ADOPTをTrainerで使う&ADOPTとAdamWの比較
なぜか始めてしまった1人ローカルLLMアドベントカレンダーの1日目です。
この機会に試そうと思っていたことを全部やり切ろうと思って始めることにしましたが、気力と財布が保たない可能性が高いです...
ローカルLLMやマルチモーダルモデルの学習やデータセット周りについて書いていく予定なので、興味がある方は明日以降も読んでいただけると嬉しいです!
要約
- 60MのMistralでADOPTとAdamWを比較
- 2種類の条件で事前学習を実施
- lossの下がり方には大きな影響はなさそう?
目的
少し前に話題になっていたADOPTをAdomWと比較してみたかったので、実際に小規模モデルで事前学習を行い、lossの推移を観察していこうと思います。
実施内容
比較するoptimizer
- ADOPT
- adamw_torch_fused
- adamw_bnb_8bit
使用するモデル
4090でも行える規模の実験にするため、60M程度の超小規模なモデルで検証することにしました。
モデルのconfigは以下の通りです。
{
"_name_or_path": "None",
"architectures": [
"MistralForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 2,
"eos_token_id": 3,
"hidden_act": "silu",
"hidden_size": 384,
"initializer_range": 0.02,
"intermediate_size": 1024,
"max_position_embeddings": 4096,
"model_type": "mistral",
"num_attention_heads": 8,
"num_hidden_layers": 8,
"num_key_value_heads": 2,
"rms_norm_eps": 1e-05,
"rope_theta": 100000.0,
"sliding_window": 1024,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.1",
"use_cache": true,
"vocab_size": 65520
}
トークナイザーは以前に自作のものを使用しています。
使用するデータセット
学習データにはAbejaさんのコーパスから取得した900万行分のWebテキストを使用しました。
今回のトークナイザーで6.5B分です。
検証データはllm-jp-corpus-v3の日本語wikipediaの検証データを使用しています。
学習について
ハイパーパラメータ
optimizer以外の条件は以下の内容で統一しています。
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=1,
learning_rate=5e-4,
lr_scheduler_kwargs={"min_lr": 5e-5},
lr_scheduler_type="cosine_with_min_lr",
warmup_ratio=0.01,
optim=optim,
weight_decay=0.01,
adam_epsilon=1e-6,
adam_beta1=0.9,
adam_beta2=0.95,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=32,
save_strategy="steps",
save_steps=1000,
logging_steps=1,
evaluation_strategy="steps",
eval_steps=100,
bf16=True,
fp16=False,
report_to="wandb",
remove_unused_columns=False,
)
ADOPTの使用方法
from adopt import ADOPT
def get_adopt_optimizer(model, lr=1e-5):
return ADOPT(
model.parameters(),
lr=lr,
betas=(0.9, 0.95),
eps=1e-6,
weight_decay=0.01,
decoupled=True
)
class ADOPTTrainer(Trainer):
def create_optimizer(self):
self.optimizer = get_adopt_optimizer(
self.model,
lr=self.args.learning_rate
)
return self.optimizer
これでTrainerの代わりにADOPTTrainerを使うことで、optimizerがADOPTになります。
結果
学習データ
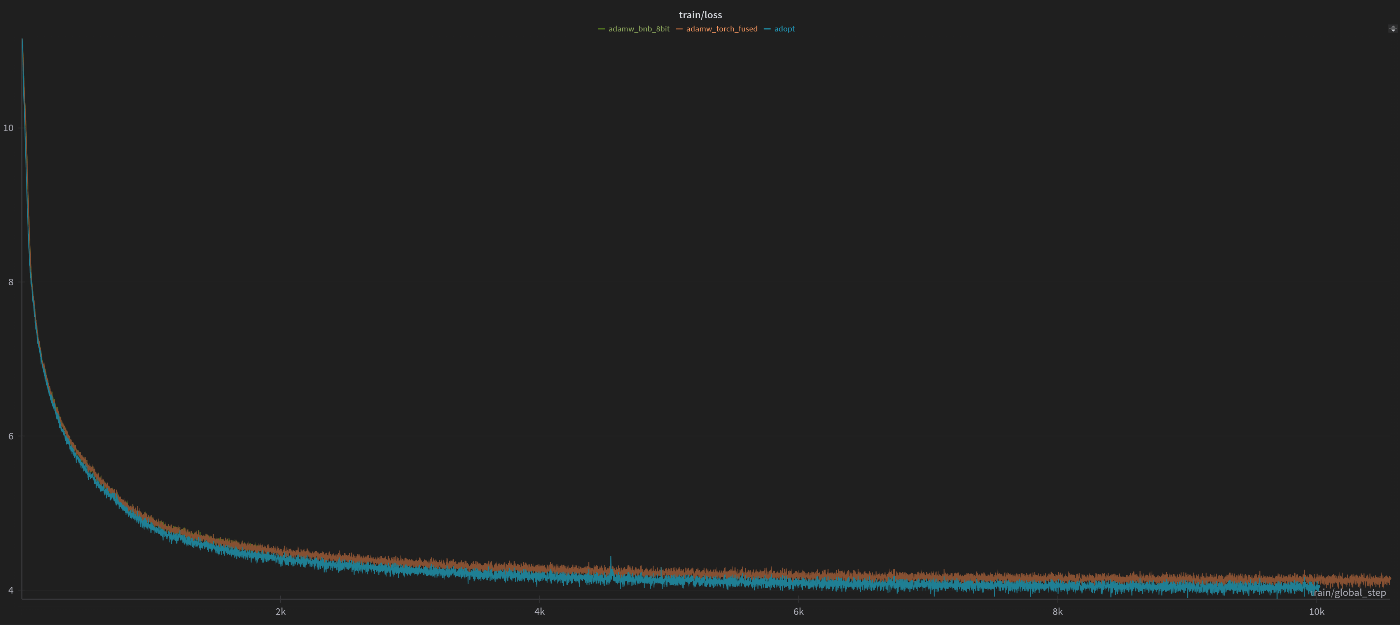
検証データ

eval loss
| ADOPT | adamw_torch_fused | adamw_bnb_8bit | |
|---|---|---|---|
| 500steps | 5.636 | 5.737 | 5.737 |
| 1000steps | 4.726 | 4.840 | 4.824 |
| 2000steps | 4.252 | 4.403 | - |
| 5000steps | 3.978 | 4.112 | - |
| 10000steps | 3.883 | 4.022 | - |
※adamw_bnb_8bitはadamw_torch_fusedとあまり変わらなかったため、途中で切り上げました
学習・検証ともにlossは常にAdamW > ADOPTの関係にあり、10000ステップ段階ではtrain lossで0.095、eval lossで0.14程度の差がついていました。
追加検証
論文を読むと、batch sizeが小さく学習が不安定になりやすいときに有効と書かれていたので、条件を変えて再度検証を行いました。
変更したハイパーパラメータ
| batch size | 16 |
| 0.95 | |
| 0.999 |
結果
学習データ

検証データ

青がADOPT、グレーがAdamWとなっています。
今回の条件では ADOPT > AdamWとなっていますね。
今回の検証は60Mという超小規模のモデルを使っていたことで、学習自体が安定してADOPTの良さが出づらい状況だったのかもしれません。
まとめ
optimizerのハイパーパラメータを最適化しているわけではないので、この実験だけで結論を出すことはできませんが、ADOPTとAdamWに大きな差は見られませんでした。
LoRAは学習が発散しやすい印象があるので、発散するケースがあったらADOPTを使って試してみようと思います。
Discussion