インデックスのことがよくわからないのでRailsとMySQLで計測してみた
はじめに
この記事ではデータベースにおけるインデックスについて初心者向けにできる限りわかりやすく解説を行うことを目的とします。
私自身インデックスについての知識は非常に曖昧でしたが、
インデックスの仕組みを調べたのちに、実際に計測を行うことでインデックスの有効性を実感することができたので、その内容をシェアできればと思い記事にまとめます。
想定する読者
下記のようなことがあてはまる方
- インデックスってそもそもなに?
- とりあえずインデックスを作っておけばデータの出力が早くなると思っている
- インデックスを意識したことがない
※コード例については Ruby で解説を行います。
そもそもインデックスって?
インデックス=索引です。
そのままですね。
たとえば Ruby の本を購入して sort メソッドについて調べたいとします。
もし索引がなければ本の 1 ページ目から順番にめくっていき sort メソッドの説明が載っているページを探す必要があります。
しかし索引のページで sort という文字を探すと何ページ目に掲載されているか知ることができます。
もしその本が数百ページに及び後半に sort メソッドが載っていればその分だけページを捲る必要がありますが、索引から探すことで数ページ探すだけで sort メソッドのページに辿り着くことができるのです。
データベースにおけるインデックスも本の場合と同様です。
例えば、名前が「太郎」というユーザーを探したいときにインデックスがない場合は全てのデータにアクセスして 1 行ずつチェックしていく(フルスキャン)ことになりますが、name カラムにインデックスを作っておくことで高速にデータを出力することができます。
インデックスの仕組み〜B-tree インデックスとは〜
一口にインデックスと言ってもいくつかの種類がありますが、ここでは最もポピュラーなインデックスである B-tree インデックスについての解説を行います。
実際に頻繁に利用するインデックスは B-tree インデックスですが、それ以外のインデックスについても知りたい場合はビットマップインデックスやハッシュインデックスで調べてみてください(本記事では取り上げません。)。
また余談ですが、MySQL の場合下記のコマンドで作成されている index を確認することができます。
この例では users テーブルの id カラムに B-tree のインデックスが作成されていることがわかります。
show index from テーブル名;
// 実行結果
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| users | 0 | PRIMARY | 1 | id | A | 1| NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
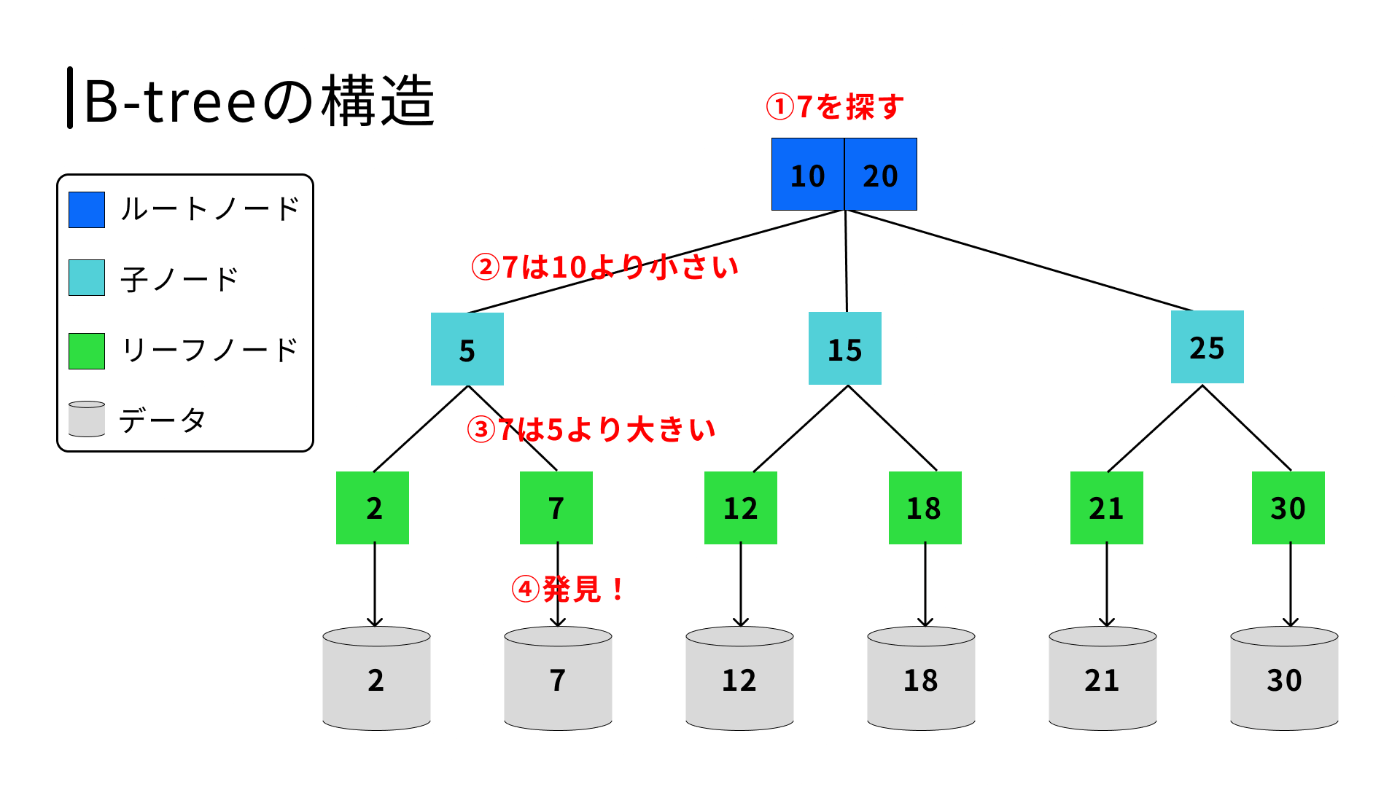
B-tree の構造
B-tree は名前の通り木構造になっており、ルートノード・子ノード・リーフノードから構成されます。
各ノードは子ノードへのポインタを持っているので下記手順を踏むことで目的のデータへのポインタまたは目的の値がないことがわかります。
- ルートノードから検索値を探す
- 検索値よりも大きなポインタを見つけた時点で直前のポインタを辿る
- 1 と2の手順を繰り返しリーフノードに辿り着く
B-tree の特徴
B-tree は以下の特徴を持っており、高速にかつ持続的に目的のデータを取り出すことが可能です。
-
均一性
B-tree はどのような値を選択したとしても、同じぐらいの速度で結果を得ることができます。
それは B-tree が平衡木という特徴をもっているためです。
平衡木とはルートから各リーフノードまでの距離が一定である木構造のことです。
常にリーフノードまでの距離が一定であるため、どの値をとっても同じ計算量で結果を出すことができます。 -
持続性
一つ目の特徴で挙げた平衡木ですが、データの追加や削除が行われる中で徐々に完全な平衡木ではなくなっていきます。
そのためデータが増えるにつれて処理時間は徐々に増加していってしまうのですが、その増加量が非常に緩やかなため B-tree は持続性に優れていると言えます。
処理時間の増加に関してオーダー記法で表すと、フルスキャンが O(n)であるのに対して B-tree は O(log n)になります。
よりわかりやすく図にすると以下のようになります。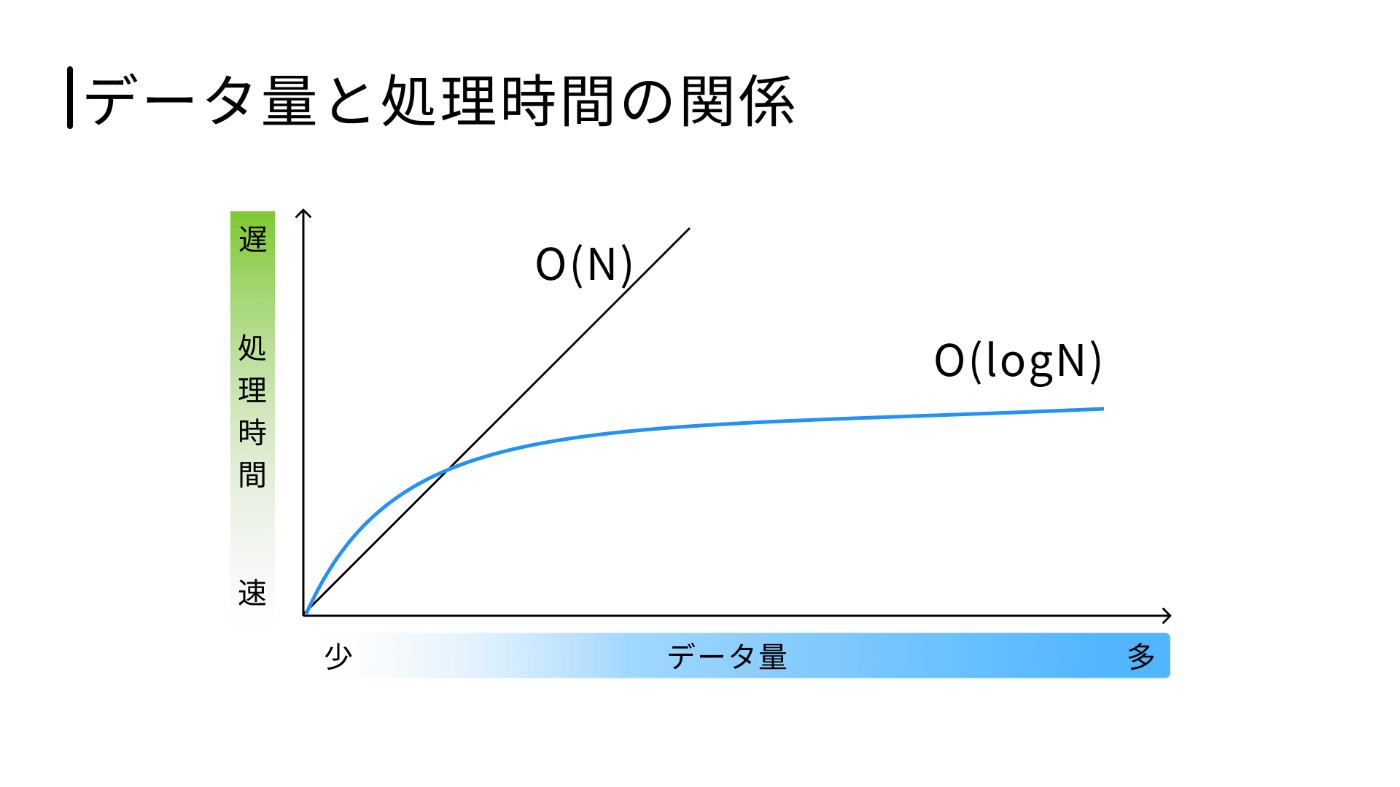
なぜこのようになるかというと B-tree の高さは平均 3〜5 程度になり、非常に平たい構造になっているためです。
(なんと 1 億レコードのデータを投入しても高さは 4 にしかならないらしい。) -
処理汎用性
B-tree はデータ検索の計算量が O(log n)であるのと同様に、データの追加・削除・更新も O(log n)の計算量で行うことができます。
そのためデータ量が増えた場合の、データ更新にかかる処理時間も緩やかにしか劣化しません。 -
非等値性
B-tree では等号による検索のみならず不等号や範囲検索に対しても高速な処理を行うことができます。
一方で否定条件に関しては、特定のノード以外のすべてのノードが該当してしまうため絞り込みが効かず効果はありません。 -
親ソート性
SQL は ORDER BY 句で明示的にソートする場合以外にも、集約関数(COUNT, SUM, AVG, MAX, MIN)や集合演算(UNION, INTERSECT, EXCEPT)を使うと暗黙的にソートが行われています。
このソート処理はコストの高い演算となっており、パフォーマンス上は避けた方が良いものとなっています。
B-tree インデックスではインデックスの構築時にキー値をソートして保持します。
そのためインデックスが存在する列をソートの対象として指定した場合、そのソート処理をスキップすることができます。
インデックスの注意点
ここまでインデックスの利点を説明してきましたが、もちろんすべてのテーブルすべてのカラムにインデックスを作ったからと言って有効なわけではなく注意点がいくつかあります。
-
大規模なテーブルに対してインデックスを作成する
先ほど出したデータ量に対する計算量の図ですが、データ量が少ない場合はフルスキャンの方がパフォーマンスが優れています。
データ量が少なく、今後も増える見込みのないテーブルに対してはインデックスを作る必要はありません。
なおその目安となるのは最近のハードウェアの性能から 1 万件程度が境界となるようです。 -
カーディナリティの高いカラムにインデックスを作成する
カーディナリティとはそのカラムに格納されるデータがどれぐらい種類を持つかということを表す数値です。
例えば users テーブルに 10 万件データが登録された場合、同姓同名の人がいることを想定しても name カラムはのカーディナリティは数万件になります。
対して age カラムは最大 120 程度にしかなりません(ギネスに載っている史上最高齢が 122 歳なので)。性別のカラムがあるとするとさらに少なくなるでしょう。
B-tree インデックスは、カーディナリティが高い列であり、さらに値が平均的に分散している場合高い効果を発揮します。 -
インデックスの効かない SQL がある
インデックスのあるカラムであっても、以下のような場合はインデックスを使用することができないため注意が必要です。- インデックスのあるカラムに対して演算を行なっている
SELECT * FROM users WHERE age * 1.1 > 50; - インデックスのあるカラムに対して SQL 関数を使っている
SELECT * FROM users WHERE SUBSTR(name, 1, 1) = 'a'; - インデックスのあるカラムに対して IS NULL 述語を使っている
SELECT * FROM users WHERE age IS NULL; - インデックスのあるカラムに対して非定形を使っている
SELECT * FROM users WHERE age <> 0; - インデックスのあるカラムに対して OR を使っている
SELECT * FROM users WHERE age == 0 OR age = 100; - インデックスのあるカラムに対して後方一致、中間一致の LIKE 述語を使っている
SELECT * FROM users WHERE name LIKE '%abc%'; - インデックスのあるカラムに対して暗黙の方変換を行なっている
SELECT * FROM users WHERE age = '100';
- インデックスのあるカラムに対して演算を行なっている
-
主キーおよび一意制約のあるカラムには作成不要
DBMS は主キー制約や一意制約を作成する際に B-tree インデックスを自動的に作成しているため、二重でインデックを作る必要はありません。 -
無駄なインデックスは作らない
インデックスはデータベース内にテーブルとは別に、独立したオブジェクトを保存しています。
そのためデータの更新があった際にはインデックスも同時に更新する必要があり、インデックスが増えるほどその更新性能は劣化してしまいます。
そのため極力無駄なインデックスの作成は避けるべきです。
インデックスの効果を計測する
インデックスの特徴や注意点を説明してきましたが、実際どれぐらいインデックスの効果があるのか疑問に思いませんか?
ここでは Rails と MySQL を使ってインデックスの有無でどの程度効果に差が出るのか試してみたいと思います。
下準備
まずは下記のようなマイグレーションファイルを作成して User モデルを追加します。
今回は name カラムと age カラムのみで試してみます。
User
| カラム | 型 |
|---|---|
| name | string |
| age | integer |
| created_at | datetime |
| updated_at | datetime |
class CreateUsers < ActiveRecord::Migration[7.0]
def change
create_table :users do |t|
t.string :name
t.integer :age
t.timestamps
end
end
end
インデックスは以下のように追加しました(インデックス無しの状態を計測後にマイグレーションする)。
class AddIndexUsers < ActiveRecord::Migration[7.0]
def change
add_index :users, :name
add_index :users, :age
add_index :users, [:name, :age]
end
end
モデルを追加したら、次のスクリプトを実行して 10 万件のデータを投入します。
ダミーデータの投入には Faker という Gem を利用しました。
下記のように記述することで簡単にダミーデータを作成することができます。
require 'faker'
cnt = 0
100000.times do
User.create(
name: Faker::Name.name,
age: Faker::Number.between(from: 0, to: 100),
created_at: Faker::Date.between(from: '2020-01-01', to: '2023-08-12'),
updated_at: Faker::Date.between(from: '2020-01-01', to: '2023-08-12')
)
cnt += 1
if cnt%10 == 0
p "#{cnt} / 100000"
end
end
計測
以下のようなスクリプトを作成し、処理時間を計測します。
ベンチマークには Ruby 標準ライブラリの benchmark を使用します。
スクリプトはそれぞれ以下の処理を 1 万回ずつ繰り返し行います。
- a~z までの文字をランダムで選択し、その文字から始まるユーザーを検索して変数に格納する
- 0~100 までの数字をランダムで選択し、その年齢のユーザーを1件取得して変数に格納する
- 1 と 2 の複合。名前検索を行なったあとに年齢が一致するユーザー1件を取得して変数に格納する。
require 'benchmark'
Benchmark.bm 10 do |r|
r.report "User name" do
10000.times do
c = ('a'..'z').to_a.sample
user = User.where("name Like ?", "#{c}%")
end
end
r.report "User age" do
10000.times do
n = rand(0..100)
user = User.find_by(age: n)
end
end
r.report "User name+age" do
10000.times do
c = ('a'..'z').to_a.sample
n = rand(0..100)
user = User.where("name Like ?", "#{c}%").find_by(age: n)
end
end
end
ベンチマークの計測結果は index の追加前後で以下のようになりました。
real は実経過時間ですが、他プロセス等にも影響を受けると思うので、とりあえず total の時間で比較するのが良さそうです。
※計測結果は実行環境等によって変わるのであくまで目安です。
// index追加前
user system total real
User name 0.607443 0.130174 0.737617 ( 1.040375)
User age 19.615497 4.345085 23.960582 ( 62.139172)
User name+age 26.335352 4.544105 30.879457 (128.644650)
// index追加後
user system total real
User name 0.452823 0.093795 0.546618 ( 0.736533)
User age 12.711392 2.832580 15.543972 ( 39.136931)
User name+age 20.692805 3.747454 24.440259 ( 56.786986)
上から順に約 25%、約 35%、約 20%の短縮を行うことができました。
インデックスが使用されているかどうかは SQL の実行計画を見ることで確認することができます。
実行計画を確認することで、どの index を使ってクエリを処理しているかを確認することができます。
Ruby の explain メソッドを使って最初のクエリを確認すると実行計画は以下のようになります。
前者は key 値が null になっているのに対して、後者は key に name カラムのインデックスが使われていることがわかります。
// User.where("name like 'a%'").explainの実行結果
// index追加前
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 90942 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
// index追加後
+----+-------------+-------+------------+-------+-------------------------------------------------+---------------------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-------------------------------------------------+---------------------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | index_users_on_name,index_users_on_name_and_age | index_users_on_name | 1023 | NULL | 13566 | 100.0 | Using index condition |
+----+-------------+-------+------------+-------+-------------------------------------------------+---------------------+---------+------+-------+----------+-----------------------+
さいごに
今回は簡単なケースでインデックスを使用してその効果を計測してみました。
計測結果から一定の効果を体感することはできましたが、実際の現場ではもっと複雑にテーブルを結合した SQL を使用しているかと思います。
その時々で実行計画を確認しながら最適なインデックスを設計できるようになりたいなと思いました。
最後まで読んでいただきありがとうございます。
少しでも参考になりましたら幸いです。
参考文献
Discussion
すごい参考になりました!
実際に測定した値を見たの初めてだったので、こんな感じになってるんだ!って思いました!

indexあると対象のrowsがそもそも少なくなっててすごいなと思いました