ドメイン駆動設計の第一歩:インターンでの学び

この記事はヌーラボブログリレー2025夏のTechブログ10日目として投稿しています。
はじめに
こんにちは!現在、株式会社ヌーラボでインターンをしています。kenta-afkです!ここでは、Rustとドメイン駆動設計(DDD)を学びながら開発に取り組んでいます。
インターンを始める前は、DDDという言葉は知っていたものの、具体的に何を指すのか、どう開発に活かすのかは全く知りませんでした。ただなんとなく「ドメインエキスパートの知識を反映させること」、といった認識でした。しかし、実際に業務を通じて手を動かし、社員の方との議論を重ねる中で、DDDの重要な概念が少しずつ腹落ちしてきました。
この記事では、私がヌーラボでのインターンを通して学んだ、ドメイン駆動設計の基本的な考え方と、その実装について、現時点での知識をアウトプットしたいと思います。
ドメイン駆動設計(DDD)とは
ドメイン駆動設計(Domain-Driven Design, DDD)は、複雑なビジネス要件をソフトウェアに正確に反映させるための、包括的なアプローチです。この設計の核心は、ビジネスの専門家が持つ知識(ドメイン知識)を開発プロセス全体に統合し、その知識をソフトウェアの設計モデルに直接反映させることにあります。これにより、開発者はビジネスルールを正確に理解し、それをコードに反映させることが可能となり、要件の誤解や実装ミスが大幅に減少します。結果として、ソフトウェアはビジネスのニーズに沿ったものとなり、プロジェクト全体の成功率が向上します。
現代のソフトウェア開発、特にマイクロサービスやクラウドネイティブといったアーキテクチャが主流となるにつれ、システムの複雑性は増大しています。インフラの柔軟な変更が可能になった一方で、システム全体をいかにして分割し、変更に強く、保守性の高い設計を維持するかが喫緊の課題となっています。DDDは、このような環境下で、混沌としたコード(スパゲッティコード)や、要件の誤解から生まれるシステムの不整合を防ぐための羅針盤となります。DDDの導入は、システムを部分ごとにスケールアウトさせたり、サーバーレスに移行したりといった、柔軟な運用を可能にする手法とも親和性が高いとされています。
💡 注意点:DDDは万能ではありません
DDDは、複雑なビジネスルールやプロセスを持つシステムで真価を発揮します。単純なCRUDアプリケーション(例: Todoリスト)にDDDの全概念を適用すると、モデルの抽象化やパターンの導入が、得られるメリットを上回ってしまう可能性があります。DDDを導入する際は、まず解決すべきドメインの複雑さを慎重に見極めることが重要です。
戦略的設計と戦術的設計
DDDは、大きく分けて戦略的設計と戦術的設計という2つの側面に分かれます。
| 戦略的設計 | 戦術的設計 | |
|---|---|---|
| 目的 | 複雑なシステム全体を俯瞰し、ビジネスの全体像を把握する。 | 戦略で定めた方針を、具体的なコードとして実装する。 |
| 主な概念 | 境界づけられたコンテキスト・ユビキタス言語・コンテキストマップ | エンティティ・値オブジェクト・集約・リポジトリ |
※本記事では、この戦術的設計をメインで紹介していきます。
戦略的設計
戦略的設計は、システムの全体像を捉えるための活動です。
ユビキタス言語(Ubiquitous Language)
プロジェクトに関わる全員が共有する、ビジネスドメインの専門用語です。ビジネスエキスパートと開発者が同じ言葉を使うことで、認識のズレを防ぎます。
境界づけられたコンテキスト(Bounded Context)
複雑なシステムを扱う上で、一つのユビキタス言語ですべての概念を表現しようとすると、言葉の多義性によって混乱が生じます。この問題に対処するために、ドメイン駆動設計では境界づけられたコンテキスト(Bounded Context, BC)という概念を導入します。BCは、特定のドメインモデルとそのユビキタス言語が一貫性を持って適用される明確な「境界」を示すものです。
大規模なシステムは、例えば「受注管理コンテキスト」「在庫管理コンテキスト」「出荷管理コンテキスト」のように、複数のBCに分割されます。
これにより、各コンテキスト内で異なるユビキタス言語やモデルを使用しても、システム全体の混乱を防ぐことができます。
例えば、「配送管理」と「請求管理」では、「顧客」や「住所」といった言葉が異なる意味を持つため(例えば顧客の場合、配送管理だと配送先と言うと思いますが請求管理では請求先と言うかもしれません。)、別々のBCとして分割することで、仕様変更に対する影響範囲を最小化できます。
このBCをサービスごとに分割する考え方は、マイクロサービスアーキテクチャ(MSA)と非常に高い親和性を持ちます。この事実は、単なる技術的な偶然の一致ではなく、組織のコミュニケーション構造がシステムアーキテクチャに影響を与えるという「コンウェイの法則」の具現化として解釈できます。ビジネスドメインに沿ってBCを設計し、それに合わせてチームを編成することで、開発チームの独立性が高まり、コミュニケーションコストが削減されます。これにより、各チームは自身のコンテキスト内で自律的に開発を進めることができ、結果としてシステムの変更耐性とスケーラビリティが向上するという因果関係が成立します。
コンテキストマップ(Context Map)
分割された「境界づけられたコンテキスト」間の関係性を図で可視化するものです。システム全体の連携方法や依存関係を明確にします。
戦略的設計は、これから構築しようとしているシステムが、ビジネスのどこに価値を置くべきか、どのように分割すべきかを定める羅針盤のような役割を果たします。
戦術的設計
戦略的設計で定めた方針に基づき、ドメインモデルを具体的なコードとして実装するのが戦術的設計です。このフェーズで登場するのが、以下のような主要な構成要素(ビルディングブロック)です。
まずは、これらのビルディングブロックを一つずつ見ていきましょう。
DDDの主要な構成要素(ビルディングブロック)
エンティティ(Entities)
エンティティとは、IDのような一意な識別子(アイデンティティ)を持つオブジェクトです。そのアイデンティティが同じであれば、たとえ名前や住所といった属性が変わっても、同一のものとして扱われます。例えば、ユーザーIDが同じであれば、名前や住所が変わっても同じユーザーです。
ドメインモデル貧血症とは?
ドメイン駆動設計(DDD)におけるドメインモデル貧血症(Anemic Domain Model)は、最も一般的なアンチパターンの一つです。これは、ドメインモデルが単なるデータの入れ物となり、ビジネスロジックや振る舞いを含まない状態を指します。このようなモデルでは、データへのアクセスを可能にするためのgetter/setterメソッドが中心となり、ビジネスの知識を表現する役割が欠如しています。
ドメインモデル貧血症が引き起こす問題
このアンチパターンには、以下のような問題点があります。
- ビジネスロジックの分散: ビジネスロジックがドメインモデルから分離され、アプリケーションサービス層やUI層に散在します。これにより、コードの理解や保守が困難になります。
- 密結合と低い凝集度: ロジックが分散するため、変更による影響範囲の予測が難しくなり、システム全体の凝集度が低下し、密結合な状態に陥ります。
- データの不整合: ドメインモデルが自身のビジネスルールを強制できないため、不整合なデータがどこからでも生成されやすくなります。例えば、ToDoリストアプリの文字数チェックや重複チェックがモデル外で行われると、そのルールはモデルを利用する開発者に委ねられ、強制力がなくなります。
DDDにおけるエンティティとORMエンティティの違い
私が勘違いしていたところは、DDDのエンティティとORM(Object-Relational Mapping)のエンティティは異なる概念というところです。
- DDDのエンティティ: 業務上の振る舞いやライフサイクル(生成・変更・削除・ビジネスルールの適用など)をメソッドとして持つ、「行動するオブジェクト」です。
- ORMエンティティ: 主にデータベースとのマッピング用で、永続化(データの保存)やCRUD操作が中心となります。必ずしもドメイン上の振る舞いを定義するわけではありません。
これこそドメインモデル貧血症になってしまう考え方だなぁと思いました。
なぜ振る舞いをモデルに持たせるべきなのか?
ドメインモデル貧血症の根本原因は、ビジネスロジックをデータから分離するという考え方にあります。これは、ビジネス上のルールを、それを扱うオブジェクト自身に責任として持たせるという、オブジェクト指向設計の根本原則に反しています。
振る舞いをモデルに持たせることで、ビジネス上のルールを、それを扱うオブジェクト自身に責任として持たせることになります。これにより、システムの凝集度が高まり、仕様変更に強い、より強固なアプリケーションを構築できます。
例えば、「注文」というエンティティに「商品を追加する」や「支払いを完了する」といった振る舞いを持たせることで、業務ロジックを一元管理できるようになり、変更の影響範囲を最小限に抑えられます。この設計は、業務上の制約や不変条件をモデル自体にカプセル化し、データの不整合を防ぐ効果もあります。
use uuid::Uuid;
#[derive(Debug, Clone)]
pub struct OrderId(Uuid);
impl OrderId {
pub fn new() -> Self {
Self(Uuid::new_v4())
}
}
pub enum OrderError {
AlreadyCanceled,
}
#[derive(PartialEq)]
pub enum OrderStatus {
Pending,
Processing,
Shipped,
Delivered,
Cancelled,
}
// 注文を表すエンティティ
#[derive(Debug, Clone)]
pub struct Order {
id: OrderId,
products: Vec<String>,
status: OrderStatus,
}
impl Order {
pub fn new(id: OrderId, products: Vec<String>, status: OrderStatus) -> Self {
Order {
id,
products,
status,
}
}
//ここでは例の一つとして挙げています。
pub fn mark_as_delivered(self) -> Result<Order, OrderError> {
if self.status == OrderStatus::Cancelled {
return Err(OrderError::AlreadyCanceled);
}
Ok(Order::new(
self.id,
self.products,
OrderStatus::Delivered,
))
}
}
値オブジェクト(Value Objects)
値オブジェクトは、その属性の組み合わせ全体によって区別され、識別子を持たないオブジェクトです。値オブジェクトは不変であり、もしその値が変更される場合は、新しいオブジェクトに置き換えられるべきとされます。例えば、住所、金額、特定の期間を表す日付範囲などが値オブジェクトに該当します。
ドメインサービス(Domain services)
ドメインで扱う概念の中には、特定のオブジェクトに属さず、単一の機能や処理として存在するものが存在します。ドメインサービスは基本的に状態を持たない(stateless)です。DDDのドメインサービスは、ドメインモデルの中にあるサービス的なものを指し、アプリケーション層のサービスとは異なる概念である点に留意が必要です。
// ドメインサービス:配送費の計算
pub struct ShippingCostCalculator;
impl ShippingCostCalculator {
pub fn calculate(info: &ShippingInfo) -> u32 {
let base = (info.weight_kg * 50.0).ceil() as u32;
let extra = info.distance_km / 10 * 100;
base + extra
}
}
// アプリケーションサービス:配送情報の登録
pub struct ShippingApplicationService;
impl ShippingApplicationService {
pub fn register_shipping(info: ShippingInfo) {
let cost = ShippingCostCalculator::calculate(&info);
println!("Shipping registered with cost: {} yen", cost);
// ここで配送情報の保存処理などを行う
}
}
判断フロー:ドメインサービスを使うべきか?
処理が単一エンティティや値オブジェクトに属するか?
→ 属するならエンティティ内にメソッドを持たせる。
複数のエンティティや集約(aggregates)にまたがるか?
→ はい → ドメインサービス。
この例を挙げるとすれば口座間送金です。
Account エンティティは「残高を持ち、自身の振る舞いを提供する」主体です。
しかし「送金」という振る舞いは、複数のアカウント間をまたぐ処理であり、個別のエンティティに属さないため、ドメインサービスに置くのが適切です。
処理がステートレスな計算や判断か?
→ はい → ドメインサービス。
集約(Aggregates)
集約は、ドメインオブジェクト同士で強く一貫性を保ちたい範囲を表す、DDDにおいて特に重要な概念です。集約は、複数のエンティティや値オブジェクトを一つのまとまりとして扱い、その整合性を保証します。例えば、「注文」という集約は、「注文項目(エンティティ)」や「合計金額(値オブジェクト)」を内部に含みます。
集約には、その集約への唯一の入口として機能する集約ルート(Aggregate Root)と呼ばれる親となるエンティティが存在します。集約内部のオブジェクトへの操作はすべて集約ルートを経由して行われ、これにより、集約全体にわたる不変条件が強制されます。不変条件とは、データが変更されても常に維持されなければならない一貫性のルールです。例えば、ECサイトで「カート内の商品点数に応じて割引率が変わる」というルールや、「在庫数が負にならない」といったビジネスルールがこれに該当します。集約は、これらのルールをドメインモデルのレベルで保証するための「境界」として機能し、不整合な状態の発生を防ぎます。
以下が集約の簡単な例です。
use uuid::Uuid;
pub struct OrderItemId(Uuid);
pub struct ProductId(Uuid);
pub struct OrderId(Uuid);
impl OrderItemId {
pub fn new() -> Self {
Self(Uuid::new_v4())
}
}
impl OrderId {
pub fn new() -> Self {
Self(Uuid::new_v4())
}
}
#[derive(Debug)]
pub struct OrderItem {
id: OrderItemId,
product_id: ProductId,
quantity: u32,
unit_price: f64,
}
impl OrderItem {
pub fn subtotal(&self) -> f64 {
self.quantity as f64 * self.unit_price
}
}
#[derive(Debug)]
pub struct Order {
id: OrderId,
items: Vec<OrderItem>,
total_amount: f64,
}
impl Order {
pub fn new() -> Self {
Order {
id: OrderId::new(),
items: Vec::new(),
total_amount: 0.0,
}
}
/// 集約ルート経由でしかアイテムを追加できないようにする
pub fn add_item(&mut self, product_id: ProductId, quantity: u32, unit_price: f64) {
let item = OrderItem {
id: OrderItemId::new(),
product_id,
quantity,
unit_price,
};
self.items.push(item);
self.recalculate_total();
}
fn recalculate_total(&mut self) {
self.total_amount = self.items.iter()
.map(|item| item.subtotal())
.sum();
}
/// 不変条件の確認
pub fn verify_invariants(&self) -> bool {
let sum: f64 = self.items.iter().map(|i| i.subtotal()).sum();
(self.total_amount - sum).abs() < f64::EPSILON
}
}
pub trait OrderRepository {
fn save(&self, order: &Order) -> Result<(), RepositoryError>;
fn find_by_id(&self, id: OrderId) -> Result<Order, RepositoryError>;
fn delete(&self, order: &Order) -> Result<(), RepositoryError>;
}
#[derive(Debug)]
pub enum RepositoryError {
NotFound,
StorageError(&str),
}
OrderItem は個別のエンティティで、「単価 × 数量」で小計(subtotal)を提供します。
Order は集約ルートであり、アイテムの追加は必ず add_item() を通じて行われます。
集約は「データを変更するための単位」として機能し、その内部では強い整合性が保証されます。
recalculate_total()のように常にtotal_amountが注文明細の合計と一致するよう、集約の内部ロジックによって不変条件を保証します。verify_invariants()は、その保証が正しく機能しているかを確認するために使用されます。
これは、集約内のすべてのオブジェクトに対する変更が、常にアトミックに成功または失敗し、一貫した状態を保つことを意味します。
集約設計の原則とベストプラクティス
集約境界を決定する際は、「何がアトミックに一貫している必要があるか」というビジネスルールを深く理解することが重要です。単にオブジェクト間のリレーションシップをモデル化するのではなく、ルールをモデル化することに焦点を当てるべきです。不変条件が集約境界を決定する主要な推進力であるという点は、集約設計が「データ構造駆動」ではなく「振る舞い駆動」(常に真でなければならないルールは何か)であることを意味します。
データ構造駆動のように、オブジェクトが関連している、または一方が他方の存在に依存しているというだけで、それらが自動的に同じ集約の一部になるわけではありません。
重要な問いは、「このオブジェクト群が変更されたときに、アトミックに一貫していなければならないビジネスルールは何か?」という点にあります。
この視点の転換は、CRUDベースやORM駆動の設計に慣れた開発者にとって、DDDの真髄を理解する上で不可欠です。
❌ データ構造駆動の考え方(私がやっていた間違い)
データ構造駆動で考えると、ショッピングカートは以下のような単純な親子関係で表現されがちです。
-
ShoppingCart(ショッピングカート)オブジェクト - カートの中に入っている
Product(商品)オブジェクト - カート内の各商品の
Quantity(数量)
これらの関係を図で表すと、「ShoppingCartが複数のProductを持つ」という構造になります。
このアプローチでは、「関連性があるから同じグループ(集約)にしよう」という考えになり、ビジネスルールよりもデータ構造に焦点が置かれます。
✅ 振る舞い駆動の考え方(DDDの正しいアプローチ)
DDDでは、まずこのショッピングカートが常に守らなければならないルール(不変条件)は何だろうと考えます。
ルール(不変条件)の例:
- 「カート内の商品の合計金額は、常に各商品の価格と数量を掛け合わせたものの合計と一致していなければならない」
- 「カート内の商品に割引が適用される場合、合計金額も正確に再計算されなければならない」
これらのルールを守るために、ShoppingCartオブジェクトが集約のルートエンティティになります。
ShoppingCartの役割は、単にProductを管理するだけでなく、カート内の商品が変更されたときに、これらのルールを常に守るように振る舞うことです。
具体的な振る舞いの例:
- ユーザーがカートに商品を追加する。
-
ShoppingCartは、新しい商品が追加されたことを受け取る。 -
ShoppingCartは、追加された商品の価格と数量を考慮して、自身の合計金額を再計算し、ルールを守る。
このように、ShoppingCartは「注文合計金額は常に商品明細の合計と一致する」というルールを、1つのアトミックな単位として保護しているのです。
この考え方によって、開発者は「データ構造」ではなく「ビジネスルール」に集中できるようになり、データの整合性を保ち、予期せぬエラーを防ぐことができます。
ファクトリ(Factories)
複雑なオブジェクト、特に集約の生成ロジックをカプセル化するためのパターンです。
// order.rs
use uuid::Uuid;
pub struct ProductId(Uuid);
impl ProductId {
pub fn new() -> Self {
Self(Uuid::new_v4())
}
}
// 値オブジェクト:注文明細
#[derive(Debug)]
pub struct OrderItem {
pub product_id: ProductId,
pub quantity: u32,
pub unit_price: f64,
}
impl OrderItem {
pub fn subtotal(&self) -> f64 {
self.quantity as f64 * self.unit_price
}
}
// 集約ルート:注文
#[derive(Debug)]
pub struct Order {
pub id: OrderId,
pub items: Vec<OrderItem>,
pub total_amount: f64,
}
impl Order {
// 外部からは直接Orderを生成させない(ファクトリを使用させる)
// このメソッドはファクトリからのみ呼び出されることを想定
fn new(items: Vec<OrderItem>) -> Self {
let total_amount = items.iter().map(|item| item.subtotal()).sum();
Order {
id: OrderId::new(),
items,
total_amount,
}
}
}
// order_factory.rs
// 注文ファクトリ
pub struct OrderFactory;
#[derive(Debug)]
pub enum OrderCreationError {
NoItems,
// 他の生成ルールに関するエラー
}
impl OrderFactory {
// 注文集約を生成するファクトリメソッド
pub fn create_order(items: Vec<OrderItem>) -> Result<Order, OrderCreationError> {
// ビジネスルール:注文明細は空であってはならない
if items.is_empty() {
return Err(OrderCreationError::NoItems);
}
// ファクトリ内でのみ呼び出される、集約の内部コンストラクタ
let new_order = Order::new(items);
Ok(new_order)
}
}
DDDにおけるファクトリとドメインモデルの役割分担
DDDでは、オブジェクトの「生成」と「振る舞い」のロジックを明確に分離します。これにより、コードの意図が明確になり、ドメインの一貫性が保たれます。
ドメインモデル(エンティティ・値オブジェクト)の役割
-
状態(データ)を保持し、その状態を変更するための振る舞い(メソッド)を定義します。
-
Orderエンティティのmark_as_delivered()メソッドのように、自己の状態を管理するロジックは、そのエンティティ自身に属します。 - 不変条件やビジネスルールは、これらのメソッドの中で守られます。
-
ファクトリの役割
- ドメインモデルを生成することに特化します。
- 生成時に必要なビジネスルール(例: 注文明細が空ではない)を検証し、有効な状態のオブジェクトだけを返す責任を持ちます。
- 生成後のオブジェクトに対する操作は行いません。
ここでdomainでもfactoryでもビジネスルールという言葉が使われており、違いがわからないという方のために以下で説明します。
ビジネスルールの種類と役割分担
ビジネスルールには、以下の2種類があります。
-
生成時のルール(Creation-time rules)
- 役割: オブジェクトが有効な状態で生まれることを保証する。
-
例: 注文明細が空であってはならない、
Customerのメールアドレスが有効な形式である、Accountの初期残高が0以上であるなど。 - 実装: ファクトリでこれらのルールを検証し、有効なオブジェクトのみを生成します。
-
変更時のルール(Mutation-time rules)
- 役割: オブジェクトの状態が変更される際に、一貫性を保つ。
-
例:
Orderにアイテムを追加する際にtotal_amountを再計算するなど。 - 実装: エンティティや集約のメソッドに実装します。
生成時のロジックにビジネスルールがある時、その生成メソッド(newなど)はドメインモデルではなく、ファクトリに書きます。
仕様(Specifications)
オブジェクトの妥当性検証、選別条件、生成条件などを表現するためのパターンです。
以下では、「割引対象の製品」というビジネスルールを仕様として実装します。Rustでは、トレイト(trait)を使うことで、このパターンをきれいに表現できます。
// specification.rs
use crate::product::Product;
// 仕様パターンを定義するトレイト
pub trait Specification<T> {
fn is_satisfied_by(&self, item: &T) -> bool;
}
// 割引対象の製品であるかを確認する仕様
pub struct DiscountableProductSpecification;
impl Specification<Product> for DiscountableProductSpecification {
fn is_satisfied_by(&self, product: &Product) -> bool {
// 価格が5000円より高い、またはセール中であるというルール
product.price > 5000 || product.is_on_sale
}
}
仕様(Specification)のメリット
仕様を使うと、ビジネスルールを独立したオブジェクトとして表現できるため、以下のようなメリットがあります。
-
再利用性
-
DiscountableProductSpecificationは独立したオブジェクトなので、アプリケーションの複数の場所(割引サービス、レポート生成、検索クエリなど)で同じロジックを再利用できます。
-
-
表現力
-
is_satisfied_by(product)のように、ビジネスルールがコードで直接的に表現されるため、可読性が向上します。
-
-
テスト容易性
- ビジネスルールを単一の仕様オブジェクトにカプセル化することで、その仕様を単体テストしやすくなります。
-
拡張性
- 新しいビジネスルールが必要になった場合でも、新しい仕様クラスを追加するだけで済み、既存のコードを変更する必要がありません(オープン・クローズドの原則)。
先ほどfactoryでビジネスルールという言葉の説明をしましたが、あのビジネスルールをこの仕様として定義して再利用するということです。
ポリシー(Policies)
集約のロジックを拡張したり、変更可能なビジネスルールを表現するためのパターンです。
// domain/policies.rs
use crate::models::{Order, ShippingMethod};
// ポリシーのインターフェースを定義するトレイト
pub trait ShippingPolicy {
fn decide_shipping_method(&self, order: &Order) -> ShippingMethod;
}
// 標準配送ポリシー
pub struct StandardShippingPolicy;
impl ShippingPolicy for StandardShippingPolicy {
fn decide_shipping_method(&self, _order: &Order) -> ShippingMethod {
// デフォルトは標準配送
ShippingMethod::Standard
}
}
// VIP顧客向け配送ポリシー
pub struct VipCustomerPolicy;
impl ShippingPolicy for VipCustomerPolicy {
fn decide_shipping_method(&self, order: &Order) -> ShippingMethod {
// primeかどうか判定する。これは別で定義する必要がある。
if order.is_prime_member {
// VIP会員は速達配送
ShippingMethod::Express
} else {
// そうでなければ標準配送
ShippingMethod::Standard
}
}
}
// 高額注文向け配送ポリシー
pub struct HighValueOrderPolicy;
impl ShippingPolicy for HighValueOrderPolicy {
fn decide_shipping_method(&self, order: &Order) -> ShippingMethod {
// orderのamountを参照
if order.total_amount > 10000 {
// 1万円以上の注文は送料無料
ShippingMethod::Free
} else {
// そうでなければ標準配送
ShippingMethod::Standard
}
}
}
先ほど紹介した仕様とポリシーは、ビジネスルールをカプセル化するという点で共通していますが、その適用されるユースケースが異なります。
以下はそのユースケースです。
仕様は、「特定の条件を満たしているか?」を判断するロジックをカプセル化します。その返り値は主に true または false であり、Yes/Noの判定に特化しています。
ポリシーは、「特定の状況でどう振る舞うべきか?」を決定するロジックをカプセル化します。その返り値は具体的な値やオブジェクトであり、何らかの決定や振る舞いに特化しています。
ポリシーは、頻繁に変わる可能性のあるルールを扱うのに適しています。
仕様とポリシーはビジネスルールをカプセル化するということです。
その限りは、factoryのような生成時のビジネスルールに限らず変更時のビジネスルールも含まれます。
DDD集約設計の実践:ログイン・マッチング機能付きすごろくゲーム
集約設計の際は、不変条件(ビジネスルール)にフォーカスすることが大切です。
ドメインの概念と不変条件の洗い出し
各機能が守るべき不変条件を特定し、4つの異なる集約として設計します。
-
認証の不変条件:
- パスワードは安全な形式で保存される必要があります。
- ユーザー名やメールアドレスは一意でなければなりません。
解決策: Auth集約
-
ユーザー管理の不変条件
- コインの数が1000以上でstatusが◯◯◯に変わります。
- status更新は、3種類からなります。
解決策: User集約
-
マッチングの不変条件:
- マッチングセッションは、必要なプレイヤー数が集まるまで維持される必要があります。
- ゲームが開始されると、マッチングセッションは終了しなければなりません。
解決策: Matching集約
-
ゲームプレイの不変条件:
- プレイヤーの現在地は、サイコロの目とボード上のイベントによって常に正しく更新される必要があります。
- ゲームの状態(ターン、勝者など)は、一貫性を保つ必要があります。
解決策: Game集約
なぜ4つの集約に分けるのか?
「なぜ、認証、ユーザー管理、マッチング、ゲームプレイを1つの大きな集約にまとめないのか?」という疑問は、DDDを学ぶ上で最も重要なポイントの一つです。その答えは、それぞれの機能が異なる不変条件とライフサイクルを持つからです。
-
Auth集約を分ける理由:
Auth集約は「ユーザー認証」という不変条件を守る責任を持ちます。例えば、パスワードを変更する際、ゲームが進行中かどうかは関係ありません。ゲームの状態がどうであれ、パスワードは安全に変更できなければならないのです。AuthとGameを分離することで、互いのロジックに影響を与えることなく、独立した変更が可能になります。 -
User集約を分ける理由
User集約は「ユーザーの状態を有効な形で更新」という不変条件を守る責任を持ちます。
これらの不変条件は、ユーザーの認証情報(Auth集約の責務)や、ゲームの進行状況(Game集約の責務)とは直接関係がありません。ユーザーがプロフィールを更新する際に、認証情報を再確認したり、ゲームの状態に依存するロジックを走らせたりすることは、関心事の分離という観点から望ましくありません 。User集約を分離することで、ユーザーのプロフィール管理に関するビジネスルールを一つの凝集度の高い単位にカプセル化し、他の集約のロジックに影響を与えることなく、独立して進化させることが可能になります。 -
Matching集約を分ける理由:
Matching集約は「ゲーム開始前の参加者募集」という不変条件とライフサイクルを持ちます。このライフサイクルは、ゲームが開始された時点で終了します。一方、Game集約のライフサイクルは、ゲームが開始されてから終了するまでです。
もしMatchingをGame集約に含めてしまうと、ゲームが始まっていないのにサイコロを振れてしまったり、ゲーム中に参加者を募集してしまったりと、不整合な状態が発生するリスクが高まります。異なるライフサイクルを持つこれらを分けることで、それぞれの責務を明確にし、健全な状態を保つことができます。
共通項がない不変条件がある時点でそれらは別の集約で分けるべきだということです。
リポジトリパターンとは
リポジトリパターンは、ソフトウェア開発においてデータ層を抽象化し、データアクセスロジックとビジネスロジックを分離しやすくするためのデザインパターンです。
以下のように、Domain層をApplication層とInfrastructure層が参照しているような図になります。
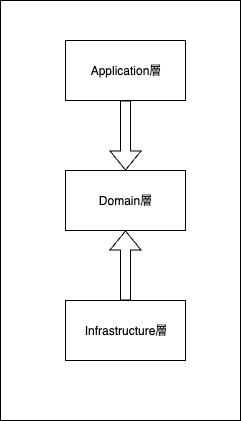
リポジトリパターンをソフトウェアプロジェクトに導入することには、いくつかの重要な利点があります。
- 関心の分離(Separation of Concerns): ビジネスロジック(Domain層)とデータアクセスロジック(Infrastructure層)を明確に分離することで、よりクリーンで保守性の高いコードを実現します。これにより、コードベースが組織化され、スケーラビリティが向上します。
- テスト容易性(Testability): データベースへの実際の接続なしにドメインロジックをテストするために、モック(模擬)リポジトリを使用できるため、ユニットテストが大幅に簡素化されます。これにより、テストの実行速度が向上し、開発サイクルが加速されます。
- データソースの柔軟性(Flexibility in Data Source Changes): 異なるデータストレージ実装間での切り替えを容易にし、ビジネスロジックに影響を与えない柔軟なアーキテクチャを促進します。例えば、プロジェクトの途中でローカルデータベースからリモートAPIへのデータソースの変更が必要になった場合でも、application層はリポジトリとのみやり取りするため、変更の影響を受けにくくなります。
一般的な実装の考慮事項
リポジトリは、この「集約」の整合性を保つために必要なデータを保存/取得/削除する役割を持ち、集約ルートとなるエンティティとペアで用意されます。
このリポジトリは、以下で説明するリポジトリインターフェースを指しています。
典型的なリポジトリパターンの実装には、まずリポジトリインターフェースを定義し、そのインターフェースの具体的な実装クラスを一つ以上作成することが含まれます。
また、依存性注入(Dependency Injection)を使用して、リポジトリをapplication層に注入することが推奨されます。これにより、テスト容易性とデカップリングが向上します。リポジトリメソッドはパフォーマンスのために最適化され、必要に応じてトランザクションを処理できることが重要です。
リポジトリパターンの立ち位置としては、DDDの中にリポジトリパターンがあります。なぜなら、リポジトリパターンは、DDDの核心的な概念である『集約』の永続化を担い、ドメイン層をインフラストラクチャ層から隔離するための不可欠な『ビルディングブロック』です。
その理由は、リポジトリがDDDの以下の原則を具体的に体現しているためです。
- ドメイン層の純粋性: リポジトリは、ドメイン層から永続化という技術的関心事を完全に分離し、ドメイン層が純粋な業務ロジックに集中できる環境を提供します。
- 関心の分離と依存性逆転の原則: リポジトリは、そのインターフェースをドメイン層に、実装をインフラストラクチャ層に置くことで、依存性逆転の原則を実践し、ドメイン層の独立性を保証します。
- 集約の整合性保護: 一般的なデータアクセスパターンとは異なり、DDDのリポジトリは集約を単位として操作することに特化しており、集約の不変条件とデータの一貫性を永続化の過程で保護します。
- 「メモリ上のコレクション」の抽象化: リポジトリは、ドメイン開発者が永続化の詳細を意識せず、あたかもメモリ上のオブジェクトを操作する感覚でドメインロジックを記述できるような、高い抽象化レベルを提供します。
Domain層
DDDで言うとdomain(エンティティ、値オブジェクト)、ドメインサービス、集約(リポジトリインターフェース)、Factory、仕様、ポリシー、などのビジネスロジックを書く場所です。
このdomain層には、リポジトリインターフェースというものを定義します。
// domain/user_repository.rs
use crate::domain::user::{User, UserId, UserError};
// UserRepositoryは、User集約の永続化を抽象化するインターフェース
#[async_trait]
pub trait UserRepository<Conn> + Send + Sync {
// IDに基づいてユーザーを見つける
pub async fn find_by_id(&self, conn: &mut Conn, id: &UserId) -> Result<User, UserError>;
// ユーザーを保存または更新する
pub async fn save(&self, conn: &mut Conn, user: User) -> Result<(), UserError>;
// ユーザーを削除する
pub async fn delete(&self, conn: &mut Conn, user: &User) -> Result<(), UserError>;
}
ドメイン層は、データの保存方法(データベース、ファイル、メモリなど)という技術的な詳細を知る必要はないので、技術的な実装はinfrastructure層に実装して、application層では、依存性の注入でこのインターフェースを通じて呼び出します。
これにより、ドメイン層はインフラストラクチャ層に依存せず(依存性逆転の原則)、アプリケーション層も具体的な実装から分離されるため、テスト容易性や保守性が向上します。
ここで大切なのが、できるだけメソッドの名前をシンプルにする。集約設計の時に言いましたが、責務の分離(不変条件で分離)ができていない場合どうなるかというと、このメソッドの名前がsave_userのようになってしまいます。こうなっていると他の無駄なコンテキストが入り込んでいる可能性があります。本来であれば一つの集約でフォーカスすることは決まっているのでわざわざuserなどという言葉を使わなくても良いですし、そもそもuser以外で更新する時があるのかとなってしまいます。
さらにdomain層に定義するデータ永続化のインターフェースなので、状態更新はドメインモデルを介して行いリポジトリでは、データ保存や検索、などにフォーカスするべきです。なのでupdateなどという更新をするようなメソッド名は使いません。
たとえば、ユーザーのメールアドレスを変更する場合、リポジトリに update_email メソッドを定義するのではなく、以下のようにします。
- まず、リポジトリを使って集約全体を取得します。
- 取得した集約のメソッド(例: change_email)を呼び出して、ドメインルールに沿って状態を変更します。
- 最後に、リポジトリの save メソッドを使って、変更された集約全体を永続化します。
この流れは、リポジトリが「データを永続化する」というシンプルな責務に徹し、集約が「ビジネスロジックを管理する」という役割を果たすことを明確に示しています。
ただし、どうしても許容しなければならない時もあるのでそこは、しっかりとコンテキスト内の意味を考え直す必要があります。
※「また後にトランザクション管理について書くのですが、データベースを使用する場合はトランザクション境界の管理が必要になります。今回はシンプルにするためにInMemoryで行なっているので詳細は割愛しますが、実際のプロダクションではUnit of WorkパターンやTransaction Managerなどを抽象化して依存性注入で管理することになります。」
Infrastructure層
先ほどのdomain層で定義された、リポジトリインターフェースの具体的な実装を記述する場所です。
// infrastructure/in_memory_user_repository.rs
use std::collections::HashMap;
use std::sync::Mutex;
use crate::domain::user::{User, UserId, UserError};
use crate::domain::user_repository::UserRepository;
// In-Memoryでデータを保持するUserRepositoryの実装
pub struct InMemoryUserRepository {
users: Mutex<HashMap<UserId, User>>,
}
impl InMemoryUserRepository {
pub fn new() -> Self {
InMemoryUserRepository {
users: Mutex::new(HashMap::new()),
}
}
}
// UserRepositoryトレイトの実装
impl UserRepository for InMemoryUserRepository {
fn find_by_id(&self, id: &UserId) -> Result<User, UserError> {
let users = self.users.lock().unwrap();
users.get(id)
.cloned()
.ok_or(UserError::NotFound)
}
fn save(&self, user: User) -> Result<(), UserError> {
let mut users = self.users.lock().unwrap();
users.insert(user.id().clone(), user.clone());
Ok(())
}
fn delete(&self, user: &User) -> Result<(), UserError> {
let mut users = self.users.lock().unwrap();
users.remove(user.id());
Ok(())
}
}
Application層
domainで定義してある、集約(リポジトリインターフェース)、domain(エンティティ、値オブジェクト)、factory、仕様、ポリシーを使ってユースケースを定義する場所です。
// application/user_service.rs
use crate::domain::user::{User, UserId, UserError};
use crate::domain::user_repository::UserRepository;
use std::sync::Arc;
// DTO (Data Transfer Object)
// プレゼンテーション層からの入力を表現する
pub struct CreateUserCommand {
pub name: String,
pub email: String,
}
// アプリケーションサービス
// ユースケースの実行を管理する
pub struct UserService<R: UserRepository> {
user_repository: Arc<R>,
}
impl<R: UserRepository> UserService<R> {
// 依存性注入: UserRepositoryトレイトを実装する具体的なオブジェクトを受け取る
pub fn new(user_repository: Arc<R>) -> Self {
UserService { user_repository }
}
// ユーザー登録のユースケース
pub fn create_user(&self, command: CreateUserCommand) -> Result<User, UserError> {
// ドメインモデルの生成。newは別で定義する必要がある。
let mut new_user = User::new(command.name, command.email)?;
// リポジトリを通じて永続化
// アプリケーション層はインターフェースを通じて操作する
self.user_repository.save(&mut new_user)?;
Ok(new_user)
}
}
上記のコードでDTOとありますがそれを以下で説明しています。
コマンド(Command)と DTO(Data Transfer Object)
アプリケーション層では、外部からのリクエストを処理するために、コマンドとDTOという2つの重要なデータ転送オブジェクトを使い分けます。
コマンドは、ユーザーの「意図」を表現するオブジェクトです。例えば、CreateUserCommandは、単にユーザー情報を持つだけでなく、「新しいユーザーを作成する」という明確な命令(意図)をカプセル化しています。アプリケーションサービスは、このコマンドを受け取ってユースケースを実行します。
DTOは、異なるレイヤー間でデータを転送するための単純なデータ構造です。プレゼンテーション層とアプリケーション層間で使われます。DTOは通常、ビジネスロジックを持たず、特定の集約の情報をクライアントが扱いやすい形で提供する役割を担います。
※Commandや後に出てくるドメインイベントもDTOの一種です。
トランザクション管理
ここまでを実践しようとして、よし!やるぞ!となったのはいいのですが、ここでトランザクションについて考えていませんでした。DDDはドメインモデルの整合性を保つためにトランザクションというものについて考えなくてはなりません。
DDDの考え方では、リポジトリを跨いだトランザクションは間違いです。
DDDでは、リポジトリは一つの集約を永続化・取得するためのものです。したがって、リポジトリを跨いでトランザクションを張るということは、複数の集約に対して単一のトランザクションを適用することになります。これは、集約の目的である「自己完結型の一貫性境界」という原則に反します。
複数の集約にまたがる処理は、単一のトランザクションではなく、結果整合性によって処理されるべきです。これは、一方の集約の変更が完了した後に、イベントを発行し、そのイベントを購読した別の集約が自身の変更を行う、という非同期的なアプローチを意味します。
集約が単一のトランザクション単位として設計される理由
集約を単一のトランザクション単位として設計する最大の理由は、ビジネス上の重要な不変条件をアトミックに強制するためです 。不変条件とは、常に真でなければならないビジネスルールを指します 。トランザクションのスコープを集約一つに限定することで、その不変条件はすべてのトランザクションコミットにおいて保証されます 。
この設計選択は、「データの一貫性境界」がドメイン層内で明確かつ明示的に表現されることを確実にします 。これにより、トランザクションのスコープがアプリケーション層のコード内の暗黙的な詳細となることを防ぎ、ドメインの真の一貫性ルールを曖昧にすることを回避します。
「単一の集約インスタンスに対する単一トランザクション」という原則に従うことで、ドメインモデルの異なる部分間の結合度が大幅に低減されます 。これにより、集約の独立性が促進され 、それぞれがより自律的に進化、開発、さらにはデプロイできるようになります。
トランザクションを単一の集約インスタンスに限定することは、高負荷時のデータベースロック、競合、デッドロックのリスクを最小限に抑えます 。これにより、異なる操作の並行処理が向上し、システムのスループットが改善されます。また、集約ごとに異なるデータストレージを選択する柔軟性も生まれ 、特にマイクロサービスアーキテクチャのような分散システムにおいて、ポリグロットパーシステンスの恩恵を受けることができます。
「単一集約に対する単一トランザクション」という原則は、一見厳格に思えるかもしれません。しかし、これは明確で理解しやすいドメインモデルの作成、結合度の低減、保守性の向上、そして独立したドメイン単位間の結果整合性を受け入れることによるスケーラビリティの向上という、DDDの核となる目標を直接支える根本的な設計選択だと思います。
厳密なトランザクション整合性を選択する際のトレードオフ
しかし、推奨されないにもかかわらず、集約間で厳密なトランザクション整合性を検討するケースも存在します。
-
厳密なドメイン要件: まれなケースでは、ビジネスドメインが複数の論理エンティティ間で即時かつアトミックな整合性を真に要求し、一時的な結果不整合さえ許容できない場合です。
-
結果整合性のコスト: 堅牢な結果整合性パターン(例:確実なイベント配送、重複排除、再試行、補償アクションの実装)に関連する実装のオーバーヘッドと複雑性は相当なものになる可能性があります。チームは、分散パターンの実装コストが高すぎると認識された場合、またはチームの専門知識がこの分野で限られている場合、単一のより広範なトランザクションという、一見「単純な」経路を実用的に選択するかもしれないです 。
-
アンチパターンとしての認識: シンプルなシステムで複数の集約にまたがるトランザクションを組むのは一時的には便利に見えるかもしれないですが、それは集約の本来の目的を理解していない証拠であり、長期的に見て設計の柔軟性や拡張性を損なうアンチパターンであるということです。
-
集約がそもそも一つしかない場合:
集約が一つしかないシステムでは、集約間の整合性という問題そのものが存在しません。システム全体が単一の一貫性境界として機能するため、すべてのデータ変更は一つのトランザクション内で厳密に処理されます。
結果整合性の採用
Q.では、具体的にどのようにしてやればいいのか?
A. 集約の変更が完了した後に、イベントを発行し、そのイベントを購読した別の集約が自身の変更を行う、という非同期的なアプローチをします。
ドメインイベント
ドメインイベントとは
ドメインイベントは、ドメイン内で発生した重要な出来事を表すオブジェクトです 。これらは通常、過去形(例:「配送キャンセル済み」、「注文済み」、「ユーザー登録済み」)で命名され、過去の事実を記述する。
その基本的な役割は、ドメイン内の状態変化や更新を伝え、システムを直接的な関数呼び出しではなくイベントを介して通信させることで、異なる部分間の結合度を下げることです 。これは、データストアを共有しないマイクロサービスアーキテクチャのような分散システムにおいて特に重要です 。
ライフサイクル:発行、購読、および反応
プロセスは、集約が内部操作を成功裏に完了し、その状態を永続化した後、一つまたは複数のドメインイベントを作成し発行することから始まります 。これらのイベントは、関心を持つイベント購読者(他の集約、アプリケーションサービス、ドメインサービスなど)が反応する必要がある意味のある変更です。
イベント購読者は、発行されたこれらのイベントを受け取ります。受信すると、彼らは自身のそれぞれの一貫性境界内でさらなるドメインロジックや更新を開始します。
この相互作用は通常、発行者と消費者が疎結合である発行/購読パターンに従います 。
確実な配送の保証:Outboxパターン
集約の状態変更とそれに対応するドメインイベントの発行がアトミックな操作であることを保証するために、「Outboxパターン」が一般的に採用されます。このパターンは、集約の状態が保存された直後にシステムがクラッシュした場合でも、イベントが確実に発行されることを保証します。

イベントはまず、集約の状態変更と「同じデータベーストランザクション」内で、専用の「Outboxテーブル」に永続化されます 。これにより、集約の状態とイベントの両方が保存されるか、またはどちらも保存されないかのいずれかが保証されます。
その後、別の独立したプロセスがOutboxテーブルを監視し(ポーリングまたはChange Data Capture - CDCを使用)、イベントを外部のメッセージバス(例:Kafka、AWSSQS)に発行します 。正常に発行されると、イベントは送信済みとしてマークされるか、Outboxテーブルから削除されます。
ビジネスプロセス整合性のための補償アクション
ドメインイベントは「すでに発生した出来事」を記述するため、単純に「なかったこと」にはできません。結果整合性システムにおいて、多集約ビジネスプロセスの後続ステップが失敗した場合、以前に成功したステップのビジネス効果を元に戻す、または軽減するための「補償アクション」が必要となります 。
例えば、OrderPlacedイベントが支払いプロセスをトリガーし、支払いが失敗した場合、補償アクションとしてOrderCancellationRequestedイベントを発行し、注文をキャンセルして在庫を戻すといった操作が考えられます 。これにより、分散システムにおける障害に直面してもビジネスの整合性が維持されます。
上記で説明したOutboxパターンは「集約間の結果整合性」を堅牢に実装するための強力なツールですが、すべてのDDDプロジェクトに必須なわけではありません。その採用は、プロジェクトの要件と、求められる信頼性のレベルに基づいて判断されるべきものです。
この図は、あるコンテキストで発生したドメインイベントが、別のコンテキストのアプリケーションサービスをトリガーする様子を表しています。
アウトボックスパターンと補償アクション
- アウトボックスパターンが保証すること: データベースへの集約の状態変更とイベントの発行が同じトランザクションで実行されることです。これにより、イベント発行の失敗がゼロになります。もしアウトボックスパターンを採用しない場合、集約の状態が更新された直後にアプリケーションがクラッシュすると、イベントが発行されず、システム間の不整合が発生する可能性があります。
- 補償アクションが解決すること: イベント発行後のコンシューマー側での処理失敗です。補償アクションは、イベントが確実に発行された後の、ロジック上のエラーやビジネス上の不整合を元に戻す役割を担います。
小規模なシステムで、イベントの損失が許容できる、または手動でリカバリできる場合は、アウトボックスパターンを省略できます。しかし、金融取引や在庫管理など、1件のイベント損失がビジネスに深刻な影響を与える場合は、アウトボックスパターンはほぼ必須のパターンとなります。
結論として、システムの規模やビジネス要件に応じて、どちらのアプローチが適切かを判断すべきです。 アウトボックスパターンは、イベントの「確実な発行」を保証し、補償アクションは「発行後の整合性」を保証するという、それぞれ異なる役割を持っています。
障害処理
-
冪等性: 分散システムでは、メッセージ配信はしばしば「少なくとも一度」であるため 、イベントが複数回配信される可能性があります。したがって、イベントハンドラーは「冪等」に設計され、同じイベントを複数回処理しても意図しない副作用なしに同じ結果が得られるようにする必要があります 。これは通常、各イベントに一意の識別子を付与し、処理済みのイベントIDを記録して重複を検出し無視することで達成されます 。
outboxテーブルのカラムとしてはid, event_type, payload, created_atなどがあり追加で特定の集約のイベントの追跡を可能にしたりするaggregate_id, イベントを送信したのか判定するstatusなどがあります。 -
再試行: イベントコンシューマーが遭遇する一時的なエラー(例:ネットワークの問題、一時的なサービス利用不可)に対しては、自動再試行メカニズムが不可欠である。再試行には指数バックオフ戦略を使用し、システムを過負荷にしないように調整することが推奨されます 。
-
デッドレターキュー(DLQ): イベントが複数回の再試行後も継続的に処理に失敗する場合、それはデッドレターキュー(DLQ)に移動されるべきです 。これにより、問題のあるメッセージが他のイベントの処理をブロックするのを防ぎ、手動での検査、デバッグ、または後での再処理を可能にします。
Sagaパターン
Sagaパターンは、複数のサービスにまたがるビジネスワークフローを、一連の「ローカルトランザクション」のシーケンスとして実行する分散トランザクション管理の設計原則です。各ローカルトランザクションは、自身のサービス内で完結し、アトミックにデータベースを更新した後、イベントやメッセージを通じて次のステップをトリガーします。この連鎖的な実行によって、全体のビジネスプロセスが進行します。
Sagaの核心は、その成功と失敗の管理方法にあります。すべてのローカルトランザクションが成功すれば、Sagaは正常に完了し、システムは一貫した状態に到達します。しかし、いずれかのステップが失敗した場合、Sagaは「補償トランザクション(Compensating Transactions)」を実行します。これは、失敗したステップの前に完了した全てのステップを「元に戻す」ための逆向きの操作です。この「巻き戻し」は、伝統的なデータベースの自動ロールバックとは異なり、ビジネスロジックに基づいた明示的な操作として設計されます。例えば、支払いが失敗した場合、補償トランザクションは単にデータベースの値を元に戻すのではなく、在庫を解放し、注文ステータスをキャンセル済みに変更し、場合によっては払い戻し処理を実行します。
Sagaを理解する上で重要な3つの概念があります。
-
補償可能トランザクション(Compensable transactions): 失敗時に元に戻す操作(補償)が可能なステップです。これは、Sagaの実行中に不測の事態が発生した場合に、一貫性を回復するために使用されます。
-
ピボットトランザクション(Pivot transactions): Sagaにおける「引き返し地点」であり、このトランザクションが成功すると、それ以降の操作は補償不能となります。ピボットトランザクションは、Sagaが不可逆な状態に移行する境界を定義します。
Sagaパターンは処理が失敗すると全部巻き戻ししますが、Sagaの処理が元に戻せなくなる決定的なポイントを決めます。
ユースケースとしては、クレジットカードの課金や、なんらかのチケットの購入などが挙げられます。主に外部サービスの呼び出しなどがあります。 -
リトライ可能トランザクション(Retryable transactions): ピボットトランザクションの後に仮に処理が失敗した場合、一時的な障害が発生しても最終的に成功するまでリトライされるべきステップです。このステップは、べき等性(Idempotency)を持つように設計される必要があります。べき等性とは、同じ操作を複数回実行しても、システムの状態が同じ結果になることを保証する性質であり、メッセージの再送や処理の再開に不可欠です。
たとえば、次のような操作を考えます。「金額を100円加算する」という操作はべき等ではありません。複数回実行すると、そのたびに100円が加算され、結果が異なります。「金額を500円にする」という操作はべき等です。何度実行しても、結果は常に500円になります。
2つの実装手法
Sagaパターンの実装には、大きく分けて二つの主要なアプローチがあります。それぞれが異なるワークフロー調整の仕組みを持ち、独自のメリットとデメリットを提供します。
オーケストレーション型Saga
このアプローチでは、中央の「オーケストレーター」がワークフロー全体を管理・調整します。オーケストレーターは、一連のステップの実行順序を把握しており、各参加サービスにコマンドを送信して操作を指示し、その応答に基づいて次のステップを決定します。失敗が発生した場合、オーケストレーターは補償トランザクションのシーケンスを起動し、回復を主導します。
-
メリット:
- 複雑なワークフローに適しています。
- ワークフローの全体像が単一の場所に集約されるため、可視性が高く、理解や管理が容易です 。
- サービスのビジネスロジックが単純化され、責務の分離が明確になります。
- 循環的な依存関係を回避できます。
-
デメリット:
- オーケストレーターが単一障害点となる可能性があります。
- コーディネーションロジックを実装するための追加のサービス(オーケストレーター)が必要になります。
コレオグラフィー型Saga
このアプローチでは、中央のコーディネーターは存在せず、各サービスが自律的に連携します。各ローカルトランザクションは、完了した後にドメインイベントを公開し、他の関連サービスがそのイベントを購読して次のステップをトリガーします。
このコレオグラフィー型は、outboxパターンと組み合わせて使われることが一般的です。
-
メリット:
- シンプルなワークフローに適しており、実装が比較的簡単です。
- 中央のコーディネーターがないため、単一障害点が存在せず、システムの耐障害性が向上します。
- サービス間の結合度が低く、それぞれのサービスが独立して進化できます。
-
デメリット:
- ワークフローが複雑になると、イベントの連鎖を追跡するのが困難になり、デバッグが非常に難しくなります。
- 循環的な依存関係が発生するリスクがあります。
- 統合テストを行うには、関連する全てのサービスを稼働させる必要があるため、テストが複雑になります。
両アプローチの選択は、ビジネスワークフローの複雑性、結合度の要件、およびシステムの可用性目標に依存します。
実例
Sagaパターンが最も効果を発揮するのは、複数の独立したサービスにまたがる、長期間にわたるビジネスプロセスを管理する場面です。
Eコマースの注文処理Saga
この典型的な例では、一つの注文が複数のサービスを跨いで進行します。
- 注文サービス: 顧客からの注文リクエストを受け取り、注文を作成します。
- 支払いサービス: 支払いプロセスを開始し、完了または失敗を通知します。
- 在庫サービス: 注文商品の在庫を確保します。
-
配送サービス: 商品の配送を手配します。
このワークフローにおいて、もし「支払いサービス」のステップで失敗が発生した場合、Sagaは補償トランザクションを起動します。これにより、「在庫サービス」は確保していた在庫を解放し、「注文サービス」は注文ステータスをキャンセル済みに更新します。
Sagaがもたらすトレードオフと高度な設計
Sagaパターンは、分散システムにおけるデータ一貫性の強力な解決策である一方で、ACID特性、特にAtomicityとIsolationを緩めるという重要なトレードオフを伴います。
Sagaは、ローカルトランザクションのコミットを不可逆的な変更として扱うため、グローバルなレベルでの厳密なAtomicityを保証することはできません。代わりに、Sagaは最終的にすべての操作を成功させるか、または補償トランザクションによってすべての先行する作業を元に戻すことで、全体的なAtomicityを達成します。また、ローカルトランザクションが個別にコミットされるため、他のサービスが不完全なSagaによって変更された「ダーティ・リード」や「ロスト・アップデート」といったデータアノマリーに直面する可能性があります。
このIsolationの欠如は、Sagaパターンの本質的な側面であり、開発者が意識的に対応しなければならない最も重要な課題の一つです。伝統的なデータベースはロック機構によってトランザクションの独立性を保証しますが、Sagaではグローバルなロックが存在しないため、アプリケーションレベルでの対策が必要です 。
分離性を確保するための高度な設計
そのアプリケーションレベルでの対抗策として、いくつかの設計技術が用いられます。
- セマンティック・ロック(Semantic locking): アプリケーションレベルで特定のデータをロックする概念です。例えば、注文プロセスが進行中の間、その注文のステータスをREVISION_PENDINGのような一時的な状態に変更することで、他のSagaが同じデータを変更しようとするのを防ぎます。
- 楽観的ロック: データのバージョン番号を使用し、更新時にバージョンが一致しない場合に競合が発生したと判断する手法です。
また、Sagaの実行順序を再設計し、データの更新をリトライ可能トランザクションで行うようにすることで、ダーティリードを回避できる場合があります。リトライ可能トランザクションの実装の一つとしてはoutboxテーブル(イベントログ用)のようなtransactionsテーブル(トランザクションログ用)を作る感じです。
最後に:戦術的設計を活かすための戦略
今回はドメイン駆動設計(DDD)の戦術的設計に焦点を当て、その具体的なビルディングブロックとトランザクションについて書きました。戦術的設計メインで書いたので大事なことを忘れがちなのですが、戦略的設計をしっかり行った上で戦術的設計を行うことにこそ、DDDの真価があるということです。
戦略的設計をおろそかにすると、ユビキタス言語や境界づけられたコンテキストが曖昧なままで、どれだけコードが美しくても、それが本当にビジネスの課題を解決しているのか確信が持てません。結果として、ビジネスのニーズからずれたソフトウェアができてしまうリスクがあります。
また、どのサブドメインが最もビジネス価値が高いのか(コアドメイン)を特定せずに開発すると、重要でない部分に多くの時間とリソースを費やしてしまう可能性があります。
とある勉強会で言われたのですが、結局はどこがコア(一番大事な部分、一番利益を生むところetc.)なのか見つけてそこに集中することが大切ですと言われました。(本にも書いてあった)。
戦略的設計への初期投資は、単に「良い設計」を生み出すだけでなく、プロジェクトのライフサイクル全体にわたるコスト削減、開発効率の向上、そして最終的なソフトウェアの品質と寿命の向上に貢献します。
Discussion