3.1 変数とデータ型~Java Basic編
はじめに
自己紹介
皆さん、こんにちは、Udemy講師の斉藤賢哉です。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Basic編』の一部の範囲をカバーしたものです。『Java Basic編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをZenn内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの言語仕様や文法を正しく理解すると同時に、現場での実践的なスキル習得を目指している方
- 新卒でIT企業に入社、またはIT部門に配属になった、新米システムエンジニアの方
- 長年IT部門で活躍されてきた中堅層の方で、学び直し(リスキル)に挑戦しようとしている方
- 今後、フリーランスエンジニアとしてのキャリアを検討している方
- 「Chat GPT」のエンジニアリングへの活用に興味のある方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
- IT企業やIT部門の教育研修部門において、新人研修やリスキルのためのオンライン教材をお探しの方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
3.1 変数とデータ型
チャプターの概要
このチャプターでは、Javaプログラミングの最も基本的な概念である変数と、変数に格納する値の種類を表すデータ型について学びます。
3.1.1 変数の概念と使用方法
変数とは
変数は、あらゆるプログラミング言語において共通的な概念です。
変数とは、方程式における変数と同じように、データを格納するための「入れ物」です。変数にデータを格納したら、格納されたデータをプログラム内で持ち運び、値を取り出して何らかの処理を行います。つまりプログラムの中にデータを固定的に埋め込むのではなく、変数という「入れ物」を用意することによって、データの中身に応じた処理を可能にするのです。
もし変数がなかったら、どのようなことが起きるでしょうか。数値の10を使って、プログラムの中で足し算を行ったり、引き算を行ったり、掛け算を行ったりするとき、10という数値を様々な場所に埋め込む必要が生じます。また後から10を20に変更したり、計算対象データをプログラムの外から与えたりすることは困難です。
【図3-1-1】もし変数がなかったら…

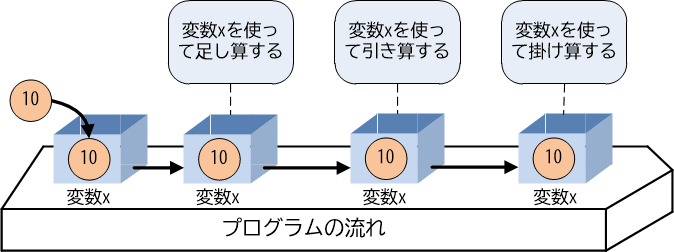
こういった課題は変数によって解決できます。数値10を変数xという「入れ物」に入れてしまえば、変数xに対して演算を行うプログラムを記述することにより、同じ仕様を実現できます。また変数を利用すると、10を20に変更することも、計算対象データをプログラムの外から与えることも容易です。
【図3-1-2】変数を利用すると…
変数の種類
Javaの変数は、大きく2つに分類されます。1つ目は、クラスのメンバーとして宣言されるフィールドで、メンバー変数とも呼ばれます。フィールドについては、詳細はチャプター7.2で説明します。もう1つはローカル変数で、宣言されたブロック内でのみ有効な変数です。単に「変数」という言い方をした場合は、通常はローカル変数を指すものと思ってください。
変数の宣言
それでは、変数の使用方法について見ていきましょう。変数を使用するためには、まず変数を「宣言」する必要があります。変数を宣言すると、メモリ上に値を格納するための領域が確保されます。
変数は以下のようにして宣言します。
データ型 変数名;
データ型と変数名の間は、1つ以上のスペースが必要です。
具体的には以下のように記述します。
int x;
データ型とは、文字通り変数に格納できる値の種類を表すための情報です。詳細は後述しますが、代表的なデータ型にint型があります。int型は整数値を格納するためのデータ型です。
変数の複数宣言
変数の宣言では、1つの命令文内にカンマで区切ることで、複数の変数を連続して宣言することができます。
データ型 変数名, 変数名, ....;
カンマの後ろのスペースは任意ですが、見やすいコードを記述するために通常はこの位置にスペースを入れます。
具体的には以下のように記述します。
int x, y, z;
変数の初期化
変数は宣言しただけでは、単なる「入れ物」にすぎません。変数には、開発者が明示的に値を格納する必要があります。このように、変数に初期値を代入することを初期化と呼びます。
変数は以下のようにして初期化します。
変数名 = 値;
この構文における=は「値が等しい」という意味ではなく、「右辺の値を左辺の変数に代入する」という意味の記号で、代入演算子(チャプター4.1)と呼ばれるものです。演算子の前後のスペースは任意ですが、見やすいコードを記述するために、通常はこの位置にスペースを入れます。
具体的には以下のように記述します。
int x;
x = 10;
この例では、まずint型の変数xを宣言し、続いて変数xに初期値として10を代入しています。
なおローカル変数の場合[1]は、初期化を行わずに当該の変数を利用(参照)しようとすると、「初期化未済」という理由でコンパイルエラーになるため注意してください。
変数の宣言と初期化
変数の宣言と初期化を同時に行うことも可能です。
データ型 変数名 = 値;
具体的には以下のように記述します。
int x = 10;
この例では、int型の変数xを宣言すると同時に、初期値として10を代入しています。
データ型が同一の場合は、1つの命令文内にカンマで区切ることで、複数の変数を連続して定義することもできます。
具体的には以下のように記述します。
int x = 10, y = 20, z = 30;
変数(ローカル変数)の初期化は、基本的には宣言と初期化を同時に行う方が望ましいでしょう。
変数への値の再代入
変数には初期値を代入した後、再度、別の値を代入することが可能です。具体的には以下のように記述します。
int x = 10;
x = 20; // 変数xに20が格納される
このようにすると、もともと格納されていた値は新たに代入された値によって上書きされるため、変数xには20が格納されます。
なお詳細はチャプター8.2で説明しますが、final修飾子を付与することによって、変数への再代入を禁止することも可能です。
変数値の参照
変数は、何らかの処理を行い最終的に何らかの結果を得るために利用します。そのためには、一度変数に代入した値を取り出さなければ意味がありません。変数から値を取り出すことを「参照する」と言います。
int x = 10, y = 20; //【1】
int result = x + y; //【2】
System.out.println(result); //【3】
ここではまず、2つの変数xとyにそれぞれ初期値10、20を代入します【1】。そして変数xとyの足し算を行い、その結果をresultという名前の変数に代入します【2】。ここで足し算の結果を得るためには、変数resultの値を参照する必要があります。変数の値は、コード上に変数名をそのまま記述するだけで参照することができます。従って変数resultの値をコンソールに表示するためには、【3】のように記述します。このようにすると変数resultが参照され、得られた値がSystem.out.println()の引数に渡されます。このコードを実行すると、足し算結果である30が変数resultに格納され、その値がコンソールに出力されることが分かります。
変数の命名
変数は一種の識別子のため、「レッスン2.1.5 識別子とキーワード」で触れたルールに則ってさえいれば、任意の名前を付けることができます。
変数が宣言された位置と使われる位置が、近い場合には、このレッスンのサンプルにあるように、xやyといった意味のない名前でも特に問題はありません。
ただし宣言した変数が広範囲に渡って使われる場合や、チャプター7.2で登場するメンバー変数(フィールド)の場合には、可読性確保の観点で、きちんと意味のある名前を付けた方が良いでしょう。その場合、変数の命名には「Lower Camel Case」と呼ばれる記法を採用するのが、一般的なコーディング上の規約です。「Lower Camel Case」とは、単語の先頭のみ小文字で、それ以外の区切り文字は大文字で表すという記法です。例えば「顧客種別」であれば「customerType」、「前月の最初の日」であれば「prevMonth1stDay」などになるでしょう。
3.1.2 データ型の分類とプリミティブ型
データ型の分類
データ型は、大きくプリミティブ型と参照型とに分類されます。
プリミティブ型は基本データ型とも呼ばれますが、本コースではプリミティブ型という呼称で統一します。プリミティブ型をさらに分類すると、数値型、論理型、文字型といった分類があり、数値型には整数型と浮動小数点型があります。
また参照型については、配列型、クラス型、インタフェース型に分類されます。
【表3-1-1】データ型の分類
| 大分類 | 中分類 | 小分類 |
|---|---|---|
| プリミティブ型 | 数値型 | 整数型、浮動小数点型 |
| 論理型 | ||
| 文字型 | ||
| 参照型 | 配列型 | |
| クラス型 | ||
| インタフェース型 |
プリミティブ型と参照型では、変数のメモリに対する考え方が異なりますが、詳細はチャプター5.2で説明します。
実際のJavaによるアプリケーション開発で利用される型は参照型が大半であり、プリミティブ型は主としてローカル変数として使われます。また昨今では、ローカル変数の場合は後述するvarキーワードが利用できるようになったため、プリミティブ型を利用するケースは少なくなりつつあります。ただし本コースでは、参照型の概念をチャプター5.2で学習するまでは、学習しやすいプリミティブ型を用いて説明します。
プリミティブ型の分類
前項で触れたように、プリミティブ型は、数値型、論理型、文字型に分類されます。さらに数値型は、整数型と浮動小数点型に分類されます。
それぞれの種類とその特徴を、以下に示します。この表にあるとおり、それぞれのデータ型には、初期値および値の範囲とサイズが決められています。サイズというのはメモリ上に確保される容量を表します。
【表3-1-2】プリミティブ型の種類と特徴
| 分類 | プリミティブ型 | 初期値 | 取りうる値の範囲 | サイズ |
|---|---|---|---|---|
| 整数型 | byte | 0 | -128 ~ 127 | 1バイト(8ビット) |
| short | 0 | -32768 ~ 32767 | 2バイト(16ビット) | |
| int | 0 | -2147483648 ~ 2147483647 | 4バイト(32ビット) | |
| long | 0 | -2^63 ~ 2^63-1 ※およそ±920京 | 8バイト(64ビット) | |
| 浮動小数点型 | float | 0 | 約±3.4×(10の38乗)~約±1.4×(10の-45乗) | 4バイト(32ビット) |
| double | 0 | 約±1.8×(10の308乗)~約±4.9×(10の-324乗) | 8バイト(64ビット) | |
| 論値型 | boolean | FALSE | trueまたはfalse | ー |
| 文字型 | char | \u0000 | \u0000 ~ \uffff | 2バイト(16ビット) |
初期値とは、そのデータ型を宣言したときに設定されるデフォルトの値です。またサイズとは、そのデータ型を宣言した時にメモリ上に確保される容量を意味します。値の範囲はサイズと連動しており、サイズが大きければ大きいほど、広い範囲を表すことができます。例えばbyte型の場合は、サイズが1バイト(8ビット)のため、取りうる値は-128から127までの255種類の数値になります。一方同じ整数型でもlong型の場合は、サイズが8バイト(64ビット)のため、±920京という無限大に近い数値を表すことができます。
これらのデータ型について、次項から順番に見ていきましょう。
整数型
まずプリミティブ整数型には、byte型、short型、int型、long型という、4つの型があります。
この中で、byte型は、主にバイナリデータを格納するために利用します。バイナリデータの取りうる値は-128から127までの範囲なので、byte型の配列に格納するのが一般的です。
通常プログラムの中で整数を扱う場合、short型またはint型を選択しますが、どちらを選択するかは代入する値の範囲によります。メモリ容量を節約するという観点からは、なるべく最小限のメモリ容量しか消費しないデータ型を選択することが望ましいですが、昨今のコンピューティングリソースは比較的メモリに余裕があるため、特別な理由がない限りはint型を選択して問題ありません。
long型は、非常に大きな範囲の整数を取り扱うためのデータ型です。long型が必要になるような業務仕様は、通常はあまり考えられません。long型はどちらかと言うと、何らかのシステム的な管理のために利用するケースを多く見かけます。例えば、時間を整数で表現するケースや、楽観的ロックにおけるバージョンID、そしてインスタンスをシリアライズする場合のシリアルバージョンUIDなどです。ただしこれらについて、本チャプターでの説明は割愛します。
整数型における負の値と「2の補数」
整数型における負の値は、「2の補数」によって表されます。「2の補数」とは、整数を2進数で表した時に、足し合わせると桁が1つ増える最小の数のことを意味します。
例えば正の整数1は、2進数で表すと「0000 0001」です。これの「2の補数」は「桁が1つ増える最小の数」なので「1111 1111」であり、これが負の整数-1の2進数表現になります。
同じように正の整数2は、2進数で表すと「0000 0010」です。これの「2の補数」は「1111 1110」であり、これが負の整数-2の2進数表現になります。
【図3-1-3】整数型と「2の補数」

この表を見ると「2の補数」による整数表現では、最上位が符号ビットを表す、ということが分かります。
整数型の「桁あふれ」
ここでは、整数型の「負の値は2の補数で表す」という特徴を踏まえ、その値の範囲を超えた場合の挙動について説明します。例えばbyte型の範囲は-128から127ですが、byte型変数の値がその範囲を超えてもコンパイルエラーは発生しません[2]。
byte x = 100;
x = x + 300; // コンパイルエラー発生せず
このコードでは、算術の結果は100+300=400になり、byte型の上限である127を超えるため「桁あふれ」が発生します。400は2進数で表すと「1 1001 0000」ですが、byte型は8ビットのため、あふれた最上位の1ビットが削られます。あふれたビットが削られると、その結果は「1001 0000」になります。ここで整数型では、最上位ビットが符号を表す、ということを思い出してください。このビット列は-112を表しています。
つまり、100に300を足した結果をbyte型変数に代入すると、その結果はマイナスの値になるという、直感的には理解しづらい挙動になりますので、注意してください。
浮動小数点型
次に浮動小数点数を表す浮動小数点型について説明します。プリミティブ浮動小数点型には、float型とdouble型という、2つの型があります。これらの型では、IEEE754で決められた仕様に則り、符号部、指数部、仮数部に分解して値を保持します。例えば32ビットのfloat型の場合は、数値は、符号部1ビット、指数部8ビット、仮数部23ビットに分解されます(詳細は割愛)。
【図3-1-4】IEEE754による浮動小数点

注意しなければならないのは、このような浮動小数点数の2進数形式では小数を含む値を正確に表現することができず、「誤差」が発生するケースがあるという点です。例えば2進数における0.1は1/2、すなわち10進数の0.5を表します。また2進数における0.01は1/4、すなわち10進数の0.25を表します。逆に10進数における0.1は、2進数では「0.000110011…」という無限小数になるため、丸め込まれた部分が「誤差」になります。
したがって例えばif文(チャプター6.2参照)による判定処理において、以下のようなことが発生します。
double d1 = 0.1 + 0.2;
double d2 = 0.3;
if (d1 == d2) {....} // この判定はfalseになる
このコードを実行し、変数d1とd2の値が等しいかを判定すると、意図に反して結果はfalseになります。
論理型
次に論理型に分類されるboolean型です。boolean型とは、true、すなわち「真」と、false、すなわち「偽」という、2種類の論理値のみを持つ特殊なデータ型です。
boolean型変数は、同一性判定や大小判定など、何らかの条件に基づく判定結果を、trueまたはfalseで表すために使用します。典型的な用途としては、if文などの条件分岐の構文や、while文などの繰り返しの構文において、分岐やループの可否を判定するために、boolean型変数が使用されます。チャプター6.1~6.3における制御構文の説明の中でも、boolean型変数が登場します。
boolean型変数には、論理値を以下のように代入します。
boolean flag = true; // またはfalse
また例えば比較演算子==による同一性判定の結果も、boolean型変数に代入することができます。
int x = 10, y = 15;
boolean flag = y == x + 5;
2行目の式の右辺(=より右側)では、yとx + 5が同一かどうかを判定しています。両者とも15なので結果はtrueになりますが、その結果は左辺(=より左側)の変数flagに代入されます。
文字型
次に文字型に分類されるchar型です。char型は、1つの文字を扱うデータ型です。
Javaでは、文字は内部的にはUnicodeの文字番号として管理されます。Unicodeとは、文字集合の国際的な標準規格です。Unicodeには日本、中国、韓国の漢字を統合した「CJK統合漢字」の他、アラビア文字やラテン文字など世界中の様々な言語の文字が含まれており、2バイト(0~65535)の範囲内で文字番号が割り当てられています。char型のサイズが2バイトであり、値の範囲が0から65535であるのはこのためです。
char型変数には以下のように文字を代入します。
char c1 = 'ア'; //【1】
char c2 = 0x30A2; //【2】
char c3 = 12450; //【3】
これらはいずれも同じ意味になります。
単一の文字は【1】のように、シングルクオーテーションで囲んで表現します。このような表現を「文字リテラル」と呼びますが、リテラルについてはチャプター3.2でも取り上げます。
【2】はカタカナ「ア」のUnicodeにおける文字番号を、16進数によって表現したものです。
【3】は【2】と同様にカタカナ「ア」のUnicode番号ですが、こちらは10進数の表現です。
文字列型
Javaでは文字列、すなわち1つ以上の文字の連続を、String型[3]というデータ型で表現します。前述したchar型が単一の文字を表す型だったのに対して、String型には文字列を格納できますが、内部的にはchar型変数の配列としてデータを保持しています。
String型変数には、文字列を以下のように代入します。
String str = "foo";
文字列はダブルクオーテーションで囲んで表現します。このような表現を「文字列リテラル」と呼びます(チャプター3.2参照)。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 変数とは、データを格納するための「入れ物」であること。
- 変数の宣言および初期化や、格納された値を参照する方法について。
- データ型は大きく、プリミティブ型と参照型に分類されること。
- プリミティブ型データには、数値型、論理型、文字型といった種類があること。
- 整数型の種類や、整数型では負の値を「2の補数」で表すこと。
- 浮動小数点型の特徴や、誤差に注意しなければならないこと。
- 論理型、文字型の特徴について。
-
フィールドの場合は初期化未済の状態で参照してもコンパイルエラーにはならず、初期値が返される。プリミティブ型の初期値は表3-1-2にあるとおりで、参照型の初期値はnull値(チャプター5.2参照)。 ↩︎
-
byte x = 400はコンパイルエラーになるが、これはbyte型の範囲を超えたからではなく、400(int型と見なされる)よりbyte型の方が範囲が狭いデータ型のために発生したものであり、縮小変換することで解消する(チャプター3.3参照)。 ↩︎ -
String型は、Stringクラスによる参照型のデータ型だが、説明の都合上このチャプターで頭出しする。Stringクラスの特徴やAPIについては、チャプター16.1にて詳しく説明する。 ↩︎
Discussion