SQL CONTESTをやってみる
↓を第一回からやってみる
第一回
問題1
やるだけ
SELECT
DISTRICT_CODE AS '地区コード',
DISTRICT_NAME AS '地区名',
TOTAL_AMT AS '総人口'
FROM POPULATION
ORDER BY TOTAL_AMT DESC, DISTRICT_CODE DESC;
問題2
これも書いてあるとおりにやるだけではあるけどちょっとしんどい。
クエリを書いているときに「あれ、SELECTの中にAGE_NAME」って含められるんだっけ、って少し不安になったが問題ない。
原則としてGROUP BYを使ったときにSELECTの中にかけるのは以下の3つ。
- 定数
- SUMなどの集約関数
- GROUP BYで指定する集約キー
この3つのうちどれにもAGE_NAMEは当てはまらない。しかしSLEEP_TIME_DTLテーブルとAGE_GRPテーブルとのINNER JOINにより、STD.AGE_CODEに対応するAG.AGE_NAMEが取得されている。これによりAG.AGE_NAMEはSTD.AGE_CODEと1対1の関係にあるため、グループ化のキー(STD.AGE_CODE)ごとにAG.AGE_NAME一意に決定される。よってSELECTの中に書いても良い。
SELECT
STD.AGE_CODE AS '年齢コード',
AG.AGE_NAME AS '年齢階層名',
SUM(STD.SP_TIME_5) AS '5時間未満',
SUM(STD.SP_TIME_6) AS '5時間以上6時間未満',
SUM(STD.SP_TIME_7) AS '6時間以上7時間未満',
SUM(STD.SP_TIME_8) AS '7時間以上8時間未満',
SUM(STD.SP_TIME_9) AS '8時間以上9時間未満',
SUM(STD.SP_TIME_9OVER) AS '9時間以上'
FROM SLEEP_TIME_DTL AS STD INNER JOIN AGE_GRP AS AG ON STD.AGE_CODE = AG.AGE_CODE
INNER JOIN PREFECTURE AS PF ON STD.PF_CODE = PF.PF_CODE
WHERE PF.PF_NAME IN('北海道','青森県','岩手県','宮城県','福島県')
GROUP BY STD.AGE_CODE
ORDER BY STD.AGE_CODE;
問題3
ややこしいので、次のステップで段階を踏んで考える。
Step1 - PORT_CODEごとに入国者と出国者を計算する
これはPORT_CODEでGROUP BYをしてIMMIGRATIONのレコードを複数の集合に切り分けたうえで、CASE句を使ってSUMを計算することで簡単に求められる。
SELECT
PORT_CODE AS '港コード',
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '110' THEN AMT ELSE 0 END) AS '入国者数',
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '120' THEN AMT ELSE 0 END) AS '出国者数'
FROM IMMIGRATION
GROUP BY PORT_CODE;
Step2 - サブクエリを使って差分を出力する
先ほど作ったビューをWITH句でImmigrationDataという名前で持っておく。すると差分を出すのも簡単になる。ついでに「外国人の入国者が出国者より多い港を抽出」ということだったのでWHERE句も書いておく。
WITH ImmigrationData AS (
SELECT
PORT_CODE,
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '110' THEN AMT ELSE 0 END) AS 'inbound',
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '120' THEN AMT ELSE 0 END) AS 'outbound'
FROM IMMIGRATION
GROUP BY PORT_CODE
)
SELECT
PORT_CODE AS '港コード',
inbound AS '入国者',
outbound AS '出国者',
inbound - outbound AS '差分'
FROM ImmigrationData
WHERE inbound - outbound > 0;
Step3 - 港名を出力するためJOINしてORDER BYを追加する
ここまで来たらあとは楽でJOINしてORDER BYを付け加えるだけ。
WITH ImmigrationData AS (
SELECT
PORT_CODE,
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '110' THEN AMT ELSE 0 END) AS 'inbound',
SUM(CASE WHEN GROUP_CODE = '120' AND KIND_CODE = '120' THEN AMT ELSE 0 END) AS 'outbound'
FROM IMMIGRATION
GROUP BY PORT_CODE
)
SELECT
ID.PORT_CODE AS '港コード',
PORT.PORT_NAME AS '港名',
ID.inbound AS '入国者数',
ID.outbound AS '出国者数',
ID.inbound - ID.outbound AS '差分'
FROM ImmigrationData AS ID INNER JOIN PORT ON ID.PORT_CODE = PORT.PORT_CODE
WHERE ID.inbound - ID.outbound > 0
ORDER BY 差分 DESC, ID.PORT_CODE DESC;
これで解けた。
問題4
これもややこしいので問題を分解して考える。
Step1 - 都道府県コードごとにランクをつけ、合計人数も求める
ウィンドウ関数をうまく使えばできる。
「集計した人数が同数の場合は、国籍コードの昇順で順位付けを行うこと。」と書いてあるので、DENSE_RANKを用いることに注意。
SELECT
PF_CODE,
NATION_CODE,
AMT,
DENSE_RANK () OVER (PARTITION BY PF_CODE ORDER BY AMT DESC, NATION_CODE) as rank,
SUM(AMT) OVER(PARTITION BY PF_CODE) as sum
FROM FOREIGNER
WHERE NATION_CODE <> '113';
Step2 - JOINをしてコードから国名と都道府県名を復元し、上位3位までを絞り込む
先ほど作ったRankテーブルにあるPF_CODEとNATION_CODE を使ってJOINを行い、名前を復元する。
また、今回必要なのは上位3位までなのでそれも絞り込んでおく。
WITH Ranked AS (
SELECT
PF_CODE,
NATION_CODE,
AMT,
DENSE_RANK () OVER (PARTITION BY PF_CODE ORDER BY AMT DESC, NATION_CODE) as rank,
SUM(AMT) OVER(PARTITION BY PF_CODE) as sum
FROM FOREIGNER
WHERE NATION_CODE <> '113'
)
SELECT
Ranked.PF_CODE,
NATIONALITY.NATION_NAME,
PREFECTURE.PF_NAME,
Ranked.AMT,
Ranked.rank,
Ranked.sum
FROM
Ranked INNER JOIN NATIONALITY ON Ranked.NATION_CODE = NATIONALITY.NATION_CODE
INNER JOIN PREFECTURE ON Ranked.PF_CODE = PREFECTURE.PF_CODE
WHERE Ranked.rank <= 3
Step3 - 指定された出力フォーマットに形を整える
あとは縦持ちテーブルを横持ちテーブルに変換すれば答えになる。
WITH Ranked AS (
SELECT
PF_CODE,
NATION_CODE,
AMT,
DENSE_RANK () OVER (PARTITION BY PF_CODE ORDER BY AMT DESC, NATION_CODE) as rank,
SUM(AMT) OVER(PARTITION BY PF_CODE) as sum
FROM FOREIGNER
WHERE NATION_CODE <> '113'
)
, Ranked2 AS (
SELECT
Ranked.PF_CODE,
NATIONALITY.NATION_NAME,
PREFECTURE.PF_NAME,
Ranked.AMT,
Ranked.rank,
Ranked.sum
FROM
Ranked INNER JOIN NATIONALITY ON Ranked.NATION_CODE = NATIONALITY.NATION_CODE
INNER JOIN PREFECTURE ON Ranked.PF_CODE = PREFECTURE.PF_CODE
WHERE Ranked.rank <= 3
)
SELECT
PF_CODE AS '都道府県コード',
PF_NAME AS '都道府県名',
MAX(CASE WHEN rank = 1 THEN NATION_NAME ELSE NULL END) AS '1位 国名',
SUM(CASE WHEN rank = 1 THEN AMT ELSE NULL END) AS '1位 人数',
MAX(CASE WHEN rank = 2 THEN NATION_NAME ELSE NULL END) AS '2位 国名',
SUM(CASE WHEN rank = 2 THEN AMT ELSE NULL END) AS '2位 人数',
MAX(CASE WHEN rank = 3 THEN NATION_NAME ELSE NULL END) AS '3位 国名',
SUM(CASE WHEN rank = 3 THEN AMT ELSE NULL END) AS '3位 人数',
MAX(sum) AS '合計人数'
FROM Ranked2
GROUP BY PF_CODE
ORDER BY 合計人数 DESC, PF_CODE ASC;
第二回
問題1
書いてあるとおりにやるだけ
UPDATE POPULATION
SET
DISTRICT_NAME = '不明'
WHERE
DISTRICT_NAME IS NULL
OR DISTRICT_NAME = '';
問題2
これも書いてあるとおりにやるだけ
SELECT
DISTRICT_CODE AS 'CODE',
DISTRICT_NAME AS 'NAME',
TOTAL_AMT AS 'TOTAL'
FROM
POPULATION
WHERE
DISTORICT_NAME LIKE '%東%'
AND TOTAL_AMT >= 100000
ORDER BY
TOTAL_AMT DESC,
DISTRICT_CODE ASC;
問題3
難しいのは飲酒率を求めるところだが、CASE文を使えば難しくない。
ただ普通にSUMとSUMの割り算をしてしまうと整数同士の割り算となって答えが整数の0で返ってきてしまうので、分子はfloatにCASTする。
SELECT
DRINK_HABITS.PF_CODE AS 'CODE',
PREFECTURE.PF_NAME AS 'NAME',
ROUND(
(
CAST(
SUM(
CASE
WHEN DRINK_HABITS.CATEGORY_CODE = '120'
AND GENDER_CODE IN ('2', '3') THEN DRINK_HABITS.AMT
ELSE 0
END
) AS FLOAT
) / SUM(
CASE
WHEN DRINK_HABITS.CATEGORY_CODE = '110'
AND GENDER_CODE IN ('2', '3') THEN DRINK_HABITS.AMT
ELSE 0
END
)
) * 100,
1
) AS 'PERCENTAGE'
FROM
DRINK_HABITS
INNER JOIN PREFECTURE ON DRINK_HABITS.PF_CODE = PREFECTURE.PF_CODE
GROUP BY
DRINK_HABITS.PF_CODE
ORDER BY
PERCENTAGE DESC,
DRINK_HABITS.PF_CODE DESC;
問題4
一旦各列が各種類の人数を表すようなSQLを書いてみる
SELECT
ES.SURVEY_YEAR,
ES.PF_CODE,
PF.PF_NAME,
SUM(ELEMENTARY) AS 'EMT_AMT',
SUM(MIDDLE) AS 'MD_AMT',
SUM(HIGH) AS 'HIGH_AMT',
SUM(JUNIOR_CLG) AS 'JC_AMT',
SUM(COLLEGE) AS 'CL_AMT',
SUM(GRADUATE) AS 'GD_AMT'
FROM
ENROLLMENT_STATUS AS ES
INNER JOIN PREFECTURE AS PF ON ES.PF_CODE = PF.PF_CODE
WHERE
SURVEY_YEAR = 2020
GROUP BY
ES.PF_CODE;
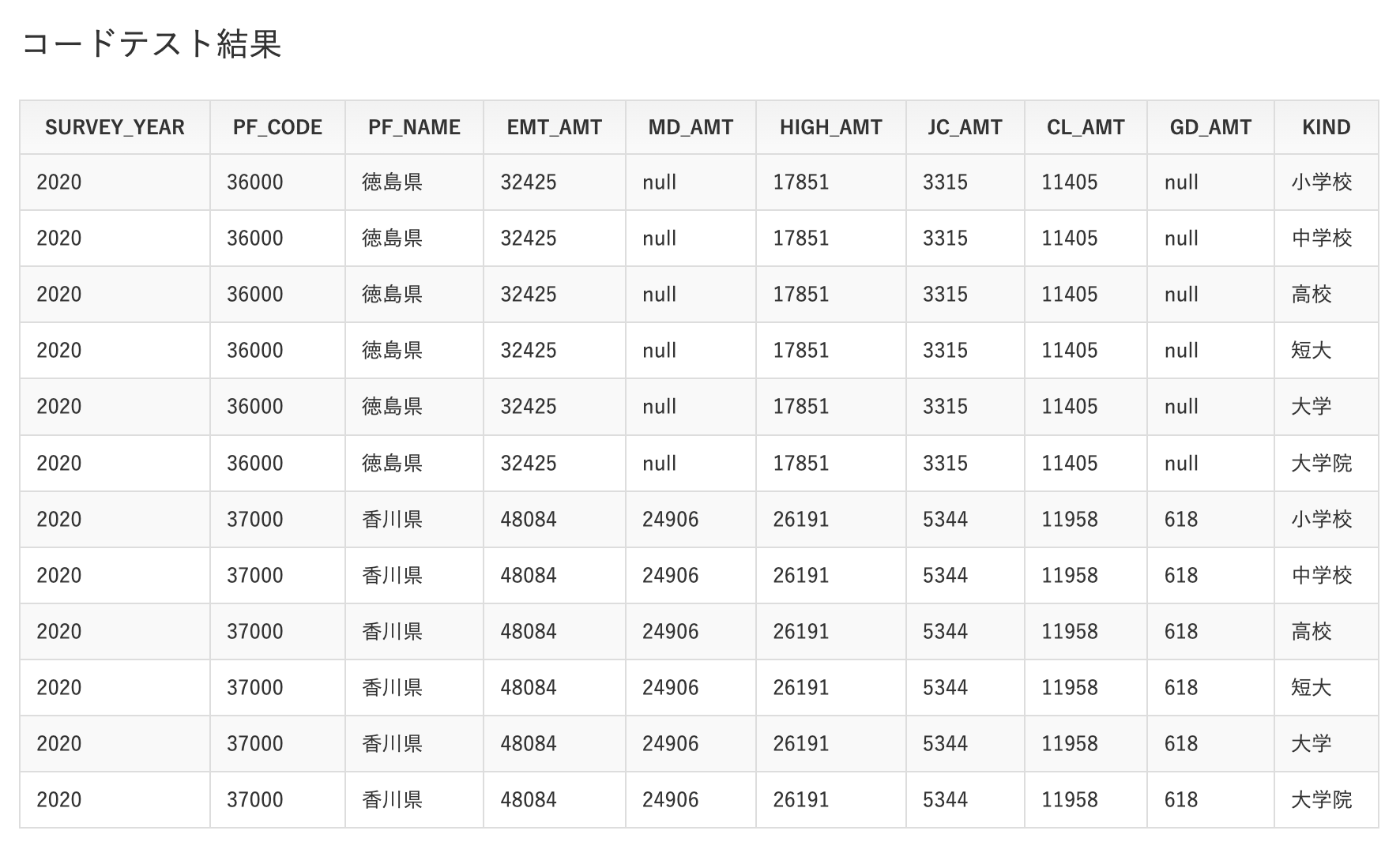
このSQLを実行すると↓のようになる。

これはいわゆる横持ちテーブルなのでこれを縦持ちに変換する。
ここは難しくてわからなかったのでググることにした。
そしたら補助テーブルを作ってCROSS JOINすればできるみたい。
WITH
ES2 AS (
SELECT
ES.SURVEY_YEAR,
ES.PF_CODE,
PF.PF_NAME,
SUM(ELEMENTARY) AS 'EMT_AMT',
SUM(MIDDLE) AS 'MD_AMT',
SUM(HIGH) AS 'HIGH_AMT',
SUM(JUNIOR_CLG) AS 'JC_AMT',
SUM(COLLEGE) AS 'CL_AMT',
SUM(GRADUATE) AS 'GD_AMT'
FROM
ENROLLMENT_STATUS AS ES
INNER JOIN PREFECTURE AS PF ON ES.PF_CODE = PF.PF_CODE
WHERE
SURVEY_YEAR = 2020
GROUP BY
PF.PF_CODE
)
SELECT
*
FROM
ES2
CROSS JOIN (
SELECT
'小学校' AS KIND
UNION ALL
SELECT
'中学校' AS KIND
UNION ALL
SELECT
'高校' AS KIND
UNION ALL
SELECT
'短大' AS KIND
UNION ALL
SELECT
'大学' AS KIND
UNION ALL
SELECT
'大学院' AS KIND
);
これをCASE文を使って縦持ちに変換する
WITH
ES2 AS (
SELECT
ES.SURVEY_YEAR,
ES.PF_CODE,
PF.PF_NAME,
SUM(ELEMENTARY) AS 'EMT_AMT',
SUM(MIDDLE) AS 'MD_AMT',
SUM(HIGH) AS 'HIGH_AMT',
SUM(JUNIOR_CLG) AS 'JC_AMT',
SUM(COLLEGE) AS 'CL_AMT',
SUM(GRADUATE) AS 'GD_AMT'
FROM
ENROLLMENT_STATUS AS ES
INNER JOIN PREFECTURE AS PF ON ES.PF_CODE = PF.PF_CODE
WHERE
SURVEY_YEAR = 2020
GROUP BY
PF.PF_CODE
)
SELECT
ES2.SURVEY_YEAR AS SV_YEAR,
ES2.PF_NAME AS PREFECTURE,
c.KIND AS KIND,
CASE c.KIND
WHEN '小学校' THEN EMT_AMT
WHEN '中学校' THEN MD_AMT
WHEN '高校' THEN HIGH_AMT
WHEN '短大' THEN JC_AMT
WHEN '大学' THEN CL_AMT
WHEN '大学院' THEN GD_AMT
ELSE 0
END AS AMT
FROM
ES2
CROSS JOIN (
SELECT
'小学校' AS KIND
UNION ALL
SELECT
'中学校' AS KIND
UNION ALL
SELECT
'高校' AS KIND
UNION ALL
SELECT
'短大' AS KIND
UNION ALL
SELECT
'大学' AS KIND
UNION ALL
SELECT
'大学院' AS KIND
) AS c;
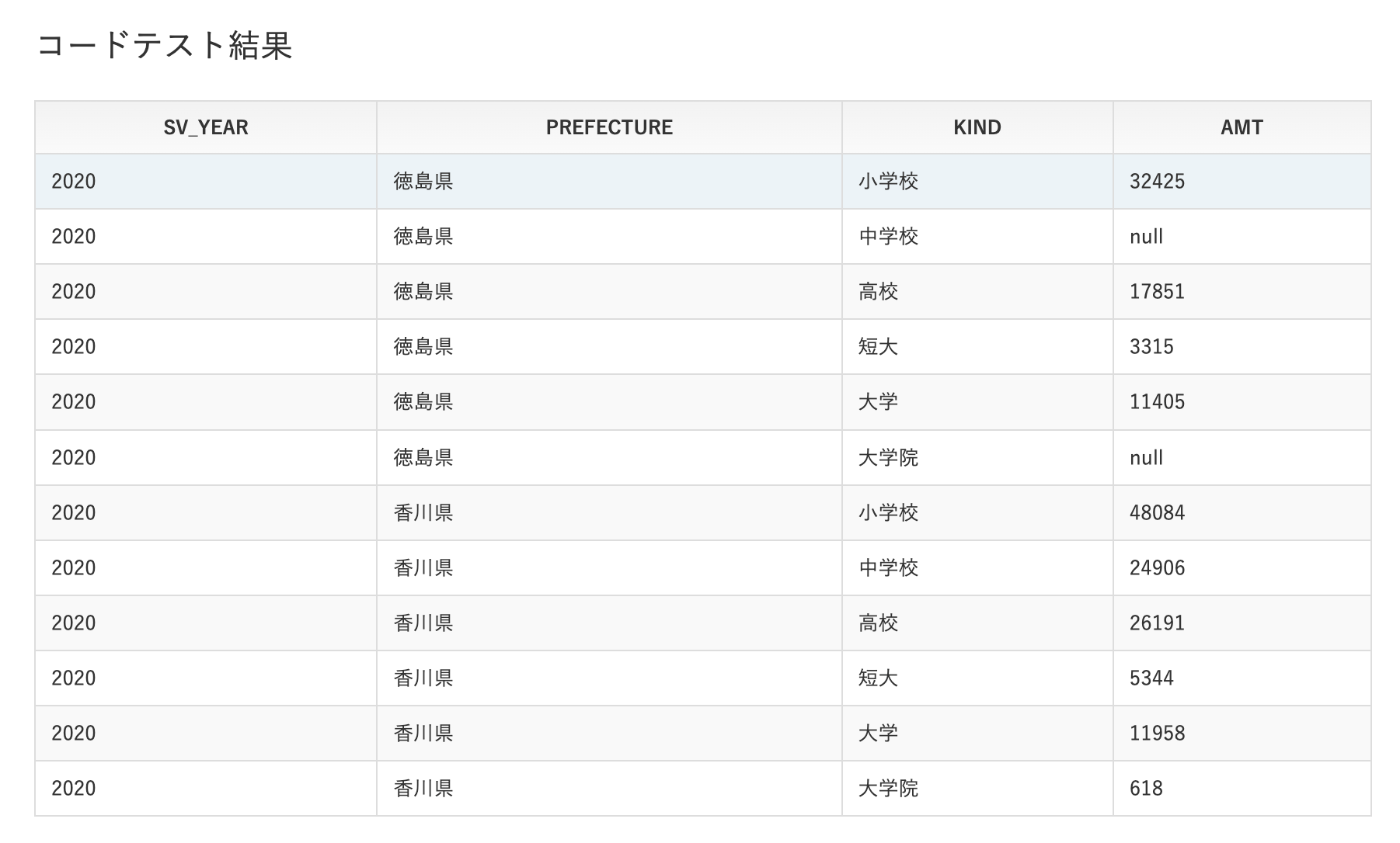
ここまできたらあとは人数がNULLのレコードを弾いてORDER BYをかけるだけ。
しかしここで問題が発生する。問題文で指定されている表示順は
就学状況データの就学先を左から並べた順番(小学校→・・→大学院)
となっているが、今のままだとその指定をするのが難しい。よって、CROSS JOINでJOINしているcテーブルに新たにNUMカラムを追加してこれをORDER BYのキーとする。
よって最終的な答えは以下となる。
WITH
ES2 AS (
SELECT
ES.SURVEY_YEAR,
ES.PF_CODE,
PF.PF_NAME,
SUM(ELEMENTARY) AS 'EMT_AMT',
SUM(MIDDLE) AS 'MD_AMT',
SUM(HIGH) AS 'HIGH_AMT',
SUM(JUNIOR_CLG) AS 'JC_AMT',
SUM(COLLEGE) AS 'CL_AMT',
SUM(GRADUATE) AS 'GD_AMT'
FROM
ENROLLMENT_STATUS AS ES
INNER JOIN PREFECTURE AS PF ON ES.PF_CODE = PF.PF_CODE
WHERE
SURVEY_YEAR = 2020
GROUP BY
PF.PF_CODE
)
SELECT
ES2.SURVEY_YEAR AS SV_YEAR,
ES2.PF_NAME AS PREFECTURE,
c.KIND AS KIND,
CASE c.KIND
WHEN '小学校' THEN EMT_AMT
WHEN '中学校' THEN MD_AMT
WHEN '高校' THEN HIGH_AMT
WHEN '短大' THEN JC_AMT
WHEN '大学' THEN CL_AMT
WHEN '大学院' THEN GD_AMT
ELSE 0
END AS AMT
FROM
ES2
CROSS JOIN (
SELECT
1 AS NUM,
'小学校' AS KIND
UNION ALL
SELECT
2 AS NUM,
'中学校' AS KIND
UNION ALL
SELECT
3 AS NUM,
'高校' AS KIND
UNION ALL
SELECT
4 AS NUM,
'短大' AS KIND
UNION ALL
SELECT
5 AS NUM,
'大学' AS KIND
UNION ALL
SELECT
6 AS NUM,
'大学院' AS KIND
) AS c
WHERE
AMT IS NOT NULL
ORDER BY
ES2.PF_CODE ASC,
c.NUM ASC;
若干不安なところとして、WHERE AMT IS NOT NULLがある。AMTはSELECT時につけた別名であるが、たしか標準SQLではWHEREでSELECT時につけた別名は使えないのではなかったか。
なので今回うまくいったのはたまたまな気がする。。。SQLiteがその記法に対応していただけな気が。。。
第三回
問題1
書いてあるとおりに書くだけ
SELECT
PF_CODE AS 'CODE',
TOTAL_VALUE AS 'SALES_AMT'
FROM
CONVENIENCE
WHERE
SURVEY_YEAR = 2019
AND KIND_CODE = '100'
ORDER BY
SALES_AMT DESC,
CODE;
問題2
これも書いてあるとおりにやるだけ。
INSERT INTO
CONVENI_SALE_2018 (SURVEY_YEAR, PF_CODE, TOTAL_VALUE)
SELECT
SURVEY_YEAR,
PF_CODE,
TOTAL_VALUE
FROM
CONVENIENCE
WHERE
SURVEY_YEAR = 2018
AND KIND_CODE = '100'
AND TOTAL_VALUE IS NOT NULL;
でも最初はINSERT文ではVALUES句内にサブクエリを直接使用できないことを忘れて下のように書いてしまっていた。。。
ググって修正することで正解できた。
INSERT INTO
CONVENI_SALE_2018 (SURVEY_YEAR, PF_CODE, TOTAL_VALUE)
VALUES
(
SELECT
SURVEY_YEAR,
PF_CODE,
TOTAL_VALUE
FROM
CONVENIENCE
WHERE
SURVEY_YEAR = 2018
AND KIND_CODE = '100'
AND TOTAL_VALUE IS NOT NULL
);
問題3
難しかった。まずは各所得階層と世帯人員ごとにその数を集計する。
SELECT
CLASS_NAME AS 'CLASS',
PERSON_NAME AS 'PERSON',
SUM(AMT) AS 'HOUSEHOLDS'
FROM
HOUSEHOLD
WHERE
CLASS_CODE <> '01'
AND PERSON_CODE <> '1'
GROUP BY
CLASS_NAME,
PERSON_NAME
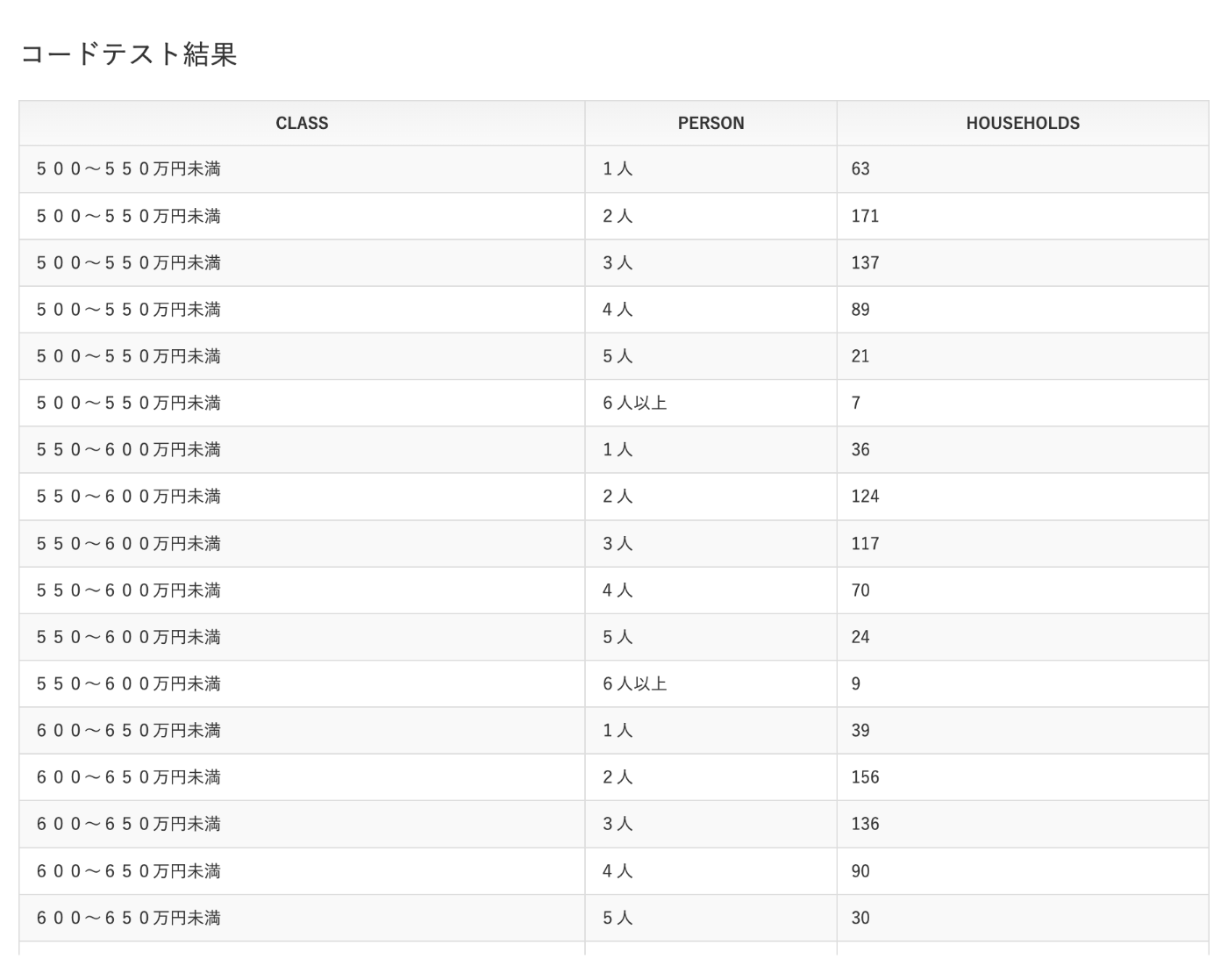
このテーブルをWITH句で持っておいてどう問題を解くかを考える。
問題を解くためには、各階級ごとのHOUSEHOLDSが最大となっているレコードを抽出すればよい。
これがわかれば後はやるだけになる。
WITH
H1 AS (
SELECT
CLASS_CODE,
CLASS_NAME AS CLASS,
PERSON_NAME AS PERSON,
SUM(AMT) AS HOUSEHOLDS
FROM
HOUSEHOLD
WHERE
CLASS_CODE <> '01'
AND PERSON_CODE <> '1'
GROUP BY
CLASS_NAME,
PERSON_NAME
)
SELECT
CLASS,
PERSON,
HOUSEHOLDS
FROM
H1
WHERE
HOUSEHOLDS = (
SELECT
MAX(HOUSEHOLDS)
FROM
H1 AS H1_tmp
WHERE
H1.CLASS = H1_tmp.CLASS
)
ORDER BY
CLASS_CODE;
問題4
はちゃめちゃにややこしい。ややこしいので分解して考える。
私はまず次のSQLを書いた。
これは、S2としてただJOINしたテーブルを作り、S3として順位を算出するのに必要な情報を計算するテーブルを作った。
めちゃめちゃネストしているけどこうする方法しか思いつかなかった。
WITH
S2 AS (
SELECT
S.SUBMIT_ID,
S.CONTEST_ID,
S.PROBLEM_ID,
S.USER_ID,
S.ENTRY_ID,
S.SUBMITTED_AT,
S.STATUS,
S.POINT,
E.STARTED_AT
FROM
SUBMISSIONS AS S
INNER JOIN ENTRIES AS E ON S.ENTRY_ID = E.ENTRY_ID
WHERE
S.CONTEST_ID = 2
AND S.USER_ID IN (
SELECT
USER_ID
FROM
SUBMISSIONS
GROUP BY
USER_ID
HAVING
SUM(POINT) <> 0
)
),
S3 AS (
SELECT
USER_ID,
SUM(POINT) AS total_points,
( -- 実解答時間
SELECT
STRFTIME ('%s', MAX(SUBMITTED_AT)) - STRFTIME ('%s', STARTED_AT)
FROM
S2 AS sub_s2
WHERE
sub_s2.USER_ID = S2.USER_ID
AND STATUS = 'AC'
) AS real_time,
( -- 各ユーザーごとの誤答数
SELECT
COALESCE(SUM(WA_cnt_by_problem), 0)
FROM
(
-- 各ユーザーごとの、各問題ごとの誤答数
SELECT
USER_ID,
COUNT(*) AS WA_cnt_by_problem
FROM
S2 AS S2_temp1
WHERE
-- 誤答数としてカウントするのは各問題の最初のAC以前に記録されたWA
SUBMITTED_AT < (
SELECT
MIN(SUBMITTED_AT)
FROM
S2 AS S2_temp2
WHERE
STATUS = 'AC'
AND S2_temp1.USER_ID = S2_temp2.USER_ID
AND S2_temp1.PROBLEM_ID = S2_temp2.PROBLEM_ID
)
AND STATUS = 'WA'
GROUP BY
USER_ID,
PROBLEM_ID
) AS tbl_for_wa_cnt
WHERE
tbl_for_wa_cnt.USER_ID = S2.USER_ID
) AS total_wa_count
FROM
S2
GROUP BY
USER_ID
HAVING
SUM(POINT) <> 0
)
SELECT
*
FROM
S3;
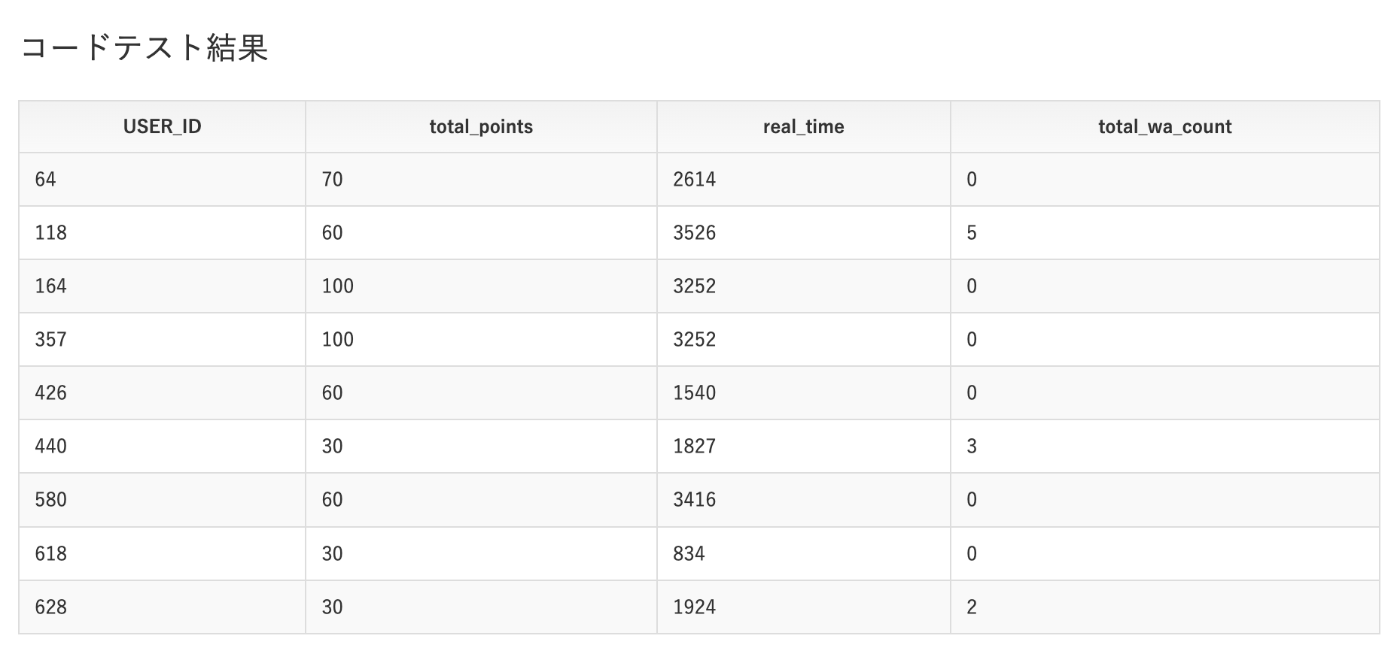
WITH
S2 AS (
SELECT
S.SUBMIT_ID,
S.CONTEST_ID,
S.PROBLEM_ID,
S.USER_ID,
S.ENTRY_ID,
S.SUBMITTED_AT,
S.STATUS,
S.POINT,
E.STARTED_AT
FROM
SUBMISSIONS AS S
INNER JOIN ENTRIES AS E ON S.ENTRY_ID = E.ENTRY_ID
WHERE
S.CONTEST_ID = 2
AND S.USER_ID IN (
SELECT
USER_ID
FROM
SUBMISSIONS
GROUP BY
USER_ID
HAVING
SUM(POINT) <> 0
)
),
S3 AS (
SELECT
USER_ID,
SUM(POINT) AS total_points,
( -- 実解答時間
SELECT
STRFTIME ('%s', MAX(SUBMITTED_AT)) - STRFTIME ('%s', STARTED_AT)
FROM
S2 AS sub_s2
WHERE
sub_s2.USER_ID = S2.USER_ID
AND STATUS = 'AC'
) AS real_time,
( -- 各ユーザーごとの誤答数
SELECT
COALESCE(SUM(WA_cnt_by_problem), 0)
FROM
(
-- 各ユーザーごとの、各問題ごとの誤答数
SELECT
USER_ID,
COUNT(*) AS WA_cnt_by_problem
FROM
S2 AS S2_temp1
WHERE
-- 誤答数としてカウントするのは各問題の最初のAC以前に記録されたWA
SUBMITTED_AT < (
SELECT
MIN(SUBMITTED_AT)
FROM
S2 AS S2_temp2
WHERE
STATUS = 'AC'
AND S2_temp1.USER_ID = S2_temp2.USER_ID
AND S2_temp1.PROBLEM_ID = S2_temp2.PROBLEM_ID
)
AND STATUS = 'WA'
GROUP BY
USER_ID,
PROBLEM_ID
) AS tbl_for_wa_cnt
WHERE
tbl_for_wa_cnt.USER_ID = S2.USER_ID
) AS total_wa_count
FROM
S2
GROUP BY
USER_ID
HAVING
SUM(POINT) <> 0
),
S4 AS (
SELECT
USER_ID,
total_points AS POINT,
real_time + 300 * total_wa_count AS EX_TIME,
total_wa_count AS WRONG_ANS
FROM
S3
)
SELECT
*
FROM
S4;