S3 SelectObjectContentが廃止になってたのでObject lambda アクセスポイントで書き換えてみた




はじめに
実務で見かけたタイトルのコマンドが面白そうだったのでここで取り上げようと思ったら使えなくなってました。残念。
これに気づくのに2時間くらいハマって悔しかったので、今回は起きたエラーの詳細の共有とアナウンスにある代替案の一つ、Object lambda アクセスポイントでの書き換えをやってみます。
SelectObjectContentが失敗した時のエラー表示
SelectObjectContentは、S3バケットのファイルのデータをSQL分で操作できる機能のことです。今回実行予定だったコードはこちら。

Expression: "SELECT `社員番号` FROM S3Object WHERE `出勤時間` = `` OR `退勤時間` = ``",
この部分でSQLでcsvのデータに対してフィルタをかけています。WHERE句で「出勤時間」「退勤時間」列のいずれかが空の行をフィルタしている、予定だったのですが...
何度やっても405エラー MethodNotAllowed が返ってきました。こうなった人はS3 Selectコマンドが使えない可能性を疑ってみましょう。サポートに問い合わせると、自分のアカウントがS3 Selectコマンドが使える状態か否か確実に分かります。
S3 Object Lambda とは
一言で説明すると、read系のS3 APIのレスポンスのデータに対してコードを適用してデータを加工できる機能のことです。
Amazon S3 Object Lambda を使用すると、Amazon S3 GET、LIST、HEAD リクエストに独自のコードを追加して、データがアプリケーションに返されるときにそのデータを変更および処理できます。
S3 Object Lambdaを使うために必要なものと動く仕組み
S3 Object Lambdaを使うためには以下の4つを準備する必要があります。
- Lambda function: データ加工のためのコードを記述
- Object Lambda アクセスポイント: S3 Object Lambdaサービスエンドポイント
- サポートアクセスポイント(標準のS3アクセスポイント): Object LambdaがS3バケットにアクセスする際に中継するアクセスポイント
- S3バケット: 加工前のデータを格納するS3バケット
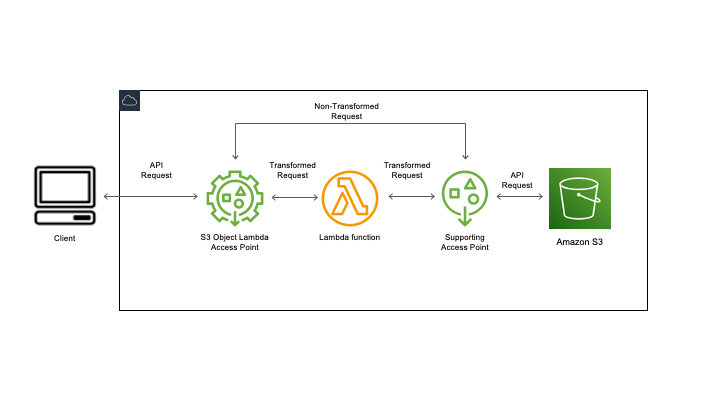
そして、S3 Object Lambdaが動く流れは次のようになります。
- Object Lambda アクセスポイントに対してS3のリクエストを送信する
- Object Lambda アクセスポイントに紐づけたlambda function が呼び出される
- Lambda functionがサポートアクセスポイントを介してS3にアクセスしてデータを取得・加工する
- Object Lambda アクセスポイントが加工されたデータを1のレスポンスとして返却される
公式のアーキテクチャ図も合わせてチェックしましょう。
 仕組みをなんとなく把握したので、実装に入っていきます
仕組みをなんとなく把握したので、実装に入っていきます
実装
CSVデータの作成
データの構造はこのようになりました。
社員番号と名前は必ず入力されていて、出勤時間と退勤時間が値なしの可能性がある仕様です。
| 社員番号 | 名前 | 出勤時間 | 退勤時間 |
|---|---|---|---|
| ID001 | 越前リョーマ | 9:41 | |
| ID002 | 大石秀一郎 | 8:42 | 17:40 |
| ... | ... | ... | ... |
サポートアクセスポイントの作成
S3の画面から左のナビゲーションパネルの「アクセスポイント」を選択して、右上の「アクセスポイントの作成」を押します。
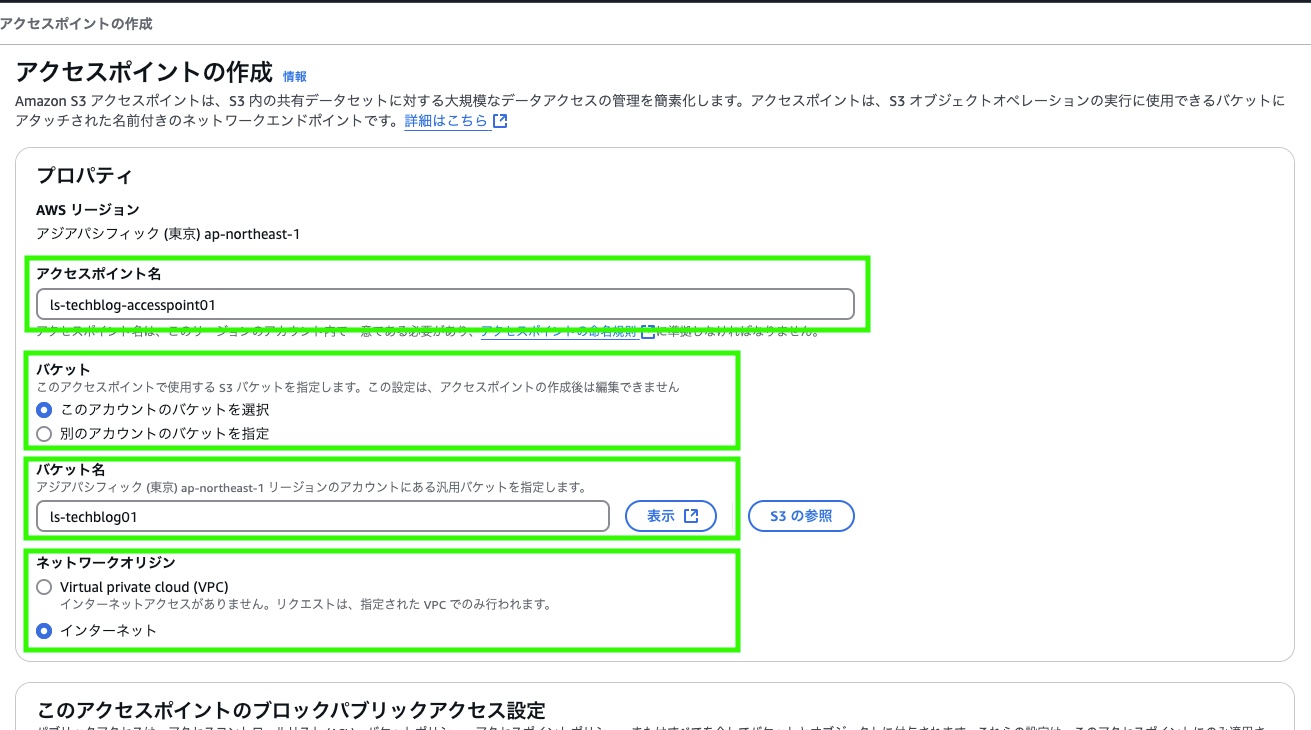
プロパティ
名前とバケット名は各自の環境に合わせてください。
- アクセスポイント名
- バケット
- バケット名
- ネットワークオリジン
パブリックブロックアクセス
特に理由がなければ全部チェックが無難。

アクセスポイントポリシー
今回は自分のユーザだけにアクセスポイント経由でのS3バケットのアクセスを許可します。
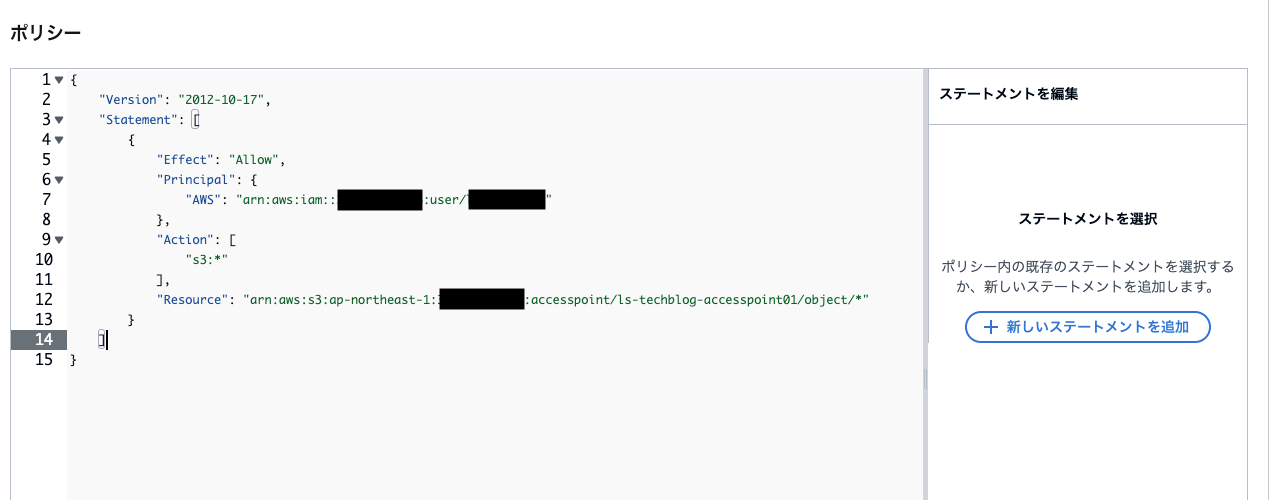
最後に「アクセスポイント作成」を押します。
データ加工用のlambda functionの作成
一番使い慣れてるJavaScript SDK v3で実装しました。
元々SQLで絞り込むところは、utils.jsで定義しているfindMembersWIthNoRecord関数に突っ込みました。やってることはシンプルで、csvデータの文字列を行ごとの配列に変換してArray.filter()をかけてるだけです。
公式のサンプルコードがv2で書かれてたのでv3に書き直すのに結構時間かかりました。コードでは配列をいじるところがあるんですけど、最近そういうのはAIに投げてたところを久々に自分で調べて実装してたら半日くらいかかりました。
仕事じゃない時くらいは自分で考えてコード書かないとですね。
あと、実行ロールにはS3のアクセス権限を忘れないようにしましょう。今回はS3FullAccessをつけてます。
import { S3Client, WriteGetObjectResponseCommand } from "@aws-sdk/client-s3"; // ES Modules import
import { findMembersWIthNoRecord } from './utils.mjs';
export const handler = async (event) => {
const client = new S3Client({region: 'ap-northeast-1'});
const { getObjectContext } = event;
const { outputRoute, outputToken, inputS3Url } = getObjectContext;
try {
const {ok, body, status} = await fetch(inputS3Url, {
method: 'GET',
});
if (!ok) {
throw new Error(`HTTP error! status: ${status}`);
};
const reader = body.getReader();
let decoder = new TextDecoder();
let csvText = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
csvText += decoder.decode(value, { stream: true });
}
// Ensure the stream is fully read and decoded
csvText += decoder.decode();
const membersWithNoRecord = findMembersWIthNoRecord(csvText);
const input = {
RequestRoute: outputRoute,
RequestToken: outputToken,
Body: membersWithNoRecord
? JSON.stringify(membersWithNoRecord)
: "all members have record correctly"
};
const command = new WriteGetObjectResponseCommand(input);
const result = await client.send(command);
console.log('result', result)
} catch (error) {
console.error(error);
}
return { statusCode: 200 };
}
export const findMembersWIthNoRecord = (csvText) => {
console.log('csvText: \n %s', csvText)
const csvWithLF = csvText.replace(/\r\n/g, "\n");
const rows = csvWithLF.split('\n');
const headers = rows[0].split(',');
const rowsWithoutHeader = rows.slice(1);
const indexOfAttend = headers.indexOf('出勤時間');
const indexOfLeave = headers.indexOf('退勤時間');
const datetimePattern = /^\d{1,2}:\d{2}/;
const rowsWithNoRecord = rowsWithoutHeader.filter((row) => {
const rowSplitByComma = row.split(',');
return (
!datetimePattern.test(rowSplitByComma[indexOfAttend]) ||
!datetimePattern.test(rowSplitByComma[indexOfLeave])
);
});
return (rowsWithNoRecord.length > 0) ? rowsWithNoRecord : undefined;
}
Object Lambdaアクセスポイントの作成
S3の画面から左のナビゲーションパネルの「Object lambda アクセスポイント」を選択して、右上の「Object lambda アクセスポイントの作成」を押します。

全般
Object lambda アクセスポイント名を任意の名前で入力します。

サポートするアクセスポイントの設定
作成したアクセスポイントを選択します
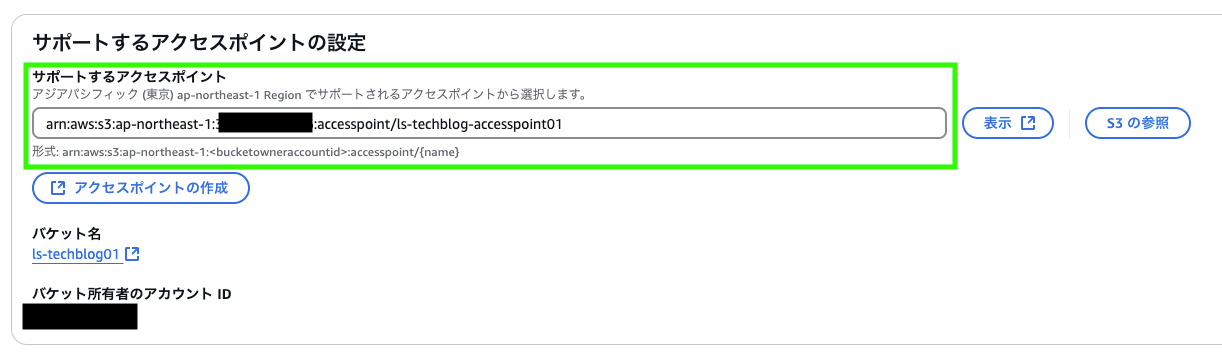
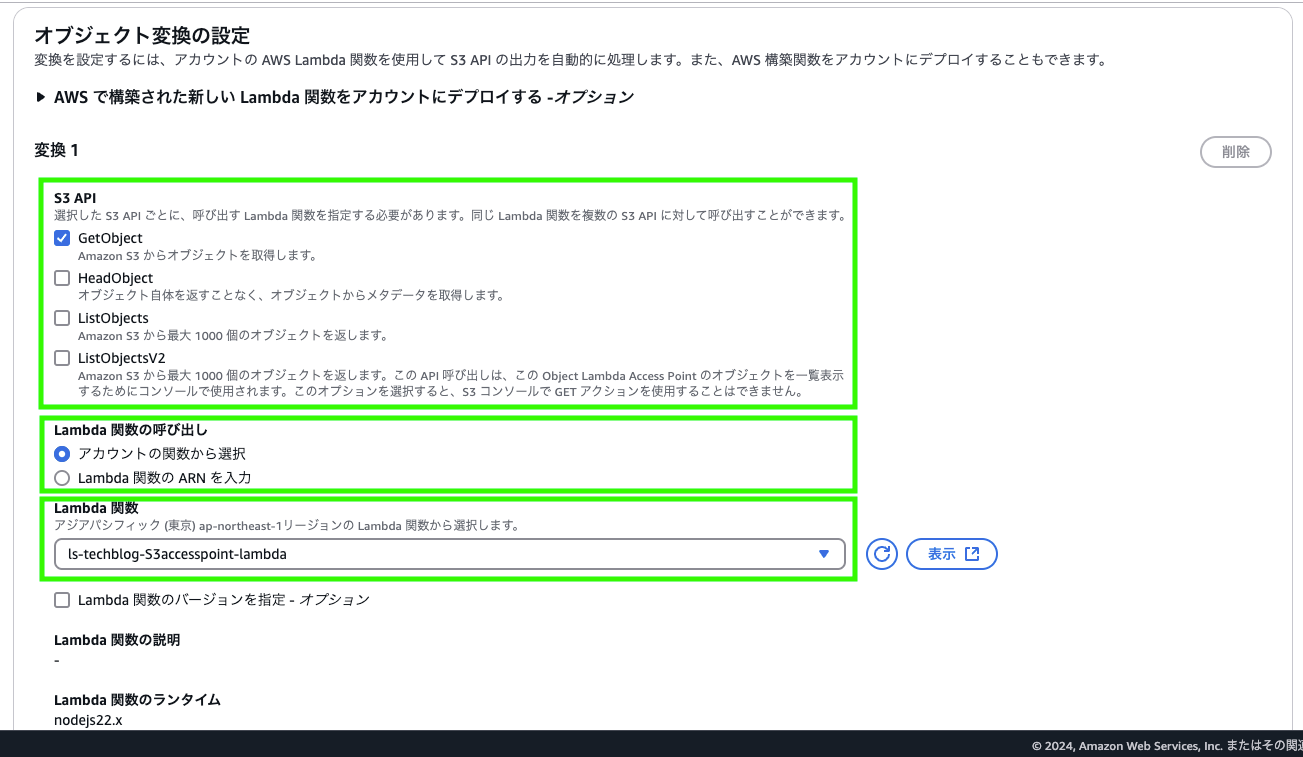
オブジェクト変換の設定
-
S3API
オブジェクトのデータ自体を加工したいので、GetObjectを選択します -
Lambda 関数の呼び出し
- lambda関数
「アカウントの関数から選択」を選択して作成したLambda関数を選択します。
- lambda関数
最後に「Object Lambda アクセスポイントの作成」押します
動作確認
AWS CLIコマンドで s3api コマンドを実行します。Object Lambda アクセスポイントを使う時、使わない時の両方でコマンドを実行して、アクセスポイントが使われたときだけ加工済のデータが返ってくるかを検証します。
アクセスポイントを使わないとき
aws s3api get-object --bucket <バケット名> --key <オブジェクト名> <結果出力先ファイル名(なくても自動作成されます)>

アクセスポイントを使ったとき
aws s3api get-object --bucket <object lambda アクセスポイントARN またはそのエイリアス> --key <オブジェクト名> <結果出力先ファイル名(なくても自動作成されます)>

アクセスポイントを使ったときだけちゃんとデータが絞り込まれてるので、成功です!
ただ、数百バイトのファイルでもレスポンスが3秒くらい差が出ているので、データ容量がもっと増えるとコードも修正が必要そうです。
まとめ
正直すごい面倒くさかったです。データ加工なら他の代替案を使った方がいいような気がします。Athenaとかクライアントサイドで処理させるとか。時間を見つけたらAthenaでやる方法も試してみようかなと思ってます。
以上!
Discussion