Azure AI Searchでサポートされる検索の仕組み
サポートされている検索の種類
AI Searchの公式ドキュメントによると、「ベクトル検索」、検索インデックスに対する「フルテキスト検索」、「ハイブリッド検索」に対応している。
ベクトル検索および検索インデックスに対するフルテキスト検索とハイブリッド検索のための検索エンジン。
フルテキスト検索(全文検索)
フルテキスト検索とは、文章(フルテキスト)で検索できる機能です。たとえば、インターネッ トではキーワード検索が使われることが多いですが、フルテキスト検索は文章で検索することが できます。内部では文章を単語に分解し、インデックスに登録されたドキュメント内での頻出度 を考慮して検索を実行します。
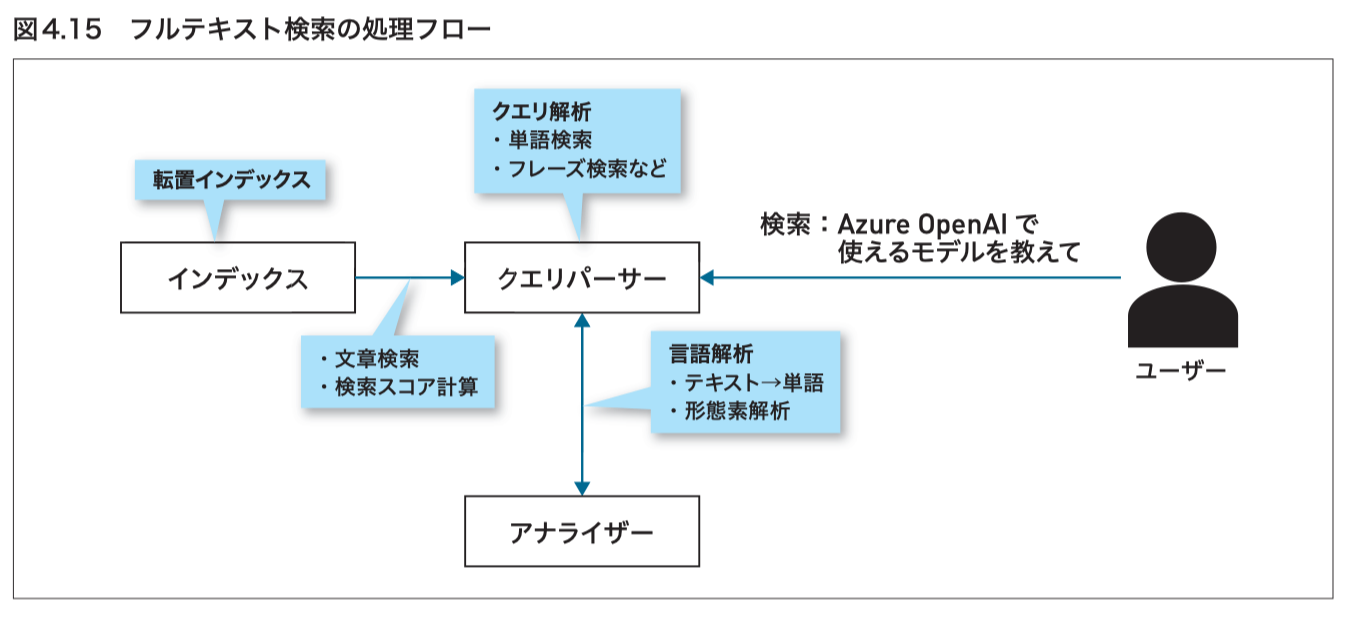
1. リクエスト送信 ― クエリはまず JSON に乗る
POST https://<service>.search.windows.net/indexes/docs/search?api-version=2023-11-01
{
"search": "Azure OpenAI で使えるモデルを教えて",
"queryType": "simple",
"queryLanguage": "ja"
}
queryType=simple を指定すると、Azure AI Search 標準のシンプルなクエリパーサーが使われます。Lucene(ルシーン) 構文を直接書きたい場合は queryType=full を指定します。
2. クエリパーサー ― 検索演算子ツリーへ展開
パーサは文字列を解析して 検索演算子ツリー を生成します。queryType=simple では下記のような意味になります(概念図)。
( Azure OR OpenAI OR で OR 使える OR モデル OR 教えて )
queryType=full なら、開発者が +Azure +OpenAI +モデル といった AND 強制 や "Azure OpenAI" といった** フレーズ検索** を明示できます。
3. アナライザー ― 日本語をトークンに分割
同じ手順で クエリ と ドキュメント側 のテキストをトークン化します。ここでは言語別ビルトイン ja.lucene を使用。
POST /indexes/myindex/analyze?api-version=2023-11-01
{
"text": "Azure OpenAI で使えるモデルを教えて",
"analyzer": "ja.lucene"
}
レスポンス例(抜粋)
"tokens": [
{ "token": "azure" },
{ "token": "openai" },
{ "token": "使える" },
{ "token": "モデル" }
]
- 英語部分 は小文字化 (LowerCaseFilter)
- 日本語 は MeCab 由来の形態素解析で単語分割
- ひらがなの助詞「で」や終助詞「教えて」は ストップワード除去 で落ちます
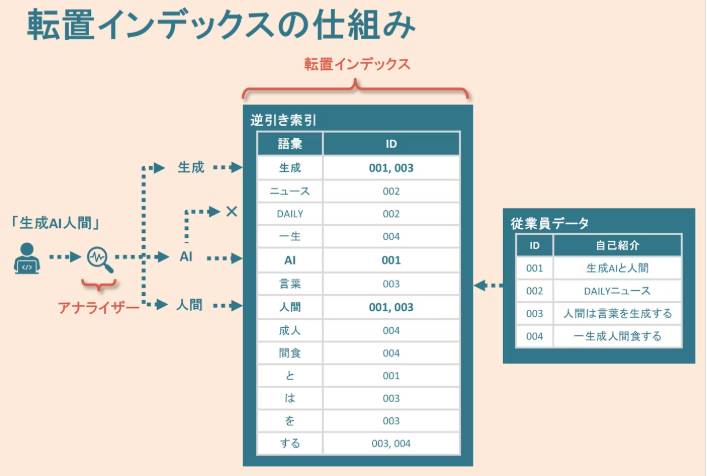
4. 転置インデックス ― トークンから DocID を瞬時に引く
各トークンは 「token → [DocID, 位置, 頻度]…」 という転置リストに紐づきます。Lucene がフィールドごとに作成するためユーザー操作は不要です。
- azure → {doc-15, pos = 3}, openai → {doc-22, pos = 7} …
- パーサーが返す演算子ツリーを走査し、対応する転置リストを集合演算(AND/OR/NOT)で合成
- ワイルドカード azure* はリストを全スキャンするため遅いので注意
転置インデックスの仕組みイメージ
5. BM25 ― 関連度スコアを数値化
候補文書ごとに BM25 を計算。デフォルト式は
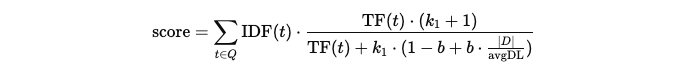
- k1(項目重み)と b(文書長補正)はインデックス定義で変更可能。
- BM25 は Lucene API の BM25Similarity 実装をそのまま利用しています。
スコアをビジネス要件で補正したい場合は Scoring Profile で「人気度」「更新日時」などを掛け合わせます。
6. Semantic Ranker(任意)― 意味で再ランク & 自動回答抽出
パラメータ queryType=semantic&answers=extractive を付けると、BM25 上位 N 件を BERT 系多言語モデルで再評価し、同時に 短い回答文 と ハイライト要約 を生成します。
※セマンティック検索という言葉がたまに出てくるけど、これはフルテキスト検索+セマンティックランカーでリランクした検索を指している。
7. レスポンス ― JSON にスコア・ハイライト・回答が載る
デフォルトで最大 50 件を @search.score 降順で返却。必要なら top=1000 まで拡張可能。
{
"@search.score": 12.3,
"content": "Azure OpenAI では gpt-4o、gpt-4-turbo などが利用可能です。",
"@search.highlights": { "content": "Azure <em>OpenAI</em> では <em>gpt-4o</em>..." },
"@search.rerankerScore": 0.92,
"@search.answers": [
{ "text": "Azure OpenAI で現在利用できる主要モデルは GPT-4o, GPT-4-turbo ...", "score": 0.87 }
]
}
- ベクトル検索を混ぜたい場合は同じリクエストに vector パラメータを追加 → BM25 とベクトル結果を RRF (Reciprocal Rank Fusion) で統合します。
ベクトル検索(Vector Search)
Azure AI Search では、テキストや画像などの非構造データを “ベクトル(数値配列)” に変換し、そのベクトル同士の距離(類似度)で検索する方式をベクトル検索と呼びます。
全文検索(BM25 などの単語マッチ)と違い、検索対象もクエリも 意味的に近いかどうか を基準に照合できるため、単語が一致しなくても関連コンテンツを返せる点が特徴です。

Azure AI Searchでサポートされている検索アルゴリズム
-
Hierarchical Navigable Small World(HNSW)
- 特徴
- 階層グラフ構造により高速・スケーラブル
- インデックスがメモリ常駐するため大量データに最適
- ユースケース
- 数百万~数十億ベクトルを扱う RAG⁄画像検索
- レイテンシ重視のリアルタイム検索
- 特徴
-
Exhaustive K-nearest neighbors(KNN)
- 特徴
- すべてのデータ点の類似度を計算。
- 計算コストが高いので小規模データが推奨
- ユースケース
- 〜数万件程度の小規模コーパス
- 精度が何より重要/リコール検証用
- 特徴
基本的にはHNSWを利用し、検索精度が悪くて小規模データの場合はKNNに切り替えるアプローチが推奨される
ベクトル検索で解決できるケース
-
同義語・言い換えを網羅
- クエリ: “経費削減” → ベクトル距離で “コスト最適化” を含む記事が上位に。
-
自然言語質問 ✕ FAQ 回答
- “パスワードを忘れた” → “Forgot Password” 手順ドキュメントを命中。
-
クロスリンガル検索
- “ヨーロッパの物価が高い都市” (日本語) → “Copenhagen is the priciest city in Europe” (英語) を取得。
-
マルチモーダル
- 画像を CLIP Embedding でベクトル化 → “海辺の夜景” と打つと類似写真が返る。
-
コールドスタートの短文
- Slack の「👍」だけのリアクションなど単語密度が低いデータでも、意味的クラスタで近傍を返せる。
これらは 埋め込みモデルの意味空間 上で近いベクトル同士を HNSW/eKNN で KNN 検索しているため実現できます。