論文紹介_検索補助型時系列拡散モデル(RATD)
前書き
ChatGPTの進化に日々怯えているAIエンジニアです。
AIに仕事を取られる前に逃げ切れるように、今年も必死に生きていきたいと思います。
今回は時系列予測の
Retrieval-Augmented Diffusion Models for Time Series Forecastingという論文が凄そうだったので読んでみたという感じの記事です。
有名な研究室の研究会でも取り上げられていたらしいです。
研究背景と事前知識
いきなり手法の説明に行く前に、背景や必要な前知識の説明をしていきます。
時系列データとその予測
時間の経過に応じて変化するデータのことを時系列データと言います。
身近な例では株価や天気などのデータがあります。
過去のデータが未来に強く影響を与える点は時系列データの大きな特徴です。
時系列予測では過去データから未来の予測を行うため、不確実性が大きく予測の難易度も高くなります。
予測対象が遠い未来になるほど、予測を当てるのが難しくなることは直感的にも理解できると思います。
時系列予測には様々なモデルがありますが、予測精度や計算コストなどに関する課題が残る分野となっています。
拡散モデル(Diffusion Model)
最近は(ChatGPTなど) 言語モデルの生成AIの発展がすごいですが、その前は画像の生成AIの発展が盛んでした。
で、その時にうまくいった手法として拡散モデル(Diffusion Model)というものがありました。
簡単に説明すると
- 画像を用意する
- 画像にノイズを段階的に加えていきノイズ少→ノイズ中→ノイズ大と変化させる
- ノイズが大きい状態から徐々にノイズを取り除くように、ノイズ大→ノイズ中→ノイズ少→元の画像(ノイズなし) に復元するように学習させる
こんな感じの手順です。
ノイズを取り除くことを学習することでノイズ部分と画像の本質的な部分の見極めができるようになるだろうというアイディアです。ノイズ除去を段階的に行うことで、生成プロセスが安定し、高品質な画像を生成できるようになります。
拡散モデルはGANなどの従来の生成モデルよりも安定しており、現在のStable Diffusionなどの画像生成AIにも採用されています。
既存の時系列拡散モデルの問題点
拡散モデルを時系列モデルに活用したものを時系列拡散モデル(Time Series Diffusion Model)と言います。
既存の時系列拡散モデルの予測が上手くいない理由として以下の問題点が挙げられます。
・情報の制約
画像の場合、これは"犬"の画像、これは"猫"の画像などのラベル付を行うことで画像データ以上の情報を人が付与することもできます。しかし、時系列データではそのようなラベル付が困難なので画像を処理する場合よりも、そもそも情報が少なくなってしまいます。
・データセットのサイズ不足
時系列データは画像データに比べてデータ数が少なくなる傾向があり、拡散モデルのような大規模な学習に必要なデータが足りません。
・データの不均衡性
特殊な例が少ないため、結果的に数の多い一般的な予測をする傾向があります。
この論文ではこれらの問題に対応するための手法として、検索補助型時系列拡散モデル(RATD) を提案しています。
検索拡張生成(Retrival-Augmented Generation)
生成モデルに外部の検索結果を取り入れることで、生成の質を向上させる手法として検索拡張生成(Retrieval-Augmented Generation, RAG) というものがあります。
主に自然言語処理の分野で使われていて、以下のような状況に適用されます。
・データ不足の補完
モデルが訓練データに基づいて十分に学習できない場合、検索エンジンやデータベースを用いて必要な外部情報を取り込む。
・最新情報の活用
訓練済みモデルが持たない、最新のデータやコンテキストを利用してより正確で時事的な応答を生成する。
具体例としては、質問応答システムや対話型AIで、ユーザーの質問に対して内部モデルだけではなく外部の情報源を検索して、その結果をもとに答えるものが挙げられます。
RAGは主に生成プロセスで外部情報を活用する手法です。一方、この論文の手法(RATD)は、検索結果を学習プロセスに取り入れる点で異なります。しかし、検索を活用して生成の精度を上げるという考え方は共通しています。
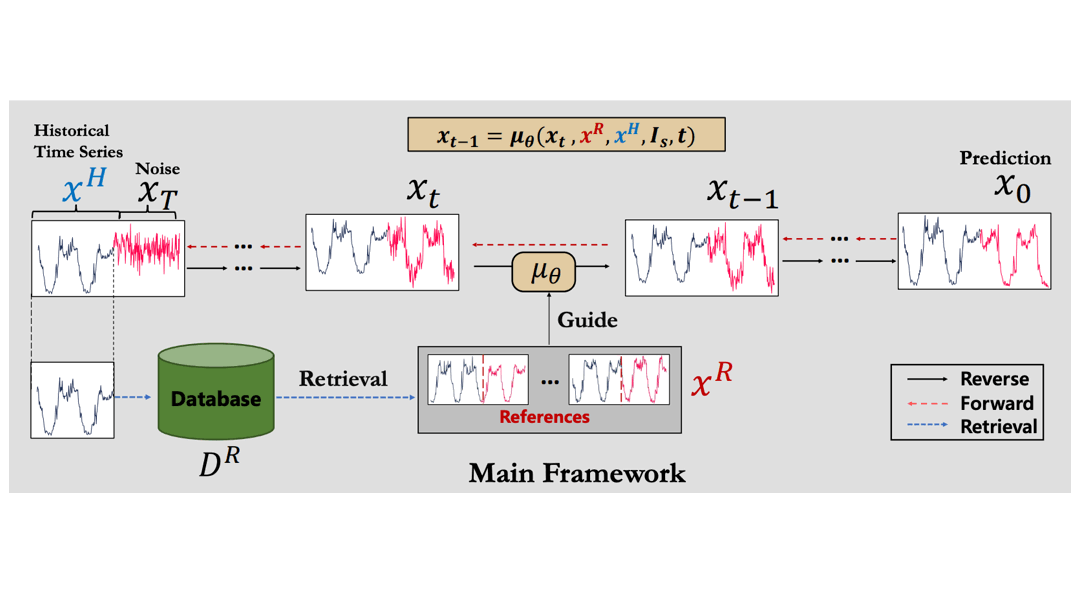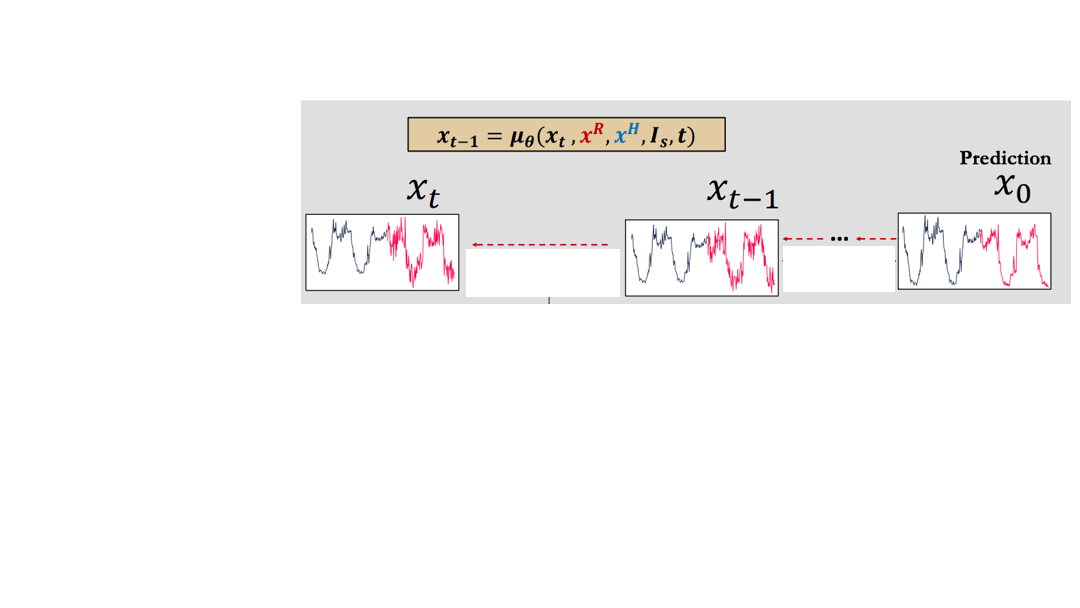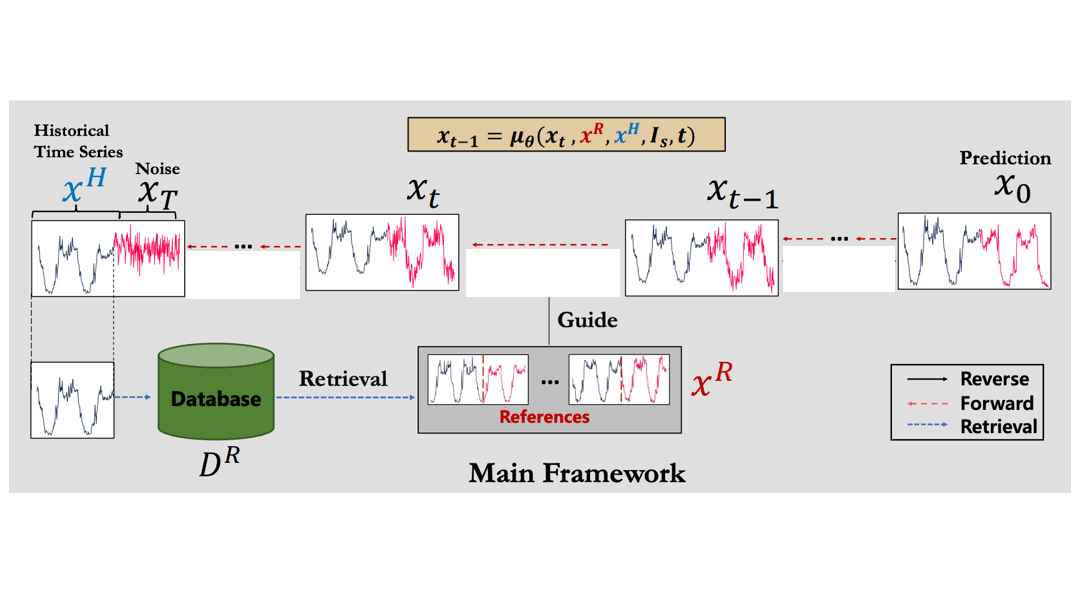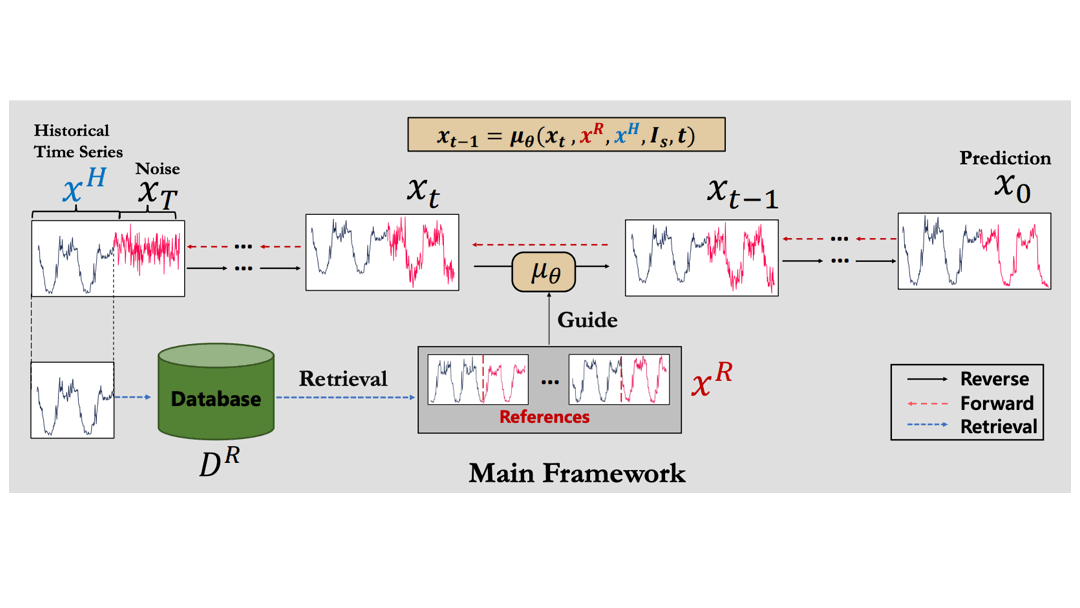
検索補助型時系列拡散モデル(RATD)
この論文では検索補助型時系列拡散モデル(Retrieval-Augmented Time series Diffusion Model, RATD)という手法を提案しています。
手法のアイディアは、時系列拡散モデルの学習時に検索結果を補助情報として活用することです。
全体の流れ
論文にある図をアニメーションにしてみます。
まず時系列データを学習期間
予測期間
学習期間
検索結果
この流れで学習を進めることで、DBにある他の時系列データを有効に活用しながらモデルを学習できるようになります。
実験と結果
為替レート(Exchange), 風量発電(Wind), 電力消費(Electricity), 気象指標(Weather)の4つのデータセットを使用した実験の結果を載せておきます。
学習期間のデータ数を168, 予測期間は96, 192, 336の3パターンで試して平均した結果を最終的な評価値にしています。
平均二乗誤差(MSE), 平均平均誤差(MAE), 連続ランク付け確率スコア(CRPS)を使用して評価しています。
(どの指標も小さいほど結果が良いことになりますが、相対指数のためこの値だから精度が良いと判断できるものではありません。)
結果の表を見ると、
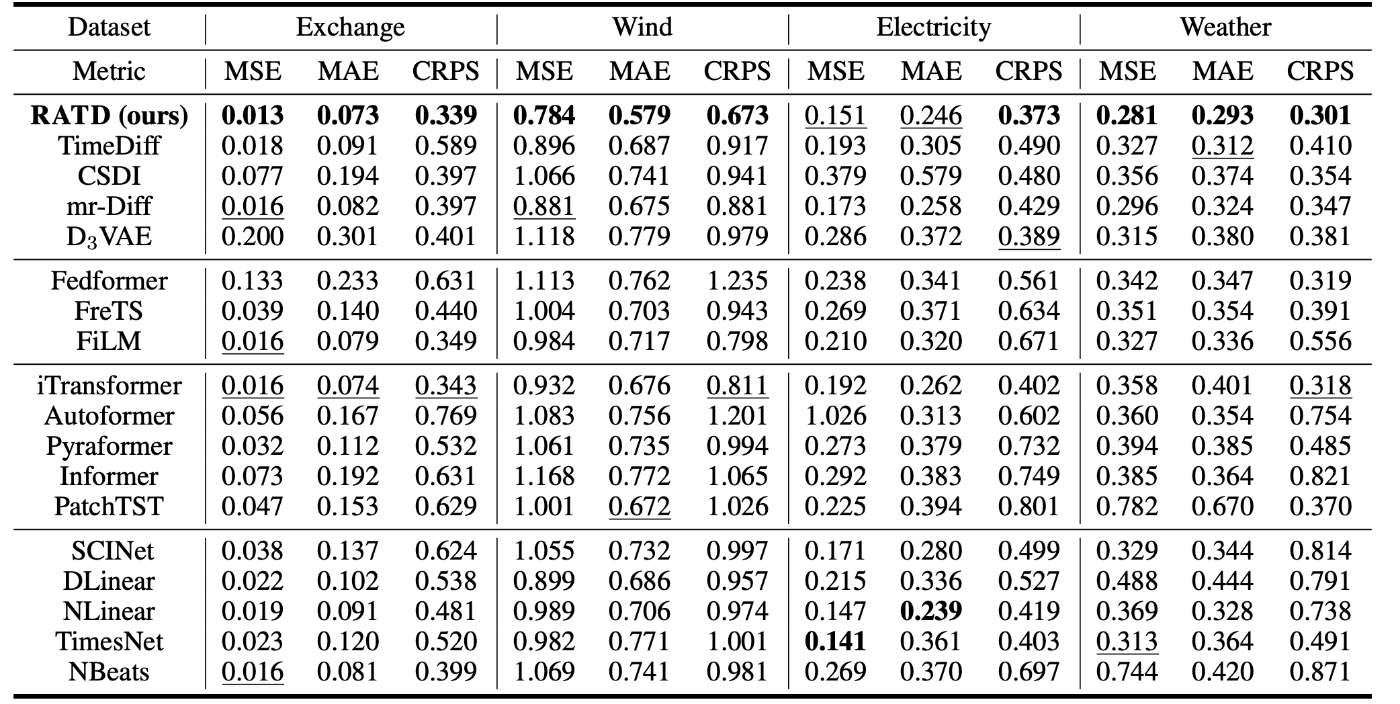
となっており、4つのデータセットのうち3つのデータセット(為替レート(Exchange), 風量発電(Wind), 気象指標(Weather))では値が最も小さくなっていることがわかります。
電力消費(Electricity)の平均二乗誤差(MSE), 平均平均誤差(MAE)の結果は最小ではないですが、最も良い手法の結果と近い値になっていることがわかります。
最も優れた結果となった風量発電(Wind)から代表的な結果を見てみると、

となっており、検索補助型時系列拡散モデル(RATD)の予測結果が長期的に優れていることがわかります。
参考_検索のやり方による結果の違い
検索補助型時系列拡散モデル(RATD)では学習時に似ているデータをデータベース
論文でもベースラインとして2種類(検索無し, ランダム検索)と相関ベースの検索として2種類(DTW, Pearson)と埋め込みベースの検索として4種類(DLinear, Informer, TimesNet, TCN)試しています。
結果は

となっています。
計算コストと精度のバランスを考慮するとTCN(時系列データを処理するために畳み込みニューラルネットワーク(CNN)を応用した手法)を利用した検索が最も優れていると著者らは述べています。
所感
あくまでDBにある他の時系列データを学習時に利用する手法なので、コロナ前の時(DBにそもそもデータがない場合)にコロナ後の予測ができるような魔法の方法ではありません。しかし、過去データが少ない場合の予測精度を上げるための手法として有効だと思いました。
検索に使用する過去データの数によっても結果は変わると思うので実用化にはその辺も含めて考える必要がありそうです。
類似度の高いデータを学習に使用するアイディアは以前試して失敗したのでいつかリベンジしたいです。
参考
・論文
・紹介記事
Discussion