CI/CDのデータを収集するCIAnalyzerの紹介
去年のGWにCIAnalyzerというツールを作成し、プライベートと仕事の両方で1年ほど活用してきました。今年の9月にCI/CD Conference 2021にて実際の活用事例を紹介させて頂きましたが、発表時間の都合上CIAnalyzer自体の使い方まで紹介はできなかったためブログにしました。
CIAnalyzerを作成したきっかけ
今の自分の仕事は社内のCI/CDの基盤を整えるのと同時に、ビルドエンジニアの真似事のようなことをしています。この分野のサポートをしていると開発を主にしているエンジニアの方から
- 「ビルドが遅いし、頻繁に壊れる」
- 「テストは時間がかかるし、いつも失敗している」
という話を聞く機会がありました。ですが、自分としてはとても意外なことにその実態を定量的に把握することはほとんどできませんでした。
もちろん短期的であれば把握できます。昨日のデプロイはN分かかったとか、masterブランチでテストが落ちていたということは開発に関わっている人であれば覚えていますし、CI/CDサービスのログを見ればわかります。ですが1ヶ月前と比較してビルド時間は伸びているのか減っているのか、masterブランチでテストが落ちてる頻度はどれぐらいか分かるでしょうか?まして半年前と比較した場合は?
おそらく多くの人が答えられない、もしくは何となくの印象ベースでしか数値を出せないと思います。その理由は、ほとんどのCI/CDサービスではビルド時間やテスト結果の情報を蓄積していない、あるいはユーザーが見やすいようなダッシュボードなどの形で提供されていないからだと気が付きました。少なくとも、自分が望むような半年、1年の長期間のデータを比較できるほどのダッシュボードを提供しているサービスはありませんでした。
そのような思いを持っている中でのAzure Pipelinesとの出会いは自分にとって衝撃でした。Azure Pieplinesはビルドのデータ、テストデータについてかなり詳細なダッシュボードを提供してくれています。これは本当にによくできているので、例えばTypeScriptのCI結果のダッシュボードを見てください。
もしさらに興味があるならばmicrosoftのリポジトリにはCIにAzure Pipelines使用しているものが多いので、自分が知っているツールなどを探してREADMEのCI結果バッチからAzure Pieplinesのダッシュボードを見てみるといいでしょう。
このAzure Pipelinesと同等のダッシュボードを他のCI/CDサービス向けにも作ることができれば自分の業務にも大いに生かすことができるだろうと確信したのでCIAnalyzerを作ることにしました。
実際に自分が業務で1年ほどデータを蓄積して作成ダッシュボードの説明、これを活用することで解決できた問題などについては先日開催されたCI/CD Conference 2021にて紹介いたしました。
発表では時間の都合上、ダッシュボードの解説や実際の事例に焦点を当てていたためCIAnalyzerの詳しい使い方についてまで解説できませんでしたので、この記事ではCIAnalyzer自体の使い方を詳しく解説していきます。
簡単な使い方
まず以下のようなCIAnalyzerの設定用のyamlを用意します。
# Github Actions用
github:
repos:
- name: Kesin11/CIAnalyzer
tests:
- '**/*.xml' # JUnit XML形式のテストレポートも取り込む場合は actions/upload-artifact でアップロードしたパスを指定する
- Kesin11/CIAnalzer # テストレポートを取り込まない場合はリポジトリ名だけの省略パターンも可能
exporter:
local:
outDir: ./output # デフォルト: output
format: json # デフォルト: json. 'json' と 'json_lines' 形式の出力がサポートされています
lastRunStore:
backend: local
path: .ci_analyzer/last_run/github.json # デフォルト: .ci_analyzer/last_run/${service}.json
CIAnalyzerはdockerから使うことを想定しているので、以下のようなdocker runのコマンドを実行します。
docker run \
--mount type=bind,src=${PWD},dst=/app/ \
--mount type=bind,src=${SERVICE_ACCOUNT},dst=/service_account.json \
-e GITHUB_TOKEN=${GITHUB_TOKEN} \
-e GOOGLE_APPLICATION_CREDENTIALS=/service_account.json \
ghcr.io/kesin11/ci_analyzer:v4 -c ci_analyzer.yaml
実行すると以下のようなGitHub ActionsのビルドデータのJSONと、JUnit XMLを解析したテストレポートのJSONが出力されます。
ビルドデータ(Workflow report)
{
"service": "circleci",
"workflowId": "Kesin11/CIAnalyzer-ci",
"buildNumber": 306,
"workflowRunId": "Kesin11/CIAnalyzer-ci-306",
"workflowName": "ci",
"createdAt": "2020-05-21T01:08:06.800Z",
"trigger": "github",
"status": "SUCCESS",
"repository": "Kesin11/CIAnalyzer",
"headSha": "09f1d6d398c108936ff7973139fcbf1793d74f8f",
"branch": "master",
"tag": "v0.2.0",
"startedAt": "2020-05-21T01:08:09.632Z",
"completedAt": "2020-05-21T01:08:53.469Z",
"workflowDurationSec": 40.752,
"sumJobsDurationSec": 39.959,
"successCount": 1,
"parameters": [],
"jobs": [
{
"workflowRunId": "Kesin11/CIAnalyzer-ci-306",
"buildNumber": 306,
"jobId": "24f03e1a-1699-4237-971c-ebc6c9b19baa",
"jobName": "build_and_test",
"status": "SUCCESS",
"startedAt": "2020-05-21T01:08:28.347Z",
"completedAt": "2020-05-21T01:08:53.469Z",
"jobDurationSec": 25.122,
"sumStepsDurationSec": 24.738,
"steps": [
{
"name": "Spin Up Environment",
"status": "SUCCESS",
"number": 0,
"startedAt": "2020-05-21T01:08:28.390Z",
"completedAt": "2020-05-21T01:08:30.710Z",
"stepDurationSec": 2.32
},
{
"name": "Preparing Environment Variables",
"status": "SUCCESS",
"number": 99,
"startedAt": "2020-05-21T01:08:30.956Z",
"completedAt": "2020-05-21T01:08:30.984Z",
"stepDurationSec": 0.028
},
{
"name": "Checkout code",
"status": "SUCCESS",
"number": 101,
"startedAt": "2020-05-21T01:08:30.993Z",
"completedAt": "2020-05-21T01:08:31.502Z",
"stepDurationSec": 0.509
},
{
"name": "Restoring Cache",
"status": "SUCCESS",
"number": 102,
"startedAt": "2020-05-21T01:08:31.509Z",
"completedAt": "2020-05-21T01:08:32.737Z",
"stepDurationSec": 1.228
},
{
"name": "npm ci",
"status": "SUCCESS",
"number": 103,
"startedAt": "2020-05-21T01:08:32.747Z",
"completedAt": "2020-05-21T01:08:37.335Z",
"stepDurationSec": 4.588
},
{
"name": "Build",
"status": "SUCCESS",
"number": 104,
"startedAt": "2020-05-21T01:08:37.341Z",
"completedAt": "2020-05-21T01:08:43.371Z",
"stepDurationSec": 6.03
},
{
"name": "Test",
"status": "SUCCESS",
"number": 105,
"startedAt": "2020-05-21T01:08:43.381Z",
"completedAt": "2020-05-21T01:08:53.369Z",
"stepDurationSec": 9.988
},
{
"name": "Save npm cache",
"status": "SUCCESS",
"number": 106,
"startedAt": "2020-05-21T01:08:53.376Z",
"completedAt": "2020-05-21T01:08:53.423Z",
"stepDurationSec": 0.047
}
]
}
]
}
テストデータ(Test report)
[
{
"workflowId": "Kesin11/CIAnalyzer-CI",
"workflowRunId": "Kesin11/CIAnalyzer-CI-170",
"buildNumber": 170,
"workflowName": "CI",
"createdAt": "2020-08-09T10:20:28.000Z",
"branch": "feature/fix_readme_for_v2",
"service": "github",
"status": "SUCCESS",
"successCount": 1,
"testSuites": {
"name": "CIAnalyzer tests",
"tests": 56,
"failures": 0,
"time": 9.338,
"testsuite": [
{
"name": "__tests__/analyzer/analyzer.test.ts",
"errors": 0,
"failures": 0,
"skipped": 0,
"timestamp": "2020-08-09T10:22:18",
"time": 3.688,
"tests": 17,
"testcase": [
{
"classname": "Analyzer convertToReportTestSuites Omit some properties",
"name": "testcase.error",
"time": 0.003,
"successCount": 1,
"status": "SUCCESS"
},
{
"classname": "Analyzer convertToReportTestSuites Omit some properties",
"name": "testcase.failure",
"time": 0,
"successCount": 1,
"status": "SUCCESS"
},
...
CIAnalyzerには出力されたJSONを可視化する機能は内蔵されていません。ダッシュボードなどの生成は、出力されたJSONをBigQueryなどのデータレイクに転送してBIツールを使って皆さんが各自で作成することを想定しています。CIAnalyzerはローカルにJSONを出力する以外にBigQueryへ直接データを転送する機能もあります。
ダッシュボードの生成に関しては、自分はBigQueryと連携できて非構造JSONのまま取り込んでもでもいい感じにグラフ化しやすいDataStudioを使っています。CIAnalyzer自体のビルドデータのダッシュボードを公開していますので、もしDataStudioで作成する場合はこれをコピーするところから始めると簡単でしょう。
上の例はGitHub Actionsのデータを取り込むためのものでしたが、CIAnalyzerは他のCIサービスのビルドデータの取り込みにも対応しています。
- GitHub Actions
- CircleCI
- Jenkins
- Bitrise
仕組みと特徴
APIからビルドデータを取得
CIAnalyzerは各CIサービスのAPIから取得できる過去のビルドデータやログを取得して解析、整形します。他のテスト結果やカバレッジを収集するようなサービスではビルド中に何らかのツールでデータを送信するタイプが多いですが、CIAnalyzerはAPIからデータを取得しているのでビルドフローに手を加える必要はありません。
収集したデータは自前で管理
CIAnalyzerはサービスではなくただのツールであり、APIから収集したデータは各自で蓄積してもらう仕組みです。BigQueryへのエクスポート機能を内蔵していることもあり、基本的にはBigQueryにデータを蓄積してもらうことを想定していますが、JSONとしても出力できるのでローカルやS3, GCSなどに保存してもらうことも可能です。
最初はウェブサービスにするべきか悩んでいた時期もあったのですが、ビルドのログやデータには業務に関する情報[1]が含まれることも多いため、外部のサービスにデータを蓄積するのはあまり受け入れられないと考えてこのような形にしました。BigQueryやGCSを各自で用意してもらう必要があるので導入のハードルは多少高くなってしまいますが、代わりに業務でも気兼ねなく導入できると思います。
cronによるポーリング方式
先述したようにCIAnalyzerはサービス型ではないためリクエストを受け付けるための常駐サーバーを立てる必要がありません。cronなどで定期的に起動して各CIサービスのAPIを呼び出すことができればよいので、サーバーを立てる代わりに各種CIサービスの定期実行ジョブを利用してCIAnalyzerを起動するのが最も簡単な導入方法となっています。
例えばCircleCIなら triggers schedule 、GitHub Actionsなら on.schedule を利用します。
前回実行時からの差分データだけを取得
cronによるポーリング方式でAPIからデータを取得するため、短い間隔で実行された場合には同じbuild_idのビルドデータを重複して取得してしまう可能性があります。さらにデータの蓄積場所として想定しているBigQueryも取り込み時にデータの重複を自動的に判定する仕組みがないため、データを取り込む際に重複データを取り除くためのなんらかの工夫が必要になります。そこで、CIAnalyzerでは前回までに取得したbuild_idのデータを出力前に自動的に除く機能を備えています。
どのCIサービスでもbuild_idに相当するビルド番号は単純に増加するという性質に着目し、前回取得したbuild_idの最大値をローカルファイルに保存して次回以降は前回よりも新しいビルドのデータだけを取得するようにしています。毎回同じマシンで実行するのであれば話はこれだけで単純なのですが、CircleCIみたいに実行するたびにマシンが変わる環境で実行される場合は前回までのbuild_idを記録したファイルをなんらかの方法で毎回前のマシンから引き継ぐ必要があります。
これを実現するには外部にRDBかKVSなどのDBを立てれば解決できるのですが、これだけのためにわざわざDBを運用したくはありません。そこで、terraformがtfstateをS3やGCSに保存する方式を参考にし、前回実行時のbuild_idの情報のJSONをGCSに保存/参照するというシンプルな形で実現しました。この仕組みをLastRunStoreという名前で呼んでいます。
従って、先述のデータの蓄積場所としてBigQueryを利用するという話と合わせるとCIAnalyzerを本格的に利用する場合には以下のリソースを活用することになります。
- 利用しているCIサービスのスケジュール実行機能
- BigQuery(データの蓄積)
- GCS(前回取得したbuild_idの保存)
実際に使用する場合の事前準備
ここからはCIAnalyzerをローカルでお試しではなく、実際に運用する場合に必要なセットアップを解説していきます。
BigQueryのテーブルを用意
まずはデータの保存先となるBigQueryのテーブルを用意します。BigQuery用のスキーマファイルはCIAnalyzerのリポジトリに既に用意してありますので、以下のコマンドを実行するだけで必要なテーブルを作成できます。
変数になっている GCP_PROJECT_ID, DATASET, WORKFLOW_TABLE, TEST_REPORT_TABLE は後ほどyamlにも入れる値になります。
git clone https://github.com/Kesin11/CIAnalyzer.git
cd CIAnalyzer
# データセット作成
bq mk
--project_id=${GCP_PROJECT_ID} \
--location=${LOCATION} \
--dataset \
${DATASET}
# テーブル作成
bq mk
--project_id=${GCP_PROJECT_ID} \
--location=${LOCATION} \
--table \
--time_partitioning_field=createdAt \
${DATASET}.${WORKFLOW_TABLE} \
./bigquery_schema/workflow_report.json
bq mk
--project_id=${GCP_PROJECT_ID} \
--location=${LOCATION} \
--table \
--time_partitioning_field=createdAt \
${DATASET}.${TEST_REPORT_TABLE} \
./bigquery_schema/test_report.json
LastRunStoreのGCSを用意
次は前回実行時のbuild_idを保存するためのGCSのバケットを用意します。これも以下のコマンドを実行するだけで作成できます。
変数の BUCKET_NAME は後ほどyamlに入れる値となります。
gsutil mb -b on -l ${LOCATION} gs://${BUCKET_NAME}
各種CIサービスのトークンを用意
各種CIサービスのAPIを使うためのトークンを用意してください。サービスによってはAPIトークンにあまり馴染みのない場合もあると思うので、参考のリンクを貼っておきます。
試しの実行
READMEやサンプルを参考に、CIAnalyzerの設定YAMLを用意しましょう。最終的にはBigQueryやGCSを使うことになりますが、まずはデバッグのために出力するビルドデータとLastRunStoreをローカルにJSON形式で出力するようにします。
# Github Actionsの場合
github:
repos:
- name: Kesin11/CIAnalyzer # 各自のプライベートプロジェクトなど
tests:
- '**/*.xml'
exporter:
local:
outDir: ./output
format: json
lastRunStore:
backend: local
path: .ci_analyzer/last_run/github.json
YAMLの用意ができたら以下のようなdockerのコマンドを実行します。先ほど用意したyamlをコンテナから読むためにローカルファイルをマウントさせ、トークンの情報などを環境変数で渡します。
docker run \
--mount type=bind,src=${PWD},dst=/app/ \
-e GITHUB_TOKEN=${GITHUB_TOKEN} \
ghcr.io/kesin11/ci_analyzer:v4 -c blog.yaml --debug -v
CIのデータが多いリポジトリの場合、終わるまで時間がかなりかかることもあります。動いているか不安な場合は --debug を付けるとAPIから取得するデータ量を少しだけに限定、 -v でAPIリクエストのログも含むデバッグ用のログも出力できます。
実行が問題なくできれば output/ に結果のjsonと、.ci_analyzer/last_run にジョブ毎の最後のbuild_idが記録されたjsonの2つが出力されているはずです(--debug の場合は最後のbuild_idを保存しない挙動になるので output/ のみ)。中身が空でなければyamlの設定やAPIトークンの設定などは正しくできています。
次は実際にCIAnalyzerから直接BigQueryやGCSにデータを送るようにyamlを設定します。
GCP_PROJECT_ID, DATASET, WORKFLOW_TABLE, TEST_REPORT_TABLE, BUCKET_NAME は先ほどbqとgsutilのコマンドで使用したものを入れてください。
github:
repos:
- name: Kesin11/CIAnalyzer
tests:
- '**/*.xml'
exporter:
bigquery:
project: { GCP_PROJECT_ID }
dataset: { DATASET }
reports:
- name: workflow
table: { WORKFLOW_TABLE }
- name: test_report
table: { TEST_REPORT_TABLE }
lastRunStore:
backend: gcs
project: { GCP_PROJECT_ID }
bucket: { BUCKET_NAME }
今度はGCPへの認証も必要なのでサービスアカウントのjsonを作成し、コンテナの中から参照できるように docker run のオプションに --mount と GOOGLE_APPLICATION_DEFAULT の環境変数にサービスアカウントのパスを指定する必要があります。
サービスアカウントはBigQueryとGCSへのread/write権限があれば何でもいいのですが、後でCIサービス上で実行することを考えると専用のサービスアカウントを用意すると良いでしょう。
docker run \
--mount type=bind,src=${PWD},dst=/app/ \
# ローカルPC上に保存したサービスアカウントのjsonをコンテナから参照できるようにマウントする
--mount type=bind,src=${SERVICE_ACCOUNT},dst=/service_account.json \
-e GITHUB_TOKEN=${GITHUB_TOKEN} \
-e GOOGLE_APPLICATION_CREDENTIALS=/service_account.json \
ghcr.io/kesin11/ci_analyzer:v4 -c ci_analyzer.yaml
これで問題なくBigQueryとGCSにデータが送れたことを確認できたら、あとはその docker run のコマンドと環境変数、サービスアカウントをお使いのCIサービスに登録してcronの設定をするだけです!
Cronの設定について
先述のようにCIAnalyzerはcronで定期的に起動してデータを収集する作りになっています。CIAnalyzerが現在サポートしているGitHub Actions, CircleCI, Jenkins, Bitriseのいずれもスケジューリング実行する機能が存在するのでそれを活用して定期的に実行してください。JenkinsとCircleCI用のサンプル設定はリポジトリに含まれているので参考になるはずです。
https://github.com/Kesin11/CIAnalyzer/tree/master/sample
注意点としては、CIAnalyzerは1度の実行で取得できるビルド数に限りがあるため[2]、特に頻繁にビルドが動いているリポジトリではスケジューリングの間隔が広がりすぎると過去のビルド結果を取得しきれない可能性があります。ビルド頻度にもよりますが1時間か30分程度の間隔[3]でcron実行することをオススメします。
docker runに使用するイメージのタグについて
https://github.com/Kesin11/CIAnalyzer/pkgs/container/ci_analyzer/versions
docker run で指定するイメージのタグは latest ではなく、例えば v4 , v4.1 , v4.1.0 などのバージョン番号のタグを利用することを推奨しています。
CIAnalyzerはSemantic Versioningに従ってバージョンを決定してリリースしているので、majorバージョンが上がるときには何らかの機能において後方互換性が無いBREAKING CHANGESを含むバージョンアップということになります。 latest では将来的に後方互換性が無い v5 へ自動的に切り替わり、ある日突然動かなくなってしまう可能性があるので最低でもmajorのバージョンタグを指定しておく方が良いでしょう。
ちなみに master というタグも存在しますが、これは最新のmasterブランチから作られるイメージです。 開発用のタグですので利用者側では latest 同様に使う必要はありません。
ダッシュボードの作成
BigQueryにデータを取り込めたらBigQueryと連携できるお好きなツールでダッシュボードを作成しましょう。データは揃っているのでお好きなように作成してもらえればいいのですが、一例として自分がDataStudioで作成したダッシュボードを公開しています。
DataStudioは公開されているレポートからコピーを作成可能です。DataStudioをお使いの方はコピーして使用するデータリソースをご自分のものに入れ替えてもらうのが一番手っ取り早いでしょう。
以下では自分が作成したダッシュボードの各画面について簡単に解説をします。
全ジョブのビルド時間の推移

全ジョブのビルド時間、成功率をざっくり見る画面です。トータルのビルド時間が長いジョブ、成功率が低いジョブを目立つようにソートしてあると改善が必要なジョブをひと目で見つけやすくなるので便利です。
1つのジョブの詳細

1つのジョブに絞ってビルド時間やステップごとの時間の推移や平均値を見る画面です。他の画面で怪しいと思ったジョブを詳細に分析したり、普段の開発でCI時間を改善したいと思った場合に改善の度合いが大きいステップを見つけるために見たりします。
テストデータ分析

JUnitのXML形式で出力されたテストデータを集計した結果の画面です。成功率が低いテストや実行時間が長いテストを見つけることができるので、ビルド全体の中でも特にテストに力を入れていた場合にはこの画面を使った分析が役に立つでしょう。
キュー待ち時間分析
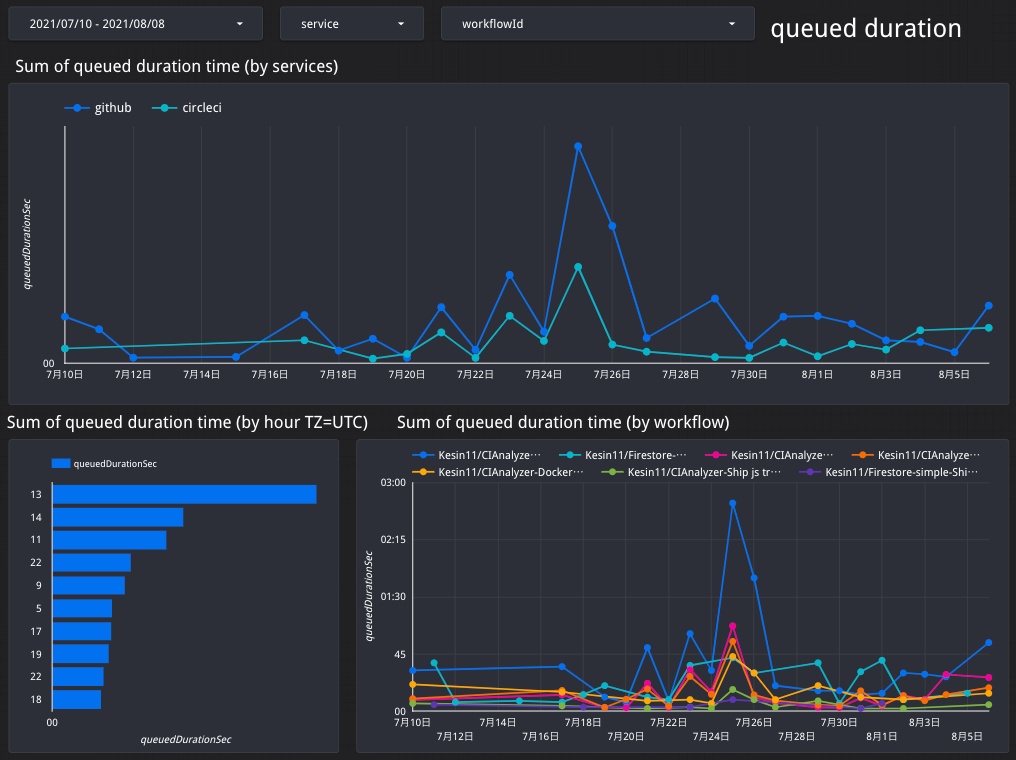
ビルドがトリガーされてから実際に実行されるまでの時間(=キュー待ち時間)の推移と、どの時間帯がどれだけ混雑しているか見ることができます。
GitHub Actionsのように並列数ではなくてビルド時間で従量課金のサービスでは気にする必要はないですが、並列数の課金プランのサービスやビルドマシンを自分で管理するJenkinsのような環境の場合はCIの利用度合いに対してマシンリソースが十分かどうかを把握するのに役立ちます。
キュー待ち時間が右肩上がりに増え続けている場合はマシンリソースが不足しつつあるということです。CIサービスの並列数を増やしたりJenkinsのビルドマシンを増やすなどの対策が必要になるでしょう。
テーブルビュー

この画面はパッと見て何かを分析するためではなく、主にデバッグ用です。各種グラフを作成するときは何らかの値をSUMだったりAVGなどで集計をすることになるのですが、その集計やフィルタリングが正しく組めているかどうかを確認するための画面を用意していると意外と便利です。
別の使い方として各カラムのフィルターを用意しておくことで、ある程度複雑な条件で過去のビルドを探したい場合にBigQuery上でSQLを書かずともDataStudio上で簡単に調べることができて便利です。
例えばジョブやステップのステータスでフィルターを用意してFailedなものだけに絞ることで、1ヶ月の間で失敗したジョブのうちどのステップで失敗しているのかを見つけるような使い方も可能です。
データのスキーマ定義
ダッシュボードを自作したいという方のために、データスキーマのそれぞれのフィールドが実際には何の値に対応しているのかを載せておきます。
前提の解説
workflow, job, stepの構造関係
各CIサービスによって用語の名前が多少異なりますが、CIのパイプライン構造に関してはほぼ以下のように構成されています。CIAnalyzerでは全てのCIサービスのデータを同一のスキーマで扱うため、このような構造にそろえています。
- workflows: pushやpull-request毎にトリガーされるパイプライン
- jobs: stepsをまとめる単位でlintやbuildなどでまとめられることが多い。matrix機能を使う場合はパラメータ毎に異なるjobとなる
- steps: 実際に実行されるコマンド
- jobs: stepsをまとめる単位でlintやbuildなどでまとめられることが多い。matrix機能を使う場合はパラメータ毎に異なるjobとなる
サービスによってはAPIのレスポンスに含まれていないスキーマの値について
各CIサービスによってAPIのレスポンスに含まれる内容は異なるのですが、CIAnalyzerとしては全てのCIサービスで可能な限り同じ意味の値となるよう独自に工夫しています。具体的には複数の値から計算で算出したり、独自に他の値を組み合わせて足りないものを生成したりしています。
実際どのように生成しているかは各サービスのAnalyzerクラスにコメントを書いています。一番苦労したJenkinsAnalyzerを見てもらうと雰囲気が分かるかと思います。
xxxDurationSecとsumXxxDurationSecの違いについて
スキーマの中に似たような名前がいくつかあるのに気づいた方がいるかと思います。 workflowDurationSec と sumJobsDurationSec 、jobDurationSec と sumStepsDurationSec の2つのペアです。
それぞれ似たような名前で別々に用意している理由は、ワークフローの場合はジョブ、ジョブの場合はステップがそれぞれ並列に実行されるケースが存在するからです。例えばワークフローAにはジョブA,Bが存在しておりそれぞれ3分ずつかかるケースを考えます。
ジョブA,Bは直列に実行されるケース
- ワークフローA:
ジョブA + ジョブB = 6min- ジョブA: 3min
- ジョブB: 3min
- ジョブA: 3min
ジョブA,Bは並列に実行されるケース
- ワークフローA:
MAX(ジョブA, ジョブB) = 3min- ジョブA: 3min
- ジョブB: 3min
このような違いがあるため、ワークフローA全体の時間をチューニングしたい場合にワークフローの実時間(workflowDurationSec)とジョブの合計時間(sumJobsDurationSec)を別々に見たいことがあります。同じ関係がジョブとステップについても考えることができます。
ダッシュボードでグラフ化する場合にどちらの値を可視化するべきかは用途によって使い分けてください。
workflow
| 階層1 | 階層2 | 階層3 | 説明 |
|---|---|---|---|
| workflowId | ワークフローを一意に識別するためのユニークなid | ||
| workflowName | ワークフローの名前 | ||
| workflowRunId | ワークフローの実行毎に一意に識別するためのユニークなid | ||
| buildNumber | ワークフローのビルド番号 | ||
| service | サービス名(github, circleci, bitrise, jenkins) |
||
| repository | リポジトリ名 | ||
| branch | ビルドしたブランチ | ||
| headSha | ビルドしたコミットハッシュ | ||
| tag | ビルドしたタグ | ||
| trigger | CIを起動したときのトリガー | ||
| status | ワークフローのステータス(SUCCESS, FAILURE, ABORTED, OTHER) | ||
| successCount | SUCESSのとき1、それ以外は0。ダッシュボードを作成するときに平均を計算すると=ビルドの成功率となる | ||
| createdAt | ワークフローがキューに積まれた時間 | ||
| startedAt | ワークフローが実際に開始された時間 | ||
| completedAt | ワークフローが完了した時間 | ||
| workflowDurationSec | ワークフローの実行時間 | ||
| sumJobsDurationSec | workflowDurationSecとは別にjobs.jobDurationSecから算出した実行時間 | ||
| queuedDurationSec | キュー待ちしていた経過時間 | ||
| jobs | jobId | ジョブのid | |
| jobName | ジョブの名前 | ||
| buildNumber | ジョブの番号(サービスによってはジョブごとの番号が存在しないこともある) | ||
| workflowRunId | 大本のワークフローのユニークなid | ||
| status | ジョブのステータス(SUCCESS, FAILURE, ABORTED, OTHER) | ||
| startedAt | ジョブが開始された時間 | ||
| completedAt | ジョブが完了した時間 | ||
| jobDurationSec | ジョブの実行時間 | ||
| sumStepsDurationSec | jobDurationSecとは別にsteps.stepDurationSecから算出した実行時間 | ||
| steps | name | ステップの名前 | |
| status | ステップのステータス(SUCCESS, FAILURE, ABORTED, OTHER) | ||
| startedAt | ステップが開始された時間 | ||
| completedAt | ステップが完了した時間 | ||
| stepDurationSec | ステップの実行時間 | ||
| number | ステップの番号 | ||
| parameters | name | パラメータ名(現在Jenkinsのみサポート) | |
| value | パラメータ値(現在Jenkinsのみサポート) |
test_report
SQLのJOIN用に用意している workflowId や workflowRunId などworkflowにも存在した一部に加えてJUnitのテストデータの情報を含む TestSuites があります。
JUnitのXMLは色々なテストフレームワークでサポートされているにも関わらずスキーマの仕様がちゃんと決まっているわけではないのですが、例えば以下のような解説も存在します。
CIAnalyzerではXMLであるJUnitの情報をBigQueryに入れられるようにいい感じのJSONに変換しており、これが TestSuites の中身になります。
このJUnit XML -> JSONの変換はCIAnalyzerとはまた別のパッケージに切り出しています。
類似サービス
ここまでCIAnalyzerの使い方を解説してきましたが、似たような機能を有するサービスも無いわけではありません。いきなりCIAnalyzerのセットアップを始めるのはハードルが高いという場合にはまずこれらのサービスから利用を検討してみるといいでしょう。
Azure Pipelines
自分にとっては本家です。Azure Pipelinesでビルドしていれば素晴らしいダッシュボードが自動的に使えるようになるため、既にAzureをお使いの方はこれを使わない手はないでしょう。別のCIサービスをメインに利用としている場合も、会社的にMSのサービスを利用しやすい環境の場合はAzure Pipelinesを検討してみる価値はあると思います。
CircleCI insights
Insights機能は以前から存在していましたが、最近になって新UIで復活しました。ビルドの成功率、時間などのグラフを提供してくれています。しかし、ビルド中のステップごとの時間などの詳細までは見ることができないためAzure PipelinesやCIAnalyzerから作成できるダッシュボードに比べると比較的簡素なものになっています。
一方でテストレポートに関してはまだPreview版だそうですが、Azure PipelinesやCIAnalyzerのものと同等の機能を有しています。
Meercode
GitHub ActionsやBitriseなど各種CIサービスのアカウントを連携するだけCIAnalyzerやAzure Pipelinesのようなダッシュボードを作成できるサービスです。それぞれのリポジトリのビルド中に特別なステップなどを実行する必要はなく、アカウントを連携するだけでダッシュボードが作られるので非常に簡単です。
自分がCIAnalyzerの実装を始めた2020年の春頃までにはまだ存在していなかったと思います。アカウント連携したりAPIトークンを登録するだけですので正直言ってCIAnalylzerよりかなりお手軽に始めることができます。ですが、例えばBitriseのようにトークンごとに権限のコントロールできないサービスではトークンを渡すということはあらゆる権限を渡すということになりますし、CIのログやステップ名などあまり外部に知られるとよくない恐れのある情報も渡してしまうことには注意が必要だと個人的には考えています。
自分も構想段階ではCIAnalyzerをサービス型で提供することも考えていたのですが、そのあたりの他人や他社の重要情報を管理したくなかったのと、自分でも業務で使いにくくなってしまうことからデータは全て各自で管理してもらう今のアーキテクチャにしたという経緯があります。
まとめ
CIのビルドを分析するためのデータを収集するCIAnalyzerという自作ツールの紹介でした。
この分野に興味がある方にはぜひ使用してみてもらいたいです。ただ、個人プロダクトレベル程度の規模だとそれほど面白い結果にはなりにくいとは思います。CIAnalyzerは複数人で長期間に渡って開発する大規模開発の現場で真価を発揮してくれるはずです。
自分はCIAnalyzerの開発を続けながら既に1年以上は業務のプロダクトのデータを収集していますが、ダッシュボードのグラフを毎日見てるだけでビルドがどれだけ安定しているか分かりますし、ビルド時間を改善する作業の際にどこがボトルネックになっているのか特定するのにとても役立ちました。
CIAnalyzerには今のところ過去に遡ってデータを収集する機能はないため、分析できるデータはCIAnalyzerを利用し始めた時点からのデータに限定されてしまいます。CI/CDに問題が発生して分析したくなってからの導入では遅いので、ぜひ今からCIAnalyzerを使ってみてください。
-
プロジェクト名などがスクリプト名の一部に含まれているなど。 ↩︎
-
具体的には各サービスのAPIで1回に取得できるレスポンス数のMAXで、サービスによりますがおおよそ50-100ビルドです。ページング処理まできちんと実装すれば理論的にはもっと増やせるのですが、その場合はAPIリミットに到達してしまう可能性が高いので現段階ではそのような実装はあまり考えていません。 ↩︎
-
APIの構造上、Jenkinsのレスポンス数のMAX一番少なくたったの10しかありません。一方でJenkinsにはAPIレートリミットが存在しないので、最も頻繁に実行されるジョブが10回ビルドされるまでの間隔でcron実行することによりデータを取り逃す可能性をなくすことができます。 ↩︎
Discussion