PlanetScale APIを使ってDBテストを高速化した
概要
PlanetScale APIを使ってDBテストを高速化したので、その時にやった具体的な手法を記載した記事になります。
対象読者
下記の通りです。
- テストコードを書いたことがある人
- PlanetScaleを使ったことがある人
- テストコードの実行速度に関して問題意識を持っている人
サンプルコードはPythonとpytestを使っていますが、この記事の内容は他言語のテストコードでも応用できるかと思います。
筆者のバックグラウンド
普段はTypeScript(Next.jsを主に利用)を用いたフロントエンド開発者です。
以前はバックエンドエンジニアで主にGoを使ってAWS上でAPIの開発などを行なっていました。
最近はLLMを用いたアプリケーション開発に関わっています。
PythonやFastAPIの経験は浅いです。
テストコード自体はキャリアの最初期から積極的に書いており、テストコードの重要性は理解しています。
この記事で説明すること
- PlanetScale APIの使い方
- テストを並列実行して高速化するための手法
この記事で説明しないこと
- pytestの詳しい説明
- PlanetScaleの詳しい説明
サンプルアプリケーションの紹介
サンプルとして個人で開発中のねこの人格を持ったAIと会話できるサービスを例に説明します。(このサービスはフロント側はまだ未完成ですが、バックエンド側は最低限の機能が完成しています)
上記サービスのバックエンド側のソースコードは以下に公開しています。
こちらのコードを見て概要を理解できる人は以降の章を読む必要はありません。(tests/ 配下がテストコード周りの実装です)
ちなみにこのアプリケーションのアーキテクチャ全体の解説に関しては下記の記事で解説していますので、興味がある人はご覧ください。
DBを使ったテストケースが遅い
以下の記事でも解説をしていますが、基本的にDBのテストは本物のDBを用意して、テストコードのなかで実際のDBにテストデータを投入する形でテストをしています。
DBはPlanetScaleを利用していたので、CI用の専用ブランチを作成してGitHubActionsのCI用WorkflowからはCI用の専用ブランチに接続してテストコードの実行を行なっていました。
実際のDBを使うテストコードはDB周りのテストがしっかりとできる反面、テストデータの初期化やテストデータの投入がテストケースごとに発生するのでテストの実行速度が問題になります。
サンプルアプリケーションの紹介で紹介している 個人プロジェクト では問題になりませんでしたが、同様の構成で作っている実案件では以下の問題が起きていました。
- 機能が多くなりDBを使ったテストが増えすぎたことでCIの実行時間が大幅に増加、終了までに約10分くらいかかってしまう
- GitHubActionsのCI用Workflowでは同じPlanetScaleのDBを参照していたのでPRが被るとテストデータの競合が発生してテストに失敗する
開発速度やデプロイ速度の低下が起こっているので、何とかこの問題を解決する必要がありました。
テスト高速化のためにテストを並列実行
真っ先に思いついたのはテストの並列実行です。
pytestでは pytest-xdist を使ってテストを並列実行可能ですがテストケースごとにテストケースが並列実行される関係上、データベースのテストデータが衝突してしまいテストが失敗してしまいます。
その為、テストケースごとに別のデータベースにアクセスする方法を考えることにしました。
PlanetScale APIを使った解決方法
PlanetScaleのドキュメントを眺めているとAPIが公開されていることに気が付きました。
以下の「Get a branch schema」はPlanetScaleに存在するブランチからDBのSchemaを取得するAPIです。
このAPIを使えば問題が解決できそうです。
テストケースの実行環境を以下のようにすることで解決できそうです。
- テストケースの実行はDockerでMySQLのコンテナを起動して、DBの向き先をコンテナに変更する
- テストコード実行時にPlanetScaleの「Get a branch schema」APIを使ってDBのSchemaを取得
- テストケースごとに異なるDBを作成、その後
2で取得したSchemaを使ってテーブルの作成を行なう -
3で作成したDBに対してテストデータの初期化&テストの実行を行なう
この方法であれば、テストデータの衝突が起きないのでテストの並列実行をしても問題がなさそうです。
PlanetScale APIの利用準備
まずはPlanetScale APIの利用準備です。下記のページを確認します。
A service token or OAuth token must have at least one of the following access or scopes in order to use this API endpoint:
とあるので簡単そうなService Tokenを使ってアクセスすることにします。
以下のページにService Tokenの発行方法が記載されています。
Get a branch schema のページを見るとService Tokenには以下の権限が必要なようです。
Service Token Accesses
read_branch, delete_branch, create_branch, connect_production_branch, connect_branch
Service Tokenの作成を行ないます。
1. https://app.planetscale.com/{あなたのOrganization名}/settings/service-tokens からトークンの発行を行ないます。
「New service token」を押下します。
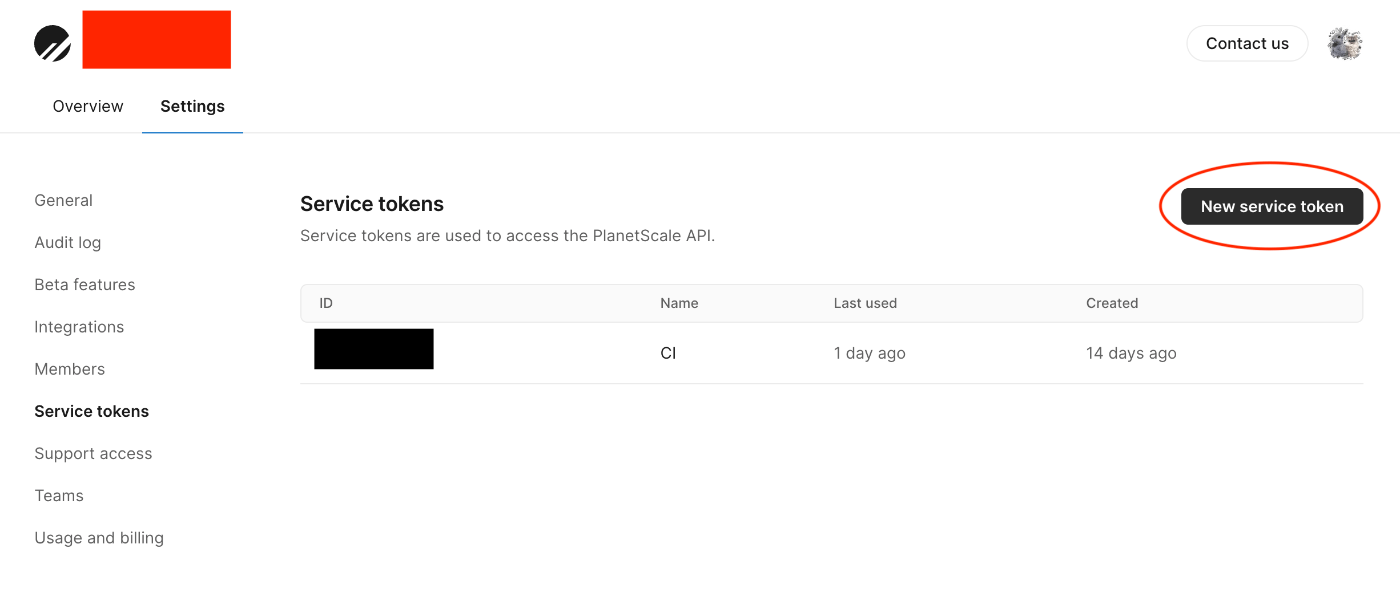
2. わかりやすい名前をつけます
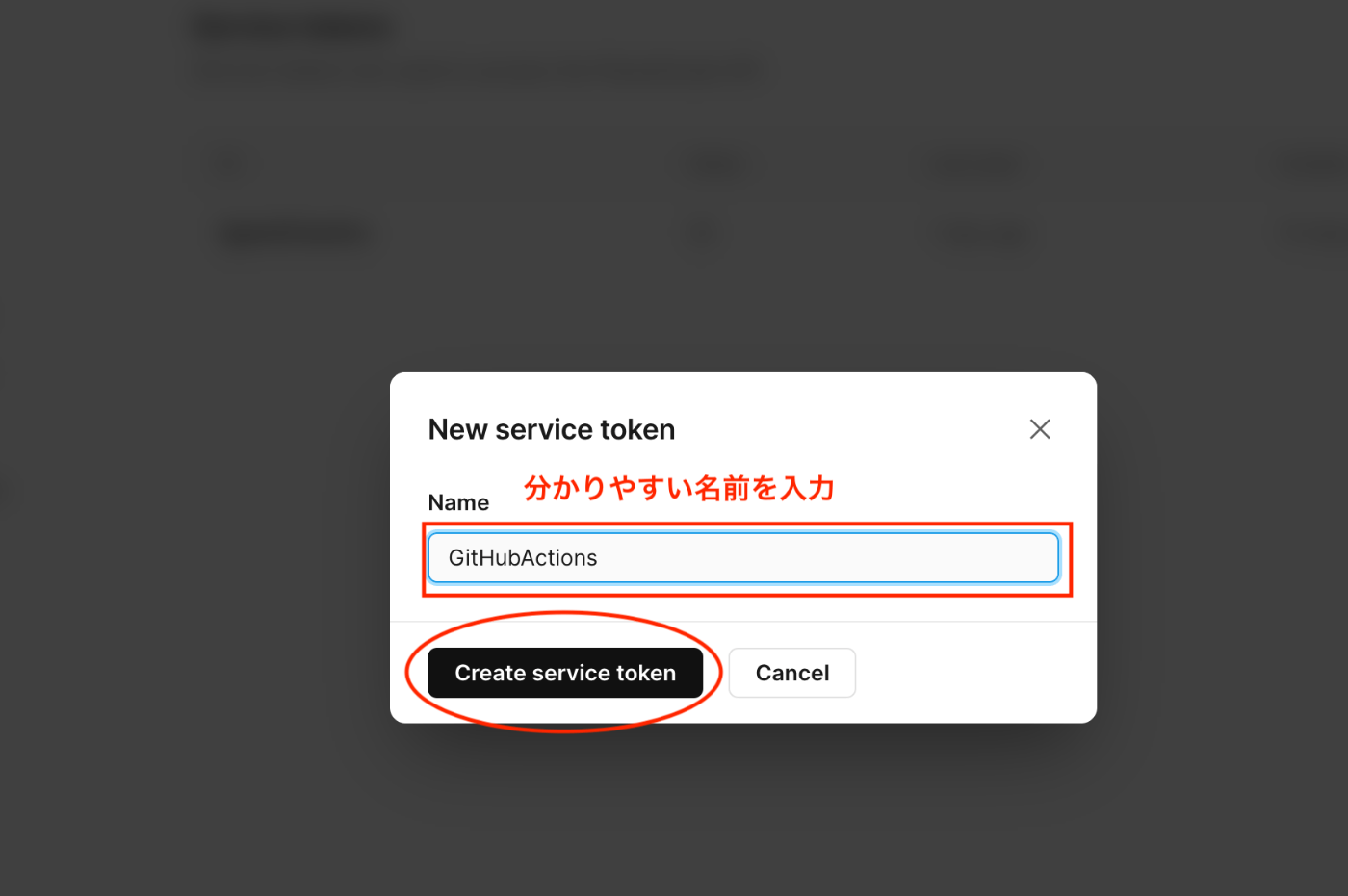
何でも良いですが自分的にはTokenの利用用途を名前にするのがわかりやすいと思います。
GitHubActionsで使うので「GitHubActions」としました。
「Create service token」を押下します。
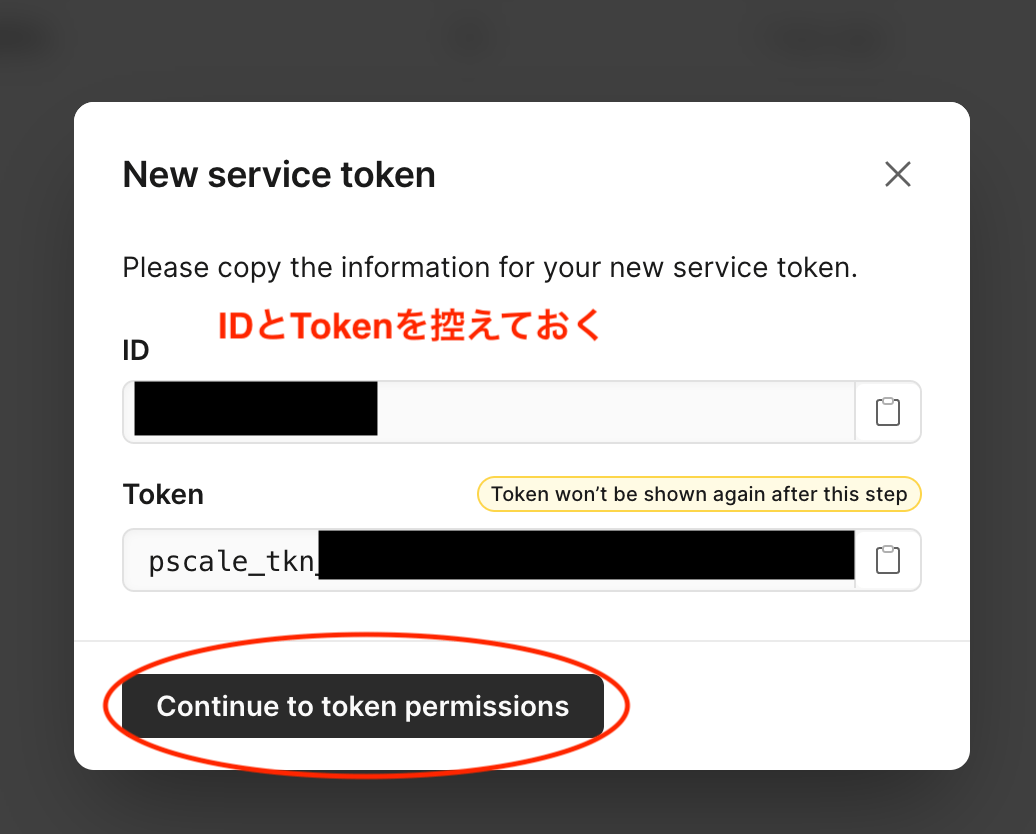
3. IDとTokenをメモしておく
IDとTokenをメモしておきます。これはあとで環境変数等に登録するために必要です。
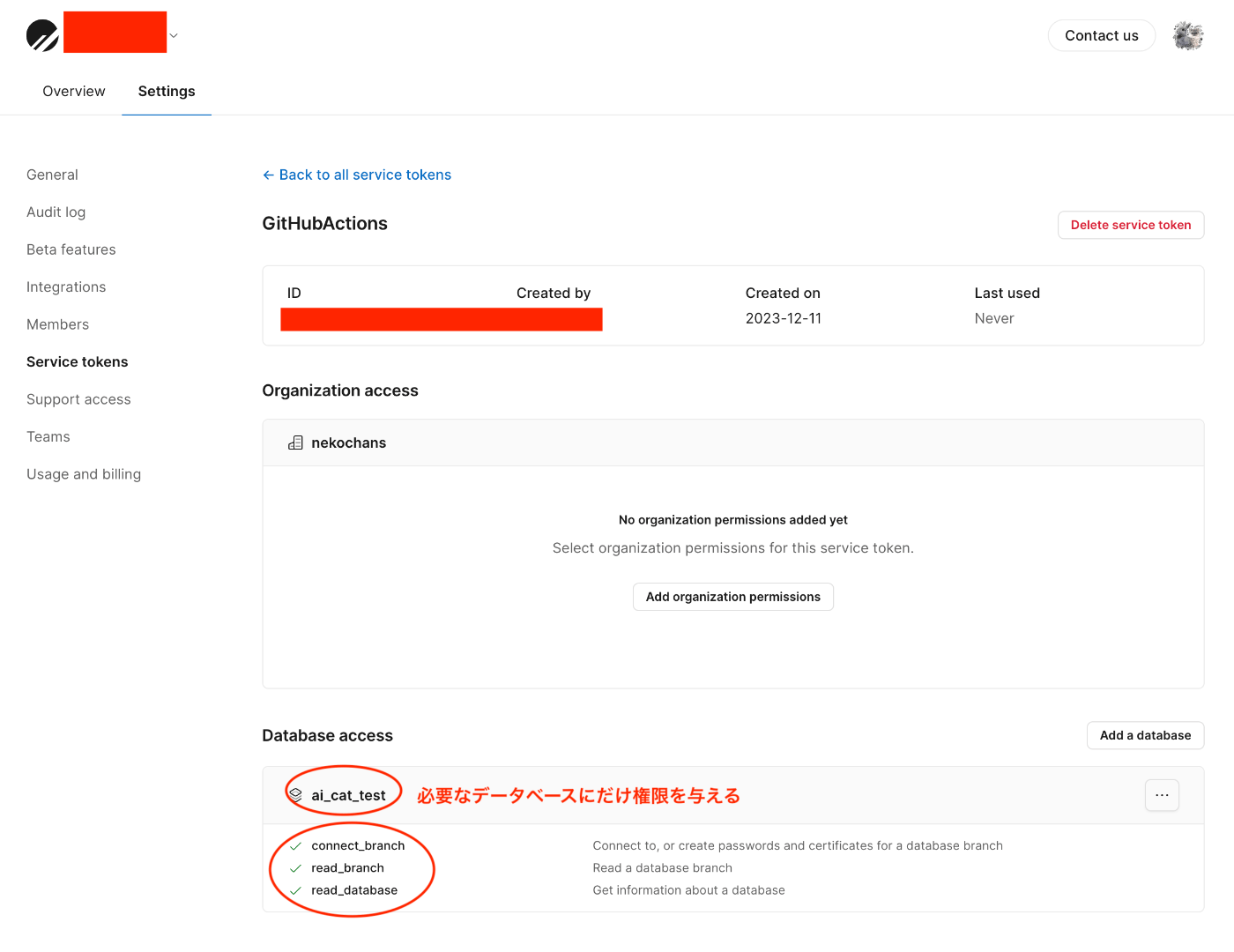
4. Service Tokenに権限を設定する
Get a branch schema のページを見ると以下の権限が必要と記載されています。
Service Token Accesses
read_branch, delete_branch, create_branch, connect_production_branch, connect_branch
しかし実際は connect_branch, read_branch, read_database の3つで大丈夫でした。
他のAPIも利用したい場合は権限の調整を行なう必要がありますが、どちらにせよセキュリティ面を考慮して必要最低限の権限に留めておくのが無難です。
以下のページに必要情報を入力すると接続用のcurlコマンドが生成されます。
以下の画像の赤で塗りつぶされた箇所を入力します。(AUTHORIZATIONの箇所はさきほど生成したIDとtokenを : で結合した値を入れます)
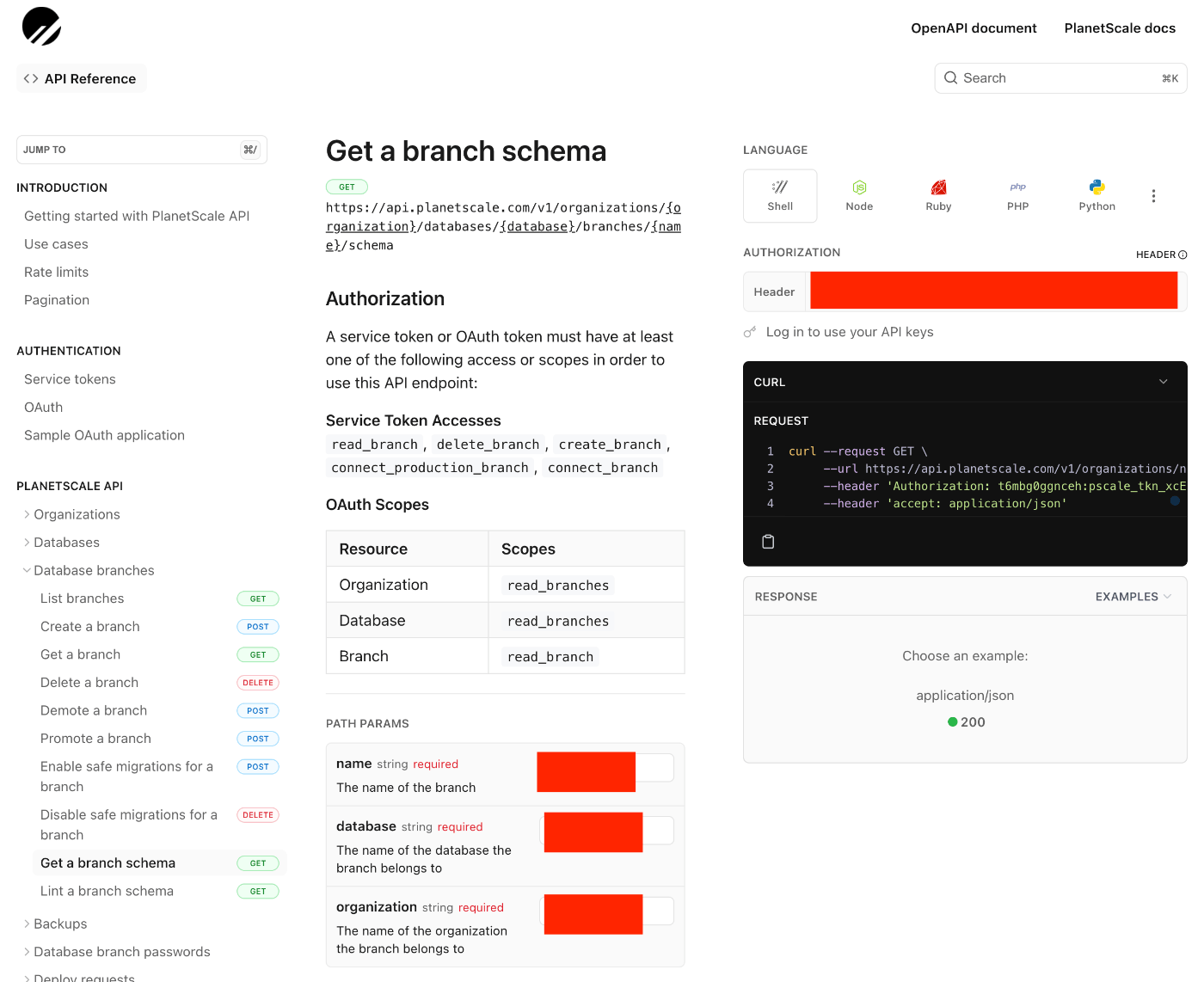
生成されたコマンドを使ってAPIからSchemaが取得できれば成功です。
以下は私の個人プロジェクトでのAPIの結果です。
raw にCREATE TABLEのSQLが入っているので、これを実行すればテスト用のデータベースに必要なテーブルを作れそうです。
{
"data": [
{
"name": "guest_users_conversation_histories",
"html": "<div class=\"line line-1\"><span class=\"k\">CREATE</span> <span class=\"k\">TABLE</span> <span class=\"nv\">`guest_users_conversation_histories`</span> <span class=\"p\">(</span></div><div class=\"line line-2\">\t<span class=\"nv\">`id`</span> <span class=\"nb\">bigint</span> <span class=\"nb\">unsigned</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"n\">AUTO_INCREMENT</span><span class=\"p\">,</span></div><div class=\"line line-3\">\t<span class=\"nv\">`conversation_id`</span> <span class=\"nb\">char</span><span class=\"p\">(</span><span class=\"mi\">36</span><span class=\"p\">)</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">COMMENT</span> <span class=\"s1\">'会話履歴ID'</span><span class=\"p\">,</span></div><div class=\"line line-4\">\t<span class=\"nv\">`cat_id`</span> <span class=\"nb\">varchar</span><span class=\"p\">(</span><span class=\"mi\">255</span><span class=\"p\">)</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">COMMENT</span> <span class=\"s1\">'ねこのID'</span><span class=\"p\">,</span></div><div class=\"line line-5\">\t<span class=\"nv\">`user_id`</span> <span class=\"nb\">char</span><span class=\"p\">(</span><span class=\"mi\">36</span><span class=\"p\">)</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">COMMENT</span> <span class=\"s1\">'ゲストユーザーのID、UUIDを生成してゲストユーザーIDとする'</span><span class=\"p\">,</span></div><div class=\"line line-6\">\t<span class=\"nv\">`user_message`</span> <span class=\"nb\">longtext</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">COMMENT</span> <span class=\"s1\">'ユーザーが送信したメッセージ'</span><span class=\"p\">,</span></div><div class=\"line line-7\">\t<span class=\"nv\">`ai_message`</span> <span class=\"nb\">longtext</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">COMMENT</span> <span class=\"s1\">'AIのレスポンスメッセージ'</span><span class=\"p\">,</span></div><div class=\"line line-8\">\t<span class=\"nv\">`created_at`</span> <span class=\"nb\">datetime</span><span class=\"p\">(</span><span class=\"mi\">6</span><span class=\"p\">)</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">DEFAULT</span> <span class=\"k\">current_timestamp</span><span class=\"p\">(</span><span class=\"mi\">6</span><span class=\"p\">),</span></div><div class=\"line line-9\">\t<span class=\"nv\">`updated_at`</span> <span class=\"nb\">datetime</span><span class=\"p\">(</span><span class=\"mi\">6</span><span class=\"p\">)</span> <span class=\"k\">NOT</span> <span class=\"k\">NULL</span> <span class=\"k\">DEFAULT</span> <span class=\"k\">current_timestamp</span><span class=\"p\">(</span><span class=\"mi\">6</span><span class=\"p\">)</span> <span class=\"k\">ON</span> <span class=\"k\">UPDATE</span> <span class=\"k\">current_timestamp</span><span class=\"p\">(</span><span class=\"mi\">6</span><span class=\"p\">),</span></div><div class=\"line line-10\">\t<span class=\"k\">PRIMARY</span> <span class=\"k\">KEY</span> <span class=\"p\">(</span><span class=\"nv\">`id`</span><span class=\"p\">),</span></div><div class=\"line line-11\">\t<span class=\"k\">KEY</span> <span class=\"nv\">`idx_guest_users_conversation_histories_01`</span> <span class=\"p\">(</span><span class=\"nv\">`conversation_id`</span><span class=\"p\">),</span></div><div class=\"line line-12\">\t<span class=\"k\">KEY</span> <span class=\"nv\">`idx_guest_users_conversation_histories_02`</span> <span class=\"p\">(</span><span class=\"nv\">`cat_id`</span><span class=\"p\">),</span></div><div class=\"line line-13\">\t<span class=\"k\">KEY</span> <span class=\"nv\">`idx_guest_users_conversation_histories_03`</span> <span class=\"p\">(</span><span class=\"nv\">`user_id`</span><span class=\"p\">)</span></div><div class=\"line line-14\"><span class=\"p\">)</span> <span class=\"n\">ENGINE</span> <span class=\"n\">InnoDB</span><span class=\"p\">,</span></div><div class=\"line line-15\"> <span class=\"n\">CHARSET</span> <span class=\"n\">utf8mb4</span><span class=\"p\">,</span></div><div class=\"line line-16\"> <span class=\"k\">COLLATE</span> <span class=\"n\">utf8mb4_bin</span><span class=\"p\">,</span></div><div class=\"line line-17\"> <span class=\"n\">ROW_FORMAT</span> <span class=\"k\">DYNAMIC</span><span class=\"p\">,</span></div><div class=\"line line-18\"> <span class=\"k\">COMMENT</span> <span class=\"s1\">'ゲストユーザー(未ログインユーザー)の会話履歴を保存する'</span><span class=\"p\">;</span></div>",
"raw": "CREATE TABLE `guest_users_conversation_histories` (\n\t`id` bigint unsigned NOT NULL AUTO_INCREMENT,\n\t`conversation_id` char(36) NOT NULL COMMENT '会話履歴ID',\n\t`cat_id` varchar(255) NOT NULL COMMENT 'ねこのID',\n\t`user_id` char(36) NOT NULL COMMENT 'ゲストユーザーのID、UUIDを生成してゲストユーザーIDとする',\n\t`user_message` longtext NOT NULL COMMENT 'ユーザーが送信したメッセージ',\n\t`ai_message` longtext NOT NULL COMMENT 'AIのレスポンスメッセージ',\n\t`created_at` datetime(6) NOT NULL DEFAULT current_timestamp(6),\n\t`updated_at` datetime(6) NOT NULL DEFAULT current_timestamp(6) ON UPDATE current_timestamp(6),\n\tPRIMARY KEY (`id`),\n\tKEY `idx_guest_users_conversation_histories_01` (`conversation_id`),\n\tKEY `idx_guest_users_conversation_histories_02` (`cat_id`),\n\tKEY `idx_guest_users_conversation_histories_03` (`user_id`)\n) ENGINE InnoDB,\n CHARSET utf8mb4,\n COLLATE utf8mb4_bin,\n ROW_FORMAT DYNAMIC,\n COMMENT 'ゲストユーザー(未ログインユーザー)の会話履歴を保存する';\n",
"annotated": false
}
]
}
PlanetScale APIからデータベースSchemaを取得する関数の実装
さきほどのAPIを使って以下の関数の実装を行ないました。
replace("\n", " ").replace("\t", " ") としているのは、APIのレスポンスの raw の中に含まれている \n, \t を消して実行可能なSQL文に変換するためです。
Schemaの取得はテスト実行時の1回だけ行なわれれば十分なので lru_cache を使って関数のレスポンスをcacheしています。
create_test_db_name 関数ではランダムな名前のテスト用のDBを作っています。この関数を各テストケースでコールします。
以下は私の個人プロジェクトでのテストケースの実装例です。
@pytest.fixture のなかで利用されている create_and_setup_db_connection 関数がテスト用のDBの作成とテストデータの初期化を実施しているので他のテストケースとデータが競合することはなくなります。
テストの高速化を実現
私の個人プロジェクトではテーブル数が少なく、テストケースも少ないので恩恵は少ないですが、同じ構成の実案件ではテストの実行時間が10分程度から2分程度には終わるようになりました。
テストケースごとに独立したDBが作られるのでCIが衝突する心配もなくなりました。
同じ構成の実案件ではテーブルの数もそれなりに多い(50個くらい)ですが問題なく動作しています。
テストを高速化してCIの待ち時間を減らし、デプロイ速度の低下を防ぐという目的は達成できました。
この方法の問題点
この方法は良い面だけではありません。以下のようなデメリットもあります。
1. テストが終わったあとでデータベースが残ってしまう
ローカルでテストを動かしているときの問題ですが、テスト実行が終了した後に以下のようにテスト用のDBが大量に残ってしまいます。
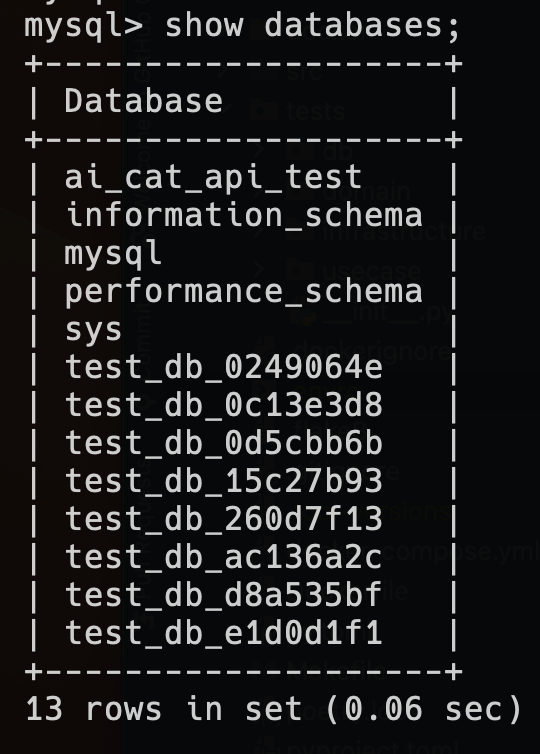
テスト終わったら削除すれば?と思うかもですが、以下の問題がありそのまま残すことにしました。
- データベースの削除自体にも時間がかかり、それを毎回やっているとテスト全体の実行時間が遅くなる
- テスト失敗時にテストデータの状態を見れなくなる
ちなみにGitHubActionsでは毎回新しいコンテナを作るので問題にはなりません。
ローカルでもコンテナの再構築を定期的にやり直すことで回避することにしました。
2. MySQLのコンテナとPlanetScaleは微妙に違う
PlanetScaleで SELECT VERSION(); を実行すると以下のような結果が得られます。
> SELECT VERSION();
+---------------+
| VERSION() |
+---------------+
| 8.0.34-Vitess |
+---------------+
MySQLコンテナのバージョンは同じく 8.0.34 に合わせていますが 8.0.34-Vitess と完全に同じではありません。
以前まではPlanetScaleのバージョンでテストを実行していたので本番でも同様に動く安心感がありましたが、今後はこの差異によって何か問題が起きる可能性がゼロではありません。
今のところ何も起きていないのと、テストの実行速度が遅いデメリットのほうが大きいので今のところはこのまま進めようと思います。
今後は実際のPlanetScaleに向けてテストを実行できるようなWorkflowを定期実行するか、E2Eテストなどを充実させる事でカバーしようと思います。
おわりに
以上がPlanetScale APIを使ったDBテストの高速化になります。
DBのテストは実行速度の問題がありますが、実データベースでテストをすることで動作確認が担保される安心感がありますので、DBのテストをMockで終わらせる事はしたくありませんでした。
今後もプロダクトの品質を維持するためにテスト周りの改善を続けていこうと思います。
以上になります。最後まで読んでいただきありがとうございました。
Discussion