DifyをセルフホストしてローカルLLMと組み合わせてみる
Difyを触る前の感想
今年の夏ぐらいに名前を聞くようになったツールで、いわゆるローコード/ノーコードでワークフローを作成できるらしい。
画像生成で遊んでいたとき、最初はプロンプトに文字を打ち込んで画像が出せることに喜んでいたけど慣れてくると段々自動化したくなり、ローカルで動かせてワークフローを作れるComfyUIにハマっていった経験がある。
そんなわけで、テキスト方面も今まではチャットで毎回単発でタスクをお願いするので満足していたが、今後はもっと自動化したくなってくるはず。コードを書けばまあ何でもできるけど、UI不要でワークフロー的な逐次処理だけで可能なことであれば自分で書くよりこの手のノーコードツールを使った方が80点のものを短時間で作れる。それがComfyUIのときに分かった。
あとは、エンジニアでなくてもエンジニア的な思考をできる人は一定いるので、そういう人たちがチャットUIの次のレベルとしてワークフローツールを使うことでLLMを使った自動化をエンジニアの助力無しに作る日が近いだろうという予想からDifyに興味が出た。
Difyを使った後の感想
Zennのスクラップで作業ログを書くと下にかなり長くなってしまい、最終的な感想までたどり着きにくくなるのでスレッド形式であることを生かして最初に感想スペースを用意してみる試み。
TODO: 一通り触った後に書く
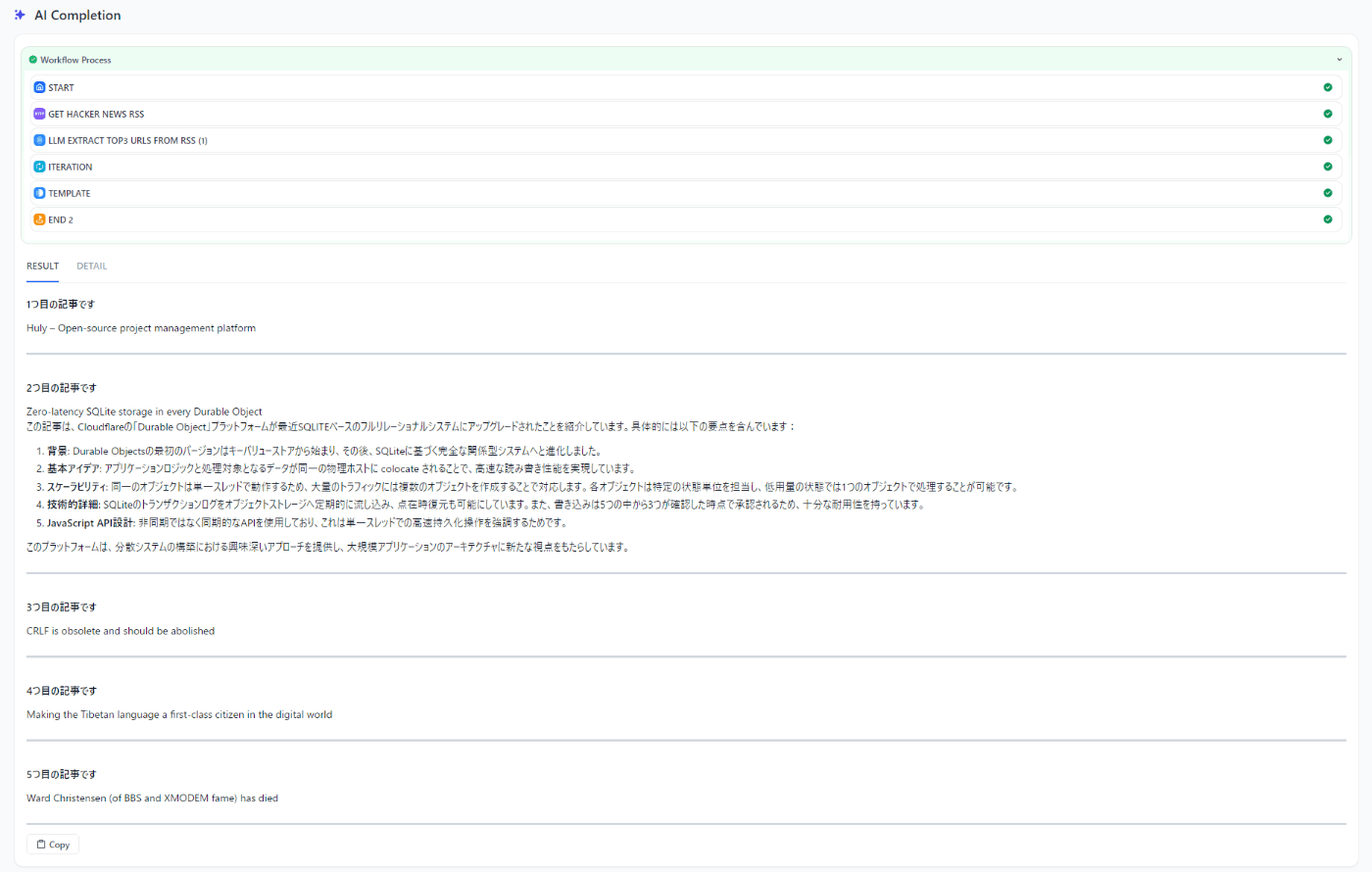
ホスティングされているdify.aiでRSSを日本語訳するワークフローを作る
まずはDifyで何ができるのかを体験してみたいので、ローカル要素は一切なしで dify.ai の無料プランで試してみる。
新しいツールを試す際、チュートリアルではなく自分のオリジナルアイディアで試してみないと本質に迫れないという持論があるので、Difyのテンプレートは使わずに自分で組んでみる。
お題は前からやってみたかった「Hacker NewsのRSSから記事を日本語で要約」
これを作るために必要な要素
- Hacker NewsのRSSを取得
- RSSから記事本文のURLを配列で取得
- 記事URLにアクセス、本文の英文を抽出
- LLMに渡して「日本語で要約してください」と依頼する
- これをループさせ、例えばSlackなどに投下する
ここで3分クッキングになるが、やってみたら何とコードを一切書かずにできてしまった。
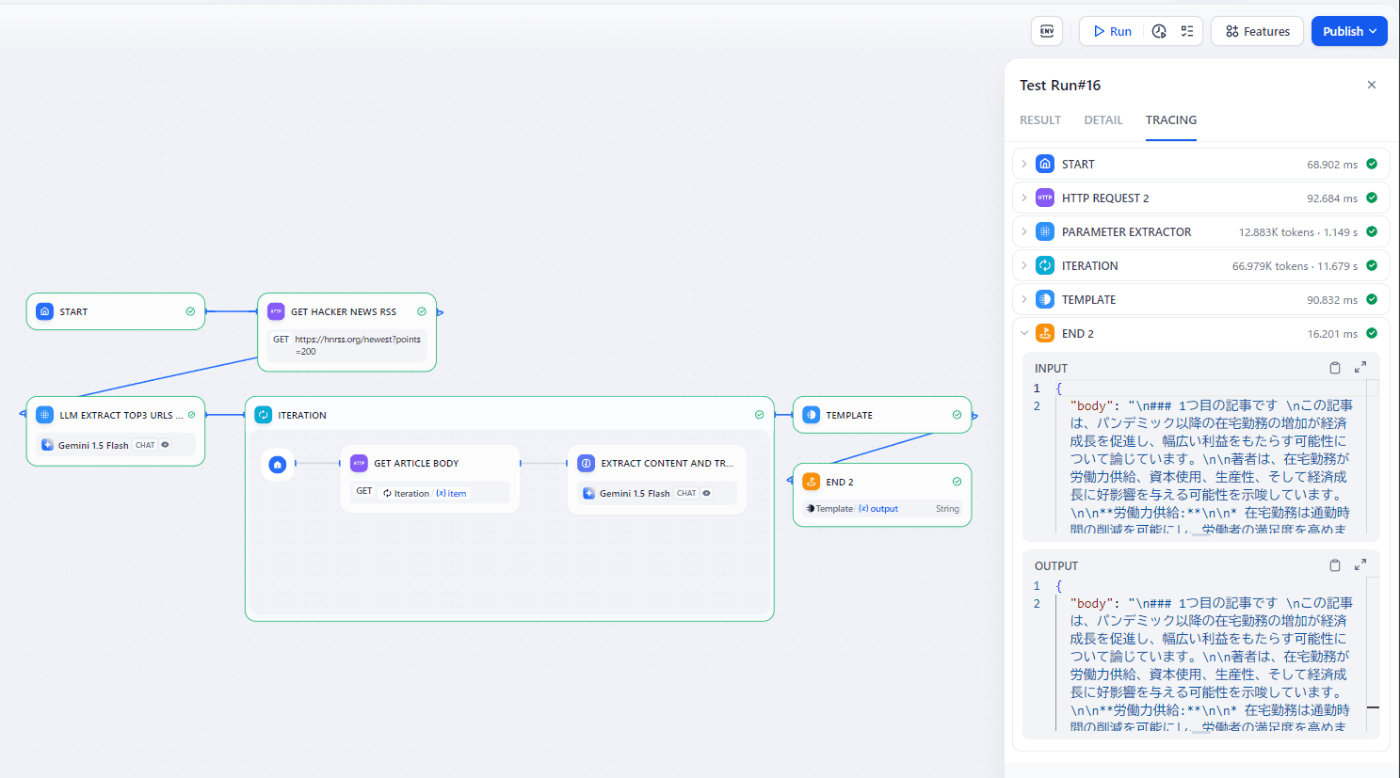
何をやってるか
- HTTP Requestで https://hnrss.org/newest?points=200 からRSS(XML)を取得
- 複数の記事をループで処理したいので、Parameter ExtractorでRSSからurlを抽出して配列にする
- PythonでXMLをパースする代わりにGeminiに「以下のXMLからニュース記事のlinkタグを全て抽出し、最初の3件のみ配列にしてください。example: ["http://...", "http://..."]」と依頼
- Extract Parametersを
news_urls: Array[String]として、後で使えるようにする
- Iterationでループを回す
- HTTP Requestで記事のHTMLを取得
- Geminiに「以下のHTMLから本文を抜き出し、日本語で要約してください」と依頼
- IterationのoutputはArray[String]なので、最後にTemplateでjinja2の
{% for item in outputs %}でループを回して展開 - END
分かってる問題点
- RSSからurlを配列で抽出するのにわざわざGeminiを使っているのでそこだけで1秒もかかる
- 生HTMLをGeminiにそのまま食わせているのでトークンの消費数が多い
- Geminiなら並列にリクエストして問題ないから、ループで回している部分をもし並列化できればもっと早く終わる
というように無駄だらけだが動く。とりあえず動く。
多分これが重要で、エンジニアがコードを1行を書かずとも配列とかJSONとかjinja2の記法をちょっと知ってればこの程度は作れてしまう。
GitHub ModelsをDifyから使ってみる -> 断念
自分はGitHub Modelのプレビューのwaitlistに登録済みで使うことができるのでDifyから使えるか試してみた。

こういう感じでOpenAI互換のモデルとして登録はできた。API endpoint URLは当然として、Model NameもGitHub Models側で表示されているものと一致している必要がある。
どうやらモデル登録のフォームでsaveを押したときに実際にリクエストを送ってそれが使えるかどうか調べているっぽい。何かがミスっている場合でもエラーが出ないのは不親切。
モデルの登録ができたらGeminiと差し替えることはできるのだが、こういうエラーになってしまった
[openai_api_compatible] Error: API request failed with status code 413: {"error":{"code":"tokens_limit_reached","message":"Request body too large for meta-llama-3.1-405b-instruct model. Max size: 8000 tokens.","details":null}}
GitHub Modelsのページではinput 131k inputと書いてあったのに・・・GitHub Modelsのお試し用チャット画面でも4096トークンがMAXだったので現状のGitHub Modelsの制約っぽい。
うーむ、その程度のコンテキスト長では全然使えないんだよな。残念
コミュニティ版のDifyをローカルでセルフホストする
docker-composeで建てられるらしい。
使うdocker-composeはこれ
最初に羅列されている環境変数を見ると、postgres, redisは基本として、celeryというタスクキュー、weaviateというベクトルDBも一緒に立ち上げるっぽい。
後はオブジェクトストレージはデフォルトはローカルファイルだが、S3にも対応しているらしくminioの文字も見えた。実際にAWSにホスティングする際にはS3に逃がしたいのでこれは嬉しい。
ドキュメント通りに cp .env.example .env で設定ファイルを用意。一応 SECRET_KEY だけはコメントに書かれているように openssl rand -base64 42で生成した独自キーに差し替えるが、それ以外はいったんデフォルトのままでいく。
普通に立ち上がったのでDifyに入るが、 http://localhost/install にアクセスせよということらしい。nginxが80と443を受けているのでそれで飛ばしてるのか。
ローカルで動かしてるので適当にメルアドとパスワードを設定して管理アカウント作成。
次にログイン画面に飛ばされるので再び入力するとDifyのUIが開いた

ローカルでDifyが立ったのでクラウド版で作成したワークフローを再現したいが、 DSLファイルをインポート という気になる文字を見つけた。インポートがあるってことはエクスポートがあるはず。
まあまあ分かりにくいが、左上のワークフロー名をクリックしたときのメニューからエクスポートできて、yamlをダウンロードできる
あんな10パーツにも満たない単純なワークフローだったがyamlにすると400近くもあったのでここには貼らないが、yamlでエクスポートできるということはやろうと思えばgit管理もできそう。
yamlをインポートしたら当たり前だがクラウド版のワークフローが再現できた。
GeminiのトークンをローカルのDifyにもセットして実行してみたら普通に動いた。クラウド版とローカルで差が全くないということなので結構すごい。まだシンプルなワークフローなので特に問題がないだけかもしれないけど。
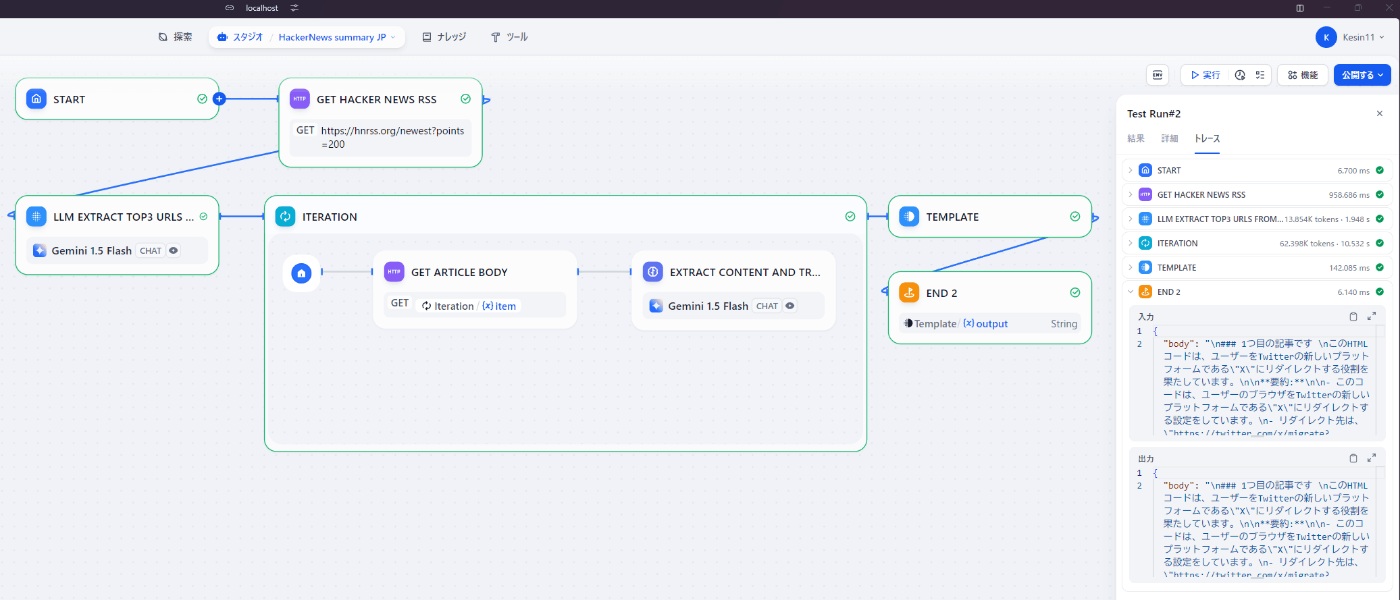
DifyはAPIでワークフローを実行することも簡単にできるらしいのでこれも試してみる。
APIアクセス というそれっぽい機能がサイドバーに存在するが、それはドキュメントのリンクしか出てこない。まずAPIキーが必要だが、それはなぜか 監視 機能の中にある。
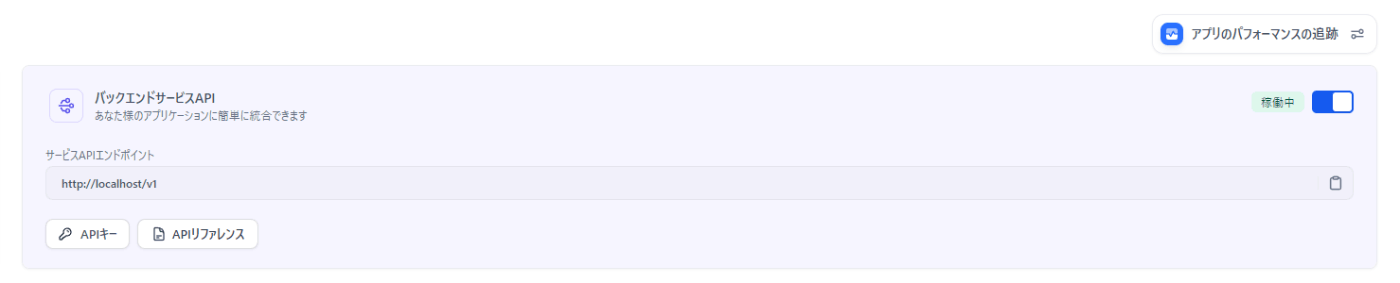
ここでAPIキーを取得し、 APIアクセス のドキュメントの通りにcurlで実行する
curl -X POST 'http://localhost/v1/workflows/run' \
--header 'Authorization: Bearer {api_key}' \
--header 'Content-Type: application/json' \
--data-raw '{
"inputs": {},
"response_mode": "streaming",
"user": "abc-123"
}'
POSTにも関わらずworkflow_id的なパラメータが存在しないのが違和感あるが、これで実際にワークフローを実行できた。ということはAPIキー自体にどのワークフローを実行するかの情報が埋め込まれているはずなので、このAPIキーはユーザーに紐づくものではなくてユーザー x ワークフローごとに発行するものっぽい?
inputに user というパラメータは存在するが、abc-123のような適当な値でも自分のユーザーが実行した扱いになっていたので存在する理由がよくわからなかった。後でログ解析で使えるとか、あるいはどこかに認証機能とかあるのだろうか?
何はともあれAPIでワークフローを実行できることが分かった。
これができるなら生成AIを使ったちょっとした処理とか、リストのデータを食わせてバッチ処理とかそういうのがDifyだけで可能になる。これは便利。
DifyからローカルLLMを利用する
ここからが本番。Difyをローカルで実行したい理由の一つはローカルLLMを使いたいからだった。
自分のWindows環境ではローカルLLMはLMStudioを使っていたのでとりあえずこれでOpenAI互換のサーバーを立てる。
今回はllama 3.2 3BのQ8_0量子化モデルを使ってみます。量子化されて3.4GBほどのサイズらしく、自分の8GBメモリGPUでもちゃんと乗り切ります。
トークンサイズはデフォルトが4096と全然足りないので2倍の8192にしておきます。llama 3.2のモデルだと131,072トークンまでいけるらしいが、MAXにすると8GBに乗り切らないので一旦様子見。

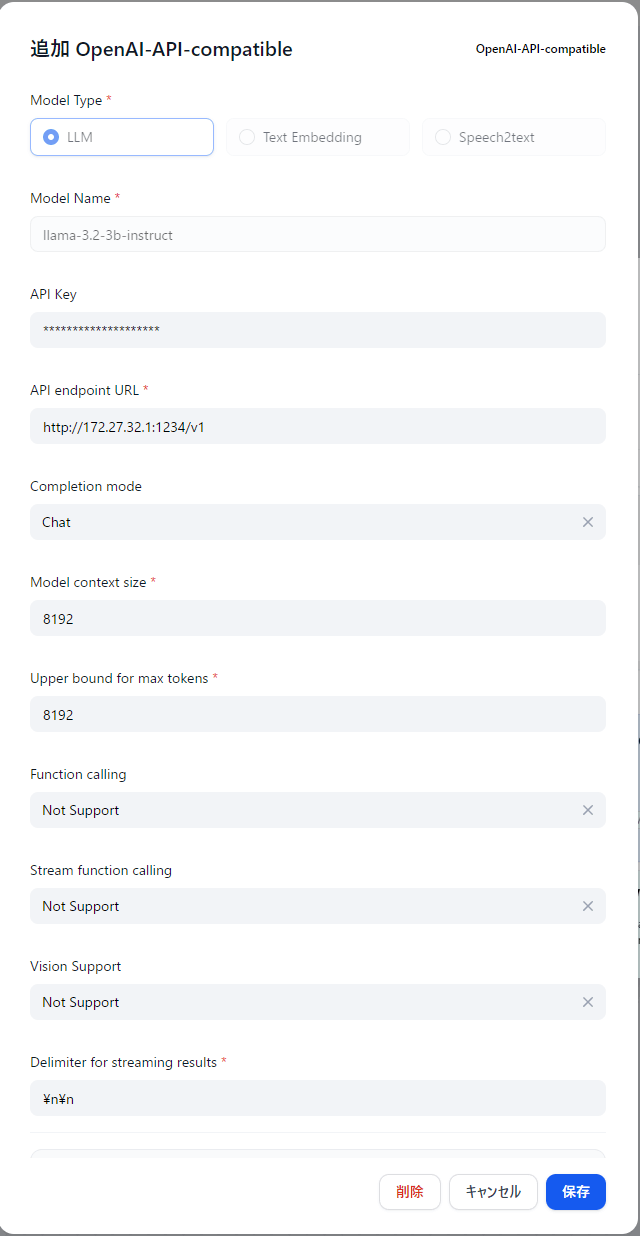
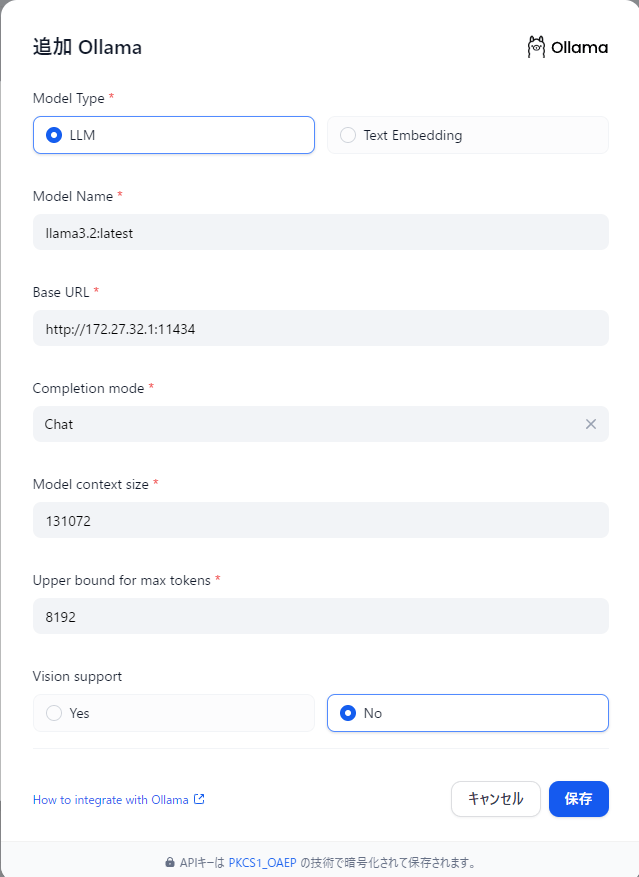
DifyにLMStudio用のプリセットは存在しないのでOpenAI API互換のモデルで追加します。
API endpoint URLは自分の環境だと、Difyを動かしているWSL2環境からWindows上で動かしているLMStudioにアクセスするためにはこのIPでした。多分環境によって異なる。
API Keyは何でもOK、Model nameはLMStudio側と合わせておきます。
Function calling, Stream function calling, Vision SupportはLMStudioではまだ未対応なので全部 Not Support にしておく。
RSSからlinkの抽出をローカルLLMに置き換える
これは試してみたが一筋縄ではいかなそうだったので一旦諦め。Geminiはlinkを抽出してURLの配列だけを返すのをほぼ100%やってくれたが、llama 3.2 3Bでは想定しているJSONの形式で出力してくれなかった。
どうもDifyのExtract Parameterブロックは裏で追加のプロンプトを差し込んだりと色々工夫されているらしい。自分はまだFunction CallingやStructure Outputの概念を理解できていないのと、そもそもOpenAIなどのクラウドのLLMと違ってローカルLLMだと、モデルとLMStudioなどのツールがそれぞれ対応していないことがあるらしい。
これについては奥が深そうなのでまたいずれ調べる。
記事の本文抽出と翻訳・要約をローカルLLMに置き換える
こっちは出力が自然言語なので多少変なものが出力されたとしてもエラーになることはない。
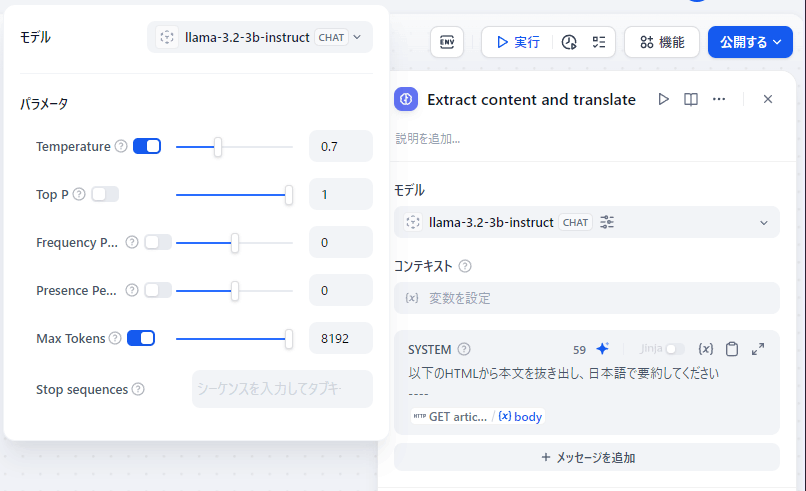
使用するモデルをGeminiから先ほど追加したllama 3.2に置き換える。
Max Tokensもモデル登録時に設定した8192にそろえておく。
これで実行すると記事の生HTMLから本文の抽出と日本語への翻訳、要約が自分のGPU上で動くllama 3.2で行われるが、結果はこんな感じでボロボロだった。
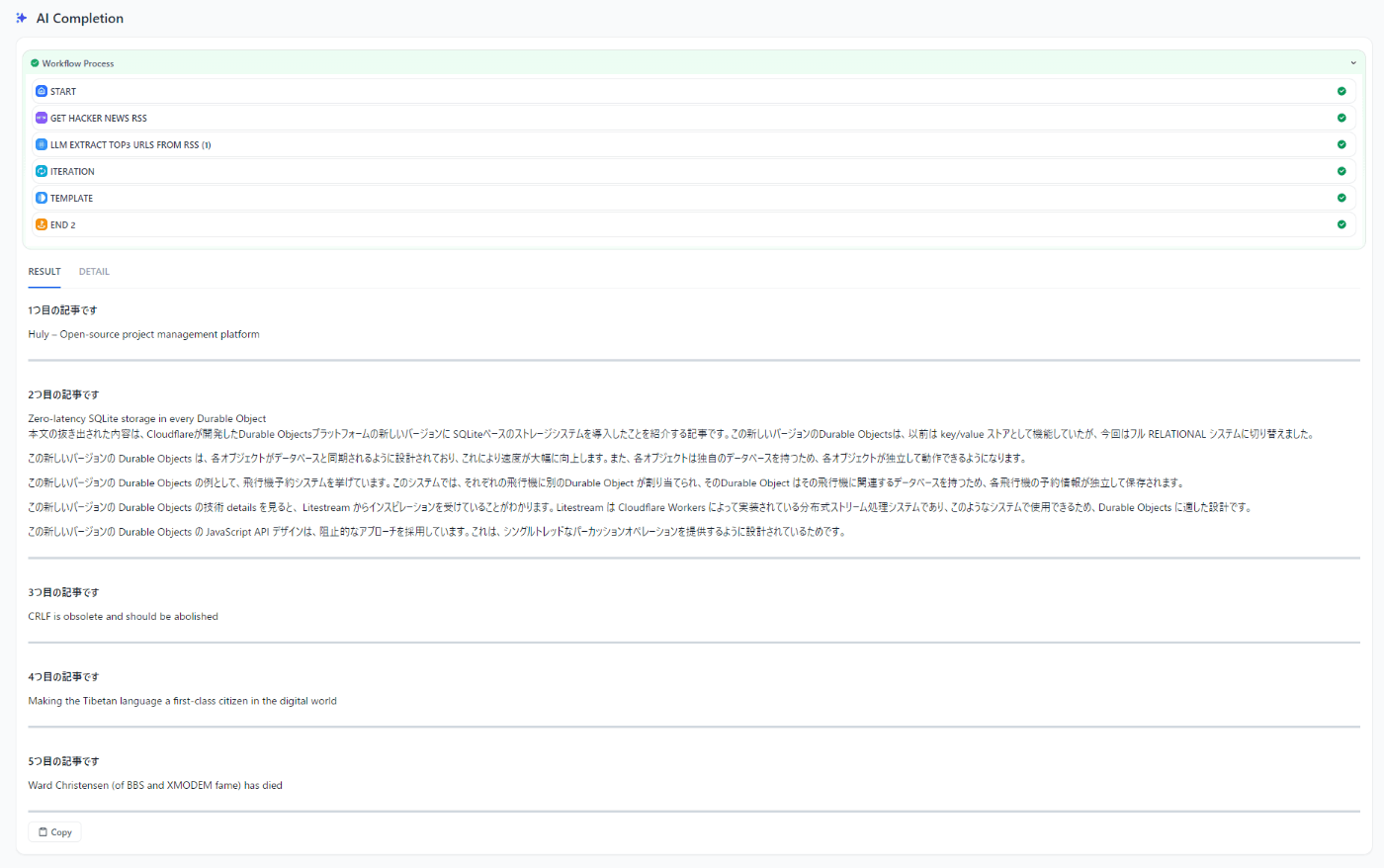
LMStudioのログを見ると、全然ダメだった記事は8192トークンでは足りないというログが出ていた。この記事は22596トークンだったらしいので3倍弱のトークン長が必要ですね・・・
2024-10-14 21:51:00 [ERROR] Trying to keep the first 22596 tokens when context the overflows. However, the model is loaded with context length of only 8192 tokens, which is not enough. Try to load the model with a larger context length, or provide a shorter input. Error Data: n/a, Additional Data: n/a
一応、トークン長の限界ではなくllama 3.2が問題という可能性を検証するため、qwen2.5 7BのQ4_K_M量子化で4.3GBのモデルでも試してみた。こちらでも2番目の記事だけが要約が出力されて、前のllama 3.2の文章とは異なるのでキャッシュではなくちゃんとqwen2.5で推論されている。それでもダメということはやはりトークン長が足りないということなのだろう。
LMStudioでllama 3.2のトークン長を増やしてみる
問題はどうやらトークン長らしいのでGPUのメモリが許す限りトークン長を増やしてみる。
試してみたところ、8192の3倍である24576までは8GBのGPUに何とか乗り切る。
GPT-4oやGeminiのトークン長が100K越えに対して24Kとは何とも厳しい限りだが、自分のGeForce 3060Ti 8GB程度のメモリでも24Kまで扱えるということは、12GBや24GBメモリのもっとハイスペックなグラボを用意すればもっといけるはず。
LMStudioではモデルをGPUとCPUに分割してロード可能で、CPUに割り当てた分はメインメモリに乗るっぽいので推論速度を犠牲にすれば24Kよりもう少し長いトークン長を扱うこともできそうである。
この24Kのトークン長を扱える状態のllama 3.2 3GBで要約させてみると、うまくいった記事はこんな感じ

こちらはLMStudioのログ。長大なので2枚に分ける。
生HTMLをそのまま食わせているが、前半はほぼ本文のテキスト。

後半はこのページに埋め込まれているっぽいjs。これもそのままLLMに食わせている。

実際のところ、HTMLのタグやjsをLLMにそのまま食わせるのは無駄すぎる。
webサイトから本文を抽出するのはそれ自体がちょっとしたタスクだが、LLMが存在しなかった時代からのスクレイピング界隈の長年の蓄積があるのでPythonのライブラリなどで多分何かしらあるでしょう。
GPT-4oやGeminiであればそのような多分そういった工夫も不要で丸投げできるだろうが、このあたりの前処理によって渡すトークン長を削減するというのがローカルLLMを使う上で現状必要なエンジニアリングである気がする。
LMStudioの代わりにollamaでローカルLLMを動かしてみる
ollamaのセットアップ
LMStudioはモデルを事前にロードしておかないとDifyから使えないが、ollamaはリクエスト時にモデルを動的にロードしてくれるのでAPI経由で実行する場合はollamaの方が便利。
自分のWindows環境ではLMStudioと同様にDifyを動かしているdocker -> Windowsで動かしているollamaへネットワーク的にアクセス可能にするために OLLAMA_HOST=0.0.0.0 を設定する必要がある。macやlinuxであればexportするだけだが、windows版はスタンドアロンのアプリとして自動で起動するのでちょっと面倒だった。
// powershell
PS C:\Users\Kesin> curl http://127.0.0.1:11434/api/tags
// bash(WSL2)
// 172.27.31.1は自分の環境でのIPなのでおそらく人によって異なる
$ curl 172.27.32.1:11434/v1/models
両方からアクセスできることを確認できればOK。
モデルはとりあえず ollama run llama3.2:latest あたりにしておく。
PS C:\Users\Kesin> ollama list
NAME ID SIZE MODIFIED
llama3.2:latest a80c4f17acd5 2.0 GB 23 hours ago
PS C:\Users\Kesin> ollama show llama3.2
Model
architecture llama
parameters 3.2B
context length 131072
embedding length 3072
quantization Q4_K_M
llama3.2 3Bなのでもともと小さいがさらにQ4_K_M量子化で小さくしているので2.0GBとかなり軽量なモデルになってる。コンテキスト長は131Kと表示されているが実際はどうなのだろう?
LMStudioの感覚だと131KでロードするとGPUの8GBは溢れそうな気がするけど・・・
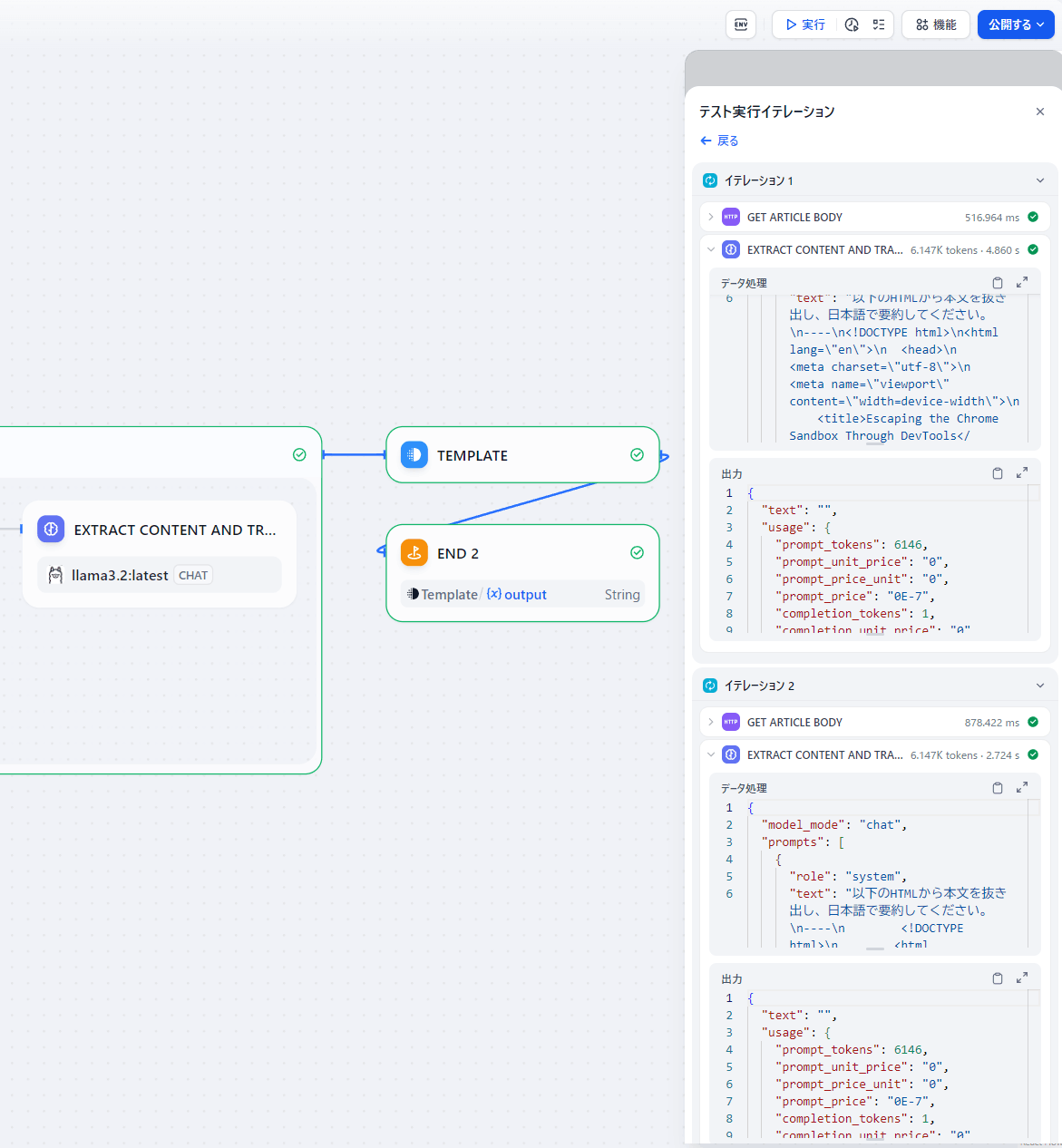
とりあえずMAXトークン数を8192でDifyに登録してみる。
記事のHTMLから本文を抜き出して日本語で要約してもらうタスクをこのllama3.2に置き換えてみたが出力が "text": "" となってしまう。トークン数を8192より増やしても変わらなかった。

LMStudioのときと同様に今度はollamaでもqwen2.5を試してみる。LMStudioのときと同じ7bでQ4_K_M量子化なのでほぼ一緒のはず。
PS C:\Users\Kesin> ollama list
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 21 hours ago
llama3.2:latest a80c4f17acd5 2.0 GB 2 days ago
PS C:\Users\Kesin> ollama show qwen2.5:7b
Model
architecture qwen2
parameters 7.6B
context length 32768
embedding length 3584
quantization Q4_K_M
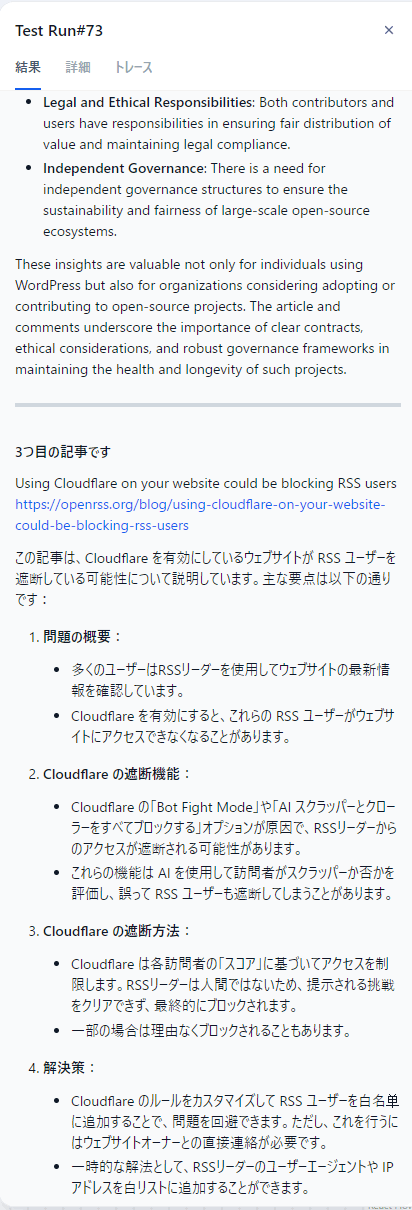
トークン数はllama3.2のときと同様に12288に設定。1/3記事が正しく日本で回答してくれたが、残りの2/3記事は英語のままだった。llama3.2は何も返してくれなかったのでそれと比べれば全然いい。
トークン数が実際関係しているのか確かめるために、今度は同じqwen2.5:7bで逆にトークン数を2048まで減らしてみる。
結果は1/3が正しく日本語で回答を返してくれた。ただしさっきは3番目の記事が日本語だったが、今回は2番目の記事が日本語だったので結果が変わっている。
さらに今回は3番目の記事の回答は破綻しているように見えた。
結論をまとめると、LMStudioとollamaで違いがあったように思える。ただ、今実験しているDifyのワークフローだと実行したときによってLLMに渡している記事が別物なので、比較条件は一致していないので偶然という可能性が大いにある。
- モデルの種類の差
- LMStudio: llama3.2でも要約を返してくれるときはあった
- ollama: llama3.2は一貫して何も返してくれなかった
- 最大トークンの挙動の違い
- LMStudio: モデルをロードしたときのトークン数の最大を超えると何も返してくれないことが多い
- ollama: トークン数が少なくとも一応何らかの返答はしてくれる。ただ回答は破綻してるように見える
LMStudioとollamaの違いが何に由来しているのか、今の自分の知識では全然わからない。
実用面だけで言えば、最大トークン数が少なくても一応何らかの回答を返してくれたり、バックグラウンドで起動して動的にモデルのロード/アンロードをしてくれるollamaの方が圧倒的に便利ではあるかな。
ただollamaの場合は呼び出し側から要求されたトークン数でモデルをロードするので、意図せずにメモリを使いすぎてしまうことがあった。
GPUのメモリで足りない場合はCPUにオフロードされてメインメモリを持っていくので、Windows全体が不安定になることがたびたびあった。
LMStudioは明示的にGPUにどれだけ乗せるかをスライダーで調節してモデルをロードするので、リソースのコントロールという面ではやりやすい。
ちなみにollamaでモデルがどれだけGPUとCPUにオフロードされているかは ollama ps を実行すると分かる。例えばqwen2.5:7bに32768トークンでリクエストした場合、自分の環境ではこうなる。
PS C:\Users\Kesin> ollama ps
NAME ID SIZE PROCESSOR UNTIL
qwen2.5:7b 845dbda0ea48 9.5 GB 39%/61% CPU/GPU 4 minutes from now
CPU側にオフロードされると露骨にGPU使用率が減って、代わりにCPU使用率が爆上がりするし、推論にめちゃくちゃ時間がかかってしまうので何一ついいことがない。

自分でGPUメモリのリソース管理をちゃんと考えないといけないのもローカルLLMの辛いところ。
ローカルのリソースで動かしているので当たり前ではあるが・・・
しかもリソースを食いすぎて慌てて途中で強制的にollamaのプロセスを終了させたりするとGPUのメモリの一部が消費されたままになってしまい、再起動するまで開放されないということもあったりする。ますます辛い

(平常時に常時使用されているGPUメモリは1GB程度なのになぜか2GB消費されっぱなしになっている。1GBのメモリを返して)
とりあえずこんなところか。Difyがどんなもので、ローカルLLMとどう組み合わせられるかの実験はいったん満足した