RecBoleを使ってみよう3 Atomicファイルについて
概要
前回はAnimeデータセットをRecBole用のデータに変換しました。変換後のデータの先頭部分を少し見てみましょう。
anime.item
| item_id:token | name:token_seq | genre:token_seq | type:token | episodes:float | avg_rating:float | members:float |
|---|---|---|---|---|---|---|
| 32281 | Kimi no Na wa. | Drama, Romance, School, Supernatural | Movie | 1 | 9.37 | 200630 |
| 5114 | Fullmetal Alchemist: Brotherhood | Action, Adventure, Drama, Fantasy, Magic, Military, Shounen | TV | 64 | 9.26 | 793665 |
| 28977 | Gintama° | Action, Comedy, Historical, Parody, Samurai, Sci-Fi, Shounen | TV | 51 | 9.25 | 114262 |
anime.inter
| user_id:token | item_id:token | rating:float |
|---|---|---|
| 1 | 20 | -1 |
| 1 | 24 | -1 |
| 1 | 79 | -1 |
これらのファイルはRecboleで共通して使われるAtomicファイルと呼ばれるフォーマットに則って作られています。今回はこのAtomicファイルについて簡単に解説します。
Atomicファイル
ファイルタイプ
Atomicファイルには .user, .item, .inter, .kg, .link, .net の6タイプがあります。よく使われるのは .user, .item, .inter の3つですので、ひとまずこれらを覚えておけば十分かと思います。
.user ファイル
ユーザーの一覧です。
ユーザーIDカラムが主キーとして必ず入り、オプショナルにそのユーザーの特徴量(年齢, 職業など)が入ります。
Animeデータセットなら、アニメを見ている「俺ら」の一覧です(このデータセットには.userファイルはないみたいですが...)。
.item ファイル
アイテムの一覧です。
アイテムIDカラムが主キーとして必ず入り、オプショナルにそのアイテムの特徴量(名前, ジャンルなど)が入ります。
Animeデータセットなら、アニメ作品の一覧です。
.inter ファイル
interactionの略で、ユーザーがアイテムにどう反応したかの一覧です。
ユーザーIDとアイテムIDが必ず入り、オプショナルに特徴量(時刻や評価値など)が入ります。
Animeデータセットなら、「俺ら」がアニメ作品に対してつけた評価の一覧などが相当します。
これら3ファイルから、次のような2部グラフを描くことができます。点はユーザーIDとアイテムID全体であり、辺は.interファイルのレコード全体です。
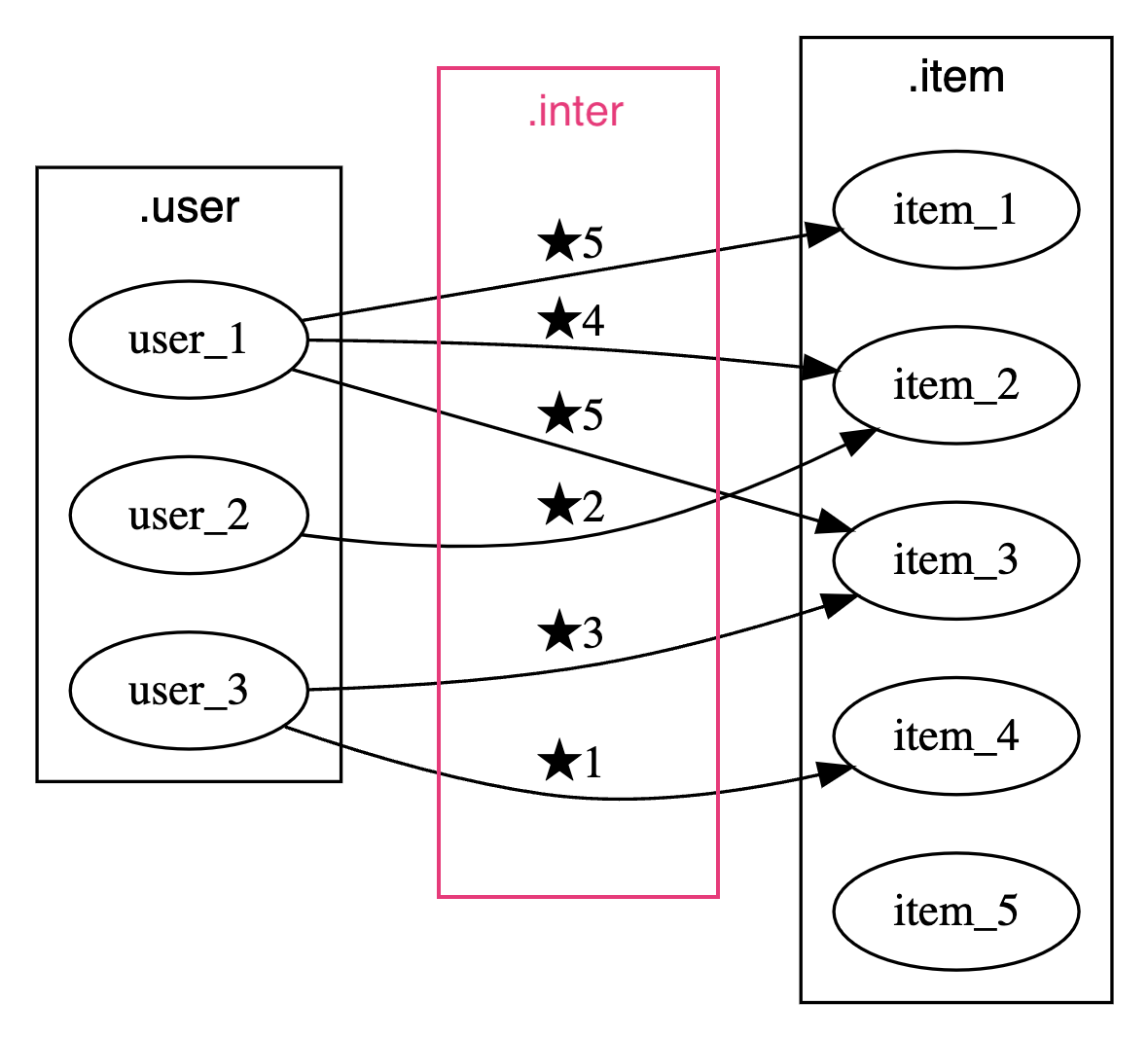
図はgraphvizで描画。
digraph expanded_graph {
rankdir=LR;
ranksep=2;
margin=10;
fontname="Helvetica";
subgraph cluster_A {
label = ".user";
user_1; user_3; user_2;
}
subgraph cluster_B {
label = ".item";
margin=10;
item_1; item_3; item_2; item_4; item_5
}
user_1 -> item_1 [label="★5"];
user_1 -> item_2 [label="★4"];
user_1 -> item_3 [label="★5"];
user_3 -> item_4 [label="★1"];
user_3 -> item_3 [label="★3"];
user_2 -> item_2 [label="★2"];
}
レコメンドに必要なファイルタイプについて
レコメンドのタスクによって、必要なAtomicファイルのタイプが変わってきます。
| タスクの種別 | 必要なAtomicファイル |
|---|---|
| General | .inter |
| Context-aware |
.inter, .user, .item
|
| Knowledge-aware |
.inter, .kg, .link
|
| Sequential | .inter |
| Social |
.inter, .net
|
公式ドキュメントの Model Introduction には83個のレコメンドモデルがタスクの種別ごとに掲載されています(Socialタスクがないのは何故だ...)。
例えばBPRモデルはGeneralタスクなので、.interファイルのみを用意すればいいことがわかります。
特徴量タイプ
また、Atomicファイルのカラムは user_id:token のように、{特徴量}:{特徴量タイプ} の形である必要があります。特徴タイプは次の4種類です。
| 特徴タイプ | 説明 | 例 |
|---|---|---|
| token | 離散値 | ユーザーID, 年齢 |
| token_seq | 離散値のシーケンス | ジャンル, レビュー |
| float | 連続値 | レーティング, 時刻 |
| float_seq | 連続値のシーケンス | 特徴ベクトル |
_seqがつくと、1レコードに複数個(0個以上)の値を入れることが可能です。
例えばAnimeデータセットならば、1作品に複数個のジャンルがあるのが普通です(Hunter x Hunter (2011)のジャンルは Action, Adventure, Shounen, Super Power でした)。ですので、元データの genre カラムはAtomicファイルでは genre:token_seq に変換されます。
区切り文字について
Atomicファイルのカラム間の区切り文字はデフォルトでTabが使われます。
また、シーケンスの区切り文字として、デフォルトでは半角スペースが使われます。
どちらも設定で変えることが可能です。
終わりに
今回はAtomicファイルについて解説しました。
レコメンドに必要なデータセットのフォーマットがわかっていると自前でデータセットを用意するときに迷いがなくなりますし、何より安心して作業を進められるかと思います。
次回はAnimeデータセットを用いて、モデルの学習と複数モデルの精度比較を行っていこうと思います。
ありがとうございました!
Discussion