AWSリファアーキを読み解く
■ 記事の目的
アーキテクチャ設計において"なぜこれなのか?"を説明するのって結構難しいなと思う機会があり、そうした時に拠り所となるのが"実際他所ではどう使われているか"といった実績になると考えた。
AWS アーキテクチャセンターを端から眺めてみて、サービス自体の理解を深めるとともにアーキテクチャパターンを調査してまとめる。
AWS での DevOps Monitoring Dashboard
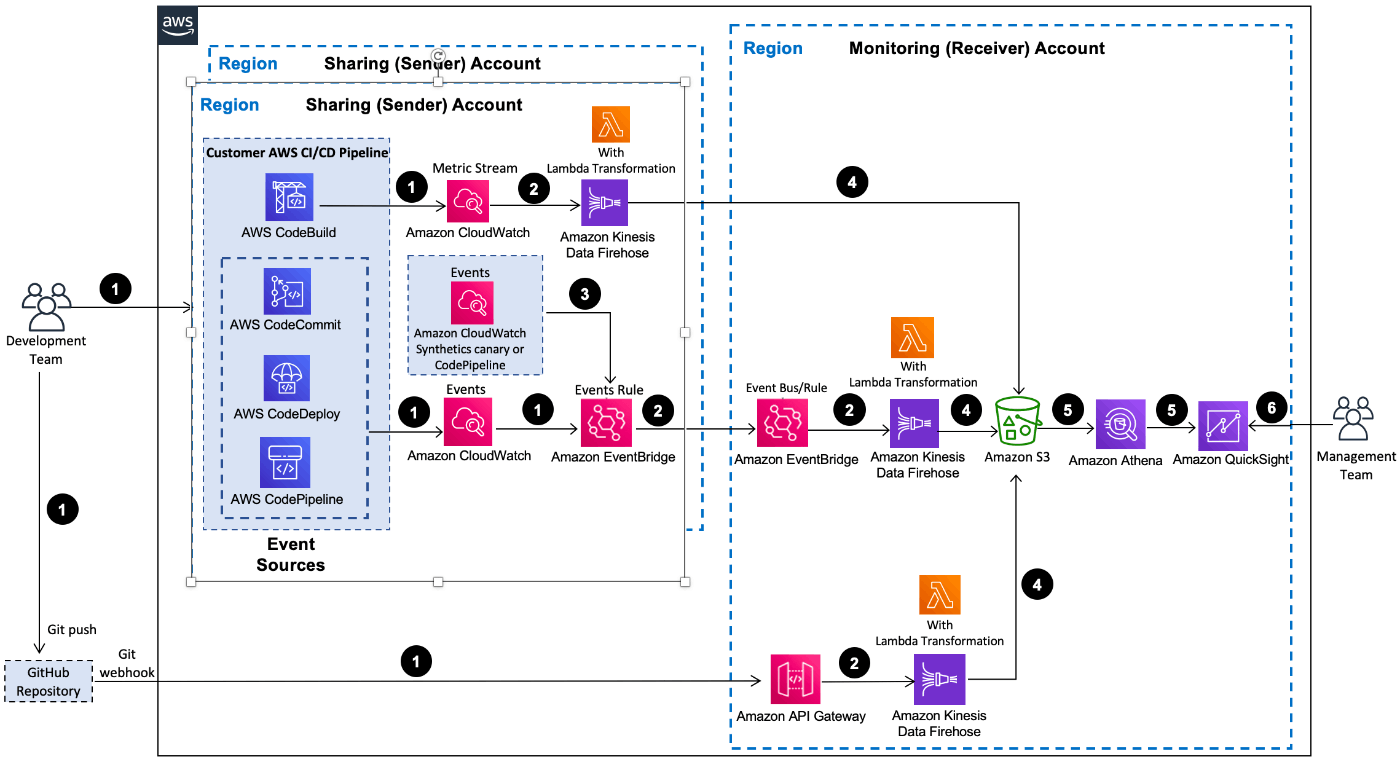
アーキ概要
メトリクスはKinesisFirehoseで分析用のアカウントのS3に流し、CloudWatchアラームやsyntheticsのイベントはEventBridgeを介して同じく分析用アカウントに流す。
アーキ図から受けた疑問
1. CICDのメトリクスを可視化してそんなに恩恵あるのか?そもそも何をみるの?
データ・ドリブンに意思決定を行う
モバイルアプリのビルドが遅ければ、ビルド速度を改善する仕組みを導入したり、インテグレーションテストの安定性が悪い時は、テストを安定させる仕組みを提供する
ソフトウェア開発のコンテキストにおける組織のパフォーマンス
DevOps のトップレベルパフォーマンス指標として以下4つ。
- リードタイム
- デプロイ頻度
- 変更の失敗率
- 平均修復時間
今までCICD環境を構築することはあったがそのメトリクスを取って開発/リリースのパフォーマンスをみることはしてこなかった。マネジメント的な立ち位置では開発効率の指標として有用なものとなるのだろうか。
技術的知見
メトリクス収集
- CodeBuildでは従来のビルドプロジェクトのメトリクスに加え、ビルド環境のコンテナのメトリクスが取れる。
-
CloudWatch Metric Streamを利用することでメトリクスをニアリアルタイムに配信可能となる。- 従来はメトリクスをサードパーティの監視サービスなどに渡す場合、定期的にポーリングする必要があったが、
CloudWatch Metric Streamを利用することでメトリクスをストリーミング配信することができ、ポーリングで回避できなかったラグを解消できるようになった。
- 従来はメトリクスをサードパーティの監視サービスなどに渡す場合、定期的にポーリングする必要があったが、
CloudWatch Synthetics
実態はCanaryと呼ばれるLambda関数。中身はNode.js(Puppeteer)かPython(Serenium)コードが自動生成された外型監視サービス。
既存の設計図から選択して構成するか独自コードを配置するかのオプションがあり、設計図から構築する場合には、WebページのURL監視やHTTP APIエンドポイントの監視などが選択できる。
Virtual Andon on AWS
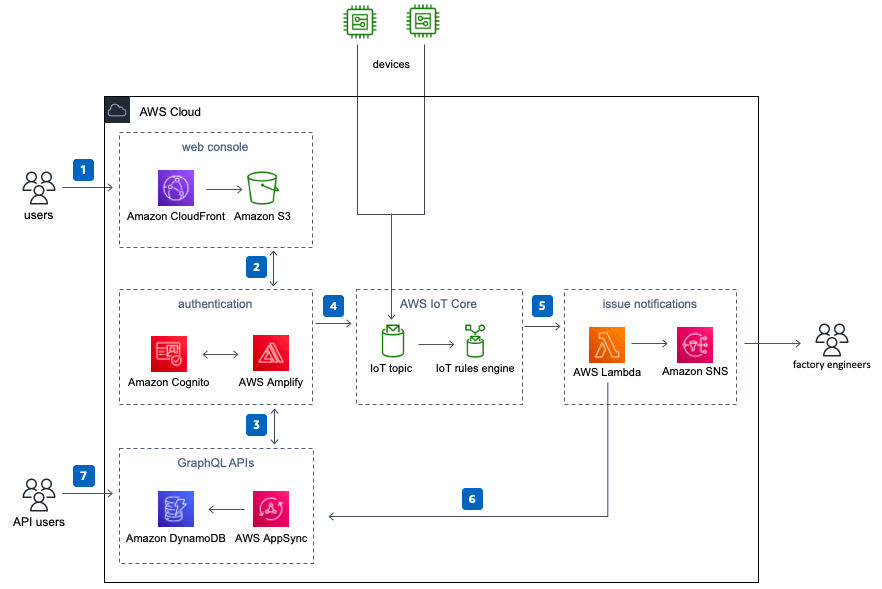
アンドンとは?
→ パトライトみたいなやつ。主に製造ライン等で異常を視覚的に伝えるのに使われたりする。
MQTT (MQ Telemetry Transport)
強み
- 不安定なネットワーク(帯域が狭い or 信頼性が低い)環境下でも動作する。
- メモリやプロセッサが制限されている非力なデバイスでも動作する。
- 処理量が少ないため消費電力を抑えられる。
特徴
- 軽量
- 固定ヘッダ長は2Bytes。メッセージは最大256MB(それ以上は分割が必要)。
- 3種類のQoS
- データの到達の保証と引き換えにアプリケーションに最適な転送効率を選択可能。
- パブサブモデル
- 多対多のメッセージのやりとり。
- Last Will and Testament
- publisherからの接続が失われた際に予め定めたメッセージをTopicに流す。
- 障害のリアルタイム検出ができるようになる。
QoS
QoS=0 |
at most once |
最大1回。届かないかも。 |
QoS=1 |
at least once |
少なくとも1回。重複して届くかも。 |
QoS=2 |
exactly once |
必ず1回。 |
※ 各QoSでのサーバ(デバイス)間のシーケンス
- QoS=0ではPublisherは送信後にメッセージを破棄するが、QoS=1ではPUBACKがBrokerから返されるまで保持し再送する。
- QoSはPub側、SUb側それぞれで指定し、Brokerとの間の通信におけるQoSを決めることができる(もちろんBrokerが対応するQoSのみ : なおAWS IoT Core ではQoS=2はサポートされない[1])。ただし、Publisherの指定するQoS以上の値を指定できない(指定しても同じ水準まで引き下げられる)。
- QoS1,2ではBrokerでメッセージを保存することができるため、ネットワークが瞬断してもその間のメッセージを再送することができる。 →
Durable subscribe
QoSを決める
基本的には QoS 0 でかまいません、確実に届けない課金情報などに 1 以上を使う感じでかまいません。
ちなみに QoS が上がれば上がるほど MQTT ブローカーの性能に影響します。
- 重複して届くリスク(QoS=1)と失報し得るリスク(QoS=0)を検討する。異常検知系(健康状態や防犯など)では失報の方が問題となるのでQoS=1,2を選択することになるのではなかろうか。
- QoSを上げることによる負荷を考慮する。シーケンスの通り、送受信するメッセージが増えることでBrokerの処理量が増加する。Brokerへの接続台数が増えると処理負荷が上がり、複数台のサーバで分散するなどが必要になりうる。
AWS での風力と太陽光の分析
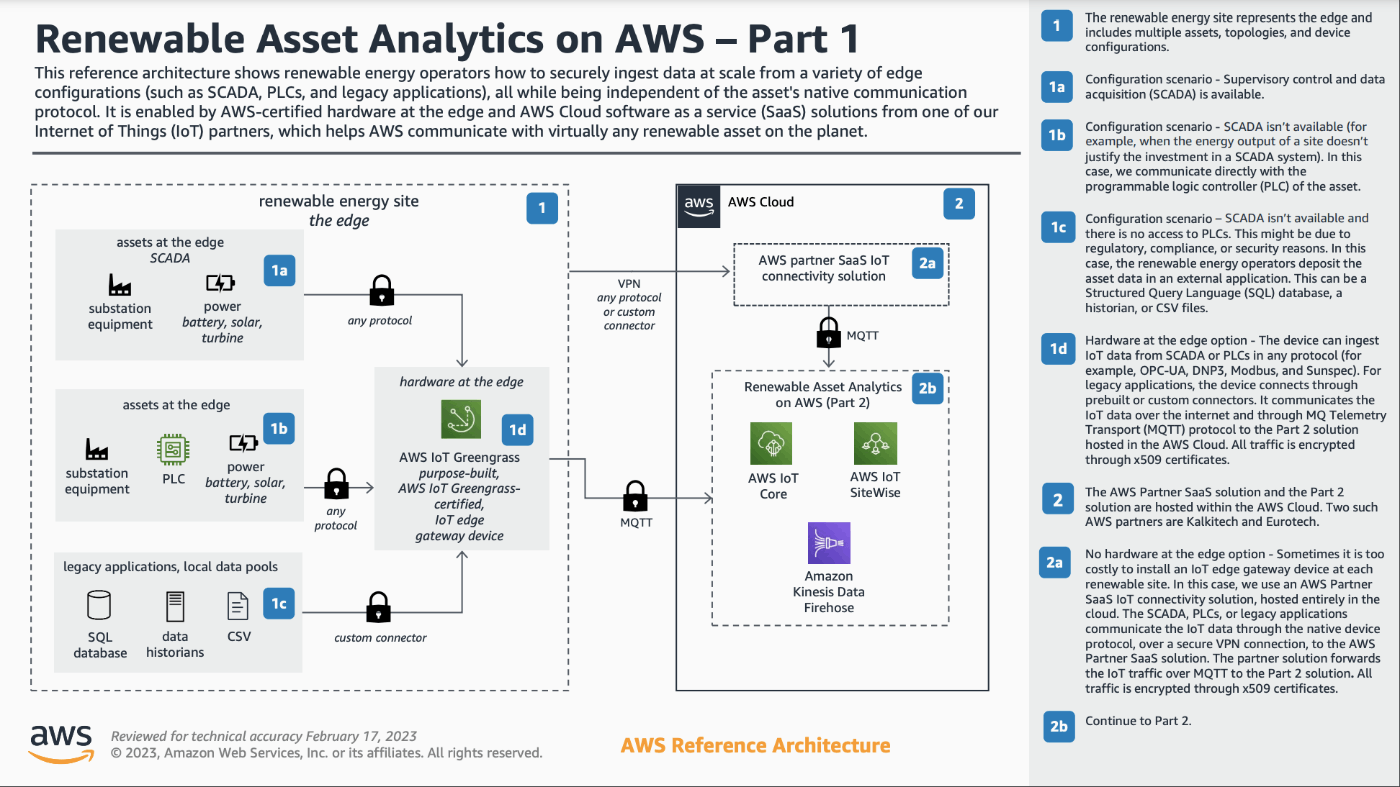

エッジデバイス
PLC (Programmable Logic Controller) とは
シーケンス制御(あらかじめ定められた順序または手続きに従って制御の各段階を逐次進めていく制御)を行う装置。
PLCはあらゆる分野の機械の制御を支えていて、工場設備だけでなく、家庭用家電製品にも使用されています。エアコンや食器洗浄機などの家電製品から、エスカレーターや自動ドアなどの設備、そして製造現場のFA(ファクトリーオートメーション)システムや発電所まで、PLCは効率的に機械を制御する必要があるさまざまな場面で活躍
PLCが機械を効率的に制御することに特化した装置だからです。あらゆる製造現場の制御装置には、耐久性、堅牢性、処理能力、信頼性、応答性などの性能、そしてプログラミングとメンテナンスの容易さが重要視されます。PLCは製造現場で使用される機器として優れた性能を発揮し、信頼性、堅牢性、そしてメンテナンスの容易さの点においても非常に高い性能を有します。
PLCとマイコン/PCの違い
PLC → プログラムに基づくシーケンス制御を行う。タイミング管理がしやすい。PCよりも反応速度が速く安価。
PC → 複数のプロセスが動いてることでタイミング管理困難(保証されていない)。
マイコン → PCには劣るが高性能。
PLCは製品でマイコンは単に部品。
巨大な工場では膨大な機械が同時に動き続けているため、それを一括して管理する必要が生じます。そうした場面ではPLCではなくコンピューターが使われ、それぞれの機械の制御をPLCが担当し、PLCから送られてくる情報処理をコンピューターが担うことも増えてきました。生産管理に特化したPC上で動作するシステム「SCADA」なども普及するようになっています。
https://www.sbbit.jp/article/cont1/44909
SCADA (Supervisory Control And Data Acquisition)
中央で管理するソフト。各機械の制御を担うPLCをコントロールするパッケージ。
各機器の入力データを受け取り、蓄積/表示、データに基づいて制御する。
各種業界での事例
AWS IoT Greengrass
従来AWS IoTがクラウド上で提供した機能をエッジデバイスに持ってきたもの。

(引用 : https://www.eureka-box.com/media/column/a27)
これまでは工場などに配置された各種デバイスで計測したデータをAWS IoTに送り、そこで処理していた。
これをGreengrassにすることで得られる恩恵は以下。
- 処理結果を得るまでのレイテンシ
- より近いエッジデバイスで処理して返すことができるため高速にレスポンスできる。
- eg.) 自動運転の車の計測データをクラウドで処理していたら衝突回避できない。
- データロストのリスク
- オフライン時、デバイスデータをクラウドに転送できないとロストすることになるがローカルに置いたGreengrassまでのアクセスが確保できていればそこに保持し、復旧時にリカバリするなどできる。
- データ漏洩のリスク
- できればインターネットに流したくない秘匿なデータをローカルで処理できる。
- コストメリット
- エッジで処理することでAWSとの通信量を減らせる。
- 処理元の計測データを一時保管する必要がなく保管コストが減らせる。
デバイス自体はいろんなメーカが出している機器にAWSが認定を行っている。こんな感じ
自身のデバイスでも動かせる。

アーキテクチャ例1 : MLOps

(引用 : https://www.eureka-box.com/media/column/a27)
センサーデータをGreengrass上で高速に処理しレスポンスする。
一方でそのデータをクラウド上に流し、機械学習モデルの構築に利用することで、Greengrassの処理を定期的にアップデートすることができる。
アーキテクチャ例2 : クラウドでのデータ活用(MQTTでIoT Core)

(引用 : https://pages.awscloud.com/rs/112-TZM-766/images/AWS-factory.pdf)
Greengrassで取得したデータをMQTTでAWS IoT Coreに送る。
まずデータ蓄積をするステップ。
→ Firehose経由でS3に投げ込む。DynamoDBの場合IoT Coreから直接ルールで転送できる。
データを処理するステップ。
→ DynamoDBやS3はデータ投入をトリガしてLambdaをキックできる。
IoT Core → S3にKinesisが必要なのは2023/10時点でも変わらず。
アーキテクチャ例3 : クラウドでのデータ活用(HTTPでIoT Sitewise)

(引用 : https://pages.awscloud.com/rs/112-TZM-766/images/AWS-factory.pdf)
AWS IoT Sitewise
産業機器データ活用における課題
- 機器ごとに異なるプロトコルの変換。
- データ送信の仕組み。
- データ収集/変換。
- データの可視化。
IoT Sitewiseではこれらを解消する。設備機器が扱える産業用の通信プロトコル(Modbus TCP や OPC UA 等)をAWSの対応するプロトコル(MQTTやHTTP等)に変換する必要があるが、ユーザ側ではこれらを意識することなくAWS上に機器データを送れる。
Sitewise Edgeゲートウェイを使いエッジデータを収集/構造化(変換)してクラウド上やオンプレ/エッジ上で可視化を提供する。
IoT Sitewiseでは各機器を1:1のアセットを作成し、階層構造をつけて管理することができる。
IoT Sitewise Edge
Greengrassコンポーネント(Greengrass上で稼働するアプリケーション)として提供されるローカルゲートウェイ(IoT Sitewise Edge)。以下の2つに分かれる。
- データ収集パック
- データ処理パック
データ収集パック
例えば、Publisherコンポーネント(IoT Sitewise Edge データ収集パック)をGreengrassに導入することでGreengrassで収集したデータをIoT Sitewiseへ送信できる。

なお、データ収集パックに依存せずともIoT Sitewiseへデータ転送する方法はその他に4つ存在する。
ユースケースとしては、Greengrasss(ゲートウェイ)も動かないような限られたリソースしか利用できないデバイスなどではSDK等でAPIを直叩きするか、より軽量なMQTTでIoT Core経由でSitewiseに送るなどの手法がある。

データ処理パック
Edge側でデータ処理や死活監視、データの可視化(ローカルネットワーク上のブラウザからアクセス可能) ← インターネットの接続状況に左右されない。

IoT Sitewise (クラウド側)
各機器と1:1で定義したアセットというオブジェクトを用いて管理。親子関係やグループ、階層構造を持って管理可能。
データの可視化においては簡易的なアプリケーションとして提供されるSitewise Monitorや、Grafana向けのプラグインとして提供されるものがある。
IoT Sitewise → IoT Core
IoT Sitewiseに登録した各アセット毎に定期的な測定値が送られてくる。
MQTT通知ステータスを有効にすることでIoT Coreの通知トピックにpublishされるようになる。
IoT Core → IoT Sitewise
IoT RuleでIoT Coreの状態変化をトリガしIoT Sitewiseアセットの値を書き換えるアクションを実行する。
IoT Analytics
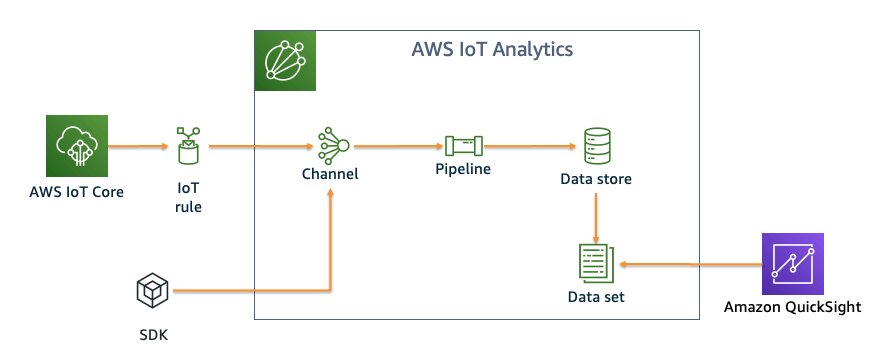
(引用 : https://catalog.us-east-1.prod.workshops.aws/workshops/03a4f79f-6971-441f-bc12-e8b755392d2c/ja-JP )
- チャネル
- データの受け口。ここで受けたRAWデータは指定した期間保存するよう定義することが出来、パイプラインを再実行させることで、指定した範囲のデータを再処理させることが可能。
- パイプライン
- チャネルで受け取ったデータを処理する。外部データソースとAWS Lambda関数を使用した処理などを実行できる。
- データストア
- パイプラインで処理されたデータの保存場所。実態としてはS3。
- データセット
- データストアに保存されたデータをSQLで集計し、データセットを作成することで、Amazon QuickSightやAmazon SageMakerなどからデータソースとして利用される。
アーキテクチャ例4 : データ分析と可視化
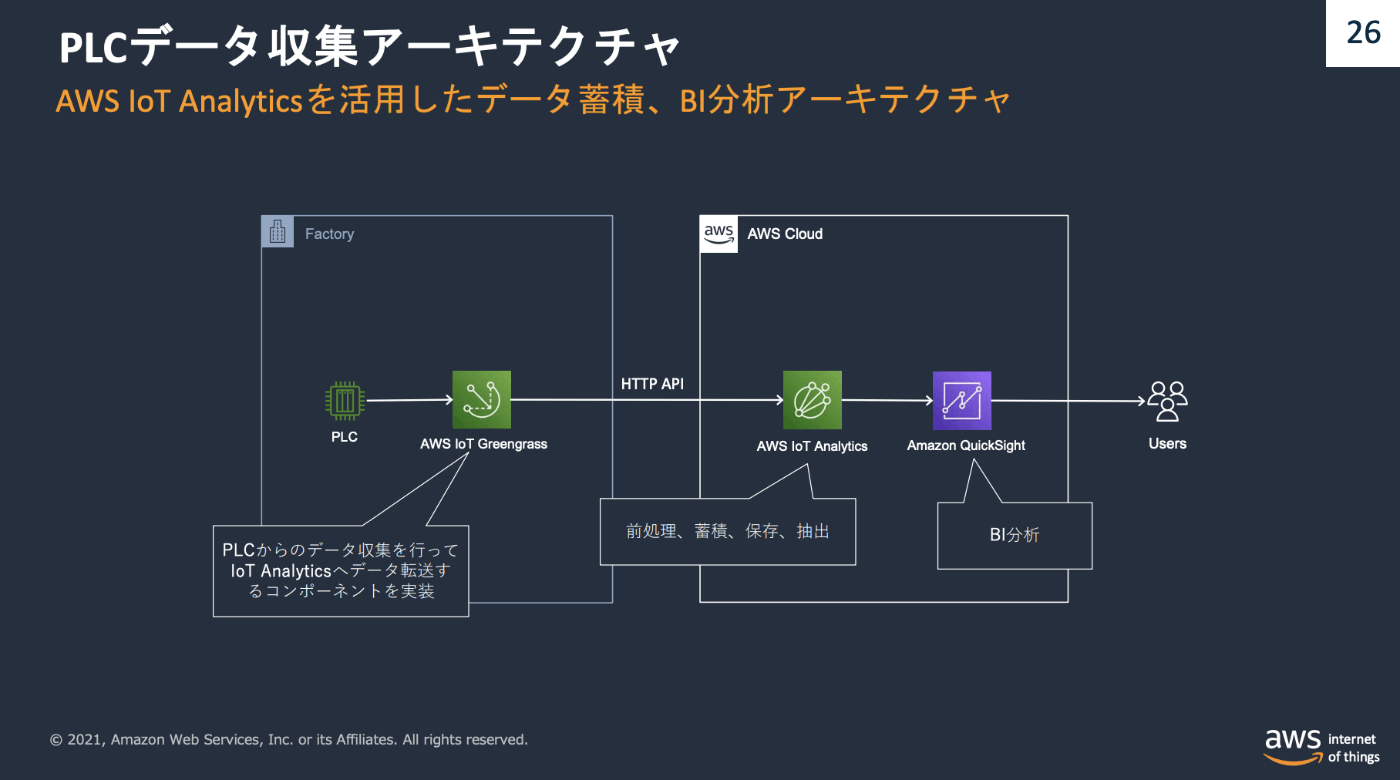
(引用 : https://pages.awscloud.com/rs/112-TZM-766/images/AWS-factory.pdf )
Kinesis Data Analytics (Amazon Managed Service for Apache Flink)との違い
Amazon Kinesis Analytics はストリーミング分析向けに設計されているのに対し、IoT Analytics は保存データの分析向けに設計されています。リアルタイム分析と IoT 分析の両方が必要な場合は、Kinesis Analytics と IoT Analytics を組み合わせて使用できます。
FAQに既に記載あり。
レイテンシの観点からミリ秒レベルのリアルタイムな分析を行う必要がある場合はKinesisになる。
IoT Analyticsでは以下のような特性を持っており、IoTのデータ分析に特化している。
- メッセージのタイムスタンプの自動的なキャプチャ
- デバイス固有のメタデータの利用
- 時系列データのストレージ
IoT データの取り込みと可視化のための7つのパターン – ユースケースに最適なものを決定する方法
アーキテクチャ例1: AWS IoT Greengrass ストリームマネージャーによるストリーミングデータの転送
連携先
- IoT Sitewise
- Kinesis Date Streams
- IoT Analytics
- S3
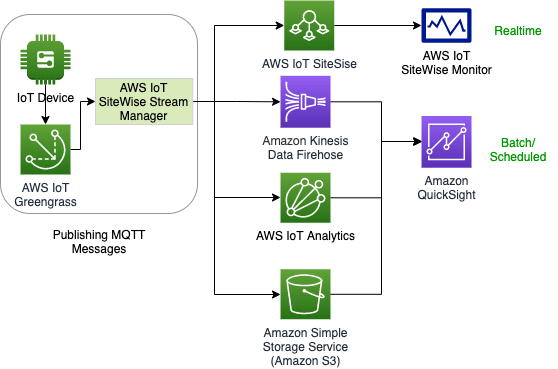
(引用: https://aws.amazon.com/jp/blogs/news/7-patterns-for-iot-data-ingestion-and-visualization-how-to-decide-what-works-best-for-your-use-case/)
※ 図のFirehoseはData Streamsの誤りと推察。
ストリームマネージャ
The stream manager component (aws.greengrass.StreamManager) enables you to process data streams to transfer to the AWS Cloud from Greengrass core devices.
コンポーネントとして提供される。ストリームマネージャを利用することでストリーミングデータをクラウドへ持って行ける。
https://docs.aws.amazon.com/greengrass/v2/developerguide/stream-manager-component.html
ストリームマネージャとのやりとりはGreenglass上のLambdaからSDKとして提供されるクライアントを介して行われる。
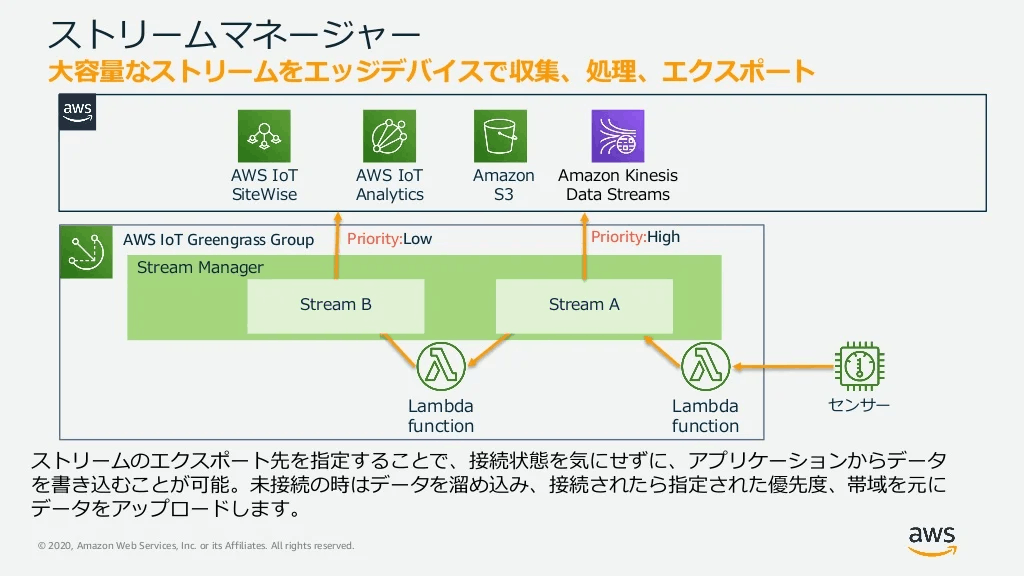

(引用 : https://docs.aws.amazon.com/ja_jp/greengrass/v1/developerguide/stream-manager.html )
■ ストリームマネージャとIoT Sitewise Edge Gatewayの関係。
Greenglassのリソースとしてのゲートウェイがあり、その中に種々のコンポーネントの1つとしてストリームマネージャーがある。

(引用 : https://dev.classmethod.jp/articles/sitewise-gateway-2-kinesis-data-streams/ )

(引用 : https://dev.classmethod.jp/articles/sitewise-opcua-swgw/ )
EdgeでのETL処理に有用。従来のRedisで実施していた構成に代わる。

(引用 : https://aws.amazon.com/jp/iot/solutions/etl-accelerator/ )
■ ストリームマネージャでできること
- AWSに転送する前にデータ処理することでSitewiseに転送するデータ量を減らし、コストを削減することができる。
アーキテクチャ例2 (パターン5): Kinesis Data Analytics

高帯域幅とリアルタイムのストリーミングデータを分析する能力を提供
アーキテクチャ例3 (パターン6): OpenSearch
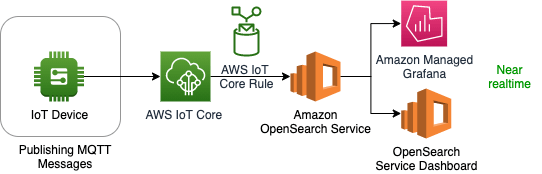
IoT CoreからルールでOpenSearchに直接投げ込める。
OpenSearchをデータソースとしてGrafanaでリアルタイムのダッシュボードアプリケーションを構築するなどの用途。
QuickSightはBIツールのため、過去データの集計や分析をした情報の可視化が得意
Grafanaは、リアルタイムに近い「今」のデータの可視化が得意
https://www.fsi.co.jp/blog/8195/
確かに、以前QSでリアルタイムにできないかと言うところで結構苦戦を強いられた。
アーキテクチャ例4 (パターン7) : AppSyncとカスタム可視化ツール
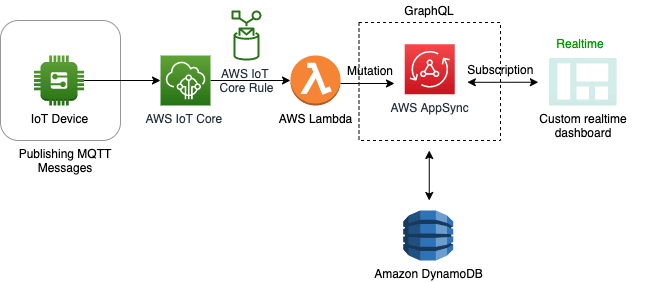
リアルタイム性を維持して独自アプリケーションで通知や可視化に利用する場合に有用なアーキ。
// todo
機械学習系
ハンズオン そのほかのアーキ
AWS での Cloud Migration Factory
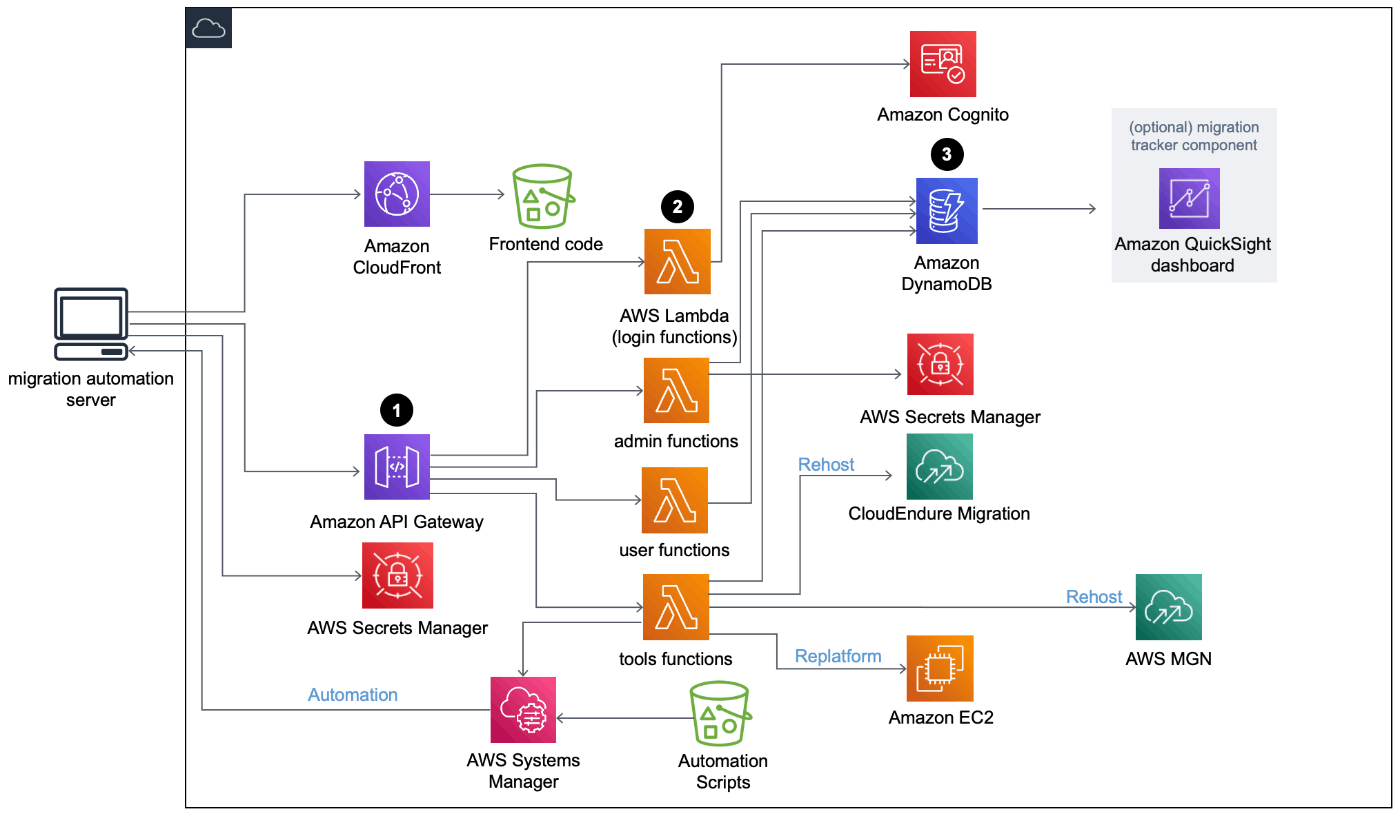
Cognito
SAML連携
以前記事書いた。
ユーザに紐づく情報の管理
Cognitoにも任意のデータを持たせることはできるがカスタム属性は検索できない。
標準属性のみを検索できます。カスタム属性は検索できません。これはインデックスが付けられた属性のみが検索可能なためで、カスタム属性にインデックスを作成することはできません。
→ Cognitoでは認証認可に必要な属性のみを持たせておき、アプリケーションで必要になるユーザ毎のデータはDynamoDBなどに持たせCognitoの発行するUUID等をキーとして紐付けする構成が一般的である。
方法的にはCognitoの各種イベントトリガでLambda実行する機能を活用してDynamoに登録する実装がメジャーと思われる。 一方で、Cognitoではユーザ削除時のイベントをトリガできないためユーザ削除時には独自にAPI GW-Lambda関数でCognitoのユーザ削除APIをラッピングし、その流れで各種Dynamoなどからユーザデータを削除するアーキテクチャがあるようだ。
CloudEndure Migration / AWS MGN
CloudEndure Migration → 既にEOL
AWS Application Migration Service (AWS MGN) → CloudEndure Migrationの次世代サービス
CloudEndure MigrationがAWSに組み込まれたのは2019年でしたが、もともとCloudEndureはクラウド移行の有償サービスとして展開されており、AWS以外のプラットフォーム向けにも対応していました。AWSの買収以降はAWSのサービスとして提供されるようになりましたが、アカウントやコンソールなどはAWSと分離したままとなっていました。MGNはCloudEndureの仕組みをベースとして、AWSネイティブなサービスとしてリリースされた形となります。
Note: CloudEndure Migration will continue to be available in China, GovCloud Regions, and for migration to Outposts through November 30, 2024.
11/30までは中国リージョンとGovクラウドへの移行では有効。
CloudEndure MigrationとAWS MGNの差分については以下。
もともと独立したサービスだったのがAWSに組み込まれたことでIAMやCloudTrailとも連携できるようになった。
AWS MGN
そもそも移行の種類
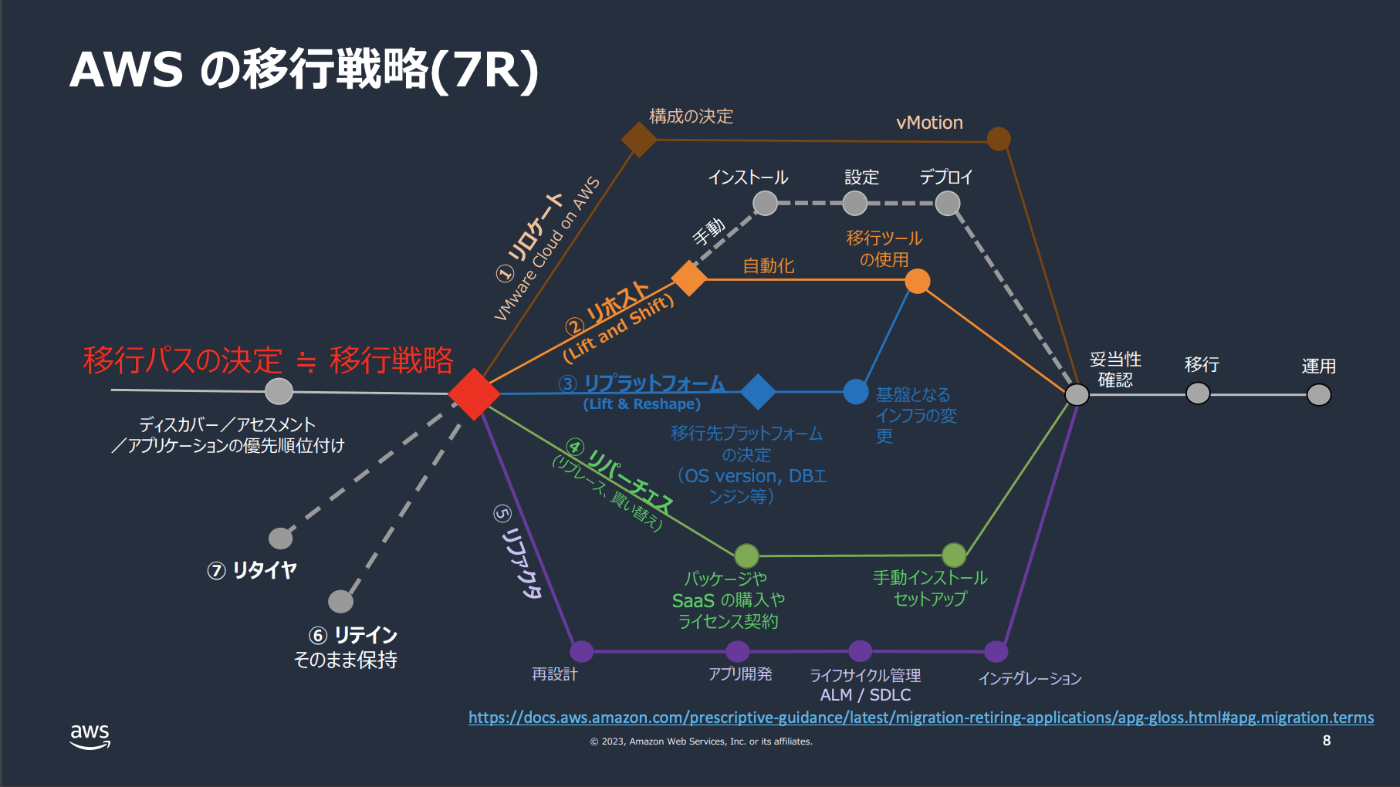

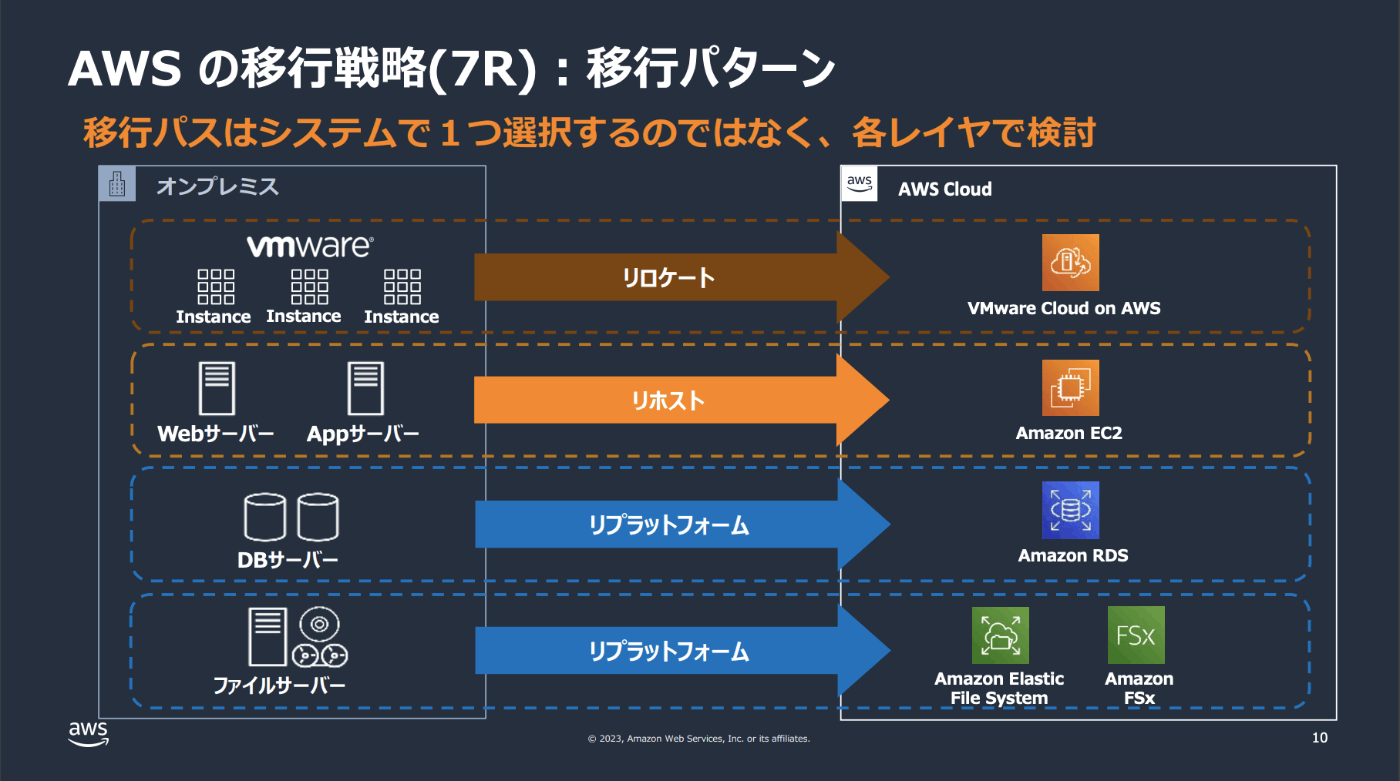
 AWS MGNはオンプレサーバ等で稼働するアプリケーションをEC2へリホストするサービス。
AWS MGNはオンプレサーバ等で稼働するアプリケーションをEC2へリホストするサービス。
仕組み
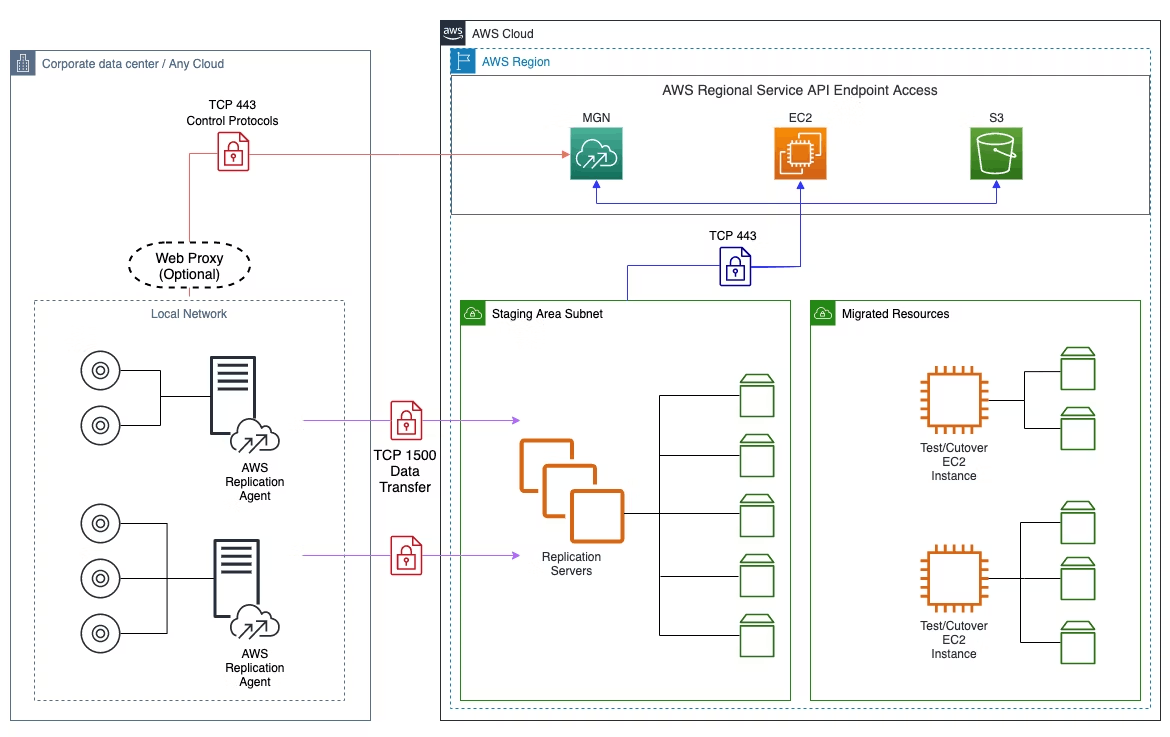
移行を行うEC2インスタンスがStagingAreaサブネットに用意される。
ソースサーバにAgentを導入すると、TCP1500を介して移行が行われる。
まずテストインスタンスを移行先とし、その後カットオーバーインスタンスに移行する。
エージェントについて
カットオーバーウィンドウが最小となるため通常エージェント利用が推奨される。
ただし、セキュリティ要件故に稼働する環境にエージェントをインストールできない場合、VMWareの仮想環境であればvCenterにMGN専用のVMを起動しクライアントを動かすことでも移行できる。
ネットワークについて
MGNではVPNやDX Connect経由での移行が可能。