誰でも簡単!Difyではじめる RAGチャットボット開発実践 with Bedrock
前提知識
AI 活用
Amazon.com での AI 活用
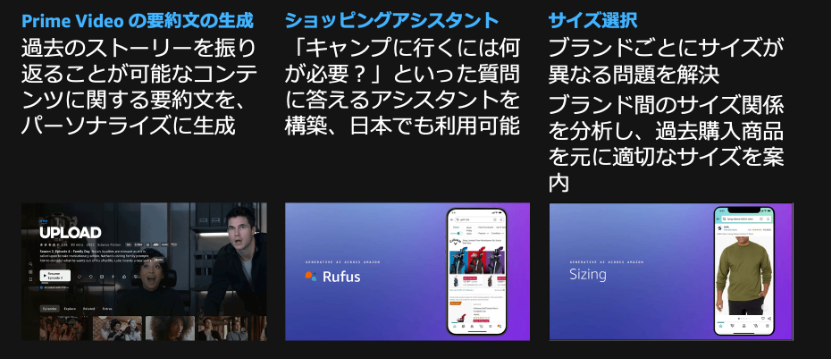
オフィスワークにおける生成 AI ユースケース

このような 生成 AI ユースケースをイチから自分で作り上げるにはさまざまな知識と経験を求められます。こういったユースケースを誰でも簡単に作れるような UI/UX を提供してくれるのがご紹介するDify です。
Dify とは
Difyは、AIアプリケーション開発を効率化するためのオープンソースプラットフォームです。直感的なインターフェースを通じて、複雑なAIワークフローの構築から実運用までをサポートする総合的なソリューションを提供しています。
このプラットフォームの特徴として、ビジュアルキャンバスを使用したAIワークフローの構築が可能で、GPT、Mistral、Llama3などの多様なLLMモデルとの連携をサポートしています。また、直感的なプロンプトIDEを備えており、プロンプトの作成やモデルのパフォーマンス比較が容易に行えます。
文書処理の面では、PDFやPPTなどの一般的な文書形式からのテキスト抽出に対応したRAGパイプラインを実装しており、文書の取り込みから検索までをシームレスに処理できます。さらに、LLM Function CallingやReActを活用したエージェント機能を提供し、Google検索やDALL·E、Stable Diffusionなど50以上の組み込みツールを利用することができます。
運用面では、アプリケーションのログやパフォーマンスを監視・分析するLLMOps機能を備えており、本番環境でのデータに基づいて継続的な改善が可能です。また、すべての機能がAPIとして提供されているため、独自のビジネスロジックへの統合も容易に行えます。
このように、Difyはプロトタイプの作成から本番環境への展開まで、AIアプリケーション開発の全工程をカバーする包括的なプラットフォームとして機能します。
Dify のメニュー

RAG チャットや、ツールを利用したエージェントも簡易に構築可能

直感的なインターフェースを用いて、 チャットボット (含 RAG) やエージェント、 ワークフローを構築可能

Dify で開発可能な生成 AI アプリ

- ボットとの対話型アプリを構築可能。ナレッジ内からの RAG チャットや、FAQ 回答 ("注釈返信") の設定も可能で、画像入力も可能
- ワークフローを連携させたチャット (チャットフロー) も作成可能

- ユーザーの 1 入力に対して 1 出力で完結させるアプリを構築可能
- メール返信生成や SQL の生成、翻訳など、多数のパラメータを元に 1 回の出力を得たいようなケースで活用できる
- 多数の実行ケースを CSV で一括入力することも可能

- 与えたツールを用いて、ユーザーからのリクエストをタスクとして遂行するエージェントを作成可能
- Dify 組み込みツール (例 : Web 検索、Web ページクローリング、etc) や、API 経由で実行可能なカスタムツールが使える

- ユーザーの入力やツールを高度に組み合わせたワークフローを GUI 上で構築し、チャットボットやテキストジェネレータを構築可能
- 「入力内容で条件分岐させて別のナレッジベースで RAG を実行する」
- などの高度なアプリケーションを実装できる
Dify のナレッジベース

- Dify のコンソール上から PDF 等を投入し、 指定した Embedding モデルでベクトル化して DB に投入する
- Dify のアプリ開発者が 個々でナレッジベースを作成し、 個別のアプリから利用することが可能
Dify での生成 AI アプリ開発 : 利用可能な組み込みツール群
Web 検索や Web スクレイピング、 Code Interpreter などのツールが組込済

Dify によるチャットボット作成の 画面構成

Amazon Bedrock とは
AWS の生成 AI スタック

APIで利用可能なサーバーレス基盤
複数の基盤モデルから 用途に最適なものを選択し、 APIで利用可能なサーバーレス基盤

生成AIアプリ開発者向けに、基盤モデルの実行とモデルカスタマイズ環境を フルマネージド & サーバーレスで提供

複数のモデルを API で使えるとはどういうことか?

様々なAI企業の基盤モデルを 共通の Bedrock API で利用可能

Amazon Nova とは
Amazon Nova は、AWS が提供するクラウドベースのコード生成AIサービスです。開発者がコードを書く際に、自然言語による要求から適切なコードを生成したり、コードの補完や改善の提案を行ったりすることができます。これにより、開発者の生産性を向上させ、より効率的なソフトウェア開発を支援します。

精度向上パターンと難易度

難易度として一番優しいプロンプトエンジニアリングから、独自のLLMモデル開発までさまざまな難易度のアプローチがあります。今回は比較的難易度が低くコストも抑えられることが多いRAGによる精度向上を目指します。
RAG (Retrieval Augmented Generation: 検索拡張生成) とは
RAG (Retrieval Augmented Generation: 検索拡張生成) は、大規模言語モデル(LLM)を使用する際に、外部の知識ベースから関連情報を検索・取得し、それを組み合わせて回答を生成する手法です。
主な特徴は以下の通りです:
- 外部データソースから関連情報を検索
- 検索した情報とLLMの能力を組み合わせて回答を生成
- より正確で最新の情報に基づいた回答が可能
- ハルシネーション(誤った情報の生成)のリスクを低減
一般的なRAGの処理フロー:
- ユーザーからの質問を受け取る
- 質問に関連する情報を知識ベースから検索
- 検索結果とユーザーの質問を組み合わせてLLMに入力
- LLMが検索結果を参照しながら回答を生成
この技術により、より信頼性の高い回答を提供することが可能になります。
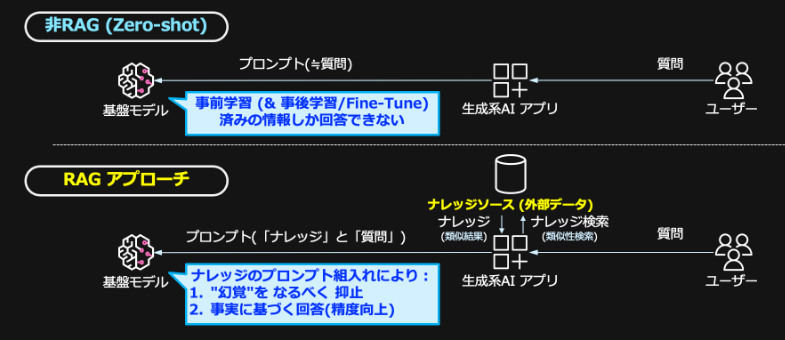
RAG を構成する基本要素 (Vector DB を利用する場合)

Vector DBのインデックス作成時のチャンクサイズを調整する。 チャンクサイズが大きいとマッチした内容に付随する周辺情報をコンテキストに 含められるようになる。一方、ベクトル検索自体の精度は下がる傾向にある。

代表的な Advanced RAG の手法
Advanced RAGというのは非常にホットなトピックで、たくさんの手法が提案されています。
その中でも濃淡があって、追加の実装することでレイテンシーやコスト的に影響が小さいものもあれば大きいものもあります。
開発コストや難易度もまちまちなのですが、基本的にはここにある左から右の順番で試していくのがいいのかなと思ってマッピングしてみました。
一番左がまずはここから試すのがいいチャンクサイズの調整、ドキュメントパースの改善、メタデータによるフィルタ、ハイブリッド検索という4つをあげています。
この4つを試した後にもっと高みを目指すとなったら、より高度なretrievalを行うための、リランキング、クエリ書き換え、small-to-big retrievalといった手法を試してみると良いと思います。
他にもエージェントとしてRAGを実装するとか、モデルのファインチューニングを行うというのもあります

この記事では Advance RAG の中でもリランキングを題材として取り扱うことにします。
つまりこの記事は生成AIの精度向上としてRAGを選択し、RAGの精度向上の手法としてリランキングを利用します。
Amazon Titan Text Embeddings とは
Amazon Titan Text Embeddings は、AWS が提供するテキスト埋め込みモデルサービスです。


このサービスは、テキストデータを高次元のベクトル(数値の配列)に変換することができ、以下のような特徴があります:
- テキストの意味を数値化して表現できる
- 類似文書の検索や文書の分類などのタスクに活用できる
- 多言語対応
- Bedrockを通じて簡単に利用可能
主な用途としては:
- 文書の類似度計算
- 検索システムの構築
- 文書の分類
- レコメンデーションシステムの開発
などが挙げられます。
AWSのマネージドサービスとして提供されているため、簡単に導入でき、スケーラブルに利用することができます。
Amazon Bedrock の Reranker Model とは
RAGでは データソースから取得したデータを適切に「並べ替え」することで 最終的なRAG応答の精度を向上が一般に可能であり、それを実現する専用のModelを Reranker Modelと呼びます

Workshop概要とアーキテクチャ説明
今回は様々なクラウドサービス、サーバーレスサービスを組み合わせてアーキテクチャを構成します

このハンズオンのアーキテクチャの要点は以下の通りです:
ユーザーインターフェース
- LINEアプリを使用してユーザーが質問を投げかける
処理フロー
- LINEからのメッセージがDifyの公開APIで受け取られる
- (PostmanでDifyのAPIを呼び出し動作確認)
- DifyがTiDB Vector Storeに保存された知識ベースを検索
- BedrockのNova(LLMモデル)が回答を生成
- 生成された回答がLINE APIを通じてユーザーに返信される
主要コンポーネント
- LINE Messaging API:ユーザーとのインターフェース
- Postman:APIのテスト、動作確認
- Dify:RAG(Retrieval Augmented Generation)の実装
- TiDB Cloud Serverless:ベクトルストアとして使用
- Amazon Bedrock (Nova):生成AI機能の提供
このアーキテクチャにより、ドキュメントベースの質問応答チャットボットを実現しています。
Amazon Bedrock ハンズオン
Bedrock でのモデルアクセスの有効化
ご自身のAWSアカウントで Management Consoleを開いてください
今回はオレゴンリージョンを利用します
Management Console で Bedrock サービスに移動し、モデルアクセスを選択

今回は以下、2種類のモデルアクセスを可能にします
- Titan Text Embeddings V2
- Rerank 1.0
- Nova Lite
「特定のモデルを有効にする」を選択

一度でも有効にしたことがある場合は「モデルアクセスを変更」を選択

以下の3つのモデルを選択し下部へスクロールして 「次へ」、よければそのまま「送信」
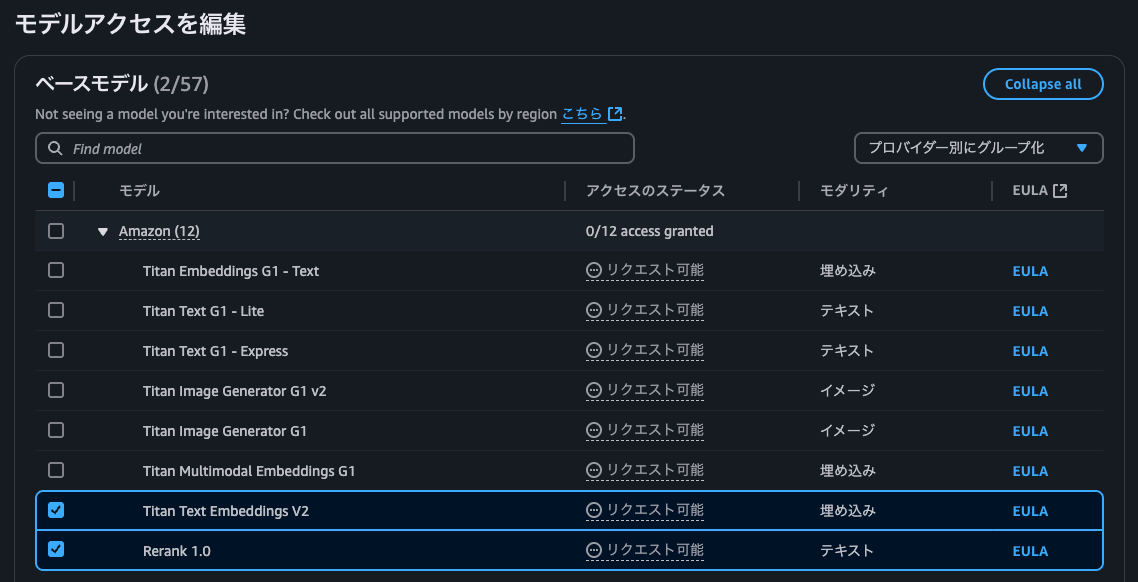

通常は直ちにアクセスが付与されます

モデルアクセスの動作確認
ここでは動作確認用の環境として AWS CloudShell を利用します
AWS CloudShell は、AWS マネジメントコンソールから直接利用できるブラウザベースのシェル環境です。
事前設定済みの環境として、AWS CLI が既にインストールされており、Python や git などの一般的な開発ツールが利用可能で、AWS 認証情報も自動的に設定されています。
AWS CloudShell は追加料金なしで AWS ユーザーが利用可能で、1GB のストレージが永続的に提供されます。主なユースケースとしては、AWS リソースの管理や設定、スクリプトやコマンドのテスト、AWS CLIコマンドの実行などが挙げられます。
利便性の面では、ブラウザから直接アクセスが可能で、ローカル環境の設定が不要であり、リージョンごとに独立した環境を提供します。

もしくは検索窓に打ち込んで CloudShell 起動

「Titan Text Embeddings V2」の動作確認
CloudShell上で以下の invoke-model コマンドを実行してください
aws bedrock-runtime invoke-model \
--model-id amazon.titan-embed-text-v2:0 \
--body '{"inputText": "こんにちは世界"}' \
--cli-binary-format raw-in-base64-out \
--output json /dev/stdout | jq
こんな形でレスポンスが表示されれば正常です
-0.027907921001315117,
-0.014145281165838242,
0.024599405005574226
]
},
"inputTextTokenCount": 5
}
{
"contentType": "application/json"
}
与えられた文字列が 埋め込み用の 多次元 Vector 表現になって返ってきています
「Rerank 1.0」の動作確認
以下の三つの文章を Indexに設定して、生成AIに関する Queryを投げてみたいと思います
Index
- AWS Lambda は、サーバーの管理なしでコードを実行できるサーバーレスコンピューティングサービスで、実際に使用した実行時間に対してのみ料金が発生するペイアズユーゴー型のサービスです。
- AWS Step Functions は、複数の AWS サービスやタスクを視覚的なワークフローとして組み合わせて、アプリケーションの分散処理を自動化・調整できるサーバーレスオーケストレーションサービスです。
- Amazon Bedrock は、AWS が提供する完全マネージド型のサービスで、Claude や Stable Diffusion などの高性能な基盤モデル(Foundation Models)を API 経由で簡単に利用できるプラットフォームです。
Query
- AWSが提供する生成AIのサービスで、複数の基盤モデルを単一のAPIで利用できるものは?
aws bedrock-runtime invoke-model \
--model-id amazon.rerank-v1:0 \
--body '{
"documents": [
{"text": "AWS Lambda は、サーバーの管理なしでコードを実行できるサーバーレスコンピューティングサービスで、実際に使用した実行時間に対してのみ料金が発生するペイアズユーゴー型のサービスです。"},
{"text": "AWS Step Functions は、複数の AWS サービスやタスクを視覚的なワークフローとして組み合わせて、アプリケーションの分散処理を自動化・調整できるサーバーレスオーケストレーションサービスです。"},
{"text": "Amazon Bedrock は、AWS が提供する完全マネージド型のサービスで、Claude や Stable Diffusion などの高性能な基盤モデル(Foundation Models)を API 経由で簡単に利用できるプラットフォームです。"}
],
"query": "AWSが提供する生成AIのサービスで、複数の基盤モデルを単一のAPIで利用できるものは?"
}' \
--cli-binary-format raw-in-base64-out \
--output json /dev/stdout | jq
こんな形でレスポンスが表示されれば正常です
{
"results": [
{
"index": 2,
"relevance_score": 0.5299628354452747
},
{
"index": 0,
"relevance_score": 0.00011147903794271353
},
{
"index": 1,
"relevance_score": 0.000019833367060283615
}
]
}
{
"contentType": "application/json"
}
Index2 が Query に対して一番意味的な関係性が高いと評価されています。また Ranking として関連性の高さで並んでいることがわかります。
「Nova Lite」の動作確認
Converse APIを使用すると、異なるBedrock基盤モデル間で統一的なインターフェースでアクセスでき、シームレスなモデルの切り替えが可能になります。
CloudShell上で以下の converse コマンドを実行してください
aws bedrock-runtime converse \
--model-id us.amazon.nova-lite-v1:0 \
--messages '[
{
"role": "user",
"content": [
{
"text": "クラウドサービスについての詩を書いて"
}
]
}
]' | jq
こんな形でレスポンスが表示されれば正常です
{
"output": {
"message": {
"role": "assistant",
"content": [
{
"text": "雲の彼方に、広がる世界\nクラウドサービス、その名は\nデータの海に浮かぶ島々\n遠く離れた場所でも、つながる心\n\n遥かな空の彼方、サーバーが眠る\nその中には、私たちの思いが詰まっている\nいつでもアクセス、どこでも共有\nクラウドサービス、私たちの未来を描く\n\nストレージの広がり、無限の可能性\nバックアップの安心、失くすことのない\n情報の流れ、瞬時に届く\nクラウドサービス、私たちの夢を叶える\n\n 時を超えて、場所を超えて\nつながる人々、共有する情報\nクラウドサービス、私たちの未来を紡ぐ\n雲の彼方に、広がる世界へ\n\n(詩:雲の彼方へ)"
}
]
}
},
"stopReason": "end_turn",
"usage": {
"inputTokens": 10,
"outputTokens": 191,
"totalTokens": 201
},
"metrics": {
"latencyMs": 1862
}
}
いかがですか? LLMへのプロンプトに応じてLLMが推論結果を返してくれています。
返却payloadが大きい場合、ConverseStream APIでチャンクごとに受け取ることも可能です (CLI未対応)
DifyのAWSデプロイ
TiDB Serverlessによるベクター検索基礎・Difyへの組み込み
PostmanでDify API (Chatbotアプリ) をテストする
LINE 連携
以上で、さまざまなServerless Serviceを利用したアーキテクチャの完成です!
Discussion