転置インデックスを使った全文検索エンジンの仕組み
はじめに
この記事では、全文検索エンジンの仕組みについて少し詳しく説明していきたいと思います。
特に、全文検索エンジンのデータ構造として広く使われている転置インデックスを利用した検索の大まかなフローを見ていきます。
現在は、優れたAPIを備えた全文検索エンジンが登場しており、全文検索エンジンの裏側や仕組みを理解していなくても利用したり、導入したりすることが可能になりました。しかし、全文検索エンジンの仕組みを詳しく理解することで、検索結果を細かくコントロールすることができるようになります。
それでは、見ていきましょう!
転置インデックスの概要
逐次方式と索引方式
まず、検索方式には2種類あります。それが、「逐次方式」と「索引方式」です。
この逐次方式は、キーワードに合致する箇所を上から順に全て見ていく検索方式です。これは、シンプルでかつわかりやすい検索方式だと思います。しかし、欠点があります。それは、検索範囲が大規模になったときに検索時間がかかりすぎてしまうということです。
そこで、この欠点を解決するのが索引方式です。この索引方式のイメージは、辞書の索引を考えてもらえればいいかなと思います。辞書の索引では、調べてたいキーワードを索引で調べて、そのキーワードが何ページ目にあるかを知ることができます。このように索引方式を検索エンジンで実装するためのデータ構造として考えられたのが転置インデックスになります。
転置インデックスのデータ構造イメージ
ここでは、四つのドキュメント(Doc1 ~ Doc4)から実際に転置インデックスを作ってみます。
①AmazonはECサイトとして設立され、オンラインショッピングを革新しました。
②ECサイトの中でも、Amazonはオンラインショッピングのリーダーです。
③クラウドの市場で、Amazonは主要なプレーヤーです。
④AIはECサイトで重要で、Amazonはこれを活用しています。
上記四つのドキュメンに含まれるキーワードをもとに表を作成すると下記のようになります。
| キーワード | ドキュメント1 | ドキュメント2 | ドキュメント3 | ドキュメント4 |
|---|---|---|---|---|
| Amazon | ✓ | ✓ | ✓ | ✓ |
| ECサイト | ✓ | ✓ | ✓ | |
| オンラインショッピング | ✓ | ✓ | ||
| クラウド | ✓ | |||
| AI | ✓ |
このようにどのキーワードがどのドキュメントに含まれているのかを表したデータ構造を転置インデックスといい、このデータ構造を元に検索機能を実装する方法を索引方式といいます。
しかし、上記の表では、わかりやすくするためにキーワードとして検索されそうなもののみをピックアップしました。本来、①の「革新」や接続後なども表のようにしなければ全てのドキュメントから検索したことにはなりません。
でも、そのようにしてしまうと大規模な検索範囲のあるシステムでは、大部分がどの一つのドキュメントにしか含まれないようなキーワードだらけになってしまいメモリ効率が非常に悪くなります。
そこで、より実用的な転置インデックスではターム辞書とポスティングリストと呼ばれる二つのデータ構造によって作成されています。次の章で詳しくみていきましょう。
実用的な転置インデックス
ターム辞書とポスティングリスト
まず、ターム辞書について説明します。このターム辞書とは、「転置インデックスを検索するときの最小単位」のことを示します。もう一方のポスティングリストは、それぞれのタームが出現するドキュメントの識別子を格納するリストになります。
ターム辞書中のそれぞれのタームから、ポスティングリストのドキュメントIDを参照できるようにしたものが、実用的な転置インデックスのデータ構造だといえます。
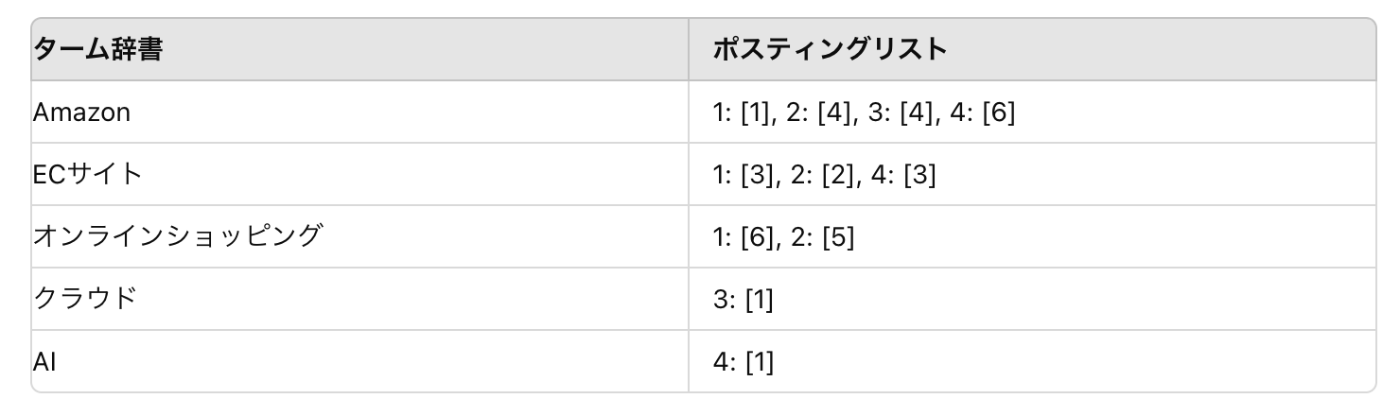
このようにターム辞書とポスティングリストのように二つのデータ構造にすることで、例えばターム辞書に存在しないドキュメントを保持する必要がなくなったり、そもそもタームを必要最低限にしたりして、メモリ効率を引き上げたのが、今回の実用的な転置インデックスの例です。
転置インデックスを使用した検索フロー
ここでは、実際に転置インデックスを使用した検索フローについて見ていきます。一般的に下記のようなフローが多いです。
①ユーザが入力した文字列をタームに分解する(テキスト解析)
②ターム辞書を引き、該当のポスティングリストを探す(辞書引き)
③ポスティングリストを先頭から走査してマージする(ポスティングリスト走査)
④見つかった検索結果をランキングして返す(ランキング)
それでは、一つずつ、詳しく見ていきましょう!
①テキスト解析
まず、このテキスト解析のフローでは、ユーザからの入力(検索クエリ)をタームに分解します。
具体的には、ユーザが「web検索エンジンの仕組み」という入力をしたとします。ここで、この検索クエリをどの大きさで分解するかを考えるのがテキスト解析のフローで行うことです。これは、実運用にあたって一番難しいことの一つになります。というのも、ターム辞書に「web」という範囲でインデックスされているとして、先ほどの検索クエリを「web検索」という範囲でタームに分解したら検索はヒットしません。
このように、そもそもターム辞書にどの範囲でインデックスするのか、検索クエリをどの範囲で分解するのかは運用の目的に応じて変わるところなので、慎重に決めていくのが良いでしょう。
②辞書引き
このフローでは、入力された検索クエリに含まれるすべてのタームについてターム辞書を引き、そのタームに対応するポスティングリストのエントリ(入口)を見つけます。このポスティングリストのエントリを元に③のフローを実行します。また、この辞書引きの際に使うアルゴリズムはいくつかありますが、一般的なところだと二分探索が使われることが多いです。
③ポスティングリスト走査
②の辞書引きが終わって、検索対象のポスティングリストのエントリを得られたら、次はそのエントリを元に実際にポシティングリストの中身を頭から順に検索していきます。そして一般には複数のタームに対応した複数のポスティングリストが得られるので、それらを AND や OR で マージした結果を返します。
④ランキング
③までのフローで、どのポスティングリストに該当の検索クエリが含まれるかがわかったので、最後にその検索結果にランキングをつけていきます。全文検索の対象となるドキュメントが膨大になると、ポスティングリスト走査で得られた結果をそのまま返しても、ユーザーにとってあまり意味がない検索結果になることが多くなります。そこで、検索クエリとドキュメントの類似度を計算することにより、検索結果を適切な順番にソートする必要が生じます。このランキングには、タームが個々のドキュメントに出現する回数や、個々のタームが検索対象のドキュメント全体でどれくらいの出現頻度があるかといった情報を利用します。
このようなフローで転置インデックスを使用した検索が行われます。
以降では、各フローについてさらに詳しく見ていきます。専門用語や難しい詳細などにも触れていくので、検索システムの概要が知りたかったという方はここで終わりでもいいかもしれません。
テキスト解析
まずは、ここまでのおさらいをしましょう。転置インデックスを用いた検索では、検索対象となる単語が「ターム辞書」に登録されています。そして、その検索対象となる単語がどのドキュメントに含まれているのかを「ポスティングリスト」に登録しています。これによって、ユーザが入力した検索クエリに含まれる単語がどのドキュメントに含まれているのかを全て見つけ出すことができ、それらをマージして、ランキングをつけるというのがここまでの流れでした。
ここまでの説明では、「ターム辞書」がすでに用意されている前提で話を進めていました。しかし、検索システムにおいてどのようなデータをタームとして扱うか、それをドキュメントや検索クエリからどうどうやって抽出するかは、難しい課題です。これが、一般的にテキスト解析と呼ばれる作業になります。
トークン
具体的なテキスト解析の処理を見ていく前にトークン化について説明します。
転置インデックスの説明では、検索対象となる単語などを「ターム」と呼んでいました。転置インデックスにはタームが登録されていることからわかるように、ユーザーが検索クエリに入力した単語などは、タームとして一致しているかどうかを基準として検索が実行されます。
一方、ドキュメントや検索クエリには、転置インデックスに登録されたタームと同じ形で単語などが出現しているとは限りません。たとえば、英語では文頭の単語で先頭を大文字にしますが、転置インデックスで同じ単語を先頭が大文字か小文字かで別々に登録すれば、ユーザーの検索意図に合わない結果しか得られないと考えられます。
そこで一般に、ドキュメントや検索クエリに出現する単語などのことは、タームとは区別してトークンと呼びます。このトークンをどのように抽出するかが肝になってきます。一般的には、単語のクセを排除していくようにします。例えば、「〇〇さんは、走ってきた」というドキュメントがあったとして、このドキュメンのトークンを「〇〇さん」、「走ってきた」としてしまうと、ほとんどのターム辞書ではヒットしません。なので、このような場合は、できるだけ単語のクセを無くすようにして、「〇〇」、「走る」のようなトークンにするのが、ベターと言えます。
このように、単語のクセを排除して、ターム辞書とのマッチ率を上げるような作業のことをステミングと呼びます。ステミングのためのアルゴリズムはかず多くあるので、目的に応じて適切なものを選ぶようにしましょう。
形態素解析を用いたテキスト解析
形態素解析とは、文章を単語に分割する際に内包している辞書を用いて「入力された文章を区切ることができる可能性」のパターンを洗い出し、それらのうち最もらしい単語列を出力するというものです。
これによって、出力された単語列をトークンとして扱ってもいいのですが、ここから「品詞」「読み」「活用形」などを元に正規化を行うことでさらにトークンとしての精度をあげます。
文字N-Gramを用いたテキスト解析
形態素解析によるテキスト解析では、使われる辞書の単語数や種類によってうまくトークン化されなかったり、長いトークンの一部の文字列で検索したい場合に不向きであるというデメリットがあります。
このような、デメリットを補うのが文字N-Gramを用いたテキスト解析です。この文字N-Gramは、入力された文章をN文字ずつに切り出して、トークンとして出力するというものです。
例えば、N=2の時に「明日も頑張りましょう」という文章が入力された場合は、下記のようなトークンが出力されます。「明日」、「日も」、「も頑」、「頑張」、「張り」、「りま」、「まし」、「しょ」、「ょう」。
一般的なテキスト解析では、上記の二つの方法をうまく合わせて行うのがメジャーなやり方です。形態素解析のメリットが行かせる時は、形態素解析を扱い、文字N-Gramの方がベターな場合は、文字N-Gramを使うといった感じです。
下記の参考書を元に今回の記事を書いたので、さらに詳しく学びたいという方は、下記をポチってみて下さい!
Discussion