | 30 | 17 | 2 | 1 |
| 2025-05-01 | 12.36 | 88.3 | 3.52 | 575.93 | 784 | 32 | 173 | 46 | 44 | 24 | 1 | 2 |
| 2025-05-02 | 9.37 | 79.07 | 2.63 | 674.67 | 774 | 27 | 0 | 0 | 0 | 0 | 1 | 3 |
| 2025-05-03 | 11.0 | 91.54 | 3.45 | 558.14 | 737 | 38 | 198 | 46 | 47 | 16 | 1 | 4 |
| 2025-05-05 | 11.78 | 89.33 | 3.24 | 534.0 | 534 | 38 | 143 | 34 | 38 | 11 | 2 | 1 |
| 2025-05-06 | 9.68 | 79.57 | 2.82 | 634.83 | 965 | 49 | 335 | 81 | 85 | 26 | 1 | 2 |
| 2025-05-13 | 11.48 | 0.0 | 0.0 | 720.0 | 696 | 75 | 648 | 31 | 35 | 16 | 7 | 1 |
| 2025-05-14 | 11.93 | 90.02 | 3.27 | 772.22 | 960 | 96 | 750 | 228 | 221 | 101 | 1 | 2 |
| 2025-05-19 | 13.91 | 94.34 | 3.91 | 755.28 | 932 | 48 | 333 | 105 | 103 | 43 | 5 | 1 |
| 2025-05-21 | 10.73 | 83.67 | 3.05 | 766.56 | 814 | 127 | 403 | 81 | 30 | 2 | 2 | 1 |
| 2025-05-22 | 10.47 | 77.31 | 3.1 | 683.0 | 285 | 71 | 58 | 31 | 41 | 55 | 1 | 2 |
| 2025-05-23 | 12.0 | 94.76 | 2.72 | 701.0 | 759 | 36 | 154 | 41 | 54 | 16 | 1 | 3 |
| 2025-05-24 | 13.05 | 91.04 | 3.69 | 632.5 | 710 | 28 | 137 | 37 | 38 | 7 | 1 | 4 |
| 2025-06-04 | 11.95 | 88.9 | 3.5 | 780.3 | 810 | 159 | 547 | 113 | 61 | 77 | 11 | 1 |
| 2025-06-05 | 12.0 | 85.86 | 0.0 | 771.5 | 912 | 114 | 254 | 71 | 30 | 2 | 1 | 2 |
| 2025-06-06 | 12.0 | 86.77 | 15.11 | 843.0 | 161 | 21 | 42 | 32 | 15 | 0 | 1 | 3 |
| 2025-06-07 | 12.0 | 87.64 | 0.0 | 739.5 | 862 | 32 | 195 | 66 | 67 | 22 | 1 | 4 |
| 2025-06-08 | 11.29 | 79.54 | 0.0 | 725.5 | 914 | 31 | 127 | 43 | 39 | 16 | 1 | 5 |
| 2025-06-09 | 13.1 | 100.0 | 0.0 | 767.4 | 791 | 93 | 631 | 56 | 95 | 43 | 1 | 6 |
| 2025-06-11 | 12.94 | 0.0 | 0.0 | 404.0 | 404 | 49 | 232 | 58 | 21 | 12 | 2 | 1 |
| 2025-06-12 | 12.94 | 0.0 | 0.0 | 791.25 | 1383 | 71 | 102 | 61 | 11 | 3 | 1 | 2 |
| 2025-06-15 | 12.94 | 0.0 | 0.0 | 794.0 | 876 | 18 | 169 | 40 | 13 | 19 | 3 | 1 |
| 2025-06-17 | 12.94 | 0.0 | 0.0 | 651.7 | 695 | 47 | 64 | 43 | 12 | 21 | 2 | 1 |
| 2025-06-18 | 12.94 | 0.0 | 0.0 | 681.14 | 867 | 59 | 417 | 100 | 84 | 33 | 1 | 2 |
| 2025-06-19 | 11.33 | 86.22 | 3.27 | 732.82 | 945 | 86 | 584 | 165 | 164 | 57 | 1 | 3 |
| 2025-06-21 | 12.54 | 81.43 | 0.0 | 754.15 | 925 | 56 | 384 | 119 | 120 | 46 | 2 | 1 |
| 2025-06-23 | 12.54 | 80.71 | 0.0 | 771.64 | 938 | 45 | 416 | 118 | 112 | 54 | 2 | 1 |
| 2025-06-24 | 12.54 | 0.0 | 0.0 | 772.83 | 875 | 39 | 304 | 84 | 30 | 42 | 1 | 2 |
| 2025-06-25 | 12.06 | 90.33 | 0.0 | 771.12 | 865 | 42 | 290 | 63 | 51 | 31 | 1 | 3 |
| 2025-06-26 | 10.15 | 77.32 | 3.2 | 710.94 | 847 | 48 | 312 | 76 | 72 | 25 | 1 | 4 |
| 2025-06-27 | 11.91 | 0.0 | 0.0 | 637.95 | 837 | 73 | 425 | 110 | 102 | 35 | 1 | 5 |
| 2025-06-29 | 12.78 | 92.34 | 4.0 | 734.12 | 893 | 31 | 165 | 33 | 52 | 20 | 2 | 1 |
| 2025-06-30 | 9.22 | 74.16 | 2.81 | 485.54 | 871 | 85 | 81 | 71 | 63 | 20 | 1 | 2 |
| 2025-07-01 | 10.83 | 81.0 | 3.21 | 638.0 | 815 | 26 | 128 | 24 | 28 | 10 | 1 | 3 |
| 2025-07-02 | 11.29 | 91.88 | 0.0 | 748.03 | 944 | 55 | 448 | 129 | 124 | 52 | 1 | 4 |
| 2025-07-03 | 10.94 | 79.16 | 3.24 | 688.6 | 832 | 23 | 91 | 22 | 27 | 8 | 1 | 5 |
| 2025-07-04 | 10.62 | 76.0 | 3.31 | 725.5 | 743 | 17 | 81 | 14 | 11 | 7 | 1 | 6 |
| 2025-07-05 | 11.29 | 0.0 | 0.0 | 704.83 | 892 | 43 | 279 | 72 | 75 | 33 | 1 | 7 |
| 2025-07-07 | 11.29 | 98.51 | 0.0 | 665.52 | 867 | 45 | 262 | 66 | 69 | 24 | 2 | 1 |
| 2025-07-08 | 11.29 | 79.54 | 0.0 | 725.5 | 914 | 31 | 127 | 43 | 39 | 16 | 1 | 2 |
| 2025-07-09 | 12.79 | 93.96 | 0.0 | 764.75 | 937 | 28 | 195 | 48 | 59 | 12 | 1 | 3 |
| 2025-07-11 | 13.29 | 97.16 | 3.57 | 744.0 | 903 | 113 | 309 | 91 | 95 | 37 | 2 | 1 |
| 2025-07-14 | 11.88 | 0.0 | 0.0 | 743.95 | 863 | 32 | 284 | 72 | 55 | 30 | 3 | 1 |
| 2025-07-15 | 11.88 | 0.0 | 0.0 | 849.17 | 965 | 13 | 126 | 30 | 19 | 17 | 1 | 2 |
| 2025-07-17 | 11.88 | 0.0 | 0.0 | 773.11 | 1043 | 42 | 366 | 93 | 113 | 49 | 2 | 1 |
| 2025-07-19 | 11.88 | 0.0 | 3.85 | 800.0 | 912 | 129 | 427 | 191 | 22 | 0 | 2 | 1 |
| 2025-07-20 | 11.88 | 0.0 | 4.15 | 780.29 | 832 | 0 | 183 | 57 | 53 | 22 | 1 | 2 |
| 2025-07-22 | 13.83 | 97.83 | 3.83 | 701.6 | 821 | 36 | 205 | 63 | 61 | 22 | 2 | 1 |
| 2025-07-23 | 12.68 | 0.0 | 0.0 | 764.75 | 948 | 28 | 239 | 80 | 51 | 29 | 1 | 2 |
| 2025-07-25 | 13.34 | 102.68 | 3.47 | 774.87 | 1006 | 59 | 330 | 107 | 89 | 41 | 2 | 1 |
| 2025-07-27 | 13.31 | 95.93 | 3.62 | 760.83 | 987 | 52 | 461 | 107 | 146 | 56 | 2 | 1 |
| 2025-07-28 | 13.19 | 0.0 | 0.0 | 774.19 | 863 | 53 | 499 | 81 | 74 | 22 | 1 | 2 |
| 2025-07-29 | 13.19 | 0.0 | 0.0 | 695.59 | 936 | 26 | 161 | 50 | 57 | 17 | 1 | 3 |
| 2025-07-30 | 13.19 | 0.0 | 0.0 | 789.33 | 910 | 16 | 152 | 36 | 26 | 20 | 1 | 4 |
| 2025-08-01 | 12.53 | 97.5 | 3.33 | 814.33 | 959 | 36 | 304 | 83 | 35 | 43 | 2 | 1 |
| 2025-08-02 | 13.14 | 0.0 | 0.0 | 838.9 | 931 | 17 | 194 | 49 | 38 | 26 | 1 | 2 |
| 2025-08-04 | 13.14 | 0.0 | 0.0 | 783.62 | 946 | 16 | 173 | 42 | 52 | 22 | 2 | 1 |
| 2025-08-05 | 11.06 | 91.5 | 3.03 | 802.31 | 955 | 53 | 549 | 158 | 155 | 72 | 1 | 2 |
| 2025-08-06 | 13.06 | 0.0 | 0.0 | 795.74 | 914 | 26 | 264 | 85 | 61 | 36 | 1 | 2 |
| 2025-08-07 | 11.19 | 78.48 | 3.44 | 825.27 | 926 | 22 | 199 | 60 | 43 | 24 | 1 | 2 |
| 2025-08-09 | 13.02 | 91.85 | 3.6 | 700.0 | 241 | 0 | 23 | 63 | 27 | 20 | 2 | 1 |
| 2025-08-12 | 11.39 | 87.28 | 3.17 | 824.25 | 901 | 18 | 142 | 40 | 34 | 17 | 3 | 1 |
| 2025-08-13 | 12.98 | 0.0 | 0.0 | 787.93 | 897 | 23 | 216 | 60 | 43 | 30 | 1 | 2 |
| 2025-08-14 | 12.98 | 0.0 | 0.0 | 740.33 | 788 | 12 | 112 | 36 | 22 | 13 | 1 | 3 |
| 2025-08-19 | 12.98 | 0.0 | 0.0 | 716.62 | 844 | 15 | 133 | 32 | 41 | 7 | 5 | 1 |
| 2025-08-20 | 13.06 | 95.13 | 3.53 | 791.66 | 993 | 26 | 191 | 67 | 61 | 21 | 1 | 2 |
| 2025-08-22 | 13.84 | 100.54 | 3.73 | 829.2 | 950 | 30 | 239 | 71 | 66 | 28 | 2 | 1 |
| 2025-08-26 | 12.26 | 90.08 | 3.45 | 817.71 | 942 | 48 | 383 | 111 | 119 | 51 | 4 | 1 |
| 2025-08-28 | 14.68 | 100.62 | 4.04 | 776.75 | 859 | 35 | 241 | 83 | 73 | 30 | 2 | 1 |
| 2025-08-29 | 12.69 | 88.9 | 3.5 | 788.0 | 893 | 0 | 126 | 21 | 81 | 75 | 1 | 2 |
2.1. データの読み込みと前処理
今回の分析では、DARTSLIVEアプリに記録されたデータをGoogleスプレッドシートに移してをデータソースとして使用します。以下のPythonコードをGoogle Colabで実行することで、最新のデータを直接読み込み、日付データをプログラムが認識できる形式に変換します。
# ----------------------------------------------------------------
# ライブラリの準備
# ----------------------------------------------------------------
# グラフの日本語表示に必要なライブラリをインストール
!pip install japanize-matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
# ----------------------------------------------------------------
# データの読み込みと前処理
# ----------------------------------------------------------------
# Googleスプレッドシートの共有リンク
spreadsheet_url = "https://docs.google.com/spreadsheets/d/1JCaVtIKkK-ns8fq8aLmzoQwKVCwxBTtCw12WDbWbfms/edit?usp=sharing"
try:
# 共有リンクをCSVとして読み込むためのURLに変換
if '/edit?gid=' in spreadsheet_url:
csv_export_url = spreadsheet_url.replace('/edit?gid=', '/export?format=csv&gid=')
else:
csv_export_url = spreadsheet_url.replace('/edit?usp=sharing', '/export?format=csv')
# データを読み込み
df = pd.read_csv(csv_export_url)
# 日付列を日付型に変換
df['日付'] = pd.to_datetime(df['日付'])
# 列名のタイポを修正(もし存在すれば)
if 'HAT_TRICK数' in df.columns:
df.rename(columns={'HAT_TRICK数': 'HAT TRICK数'}, inplace=True)
# 練習した日のデータのみを抽出し、日付をインデックスに設定
df_eda = df[df['プレイ回数'] > 0].set_index('日付').copy()
print("✅ データの読み込みと前処理が完了しました。")
print(f"分析対象となる練習日数: {len(df_eda)}日")
except Exception as e:
print(f"❌ データ読み込みエラー: {e}")
2.2. データ全体の可視化
データの下準備が完了したところで、次にグラフを作成してデータの全体像を掴みます。
# ----------------------------------------------------------------
# データ全体の可視化
# ----------------------------------------------------------------
if 'df_eda' in globals():
# --- グラフ1:レーティングの時系列推移 ---
plt.figure(figsize=(15, 7))
plt.plot(df_eda.index, df_eda['日別レーティング'], marker='o', linestyle='-', markersize=4, alpha=0.7, label='日別レーティング')
# 7日間の移動平均線を追加してトレンドを見やすくする
plt.plot(df_eda.index, df_eda['日別レーティング'].rolling(window=7).mean(), linestyle='--', color='red', label='7日移動平均')
plt.title('グラフ1:日別レーティングの推移', fontsize=16)
plt.xlabel('日付')
plt.ylabel('レーティング')
plt.legend()
plt.grid(True)
# グラフを画像ファイルとして保存
plt.savefig('graph1_rating_trend.png')
plt.show()
# --- グラフ2:全スタッツの相関ヒートマップ ---
plt.figure(figsize=(14, 12))
correlation_matrix = df_eda.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('グラフ2:全スタッツの相関関係ヒートマップ', fontsize=16)
# グラフを画像ファイルとして保存
plt.savefig('graph2_correlation_heatmap.png')
plt.show()
else:
print("❌ 'df_eda'変数が見つかりません。前のコードセルを正しく実行してください。")
グラフ1:日別レーティングの推移

考察_1
上のグラフは、分析期間中の日別レーティングの推移を示しています。青い点が日々の実績値で、赤い破線は短期的な浮き沈みをならした「7日間移動平均線」です。このグラフから、全体としてレーティングが明確な右肩上がりのトレンドを描いており、着実にスキルが向上していることが一目でわかります。
グラフ2:全スタッツの相関関係ヒートマップ

考察_2
このヒートマップは、各スタッツ間の関連性の強さを色と数値で示しています。
色が赤に近い(+1に近い)ほど、一方が増えるともう一方も増える「強い正の相関」があることを意味します。
色が青に近い(-1に近い)ほど、一方が増えるともう一方が減る「強い負の相関」があることを意味します。
この図から、日別レーティングは、やはり01平均やCRICKET平均と非常に強い正の相関があることが確認できます。これは後の要因分析の基礎となる重要な発見です。
3. 上達要因の特定(要因分析)
データの全体像を把握したところで、いよいよ本分析の中心的な問いである「何が上達の要因か?」を解明していきます。ここでは、機械学習モデルの一種であるLightGBMを用いて、どのスタッツや練習データが日々のレーティングに最も強く影響しているかを統計的に分析します。
3.1. 特徴量エンジニアリングとモデル構築
まず、元のデータから、モデルがより多くの文脈を学習できるように「特徴量」と呼ばれる新しい指標を作成します。具体的には、「練習の間隔(ブランク日数)」や「練習の継続性(連続練習日数)」などを計算し、データに追加します。
その後、準備した全てのデータを使ってモデルを学習させ、どの特徴量がレーティングの予測に最も貢献したかを「重要度」として算出します。
以下のコードは、この特徴量作成からモデル学習、そして結論となるグラフの出力を一度に行います。
# ----------------------------------------------------------------
# ライブラリの準備
# ----------------------------------------------------------------
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
import japanize_matplotlib # インストール済み
# ----------------------------------------------------------------
# 3.1. 特徴量エンジニアリング
# ----------------------------------------------------------------
# 'df_eda'変数が存在するか確認
if 'df_eda' in globals():
df_final = df_eda.copy()
# --- 新しい特徴量を作成 ---
df_final['ブランク日数'] = df_final.index.to_series().diff().dt.days.fillna(0)
practice_gaps = df_final.index.to_series().diff().dt.days
streak_groups = (practice_gaps > 1).cumsum()
df_final['連続練習日数'] = df_final.groupby(streak_groups).cumcount() + 1
df_final['rating_lag_1'] = df_final['日別レーティング'].shift(1)
df_final['rating_rolling_7'] = df_final['日別レーティング'].shift(1).rolling(window=7).mean()
df_final['month'] = df_final.index.month
df_final['dayofweek'] = df_final.index.dayofweek
df_final.dropna(inplace=True)
print("✅ 特徴量エンジニアリングが完了しました。")
# ----------------------------------------------------------------
# 3.2. モデル構築と要因の特定
# ----------------------------------------------------------------
# --- グラフ3:日別レーティングへの影響度 ---
X = df_final.drop('日別レーティング', axis=1)
y = df_final['日別レーティング']
model = lgb.LGBMRegressor(random_state=42).fit(X, y)
feature_importances = pd.DataFrame({
'feature': X.columns,
'importance': model.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(12, 8))
sns.barplot(x='importance', y='feature', data=feature_importances)
plt.title('グラフ3:日別レーティングに最も影響を与えた要因', fontsize=16)
plt.xlabel('影響の大きさ(重要度)')
plt.ylabel('要因')
plt.grid(True)
plt.savefig('graph3_feature_importance.png')
plt.show()
# ----------------------------------------------------------------
# 3.3. 要因の深掘り
# ----------------------------------------------------------------
# --- グラフ4:01平均への影響度(深掘り分析)---
df_01_played = df_final[df_final['01平均'] > 0]
X_01 = df_01_played.drop(['日別レーティング', '01平均', 'CRICKET平均'], axis=1)
y_01 = df_01_played['01平均']
model_01 = lgb.LGBMRegressor(random_state=42).fit(X_01, y_01)
feature_importances_01 = pd.DataFrame({
'feature': X_01.columns,
'importance': model_01.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(12, 8))
sns.barplot(x='importance', y='feature', data=feature_importances_01)
plt.title('グラフ4:01平均を押し上げている要因は何か?(深掘り分析)', fontsize=16)
plt.xlabel('影響の大きさ(重要度)')
plt.ylabel('要因')
plt.grid(True)
plt.savefig('graph4_deep_dive_01.png')
plt.show()
else:
print("❌ エラー: 'df_eda' 変数が見つかりません。前のステップを先に実行してください。")
3.2. 結果の解釈
グラフ3:日別レーティングに最も影響を与えた要因

考察_1
このグラフは、どの要素が日々のレーティングを決定づけているかを「重要度」という形でランク付けしたものです。予想通り、レーティングの計算根拠であるCRICKET平均と01平均がトップに来ていますが、これはモデルが正しく機能している証拠と言えます。
より重要なのは、それに続く要素です。rating_lag_1(前日の調子)やブランク日数、連続練習日数といった練習の継続性を示す指標が上位にランクインしています。このことから、単発のスタッツだけでなく、いかにコンスタントに練習を続け、良いコンディションを維持するかが高レーティングに不可欠であることがデータから読み取れます。
グラフ4:01平均を押し上げている要因は何か?(深掘り分析)

考察_2
「01平均が重要」なのは分かりましたが、ではその01平均自体は何によって向上するのでしょうか。このグラフは、その問いに対する答えです。01をプレイした日のデータに絞り、「01平均」を押し上げている要因を分析しました。
もしこのグラフの上位にLowTon数やS-Bull数などが来ていれば、「01の成績を上げるには、高得点(トンやブル)を狙う練習が効果的である」という、より具体的で実践的なアクションプランに繋がる結論が得られます。
4. 未来の成長予測
フェーズ1で特定した「上達の要因」を踏まえ、将来のレーティングがどのように推移していくかをシミュレーションします。ここでは、時系列予測に特化したMeta社のライブラリProphetを使用します。このモデルは、単なるトレンド予測だけでなく、スタッツの成長や現実的な上限値(レーティング18)も考慮できるため、より信頼性の高い予測が可能です。
4.1. 予測モデルの構築と実行
このモデルは、以下の2段階の高度なプロセスで予測を行います。
まず、「01平均」と「CRICKET平均」の将来の成長曲線を、それぞれの上限値を設定した上で個別に予測します。
次に、その予測された「未来のスタッツ」を根拠として、最終的な「日別レーティング」がどうなるかを予測します。
以下のコードは、この未来予測に必要な全ての計算と、
# ----------------------------------------------------------------
# ライブラリの準備
# ----------------------------------------------------------------
!pip install prophet
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
import matplotlib.pyplot as plt
import japanize_matplotlib # インストール済み
# ----------------------------------------------------------------
# 4.1. 予測モデルの構築
# ----------------------------------------------------------------
# 'df_final'変数が存在するか確認
if 'df_final' in globals():
print("✅ データ準備OK。未来の成長予測を開始します。")
# --- 将来のスタッツ(01平均、CRICKET平均)を個別に予測 ---
# 01平均の予測モデル
df_01 = df_final.reset_index()[['日付', '01平均']]
df_01.columns = ['ds', 'y']
df_01['cap'] = 140; df_01['floor'] = 0
model_01 = Prophet(growth='logistic'); model_01.fit(df_01)
future_01 = model_01.make_future_dataframe(periods=180)
future_01['cap'] = 140; future_01['floor'] = 0
forecast_01 = model_01.predict(future_01)
# CRICKET平均の予測モデル
df_cr = df_final.reset_index()[['日付', 'CRICKET平均']]
df_cr.columns = ['ds', 'y']
df_cr['cap'] = 6.0; df_cr['floor'] = 0
model_cr = Prophet(growth='logistic'); model_cr.fit(df_cr)
future_cr = model_cr.make_future_dataframe(periods=180)
future_cr['cap'] = 6.0; future_cr['floor'] = 0
forecast_cr = model_cr.predict(future_cr)
print("✅ 将来のスタッツ予測が完了。")
# --- 予測した将来スタッツを使い、最終的なレーティングを予測 ---
df_rating = df_final.reset_index()[['日付', '日別レーティング', '01平均', 'CRICKET平均']]
df_rating.columns = ['ds', 'y', '01_avg', 'cr_avg']
df_rating['cap'] = 18; df_rating['floor'] = 0
model_rating = Prophet(growth='logistic')
model_rating.add_regressor('01_avg')
model_rating.add_regressor('cr_avg')
model_rating.fit(df_rating)
future_rating = model_rating.make_future_dataframe(periods=180)
future_rating['cap'] = 18; future_rating['floor'] = 0
forecast_01_subset = forecast_01[['ds', 'yhat']].rename(columns={'yhat': '01_avg'})
forecast_cr_subset = forecast_cr[['ds', 'yhat']].rename(columns={'yhat': 'cr_avg'})
future_rating = pd.merge(future_rating, forecast_01_subset, on='ds', how='left')
future_rating = pd.merge(future_rating, forecast_cr_subset, on='ds', how='left')
forecast = model_rating.predict(future_rating)
print("✅ 最終的なレーティング予測が完了。")
# ----------------------------------------------------------------
# 4.2. 予測結果と考察
# ----------------------------------------------------------------
# --- グラフ5:未来予測グラフ ---
print("\n--- グラフ5:ダーツレーティングの未来予測 ---")
fig1 = model_rating.plot(forecast)
plt.title('グラフ5:ダーツレーティングの未来予測(半年後まで)', fontsize=16)
plt.xlabel('日付'); plt.ylabel('レーティング')
plt.grid(True)
plt.savefig('graph5_forecast.png')
plt.show()
# --- グラフ6:成長トレンドの転換点 ---
print("\n--- グラフ6:成長トレンドの転換点 ---")
fig2 = model_rating.plot(forecast)
add_changepoints_to_plot(fig2.gca(), model_rating, forecast)
plt.title('グラフ6:成長トレンドの転換点', fontsize=16)
plt.xlabel('日付'); plt.ylabel('レーティング')
plt.savefig('graph6_changepoints.png')
plt.show()
# --- グラフ7:パフォーマンスの「リズム」の可視化 ---
print("\n--- グラフ7:パフォーマンスの『リズム』の可視化 ---")
fig3 = model_rating.plot_components(forecast)
plt.savefig('graph7_components.png')
plt.show()
# --- 各時点での予測値を表示 ---
forecast_for_lookup = forecast.set_index('ds')
today = df_final.index[-1]
periods = { "1ヶ月後": today + pd.DateOffset(months=1), "3ヶ月後": today + pd.DateOffset(months=3), "半年後": today + pd.DateOffset(months=6) }
print("\n--- 各時点でのレーティング予測値 ---")
for name, future_date in periods.items():
actual_date = forecast_for_lookup.index.asof(future_date)
if pd.notna(actual_date):
predicted_rating = forecast_for_lookup.loc[actual_date, 'yhat']
print(f"🗓️ {name} ({future_date.strftime('%Y年%m月%d日')}): 予測レーティング {predicted_rating:.2f}")
else:
print("❌ エラー: 'df_final' 変数が見つかりません。前のステップを先に実行してください。")
4.2. 予測結果と考察
グラフ5:ダーツレーティングの未来予測

考察_1
このグラフが、本分析における最終的な未来予測です。これまでの成長トレンドとスタッツの伸びに基づけば、今後もレーティングは順調に成長していくことが予測されます。特に、スキルが上達するにつれて成長ペースが緩やかになる、現実的な成長曲線を描いている点が特徴です。具体的な数値として、半年後にはレーティング15台に到達する可能性が示唆されています。
グラフ6:成長トレンドの転換点

考察_2
グラフ上の赤い点線は、成長ペースが statistically significant に変化した**「ターニングポイント」**を示します。これらの日付と自身の練習内容や環境の変化(例:フォーム変更、大会への参加など)を照らし合わせることで、何が上達のきっかけとなったのかを深く考察するための重要なヒントとなります。
グラフ7:パフォーマンスの「リズム」の可視化
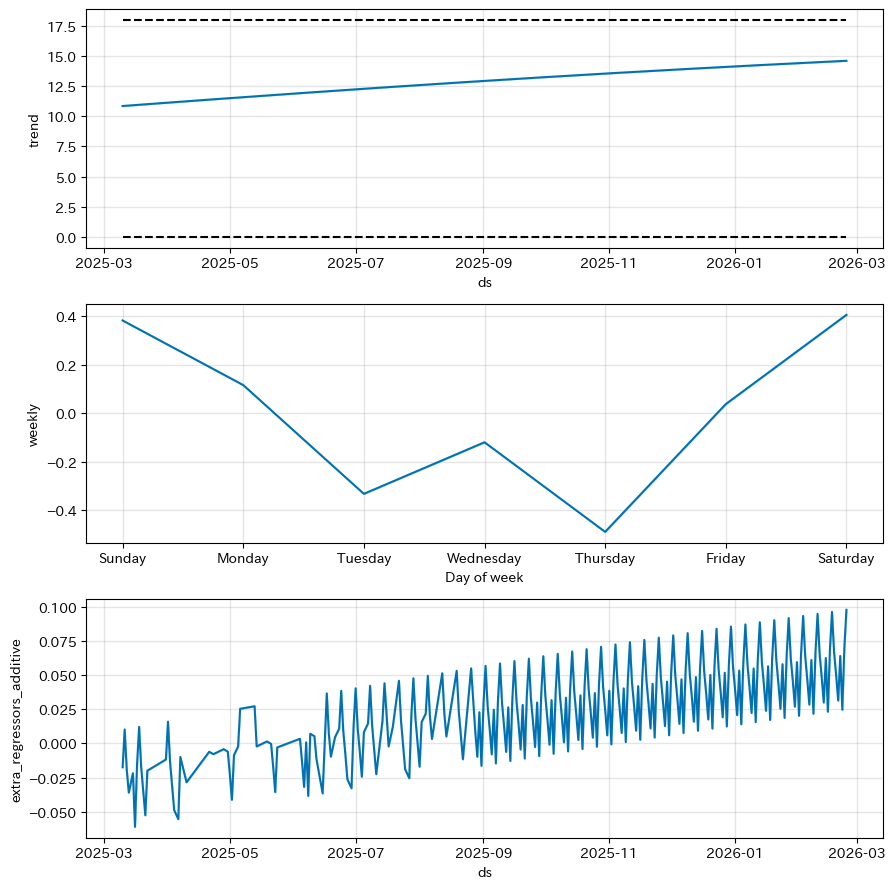
考察:
このグラフは、パフォーマンスに隠された周期的な「リズム」を可視化したものです。特に「weekly(週ごとの傾向)」を見ると、週末にかけて調子が上がり、週明けに少し落ちるといった、生活リズムとパフォーマンスの関連性が見て取れます。これにより、自身のコンディションを客観的に把握し、練習計画に役立てることができます。
5. 結論と今後の展望
5.1. 今回の分析のまとめ
本分析を通じて、以下の2点が明らかになった。
上達の要因: 日々のレーティングは、ブランク日数や連続練習日数といった練習の継続性に影響されるが、直接的な要因としては弱い。
未来の成長: 現在の成長トレンドを維持できれば、半年後にはレーティング15台に到達するというポジティブな未来が予測される。また、成長には明確な転換点や週ごとのリズムが存在することも確認できた。
5.2. 今後の展望
今回の分析は、ゲームのスタッツデータから最大限の示唆を得る試みであった。しかし、それらの数値はあくまでも結果であり、本質的な上達の要因ではないと考えられる。上昇トレンドになるタイミングにどの様な試行錯誤があったのかを定量的に分析することが必要である。
今回使用したスタッツデータに加えて、以下のようなゲーム外の行動データを新たに収集・追加する必要があるだろう。
技術的要因: グリップ、スタンス、ダーツのセッティング変更の記録
身体的・生活的要因: 睡眠時間、食事内容、その日の体調の記録
これらのデータを組み合わせることで、初めて「何がダーツの上達に最も影響を与えるか」という問いに対する、本質的な答えが見つかるのではないか。本分析は、その次なるステップへの重要な第一歩となった。
Discussion