16.2 正規表現とAPI~Java Basic編
はじめに
自己紹介
皆さん、こんにちは、Udemy講師の斉藤賢哉です。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Basic編』の一部の範囲をカバーしたものです。『Java Basic編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価より3割以上安く購入可能なクーポンをZenn内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの言語仕様や文法を正しく理解すると同時に、現場での実践的なスキル習得を目指している方
- 新卒でIT企業に入社、またはIT部門に配属になった、新米システムエンジニアの方
- 長年IT部門で活躍されてきた中堅層の方で、学び直し(リスキル)に挑戦しようとしている方
- 今後、フリーランスエンジニアとしてのキャリアを検討している方
- 「Chat GPT」のエンジニアリングへの活用に興味のある方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
- IT企業やIT部門の教育研修部門において、新人研修やリスキルのためのオンライン教材をお探しの方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
16.2 正規表現とAPI
チャプターの概要
このチャプターでは、正規表現の基本的な仕様と、Javaで正規表現を使った検索・置換を行うためのAPIについて学びます。
16.2.1 正規表現の一般的な仕様
正規表現とは
正規表現とは、ある特定のパターンを持った文字列を、ルールとして表現するための方法です。正規表現を利用すると、文字列のパターンに対して効率的に検索や置換を行うことが可能になります。従って例えば、ある文章から先頭が"Foo"で始まる行を抽出したり、ある文字列が電話番号やメールアドレスの形式を満たしているかをチェックしたりする、といったことを容易に実現可能です。
正規表現は、Javaに限らず、多くのプログラミング言語で機能としてサポートされています。まずこのレッスンでは、言語に依存しない正規表現としての一般的な仕様について説明します。
メタ文字
正規表現には、「メタ文字」と呼ばれる特殊な記法が規定されています。メタ文字によってパターンマッチングを行い、文字列を検索したり、マッチした文字列を別の文字列に置換したりする、といった処理が正規表現の基本です。
本コースでは、メタ文字を以下のように分類します。
- 文字クラス
- 定義済み文字クラス
- 単語境界
- 数量子
- 正規表現グループ
- 前方参照
- 特殊文字
メタ文字には数多くの種類がありますが、本コースではこれらの記法の中から特に代表的なものを取り上げ、具体的な使用方法を説明します。
文字クラス
文字クラスとは[と]の間に1つ以上の文字を列挙したもので、いずれかの1文字にマッチします。
文字クラスは、以下のように記述します。
| 正規表現 | マッチ対象 |
|---|---|
| [abc] | a、b、またはc(単純クラス) |
| [^abc] | a、b、c以外の文字(否定) |
| [a-z] | a~z(範囲) |
| [a-zA-Z] | a~zまたはA~Z(範囲) |
例えば正規表現[egy]mailであれば、文字列"email"、"gmail"、"ymail"の3つがマッチします。また正規表現[A-D]ランクであれば、文字列"Aランク"、"Bランク"、"Cランク"、"Dランク"がマッチしますが、"Eランク"はマッチしません。
定義済み文字クラス
文字クラスの中でも特によく使用されるものについては、定義済みの文字クラスが用意されています。以下の表に、代表的な文字クラスを示します。
| 正規表現 | マッチ対象 | 他の正規表現 |
|---|---|---|
| . | 任意の一文字 | |
| ¥d | 数字 | [0-9] |
| ¥D | 数字以外 | [^0-9] |
| ¥s | 空白、タブ、改行などの区切り文字 | [¥t¥n¥r¥f¥x0B] |
| ¥S | 非空白文字 | [^¥s] |
| ¥w | 単語構成文字 | [a-zA-Z_0-9] |
| ¥W | 非単語構成文字 | [^¥w] |
この中でも特に、任意の一文字を表す.は非常によく使われます。例えば正規表現...dayであれば、「任意の一文字が3回登場しその後ろにdayが付く」という意味になります。従って文字列"Sunday"、"Monday"、"Friday"などがマッチしますが、"Saturday"は長さが合わないためマッチしません。
単語境界
正規表現には、単語境界と呼ばれる以下のような記法があります。
| 正規表現 | マッチ対象 |
|---|---|
| ^ | 行の先頭 |
| $ | 行の末尾 |
| ¥b | 単語境界(単語の前後) |
例えば正規表現^Fooであれば、行の先頭が文字列"Foo"で始まる文のみがマッチします。同じように正規表現;$であれば、行の末尾が文字列";"で終わる文のみがマッチします。また正規表現¥bFoo¥bであれば、"Foo"が独立した文字として前後に空白などで区切られている場合にマッチしますが、"FooCompany"など連続した文字の一部の場合はマッチしません。
数量子
数量子とは、指定された文字または文字列の登場回数を指定するための記法です。以下の表に、数量子の記述方法と、どのような文字がマッチ対象になるのかを示します。
| 正規表現 | マッチ対象 |
|---|---|
| X? | Xが0回または1回 |
| X+ | Xが1回以上 |
| X* | Xが0回以上(任意の回数) |
| X{n} | Xがn回 |
| X{n,} | Xがn回以上 |
| X{n,m} | Xがn回以上、m回以下 |
例えば正規表現Foo?であれば、?の直前文字"o"が0回または1回登場することを意味しますので、文字列"Fo"または"Foo"がマッチします。
また正規表現Foo*であれば、*の直前文字"o"が任意の回数登場することを意味しますので、文字列"Fo"、"Foo"をはじめ、"Fooooo"など、"o"が連続して続く文字はすべてマッチします。
また正規表現Go{2,4}dであれば、{2,4}の直前文字"o"が2回以上4回以下登場することを意味しますので、文字列"Good"、"Goood"、"Gooood"がマッチします。
数量子は非常に応用範囲が広い技法です。
英語の文章の中で、一般的に「単語」とは「前後が空白などで区切られた任意の長さの文字列」ですが、「3文字以上5文字以下の単語」を正規表現で表すのであれば、定義済み文字クラス¥bおよび¥wと数量子を組み合わせ、¥b¥w{3,5}¥bで表すことができます。
また市外局番からのハイフン付きの電話番号も、正規表現で表すことができます。この場合は定義済み文字クラス¥dと数量子を組み合わせ、¥d{2,4}-¥d{2,4}-¥d{4}と表されます。
最長一致数量子と最短一致数量子
実は数量子には、最長一致数量子と最短一致数量子という2つの種類があります。
最長一致数量子は、できる限り長い部分にマッチさせようとするもので、逆に最短一致数量子は、できる限り短い部分にマッチさせようとするものです。前項で取り上げた数量子は、最長一致数量子にあたります。
一方で最短一致数量子には、以下のような記法があります。いずれも最長一致数量子の後ろに?を追加したものです。
| 正規表現 | マッチ対象 |
|---|---|
| X?? | Xが0回または1回 |
| X+? | Xが1回以上 |
| X*? | Xが0回以上 |
| X{n}? | Xがn回 |
| X{n,}? | Xがn回以上 |
| X{n,m}? | Xがn回以上、m回以下 |
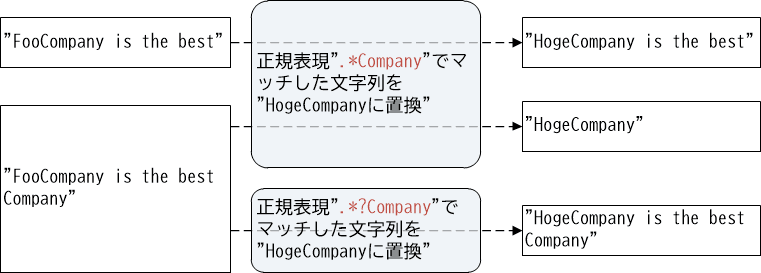
最長一致数量子と最短一致数量子の違いは、主に正規表現による置換の際に現れます。例えば.*Companyという正規表現は、「任意の長さの文字列とその後ろに"Company"が付く」という意味で、ここでは最長一致数量子が使われています。
ある文字列の中から、これらの正規表現にマッチする部分を"HogeCompany"に置換する、という処理を考えてみましょう。
まず最長一致数量子です。"FooCompany is the best"という文字列に正規表現.*Companyを適用すると"FooCompany"がマッチするため、"HogeCompany is the best"に置換されます。
続いて"FooCompany is the best Company"という文字列の場合は、正規表現.*Companyの*は最長一致数量子であり、できる限り長い部分にマッチさせようとするため、"FooCompany is the best Company"全体がマッチします。そのためこの文字列は、"HogeCompany"に置換されます。
今度は最短一致数量子です。同じように文字列"FooCompany is the best Company"に対する置換を、正規表現.*?Companyによって行うとどうなるでしょうか。*?は最短一致数量子であり、できる限り短い部分にマッチさせようとするため、先頭の"FooCompany"のみがマッチします。従ってこの文字列は、最長一致数量子の場合とは異なり、"HogeCompany is the best Company"に置換されます。
【図16-2-1】最長一致数量子と最短一致数量子の違い
正規表現グループ
正規表現グループとは、マッチさせる文字列を( )で囲むことによって、1つのグループにすることです。
| 正規表現 | 対象 |
|---|---|
| (XXX) | XXX |
| (XXX|YYY) | XXXまたはYYY |
例えば正規表現(Foo)*Companyであれば、文字列"Foo"が任意の回数登場し、その後ろに"Company"が付くことを意味しますので、文字列"Company"、"FooCompany"、"FooFooCompany"などがマッチします。
また正規表現(Foo|Bar)?Companyであれば、文字列"Foo"または"Bar"が0回または1回登場し、その後ろに"Company"が付くことを意味しますので、文字列"Company"、"FooCompany"、"BarCompany"がマッチします。
前方参照
正規表現グループによってマッチングを行い、それを別の文字列に置換するとき、マッチした文字列を置換で利用したいケースがあります。そのような場合は、マッチした文字列を前方参照によって取り出すことができます。前方参照は以下のように$nと記述し、nにはマッチした正規表現グループの出現位置を指定します。
| 正規表現 | マッチ対象 |
|---|---|
| $1 | 前方でマッチした1番目の正規表現グループ |
| $2 | 前方でマッチした2番目の正規表現グループ |
| $n | 前方でマッチしたn番目の正規表現グループ |
例えば"{foo}"や"{Bar}"といった文字列が含まれる文章があり、その中から"{ }"に囲まれた文字列(この例では"foo"や"bar")を取り出す、という要件があるものとします。このケースでは正規表現¥{.*¥}でマッチングしますが、どのような文字列がマッチしたのかが分からないと、その文字列を取り出すことができません。
そこで前方参照を利用します。置換後に参照したい部分を( )で囲って正規表現グループにするため、正規表現は¥{(.*)¥}になります。この正規表現でマッチングを行い、置換後の文字列を$1と指定すれば、"{ }"に囲まれた文字列を取り出すことが可能です。
【図16-2-2】前方参照

続いて別のケースを考えます。例えば"Foo"、"FooCompany"、"FooCorporation"、"BarCompany"、"BarCorporation"といった文字列が含まれる文章があり、それを以下のように一括置換したいものとします。
・単独の"Foo"や"Bar" → 置換せず
・"FooCompany" → "HogeCompany"
・"FooCorporation" → "HogeCorporation"
・"BarCompany" → "HogeCompany"
・"BarCorporation" → "HogeCorporation"
このケースでは、正規表現(Foo|Bar)(Company|Corporation)によってマッチングを行い、マッチした文字列をHoge$2に置換すれば要件を満たせます。$2は2番目の正規表現グループを表しますので、"Company"または"Corporation"のいずれかマッチした文字列を参照します。
先読みと後読み
正規表現によるパターンマッチングでは、マッチング対象の文字列の前後に登場する文字列によって、マッチするかどうかを判定したいケースがあります。そのような場合は、先読みグループまたは後読みグループを使用します。以下の表に、先読み・後読みグループの記述方法と、どのような文字が対象になるのかを示します。
| 正規表現 | マッチ対象 |
|---|---|
| X(?=Y) | Xの直後にYがある場合に限り、Xにマッチ(肯定的先読み) |
| X(?!Y) | Xの直後にYがない場合に限り、Xにマッチ(否定的先読み) |
| (?<=Y)X | Xの直前にYがある場合に限り、Xにマッチ(肯定的後読み) |
| (?<!Y)X | Xの直前にYがない場合に限り、Xにマッチ(否定的後読み) |
例えば正規表現(Foo|Bar)(?!Company)であれば、文字列"Foo"または"Bar"の後ろに、"Company"がない場合にマッチします。従って"FooCorporation"や"BarFirm"などはマッチしますが、"FooCompany"や"BarCompany"はマッチしません。
特殊文字
正規表現では、特殊文字は以下のように記述します。
| 正規表現 | 説明 |
|---|---|
| ¥~ | ~で表される文字 |
| ¥t | タブ |
| ¥n | 改行 |
| ¥r | キャリッジリターン(復帰) |
| ¥f | フォームフィード(用紙送り) |
| ¥e | エスケープ |
この中で¥は、後ろに.、$、¥などの予約された文字を記述し、その効果を打ち消すために使用します。例えば正規表現の中で"."を1つの文字として表現したいのであれば、¥.と記述します。
16.2.2 正規表現のAPI
正規表現のAPI全体像
Javaで正規表現による検索や置換を行うために使用するクラスが、java.util.regex.Patternとjava.util.regex.Matcherです。
まずPatternクラスは、文字列としての正規表現を表すクラスで、正規表現文字列を解析することでオブジェクトを生成します。またMatcherクラスは、正規表現による検索や置換を行うための正規表現エンジンを表すクラスで、Patternクラスから生成します。
基本的な処理の流れは、Patternで正規表現を解析し、Matcherで検索や置換を行う、というものです。ただし解析した正規表現を再利用せず、直接Patternクラスでマッチングを行うことも可能です。またレッスン16.1で取り上げたStringクラスには、正規表現によって置換をするためのAPIが用意されていますので、このレッスンで取り上げます。
PatternクラスのAPI
ここではまず、Patternクラスの主要なAPIを説明します。
Patternクラスには、以下のようなAPIがあります。
| API(メソッド) | 説明 |
|---|---|
| static Pattern compile(String) | 指定された正規表現を解析(コンパイル)し、その結果をPatternとして返す。 |
| static Pattern compile(String, int) | 指定されたフラグを使用して、指定された正規表現を解析(コンパイル)し、その結果をPatternとして返す。 |
| Matcher matcher(CharSequence) | このPatternから、指定された文字列領域とのマッチングを行うためのMatcherを生成して返す。 |
| static boolean matches(String, CharSequence ) | 第一引数に指定された正規表現をコンパイルし、第二引数に指定された文字列領域全体とのマッチングを行い、その結果を返す。 |
Patternクラスのオブジェクトは、スタティックなcompile()メソッドに正規表現を指定し、それを解析(コンパイル)することによって生成します。
compile()メソッドには、第二引数にint型のフラグを取るものがありますが、このフラグはPatternクラスに定義された、以下のような定数によって指定します。
| 定数 | 説明 |
|---|---|
| CASE_INSENSITIVE | 大文字と小文字を区別しないマッチングを行う(デフォルトでは区別する)。 |
| MULTILINE | 行頭を表す^や行末を表す$が、文字列内の改行ごとに評価される(デフォルトでは文字列領域全体の行頭・行末しか評価されない)。 |
| COMMENTS | 空白は無視され、"#"で始まる埋込みコメントは行末まで無視される。 |
| DOTALL | 任意の一文字を表す.が行末記号を含む(デフォルトでは含まない)。 |
| LITERAL | 正規表現のメタ文字の意味を無効化し、リテラルとして解釈する。 |
MatcherクラスのAPI
続いて、Matcherクラスです。Matcherクラスのオブジェクトは、Patternクラスのmatcher()メソッドで生成します。生成したMatcherオブジェクトに対して、以下のようなAPIによって検索や置換を行います。
| API(メソッド) | 説明 |
|---|---|
| boolean matches() | 事前に定義された正規表現と文字列領域全体とのマッチングを行い、その結果を返す。 |
| boolean lookingAt() | 事前に定義された正規表現と文字列領域とのマッチングを行い、その結果を返す。マッチングは領域全体ではなく、領域の先頭からマッチする部分を検索する。 |
| boolean find() | 事前に定義された正規表現と文字列領域とのマッチングを行い、その結果を返す。マッチングは領域全体ではなく、領域の先頭からマッチする部分を検索し、マッチするたびに検索開始位置が移動する。 |
| String group() | 直前の(lookingAt()メソッドやfind()メソッドによる)マッチングで、マッチした部分の文字列を返す。 |
| String replaceAll(String) | 事前に定義された正規表現と文字列領域全体とのマッチングを行い、その結果を、指定された置換文字列に置き換える。置換は、マッチしたすべての文字列が対象になる。 |
| String replaceFirst(String) | 事前に定義された正規表現と文字列領域全体とのマッチングを行い、その結果を、指定された置換文字列に置き換える。置換は、マッチした最初の文字列のみが対象になる。 |
Stringクラスの正規表現を指定可能なAPI
Stringクラスには、正規表現を指定することによって検索や置換を行うためのAPIが備わっています。これらのAPIは、PatternクラスやMatcherクラスによる検索や置換を、より簡便に記述するために用意されたものです。
| API(メソッド) | 説明 |
|---|---|
| boolean matches(String) | この文字列領域全体を、指定された正規表現とマッチングし、その結果を返す。 |
| String replaceAll(String, String) | この文字列領域を、第一引数に指定された正規表現とマッチングし、その結果を、第二引数に指定された置換文字列に置き換える。置換は、マッチしたすべての文字列が対象になる。 |
| String replaceFirst(String, String) | この文字列領域を、第一引数に指定された正規表現とマッチングし、その結果を、第二引数に指定された置換文字列に置き換える。置換は、マッチした最初の文字列のみが対象になる。 |
16.2.3 正規表現APIによるパターンマッチングと検索
正規表現APIによるパターンマッチングの基本
このレッスンでは、前のレッスンで取り上げた正規表現APIを使って、パターンマッチングを行うための方法を具体的に説明します。
まずは最も基本的な、PatternクラスとMatcherクラスを使った検索から見ていきましょう。
String str = "FooCompany is the best Company"; //【1】
Pattern pattern = Pattern.compile("^FooCompany.*"); //【2】
Matcher matcher = pattern.matcher(str); //【3】
boolean matches = matcher.matches(); //【4】true
boolean lookingAt = matcher.lookingAt(); //【5】true
String group = matcher.group(); //【6】"FooCompany"
対象となる文字列領域は、ここでは"FooCompany is the best Company"とし、これを変数strに格納します【1】。
次にPatternクラスのcompile()メソッドに、正規表現文字列^FooCompany.*を渡し、正規表現を解析してPatternオブジェクトを生成します【2】。
続いてPatternのmatcher()メソッドに、対象となる文字列領域(変数str)を渡し、Matcherオブジェクトを生成します【3】。
これで文字列領域である"FooCompany is the best Company"に対して、正規表現文字列^FooCompany.*で検索および置換をするための準備が整いました。
それでは、Matcherを使ってマッチングを行ってみましょう。
Matcherクラスには、マッチングの結果をboolean型を返すAPIとして、matches()メソッド、lookingAt()メソッド、find()メソッドがありますが、ここではmatches()メソッドとlookingAt()メソッドの挙動を説明します。
まずmatches()メソッドは、この文字列領域全体と正規表現とのマッチングを行うメソッドです。この例ではマッチするため、trueが返ります【4】。
またlookingAt()メソッドは、この文字列領域の先頭から正規表現とのマッチングを行うメソッドです。この例では同じようにマッチするため、trueが返ります【5】。
またgroup()メソッドを呼び出すと、lookingAt()メソッドによってマッチした文字列を取り出すことができます。この例では、文字列"FooCompany"が返ります【6】。
さてこのコードでは、matches()メソッドとlookingAt()メソッドはともにtrueを返しましたが、次に両者の違いを明らかにするために、正規表現を以下のように"FooCompany"に変更します。
Pattern pattern = Pattern.compile("FooCompany");
この場合lookingAt()メソッドはtrueが返りますが、matches()メソッドは文字列領域全体とのマッチングを行うため、マッチは成り立たずfalseが返ります。
find()メソッドによる部分マッチング
Matcherクラスのfind()メソッドは、lookingAt()メソッドと同じように文字列領域の先頭からマッチングを行いますが、マッチするたびに領域内で検索開始位置が移動する点が特徴です。そしてfind()メソッド→group()メソッドと繰り返し呼び出すことで、文字列領域内において、マッチした文字列を順に取り出すことが可能です。
具体的には、以下のコードを見てください。
String str = "FooCompany is better than BarCompany"; //【1】
Pattern pattern = Pattern.compile("([A-Z].*?)Company"); //【2】
Matcher matcher = pattern.matcher(str); //【3】
boolean find1 = matcher.find(); //【4】true
String group1 = matcher.group(); //【5】"FooCompany"
boolean find2 = matcher.find(); //【6】true
String group2 = matcher.group(); //【7】"BarCompany"
boolean find3 = matcher.find(); //【8】false
対象となる文字列領域は、ここでは"FooCompany is better than BarCompany"とし、これを変数strに格納します【1】。
次にPatternクラスのcompile()メソッドに、正規表現文字列([A-Z].*?)Companyを渡し、正規表現を解析してPatternオブジェクトを生成します【2】。
続いてPatternのmatcher()メソッドに、対象となる文字列領域(変数str)を渡し、Matcherオブジェクトを生成します【3】。このパターンマッチングでは、文字列領域内の"FooCompany"、"BarCompany"という2つの文字列が、それぞれマッチします。従って、まず最初のfind()メソッドでは先頭からマッチングが行われ、"FooCompany"がマッチするためtrueが返ります【4】。
次にgroup()メソッドを呼び出しています【5】が、このメソッドにより、直前のfind()メソッドによってマッチした文字列を取り出すことができます。ここでは"FooCompany"が返ります。
次に2度目のfind()メソッドですが、このとき、前回マッチした部分よりも後ろからマッチングが行われます。つまり" is…"からマッチングが行われることになり、結果的に"BarCompany"がマッチするため、trueが返ります【6】。同じようにその直後のgroup()メソッドは、"BarCompany"が返ります【7】。
次に3度目のfind()メソッドですが、すでに領域の最後に到達しており、マッチする文字列はないため、falseが返ります【8】。
簡潔なマッチングの記述方法
前述したようにマッチングのための基本的なフローは、Patternクラスで正規表現を解析し、Matcherクラスで検索や置換を行う、というものでした。
この流れを改めてコードで表すと、以下のようになります。
Pattern pattern = Pattern.compile("^FooCompany.*");
Matcher matcher = pattern.matcher(str);
boolean matches = matcher.matches();
このコードは、Patternクラスのmatches()メソッド(スタティックメソッド)を使うことにより、以下のように一行で簡潔に記述することができます。
boolean matches = Pattern.matches("^FooCompany.*", str);
またはStringクラスのmatches()メソッドでも、同じ処理を簡潔に記述可能です。
boolean matches = str.matches("^FooCompany.*");
これらの3パターンのコードは、内部的には同じ処理が行われています。ここで注意しなければならないのは、正規表現の解析(Patternクラスのcompile()メソッド呼び出し)は一定のリソースを消費する、という点です。従ってもし同じ正規表現を繰り返し利用する場合は、最初の手順、すなわち、PatternおよびMatcherのオブジェクトを生成する手順を踏んだ方が望ましいでしょう。逆に一度限りのパターンマッチングであれば、二番目もしくは三番目の手順(簡潔な方法)でも、特に問題はありません。
正規表現による形式チェック
正規表現によるパターンマッチングは、文字列の形式チェックに利用することができます。典型的な例は、電話番号の形式チェックです。市外局番からのハイフン付きの電話番号は、正規表現では¥d{2,4}-¥d{2,4}-¥d{4}と表されます。
この正規表現を利用して、与えられた文字列の形式チェックを行うためのチェックメソッドを作成してみましょう。具体的には、以下のようになります。
boolean checkPhoneNumber(String phoneNumber) {
return Pattern.matches("¥¥d{2,4}-¥¥d{2,4}-¥¥d{4}", phoneNumber);
}
このチェックメソッドに、"03-1234-5678"や"080-1234-5678"を渡すと、この正規表現にマッチするためtrueが返ります。逆に"070-123-45678"のように、電話番号として形式不備がある文字列を渡すと、マッチせずにfalseが返ります。
ところでコードでは、正規表現として数字を表す定義済み文字クラス¥dを使用しています。Javaの文字列リテラルでは、¥を表すためにはエスケープシーケンスとして¥¥と記述する必要があるため、¥dは¥¥dになります。定義済み文字クラス以外にも、単語境界、数量子、特殊文字など、正規表現として¥を使うものは、Javaの文字列リテラルではすべて¥¥と記述する必要がありますので注意してください。
さて
16.2.4 正規表現APIによる文字列置換
replaceAll()メソッドによる文字列置換
ここでは、正規表現のパターンマッチングによってマッチした文字列を、何らかの文字列に置換するための方法を説明します。文字列を置換するために使用するAPIが、MatcherクラスのreplaceAll()メソッドまたはreplaceFirst()メソッドです。
具体的にコードで説明します。以下は、文字列"FooCompany"を対象に、英語小文字を"x"に置換するためのコードです。
String before = "FooCompany";
Pattern pattern = Pattern.compile("[a-z]");
Matcher matcher = pattern.matcher(before);
String after = matcher.replaceAll("x"); //【1】
Patternクラスで正規表現を解析し、Matcherオブジェクトを生成するところまでの手順は、これまでの処理と変わりはありません。
文字列の置換は、生成したMatcherに対してreplaceAll()メソッドを呼び出し、置換文字列を渡すことで実現します【1】。replaceAll()メソッドでは、マッチしたすべての文字列が置換されるため、置換後の文字列は"FxxCxxxxxx"になります。
replaceAll()の代わりにreplaceFirst()メソッドを呼び出すと、マッチした最初の文字列のみが置換されるため、このコードでは置換後の文字列は"FxoCompany"になります。
簡潔な文字列置換の記述方法
前項のコードと同じ処理は、StringクラスのreplaceAll()メソッドでも実現可能です。具体的には、以下のコードのようになります。
String before = "FooCompany";
String after = before.replaceAll("[a-z]", "x");
ただし前述したような消費リソースの観点から、もし同じ正規表現を繰り返し利用する場合は、PatternおよびMatcherのオブジェクトを生成する手順を踏んだ方が望ましいでしょう。
様々なパターンマッチングによる文字列置換
ここでは、これまで取り上げてきた正規表現を利用して、様々なパターンマッチングによる文字列置換を紹介します。便宜上、すべての処理でStringクラスのreplaceAll()メソッドを使うものとします。
まず以下のコードは、3文字以上5文字以下の単語をマッチング対象にし、それを"xxx"に置換にするものです。
String before = "FooCompany is the best Company";
String after = before.replaceAll("¥¥b¥¥w{3,5}¥¥b", "xxx");
このコードの結果は、"FooCompany is xxx xxx Company"になります。
次に以下のコードは、パリを表す文字列が"Pari"または"Paris"と表記ゆれがある文章において、すべてを"Paris"に統一するためのものです。
String before = "Alice lives in Paris, Bob lived in Pari";
String after = before.replaceAll("Paris?", "Paris");
この処理は、"Pari"を"Paris"に置換すれば良さそうに思えますが、それだと"Paris"までが"Pariss"へと誤って置換されてしまいます。よってこのコードのように、"Paris"の"s"に数量子?を付与して「PariまたはParis」をマッチさせ、それを"Paris"に置換するのが正しい方法です。
続いて以下のコードは、"〇〇Company"という文字列をすべて"HogeCompany"に置換するものです。
String before = "FooCompany is the best Company";
String after = before.replaceAll("^.*Company", "HogeCompany");
ただしここでは最長一致数量子が使われており、文末の"Company"までがマッチしてしまうため、置換の結果は"HogeCompany"になります。
次に以下のコードも同じように、"〇〇Company"という文字列をすべて"HogeCompany"に置換するものです。
String before = "FooCompany is the best Company";
String after = before.replaceAll("^.*?Company", "HogeCompany");
このコードでは最短一致数量子が使われており、"FooCompany"までがマッチの対象になるため、置換の結果は"HogeCompany is the best Company"になります。
続いて以下のコードは、{ }に囲まれた文字列を取り出すためのものです。
String before = "{foo}";
String after = before.replaceAll("^¥¥{(.*)¥¥}$", "$1");
このコードは、正規表現グループによって{ }に囲まれた文字をマッチさせ、それを置換文字列において前方参照しています。正規表現文字列における{や}は数量子として決められた文字ですが、ここでは文字としての"{"や"}"を表したいため、¥によって打ち消します。ただし前述したようにJavaの文字列リテラルでは、"¥"はエスケープシーケンスとして"¥¥"と記述する必要があるため、結果として"¥¥{"や"¥¥}"といった記述になります。
次に以下のコードは、"FooCompany"や"BarCorporation"といった文字列を、すべて"Hoge〇〇"に置換するためのコードです。このとき"〇〇"には、マッチした"Company"か"Corporation"のいずれかが入りますが、それを置換文字列において$2で前方参照しています。
String before = "FooCompany BarCompany FooCorporation";
String after = before.replaceAll("(Foo|Bar)(Company|Corporation)", "Hoge$2");
このコードの結果は、"HogeCompany HogeCompany HogeCorporation"になります。
最後に以下のコードは、否定的先読みにより「Companyを直後に持たない"Foo"または"Bar"」をマッチさせ、それを"Hoge"に置換するためのコードです。
String before = "FooCompany FooCorporation BarFirm";
String after = before.replaceAll("(Foo|Bar)(?!Company)", "Hoge");
このコードの結果は、"FooCompany HogeCorporation HogeFirm"になります。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 正規表現の概念や一般的な仕様について。
- メタ文字の種類(文字クラス、定義済み文字クラス、単語境界、数量子、正規表現グループ、前方参照、特殊文字など)と特徴について。
- 正規表現APIによるパターンマッチングと、文字列の検索および置換の方法について。
Discussion