コンテナ周辺知識の学習録
Dockerfile
RUN → ビルド時に実行するコマンド
CMD → 実行時(docker run)に実行されるコマンド (docker run実行時に明示的にコマンド指定したら上書きされる)
- シェル形式
- シェル変数が展開される。
-
/bin/shがPID1として起動して、サブコマンドとして渡されることになるためコンテナ終了時に送られるSIGTERMシグナルを受け取れない(=PID1に渡るけどCDMで実行したプロセスには渡らない)。10秒程度するとDockerは強制終了するためSIGKILLシグナルを送られる。
- exec形式 <- 配列で仕切った形式 [推奨]
- シェル変数が展開されない。
-
/bin/shが起動しない分軽量 -
SIGTERMシグナルを受け取れる
ENTRYPOINT → 実行時(docker run)に実行されるコマンド (docker run実行時に明示的にコマンド指定したら上書きされない)
- ENTRYPOINTで指定されたコマンド
-
docker run時に指定したコマンド - Dockerfileで定義された
CMD - イメージのデフォルトの
CMD
LABEL → 作者名やversion番号などDockerfileに付随するメタデータを記載。
EXPOSE → 公開するポートを指定。実際に公開するには実行時に-pオプションでマッピングする必要がある。Dockerfile上は宣言するだけみたいな?
ENV → key=value形式で定義するべき。
ADD : リモートからも追加できる / 圧縮ファイルが自動解凍される
COPY : 上記2点がされない。
ref)
WORKDIR → 以降のRUN、CMD、ENTRYPOINT、COPY、ADD実行時の作業ディレクトリ
ARG → ビルド時のパラメータ $ docker build --build-arg <key>=<value>で指定
※ ビルドの変数としてクレデンシャルを渡すべきではない。$ docker historyで変数も展開できてしまうため。
デフォルト値を定義可
ARG <variable>=<default value>
HTTP_PROXYなどいくつかの予約された変数があり、これらはhistoryで出力されないしキャッシュもされない。
輸送コンテナの歴史に見るdockerコンテナ[1]
かつては人や動物が荷物を運んだ。
一度に運べる量は少ないし、荷物に規格のないので積み替えたり載せ替えたり時間と労力を要した。
車輪の発明によって多くの荷物を一度に運べるようになった。それでも積み替えたり載せ替えたりにかかる時間と労力は改善できなかった。
一度に扱う荷物が増えたことで荷物の紛失や盗難も問題となった。
統一企画のコンテナ
統一された企画のコンテナ化されたことで荷物の積み替えのコストが大きく減った。
陸路はトラックや鉄道、海路は船でコンテナをそのまま載せ替えるだけでよく、また輸送に関わる者はコンテナの中身を意識する必要がなく、安全性を手に入れた。
コンテナを支える技術
namespace : 名前空間
プロセスに対して種々の実行コンテキスト[2]における隔離された空間を提供する機能。unshare()システムコールを使うことで分離できる。[3]
名前空間で分離できるリソース[4]
- マウント名前空間: マウントの集合、操作
- UTS名前空間: ホスト名、ドメイン名
- PID名前空間: プロセスID(PID)
- IPC名前空間: SystemVプロセス間通信(IPC)オブジェクト、POSIXメッセージキュー
- ユーザ名前空間: UID、GID
- ネットワーク名前空間: ネットワークデバイス、IPアドレス、ポート、ルーティングテーブル、フィルタなど
マウント名前空間を分離できることでコンテナごとに異なるボリュームのマウントができるし、PIDやネットワーク名前空間を分離することでホストOS上で使用されているPIDやポート番号をコンテナ内でも同じ値を使える。
cgroup : Control Group
プロセスをグループ化し、グループ化されたプロセスの集合に対し共通の管理を行う。
ホストOSが持つハードウエアリソース(CPUやメモリ、ネットワーク帯域など)の割り当てを制御することで、特定のコンテナがホストOSの持つリソースを使いつくし、ホストOS上のプロセスや他のコンテナに影響を与えないように制限できる。
cgroupでグループ化されたプロセス情報はcgroupファイルシステム(cgroupfs)で管理される。
cgroupfsは/sys/fs/cgroup/以下にその情報が書かれる。この階層は制御する内容ごとに分かれているので以下はCPUについて取り上げるものとする。(CPU以外のディレクトリが示すものは後述)
[/sys/fs/cgroup] # ls
blkio cpuset hugetlb net_prio rdma
cpu devices memory perf_event systemd
cpuacct freezer net_cls pids
[/sys/fs/cgroup/cpu] # ls
cgroup.clone_children cpu.rt_period_us notify_on_release
cgroup.procs cpu.rt_runtime_us tasks
cpu.cfs_period_us cpu.shares
cpu.cfs_quota_us cpu.stat
このディレクトリ内にディレクトリを切ることで新しいcgroupを作成できる。
[/sys/fs/cgroup/cpu] # mkdir <cgroup名>
/sys/fs/cgroup/cpu/<cgroup名>/tasks以下にこのcgroupで束ねられたプロセス番号が並ぶ。
ここにプロセス番号を書き込むことでそのプロセスはcgroupの中に属することになる。
/sys/fs/cgroup/cpu/<cgroup名>/tasksはcgroup毎にあるので、当然別のcgroupからはそのプロセス番号は確認できない。
tasksファイルの中が空になったcgroupは削除できる。
/sys/fs/cgroup/cpu/tasksにはcgroupを切られる前のプロセスIDがずらっと入っている。
cgroupに属しているプロセスを解放したい場合はcpu/のトップの階層にあるtasksファイルにそのPIDを書き込んだらOK(cpu/<cgroup名>/tasksの方に書いた番号は勝手に消えるので)。
cgroupの階層構造
cgroupは階層構造をとることができる。
= cgroupAの中にcgroupBとcgroupCが属するような構成。(/sys/fs/cgroup/cpu/<cgroup名>/<cgroup名>になるような感じ。)
上記の通りcgroupの機能はホストOSが持つハードウエアリソースの割り当ての制御なので、cgroupAにCPUリソースの30%を割り当て、その中でcgroupBに20%、cgroupCに10%みたいな制御ができる。
cgroupによる制御
cgroupでは「サブシステム」もしくは「コントローラ」という名称で制御するリソースを区別している。
以下はサブシステム一覧。
blkio cpuset hugetlb net_prio rdma
cpu devices memory perf_event systemd
cpuacct freezer net_cls pids
例えば、cpuでは割り当ての配分や帯域制御(単位時間内にグループ内のタスクが実行できる合計時間)、memoryではメモリ制限、blkioではI/Oアクセスの比率の配分や帯域制限(グループ内のタスクが各デバイスに対して行える操作数の制限)を指定できる。
これらサブシステムは/proc/cgroupで確認できる。
[/sys/fs/cgroup/cpu] # cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 1 31 1
cpu 2 31 1
cpuacct 3 31 1
blkio 4 31 1
memory 5 32 1
devices 6 31 1
freezer 7 31 1
net_cls 8 31 1
perf_event 9 31 1
net_prio 10 31 1
hugetlb 11 31 1
pids 12 31 1
rdma 13 4 1
-
実行コンテキスト : "コンテキストスイッチ"のコンテキスト。CPUがそのプロセスを実行するためのひとまとまりのプロセス情報のこと。(要出典) ↩︎
-
https://manpages.ubuntu.com/manpages/bionic/ja/man2/unshare.2.html ↩︎
-
https://gihyo.jp/admin/serial/01/linux_containers/0002#sec4_h2 ↩︎
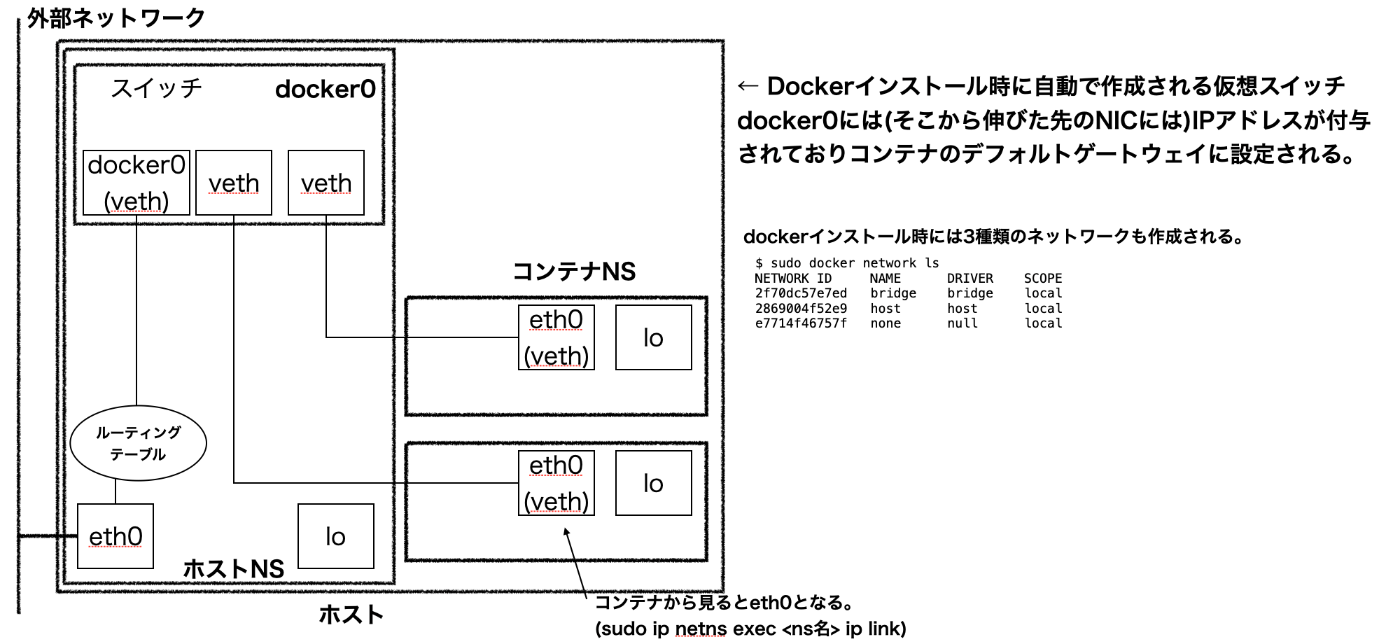
ネットワーク
コンテナでネットワークを使用する場合、ホスト上の空いているネットワークインターフェースをコンテナに割り当てる必要がある。ホスト上の物理NICが無限にあれば大量のコンテナを起動しそれらをネットワークに繋ぐことは可能だがホストのNICはそんなにない。
→ 仮装的なNICを使い、物理NICを共有する。
vethインターフェース
vethインターフェースはレイヤ2の仮装ネットワークインターフェースであり、vethを作成すると、2つのインターフェースがペアで作成され、この2つのインターフェース間で通信が可能となる。
vethの一方をコンテナの中に配置し、もう一方をホスト側に用意してNICと繋ぐことでコンテナでネットワークを利用できる。(逆にvethのペアはお互いに異なるネットワーク名前空間に存在しなければ利用できない。)

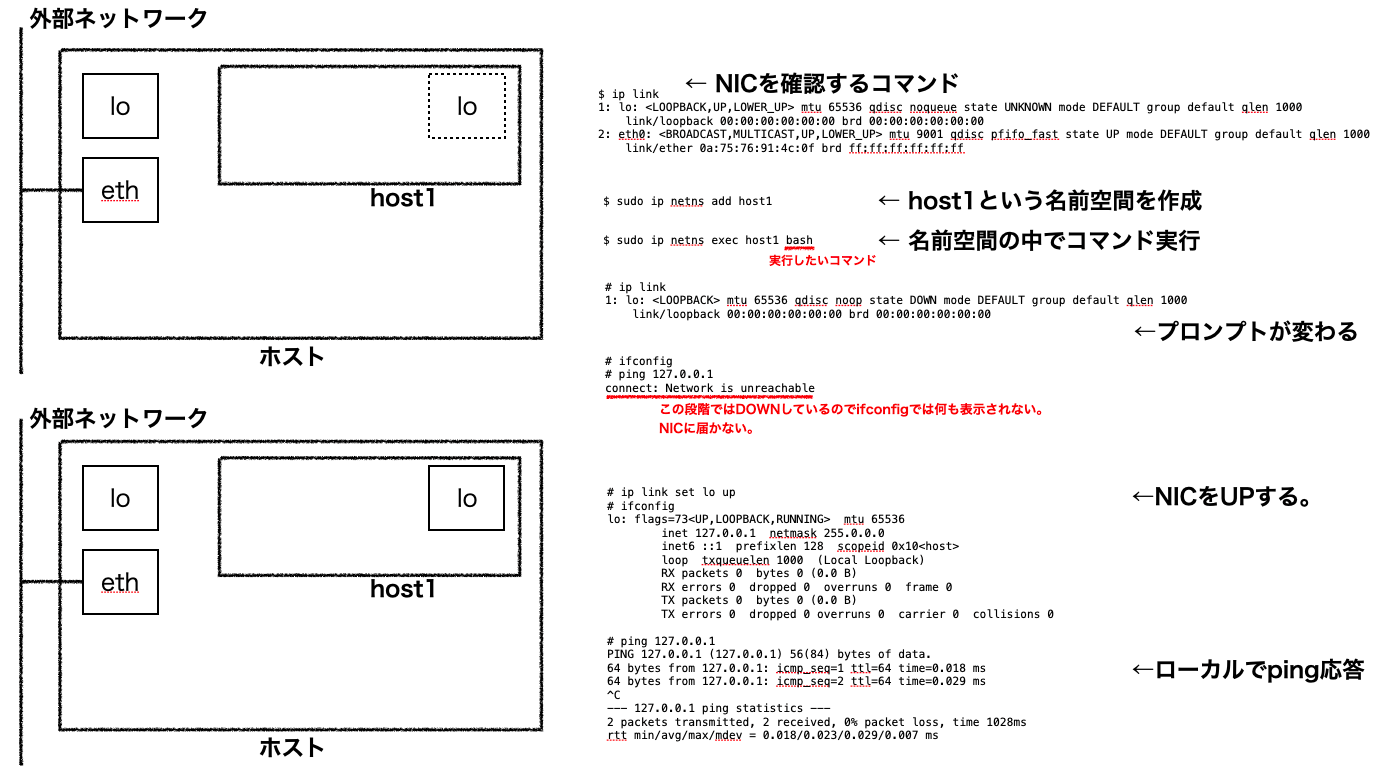
▲ 図はホストの上に2つの名前空間を切ったコンテナ内に2本のvethトンネルをひき、仮想スイッチでNICに繋いでいる様子。以下手順[1]で作成。
作成手順
# ネットワーク名前空間を作成
$ sudo ip netns add ns1
$ sudo ip netns add ns2
# 仮想スイッチ(ブリッジ)とvethネットワークインターフェースを3本作成
$ sudo ip link add br0 type bridge
$ sudo ip link add name ns-veth1 type veth peer name br-veth1
$ sudo ip link add name ns-veth2 type veth peer name br-veth2
$ sudo ip link add name rt-veth type veth peer name br-veth3
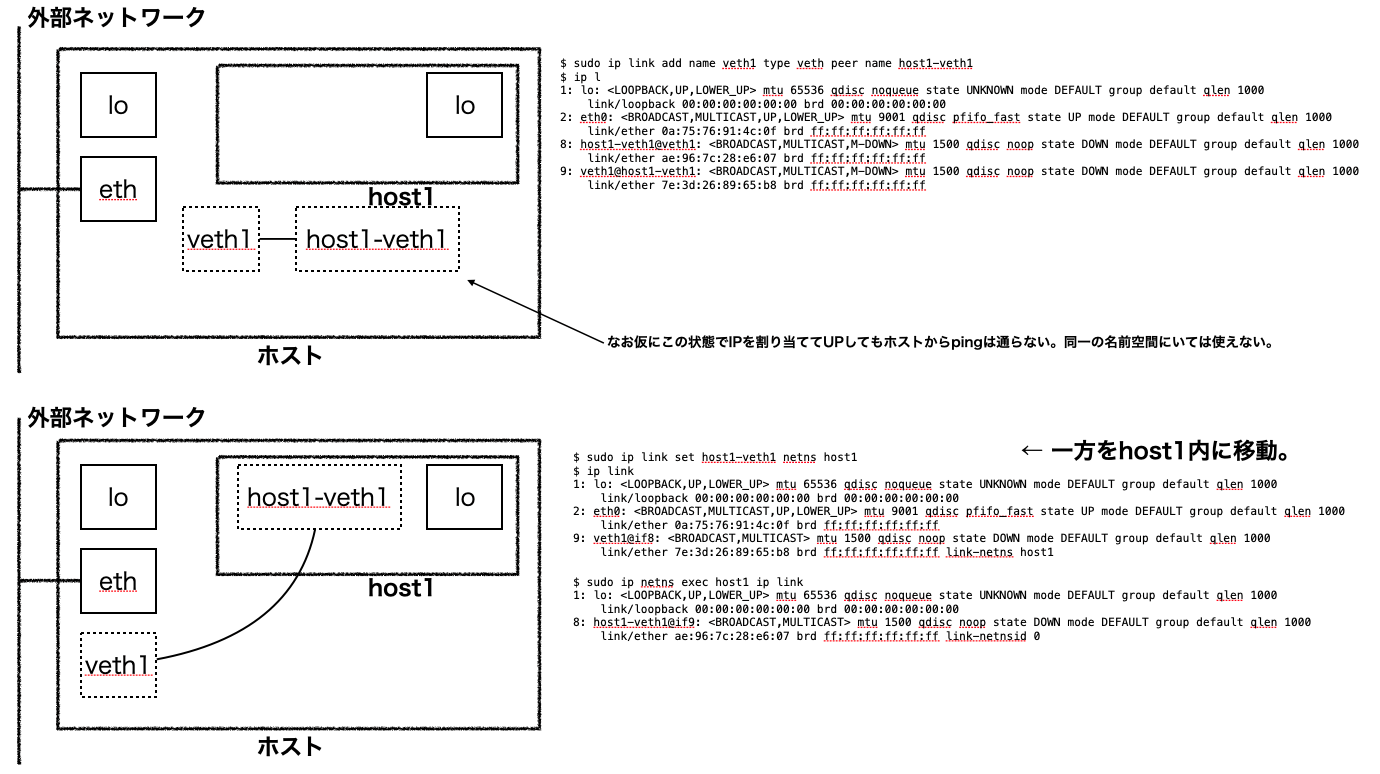
# 各vethのトンネルの終端を適切な名前空間のもとに配置
$ sudo ip link set ns-veth1 netns ns1
$ sudo ip link set ns-veth2 netns ns2
$ sudo ip link set dev br-veth1 master br0
$ sudo ip link set dev br-veth2 master br0
$ sudo ip link set dev br-veth3 master br0
# 仮想スイッチと各仮想NICをUP
$ sudo ip netns exec ns1 ip link set ns-veth1 up
$ sudo ip netns exec ns2 ip link set ns-veth2 up
$ sudo ip link set rt-veth up
$ sudo ip link set br-veth1 up
$ sudo ip link set br-veth2 up
$ sudo ip link set br-veth3 up
$ sudo ip link set br0 up
# IPアドレスの付与
$ sudo ip netns exec ns1 ip addr add 192.168.0.1/24 dev ns-veth1
$ sudo ip netns exec ns2 ip addr add 192.168.0.2/24 dev ns-veth2
$ sudo ip addr add 192.168.0.100/24 dev rt-veth
# IP フォワード有効化
$ sudo su
# echo 1 > /proc/sys/net/ipv4/ip_forward
# 隔離したネットワーク名前空間のデフォルトゲートウェイを設定
$ sudo ip netns exec ns1 ip route add default via 192.168.0.100
$ sudo ip netns exec ns2 ip route add default via 192.168.0.100
# 物理NICへの転送時にNATする。
$ sudo iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eth0 -j MASQUERADE
この構成は$ docker run <イメージ名>でdockerコンテナを起動した時に作成されるものとほぼ同じ。
以下の図は次の記事を元に試したものをまとめたもの。

まとめ
コンテナ - インターネット通信
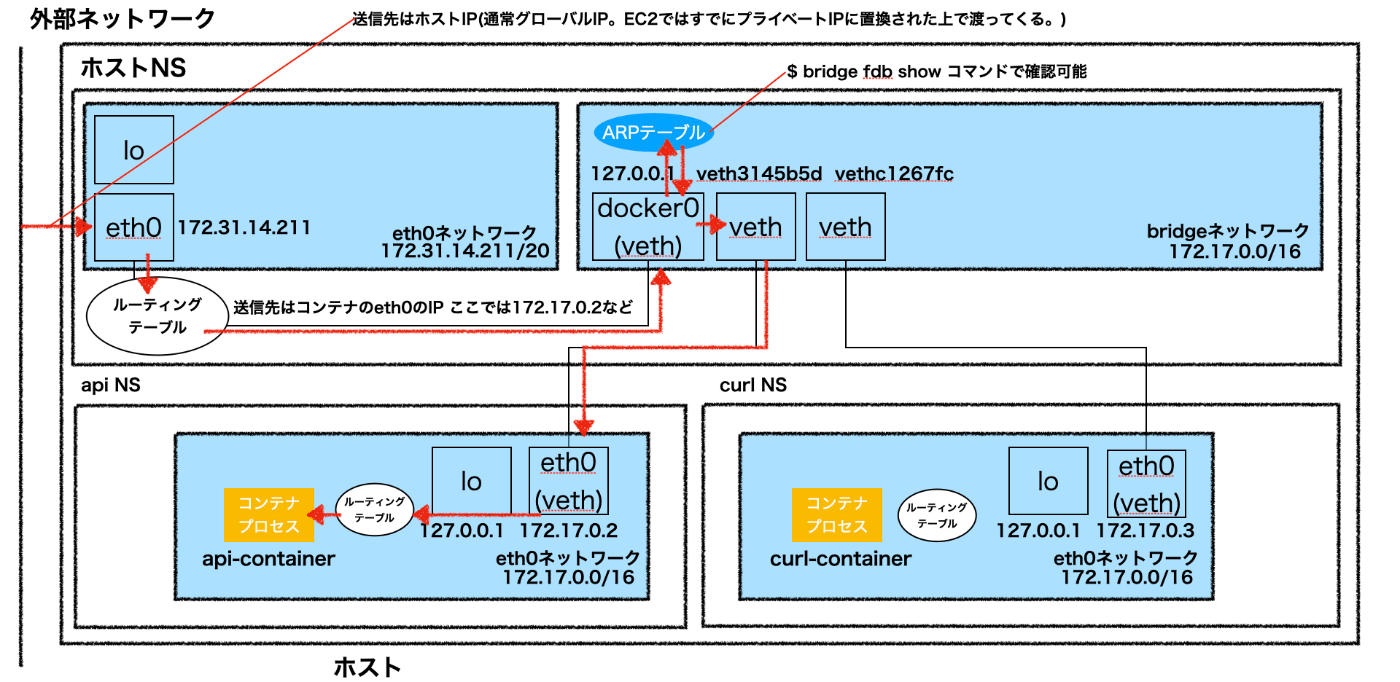
コンテナ間通信 → 詳細は後述

参考
Overlayfs (UnionFS)
Linux用のファイルシステムとして知られる「UnionFS」の実装の1つ。
複数のイメージレイヤー(ディレクトリーやファイル)を重ね合わせて1つのファイルシステムとして見せる。[2]
$ sudo mount -t overlayfs -o lowerdir=<下層のディレクトリ>,upperdir=<上層のディレクトリ> overlayfs <Overlayディレクトリ>
chroot
実行した階層をrootディレクトリと見做してファイルシステムを隔離する。
$ sudo chroot <ルートディレクトリにするディレクトリ> <変更後に実行するコマンド>
指定のディレクトリをrootとして隔離し、そのrootにおいて指定のコマンドを実行する。
→ ここでコマンドを省略すると$SHELL環境変数に書かれた値(通常/bin/sh)を実行する。
→ 逆にいうと新しいroot直下には予め/bin/shや指定の実行可能なファイルが置かれている必要がある。
例えば、予めこのパスにAlpine Linuxのディストリビューションのtarアーカイブをダウンロードし、展開しておくことで $ sudo chroot . /bin/shが実行できる。
ただし、task_struct構造体のrootのみ変更しpwdを変更しない。これによりプロセスが CAP_SYS_CHROOT Capability (chrootシステムコール実行権限) を持っている場合に脱獄できる。
= cd .. ではタスク構造体のpwdとrootに一致したかどうかでバリデーションするため、pwdとrootに乖離が発生すると隔離されたrootで停止せず、本物のrootまで遡上できる。
→ 改善されてpivot_rootシステムコールが使われる。
- https://container-security.dev/namespace/chroot-and-pivot_root.html
- https://linuxcommand.net/chroot/
コンテナイメージ
OSイメージや必要なものがtarで圧縮したもの。docker saveでtar圧縮し、docker loadで読み込める。
これはDockerHubなどを経由せず直接ファイルとしてイメージを移植できるということ。
コンテナ実行の仕組み
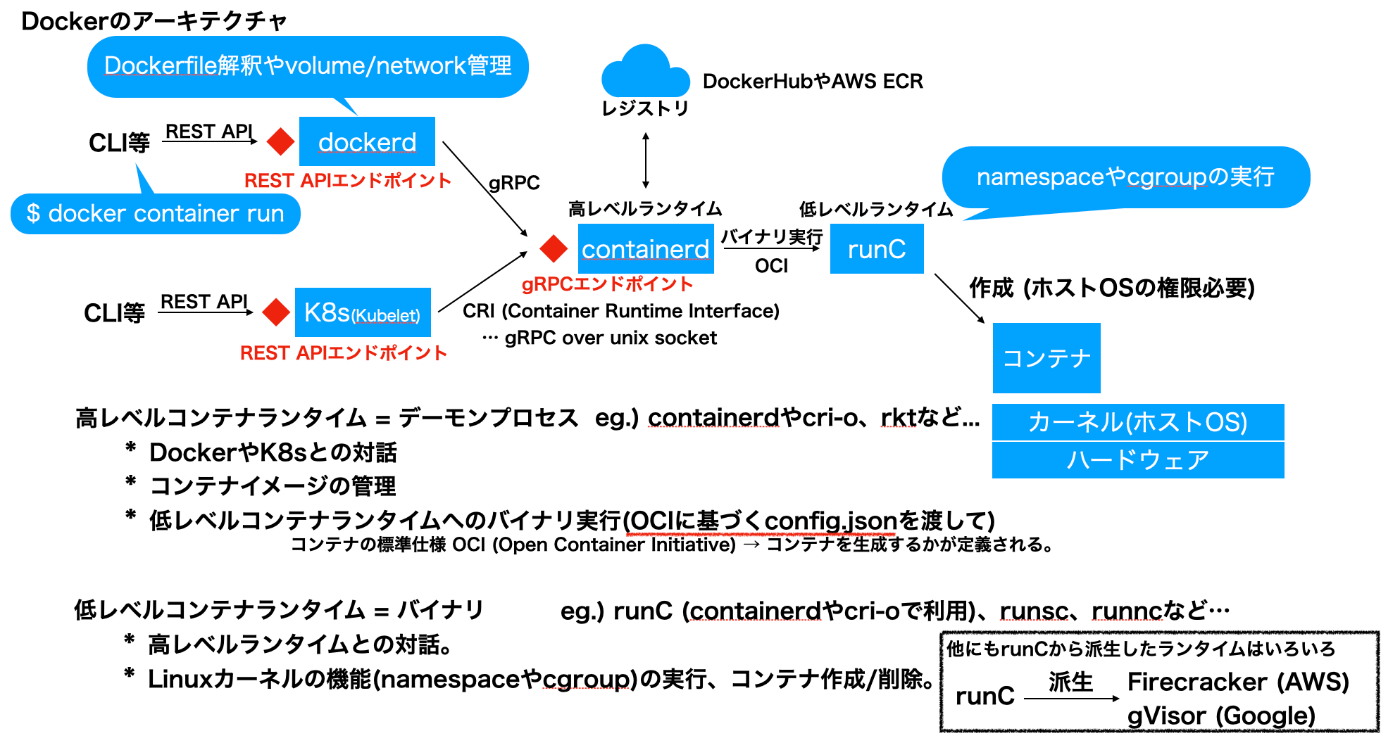
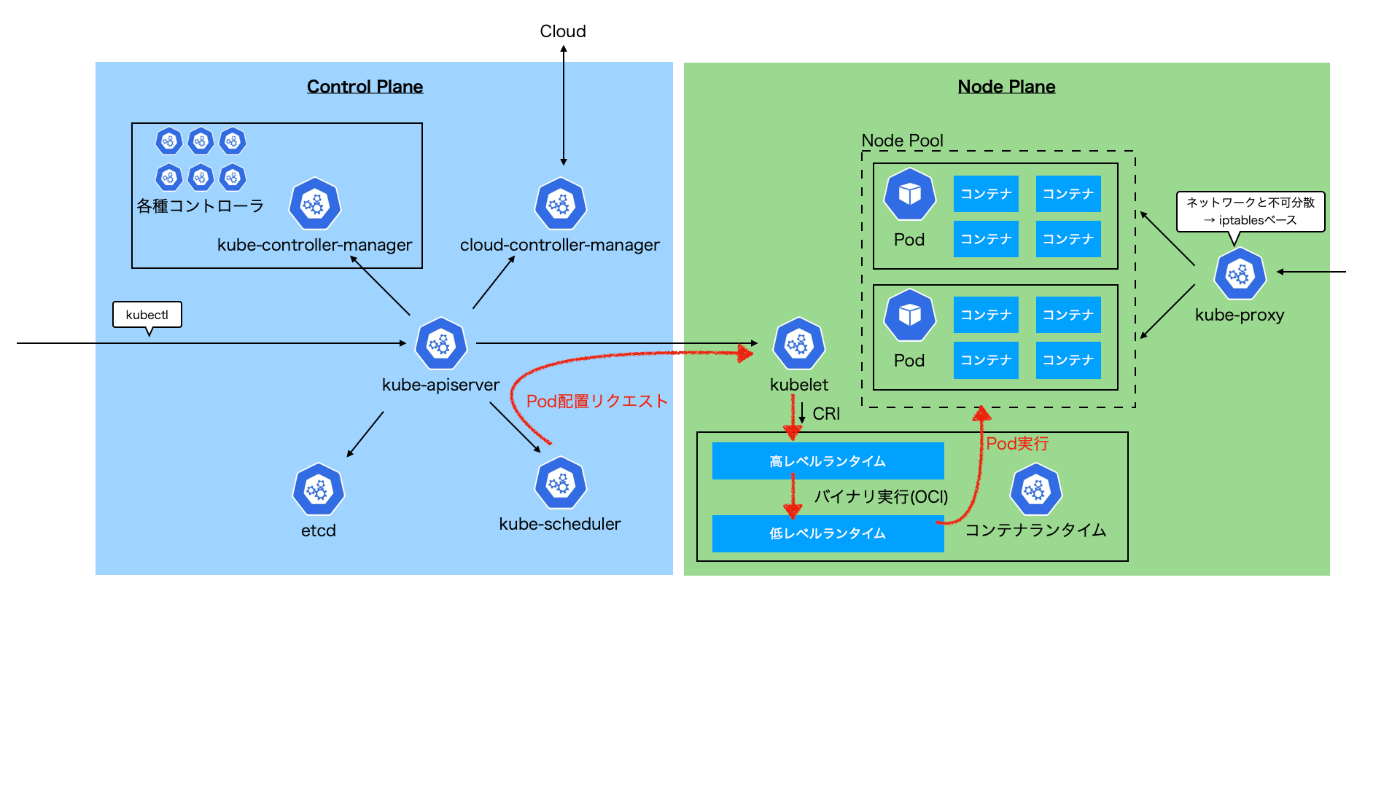
上記のnamespaceやpivot_root、cgroupなどで実際に隔離された空間(コンテナ)を作成/削除するのはコンテナランタイム(とりわけ低レベルランタイム)。dockerdがCLIを解釈しランタイムにリクエストされる。
dockerdがAPIエンドポイントであることを確認するために稼働中のコンテナ一覧を取得するAPIを叩いてみる。[3]
$ docker version
(略)
Server: Docker Engine - Community
Engine:
Version: 20.10.7
API version: 1.41 (minimum version 1.12)
$ curl --unix-socket /var/run/docker.sock http://v1.41/containers/json | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 803 0 803 0 0 80573 0 --:--:-- --:--:-- --:--:-- 89222
[
{
"Id": "2353cdbf0fa6470ec56a7a5af381482f5d2e072054087401686427c11d80be17",
"Names": [
"/stupefied_mendel"
],
"Image": "kernel_learning",
"ImageID": "sha256:a209b7680e51bce67dfa2efbf38ad0e8a6f8ec30b3d858b3bbd00b213fd508c2",
"Command": "/bin/sh",
"Created": 1681551035,
"Ports": [],
"Labels": {},
"State": "running",
(略)
Docker Engine
次の3つの主なコンポーネントを持つクライアント・サーバ型アプリケーション。
- サーバ (デーモンプロセス)
- REST API
- CLIクライアント
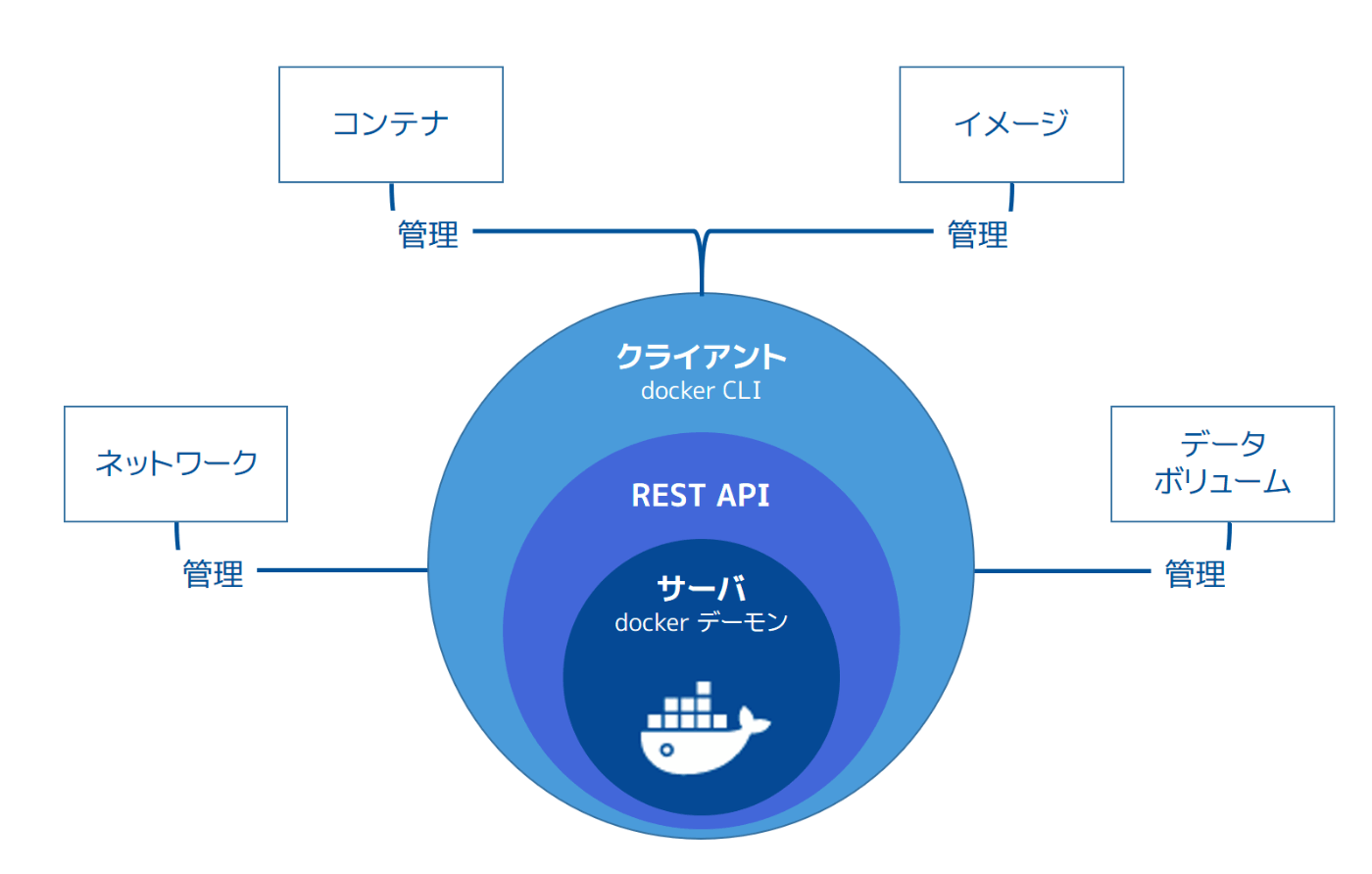
ここでいうサーバの中にdockershimやrunc、生成されるコンテナも含まれる。
- https://docs.docker.jp/v1.12/engine/understanding-docker.html
- https://www.publickey1.jp/blog/20/firecrackergvisorunikernel_container_runtime_meetup_2.html
- https://xtech.nikkei.com/atcl/learning/lecture/19/00095/00001/?P=8
- https://docs.docker.com/engine/api/v1.41/#tag/Container/operation/ContainerList
コンテナ間通信
同一ホスト上のコンテナ間通信は前述のようにbridgeネットワーク内でルーティングされる。
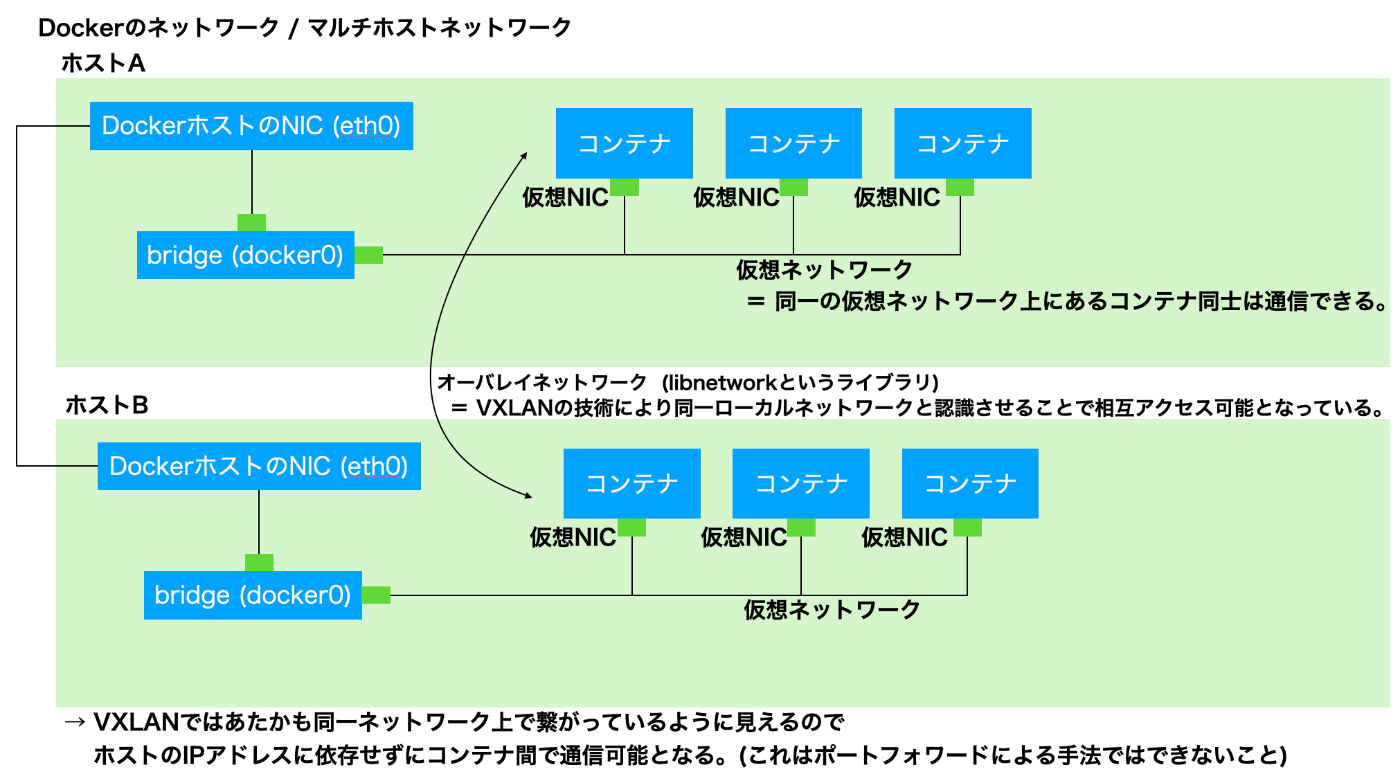
ホストを跨いだコンテナ間通信は?
→ マルチホストネットワークでは、複数のホストに跨るコンテナ間はVXLANの技術により同一ローカルネットワークと認識させることで相互アクセス可能となっている。
マルチホストネットワーク
そもそもVLANとは? - 仮想的にネットワークセグメントを分割する技術。
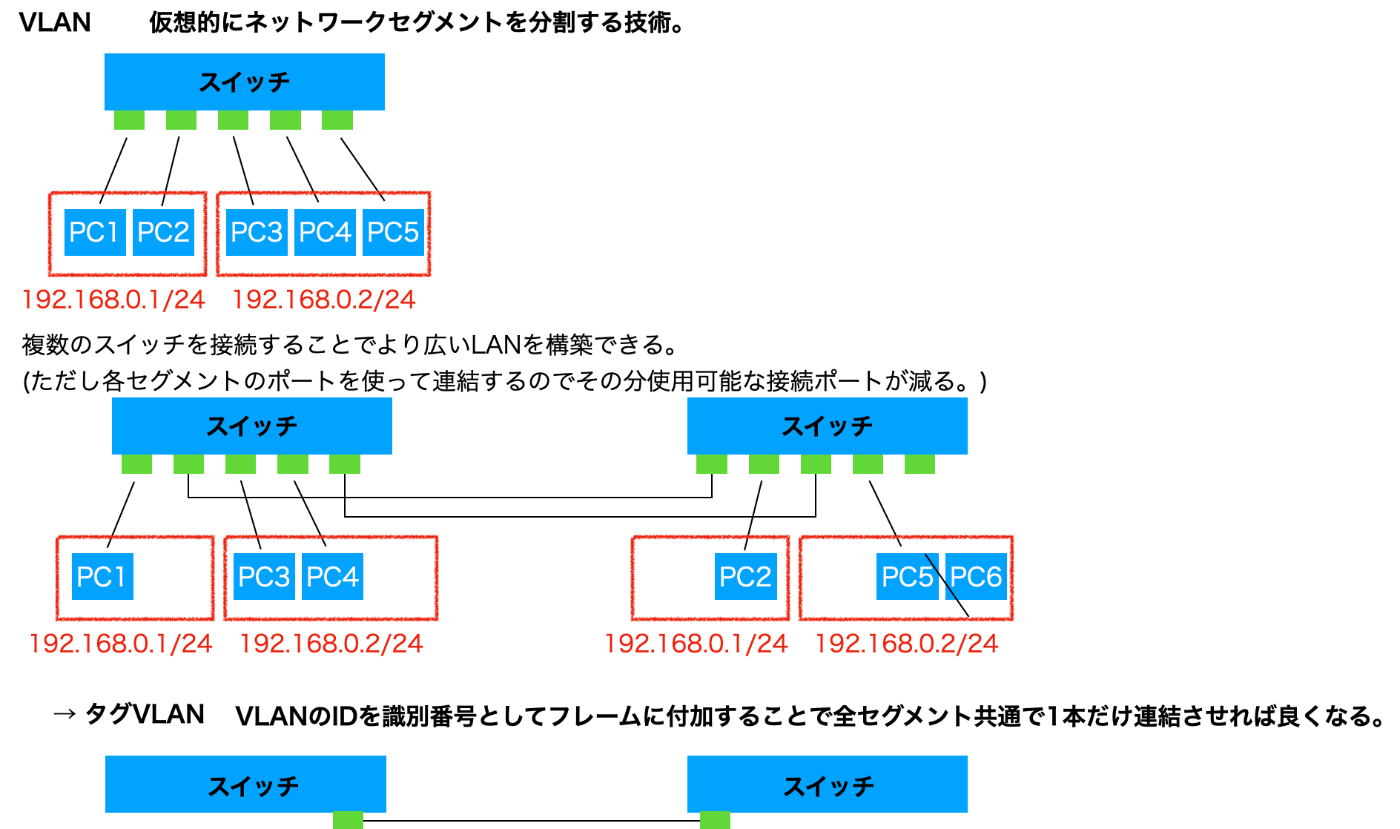
VLANのIDは12ビットなためそれより大きいネットワークが作れない。拡張されたのがVXLAN。
VXLAN
L2フレームを改変せずにL3ネットワークを超えて転送できる技術。
つまりオーバーレイネットワーク(L3ネットワーク上でL2ネットワークを実現している「L2層 over L3層」のプロトコル)。
通常、スイッチやルータを超える度にヘッダ情報は付け替えられるが、VXLANではフレームにUDP/IPでカプセル化する
ことで中身をそのまま宛先まで届けることができる。
→ あたかも送信元と宛先のホスト同士が同一IPアドレスのセグメント上で直接やりとりしているかのように見える。
面白かった。Golangでコンテナを作る。
Kubernetes
コンテナオーケストレーションツール。
各コンポーネントと役割
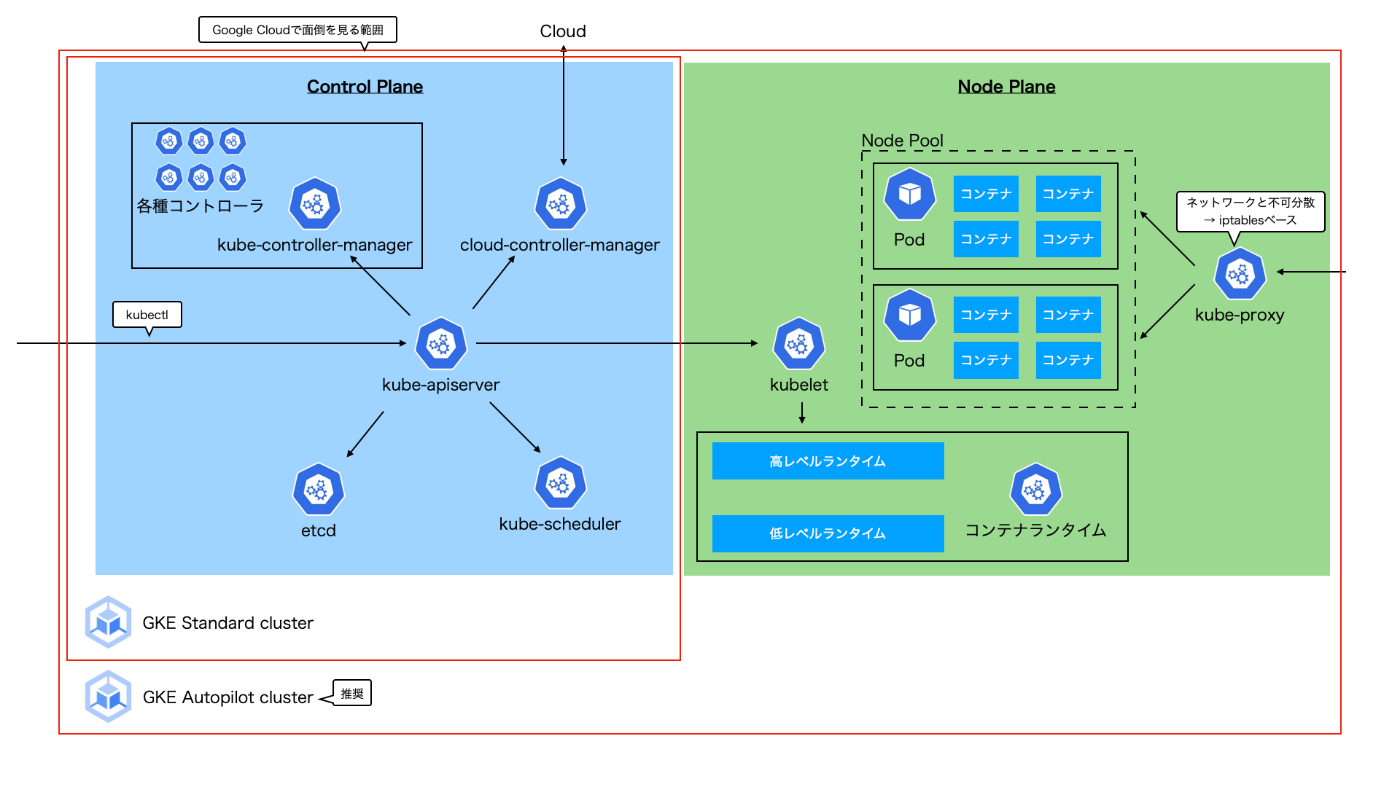
etcd
クラスタ情報を保管するキーバリューストア。
kube-scheduler
PodをどのNodeにデプロイする。リソース要求やアフィニティなどの条件を考慮して最適なノードにスケジュールする。
kube-controller-manager
クラスタ内のリソースの状態を監視し、調整を行う。
各コントローラが望ましい状態と現在の状態の間の差異を解決し、クラスター全体の安定性とスケーラビリティを確保する。
kube-api-server
すべての操作を処理するAPIエンドポイントとしてユーザーとの対話やクラスター内の他のコンポーネントとの通信を担当する。
アクセスの認証認可、実行を担う。
kube-proxy
クラスター内のポッド間通信とポッドから外部リソースへの通信を管理する。
ルーティング、ロードバランシング、およびサービスディスカバリなどの機能を提供し、ポッドとサービスの間の通信を仲介します。
kubelet
schedulerからのPod配置指示をapiserverを介して受け取り、コンテナランタイムを操作してPodを作成する。
Podやノードの状態を監視しapiserverにレポートする。
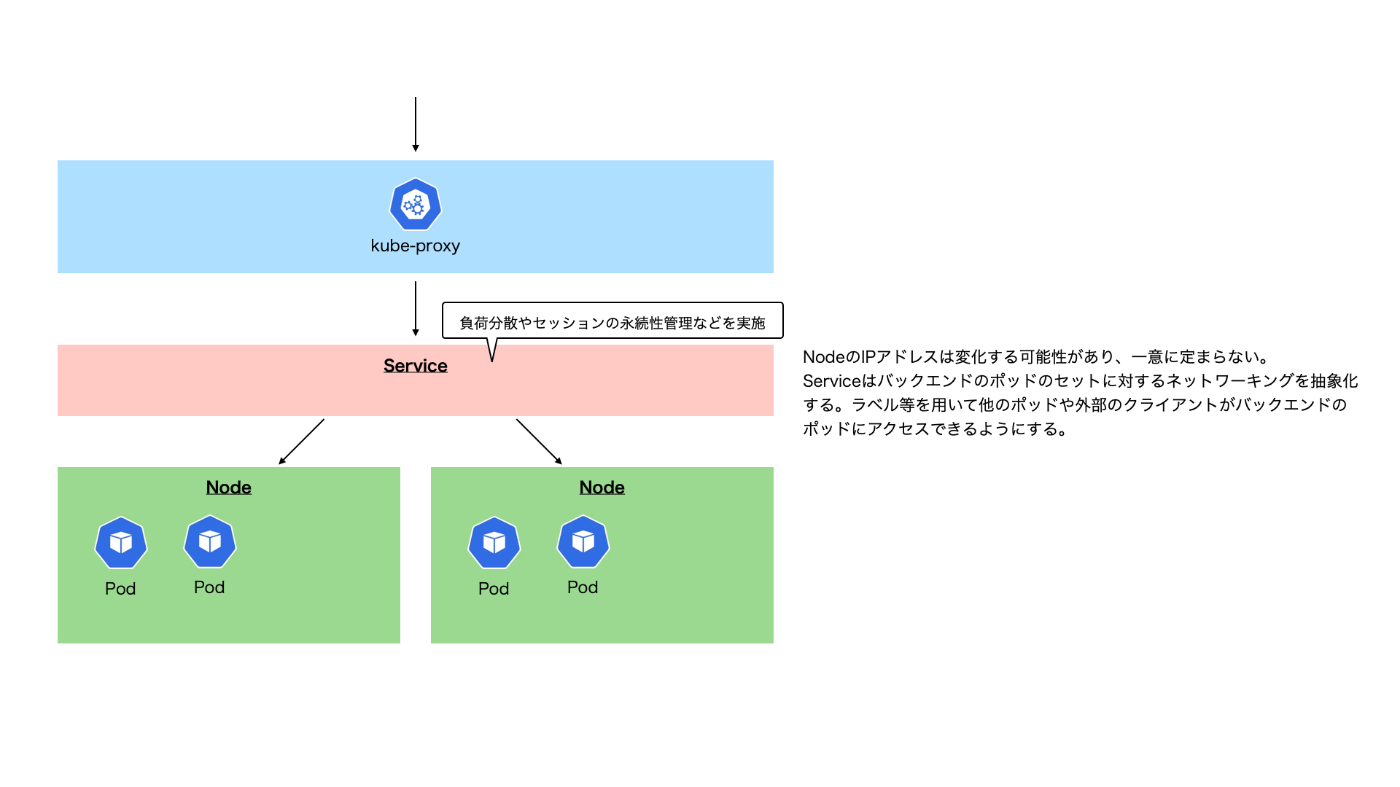
Service
k8sクラスター内のネットワーキングを抽象化し、マイクロサービスアーキテクチャの構築やスケーリングをサポートする。
Ingress
クラスター内のサービスに対する外部からのアクセスを管理する。
クラウドやオンプレミスなどのクラスタ外部のロードバランサを使用する形式と、クラスタ内部にIngress用のPodを起動する形式がある。
Ingressコントローラーを利用する。
- ルーティング
- ホスト名ベース、パスベースのルーティング
- TLS終端
- TLS/SSLトラフィックの終端処理する。
- ServiceのLBでは終端しない = 接続先からするとリクエスト送信元は接続元クライアントになる
- ロードバランシング
- 複数のサービス間でトラフィックを均等に分散する。
- ※ ServiceのLoadBalancerはL4LB。Ingressはそれに被せるL7LB。
- ホストベースの仮想ホスティング
- 同じIPアドレスやポートを共有しながら、異なるホスト名に基づいて複数のサービスを公開する
※ Ingress はクラスタ外部からのトラフィックを制御するもの、対して内部の通信はServiceを利用。Service DNS名を通じた内部通信を制御可能。
Pod
Podには固有の仮想IPアドレスが割り当てられPod内のコンテナはIPアドレスやポート等を共有する。
1Pod1コンテナが理想。
ReplicaSet
Self-Healingを支える仕組み。ノードやポッドの障害時に自動でPodを配置しなおし、事前定義された状態を維持する仕組み。
ReplicaSetで定義されたPod数を更新することでPod数が調整され、その後はその定義に従った状態が維持される。
Deployment
ReplicaSetを管理し、ローリングアップデートやロールバックを実現する。
Persistent Volume Claim
ディスク定義。
ConfigMap
KeyValueのconfig情報
Secret
クレデンシャル情報を格納する。
StatefulSet
ステートフルな構成sとする場合。
参考
アクセス制御
RBAC (Role Base Access Control)
以下2種類ある。
- UserAccount
- 対象はユーザ
- AWSやGCPと連携させることが可能。
- ServerAccount
- 対象はプロセス
- namespace内で利用可能
- Pod起動時には必ずServerAccountを当てる必要がある。
以前は属性ベースのアクセスコントロール(ABAC)だったが現在はRBACがデフォルト。
参考
その他のエコシステム
エコシステムとは、関連する異なる用途をもった概念・機能・サービスを組み合わせてメリットを最大化して享受する仕組みのこと。
参考
Helm
Linuxのaptやyum同様、Kubernetesのパッケージ管理ツール。デプロイメントを簡素化し、スケーラビリティを向上させる。
Chartと呼ばれるテンプレートを用いてソフトウェア構成を定義する。
CoreDNS
レガシーなkube-dnsに替わりクラスタにおいてDNSの役割を果たす。
CoreDNSサービスがCoreDNS Podに負荷分散負荷分散させる。
Prometheus
サービス監視ツール。
JP1やDatadogなどの従来のエージェントによる監視ツールはPush型であり、監視対象のサーバに同級したエージェントが監視サーバに情報を送信する。
しかし、コンテナやサーバのオートスケールが発生するような動的な状況においてはこれらの構成は難しい。
PrometheusはPull型の監視手法。
Prometheusサーバは以下の3コンポーネントで構成される。
- Retrieval
- 被監視サーバに導入したexporterからリソース情報を取得する
- Storage
- 取得した情報の格納庫
- PromQL
- リソース情報を可視化するコンポーネント
- ただし、単純なグラフしか出力されず可視性が低いため、
GrafanaやKibanaなどサードパーティの可視化ツールを活用するこケースが多い。
Fluentd
ログデータの管理。
各Dockerコンテナの持つLoggingドライバにFluentdを指定しログデータをFluentdに送信する。
出力プラグインによりさらに外部のS3やGCSに転送することも可能。
参考
Probe
- Startup Probe
- 他のProbeを開始可能かを検知するためのProbe
- 最大5min
- 起動に時間のかかるアプリケーションの場合に有用
- Liveness Probe
- アプリケーションプロセス自体は稼働しているが応答しないコンテナを検知する。
- Readiness Probe
- コンテナにトラフィックを流していいかを検証する。
Google Kubernetes Engine (GKE)
以下2種類のモードがある。
- Standard
- Autopilot
Autopilotではユーザが直接NodeにSSHが禁止されていたり、Google提供のContainer-Optimized OSのみが利用可能であったり制限はある。
冗長性
シングルゾーンクラスタ
- コントロールプレーン: 単一ゾーン
- ノードプレーン : 単一ゾーン(コントロールプレーンと同一ゾーン)
マルチゾーンクラスタ
- コントロールプレーン: 単一ゾーン
- ノードプレーン : マルチゾーン
リージョンクラスタ (Autopilotモードではこれ)
- コントロールプレーン: マルチゾーン
- ノードプレーン : マルチゾーン
ネットワーク
VPC ネイティブクラスタ
- 推奨。Autopilotモードではこれ。
- クラスタ内でPodやServiceの使用するIPアドレス範囲をノードが作成されるVPCネットワークと同一のネットワークに揃える。
- 各リソースにVPCサブネットを割り当てることでVPCに関連する機能(ピア接続、CloudVPN、ネットワークエンドポイントグループによる負荷分散、FWなど)を直接利用できるようになる。
- 限定公開クラスタを設定可能。
プライベートクラスタ(限定公開クラスタ)
- 通常のGKEクラスタは、ノードに対してパブリックIPが付与されており、Nodeportを利用してワークロードを公開することで外部からアクセスできる。
- コントロールプレーンに対してはパブリックエンドポイントが提供されており、インターネットからクラスタに対するkubectlによる操作が可能。
- 承認済みネットワーク を設定することでパブリックエンドポイントへのアクセス元IPを制限できる。
ここで、限定公開クラスタを設定することで、ノードにはプライベート IP アドレスのみが付与されるようになる。

ルートベースクラスタ
- クラスタ内でPodやServiceの使用するIPアドレス範囲をノードが作成されるVPCネットワークと異なるネットワークとする。
クラスタのスケーリング
ノードのスケーリング
ClusterAutoscaler
Node自体のスケーリング。
Node Auto-Provisioning (NAP)
- スケジューリングされたPodサイズに応じて適切なマシンサイズをプロビジョニングし、ノードプール(=クラスタ内で同じ構成を持つノードのグループ)単位で増減させる。
- GKE AutopilotではNAPを利用してプロビジョニングされている。
Podのスケーリング
Horizontal Pod Autoscaler (HPA)
- 水平スケール
- CPU/メモリなどのインスタンスメトリクスに基づいたスケーリングのほか、Pub/Subキューのメッセージ数を元にしたスケールなども可能。
Vertical Pod Autoscaler (VPA)
- 垂直スケール
- 以下の更新モードが提供される。
- Off : 推奨値を算出するのみ
- Initial : 既存のPodの再起動は伴わない
- Auto : 既存のPodの再起動を伴う
- ユースケース
- 基本HPA推奨。Offモードとして推奨スペックの見積もりに利用する用途としては有用。
Multidimensional Pod AutoScaler (MPA)
- HPAとVPAの併用版。
- ユースケース
- CPU UtilizationベースでPod数をスケーリングさせつつ、OOM予防のためにメモリベースの垂直スケールも含めるなどの場合に有用。
セキュリテイ
Workload Identity
特定のPodからのGoogleCloud内へのリソースアクセスを与える場合、クラスタにIAMサービスアカウントを設定すると全てのPodにアクセス権を当ててしまう。
→ k8sのリソースであるサービスアカウントとIAMサービスアカウントを紐づける(Workload Identity)ことでよりきめ細かいアクセス制御が可能となる。
オートヒール
Node Auto Repair
- UnhealthyなNodeを自動的に再作成する。
オートアップグレード
クラスタのアップグレードにおける運用負荷を軽減する。
リリースチャネル
- リリースチャネルにクラスタを登録することでControl PlaneのみではなくNode Planeもバージョンアップグレードもマネージドに更新される。(Autopilotモードでは自動でリリースチャネルに登録される。)
- Rapid、Regular、Stableの3つのチャネルの種類を提供。
- 予めメンテナンスウィンドウを指定し、アップデートの適用時間帯を指定することが可能。
ロールアウトシーケンス
- 複数クラスタ間での自動アップグレードの順序を制御する。
- dev環境→stg環境→prd環境の順でアップグレードを適応できる様にするなど。
アップグレード戦略
- サージアップグレード : ローリング方式。一時的に縮退運転となりうる。
- Blue/Greenアップグレード : 一時的にノード数が2倍になる分コストにはなる。ロールバックは迅速。
他
Cloud DNS for GKE
クラスタ内のDNSコンポーネント(kube-dns)をCloud DNSに拡張したもの。
NodeLocal DNSCacheアドオンを有効にすることで各NodeでDNSキャッシュが可能。
Backup for GKE
アドオン。GKE クラスタ全体をバックアップ可能。
参考
istio [未まとめ]
マイクロサービスのメリット
- スケーラビリティ : ものりシックではスケールアップにコストがかかる。マイクロサービスは必要なコンポーネントのみスケールできる。
- 更新容易性 : 特定のコンポーネントの更新の際に他への影響が最小限。APIで素結合になってるのでIN/OUTがテストされていれば全体の結合テストを複数パターン実施しなくて良くなる。
- 大人数で開発 : APIで素結合担っているので開発速度が上がる。
デメリット
- コンポーネント間の通信のメッシュ化 : カナリアリリースでトラフィックを分割したり、モバイル/PCで分けたりさまざまなトラフィックがコンポーネント間に発生。管理が困難
- トレーサビリティとトラブルシュート : アプリケーションが遅いみたいな時にどこで遅延しているのか分かりにくい、問題が発生した時に困る。
- 網羅的なテストしにくい : あるサービスのダウンが他に影響しないことを全てでテストすることは不可能。
マイクロサービスとして、何かのサービスが失敗していても何かのサービスは成功しているを許容することになるためテストケースが膨大になる。今までなら何かが成功しなかった時点で落ちていたはず。
→ 解決するのがIstio
コントロールプレーンという管制塔と、ノードプレーンというアプリケーションのPODが動く環境で構成。
PDOにはサイドカーとしてEnvoyプロキシというL4/7プロキシが立ち上がり、アプリケーションにわたるトラフィックをプロキシする。
外部からK8s環境に入ってきたトラフィックをコントロールプレーンが適切なenvoyに向けることでサービスメッシュを管理する。コントロールプレーンにあらかじめトラフィックの分割を定義しておくことでアプリ側に変更なくそうした分割可能。
トレーサビリティに関してはプロメテウスやGraffanaと連携してメトリクスの可視化を提供。
トラブルシュートやテストについてはカオスエンジニアリング的な考えで、Envoyプロキシが通信を遅延させたり勝手に400を返すとかでfault injectionできる。こてもアプリケーションに変更なく異常系をテストできる。
istioとはざっくり : マイクロサービスで複雑化したサービス間のメッシュを管理するもの