for Google Cloud PCA
Google Computing Engine (GCE)
IaaS (Infrastructure as a Service)。AWS EC2相当。
基本EC2同様、マシンスペックやOSを指定して起動する。
カスタムマシンタイプ
ワークロードに最適なCPU数とメモリ容量を搭載した仮想マシンを指定可能。
インスタンスタイプ
- 末尾の数字がvCPUに対応する命名規則。
- C系 : コンピュート最適
- M系 : メモリ最適
- A系 : 機械学習向け
- E系 : コスト面で経済的
etc... AEC2同様それぞれのファミリーに向き不向きがある。
Live Migration
仮想マシンを稼働状態のまま別のホストに移動させる機能。
事前にメモリレベルでコピーし、瞬断させたのち移動させる。ユーザからはその移動を気にすることなく利用し続けられる。
AWSやAzureでもホストの計画メンテナンス時にはVMの停止が必要になるがGoogle Cloudではそれが不要。
スポットVM / プリエンプティブルVM
EC2スポットインスタンス相当。プリエンプティブルVMはスポットVMの前駆サービスであり、最大24時間の連続稼働時間の制限があったがスポットVMでは撤廃。現在はスポットVM利用を推奨。
シャットダウンスクリプト
- インスタンス起動時にシャットダウンスクリプトを
shutdown-scriptをキーとしてメタデータエントリに指定することでシャットダウン前に実行するスクリプトを定義できる。 - なお、実行時間は最大30secでそれ以降は強制停止する。
Confidential Compute
- メモリ内の暗号化が可能。
- 通常、メモリに展開されるデータは復号されているためメモリスヌーピング等でデータ漏えいのリスクがあるが、インスタンス作成時にConfidential Computeを有効にするだけでパフォーマンスに影響せずメモリ暗号化が可能。
- コンピュートリソースがクラウドにある点で現実的にどれほどリスクがあるのかは疑問だが要件としてある場合などに対応可能という理解。
Shielded VM
インスタンス期同時に有効化することで、セキュアブート、vTPM対応のメジャードブートなどによりインスタンスが改竄されていないことを検証できる。
アクセススコープ
- VMから実行可能なGoogle Cloud APIを制限するレガシーな手法。現在はIAM サービスアカウント(SA)による制御が推奨。
- アクセススコープはVM作成時の設定を更新できない。
- SAとアクセススコープが同時に定義される場合、アクセススコープによる制限が優先される。
ディスク
以下の2種類に分かれる。
- ローカルSSD (エフェメラルストレージ)
- ホストに物理的に接続され、非常に高いIO性能を持つ
- インスタンス停止と共にデータはロストし永続性はない。
- アプリケーションデータのキャッシュなどに有効。
- Persistent Disk
- ネットワーク越しにマウントする。AWS EBS相当。
- ディスクのサイズが大きいほどIOパフォーマンスが増大する。これはEC2でも同様。
- パフォーマンス面での提供タイプ
- Standard
- コスト重視、性能低め
- Balance
- コストパフォーマンスのバランス型
- SSD
- パフォーマンス重視
- Extreme
- AWSのプロビジョンドIOPS相当
- Standard
- 可用性面の提供タイプ
- ゾーン永続ディスク
- リージョナル永続ディスク
- ゾーン障害でVMが利用できなくなっても異なるゾーンのVMに強制接続が可能。なおExtremeでは非対応。
- 起動時に
--no-auto-deleteオプションを有効にすることでVM停止時に自動で永続ディスクが削除されないように設定できる。 - 最大2つのVMにアタッチして書き込み可能 : マルチライター (preview)
スナップショット
- ルートディスクのスナップショットを作成できる。
- プロジェクト間やリージョン間で直接使用することはできない。
- そのため、作成したスナップショットを一度GCSにイメージファイルとして作成・保存することで別リージョンから作成可能になる。
ノードアフィニティラベル
- 指定ラベルのついたノードグループにインスタンスをプロビジョニングするラベル。
- ノードグループではなくノード名を指定する。 // ?
- 単一テナントノード(Sole Tenancy Node)にVMインスタンスを起動したい時に利用。
- 逆にプロビジョニングしないための設定をアンチアフィニティという。
OS Patch Management
- SSM Patch Manager相当の機能。利用可能なアップデートのインストールを自動化できる。
シリアルポートログ
- VMには4つの仮想シリアルポートがあり、OSやBIOSなどの出力が書き込まれる。
- ロギングを有効にすることでCloud Loggingに出力できる。
OS Login
SSHでインスタンスにログインするユーザをGoogleアカウントと連携して管理することが可能。
Rightsize Recommendation (サイズ適正化)
稼働中の VM の CPU とメモリ使用量をモニタし、過去 8 日間のデータを使用して推奨情報を提供する。
割引
AWSのリザーブドインスタンス相当の確約利用割引(Commired Usage Discounts : CUD)のほかに、継続利用割引が自動で適用される。
他にも細かな割引のオプションがあるが後で読む // TODO
参考
マネージドインスタンスグループ (MIG)
- 以下3種類
- アンマネージドインスタンスグループ
- アンマネージドインスタンスグループはCloud Load Balancingの配下に単にVMをぶら下げるためのインスタンスグループ。
- オートスケーリングやオートヒーリングは利用不可。
- 単一ゾーンでのみVMをグルーピングする。
- ステートレスマネージドインスタンスグループ
- オートスケーリングやオートヒーリングを利用可能。
- ステートフルマネージドインスタンスグループ
- オートスケーリングは利用不可。
- オートヒーリングを利用可能。
- アンマネージドインスタンスグループ
- インスタンステンプレートの更新 ( Instance Group Updater が組み込まれたもの)
- PROACTIVE (先行型)
- 既存の稼働中のVMにも適応する場合
- OPPORTUNISTIC (追従型)
- 既存の稼働中のVMには適応を保留し、インスタンスが終了したものにだけアップデートを行う。
- PROACTIVE (先行型)
- インスタンステンプレート
- インスタンスの設定を保存したテンプレート。
- オートスケール
- カスタムイメージからインスタンステンプレートを作成し、インスタンステンプレートを基にオートスケールを指定したマネージドインスタンスグループを作成する。
Bare Metal Solution
Regional Extentionと呼ばれる拡張されたリージョンで専用のベアメタルインスタンスを提供。
ライセンスはBYOL(Bring Your OWN LICENCE)。
GCEのネットワークの話
VPCネットワーク
- NICに対してIPアドレスを付与する。
- 内部IP
- プライマリIP : 必須。サブネットから与えられる。
- エフェメラル
- 静的
- セカンダリIP : VM上のコンテナ運用で利用。各コンテナはセカンダリIPからIPを払い出される。
- プライマリIP : 必須。サブネットから与えられる。
- 外部IP : グローバルID。任意。
- 内部IP
BIOIPも可能。
VMは最大8つのNICを持てる。ネットワークアプライアンス(FW)などをインスタンスにインストールして利用する場合に入口NWと出口NWで分けるためにそれぞれNICが必要。
Google Virtual NIC (gVNIC)
// TODO
GCEのバックアップの話
- スナップショット
- ディスク単位で取得
- 増分バックアップ
- マルチリージョン or 特定のリージョンに保存可能
Migration for Compute Engine
VMware vSphere、EC2、Virtual machine (Azure)からGoogle CloudのGCEにサーバ移行するツール。
移行元にセットアップするMigrate Connectorがデータを継続的にGoogle Cloudへ転送する。
ダウンタイムを最小限にしながらサーバ移行できる。
- 移行ランブック
- 移行するVMの構成を定義したCSV
Sole Tenancy Instance (GCE)
- ライセンス持ち込み(BYOL)シナリオ等でポリシーゆえに共有インスタンスを使えない場合に物理サーバを貸し切りにする。
- Windows Serverとか。
IAMと組織ポリシー
AWSではAWS IAMで認証認可が行われるが、Google CloudではGoogleアカウントが認証し、IAMが認可を担っている。
プリンシパル
ユーザアカウントとサービスアカウントの2種がある。
ユーザアカウント
- 各個人で管理するアカウント
- Googleアカウント (@gmail.com or @xxxxx.com(企業ドメイン))
- Google グループ (Googleアカウントをグループ化した単位)
- 企業で一括管理するアカウント
- Google Workspacesアカウント
- Cloud Identity
Cloud Identity
Google Workspacesからアカウント管理機能のみを切り出したIDaaS。
- ユーザやグループ管理のほか、各ユーザのMFA有効化の強制やデバイス管理が可能。
- サービスとして切り出されているためGoogle Cloudコンソール外の独自のコンソールを有する内部的には連携している。
- ユースケースとしては、既にO365が導入されている企業においてはGoogle Workspacesは不要だが、Google Cloudへの社員のアクセスを一元管理する必要がある様な場合。
サービスアカウント
AWS IAMロールに相当。リソースに対して付与し、他のリソースへアクセスする際の権限を定義する。
Eg.) Cloud FunctionsからGCSへ読み取りが発生するので許可する。GCEインスタンスからPub/Subへプッシュするので許可する。 etc..
- サービスアクセスキー
- オンプレミスシステムやほかのプラットフォームからGoogle Cloudリソースへのアクセスが必要な場合に利用する。AWSユーザに発行されるアクセスキー/シークレットキー相当。
- 最大10個のキーを発行できる。
- 実体はテキストベースのファイルであり漏えいリスクが大きいため可能なら使用しない方法を検討する。
- Workload Identity連携 (後述)
- 外部IDに対してサービスアカウントになりすますことでサービスアクセスキーなく上記と同等のことを実現する。
- AWSやAzure、OICD、SAML2.0との連携に対応。
ロール
サービス名+リソース名+動詞のセット。「何に対して」「何ができる」を定義したもの。「誰が」には言及していない。以下3種類がある。
- 基本ロール (レガシー)
- オーナー/編集者/閲覧者
- 事前定義ロール (推奨)
- 各サービス向けに用意されたよりきめ細かなロール
- カスタムロール
- 独自に権限(permission)を組み合わせて定義。
- 事前定義ロールよりもさらに細かい権限管理を行いたい場合。

バインディング
プリンシパルとロールを1:1で紐付け(バインド)したもの。これにより「誰が」「何に対して」「何ができる」が揃った状態。
- 条件
- バインディングには特定の条件でのみ
「誰が」「何に対して」「何ができる」を有効にさせることが可能。 - 特定の時間帯や特定のサービス/リソース/タグについて制限を加えることが可能。
- バインディングには特定の条件でのみ
ポリシー
バインディングを複数束ねたものがポリシーとなる。
継承の概念と権限
AWSとの違いを考えてみた。

Workload Identity Federation (Workload Identity連携)
Google Cloud の外部(他のクラウドや Kubernetes など)で実行されているアプリケーションが、Service Account の Key を利用せずに Google Cloud 上のリソースを扱うことができる
// TODO 細かいシーケンスは別途
AWSでも連携方法あったはず。ざっと見ありそう。
この辺はAWS SAP取るために一度整理したから近いかも。後で見る。 // TODO
K8sにおけるWorkload Identity Federationではk8sの ServiceAccountリソース と Google Cloud の IAM サービスアカウント を紐付けする。
- https://cloud.google.com/kubernetes-engine/docs/concepts/workload-identity?hl=ja
- https://note.com/noise_net/n/n14fd2cedc023
組織ポリシー
IAMは「誰に」を主体としてリソースへのアクセス権を付与してきたが、特定のリソースに対して制限する場合には組織ポリシーを利用する。
- GCSバケットの外部公開禁止(
constraints/storage.publicAccessPreventation)や外部IP使用の特定インスタンスのみの制限(constraints/compute.vmExternalIpAccess) 、リソース展開可能なリージョンの限定、OS Loginの有効化義務化など。 - IAM同様に事前定義のものとカスタムで作成するものがある。
- 特定のドメインからのIAMユーザーのアクセスを制御可能。
Google Cloud Directory Sync (GCDS)
Cloud Identityの機能。
Microsoft Active DirectoryやLDAPサーバで登録されているユーザやグループをGoogle WorkSpacesやCloud Identityのユーザやグループに同期するツール。Linux版、Windows版と提供されている。
ユーザー認証の仕組みを提供するものではない。 認証を一元化する場合、既存のIDプロバイダとSAML2.0経由でフェデレートする。
GCDS では Cloud Identity 側にディレクトリが同期されるため、最終的には、Google Cloud の ID を使いログインするという点です。
それに比べてWorkforce Identity Federation では一連のプロセスにおいて Cloud Identity が使われることがありません。
- Workforce Identity Federation
- Google Cloud リソースにアクセスできるようになるのは"ユーザ"
- Workload Identity Federation
- Google Cloud リソースにアクセスできるようになるのは"(外部のクラウドやk8sで稼働する)アプリケーション"
これとは別でPassword Syncというのもある。 // TODO
Cloud Dataflow
- ETLのマネージドサービスであるデータパイプライン。AWS Glue相当。
- 実態としてはユーザ管理のVPC上にGCEが起動してワーカーノードとしてパイプラインが処理される。
- あらかじめ定義されたスキーマのデータに毎回同じ加工をしデータ処理する定型処理に向いている。
- 実装はコーディングを要求する。
- 技術的にはApache Beamによるデータ処理の実行環境を提供するサービス。ストリーム処理とバッチ処理両方に対応し、オートスケールをサポートするため複雑な処理が可能。(ストリーム処理に特化している。)
- バッチ処理はGCS等を入力ソースに。
- ストリーム処理はPub/Subなどで受け付けて特定のwindowに区切ってまとめて処理。 (この感じKinesis Firehoseなどど似てる。)
- Apache Beamはpythonなどでデータ処理のパイプラインを定義するものであり、その実行環境として、Apach SparkやAWS Kinesis Data Analytics、Google Cloud Dataflowなどが並ぶ。
- Cloud Dataflowを実行環境として利用することで、ETL処理の開発者や実行者はその下で動くワーカーノードの調整を行う必要がなくない。
ユースケース
◆ クイックストリーム分析 (Pub/Sub連携)
Pub/Subと連携し、受け取ったメッセージをパイプライン処理してBigQueryなどの分析基盤に投入する用途が一般的。
- Pub/Subはメッセージに一意なIDを付与するのでそれを使用して重複排除を行える。
- なお、以前はPub/Subは厳密なFIFOを保証しないためDataflowを用いて大量のストリームデータをタイムスタンプ順に処理できる様にする手法だった(?) // TODO 要調査
- → 現在はSub/Pubに順序指定するオプションが提供されている。ただしDataflowと繋ぐ場合はパフォーマンスが下がるので非推奨。
◆ データ移行
異なるデータストア間のデータ移行パイプラインとしても利用される。
DatastreamをDataflowのデータソースに指定することでDBの変更をトリガして他のDBに同期させる様な用途に使える。
Cloud Dataprep
- 内部的には
Cloud Dataflow(とBigQuery?)が動くETLツール。それ故Dataflowのコンソールからも確認可能。 -
Dataprepはpreparationの頭文字と考えられる。preparationは不定型なスキーマの生データを収集/加工し分析に利用できる状態にすること。 - GUI操作が提供され、データを確認しながら処理できる。→ AWS Glue Studio相当?
- データソースにはGCSやBigQueryなど種々指定できる。オンプレもでるとかできないとか // TODO 要確認
Cloud Dataproc
- HadoopやApatch Sparkのクラスタを作成し、クラスタ上でジョブを実行する。AWS EMR相当。
- ジョブ実行にあたり必要なインスタンスはユーザ側で作成する必要がある。
- その点DataflowではマネージドなETLサービスゆえに、インスタンスのオートスケールにより自動調整されるため考慮不要。
- ワーカーインスタンスとしてオンデマンドインスタンス以外にスポットインスタンスを利用可能。
- HDFSではなくGCSにデータを永続化可能。
- ストレージとコンピュートリソースが分離できるため
- それゆえサーバの常時起動不要でクラスタを使用する時のみ コンピューティングリソースを起動しオートスケールすることが可能。
- 既存リソースとしてHadoopやSparkの資産をリフト&シフトするならDataprocだが、そうでないならDataflowが推奨。
Data Fusion
GUIベース(Data Fusion Studio)で簡単にETL環境を構築できる。
スケジュール実行やパイプラインのテンプレート化、エクスポートにも対応。
こちらはDataprocの上で動く。
まとめるとこんなイメージ。
| フルマネージド | 非マネージド | |
|---|---|---|
| GUI操作 | Dataprep | Data fusion |
| 非GUI操作 | Dataflow | Dataproc |
- Dataflow 系はバッチ処理とストリーミング処理に対応し、特に ストリーミング処理に強い 。
- Dataproc 系はバッチ処理と インタラクティブなSQLクエリに有用 だが、ストリーミング処理に弱い。
ネットワーク
VPC
IPアドレス
AWS VPCと異なりVPCはグローバルリソース。故にリージョンを跨いでいてもインスタンス間で通信可能なため、マルチリージョン展開したインスタンス間でVPCピアを設定する必要がない(いずれVPCが増えるとメッシュ化して管理が煩雑かするのがよくある困りごと)。
更にCIDERレンジを指定する必要がなく単なる箱の定義でしかない。
更に、Google Cloud ではサブネットは異なるアドレスレンジをつけることが可能(単一VPC内に192.168.0.0と10.0.0.0のサブネットが混在するとか気にしない)。
AWS等ではVPCのレンジ内でサブネットを切り出すのが一般的だが、VPCはCIDERを持たず任意にサブネットにアドレスレンジを当てられるためアドレス範囲の枯渇を気にする必要がない。
ベストプラクティス
- デフォルトVPC削除
- AWS同様にデフォルトVPCは使わないことが推奨。
- リージョン全てにサブネットが用意されているため将来的に拡張した際にアドレス範囲が重複しうる。
- 複数VPCを構成し相互に接続したい場合の対応
- VPCピアリング
- Cloud VPN
- なおこの選択肢は以下ケースで有用
- VPCピアの上限に達した場合
- トランジットを有効にしたい場合
- IPレンジの重複がある場合に 共有VPCを介して接続する場合
- なおこの選択肢は以下ケースで有用
Shared VPC (共有VPC)
同一組織内の異なるプロジェクト間やオンプレミスと通信を行う手法。
ホストプロジェクト側でshared VPCネットワークとサブネットを構築し、それを利用する側(サービスプロジェクト)に対してサブネットを割り当てる。これによりサブネット間では内部IPで通信が可能。
- ユースケース
- ネットワークリソースを一元管理したい要件がある場合 (アプリケーションの開発とネットワークの管理でIAM権限を分離する)
- ホストプロジェクトがネットワークリソースをセットアップし、通常ではプロジェクト内でインスタンスを設置するが、サービスプロジェクトがVMを配置させることができる(=サブネットへのインスタンス配置の権限のみを各サービスプロジェクトに渡す。)ように該当プロジェクトのユーザにComputeAdminなどの配置権限を与える。
サブネット
- リージョンリソースであるためゾーンを跨いで作成可能。
- それゆえ、別のゾーンでインスタンスを再起動するようなケースでもIPアドレスを変更しなくてよい。
- パブリックサブネットやプライベートサブネットの様なくくりではないのでアプリケーションやサービスの単位でサブネットを分ける。 // TODO 要出典
VPCピアリング
- 異なるVPC間で内部IPアドレスを介した通信が可能となる。これは組織やプロジェクトを跨ぐことも可能。
- VPC同士はGoogle内部回線で通信できるため高速。
- VPNだと結局インターネット経由のため速度面の優位性はない。
- 最大25接続まで。
- トランジット(推移的遷移)不可。
- IPレンジの重複するサブネットがある場合には利用不可。 (AWSも一緒)
ファイアウォール
AWS セキュリティグループ相当。ステートフル。
VPCに紐づくリソース。
- VPC ファイアウォールルール
- 単一のVPC内でIPアドレス(とタグ)に基づくL3/L4 レベル制御を提供(Essentials Tier)
- VPC ファイアウォールポリシー
- 複数プロジェクトや複数VPCを対象。IAM同様上位のリソースで定義されたポリシーを継承する。
- IPベースのEssentials Tierの他、FQDNや地理情報に基づく制御が可能(Standard Tier)。
ファイアウォールルール
- 「どこからどこのプロトコルが何を通信を許可/拒否する」を定義する。
- この"どこから(ソース)"にCloud Load Balancerを指定できない。 // AWS セキュリティグループの考え方と違う点。
- 0〜65535までで小さいものから評価。
- 上りは暗黙のdeny(0.0.0.0/0)、下りは暗黙のallow(0.0.0.0/0)が最も低い優先度(65535)で設定されている。
- ターゲットにはCIDERでの指定のほか、特定のネットワークタグ(*)、特定のサービスアカウントに基づくルールを設定できることからオートスケール等の動的な状況に対応可能。
- ルールのロギングを有効することでCloud LoggingやFirewall Insightsから確認できるようになる。
(*): Google Cloudにおいてラベルとタグは異なる意味を持つ。
ラベルは請求などのグループ化を目的としたkey-value(AWSのtagのイメージ)。一方でタグ(Google Cloud)は単なる文字列でファイアウォールでの一括指定などに利用される。
ファイアウォールポリシー
組織やフォルダレベルで設定することでプロジェクトではそのポリシーを継承する。
// TODO
VPC Service Controls (VPCサービスコントロール)
クラウドデータの漏洩リスクを低減する目的で、各種リソース(VPCとは無関係。VPCリソースやVPC外のリソースも含む)を論理的な境界で囲い、外部とのGoogle Cloud APIアクセスを隔絶する。
なお、これはネットワーク的な隔絶ではないためインスタンスへのSSHなどの話ではない。
アクセス制御は基本はFWであり、それでも守りきれないケースを想定している。
特に、悪意のある内部関係者や感染したコードによるデータ流出や漏洩に対しリスク軽減を目的に設計されている。IAM制御だけではデータを他のプロジェクトにコピーするみたいなことができてしまう。
- サービス境界
- Google Cloud APIへのアクセスを制限する仮想的な囲い。
- 境界内のリソースは境界外のリソースと隔絶され、外から内部のGoogle Cloud APIをコールすることも、外部のGoogle Cloud APIをコールすることもできなくなる。
- 1プロジェクトにつき1つのサービス境界まで作成可能。
- アクセスレベル
- 特定のアクセス元からのGoogle Cloud APIコールを許可する。
- アクセス元の指定方法は以下
- IPアドレス
- サービスアカウント
- デバイスポリシー(別途BeyondCorp Enterprise契約が必要) // TODO
- 上り(内向き)/下り(外向き)ポリシー
- サービス境界内の特定のAPIやプロジェクトのみへのアクセスを許可するなどアクセスレベルよりきめ細かい制御が可能。
- 境界ブリッジ
- サービス境界間を双方向にアクセス可能とする。
- VPCピア同様にトランジットはできない。
https://zenn.dev/cloud_ace/articles/6a26443b8e7bb4
VPCフローログ
- 全パケットを記録するものではない
- 30パケット毎にサンプリングする。
- 全てのパケットを記録する場合はパケットミラーリング(Packet Mirroring)を有効にする。
パケットミラーリング(Packet Mirroring)
特定インスタンスに出入りする全パケットをミラーリングできる。
コレクタ宛先としてInternal TCP/UDP Load Balancerとその背後でオートスケールするインスタンス(MIG)で構成される。
ユースケース
- IDS(侵入検知システム)ツールを通し脅威検知する場合。
Cloud VPN
- IPsecを利用したインターネットVPNでオンプレミスネットワークとVPCを接続する。
- 帯域幅は上下合計で3Gbpsが上限。一般的に10Gbps以下の帯域幅でよいなら専用線は不要でVPNで十分。
- VPNの終端であるVPNゲートウェイで暗号化/復号が行われる。
- 以下2種類提供。
- HA VPN (高可用性 VPN)
- SLA 99.99% (内部的にトンネルが2つ)
- BGP(動的)のみサポート
- Classic VPN
- SLA 99.9% (内部的にトンネルが1つ)
- 基本、静的ルーティングのみサポート(動的も一部条件下でのみサポートあり)
- 比較表あり
- HA VPN (高可用性 VPN)
- HA Cloud VPNでは、HA Cloud VPNとオンプレミスVPNゲートウェイの間に2本のトンネルが構成されており、一方がダウンしても接続が可能な冗長構成がとられている。一方でClassic Cloud VPNはトンネルによる冗長化がされず可用性が低い。
- VPNゲートウェイはリージョナルリソースであるため複数リージョンに接続する倍はそれぞれのリージョンにVPNゲートウェイを設置する必要がある。
- VPC間やVPC-オンプレ間でプライベートIPアドレス範囲が重複している場合、VPCピアは使えない(前者の場合)ので、VPNで解決する。
- そもそも何でアドレス範囲が共通していると通信できあにのか?
- VPC内のルータは自身と同じアドレスレンジの通信はローカルネットワーク宛のものと解釈するためVPC外に出ることができない。
- そもそも何でアドレス範囲が共通していると通信できあにのか?
- VPNではSNAT(sourceNAT)、DNAT(destinationNAT)により実際のIPアドレスをマスクして通信できるためIPアドレスのコンフリクトを機にしなくていい。
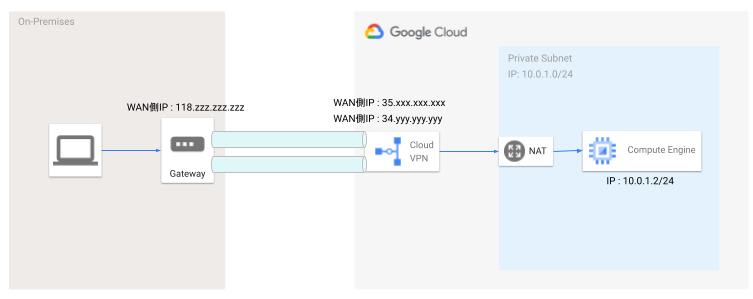
▲引用元: https://blog.g-gen.co.jp/entry/vpn-base
- ピアVPNゲートウェイ
- オンプレやほかのクラウドプロバイダがホストするVPNゲートウェイ
- Cloud VPN ゲートウェイ
- Google Cloud で稼働する仮想 VPN ゲートウェイ
- リージョナルリソース。→ 冗長性を確保する場合、複数リージョンに展開し、それぞれピアVPN GWと1つ以上のトンネルを有する構成を取る。
Cloud Interconnect
AWS DX相当。
- インターネットを介さずGoogleの専用線を用いるため高速。
-
Dedicated InterconnectとPartner Interconnectの2種類が存在。
Dedicated Interconnect
- Google指定のコロケーション施設(PoPが設置されている施設)内の相互接続ロケーションにおいて設置された
Google peering edgeとユーザのオンプレミスネットワークを直接光ファイバーケーブルで接続する。 - 10Gbpsまたは100Gbpsから帯域幅を選べる。
Partner Interconnect
- Googleのパートナーのサービスプロバイダを介して接続する。相互接続ロケーションにおいて
Google peering edgeとService provider peering edgeが接続されており、ユーザのオンプレミスネットワークとService provider peering edgeを繋ぐことで専用線接続できる。 - 帯域幅は50Mbps〜10Gbpsの範囲で柔軟に選ぶことができる。
用語
メトロ(大都市圏)
コロケーション施設のある都市。
エッジアベイラビリティドメイン
- 各メトロにはエッジアベイラビリティドメインが2つ以上存在する。
- エッジアベイラビリティドメインは冗長性確保が目的であり、Googleの定期メンテナンスにて片方が停止していても片方が稼働している状態となる。
- この単位はゾーンとは異なる。
相互接続ロケーション
- ロケーション施設内でGoogleのネットワークと接続するポイント。
- いくつかの相互接続ロケーションは低レイテンシーが保証されており、コロケーション施設からVMまで5ミリ秒未満のアクセスが可能。
VLANアタッチメント
- ユーザ側のルータと接続先のVPC内のCloud Router間で、仮想的なインターフェースである
VLANアタッチメントを介したBGP接続を行う。 - Interconnectの契約単位。VPCの接続毎に1契約および帯域指定が必要となる。
ダイレクトピア
- GoogleWorkspacesやGoogle Cloudリソースへ高速なアクセスを提供する。
- Google Cloudアクセスが必須ではないため Google Workspacesの利用がメイン。
- インターネットASを運営している様な大規模な企業が対象であり、インターネット上のピアリングであることからGoogle Cloudのリソースとしては現れない。
キャリアピアリング
- インターネットASを自社で用意できないが同様の要件がある場合に、サービスプロバイダを介してピアリングを行うもの。
- 同じく Google Workspacesの利用がメイン。
Cloud NAT
- 戻りの通信は透過するが外部からの直接の内部IPしか持たないインスタンスへのアクセスはできない。AWS NAT GW相当。
- 内部IPしか持たないインスタンスにインターネットからアクセスできるようにするには?
- → CLBを配置して前面に置くか、外部IPを付与するしかない。
- Cloud Routerにも設定が必要。
Cloud Router
VPC内において、サブネット間でルーティングの自動化を行う。
BGPを使用してルーティング情報を更新しIPトラフィックのルートを自動的に切り替える。
NATやInterconnect、VPN利用時には必要になる。
当然接続する環境間でIPアドレスの重複はしてはいけない。
Network Intelligence Center
ネットワークの可視性向上やトラブルシュートのツール群。
対応したGoogle Cloudリソース間の通信の到達性をテストできる。
- Firewall Insights
- ファイアウォールの運用や効率を可視化しトラブルシュートや最適化に利用するツール。
- 緩すぎるルールに対するサジェストや、無駄なルール(シャドウルール)の削除の推奨などを表示。(裏では Recommender API が利用されている。)
- ファイアウォールルールロギングを有効にする必要がある。
- ネットワークアナライザ
- VPC ネットワークの構成ミスや最適でない構成を検出する
【提供終了】Cloud Machine Learning Engine (Cloud ML Engine)
フルマネージドの機械学習サービスであり、TensorFlowのトレーニングジョブの実行環境を提供する。
機械学習プロジェクトの開発からデプロイメントまでのライフサイクルをサポートし、開発者がモデルのトレーニングと予測を容易に実行できる環境を提供する。
→ 2019年以降AI Platform TrainingとAI Platform Predictionに移行。
→更に現在ではVertex AIに統合。
この古いバージョンの AI Platform Prediction は非推奨になりました。2025 年 1 月 31 日を過ぎると Google Cloud で使用できなくなります。2025 年 1 月 31 日以降、すべてのモデル、関連するメタデータ、デプロイが削除されます。リソースを Vertex AI に移行することで、AI Platform にはない新しい機械学習機能を利用できます。
2019 年 4 月 10 日、Cloud Machine Learning Engine が AI Platform Training と AI Platform Prediction になりました。このページには Cloud ML Engine の更新履歴が記載されています。
This legacy version of AI Platform Training is deprecated and will no longer be available on Google Cloud after January 31, 2025. Migrate your resources to Vertex AI custom training to get new machine learning features that are unavailable in AI Platform.
Cloud KMS
BigQueryやPersistentDisk、GCSのデータを暗号化するキーの管理サービス。AWS KMS同様。
デフォルト暗号化ではGoogle管理。CMEK(customer managed encription key)なら顧客管理。
※ CMEKは顧客がキーをローカルで生成しているとは限らない。単に自分でKMSにてKey ring/Keyを作成し、それを指定することもCMEKに当たる。Key作成時にインポートを選択していれば外部で生成したキー。
Key
Key ringに紐づくリソース。ともにロケーション(≒リージョン)リソース。
Key、Key ringともにIAMポリシーを付与でき、鍵へのアクセスを制御することができ、Key ringのポリシーをKeyは継承する。
エンベロープ暗号化はAWS KMS同様。
- Data Encription Key(DEK)、Key Encription Key(KEK)の2つ。
- 外部からインポートすることも可能。これもAWS KMS同様。
目的
- 以下の4種類
- 対称暗号化 (対称鍵)
- 非対称署名 (非対称鍵)
- 非対称暗号化 (非対称鍵)
- MAC署名 (対称鍵)
- 対称鍵のみ自動ローテーションが可能。デフォルト90日。
- 非対称鍵を手動でローテーションし多場合、公開鍵を取得/再配布する必要がある。
保護レベル
- 以下の4種類
- SOFTWARE
- HSM
- フルマネージドなHardware Security Moduleで管理される。(=AWS Cloud HSM的位置付け?)
- EXTERNAL
- EXTERNAL_VPC
- 外部の鍵管理システム(3rd party等)で管理されたキーをKMS経由で利用する保護レベル。
-
Cloud External Key Manager(EKM)を利用する際のレベル。 - 外部の鍵管理システムとの接続をインターネット経由にするかVPC経由にするかで異なる。
状態
キーのバージョン毎に有効/無効/破棄予定/破棄の4つのステータスがある。
破棄予定ステータスはあらかじめ定めたKeyの削除までの期間で変更不可。
GCSバケットのデフォルト暗号化をCMEKに変更することでそれ以降にバケットにアップロードするオブジェクトは全て顧客管理のキーで暗号化される。Keyを無効化するとオブジェクトは復号に失敗するためデータを確認することはできなくなる。
Transfer Appliance
- 物理デバイスを利用して大量データ(通常100TB以上)を転送する。AWSのSnow Family相当。
- 40TBと300TBの容量が提供されている。
- GoogleデータセンタにてTransfer Appliance RehydratorによりGCSに復号する。
- CMEKやAES 256暗号化のサポート。
- ユースケース
- 船舶などの一時的にネットワークから隔絶された場所でデータ収集を行い、着港後にGoogle Cloudに送るなどの用途がある。
Google App Engine
インフラの管理やデプロイがマネージドで提供され、開発者はアプリケーション開発に集中できるPaaS(Platform as a Service)。AWS Elastic Beanstalk相当。主にWebアプリケーションのホスト環境を提供する。
- 以下2種類の提供がある。
- Standard Environment(SE)
- Flexible Environment(FE)
Standard Environment(SE)
- 基本はこっちを選択。FEは高度にカスタマイズが必要なケースで選択。
- 主要な開発言語で開発可能。
- インスタンスサイズを選択し起動。
- Cloud Functions や Cloud Run のようなサーバーレスの実行基盤が利用可能。
- 高速なスケーリングとゼロスケーリング(インスタンス数を0にスケールインする)が可能。 // TODO 要調査 : gvisor
- 実行時間が60secであったり、ネットワーク接続が制限されるため、外部サービスアクセスにそれ用のサービスを必要とするなど条件付き。(→ オンプレと接続必要などの要件ではFEが必要。) // 時間変更になってるかも TODO
- VPCの外側で構成されるため、 VPC リソースに対するプライベート IPによる接続は
サーバレスVPCアクセスの設定が必要。→ コネクタインスタンスが常時起動することになるので VPCにApp Engine(FE)を構成することを検討した方がいい。
オートスケーリング
スケーリングには自動/基本/手動から選択可能。
-
自動 : 内部的にキューを持ちその未処理メッセージ数に基づきオートスケーリングする。app.ymlでどんなメトリクス(CPUやメモリなど)を元にするかを選択可能。
-
基本 : リクエスト受信時にインスタンスを生成する。24hr程度動かせるためバッチ的な処理に向く。
-
手動 : 手動でインスタンスをスケーリングする。
-
max_idle_instances/min_idle_instancesというパラメータがあり、アイドル状態のインスタンス数を制御する。 -
アイドル状態のインスタンスはトラフィック急増を受け止めるのに有用。
-
ただしアイドル状態のインスタンスも課金対象なので適切に運用必要
バージョン管理とデプロイ
複数のバージョンを管理することができ、Blue/Greenデプロイメントをサポート。
-
Traffic Splittingにより、特定の割合でユーザートラフィックを新旧のバージョン間で分割可能。- Blue/Greenデプロイメント
- カナリアリリース(現行トラフィックの一部を流す段階的なロールアウト)
- A/Bテスト(50%ずつでトラフィックを分けてUIなどをテストする)
Flexible Environment(FE)
- マネージドなGCE上でDockerコンテナとしてアプリケーションが実行される。
- 実行時間制限60minなどゆるい。
- インスタンスへの直接SSHやインターネットアクセス可能など柔軟性が高い。
- ただしSEに比べスケーリングが少々遅い。
- FEでは固定のCPUとメモリオプションしか提供していない。 // ? TODO
App Engine Firewall
特定のIPアドレスからのアクセスのみを許可。
App Engine Cronサービス
- cron.yamlを使用してジョブのスケジューリングか可能。
-
Cloud Schedulerでより柔軟かつ複数の cron ジョブを管理可能。
1st → 2nd generation移行にあたり、GAEがこれまで独自に提供していた付属サービスが終了し、Google Cloud内のリソースでの代用が求められる。
IAP連携
アプリケーションに変更を加えることなくホストするアプリケーションへの認証認可を加えることができる。
CaaS
- PaaSに比べてマネージドな範囲は減る。
- コンテナのランタイムなどversionによって挙動が変わりうる部分をイメージとして固めることで移植性を高めることができる。
- Google Cloudでは
Cloud RunとGoogle Kubernetes Engineがこれに該当。
Cloud Run
CaaS。App Engine(PaaS)と似ているがあくまでコンテナの実行環境。
KnativeのServingがバックエンドを支えている。 // TODO Knative調査
GKEの場合はクラスタを作ってその上にコンテナをデプロイしていくが、Cloud Runでは実行環境は提供されているのでコンテナを稼働させる間だけ課金される。
- 作成したアプリケーションをbuildしイメージを作成後、Artifact Regsitryにアップロードし、Cloud Runがそれを取得して実行する。
- 同時実行性
- 一般的なFaaSでは1インスタンスで1つしか処理できない。
- 複数の処理を1インスタンスで実行できる。 リソース消費が効率化しコスト削減につながったり、コールドスタートを回避可能になる。
- リクエストがなければインスタンスは0。
- コールドスタートを回避したい場合は最小インスタンス数を指定してWarm状態にすることも可能。
- 新しいリビジョンとしてアプリケーションをデプロイし、リビジョン間で任意の割合でトラフィックを分けテストするといったことが可能。
コンポーネント
Service
// TODO
Revision
上書きではなくバージョンが保持される。GAE同様。
CPUを常に割り当て
- リクエスト処理中のみCPUが割り当てられるため、非同期で処理させようとするとCPUを永続させる必要がある。
トラフィック制御
Blue/GreenなどGAE同様に制御可能。
アクセス制御
関数の呼び出し
IAM認証
認証には以下選択可能。
- 未承認の呼び出しを許可
Allow unauthenticated invocations- 一般公開する用途など
- 認証が必要
Required Authentication- IAMアクセス制御される。
- Authorizationヘッダを入れないとアクセスできなくなる。
Ingress設定
特定IPに絞りたいなどの場合にはLoadBarancerを前段に立ててCloud Armorで制御が必要。
その上でCloudRunのIngressの設定として内部トラフィックとCloud Load Balancingからのトラフィックのみを許可することが必要。
← LBからのアクセスに絞らないとCloud Runを直叩きされるとアクセスできてしまうため。
関数から外部へのアクセス
サービスアカウント
Service単位でサービスアカウントを設定可能。
Egress設定
Cloud RunはVPC外のリソースであるためVPC内リソース(Memorystoreなど)に直接アクセスができない。
→ サーバレスVPCアクセスを設定することでVPCリソースにアクセスできる様になる。
サーバレスVPCコネクタを設定し、全てのトラフィックをVPCコネクタ経由に設定することも可能
→ IP固定したい場合(外部のSaaSを叩く必要がある場合かつ特定の登録済みIPからのみアクセスが許可されている様な場合)に全てのトラフィックをサーバレスVPCコネクタでVPCに渡し、固定IPを当てたCloud NAT経由でコールする方法が取られる。
IAP連携
Cloud Identity Aware Proxy(IAP)と連携することでアプリケーションはそのままに認証認可の仕組みを加えることができる。
AppEngineと異なり Cloud Runの前段にLoad Balancingを設定し、そこにIAPを当てる必要がある。
サーバレスNEG(Network Endpoint Group)を構成する必要がある。
サーバレスNEG(Network Endpoint Group)
Cloud RunやGAE、Cloud Functions、 API Gatewayのようなサーバレスリソースへのロードバランシングをする差異のエンドポイントのこと。
セキュリティ
VPC サービスコントロール境界に含めることができる。
App Engine vs Cloud Run
一般的なケースではどちらでも利用可能。
今後はCloud Runの開発に注力されていく。
Cloud Functions
FaaS。 Lambda相当。
- イベント駆動
- 何かしらのイベントをトリガしてサーバレスな関数を実行する。
- トリガとしてPub/Subからリクエストを受けるなど設定することが可能。
2nd GenではバックエンドはCloud Runが動いている。
- Cloud Functionsを作成するとCloud Runのコンソールから確認可能。
- 長時間の処理にも対応できる : 60min
- CLoud Run同様にリビジョン管理可能
- トリガはEventarcをサポとし、より多くのトリガを設定可能。
- 関数タイプ
- HTTP関数
- 同期実行
- At-most-once
- イベント実行
- 非同期実行
- At-least-once
- 冪等性のある実装を。
- HTTP関数
CPUのみ指定可能。メモリはそこから自動的に決まる。
認証
Cloud Run同様。
- 関数を実行するURLを認証なしで直叩きできるかどうか
- Allow unauthenticated invocations → 一般公開する用途で利用。
- Required Authentication → AuthorizationヘッダにIDトークンを持ってないと拒否される。
Cloud RunとCloud Functionsの使い分け
→ 内部的には同じなので機能面で差はなくなる。
→ イベント駆動や小規模ではCloud Functions
Storageまとめ
Memorystore、CloudSQL、AlloyDB → 商用/OSS DBをマネージドサービス化したもの
その他についてはクラウドウェイティブに設計されたマネージドDB。(AlloyDBはポスグレをクラウドネイティブに最適化したもので両方の特性を持つ)
Cloud SQL (PostgreDQL / MySQL / SQL Server)
- RDB。AWS RDS相当。
- SQL ServerのAlwaysOnを再現しようとすると本来Windowsサーバのクラスタリングを構成する必要があるがワンクリックで利用可能。
- プライマリインスタンスとスタンバイインスタンス(=フェイルオーバーレプリカとも呼ばれてる?)を異なるゾーンに作成することで耐障害性を提供。
- ストレージの自動拡張 を有効にすることで当初用意したストレージ容量の上限に近づいた差異には自動で拡張することが可能。
- HA構成
- 内部的にはGCEとリージョン永続ディスクで構成されている。そのため複数ゾーンにまたがってプライマリ/スタンバイを用意できる。
- HA構成は準同期レプリケーション(リアルタイムなデータレプリケーション) ←→ リードレプリカは非同期レプリケーション
- HA構成はデータロスト時の復元用途ではない(完全な復元は保証されない)。 // TODO ?
- リードレプリカ
- 任意ゾーンに作成可能。
- リードレプリカは非同期レプリケーション
- 負荷分散や可用性の向上が目的。
- CloudSQL Auth Proxy
- IAMによる認証を用意に実現する //あとでハンズオン
- バックアップ
- 増分バックアップ
- 自動バックアップ
- 定期的なスナップショット取得。
- day単位。デフォルト7で365日分まで保持。それ移行はエクスポートする。
- 保存先はマルチリージョンも選択可能。
- ポイントインタイムリカバリ
- 最大7日の任意時点にリカバリ可能。
- メンテナンス
- HWメンテはLiveMigrationのためダウンタイムなし
- OSなどSWメンテはメンテはダウンタイムあり。
- メンテナンスウィンドウを指定しておく。
- Query Insights
- DB負荷やクエリ性能を可視化、クエリのボトルネックなどを探すのに有用
- Database Migration Service
- 他社クラウドやオンプレからの移行をサポート
- バイナリログ(どちらかというとMySQLの機能)
- MySQLのトランザクションログ機能。DB障害時にログから直前の状態まで復元することができる。
AlloyDB (PostgreDQL)
- コンピュート環境とストレージ層を分離。
- AWS Aurora相当?
Cloud Spanner
- RDBに属する。
- RDBの持つ特性であるSQLによるアクセスと整合性を維持しつつ、NoSQLのように可用性と水平スケーリングを可能にしている。
- RPO RTOを0とするクリティカルなワークロードでは有用。というかこれしかない。
- 自動バックアップをサポートしていないのでCLoud Schedulerなどと組み合わせて対応する必要がある // 要確認
- トランザクション型のワークロードに有用。大量のテレメトリを解析するような分析型ワークロードではBigQueryなどを選択する。
| - | CloudSpanner | RDB | NoSQL |
|---|---|---|---|
| SQL実行 | o | o | - |
| 整合性 | o | o | -(結果整合性) |
| 可用性(*1) | o | - | o |
| 水平スケール | o | -(スケールアップ) | o |
*1 : active-active構成が取れること。RDBでは一方をスタンバイとし非同期にコピーするため利用することはできない。
- リージョン/マルチリージョンを指定して構成するノード数を指定するだけで立ち上がる。
- 自動でシャーディングし、クエリをルーティングする。シャードの増減にダウンタイムを伴わない。
- パフォーマンスのための設計
- スキーマ設計として、ホットスポットを回避する。プライマリキーの連番などはNG。(=アーキテクチャとしてはNoSQLに近いため)
- インターリーブ(親子関係)を定義することでシャードが分かれて保存されデータアクセス時に複数シャードにアクセスし結合する手間がなくなる。
Cloud Bigtable
- Apatch HBase APIでアクセス可能なNoSQL(KVM型/ワイドカラム型)
- クイックストリーム分析や時系列データに最適。
- 数百PBクラスまでシームレスにスケール可能であり、秒間数千万件のリクエストを裁くことができることから、IoTデータや金融取引、株価データなどの低レイテンシー高スループットを要求されるシステムに利用される。
- 同じNoSQLであるDatastore(おそらくFirestoreも同様)では高トランザクションに対応できない。
- 特にIoTセンサーデータや機械学習基盤など大量の列数を持つ場合に有用。(=ワイドカラム型の特性)
- 高いリアルタイム性を要求されるケースで有用。
- 大量のリアルタイムデータの取り扱い がポイント。大量のログデータ分析などは向かず、BigQueryを利用。
- テーブルにデータが書き込まれると3台以上のサーバに自動でレプリケートされるため耐障害性が高い。
- マルチリージョンまたはマルチゾーンでのレプリケーションが可能。
- ただし、レプリケーションによりreadスループットは向上するが、writeスループットは低下する。
- NoSQLのスキーマ設計のアプローチに従い、ホットスポットを回避すべくRowKeyを適切に選択する必要がある。
Cloud Firestore
- NoSQL(ドキュメントストア型)であるが、ACIDトランザクションやSQLライクなクエリを提供している。AWSのDynamoDB相当(どちらかというとDatastoreと近そう、ネイティブモードは…?)。
- キーによりエンティティを一意に識別する。DyanmoDBのイメージ。
- 複数のエンティティを取得する場合、個々に取得するより一括取得を行う方が効率的。
- Firebaseとの親和性が高いためモバイルのバックエンドに使われる。
- オフライン利用
- オフライン時にデータにアクセスでき、のちにオンラインになった際に同期される
- ネイティブモードとDatastoreモードを提供。
- Cloud FirestoreはFirebaseの
Firebase Realtime DBの後継サービス。 - AppEngine由来のDataStoreから機能拡張したもの。
- 故に今後はネイティブモードの利用が推奨。
- 1つのプロジェクトではどちらかしか選択できない様になっているのはそういう背景もあるものと推察。
- Cloud FirestoreはFirebaseの
- モバイルとのリアルタイム同期をサポート。
- Cloud KMSを利用することで暗号化可能。
| - | ネイティブモード | Datastoreモード |
|---|---|---|
| 秒間の書き込み | 1万まで | 上限なし |
| リアルタイムアップデート | o | - |
| オフラインデータの永続性(*) | o | - |
- リアルタイムアップデート : データストア側の更新をアプリケーション側にリアルタイムに反映させる。
- index情報を更新したい場合は
gcloud datastore create-indexesとすることでほかと同様に扱える
。
*: 注釈
アプリが使用している Firestore データのコピーがキャッシュに保存されるため、デバイスがオフラインであっても、アプリはデータにアクセスできます。
https://cloud.google.com/firestore/docs/manage-data/enable-offline?hl=ja#:~:text=Firestore はオフライン データの,データにアクセスできます。
アクセス制御
モバイルクライアント/Webクライアントライブラリ
Firebase AuthenticationとFirebaseセキュリティルールを使用してサーバレスな認証認可を実施できる。
サーバクライアントライブラリ
IAMベースのアクセス制御。ただし反映されるまでに5min程度のラグがある。
他
Datastoreで1エンティティ毎Getするのは非効率で、一括で取得することが推奨されているようです。
Stackdriverトレースでも複数回Getしているものは、一括で処理するようにアドバイスされます。
用途としてもDanamoDB的で、アプリケーションのセッション情報などはDataStoreに逃し、インスタンスがスケールインしてもセッションを永続できるようにする用途がある。
Google Cloud Storage (GCS)
- AWS S3相当。
- リージョン/デュアルリージョン/マルチリージョンを選択可能。
ランダムプレフィックス
- パフォーマンスを改善する。
- AWS S3ではこの制約は無くなったはず。Google Cloudでは今はどうなのか?
ストレージタイプ
- Standard
- 短期間のストレージや頻繁にアクセスされるデータに最適
- Nearline
- アクセスが 1 か月に 1 回未満のバックアップとデータに最適
- Coldline
- データへのアクセスが四半期に 1 回未満の場合に最適。
- ただし、バックアップやアーカイブプロセス用にデータを完全に保持する場合、Archiveストレージのほうがストレージ費用が最も安くなる。
- Archive
- アクセス頻度が年 1 回に満たないデータの長期デジタル保存。
- コールドデータストレージ、DR用途。
もしくはAutoclassを指定することでアクセス頻度に基づいてストレージクラスを最適化してくれる。 (S3 Interigent IA的な位置付け?)
なお、各ストレージタイプでアクセスする時間は同じ。
バージョニング
AWS同様
リクエスト元による支払い
AWS同様 → リクエスタ支払い
アクセス制御の方法
- IAMによるバケットレベルの制御
- ACLによるオブジェクトレベルの制御
なお、ACLによる制御は一般的なユースケースでは不要。例としてはIAMでアクセス管理できないユーザからのアクセスが想定される場合など。
バケット内の個々のオブジェクトへのアクセスをカスタマイズする必要がある場合。IAM 権限を付与できるのはバケットレベル以上ですが、ACL は個々のオブジェクトに設定できます。
署名付きURL
XML APIエンドポイントをGCSアクセスする場合のみ利用可能。 // TODO Hostingで使えないよという意味?
サービスアカウントの力を借りて指定期間だけアクセス可能なURLを発行する。
→ サービスアカウントキー(秘密鍵)の発行が必要。
サービスキーは以下フォーマットでDLされ、gsutilで署名付きURL作成時に指定する。
{
"type": "service_account",
"project_id": "hogehoge",
"private_key_id": "xxxxxxx",
"private_key": "-----BEGIN PRIVATE KEY-----\nxxxxxxxx-----END PRIVATE KEY-----\n",
:
}
期限切れでアクセス不可になる他、サービスアカウントキーが無効化(削除)されるとすでに発行された署名付きURLも無効化される。
保持ポリシー
- バケットに設定することで特定期間、バケット内のオブジェクトの削除/上書きを禁止する。S3オブジェクトロック機能相当。
- 保持ポリシーにはロックをかけることで、ポリシー事体の削除や保持期間の短縮が不可となる。
Object Lifecycle
- 指定日数が経過したオブジェクトのストレージクラスを自動で変化させる。
アップロードしたファイルの同一性確認
- オンプレミスのファイルのCRC32Cハッシュを取得し(
gsutil hashコマンド)、指定のバケット内のオブジェクトのハッシュを計算する(gstil lsコマンド)ことでアップロードしたファイルの同一性を確認できる。
gcs-fuse
- インスタンスからバケットををローカルファイルシステムとしてマウントするFUSEアダプタ。
- パフォーマンスは低下する。
暗号化
- KMSでキーを作成し、バケットの暗号化キーに設定することでCMEK可能。(デフォルトならGoogle側で管理のキー)
- KMSのencryptメソッドを使って手元でデータを暗号化することも可能だが、ローテーションをサポートしない。
- .boto設定ファイルに顧客提供の暗号化キーを指定することで、gsutilコマンドでファイルアップロードする際に自動で暗号化キーが使用される。
gsutil
.boto構成ファイルを利用することで以下が可能。
- プロキシ経由で使用できるように gsutil を設定する。
- 顧客管理または顧客指定の暗号鍵を使用する。
- 独自の運用に合わせて gsutil の動作を全体的にカスタマイズする。
https://cloud.google.com/storage/docs/boto-gsutil?hl=ja
Cloud Filestore
- ファイル共有サービス。AWS EFS相当。
- NFSのみ対応。SMB非対応。
- POSIX準拠のファイルシステム。インスタンス間で共有してWrite/Read可能。
- Persistent Diskの場合は共有できてもReadだけになる。(previewでマルチライター機能あり : 最大2台のVMから書き込める)
Memorystore (Redis / Memcached)
インメモリキャッシュ。 Redisとmemcachedの2つをサポート。
AWSのElasticache相当。
- shared
- 他のユーザとリソースを共有する。利用リソースは保証されず(=ベストエフォート)、他のユーザの影響を受けうる。
- dedicated
- 自分だけが占有するmemcache。利用リソースが保証される。
BigQuery
サーバレスなDWH。大量のデータから複雑なクエリを高速に実行する(OLAP)ビッグデータ分析向けサービス。
SQLでアクセス可能。
コンピューティングとストレージが分離されている。AWS RedShift Spectrum的な?
バッチ読み込みのほか、DataflowやPub/Subに繋いでストリーミング読み込みも可能。
データセットはプロジェクトに関連付く。
ジョブ(クエリやコピー、エクスポートなどの操作)はプロジェクトに紐づく。(異なるプロジェクトのデータでも実行可能。)
→ グループ会社でデータを提供する時にはIAM権限をあげるだけ。
→ Analytics Hubでデータ共有も可能。
- Analytics Hubに一度公開
- リアルタイムな分析には向いていない。→ リアルタイム性ならBigtable
- 特定の行を削除するクエリは非推奨 → テーブルの再作成が必要になりコストがかかる。
- パーティションをタイムスタンプにし、
time_partitioning_expirationオプションを使用して有効期限を設定できる。 - アクセス制御リスト (ACL)
- 特定のオブジェクトへのアクセス権を管理できる。
- データアクセス監査ログは明示的に有効にする必要がある。
コンポーネント
データセット
- ロケーションにデータを保存する。
- クエリ実行は同一ロケーションのデータにのみ。別ロケーションのデータにはアクセスできない。
テーブル
通常のDBのテーブル
ビュー
仮想的なテーブル。
通常のビュー : 実態は事前定義したSELECT文なので毎回ソースにアクセスが発生する
マテリアライズドビュー : 事前計算済みのテーブル。キャッシュするのでコストメリットがある。ソースデータに変更を加えると再計算される。
ルーティン
種々のデータ処理。
ユーザ定義の関数を実行したり、CLoud Functionsの関数と連携して実行することが可能。
外部データソース
サポートされたBigQuery以外のデータソースに対して直接接続してデータ操作可能。
パフォーマンス
パーティショニング : テーブルの分割。Athenaとかと考えは一緒。
クラスタリング : 特定列の値に基づくソートやフィルタ
BI Engine
各種BIからのリクエストをインメモリにキャッシュすることでデータアクセスを高速化することができる。 (AthenaのSPICE相当?)
データレイクの設計
以下の構成がある。
- データレイクを中央に置き、各部門がデータマートとして必要なデータのサブセットを取り出す。
- 各部門がデータレイクとして一次データを所有し、中央のデータウェアハウスに集計して取り込ませる。
BigQuery ML
DWHのデータを抽出し、MLにかけ、また戻すといったパイプラインを組む必要がない。中に組み込まれている。→ SQL文でモデル(一般的な線形回帰やロジスティック回帰...etc)を作成できる。
ACL
特定のオブジェクトへのアクセス権を管理できる。
- 列レベルのきめ細かいアクセス制御
- アクセス不可にするか
- 他にもnullや0でマスクして返すなど挙動を指定することも可能。
- 行レベルのきめ細かいアクセス制御
- パフォーマンスメリットはないのでTableを分ける方がいい。
VPCサービスコントロールで保護可能。
- パフォーマンスメリットはないのでTableを分ける方がいい。
データセット単位で権限を与えるとそのデータセットのデータが全て閲覧できてしまうため、他のプロジェクトから一部のテーブルやデータのみを閲覧させる場合、該当プロジェクト用にデータセットを別途作成する。共有したいデータへのアクセスはビューを作成することで解決する。
該当プロジェクトからビュー/データセットへのアクセス権を付与し、ビューからオリジナルのデータセットへのアクセスを許可することで対応できる。
他
- テーブルスナップショット
- 読み取り専用
- テーブルクローン
- 読み書き可能
IaCまとめ
Cloud Deployment Manager
- Google Cloud環境のIaC。YAMLで定義。Python、jinja2で作成可能。AWS CloudFormationやAWS CDK相当
- 今後はConfig Controllerを推奨。
Config Controller
- Google Cloud環境のIaC(IaD?)。
- Kubernetes上で動作しYaml定義をkubectl applyでデプロイする。
Configuration as Data (CaD) は、リソースをプロビジョニングするための操作や手順を定義するのではなく、リソースの理想の状態をデータとして定義する宣言型アプローチです。(CaD の詳細については以下の公式 Blog をご覧ください)
Terraform
多くのクラウドプロバイダに対応したOSS。
マルチクラウド化するにあたり重要。
ローカル端末からTerraformを使いたい場合、サービスアカウントキーを発行するかgcloud auth application-default login(推奨)を利用する。
gcloud auth application-default login を実行すると、個人の Google アカウントもしくはサービスアカウントを使って認証し、任意のアプリケーションが Google Cloud API にアクセスできるようになります。
認証に成功すると、Go や Python といった言語で記述したプログラムや IaC ツールに代表される Terraform など、様々なアプリケーションが Google Cloud の API を呼び出せます。
対応イメージ
terraform init = cdk init (必要なプロバイダプラグインがDLされる)
terraform plan = cdk diff
terraform apply = cdk deploy (デプロイ後terraform.tsstateにデプロイ後の状態がjsonで定義されている。)
terraform destroy = cdk destroy
terraform.tsstateは超重要ファイル。既存環境を表すため、これがなくなると差異の確認や既存リソース削除ができなくなる。
// TODO 後で見る。
→ https://cloud.google.com/docs/terraform?hl=ja
よく使う構成はTerraformが公式モジュール化しているものがある(AWSもGoogle Clloudでも)。
Ansible
構成管理ツール。インスタンス内向け。
ChefやPuppetは管理対象にエージェントを入れるPull型な一方でAnsibleはPush型。
Pythonベースで動く。
Yaml定義されたPlaybookを作成し宣言的に状態を定義し、コントローラ側でPlaybookを実行するとSSH経由でターゲットのサーバに処理を実行し環境構築を行う。
CMSであるWordPressなどを利用してApacheやMySQL、PHPなどのインストールも発生しそれらの設定も必要になることを考えるとAnsibleで自動化されると楽。
Artifact Registory
Container Registoryの後継。
Container Analysis
- Artifact Resistory内のコンテナイメージの脆弱性スキャン。
- CICDパイプラインに組み込むことが可能。
- Pub/Sub連携で通知なども。
Binary Authorization (バイナリ認証)
- CICDパイプラインにおいてイメージの信頼性確保のため、Dockerイメージが信頼できるソースから生成されていることを確認する仕組み。
- イメージの証明書チェックやイメージ名の許可リストとの照合
- ポリシーによって特定の環境にデプロイできるイメージを制限することも可能。
Cloud Pub/Sub
AWS SNS相当。(SQSっぽい側面も感じる)
- At-least-once配信モデルを採用しているためサブスクライバの処理には冪等性を持たせる必要がある。
- → 重複排除を行いたい場合はDataflowに繋ぎ追加実装する必要がある。
- バッチ処理
- 複数のメッセージを蓄積しまとめて配信することが可能。
- デッドレタートピック
- 再思考回数上限に達したメッセージを捨てる場所。
- Pub/Sub Lite
- Cloud Pub/Subより可用性を削りコストを抑えたもの。
- 顧客管理の暗号化に対応。
- 厳密な時系列順のデータ配信を保証する場合、Dataflowと連携する必要がある。 // ほんと?
Cloud Tasks
Pub/Subとの比較。
- 順序保証なし
- デッドレターなし
Google Kubernetes Engine (GKE)
以下2種類のモードがある。
- Standard
- Autopilot
- Autopilotではユーザが直接NodeにSSHが禁止されていたり、Google提供のContainer-Optimized OSのみが利用可能であったり制限はある。
- → 低レイヤを触る必要がある場合やOSに指定がある場合に選択できないことがある。
クラスタ
- シングルゾーンクラスタ
- マルチゾーンクラスタ
- リージョンクラスタ (AutoPilotではこれ)
| シングルゾーン | マルチゾーン | リージョン | |
|---|---|---|---|
| コントロールプレーン | 1zone | 1zone | 3zone |
| ノードプレーン | 1zone | 3zone | 3zone |
| ゾーン障害時のクラスタ操作 | x | x | o |
| ゾーン障害時のアプリケーション稼働 | x | o | o |
ネットワーク
ルートベースクラスタ (非推奨)
- クラスタ内でPodやServiceの使用するIPアドレス範囲をノードが作成されるVPCネットワークと異なるネットワークとする。
VPC ネイティブクラスタ
- 推奨。Autopilotモードではこれ。
- クラスタ内でPodやServiceの使用するIPアドレス範囲をノードが作成されるVPCネットワークと同一のネットワークに揃える。
- 各リソースにVPCサブネットを割り当てることでVPCに関連する機能(ピア接続、CloudVPN、ネットワークエンドポイントグループによる負荷分散、FWなど)を直接利用できるようになる。
- 限定公開クラスタを設定可能。
プライベートクラスタ(限定公開クラスタ)
パブリックに公開されるエンドポイントを制限しセキュリティを高めたもの。
- 通常のGKEクラスタは、ノードに対してパブリックIPが付与されており、Nodeportを利用してワークロードを公開することで外部からアクセスできる。
- コントロールプレーンに対してはパブリックエンドポイント(kube-apiserverのエンドポイント)が提供されており、インターネットからクラスタに対するkubectlによる操作が可能。
コントロールプレーンのエンドポイント(kube-apiserver APIエンドポイント)の種類
- パブリックエンドポイント
- 承認済みネットワーク (Master Authorized Network)を設定することでパブリックエンドポイントへのアクセス元IPを制限できる。ホワイトリスト的なイメージ。
- プライベートエンドポイント
- ノードにはプライベート IP アドレスのみが付与されクラスタの属するVPC内からのみアクセス可。→ GCEでbastionを立てる必要がある。
- さらにパブリックエンドポイント同様に承認済みネットワーク (Master Authorized Network)を設定してbastionのサブネットを登録する必要がある。
- ノードにはプライベート IP アドレスのみが付与されクラスタの属するVPC内からのみアクセス可。→ GCEでbastionを立てる必要がある。
クラスタの種類
- パブリッククラスタ(デフォルト)
- コントロールプレーンとノードプレーンの間はパブリックIPでアクセス。
- コントロールプレーンはパブリックエンドポイント。
- ノードプレーンはインターネットアクセス可能。
- もちろんVPCリソースなのでファイアウォール設定で許可された通信のみ。
- プライベートクラスタ
- コントロールプレーンとノードプレーンの間はVPCピアリング接続されVPC間でプライベートIPでアクセス。
- コントロールプレーンはプライベートエンドポイント。
- ノードはプライベート IP アドレスのみが付与されクラスタの属するVPC内からのみアクセス可。
- 外部からアクセスさせたい場合にはLB(Service/Ingress)を構成しインターネットアクセスできる様にする
- ノードからインターネットアクセスが必要になる場合はCloud NATをVPCに構築する必要がある。
- Google Cloud APIにアクセスが必要な場合、Private Google AccessでもOK。

Network Endpoint Group (NEG)
GKEではCloud Load Balancing + kube-proxyの2種類のロードバランシングがかかっている。
→ 極めて低レイテンシな通信を要求する場合にはLBから直接Podにバランシングさせる方法。(ネイティブクラスタでは内部的にPodのIPがわかるので直接飛ばせている。)
DodeLocal DNS Cache
ノード上でDNSをキャッシュできるアドオン。
ストレージ管理
- Persistent Disk
- 1つのPodが書き込み可能。Readは複数から可能。
- Cloud Filestore
- 複数Podが読み書き可能
アップグレード
リリースチャネル
- Rapid : 最新 (SLA対象外)
- Regular : バランス型
- Stable : 安定
メンテナンスウィンドウ
DBと同様。割愛。
ノードアップグレード
In-place(サージ)アップグレード
- 無停止てアップグレート可能。
- ローリングアップレード
- Nodeのアップグレード速度を支配するパラメータ
- Max Surge
- Max unavailable
- Podを落とす設定
- PodDisruptionBudget (Nodeのと同様の設定)
- TerminationGracePeriodSeconds (猶予期間)
Blue/Greenアップグレード(ノードレベル)
一部ユーザによる手動操作が必要になる
Blue/Greenアップグレード(クラスタレベル)
一部ユーザによる手動操作が必要になる
クラスタのスケーリング
ノードのスケーリング
ClusterAutoscaler
Node自体のスケーリング。
一般にCPU/メモリ使用率などをもとにしてスケーリングする場合にはHorizontalPodAutoscalerなどのPodのスケーリングと共に設定する。
Node Auto-Provisioning (NAP)
- スケジューリングされたPodサイズに応じて適切なマシンサイズをプロビジョニングし、ノードプール(=クラスタ内で同じ構成を持つノードのグループ)単位で増減させる。
- GKE AutopilotではNAPを利用してプロビジョニングされている。
Podのスケーリング
Horizontal Pod Autoscaler (HPA)
- 水平スケール
- CPU/メモリなどのインスタンスメトリクスに基づいたスケーリングのほか、Pub/Subキューのメッセージ数を元にしたスケールなども可能。
Vertical Pod Autoscaler (VPA)
- 垂直スケール
- 以下の更新モードが提供される。
- Off : 推奨値を算出するのみ
- Initial : 既存のPodの再起動は伴わない
- Auto : 既存のPodの再起動を伴う
- ユースケース
- 基本HPA推奨。Offモードとして推奨スペックの見積もりに利用する用途としては有用。
Multidimensional Pod AutoScaler (MPA)
- HPAとVPAの併用版。
- ユースケース
- CPU UtilizationベースでPod数をスケーリングさせつつ、OOM予防のためにメモリベースの垂直スケールも含めるなどの場合に有用。
セキュリテイ
Workload Identity
特定のPodからのGoogleCloud内へのリソースアクセスを与える場合、クラスタにIAMサービスアカウントを設定すると全てのPodにアクセス権を当ててしまう。
→ k8sのリソースであるサービスアカウントとIAMサービスアカウントを紐づける(Workload Identity)ことでよりきめ細かいアクセス制御が可能となる。
オートヒール
Node Auto Repair
- UnhealthyなNodeを自動的に再作成する。
オートアップグレード
クラスタのアップグレードにおける運用負荷を軽減する。
リリースチャネル
- リリースチャネルにクラスタを登録することでControl PlaneのみではなくNode Planeもバージョンアップグレードもマネージドに更新される。(Autopilotモードでは自動でリリースチャネルに登録される。)
- Rapid、Regular、Stableの3つのチャネルの種類を提供。
- 予めメンテナンスウィンドウを指定し、アップデートの適用時間帯を指定することが可能。
ロールアウトシーケンス
- 複数クラスタ間での自動アップグレードの順序を制御する。
- dev環境→stg環境→prd環境の順でアップグレードを適応できる様にするなど。
アップグレード戦略
- サージアップグレード : ローリング方式。一時的に縮退運転となりうる。
- Blue/Greenアップグレード : 一時的にノード数が2倍になる分コストにはなる。ロールバックは迅速。
参考
他
GKE On-prem
オンプレミス環境でGKEを利用するためのサービス。
現在はAnthos Cluster for VMWare。
Cloud DNS for GKE
クラスタ内のDNSコンポーネント(kube-dns)をCloud DNSに拡張したもの。
NodeLocal DNSCacheアドオンを有効にすることで各NodeでDNSキャッシュが可能。
Backup for GKE
アドオン。GKE クラスタ全体をバックアップ可能。
Cloud Operations for GKE
- 有効にすることでGKEクラスタのトラブルシュートやシステム全体のパフォーマンスの可視化を行うことが可能。
[廃止] kubemci (k8s-multicluster-ingress)
→ Ingress for Anthosが後継。
- 複数のKubernetesクラスターに跨ったIngressを作成するGoogle Cloudのツール。
- グローバルロードバランサを作成し複数のクラスタ間でトラフィックを分散させることが可能。
GKE vs Cloud Run
- 規模 大規模かどうか
- サーバレス(ゼロスケール)可能な点
- カーネルレベルのパフォーマンスチューニング要否
ワークロード
Kubernetes上で実行中のアプリケーションです。
ワークロードが1つのコンポーネントからなる場合でも、複数のコンポーネントが協調して動作する場合でも、KubernetesではそれらはPodの集合として実行されます。
GKEで対応するワークロード
- Deployment
- ステートレスアプリケーション
- 多くのWebアプリケーション向け
- Stateful
- ステートフルアプリケーション
- DBやメッセージキュー向け
- Job
- バッジジョブ
- DeamonSet
- デーモン。ユーザーの介入を必要とせずに、割り当てられたノードで継続的なバックグラウンド タスクを実行する。
- ログ収集やモニタリングツール向け
Google Cloud Operation Suite
Google Cloudのパフォーマンスと可用性を監視するためのツール群。
ログ管理のCloud Loggingのほか、メトリクス管理のCloud Monitoringがある。
Cloud Logging
ログ管理。
Google Cloudの全てのアクティビティ(リソースの作成/削除/変更など)も記録される。Cloud TrailとCloudWatchの機能の統合版?
→ ログエクスプローラで確認可能。
- Google Cloudのログ
- エージェントのログ
- VPCフローログ
- ユーザ作成のログ
- 監査ログ ( = Cloud Audit Logs)
- 管理アクティビティ監査ログ
- メタデータ/構成情報の作成/変更/削除などユーザ操作を伴うGoogle Cloud内の変更。
- _Requiredパケット
- デフォルト有効
- システムイベント監査ログ
- ユーザ操作を伴わないGoogle Cloud内の変更。
- _Requiredパケット
- デフォルト有効
- ポリシー拒否監査ログ
- VPC サービスコントロールのポリシーで拒否されたログを記録。
- _Defaultパケット
- デフォルト有効
- データアクセス監査ログ
- データに対する変更。メタデータ/構成情報の読み取り
- デフォルト無効
- ただしBigQueryのselect文の実行はデフォルト有効。無効化できない。
- _Defaultバケット
- 管理アクティビティ監査ログ
- アクセスの透明性ログ
- サポートで環境に触った際のログ
GCEからログ出力する場合はOpsエージェントが必要。 (AWSと一緒。CWLogsエージェント入れる)
- シンク
- Cloud Loggingの受け取るログは全てLog Routerを通過する。
- シンクはLog Routerにおいてログの振り分けを行うコンポーネント。
- デフォルトでは_Requiredシンク、_Defaultシンクがあり、それぞれのCloud Loggingバケットに対して転送し、前者は400days、後者は30days保持される。 CloudWatchログストリーム相当。
- ユーザ定義のシンクを作成することで任意の場所にログを転送することができ、転送先としては、Cloud LoggingバケットやGCSバケットのほか、BigQueryデータセット、Pub/Sub、Splunkなどがサポートされる。Pub/Subを通しCloudFunctionsなどをトリガするアーキテクチャが可能。
- 集約エクスポート(集約シンク)を組織やフォルダリソースに作成することで組織やフォルダに属するすべてのプロジェクトからログをエクスポート可能となる。
- _Requiredバケット、_Defaultバケットはデフォルトでグローバルに作成されるが任意のリージョンに変更可能。ただし組織全体にかかる設定。また、作成後は変更不可。
Cloud Monitoring
各種メトリクス収集。
-
メトリクスをトリガとしたアラートを設定可能。
-
SLOを定義し監視することも可能。
-
標準メトリクスのほかカスタムメトリクスを格納できる。ダッシュボード化することでサービスのKPI監視として有用。
-
アップタイムチェック
- 公開サービスの稼働時間をチェックできる。
- 死活監視などに有用。 → 失敗時にCloud Functionsをトリガして通知などの運用が可能。
スコーププロジェクト
- 複数のプロジェクトを横断して管理したい場合、監視対象のプロジェクトを束ねた監視専用のプロジェクト(=スコーププロジェクト)を作成することがベスト。
インシデントの管理
アラートにインシデントを定義でき、それらの対応状況を管理できる。
メトリクスエクスプローラ
グラフで可視化→ ダッシュボードに登録できる。
稼働時間チェック
SLO(目標)を定義し管理可能。(※SLAは保証。)
SLOの定義するには SLIを定義する必要がある。
ErrorBudget = (1 - SLO)
ErrorBudgetが100%であることがいいことではない。=アプリケーションに変更を加えなければ達成される。→ ErrorBudgetの範囲で変更を加えアプリケーションを進化させることが重要(SREの考え方)
メトリクス
- 一度に 1 つの値で構成される測定値 →
valueTypeはBOOLやINT64などを指定。 - 分布の測定の場合、値は単一の値ではなく集合となる。
valueTypeはDISTRIBUTION。
metricKind フィールド
- GAUGE : 特定の時点で測定される値(時間単位の温度レコードなど)。
- CUMULATIVE 指標 : 特定の時点に測定対象となったデータの累積値が保存されます(例: 車両の走行距離計)。
- DELTA 指標 : 特定の期間に測定される対象の値の変化(株式の損失や損失を示す株式の概要など)。
アラートポリシー (通知ポリシー)
ClousWatch Alarm相当。
メトリクスを選択し条件式と異常時の通知先を指定する。
Cloud Trace
トレースを提供。AWS X-Ray相当。OSSだとOpenTelemetry。
複数のマイクロサービスで構成される一連のアプリケーションのパフォーマンスを計測し、ボトルネックとなっている箇所を割り出す。
- Cloud Monitoringにメトリクスではダメなのはなぜか?
- 複数のサービスがを横断する状況だと個々のサービスのパフォーマンス、処理時間を見ることが難しい。
Cloud Profiler
アプリケーションのパフォーマンス(リソース消費(CPUやヒープ)など)を継続的にプロファイリングする。
リアルタイムのレイテンシ確認(Traceの仕事)やアラート(Monitoringの仕事)の発報には向かない。
リソースを消費しているパスやコードを特定する。
プログラミング言語ごとにエージェントがあり、アプリケーション環境にインストールすることでパフォーマンスを解析し問題のあるコードを特定できる。
数行のコードを埋め込むだけでProfilerパッケージを利用し分析できるようになる。
Cloud Debugger
リアルタイムのアプリケーションデバッグなどトラブルシュートに役立つツール。
デバッグログポイント
サービス再起動や再デプロイ不要で、実行中のサービスにロギングを挿入することができる機能。
プリントデバッグを行う場合に何度もデプロイし直す必要がなくなる。
Error Reporting
内部にはCloud Logging上で稼働。
実行中のアプリケーションで発生したエラーを自動的に追跡、分析、通知するツール。エラーカウントや分析に利用。
アプリケーションの死活監視のように稼働状況を定期的に監視して通知するような用途のサービスではない。→ 監視したいならCloud Monitoringでアップタイムチェック(ヘルスチェック機能)。
Managed Service for Prometheus
フルマネージドのPrometheus(GKEの外形監視OSS)。
Log Analytice
ログデータをBigQueryで直接ログ分析できるCloud LoggingとBigQueryの統合サービス。
VPCフローログ
傾向分析。VPCのトラフィックをサンプリング。
パケットミラーリング
VPCのトラフィックをミラーリング。
Security Command Center
把握、保護、検出、報告、対策の各ステップを網羅的に管理。 AWS Guard Duty相当?
公開されたバケットの検出やVPCフローログの設定有無などを検出可能。
脅威検知
Firebase
Firebase Test Lab
種々のデバイス(モバイル等)およびデバイス設定で自動テストを実行できるサービス。対象デバイス上でのテスト実行結果をレポートとして得られる。
Cloud Identity Aware Proxy (IAP)
- IAP TCP転送
- HTTPSアクセスをプロキシし、ポート22に転送しすることで擬似的なSSHを提供。
- AWS SSM Session Manager相当。
- CLBの前段に置くことで認証処理をアプリケーションの変更を伴わずに挟むことが可能。
Private Google Access (限定公開のGoogleアクセス)
- VPC内からGCSやSpanner、BigQueryなどのグローバルリソースへのアクセスは通常不可。(AWS VPC同様ネットワーク的に隔絶されているため。)
- 199.36.153.8/30 private.googleapi.com をユーザのオンプレミスのルータやVPC内のルータに設定することでGoogle APIの通信をGoogleネットワーク内に限定することができる。
- ただ、全てのリクエストがここを通るので特定のVPCだけに限定したいといった用途で困る。
- → Private Service Connectが後継サービス。
Private Service Connect
Private Google Accessの後継。
Private Service ConnectエンドポイントをVPC内に作成しエンドポイントにGoogle APIリクエストを送信する。
サーバレスVPCアクセスコネクタ
- サーバレス環境(Cloud RunやApp Engine等)からVPCネットワークのリソース(Cloud SQLなど)にアクセスする際に中継するリソース。
- コネクタの実態はGCEインスタンスであるためコネクタインスタンスのコストが発生する。
- コネクタインスタンスは自動でスケールアウトするがスケールインはしない。 // TODO え?
- 現在プレビューだがDirect VPC egressを用いることで直接VPC内にCLoud Runを配置可能。インスタンスコストがかからない。
まとめ
- VPCリソース(オンプレからInterconnect接続した場合なども含む)からサーバレスリソースにアクセスする場合
- Private Google Access
- オンプレミスホスト用のPrivate Google Access
- Private Service Connect
-サーバレスリソースからVPCリソースにアクセスする場合
-サーバレスVPCアクセスコネクタ
Cloud Shell
~/bin配下にセッションを跨いで永続する5GBのストレージが利用可能。
Go、Python、Java、.NET Core、Node.js をサポートしており、オンライン開発環境として利用可能。
Cloud Data Catalog
データカタログ。社内のデータ資産を一元的に網羅的に整理したインベントリ。実態はメタデータを管理している。AWS Glue DataCatalog相当?
Cloud Data Loss Prevention (DLP : データ損失防止)
個人情報などの機密データを識別し、検出時にマスクしたり削除したりといった保護アクションを実行できる。Amazon Macie相当?
BigQueryなどの列指向DBに格納するデータ内の個人情報をDLPにて検出しDataCatalogでメタデータとしてその保持する場所を特定できるようにしておくことで任意の機密データを削除することが可能(特に列指向DBでは対象データを含むレコードを削除しようとすると大量のコストがかかり非効率なため有用)
Cloud Load Balancing (CLB)
- LBはファイアウォールルールにてソースとして指定できない。 // AWSと違う点
- 直接Cloud Entpointsをバックエンドに指定することはできない。 // これもNEG? 要調査
分類
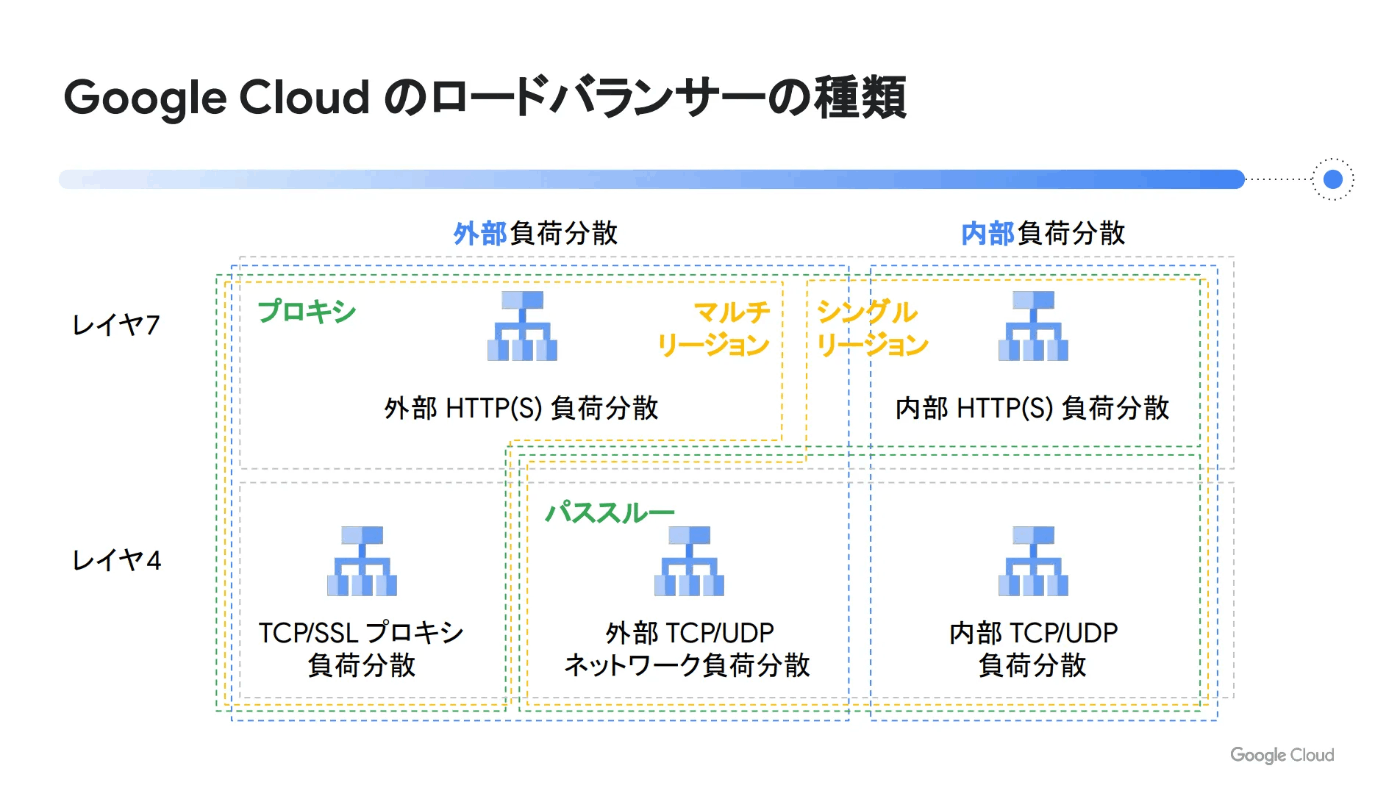
▲ 引用元 : https://www.topgate.co.jp/blog/google-service/20716#レイヤによる分類
-
URLマップ
-パスベースで転送先のバックエンドをルーティングできる。 -
セッションアフィニティ
- スティッキーセッション相当の機能。
- HTTPセッションやWebSocketでは特定のユーザセッションに関連付けられたデータがクライアントとサーバ間で維持される必要があり、常に同じサーバーに送られる必要がある。
-
種々のバックエンドサービスを指定する歳に論理的なエンドポイントとしてNEGを提供。
Cloud CDN
コンテンツキャッシュ。CloudFront相当。
ただ、注意すべきはLBに組み込まれている。Google Cloudにおいては前段に立てるという認識は間違い。
ちなみに、他の CDN ですと「CDN」という別種のサービスがあって、それを自分のサービスの手前(エンドユーザーとの間)に置く、といったイメージの方が多いと思います。つまり、CDN サービス → ロードバランサー → バックエンド、みたいなイメージです。そのため CDN の設定というと、「ロードバランサー( → バックエンド)」を指定することになると思います。
しかし、GCP では HTTP(S) Load Balancing 自体が巨大な CDN 機能付きロードバランサーなので、「CDN サービス → ロードバランサー」が一体化しており、CDN の設定というのは「バックエンド」の部分を指定する形になります。
絵にすると ↓ みたいな感じです。少し考え方が異なるので戸惑いがあるかもしれません。
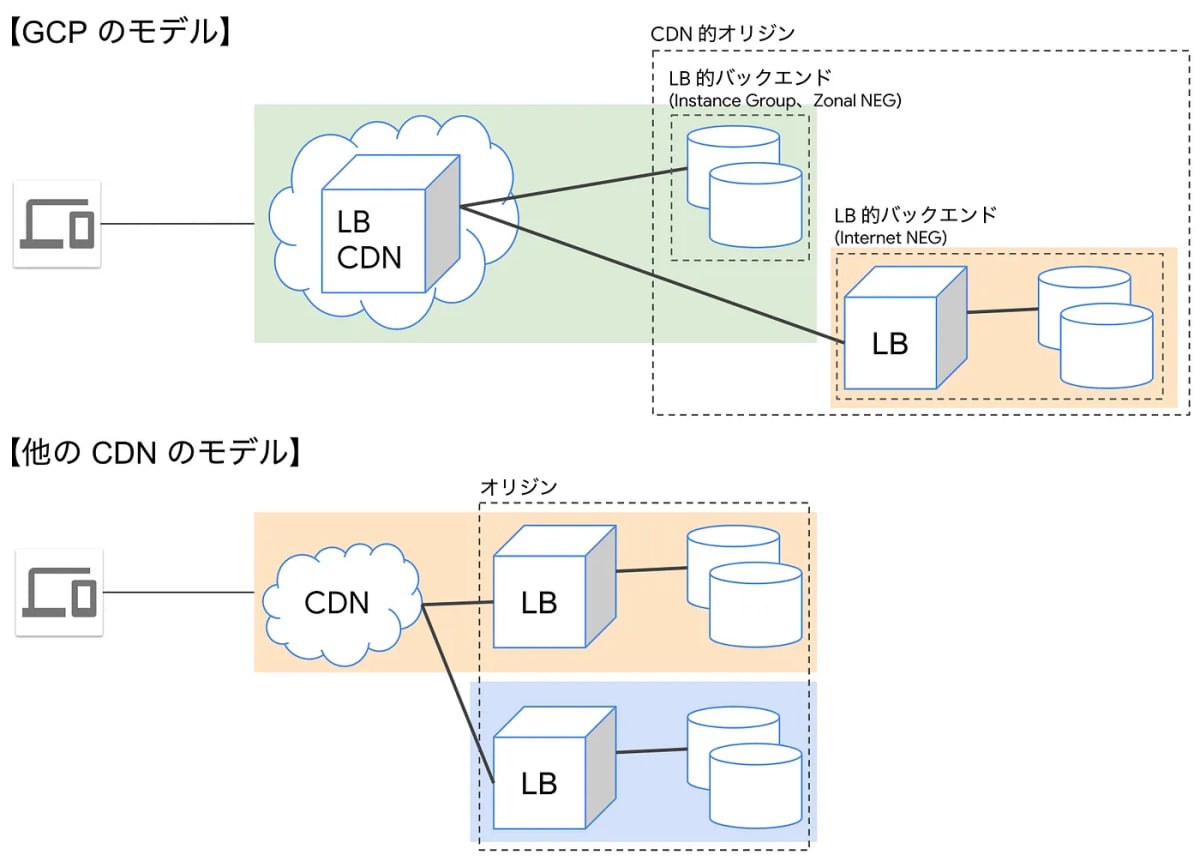
▲ 引用元: https://medium.com/google-cloud-jp/cloud-cdn-custom-origins-dd496092b395
- キャッシュ
- スキーム(プロトコル)やホスト名、クエリパラメータなどのキャッシュキーに基づきキャッシュされる。
- すなわちキーにプロトコルを含んでいるとHTTPSとHTTPを区別するためキャッシュ効率が低下し得る。
Cloud Armor
AWS WAF相当。アプリケーションレイヤの攻撃を検知し、防御する。
基本、Cloud Load Balancing の背後にある Web アプリケーションのみを保護可能。
セキュリティポリシー
- 以下3種類
- バックエンドセキュリティポリシー
- エッジロケーションからバックエンドにルーティングされたリクエストを評価。
- すなわちキャッシュヒットしなかったリクエストや動的コンテンツなどが対象。
- エッジからキャッシュで返されるリクエストは評価対象外。
- エッジセキュリティポリシー
- エッジからキャッシュを返す前に評価。
- Cloud CDN を有効化したバックエンドや Cloud Storage バケットが対象となる。
- ネットワークエッジセキュリティポリシー
- LBを使わない VMにも利用可能なポリシー。
- 接続元IPなどによる制限をかけ、Googleのネットワークのエッジでブロックする。
- 不正アクセスやDDoSを防げる。
- バックエンドセキュリティポリシー
- セキュリティポリシー内には複数のルールを定義する。
ルール
- ルールは優先度の高いものから評価される。
-
gclout compute security-policiesコマンドで操作する。
DDoS保護
Standard Tier と Enterprise Tier の2種類。
- Enterprise TierではDDOSの請求保護が受けられる。(Shield Advanced相当。)
- Adaptive Protectionに対応。(Enterprise Tierでは全機能、Standardではアラート機能のみ利用可能。)
- 機械学習モデルに基づき、DDoS攻撃と思われる挙動を検出、アラートやシグネチャを自動生成する機能。
- Enterprise Tierに登録すると、Cloud Logging と Cloud Monitoring でDDoS攻撃の状況を可視化できる。
スロットリング
リクエストにレート制限をかけることが可能。
他
- reCAPTCHA Enterprise との統合によりbot対策可能。
- WAFのブロックログはCLBのログを有効にする必要がある。
Looker Studio (旧Data Studio)
BIツール。QuickSight相当
Google Data StudioのリンクがLooker Studioにリダイレクトされてるのでおそらく後継。調べても旧Data Portalみたいな名称で出てくるので謎。
Cloud Datalab
Jupyter Notebookをベースとして作られた大規模データ分析・可視化のためのツール。
CLoud Monitoringのメトリクスをより深く掘り下げて確認したいようなケースで利用される。
Anthos
Google Cloud以外の環境で動くGKEベースのKubernetesサービスを提供し、オンプレミスやAWS、Azureなどの他社クラウドでも統一的にコンテナを管理できるようにする仕組み。
Anthos Service Mesh
フルマネージドなIstio。
コンテナ間の通信を管理し、メトリクス取得やFault Injectionを提供する。
Anthos Config management
環境間で統一したポリシーや設定を適用するためのツール。
Recommender
Trusted Advisor的な立ち位置?。アイドリング中のVMやオーバースペックなVMを通知したり、解放されている静的IPなどを発見可能。
プロジェクトとゾーンを指定する必要がある。 → Cloud Asset Inventory と組み合わせることで効果的になる。
Cloud Asset Inventory
組織全体のリソースを一括で検索可能。
Cloud Endpoints
今ではCloud API Gatewayが主流? Cloud API Gatewayが後継サービス。
Google Cloudのサービスにプロキシ(Envoyをベースに作られてるらしい)を置き、API機能を持たせる。
サーバレスサービスの前段にCloud Endpoints+Cloud Runの構成をおかないといけなかったところをマネージドなAPI Gatewayをおくことで省力化。→ Cloud API Gatewayへ
Cloud API Gateway
API GW相当。
Apigee
APIのプロキシとしての機能のほか、使用状況を監視/分析しAPIの課金を管理する機能などを提供している。
→ 商用APIとして公開する場合などに利用される。
→ その利用率をモニタリングすることで今後の開発の投資方針などに役立てることが可能。
比較
Vertex Explainable AI
モデルの意思決定の理由について特徴ベースの説明と例に基づく説明が提供される。
Storage Transfer Service
AWSやAzure、オンプレミス等のストレージからGCSにファイルを自動で転送することが可能。
Google Cloud Status Dashboard
サービスの正常性やインシデントに関する情報提供の場所。
FeedのURLはhttps://status.cloud.google.com/feed.atom。
Google Cloud Security Bulletins
脆弱性情報、影響と対処法を確認できる。
Web Security Scanner (旧Cloud Security Scanner)
App Engine、GCE、GKE上のWebアプリケーションにおける脆弱性スキャンを実行できる。
Firebase
- Firebase Test Lab
- モバイルアプリケーションテストサービス。異なるデバイスやシステム構成(AndroidやiOS)でのテストをクラウド上で自動化可能。
- Firebase Hosting
- 静的ウェブサイトをホスティングするサービス。
- 高速なグローバルCDNとHTTPSの自動プロビジョニングを利用可能。
Cloud Billing
- ユーザごとの利用とかは見れない。 AWSでもそう
- 細かいところまで見たい場合はBigQueryで実施する必要がある。
- 課金エクスポート
- ファイル出力もしくはBigQueryのデータセットへ1日毎に出力できる。
- ユーザ単位などの細かい情報は見れないため、アクセスログをLoggingに流し、抽出した情報をBigQueryへ転送するシンクを設定する方法を取る。
Secret Manager
DBへの認証情報を安全に保存する。
Cloud Resource Manager
// TODO
Cloud Source Repositories (CSR)
プライベートgitリポジトリ。AWS CodeCommitと一緒。
外部リポジトリとの同期を有効にすることが可能。
→ coddeCommitと一緒で、外部を直接参照してるわけではなく同期なのでコストメリットとかがあるわけではない。