PythonとTensorflowでAIを学ぶ
はじめに
PythonとTensorflowを使ってAIを学びます。このスクラップの目的は、ニューラルネットワークの意味を理解し、実装できるようになることです。サンプルコードはこちらにあります。
用語整理
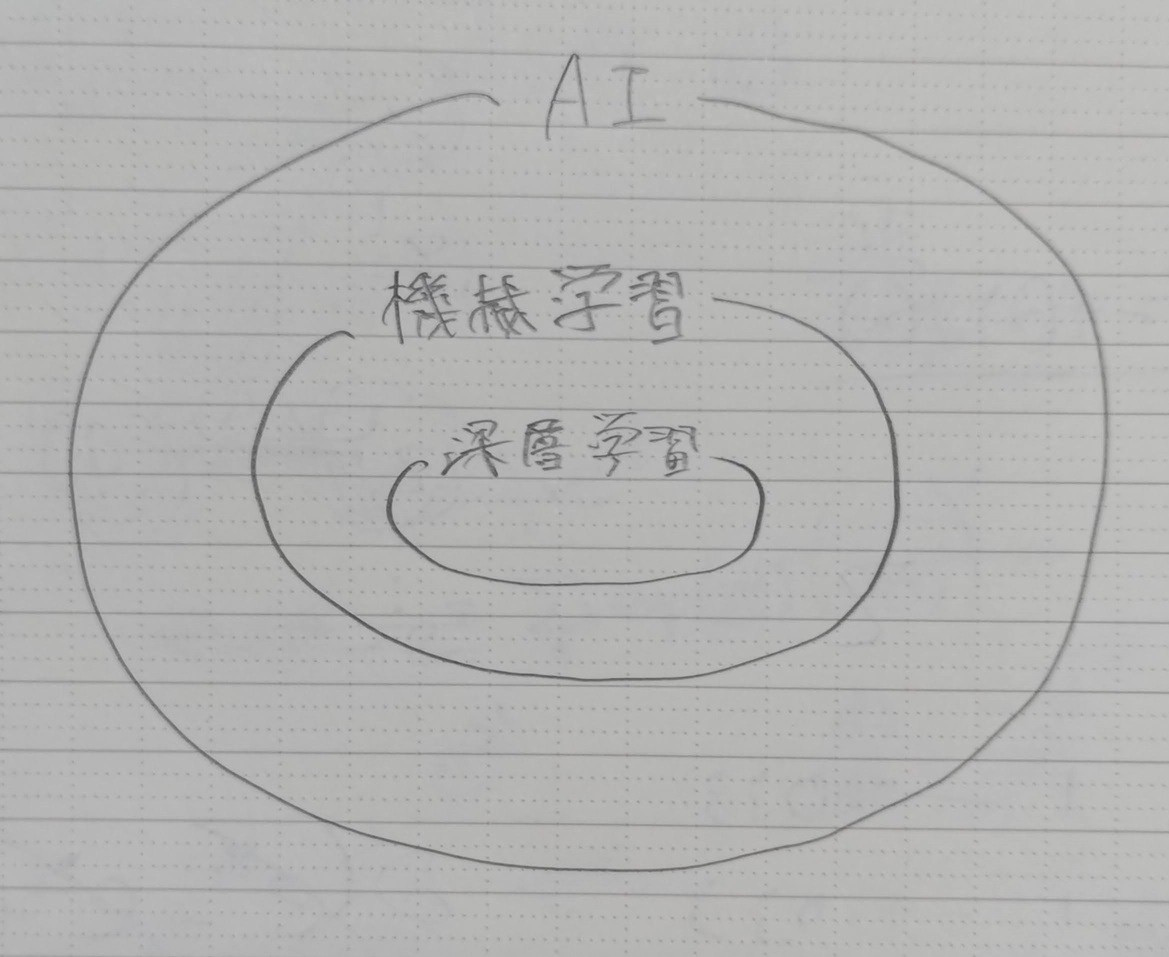
AI(人工知能)
コンピューターが、人間のようになにかを考えてなにかをすることです。幅広い概念です。
機械学習(Machine Learning)
AIの一種です。データから学習し、新しい入力に対して予測や判断を行うことです。
深層学習(Deep Learning)
機械学習の一種です。厳密な定義はありませんが、複数の中間層を持つニューラルネットワークによる学習を指すことが多いです。
機械学習の種類
-
教師あり学習(Supervised Learning):
データとそれに対応するラベルを使用し、データからラベルを予測します。 -
教師なし学習(Unsupervised Learning):
ラベルのないデータを使用し、データの構造やパターンを発見します。 -
強化学習(Reinforcement Learning):
試行錯誤をして、報酬を最大化するような行動を学習します。
このスクラップでは、教師あり学習のみ扱います。
全結合層
最も基本的なニューラルネットワークが全結合層です。前の層のすべてのノードが次の層のすべてのノードに接続されている層です。
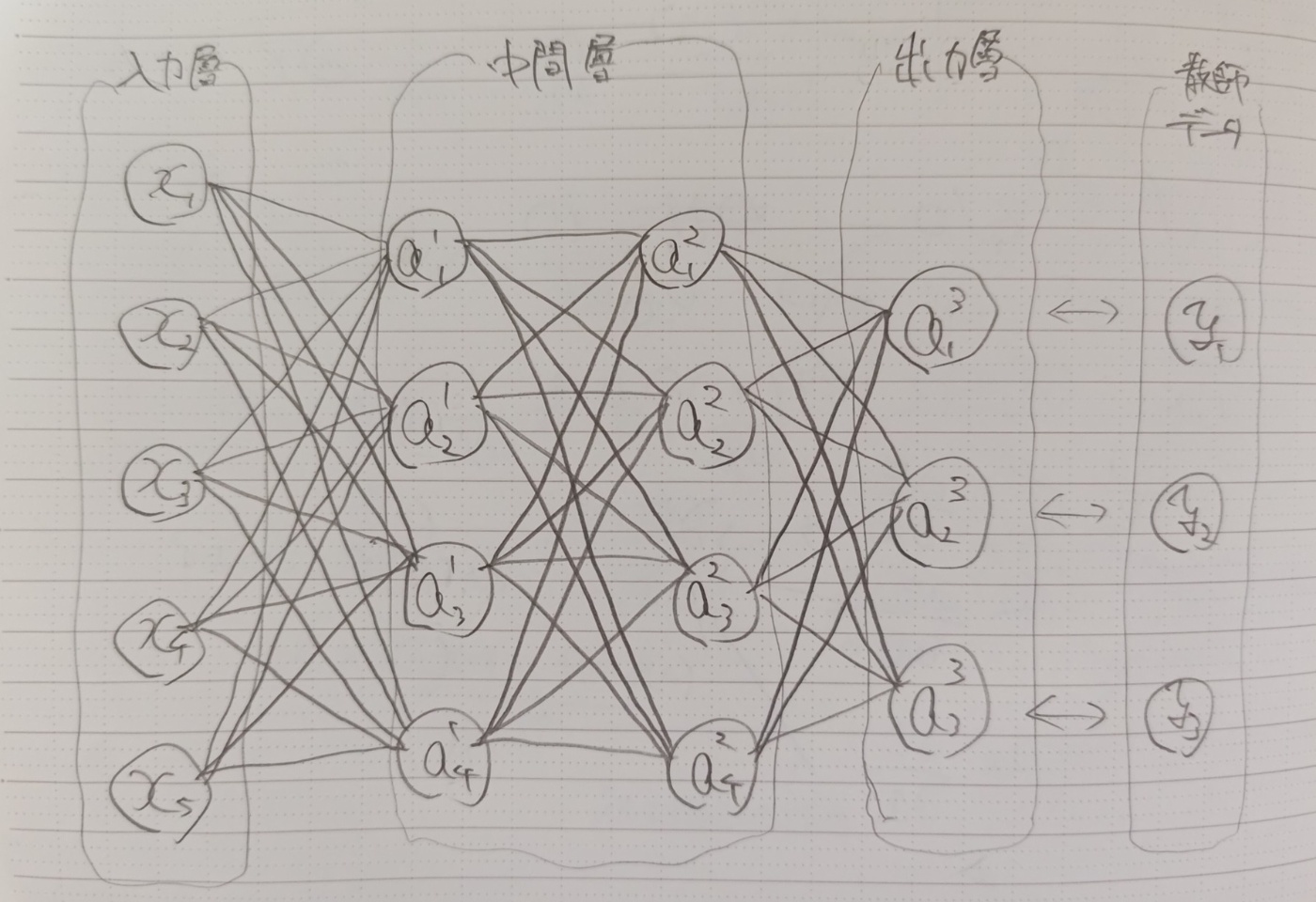
以下では、全結合層が
変数の定義
スカラー
行列とベクトル
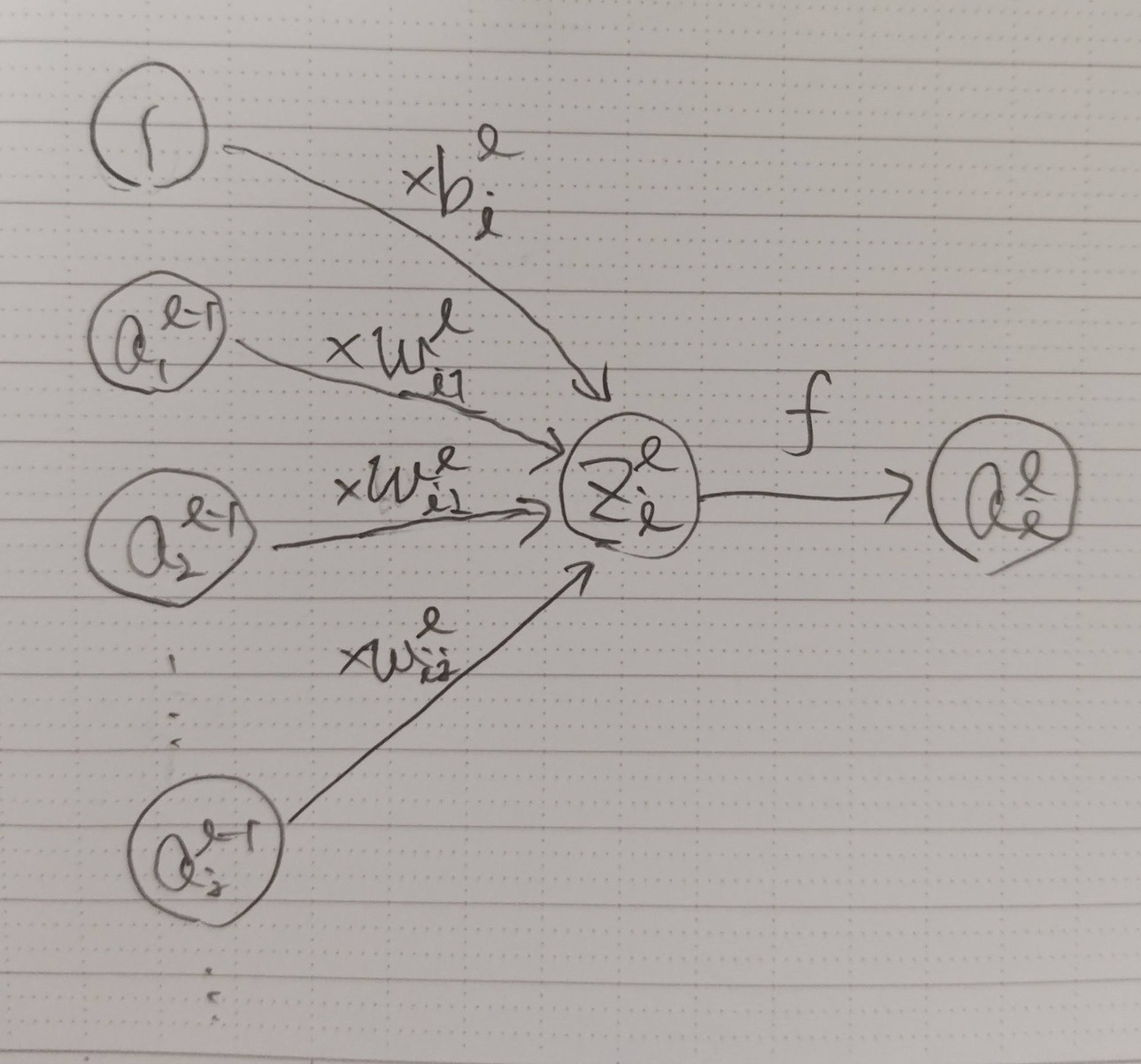
順伝播(フォワードプロパゲーション)
1層目
ベクトルと行列で表すと以下のようになります。ベクトルはすべて列ベクトルとします。
ベクトルの各要素を個別に計算すると以下のようになります。
例えば、入力を5次元ベクトル、1層目の出力を3次元ベクトルとすると、以下のようになります。
l
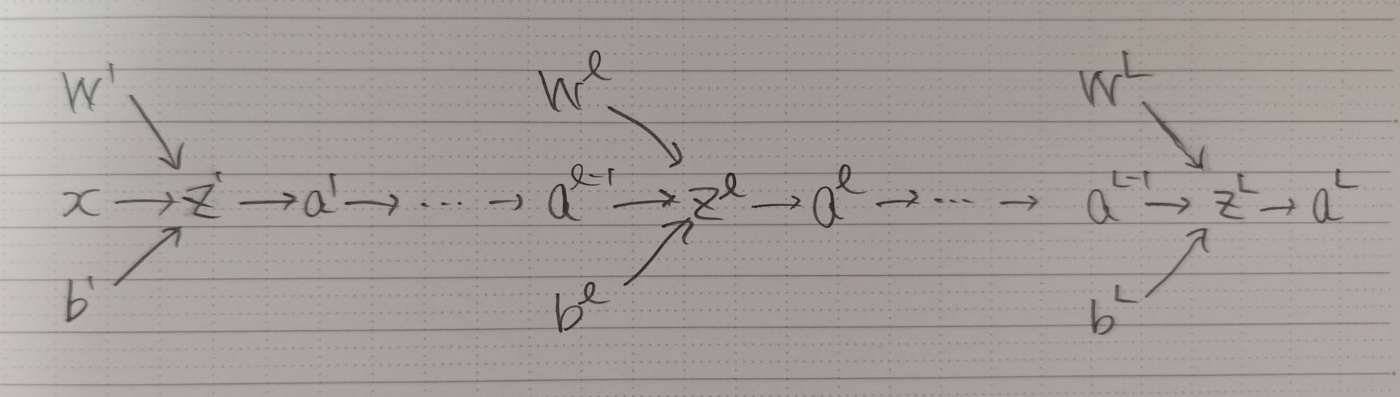
ベクトルと行列で表すと以下のようになります。1層目との違いは、入力が前の層の出力になっていることだけですね。
ベクトルの各要素を個別に計算すると以下のようになります。
これを最後の層まで繰り返すことで、ニューラルネットワーク全体の出力が得られます。
活性化関数
活性化関数の役割
活性化関数は、ニューラルネットワークの各層での出力を決定する重要な関数です。この関数がなければ、ネットワークは単なる一次変換の連続となり、複雑な問題を解決する能力を持ちません。
ReLU関数
今回用いる活性化関数は、ReLU(Rectified Linear Unit)関数です。ReLU関数は、以下のように定義されます。
この関数は、入力が0以上の場合はその値をそのまま出力し、0未満の場合は0を出力します。
他の活性化関数
他にもステップ関数やシグモイド関数などがありますが、それぞれ以下の図に示される特徴を持ちます。
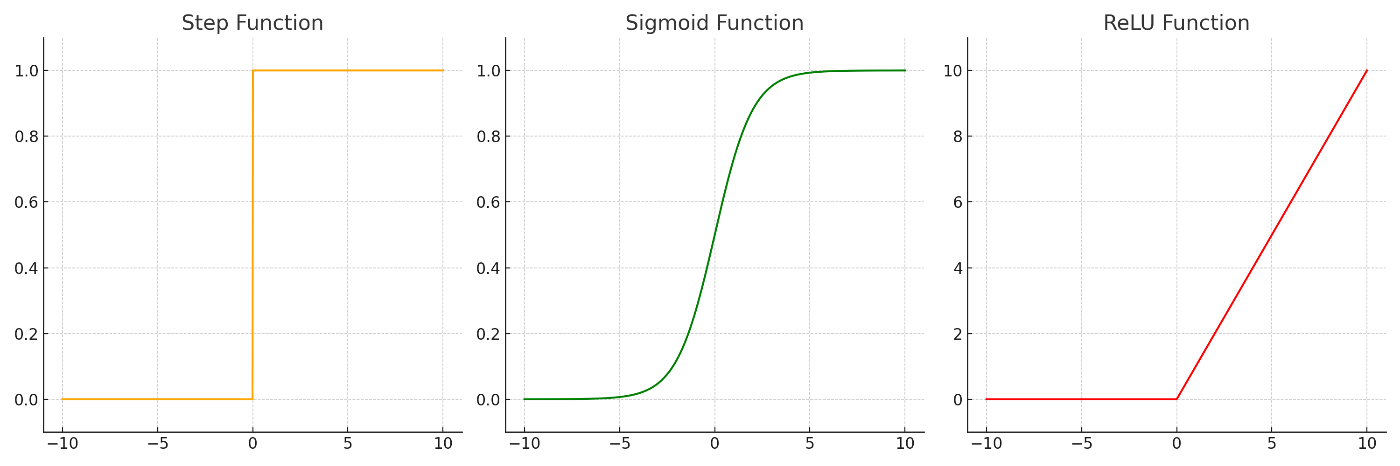
ReLU関数だけ出力の範囲が異なることに注意してください。
活性化関数の比較グラフ
各活性化関数の入力と出力の関係を以下の棒グラフで比較します。ここでは、-10以上10以下の一様乱数を入力としています。

左上が入力、右上がステップ関数の出力、左下がシグモイド関数の出力、右下がReLU関数の出力です。それぞれの特徴をよく観察してみてください。
活性化関数がない場合のニューラルネットワーク
活性化関数がない場合の順伝播の式を考えてみましょう。以下は、2層のニューラルネットワークの順伝播の式です。
ここで、
活性化関数がなければ、どんなに層を重ねても、ニューラルネットワークは一つの行列とバイアスの組み合わせに過ぎず、複雑な関数を表現できません。
誤差逆伝播法(バックプロパゲーション)
順伝播で入力に対する出力が得られましたが、最初の重みはランダムな値に設定されているので、出力もランダムになっています。そのため、重みを調整して正解に近づける必要があります。重みを調整するステップは以下のようになります。
- 順伝播で出力を計算する
- 出力と教師データの誤差を計算する
- 誤差を重みで偏微分する
- 偏微分した値を使って重みを更新する
これは、最適化問題を解くときによく使われる勾配降下法と同じです。しかし、中間層の重みに関する誤差の微分(重みを変化させたときに誤差がどれだけ変化するか)を計算するためには、後ろの層から前の層に向かって偏微分を計算する必要があります。順伝播の計算を逆向きに辿っていくため、誤差逆伝播法と呼ばれます。
以下の動画が参考になります。
損失関数
現在のニューラルネットワークがどれだけ正解から離れているかを表す関数を損失関数と呼びます。以下では、代表的な損失関数を2つ紹介します。
二乗和誤差
出力の各要素と教師データの各要素の差の二乗を合計したものです。回帰問題においてよく使用されるこの手法は、空間距離の計算に似ており、直感的に理解しやすいです。
交差エントロピー誤差
予測された確率分布と実際の確率分布がどの程度異なるかを測る尺度です。分類問題では、教師データは「ワンホットベクトル」として表されます。ワンホットベクトルは、正解ラベルのインデックスのみ1で、それ以外は0であるようなベクトルです。このベクトルは、正解ラベルが100%の確率で正しいという確率分布を示しています。
交差エントロピー誤差は、以下のように定義されます。
見慣れない数式かと思いますが、この式は
教師の確率分布をワンホットベクトルに限ってしまえば、この式は正解ラベルの予測確率の対数を取るだけの簡単な式になります。例えば
以下では、分類問題を例に説明するため、損失関数は交差エントロピー誤差を使います。
出力層の活性化関数
分類問題において、出力層の活性化関数は特別な役割を担います。分類問題では、入力データが特定のクラスに属する確率を予測することが目的です。出力を確率分布として解釈するためには、以下の二つの性質が必要です。
- 各要素の出力が0以上であること。
- 出力の総和が1であること。
これらの条件を満たす代表的な関数がソフトマックス関数です。今回、出力層の活性化関数には、ソフトマックス関数を使うことにします。ソフトマックス関数は、ベクトルを入力とし、各要素に対して以下の式を適用します。
ソフトマックス関数の定義
ソフトマックス関数はベクトル全体に適用され、以下のように定義されます。
ここで、
ソフトマックス関数の特徴
ソフトマックス関数は、各要素の指数関数を取り、それらの総和で割ることで、出力を正規化します。以下のグラフは、-10以上10以下の一様乱数を入力とした場合のソフトマックス関数の出力を示しています。また、すべての入力に100を加えた場合の出力も示しています。
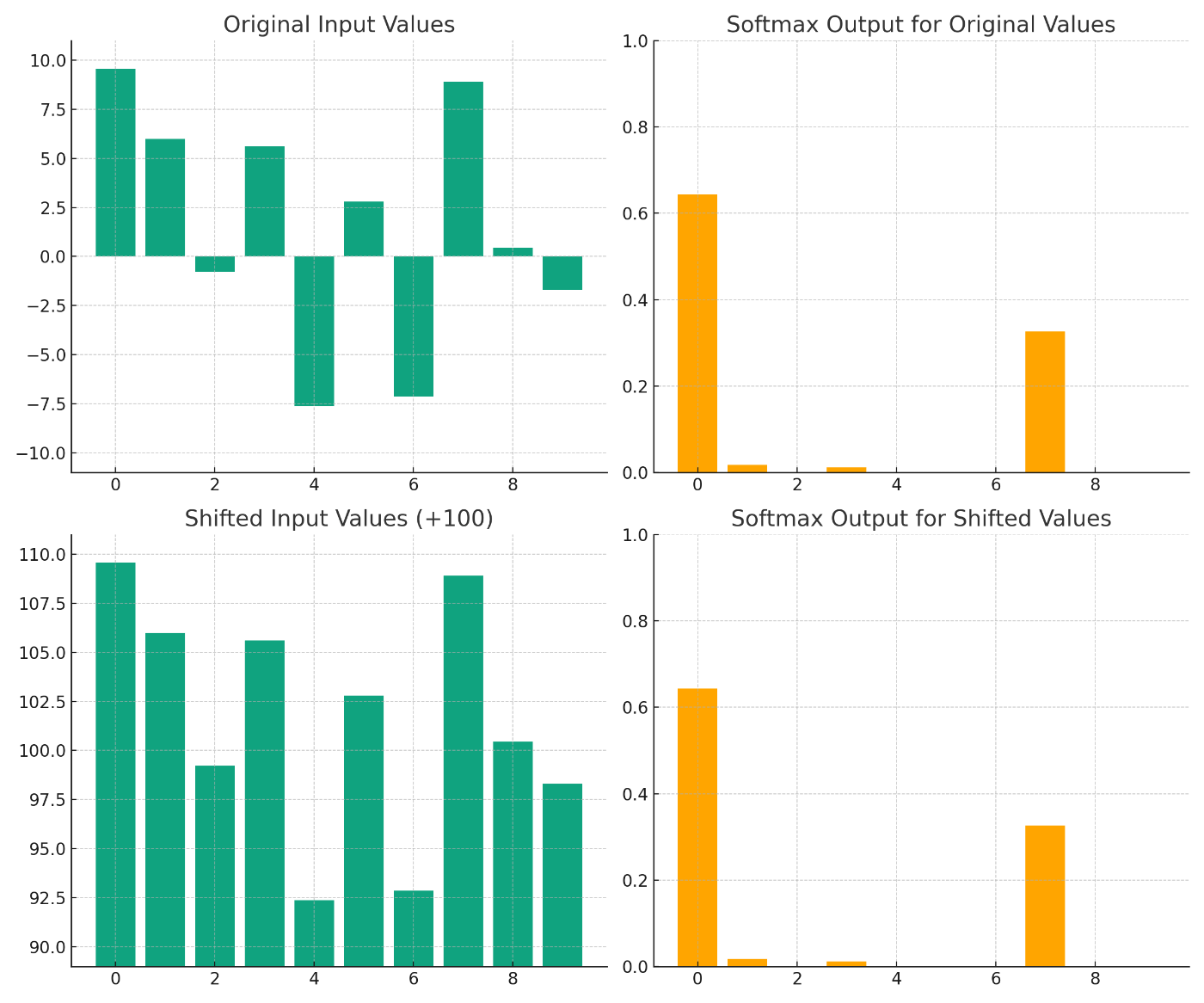
このグラフから、ソフトマックス関数が大きい値をさらに大きくし、小さい値をさらに小さくする性質が見て取れます。また、すべての出力の総和が1になるため、これを確率分布として解釈することができます。
定数の加算とソフトマックス関数
興味深い点として、すべての入力に定数を加えてもソフトマックス関数の出力は変わりません。これは指数関数の性質から導くことができます。
この性質は、ソフトマックス関数が入力のスケールに依存せず、相対的な大小関係にのみ影響を受けることを意味します。
出力に関する損失関数の偏微分
計算式が揃ったので、後ろから順番に偏微分を計算していきます。まず、交差エントロピーを
ソフトマックス関数の偏微分
ソフトマックス関数は、ひとつの加重総和がすべての出力に影響を与えます。加重総和の添え字と出力の添え字が一致する場合と一致しない場合で結果が異なるため、場合分けして計算します。
i \neq j
i = j
これらをまとめると以下の式で表せます。
ここで、
出力層の加重総和に関する損失関数の偏微分
連鎖率を使うことで、
ここで、
これをベクトルで表すと以下のようになります。
出力層の重み、バイアス、入力に関する加重総和の偏微分
最終的に求めたいのは、重みとバイアスに関する損失関数の偏微分です。しかし、重みとバイアスは損失関数に直接影響を与えないため、先に加重総和に関する偏微分を計算します。順伝播の計算式を思い出してください。
出力層の入力(ひとつ前の層の出力)に関する偏微分も計算しておきます。これは、中間層の偏微分を計算するときに使います。
出力層の重み、バイアス、入力に関する損失関数の偏微分
ようやく重みに関する損失関数の偏微分を計算できるようになりました。さらに連鎖率を用いて計算します。このとき、
バイアスに関する偏微分も同様に計算できます。
これで出力層の重みとバイアスに関する損失関数の偏微分がわかったので、出力層の重みとバイアスを更新できます。
しかし、中間層の重みとバイアスも更新する必要があります。後に必要になるので、ひとつ前の層の出力に関する偏微分も計算しておきます。各出力はすべての加重総和に影響を与えるため、
上記の重み、バイアス、入力に関する偏微分を、それぞれベクトルと行列で表すと以下のようになります。
プログラムでは行列演算を使うことで、簡潔に書くことができます。
ReLU関数の偏微分
ここから中間層の偏微分を計算していきます。活性化関数にはReLU関数を使うので、ReLU関数の偏微分を計算します。
条件分岐が式に含まれると煩雑になるので、活性化関数の微分
ベクトルの場合は以下のように定義します。各要素に
中間層の加重総和に関する損失関数の偏微分
ReLU関数はソフトマックス関数と異なり、ある加重総和に対して、ひとつの出力にしか影響を与えません。そのため、連鎖率で偏微分を計算するときは、対応する出力のみを考慮すればよいです。
ベクトルで表すと以下のようになります。
中間層の重み、バイアス、ひとつ前の出力に関する損失関数の偏微分
連鎖率を使うと、中間層の重みとバイアスの偏微分は以下のようになります。
ひとつ前の層の出力に関する偏微分は以下のようになります。連鎖率を使うときは、どの変数を介して損失関数に影響を与えるかに注意してください。
ここで、

行列とベクトルを使って表すと以下のようになります。
最適化手法
以下のサイトにまとめられています。どの手法も、勾配降下法をベースにしています。