😽
MacでローカルLLMを使う:OllamaとVSCode設定
はじめに
この記事では、MacでローカルLLM(大規模言語モデル)を使うための環境設定を解説します。OllamaとVisual Studio Code(VSCode)を使って、効率的な開発環境を作る手順を紹介します。
動作環境
- Mac(例:Mac mini、Apple M2 pro、メモリ16GB)
- エディタ:Visual Studio Code(VSCode)
Ollamaのインストール
- Ollamaの公式サイトからインストーラーをダウンロード。
- Homebrewユーザーは、次のコマンドでもインストール可能:
brew install ollama
ローカルLLMの準備と使用
- Ollamaのライブラリから好みのモデルを選びます。
- ここでは
gemma2:9bモデルを例に説明します。 - モデルのダウンロードと起動:
ollama run gemma2:9b - 対話を終了するには、
Ctrl + dか/byeコマンドを入力。
よく使うコマンド
- モデル一覧表示:
ollama list - モデルのダウンロードと起動:
ollama run モデル名 - モデルのダウンロードのみ:
ollama pull モデル名 - モデルの削除:
ollama rm モデル名
VSCodeの準備
- まだVSCodeを持っていない場合は、公式サイトからダウンロード。
VSCode拡張機能「Continue」の追加
- VSCodeを開き、拡張機能タブへ。
- 「Continue」を検索。
- Continue拡張機能をインストール。
VSCodeとOllamaの連携
- VSCodeで「Select model」を選択。
- 「Add Model」を選択。
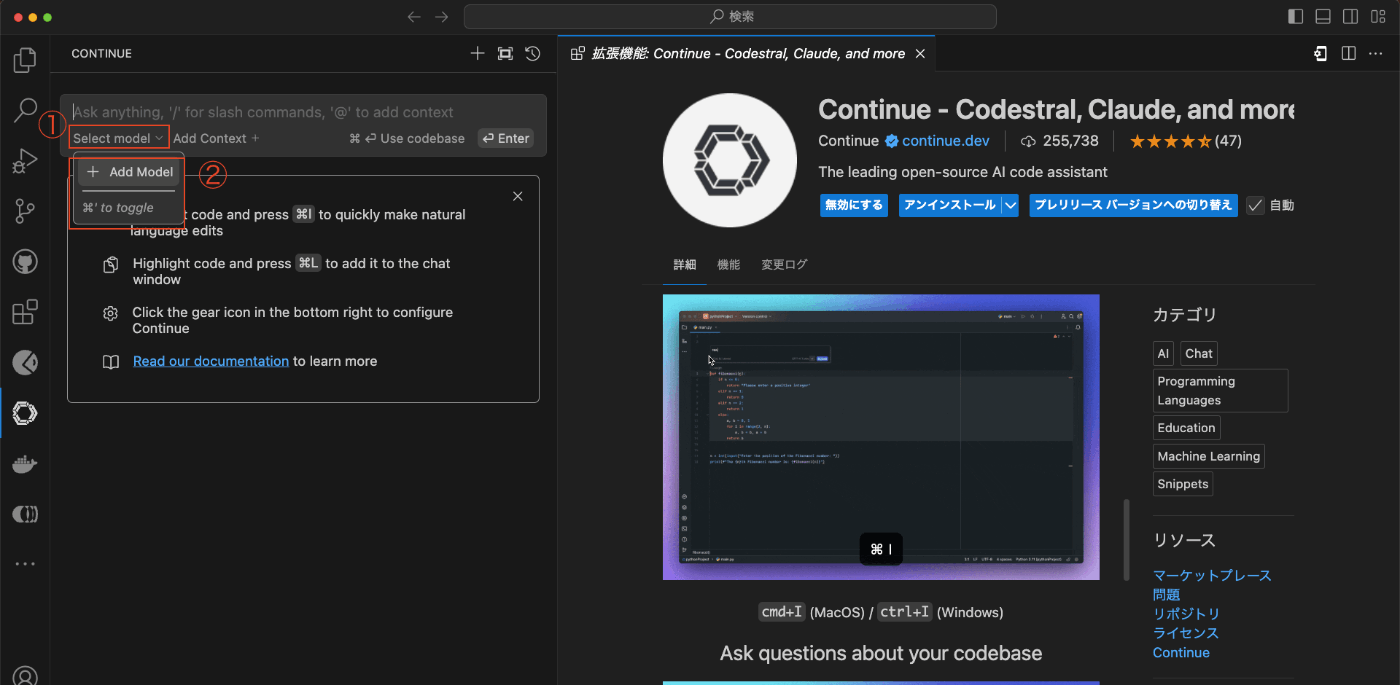
- 「ollama」を選択。
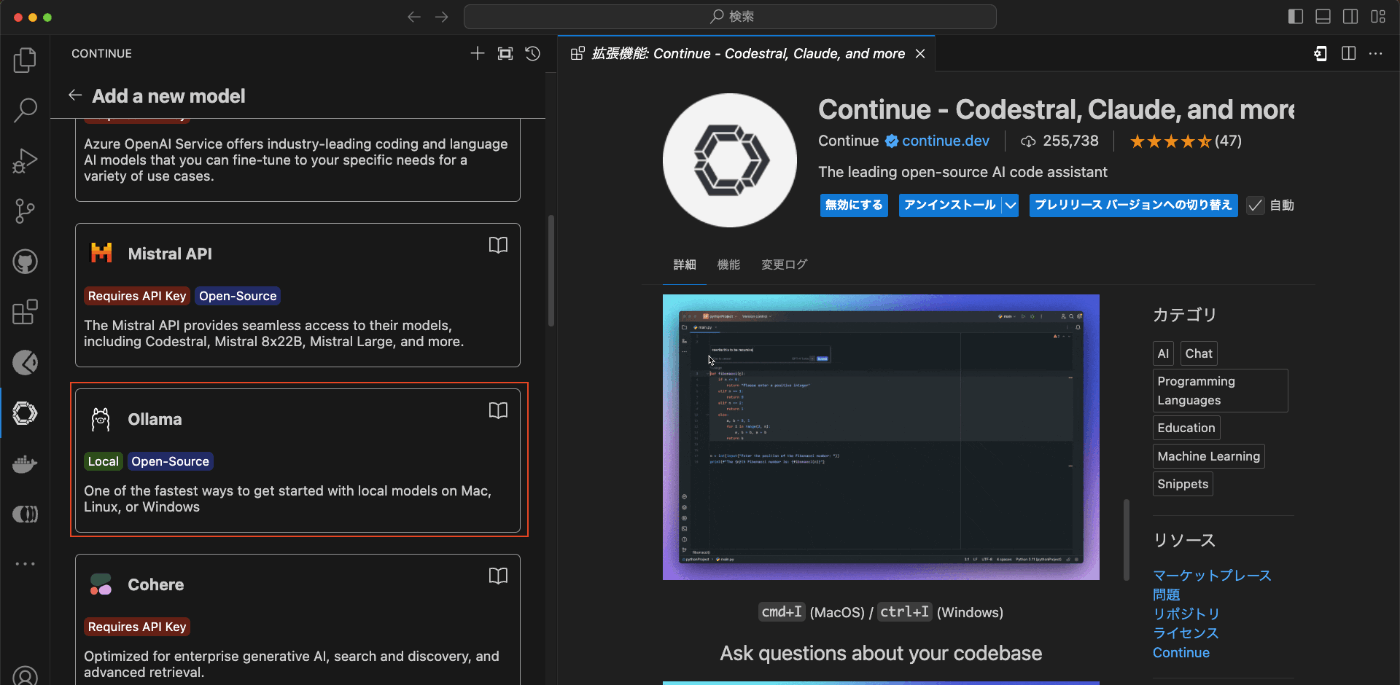
- 「Autodetect」を選択。

- 「Ollama - gemma2:9b」と表示されれば設定完了。

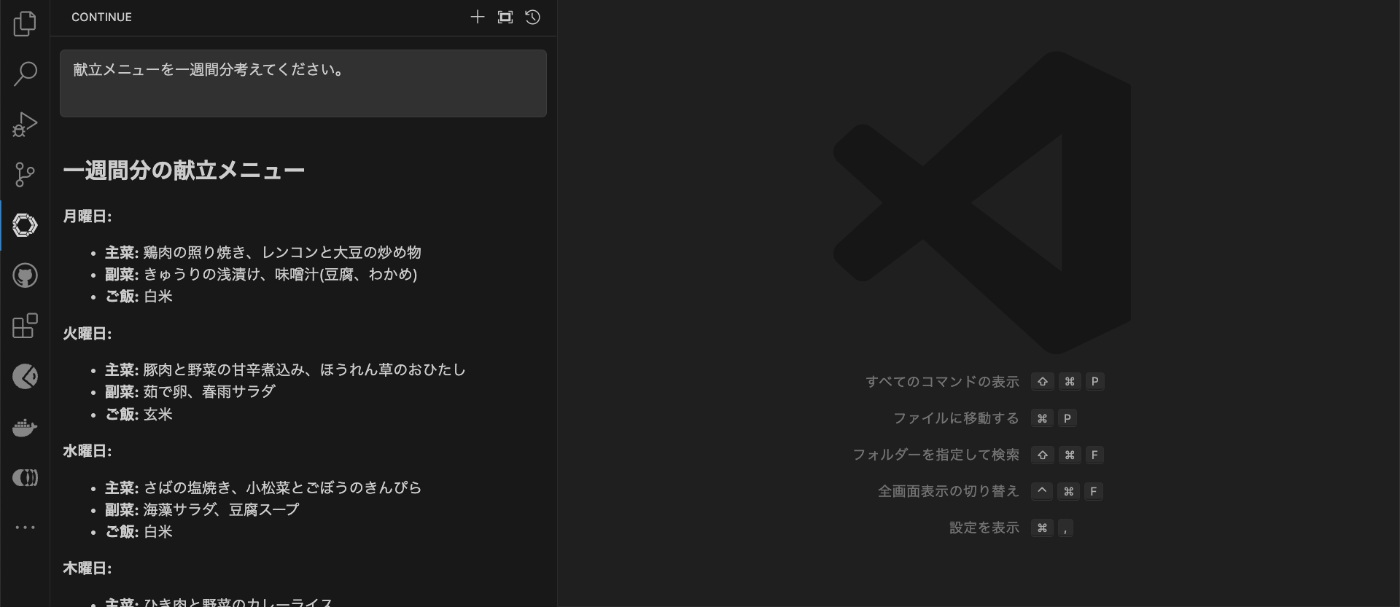
- 動作確認
入力欄に「献立メニューを一週間分考えてください。」と入力すると画像のように献立を出力してくれます
まとめ
これで、MacにOllamaを使ったローカルLLM環境とVSCodeの開発環境が整いました。
この設定により:
- プライバシーを守りながら高度な言語モデルが使えます。
- インターネット接続なしで、安全にデータを扱えます。
- VSCodeとContinue拡張機能で、コーディングの効率が上がります。
- エディタ内で直接AIアシスタントが使え、開発がスムーズになります。
- 必要に応じて簡単にモデルを切り替えられます。
この環境を使って、より効率的で創造的な開発を行ってください。
Discussion