SREへの道 ~ 第1章 パフォーマンスを向上させよう! ~
こんにちは!ヒロケイと申します。
SRE(site reliability engineering)を目指して勉強中なのですが、求められるスキルの一つであるパフォーマンスチューニングについて学習しています。
そこで、Webサービスのパフォーマンスチューニングについてまとめました。
以下のような読者を想定しています。
想定する読者
- SREを目指しているが、何から勉強すれば良いのかわからない
- Webサービスを作れる人間になったけど、作ったアプリを改善する手段を知りたい!
- ISUCONに出てみたい!
第1章~第9章まで理解すると得られるもの
- SREに求められるパフォーマンス改善スキルを体系的に学べる
- ボトルネックを特定してパフォーマンスを改善する具体的な手段
- ISUCONに出場するためのベースになる知識を会得できる
扱わないテーマ
- SREとは何か?
- Webアプリケーションの作り方
高速であることの重要性

かつては高速であることは、「達成できていると嬉しい」という要件でした。
しかし、最近では「達成することが絶対必要」となってきました。
高速であることが、webサービスの競争力に直接的に影響してくるからです。
なぜ高速であることが求められるの?
Webサービスの表示速度が遅くなると、ユーザーの離脱率は増します。
0.1s遅くなると0.2%減り、0.4s遅くなると0.6%減流と言われています。
3s以上かかると53%以上のユーザーが閲覧を止めて離脱してしまいます。
利用者が十万人いたとすると、0.1s遅いだけで200人、0.4s遅くなると600人、5s以上遅いと53000人ものビジネス機会を失うことになります。
規模の大きいサービスほど、ビジネスチャンスを逃さないという意味で高速である価値は大きくなることがわかるかと思います。
SEOに強くなれる
高速であるとSEOに強くなり、検索順位を上げることができます。
SEOでは、ページの検索順位を決める軸として、Core Web Vitalsを公開しています。
Core Web Vitals
検索結果の順位付けにページエクスペリエンス(体験の良さ)を利用している。
具体的な評価軸は以下の通り。
| 評価軸 | 概要 |
|---|---|
| LCP(Largest Contentful Paint) | 一番大きなコンテンツが表示される時間、目標は2.5s以内に収める |
| FID(First Input Delay) | ユーザーがページを操作してから、ブラウザが操作に対応した処理を開始するまでの時間。目標は0.1sを下回るようにする |
| CLS(Cumulative Layout Shift) | Webページの読み込み中にコンテンツが移動する量を示す指標 |
Time to First Byte(TTFB)やFirst Contentful Paint(FCP)など、他にも色々あるが、主要な評価軸は上記3つ。
検索順位の判断に表示速度が考慮されるのであれば、高速化することは優先度が高くなるでしょう。
コストパフォーマンスが良くなる
Webサービスが高速だと、一つの処理でサーバー上のシステムリソースを占有する時間が短くなります。
その結果、あるスペックでのサーバーでの単位時間あたりに処理できるリクエスト数は多くなります。
つまり、システムリソースのコストを安くできるのです。
高速なWebサービスとは?
一般的に以下で表されることが多いです。
Webサービス利用者がリクエストを送信してからレスポンスを受け取るまでの所要時間が短いサービス
レスポンスを受け取るまでの待機時間をレイテンシと呼びます。
レイテンシはが低いと高速で、高いと重いサービスだと言えるでしょう。
サービスを高速化することは、レイテンシを小さくすることだと言えますね!
リクエスト送信開始からレスポンスを受け取るまでの時間の長さをRTT(Round Trip Time)と呼びます。
ブラウザのレンダリングを考慮すると、1sまでには収められるとGoodでしょう!
レイテンシとRTTの違いは?
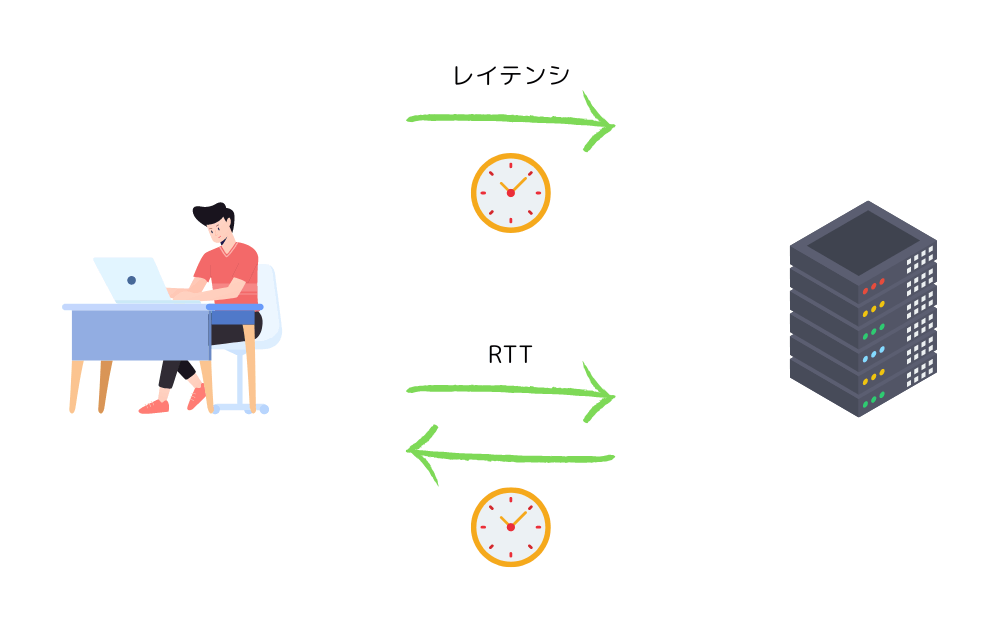
レイテンシ(Latency)は、通信が送信元から目的地まで到達するまでにかかる時間を指す。
つまり、データが送信されてから目的地に到着するまでの遅延時間。
レイテンシは一般的にミリ秒(ms)単位で表される。
レイテンシは、通信経路の物理的な距離や、ネットワーク機器(ルーターやスイッチなど)を通過する際の処理時間などによって影響を受ける。
RTT(Round-Trip Time)は、送信元から目的地までのデータの往復にかかる時間を示す。
つまり、データが送信元から目的地に到達し、目的地から送信元に返信が戻ってくるまでの時間。
この値は往復するため、一般的には片道のレイテンシの2倍になる。RTTも一般的にミリ秒(ms)で表される。
つまり、レイテンシは単方向の遅延時間を示し、RTTは往復する遅延時間を示す。
Webサービスの処理性能の指標
Webサービスは、単純に処理が早くするだけで単純に高速化できるわけではありません。
大量のリクエストを少ないシステムリソースで同時進行に捌く必要があります。
単位時間あたりに処理できるリクエスト数はスループットという言葉で表されます。
負荷について知る
Webサービスの負荷は、システムリソースの使用率の高さで表されることが多いです。
システムリソースには以下の要素があります。
- CPU時間
- メモリ領域
- メモリI/O領域
- ネットワークI/O領域
- ストレージI/O領域
システムリソースの需要が過多になると処理が遅くなったり、タイムアウトエラーが発生したり、最悪の場合サービスが落ちるといったこともあります。
キャパシティ
サービスがどのくらいのリクエストを捌けるかをキャパシティという単語で表現します。
捌けるリクエストの数という視点で言えば、スループットやレイテンシが当てはまります。
システムリソースという視点で言えば、利用可能なシステムリソースが当てはまるでしょう。
- レイテンシを短くする
- リクエストがシステムリソースを占有する時間が短くなる。
- 占有時間が短くなると、単位時間あたりに処理できるリクエスト数は増える。
- システムリソース観点でのキャパシティは同じまま、リクエスト観点でのキャパシティは多くなった!
例)
1sあたり50リクエストを捌けるシステムのリクエスト処理時間は20msec
処理時間を20msec→10msecにすることで、1sあたり100リクエストを捌けるようになった!
過不足なくシステムリソースを用意するためには?
スケーリング
システムリソース観点のキャパシティは、個々の性能 * 数で決まります。
システムリソースを増減させる上で、2つのアプローチがあります。
- 垂直スケーリング
- 水平スケーリング
垂直スケーリングとは?
それぞれのサーバーの性能を変更させてシステムリソースの総量を変える手法。
性能を上げることをスケールアップ、下げることをスケールインと呼ぶ。
水平スケーリングとは?

サーバーの数を増減させてシステムリソースの総量を変える手法。
増やすことをスケールアウト、減らすことをスケールイン
必要十分なキャパシティ
必要十分なキャパシティとは、需要に対して不足せず且つ過剰でない状態のことを指します。
キャパシティ需要は色々な要素で変動します。
- サービス利用者
- 取り扱うデータ量
- 処理内容や方法の変更
- etc...
サービス利用者が増えればキャパシティ需要は増え、処理のアルゴリズムを高速にすれば減ります。
必要十分なキャパシティが用意されていれば、スループットとレンテインシは維持されて理想的な状態になります。
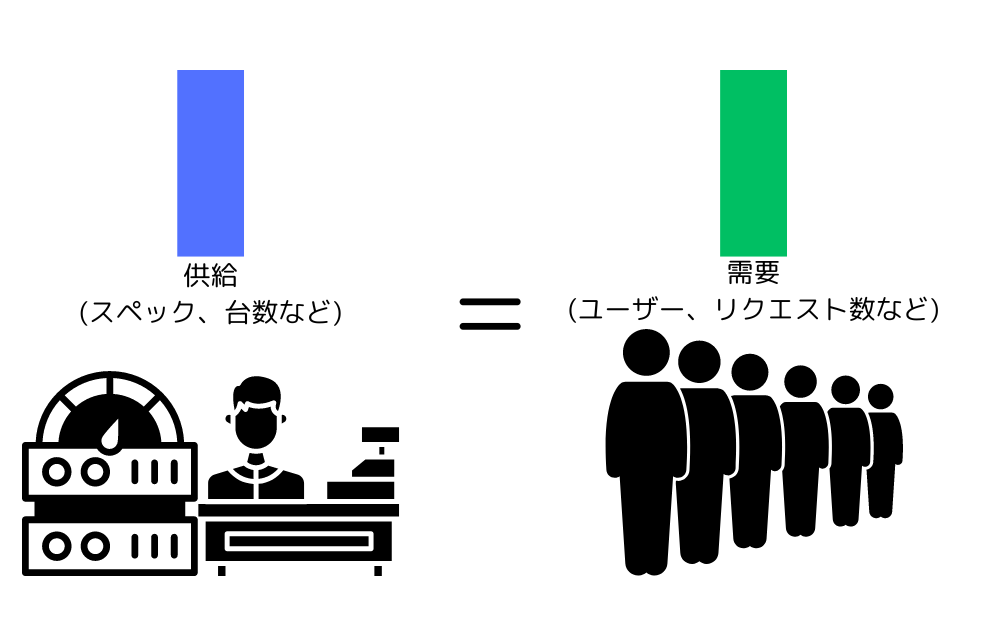
キャパシティ需要に対してキャパシティ供給が不足すると、過負荷状態になり、レイテンシ増加やデータ破壊など、壊滅的な出来事が起こる可能性が出てきます。

キャパシティ需要に対してキャパシティ供給が過剰になると、利用しないリソースを確保し、余分なお金を払っていることになるので、コストパフォーマンスを悪化させます。

キャパシティ需要をコントロールする方法
キャパシティ需要をコントロールする技術的な手段としては、以下があります。
- 処理要求を順番待ちさせる(キューイング)
- 単位時間あたりのリクエスト受付を一定数に絞る(レートリミット)
- リクエストの発生にランダムな待ち時間を発生させてタイミングを分散
もちろん技術的以外の手法もあるでしょう。
- 先着販売ではなく、抽選販売にする
- 抽選受付申し込みのタイミング重複を避けるため、応募券を時間差で配布
効果はとても高いが、ユーザーに影響が出る可能性が高いことに注意です!
キャパシティ供給をコントロールする方法
ユーザーに影響がなく実施できるので、供給側の調整が主軸になります。
垂直、水平スケーリングによってシステムリソース量を増減することで供給をしていきます。
必要なシステムリソース量を想定して変動を予測し、事前にスケール変更するというプロアクティブな手法が取られてきました。
最近はAWSやGCPなどのクラウド上では、システムリソースのスケール変更を自動でしてくれる機能(オートスケール)もあります。
しかし、これは発生したキャパシティ需要に対して供給を変更するというリアクティブな手法であるため、オートスケール機能だけでキャパシティ供給を満足させられるわけではありません。
プロアクティブ、リアクティブ
プロアクティブ: 未来の問題や挑戦に対して予防的な行動をとることを指す。事前対応なので、リスクを最小限に抑えられる。
リアクティブ: 問題が発生した後に対処することを重視する。事後対応なため、対処がより手間やコストがかかる場合がある。
以下の問題があるためです。
- 需要が発生してからスケール変更するまでにリードタイムが発生し、ユーザーを待たせてしまう。
- 需要の振れ幅が大きいほどリードタイムが長くなり、ユーザー待機時間は伸びまくる。
- いざシステムリソースを増やそうとしたら、インフラ基盤側のキャパシティが売り切れで増やせない。
プロアクティブ、リアクティブの両方の視点でキャパシティ供給をコントロールする必要があります。
キャパシティ供給の見積もり方
事前にこれくらいのキャパシティ供給(システムリソース)が必要だろうと予測することはほぼ不可能です。
なので、試すというアプローチをします。
ここで登場するのが負荷試験です。
負荷試験を実施すると、現実的なキャパシティについて検討する土台となるデータを取得できます。
パフォーマンスチューニングのマインドセット
心がけることが2つ。
- いきなり手を動かさない
- 勘で行動しない
パフォーマンスチューニングの基本やロジック、具体的な手法について把握した上で手を動かすことがとても大切です。
推測するな計測せよ
計測結果などの実際のデータを出発点として、様々な理論や知識を適切に利用する可能性が出てきます。
計測対象としては、主に以下があります。
- システムリソース利用状況
- レイテンシ
- スループット
負荷試験などで計測した場合は、負荷をかける対象のシステムだけでなく、負荷を与える側のシステムもモニタリングすることが大切です。
与負荷側の情報が高速化のヒントになる場合もあります。
公平に比較する
理科の実験でいう対照実験と同じで、二つのデータを比較するときは前提条件を揃える必要があります。
- アプリケーションバージョン
- スペック
- 設定値
- 与負荷条件
意図的に変更したところ以外は同じ条件にすることで、変更箇所の因果関係を推察できます。
ボトルネックにアプローチする
パフォーマンスチューニングは処理が遅い原因となっている箇所を特定し、解消することで実現します。
自分の技術領域以外の箇所がボトルネックの場合、新しく技術をキャッチアップする必要があるのは難しいところです!
パフォーマンスチューニングにおいて、ボトルネック以外の箇所を高速化してしまうと効果がないだけでなく、逆効果になってしまうパターンもあります。
例: コンビニの待ち列が行列なのにお客さんを呼び込んでも、時間あたりの売り上げは増えない。レジ待ち行列が長くなるだけ。
ボトルネックを特定する
Webサービスの構造を理解して適切にモニタリングできれば、ボトルネックを見つけることができるでしょう。
まずはマクロな視点でサービス全体を俯瞰し、データの流れを把握します。
データの流れに沿ってそれぞれの要素を切り分けし、以下を実行します。
- 入り口と出口で所要時間を計測
- システムリソースの利用状況を計測
ここで所要時間が長かったり、リソースが不足している箇所が怪しいポイントです。
ボトルネックになりがちなポイントは以下です。
- CPU
- メモリ
- ディスクI/O
- ネットワークI/O
システムリソースを100%使い切っているのは必ずしもボトルネックになりえないことを抑えておいてください。
ちょうどよく使っているコスパが良い状態かもしれないですよ。。。!
対処法3パターン
マクロ視点でボトルネックを特定したら、次はミクロ視点でのアプローチに切り替えます。
解消指針として以下の3つがあります。
- 解決: 該当箇所がボトルネックでなくなるよう処理方法を変える
- 回避: 構造や仕組みを変えて、処理そのものを不要にする
- 緩和: 配置変更やスケールアップ、スケールアウトを行い、ボトルネックの程度を緩和する
ほとんどの場合では解決が求められるが、場合によっては回避の方が対応コストが少なく済むことがあります。
Webサービスの構造を理解しよう
高速化には、以下の力が必要です。
- マクロ視点でアーキテクチャ全体を俯瞰する力
- ミクロ視点で問題箇所を掘り下げる力
これらの力を使ってWebサービスの論理的な構造と物理的な構造の2つを理解することが必要です。
- 論理的構造: サーバーの配置(クラウドホスティング、オンプレミス)、ネットワーク構成(ロードバランサー、ファイアウォール)、データベースの配置など
- 物理的構造: コンポーネントの関係性、クライアントとサーバーの間での通信プロトコル、アプリケーションのモジュール化、データの処理フローなど
構造がわかると、それぞれの要素が何をしているのかを把握できます。
高速化のためにどこを改善すれば良いのかを考えられるでしょう。
まとめ
今回はWebパフォーマンスチューニングの導入ということで、高速化の意味と重要性についてまとめました。
あなたがWebサービスの高速化を実現できる人間として活躍できることを願っています!
最後まで読んでいただき、ありがとうございました!
Discussion