📖
インデックスと仲良くなろう


概要・目的
- DBで使われるインデックスの内部の仕組みを理解して効率的に貼れるようにする
- 内部の仕組みを理解することで応用の効く知識にする
インデックスとは何か
- 特定のカラム値のある行を素早く見つけるために使用される。インデックスがないと関連する行を見つけるために先頭の行から順番に見ていく必要がある
- select以外にもjoinやmin・max関数でも使われる
https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html
なんで速いのか
- 内部では基本的にB+Treeという構造を使用している
- 一般的にレコードの読み取りでボトルネックとなるのはディスクの読み込みでB+Treeはその読み込みを最小化してくれる
B+Treeの構造
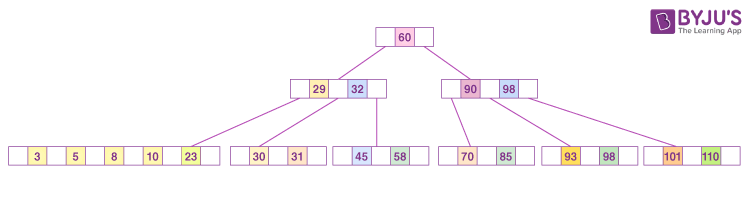
- 上記画像の辺で繋がっている要素をノードという
- さらにノードの中でも一番下の横一列をリーフノードという。この列のノード達が各レコードのデータを持っている。
- リーフノード以外は全て中間ノードと呼ばれレコードのデータは持っておらず、キーの閾値と次にアクセスするべきノードへのポインタを持っている
- 参考文献1p156から引用
Internal nodes contain only search information (key values) and child pointers.Keys in an internal node are sotred in the sort order, and are used in directing a search to appropriate child node.all of the keys on the left most child subtree that ptr(0) points to have values less than or equal to Key(0)all of the keys on the child subtreethat ptr(1) points to have values greater than Key(0) and less than or qual to Key(1), and so forth
- 参考文献1p156から引用
内部でどのような形で保存されているか
- 基本的にデータを保存する場所はただのファイルで、それを上手に使うことでインデックスを実現している。
- まずファイルを定数バイトで区切りその一つ一つをページと呼び、これが先ほどの図のノードを表す。
- ノード一つ一つに画像に載っているようなキーバリューの値が入る
- 中間ノードの場合は閾値の値と対応する子のページID、リーフの場合はインデックスのカラムの値と他の列の値のそれぞれバイト列にしたもの
どのように探索しているのか
- 最初にルートのページを取得して、対象のキーの値をもとに次のページIDを探す。そのページIDをもとに次のページを探す。それを繰り返して対象のリーフに到達したらそのリーフが該当のキーの値を持っていればそのレコードを返すようになっている。
- 例えば先の画像の場合キーが58のレコードを見つけたい場合はまずルートページで
60より小さいため左の子ノードを次に見てみると判断し、次のノードで32より大きいため45と58のキーが含まれるリーフノードを確認してみるとなり、最終的にリーフノードの中から該当のレコードを見つけることができる。
- 例えば先の画像の場合キーが58のレコードを見つけたい場合はまずルートページで
- 範囲検索の場合はまず最小値を含むページを取得してそこから最大値を含むページになるまで横に探索していく
- B+Treeの場合同じ深さのページはそれぞれ前後のページIDを持っているので探索が可能
挿入に流れ
- 最初に挿入するべきページを上記と同じ方法で見つける。そのページにスペースが存在していたら挿入して終了。もしスペースが無かったら、ページを分割して新しいキーとページIDを親の中間ノードに挿入する。親にスペースがあったら終了。なければ分割。。を続ける。
- 参考資料1のp158から引用
First, we invoke the normal search to find the leaf where k could reside. if there is space on the leaf node, we insert the key and the data on the node in the desired sort position. if there is no space on the leaf node, we would split existing entries residing there and the new one into two equal halves. we allocate the new leaf node, and move the upper half into the new node. we now need to add the new node into the tree. we add a pair<k, p> where k is the max key on the splitting node and p is the pointer to the new node into the parent of original leaf. if the parent has space for the new pair, the pair is stored there and terminates. otherwise the parent is split in the same way. the split propegats until we find some ancestor with sufficient space for a new pair or the root is split
- 参考資料1のp158から引用
- また一つのテーブルに複数のインデックスが定義されているとそれぞれに対して挿入しないといけないため、物理的に処理が増える。
得意不得意
- 探索はメチャ得意速くなる
- 挿入は上述した通りやることがいくつかあり時間がかかる。更新もキーの値が変わった場合再度挿入をしないといけないため時間がかかる。
- 削除は分割はないが、ページ内のキーバリューの値が少なくなったらマージが必要になるケースもあるらしい
ケーススタディ
等号での比較
- 最速。
フルスキャン
- インデックスでリーフノードを絞り込むことができないので全てのリーフをスキャンしてそこから絞り込む必要がある。なので、一番ディスクアクセスが必要で時間もかかる。
範囲検索
- 範囲が広くなればなるほどより沢山のページへのアクセスが必要になり横の探索でのディスクアクセスが発生するので遅くなる。
カーディナリティの低いカラムでの絞り込み
- カーディナリティとは対象のカラムに含まれているデータの数
- 例えば性別の場合男・女で2になる。
- カーディナリティが低いとそのカラムで絞り込んでも対してレコードは減らず、他の絞り込み条件がある場合そこからスキャンをかけるので結果大量のリーフノードを確認する必要が出てくる。
- もしインデックスでの絞り込みでページ数を大きく減らせることができればその後の絞り込みで大量のディスクアクセスをする必要がなくなる。
- インデックスに使われるのカラムのカーディナリティを気にする必要があるのはこの観点から
マルチカラムインデックス
- 前提としてマルチカラムインデックスの場合キーがそのカラムの値が合体したバイト列になる。
- column1(以下c1)の値が10でcolumn2(以下c2)の値が20の場合は[10,20]みたいに保存される。
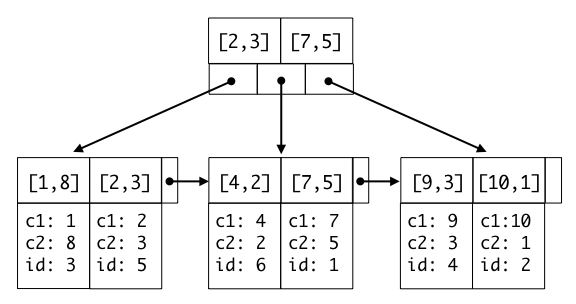
- column1(以下c1)の値が10でcolumn2(以下c2)の値が20の場合は[10,20]みたいに保存される。
- c1で絞り込みたい時に複合インデックスは使える?
- 使える。インデックスで絞り込む際は内部でkeylenを指定できる(実行計画でも確認できる)ので複合インデックスでもc1カラム分の長さだけ指定してやればaカラム単体のインデックスと同じ意味を持つ。
- 複合インデックスを使ってc2で絞り込む
- できない
- 前提として挿入する際のページ決めとしてc1の大小比較->c2の比較をして挿入するページを決める。のでc2の内容をもとに絞り込みはできない。
- 例えば上の図のB+Treeからc2が3のデータを取得したい場合該当のデータは左から2番目のリーフと右から2番目のリーフに存在することが分かる。このようにマルチカラムインデックスは一つ目のカラムを昇順にしてさらにその中で二つ目のカラムを昇順にして保存するので、全体で見た時二つ目のカラムは昇順にはならない。
- c1とc2で不等号を使って絞り込む
- c1しかインデックスとして使えない
- c1とc2両方不等号で絞り込みはできない(e.g. c1 > 2 and c2 < 5)
- c1 > 2の段階でリーフが絞り込めてもc2 < 5のリーフは点在しているので残りはフルスキャンする必要あり
- もしc1を等号で比較する場合はその段階でc2も昇順で並んでいることが確定なのでc2もインデックスとして使える
- 以下mysqlより引用
-
The optimizer attempts to use additional key parts to determine the interval as long as the comparison operator is =, <=>, or IS NULL. If the operator is >, <, >=, <=, !=, <>, BETWEEN, or LIKE, the optimizer uses it but considers no more key parts. For the following expression, the optimizer uses = from the first comparison. It also uses >= from the second comparison but considers no further key parts and does not use the third comparison for interval construction:key_part1 = 'foo' AND key_part2 >= 10 AND key_part3 > 10
-
インデックスのないクエリについてのjoin
- インデックスを使うことで結合する行をフルスキャンをすることなく見つけることができる。インデックスが貼られていない場合都度フルスキャンが必要になる
minとmax関数
- それぞれのレコードはリーフ列の一番左と右と決まっているので、フルスキャンをせずとも見つけることができる。
ソートでも使われるかどうか
- クエリで使われているインデックスのキーとソートのキーが一致している場合のみ使える
- レコードを取得した時点ですでに対象のキーでソートされているため再度ソートする必要がないため。
参考文献
SQLite Database System Design and Implementation
WEB+DB PRESS Vol.122
おまけ
こちらで実際にB+Treeの実装(挿入と探索)をしてみたので興味ある方はどんな風に実装されているか見てみてください。
Discussion