全文検索エンジン Solr と Elasticsearch
全文検索エンジンとは
逐次方式と索引方式
全文検索エンジンを理解するためには、まず検索方法に大きく2種類あることを理解しなければなりません。
それが、「逐次方式」と「索引方式」です。この「逐次方式」とは、キーワードで検索などを行うときにDBを上から順に全て見ていき、該当のキーワードを探す方式のことです。これは、シンプルで想像がしやすい方法ではないでしょうか。しかし、この方法では検索するDBが大量にある場合、検索するたびにDBへの負荷がかかるのと検索結果を返すまでに時間がかかってしまうという課題が存在します。
これに対して、「索引方式」とは、DBの構築段階でキーワードごとに対象ドキュメントの表のようなものを作成しておき、検索時にそのキーワードと対象ドキュメントがついになっている表を使用する検索方式のことです。この表のようにキーワードと対象ドキュメントをついにさせることを転置インデックスといい、これにより高速に検索を行えるようになります。しかし、この「索引方式」を実装するには、通常のDBとプラスで転置インデックスを実装したDBが必要になるというデメリットも存在します。
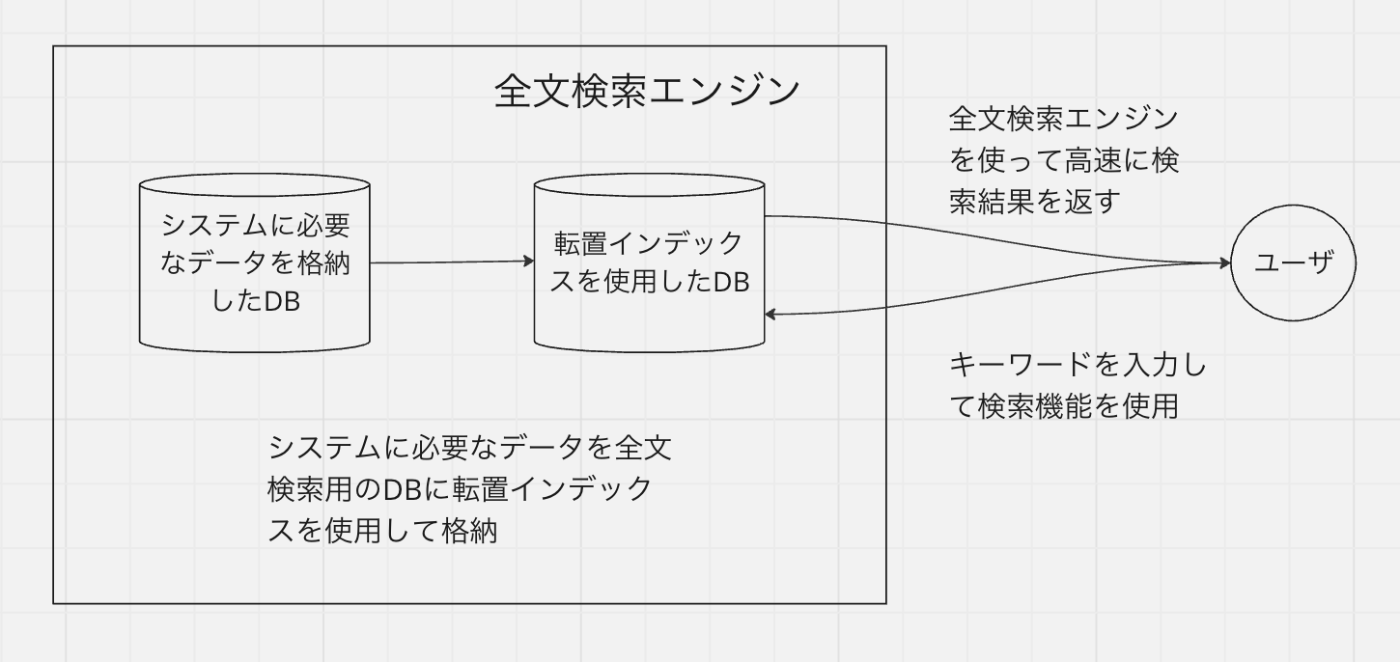
全文検索エンジンまとめ
ここでは、上記で見てきた全文検索エンジンについて軽くまとめます。
全文検索とは、構造化されていないテキストから、検索したいキーワードに合致する箇所を全て見つけ出すことを言います。また、事前に索引を構築して全文検索を実現するソフトウェアのことを全文検索エンジンと呼びます。そして、この全文検索エンジンでは索引を構築する際に転置インデックスという技術を使用して高速に検索結果を返すことを可能にしています。
全文検索エンジンの代表例
SolrとElasticsearchについて
・共通点
まずは、SolrとElasticsearchの共通点について説明します。
大きく二つの共通点があります。一つ目が、どちらもJavaで書かれたソフトウェアという点です。
Javaは、高い処理能力と豊富なライブラリから大規模開発に向いている言語なので、全文検索エンジンのように処理のスピードと大量のデータを捌く必要がある大規模なソフトウェア開発に向いています。
二つ目の共通点が、どちらもApache Luceneというライブラリを使用している点です。このApache Luceneというライブラリは、オープンソースのデータ検索エンジンのライブラリです。長年にわたり開発されてきたオープンソースでより強力な機能と洗練されたアーキテクチャが特徴です。
・Solrの特徴
検索パラメータにクエリパラメータを使用しているので、Elasticsearchの検索パラメータであるクエリDSLよりも直感的に検索を行えます。また、ハイライト検索やファセット検索などの便利な機能が実装されており、Elasticsearchに比べて学習コストがかからない点も特徴と言えます。
・Elasticsearchの特徴
こちらは、先ほど少し説明にあがったクエリDSLというJSON形式の検索パラメータを使用しており、やや学習コストがかかります。しかし、慣れればSolrに比べて複雑な検索を効率的に実行できるなど、柔軟性に富んでいるのが特徴です。
検索パラメータの違い
ここでは、上記で少し説明があったSolrとElasticsearchの検索パラメータの違いについて深ぼっていきます。
Solrのクエリパラメータ
Solrで使用されているクエリパラメータは検索したい内容を指定するためのシンプルなパラメータになります。
基本的な使い方が下記のようなものになります。
・キーワード検索
「q=apple」というクエリパラメータを指定することでappleを含むドキュメントを検索します。
・フィールド指定検索
「q=title:apple」というクエリパラメータを指定することでtitleというフィールドにappleを含むドキュメントを検索します。
・ブースト機能
「q=title:apple^2 OR content:fruit」というクエリパラメータを指定することでtitleフィールドにappleを含むドキュメントのスコアを2倍にして、検索結果の優先順位を高める方法です。
・フィルタリング
「fq=price:[10 TO 20]」というクエリパラメータを指定することで価格が10から20の範囲にあるドキュメントをフィルタリングします。fq(フィルタクエリ)は、検索結果から条件を絞り込む際に使用します。
ElasticsearchのクエリDSL
ElasticsearchのQuery DSLは、より柔軟で強力なクエリを作成するためのJSON形式のドメイン固有言語です。これにより、複雑な検索要件やフィルタリング、集計などを行うことができます。
基本的な使い方が下記のようになっています。
・キーワード検索
{
"query": {
"match": {
"content": "apple"
}
}
}
これは、contentフィールドにappleを含むドキュメントを返します。
・複合クエリの使用
{
"query": {
"bool": {
"must": [
{ "match": { "title": "apple" } },
{ "match": { "content": "fruit" } }
],
"should": [
{ "match": { "author": "John" } }
],
"filter": [
{ "range": { "price": { "gte": 10, "lte": 20 } } }
]
}
}
}
これは、mustで指定されたクエリは必須条件であり、titleが「apple」で、contentが「fruit」であるドキュメントを検索します。そして、shouldで指定された条件は、満たされるとスコアが上がります。この場合、authorが「John」である場合、優先度が上がります。さらに、filterで指定された条件はスコアに影響を与えず、結果をフィルタリングします。この例では、価格が10から20の範囲にあるドキュメントをフィルタリングします。
このように複数のクエリを複合的に使用して複雑な検索を行えるのがElasticsearchの最大の特徴です。
SolrとElasticsearchの少し実践的な使い方
Solr
eコマースサイトで、ユーザーが「iPhone」というキーワードを検索し、結果を価格の昇順で並べ替え、かつ在庫がある商品のみを表示する場合、次のようなクエリを送ります。
q=title:iPhone AND is_stock:true&sort=price asc
Elasticsaerch
ブログ記事の検索で、特定の著者による、特定のキーワードを含む記事を検索し、記事の長さが1000文字以上のものに絞り込み、かつ投稿日順に並び替えたい場合、次のようなクエリを送ります。
{
"query":{
"bool":{
"must":[
{"match":{"author": "Jane Doe"}},
{"match":{"content": "machine learning"}}
],
"filter":[
{ "range": { "length": { "gte": 1000 } } }
],
}
},
"sort":{
{ "publish_date": { "order": "desc" } }
}
}
Discussion