YOLOで画像認識した動画をWebRTCでリアルタイム配信
はじめに
RTPで送信されてくる動画を中継するサーバを作り、YOLOで物体認識させてみます。
前提条件として、前回記事で作成した環境を使います。
今回作成するシステムの構成図(赤点線枠の部分が今回追加する部分)
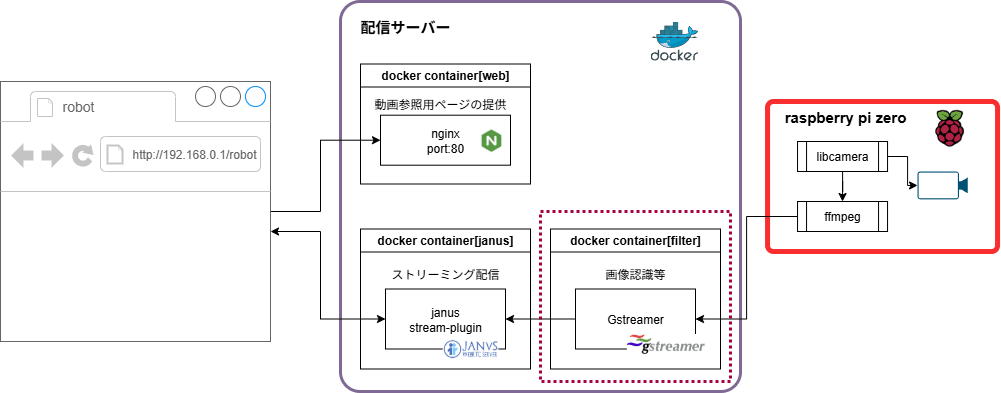
GPUを有効にしたコンテナ構築
物体検出を行うためにコンテナを一つ追加します。
今回のサンプルでは、物体検出にはYOLOを使います。リアルタイムで行うにはGPUが必須となりますので、CUDAを有効化したコンテナを作ります。
Dockerの設定
以下のようなディレクトリ構成とします。
/
├─ docker-compose.yaml <-- 前回作成したものに追加
├─ container/
│ ├─ nginx/ <-- 前回作成したもの
│ │ ├─ :
│ ├─ janus/ <-- 前回作成したもの
│ │ ├─ :
│ ├─ filter/ <-- 追加
│ ├─ Dockerfile <-- 追加
├─ filter/ <-- 追加
├─ <ここにテスト用のファイルを置く>
Dockerfileは以下のようにします。本記事で使用するgstreamer ffmpeg pytorch YOLO等をインストールしています。
FROM nvidia/cuda:12.8.1-runtime-ubuntu24.04
WORKDIR /work
CMD ["/usr/bin/bash"]
RUN apt-get update \
&& apt-get install -y --no-install-recommends tzdata\
&& apt-get install -y git cmake sudo vim \
&& apt clean
ARG DEBIAN_FRONTEND=noninteractive
ENV TZ=Azia/Tokyo
RUN apt-get install -y tzdata
RUN apt-get update \
&& apt-get install -y python3 python3-pip python3-setuptools python3-wheel python3-venv python3-opencv \
&& apt clean
RUN apt-get update \
&& apt-get install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav gstreamer1.0-tools gstreamer1.0-x gstreamer1.0-alsa gstreamer1.0-gl gstreamer1.0-gtk3 gstreamer1.0-qt5 gstreamer1.0-pulseaudio \
&& apt-get install -y python3-gi \
&& apt-get install -y libgirepository1.0-dev gcc libcairo2-dev pkg-config python3-dev gir1.2-gtk-3.0 \
&& apt-get install -y ffmpeg \
&& apt clean
ARG USERNAME=user
ARG GROUPNAME=user
ARG UID=1001
ARG GID=1001
ARG PSWD=user
RUN groupadd -g $GID $GROUPNAME && \
useradd -m -s /bin/bash -u $UID -g $GID -G sudo $USERNAME && \
echo $USERNAME:$PSWD | chpasswd && \
echo "$USERNAME ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
RUN mkdir /opt/env && chown ${USERNAME}:${USERNAME} /opt/env
RUN usermod -aG sudo ${USERNAME}
USER ${USERNAME}
RUN python3 -m venv /opt/env --system-site-packages
ENV PATH="/opt/env/bin:$PATH"
RUN echo '. /opt/env/bin/activate' > ~/.bashrc
RUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
RUN pip install opencv-python
RUN pip install pycairo
RUN pip install pygobject
RUN pip install ultralytics
RUN pip install ffmpeg-python
docker-compose.yamlは以下のようにしました。
services:
:
filter:
container_name: filter
build:
context: .
dockerfile: containers/filter/Dockerfile
environment:
- NVIDIA_DISABLE_REQUIRE=true
- WAYLAND_DISPLAY=wayland-0 # WSLg
- PULSE_SERVER=/mnt/wslg/PulseServer # WSLg
- XDG_RUNTIME_DIR=/mnt/wslg/runtime-dir # WSLg
- DISPLAY
deploy:
resources:
reservations:
devices:
- driver: nvidia
count : 1
capabilities: [compute,video,graphics,utility]
volumes:
- ./filter:/work
- /tmp/.X11-unix:/tmp/.X11-unix # WSLg
- /mnt/wslg:/mnt/wslg # WSLg
tty: true
command: ["/bin/sh"]
ports:
- 5010:5010/udp
コンテナの起動
Dockerfileとdocker-compose.yamlを修正したら、
$ docker compose up filter -d --build
でコンテナを起動します。
無事コンテナが起動したら、nvidia-smiコマンドで、コンテナ内でGPU認識しているか確認します。
$ docker container ls # コンテナの起動確認
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6a58f6702c3c webrtc-filter "/opt/nvidia/nvidia_…" 6 days ago Up 59 minutes 0.0.0.0:5010->5010/udp, [::]:5010->5010/udp filter
$ docker exec -it filter nvidia-smi # GPUを認識しているか確認
Sat Oct 4 07:34:41 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.65.05 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GTX 1650 On | 00000000:01:00.0 On | N/A |
| 30% 31C P8 5W / 75W | 888MiB / 4096MiB | 2% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 25 G /Xwayland N/A |
| 0 N/A N/A 39 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
gstreamerによる、パイプライン処理
Raspberry PI等からRTPで送られてくる動画に対して、YOLOで物体検出を行い、結果をjanusに送信することを考えます。
これを実現するためには、以下の流れで処理を行うことになります。
(janusとの間に入って動画ストリームを中継します。)
- 動画の受信、H264 エンコード/デコード、動画再配信については、gstramerを使うことで実現しています。
- 物体検出と、その結果の各コマへの書き出しはPython上でYOLOでおこないます。
- gst-pythonを使うことで、gstreamerからyoloの呼び出しをpython上で行っています。
gstreamerの動作テスト
最初に、動画の中継に使うgstreamerの動作確認を行います。
準備
前回の記事で作成した2つのコンテナ(webサーバと、janusサーバ)を起動して、デモサイトにアクセスしてください。
デモサイトにはhttp://localhost/janus/で参照できます。
テスト動画の受信
gstreamerでは「エレメント」をパイプでつないでいくことで、動画処理を行うことができます。
以下のようにgstreamerのエレメントをつなぐことで、テスト動画をH.264でRTP送信することができます。
今回追加したコンテナfilterにて以下のコマンドを実行してください。
$ docker exec -it filter /usr/bin/bash # <-- コンテナ:filterのshellを起動
$ gst-launch-1.0 videotestsrc ! nvh264enc ! video/x-h264,profile=baseline ! rtph264pay pt=96 ! udpsink host=janus port=8004 sync=false # host名にはdockerコンテナ名を指定します。
Setting pipeline to PAUSED ...
Pipeline is PREROLLING ...
Got context from element 'nvh264enc0': gst.cuda.context=context, gst.cuda.context=(GstCudaContext)"\(GstCudaContext\)\ cudacontext1", cuda-device-id=(uint)0;
Got context from element 'nvh264enc0': gst.gl.GLDisplay=context, gst.gl.GLDisplay=(GstGLDisplay)"\(GstGLDisplayWayland\)\ gldisplaywayland0";
Pipeline is PREROLLED ...
Setting pipeline to PLAYING ...
Redistribute latency...
New clock: GstSystemClock
0:00:12.4 / 99:99:99.
janusのdemoサイトにテスト動画が流れれば成功です。
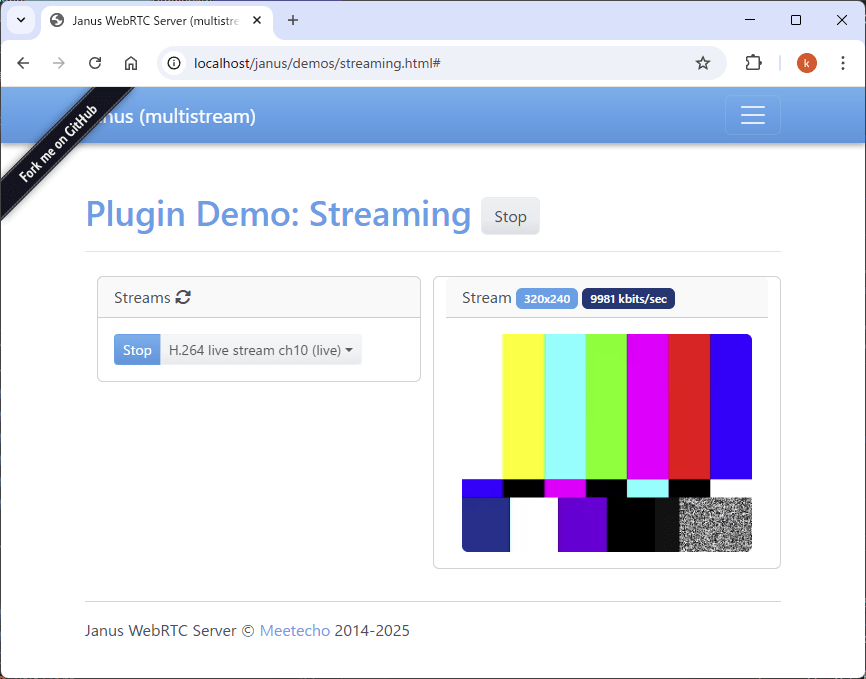
動画ストリームの転送
次にgstreamerのudpsrcでRTPストリームを受信し、何も手を加えず udpsinkでjanusに転送するテストを行います。
mp4ファイルをそのままjanusに流す
最初に、下図のように、gstreamerを経由せず動画ストリームを直接janusに流す例からやってみます。
動画ファイルについては、下の「動画ファイルの準備」を参考に動画ファイルを準備してください。
動画ファイルの準備
適当な動画ファイルがない場合は、以下などからダウンロードしたものが使えます。
今回のテスト環境ではホスト側で/filter下にファイルを置くと、コンテナ内からは/workフォルダから参照できるようになります。
ここでは、filter/test_movie.mp4として保存したとします。(コンテナ内から参照する場合はwork/test_movide.mp4になります。)
mp4ファイルをffmpegで配信するには、以下のようなコマンドとなります。
(ハードウェアエンコーダーh264_nvencを使っています)
$ ffmpeg -re -i test_movie.mp4 \
-c:v h264_nvenc -pix_fmt yuv420p \
-s 1280x720 -an -r 25 -bitrate 2000 -preset fast \
-f rtp rtp://janus:8004
うまくいけば、janusのサイトに動画が流れるはずです。
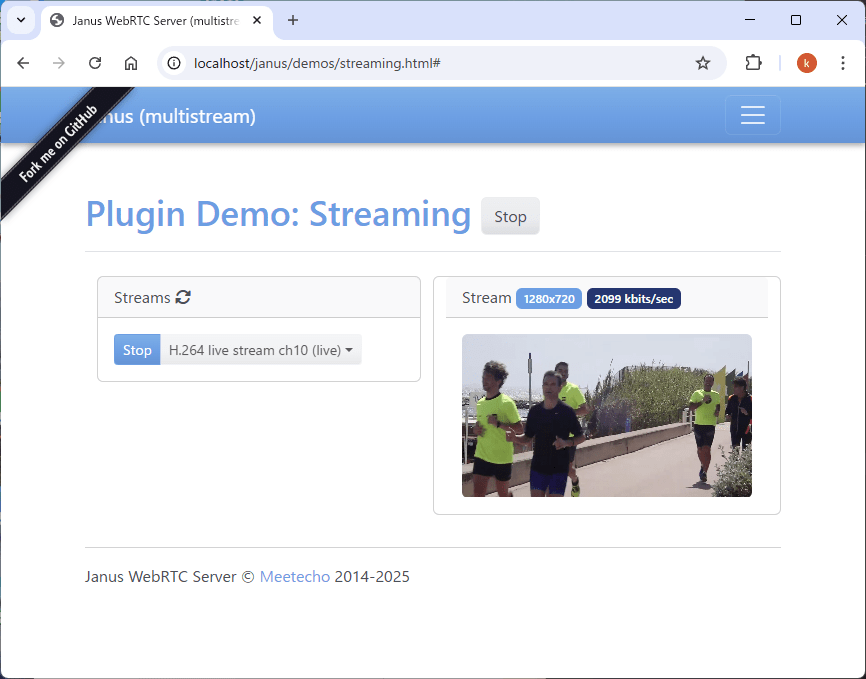
gstreamerで中継
問題なく再生出来たら、下図のように動画ストリームをgstreamerで中継してみます。
動画中継用と再生用に2つターミナルが必要になります。それぞれで以下を実行してください。
- 1つ目(gstreamerで中継)
udpsrcでport=5010の待ち受けportを指定しています。
その後、udpsinkでhost=janus,port=8004へ送信しています。
$ gst-launch-1.0 udpsrc port=5010 caps="application/x-rtp,media=video,encoding-name=H264,payload=96" \
! rtph264depay ! h264parse \
! nvh264dec \
! nvh264enc preset=low-latency zerolatency=true min-force-key-unit-interval=30 \
! video/x-h264,profile=baseline \
! rtph264pay config-interval=1 pt=96 \
! udpsink host=janus port=8004 sync=false
- 2つ目(ffmpegで動画再生)
先ほどの例と同様ですが、送信先ホストをjanus⇒filter、ポートを8004⇒5010に変更しています。
$ ffmpeg -re -i test_movie.mp4 \
-c:v h264_nvenc -pix_fmt yuv420p \
-s 1280x720 -an -r 25 -bitrate 2000 -preset fast \
-f rtp rtp://filter:5010
先ほどと同じ動画が、janusのデモサイトに流れれば成功です。
(見た目は変わりませんが、gstreamerで中継されています。)
以上で、動画を中継する部分の確認ができました。以下YOLOで物体認識をさせます。
YOLOによる画像認識
動画を中継する準備が整いましたので、物体認識の準備を行います。ここでは物体認識にYOLOを使います。
様々な物体検出アルゴリズムがあり認識精度という点ではYOLOより優れたものもありますが、YOLOは処理速度が速いという特徴があり動画処理のようなリアルタイム処理に向いています。ultralyticsパッケージを入れれば簡単に利用することができます。
コンテナビルド時に必要なライブラリはインストール済みですので、以下のサンプルが動くことを確認してください。
yolo_test.py
from PIL import Image
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model(["https://ultralytics.com/images/bus.jpg", "https://ultralytics.com/images/zidane.jpg"])
for i, r in enumerate(results):
im_bgr = r.plot()
im_rgb = Image.fromarray(im_bgr[..., ::-1])
# r.show()
r.save(filename=f"results{i}.jpg")
上記を、yolo_test.pyというファイル名でfilterフォルダに保存し(コンテナ内では/workにマウントされています)
以下のコマンドを実行すると、同フォルダにresult0.jpg result1.jpgが作られます。
$ docker exec -it filter python /work/yolo_test.py
0: 640x640 4 persons, 1 bus, 29.8ms
1: 640x640 2 persons, 1 tie, 29.8ms
Speed: 7.1ms preprocess, 29.8ms inference, 146.1ms postprocess per image at shape (1, 3, 640, 640)
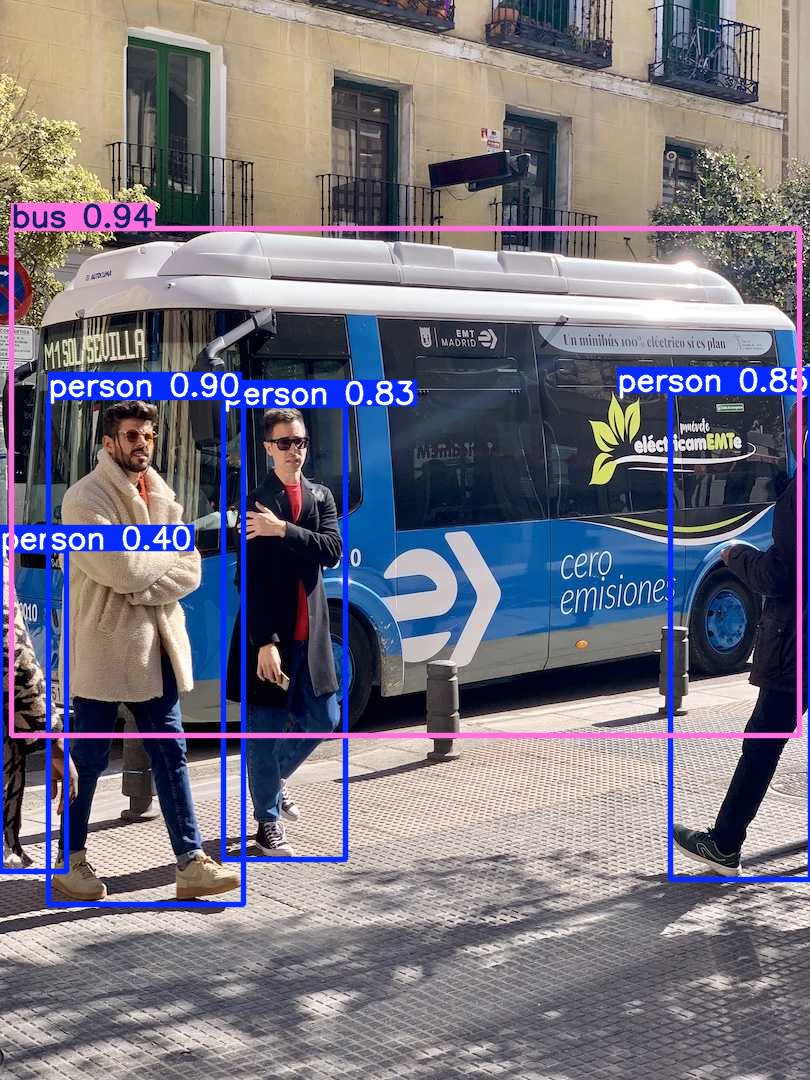
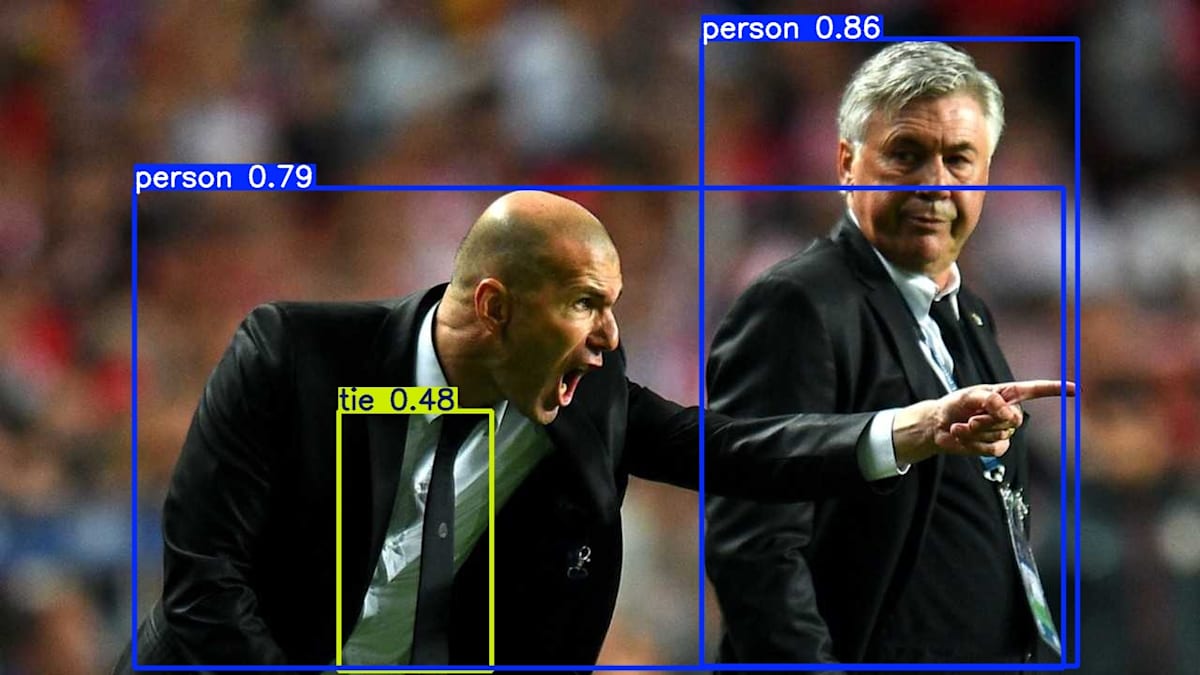
pythonによる実装
ここまでで一通りの動作確認ができましたので、すべてを組み合わせて動画ストリームに対する物体検出を行ってみます。
以下のpythonスクリプトを使います。
import os
import datetime
import json
import gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
import numpy as np
import cv2
from ultralytics import YOLO
# 初期化
Gst.init(None)
class ProcCntl:
def __init__(self):
self.WIDTH = 1536//2
self.HEIGHT = 864//2
self.FRAMERATE = "20/1"
self.model = YOLO('yolo11s.pt')
self.loop = GLib.MainLoop()
# GStreamerのパイプラインを作成
self.input_pipeline = Gst.parse_launch(
f'udpsrc port=5010 caps="application/x-rtp,media=video,encoding-name=H264,payload=96" '
+ f' ! rtph264depay ! h264parse '
+ f' ! nvh264dec '
+ f' ! videoconvertscale ! video/x-raw,format=BGR ,width={self.WIDTH},height={self.HEIGHT} '
+ f' ! appsink name=sink emit-signals=true max-buffers=5 drop=true '
)
self.input_pipeline.set_name("input_pipeline")
self.output_pipeline = Gst.parse_launch(
f"appsrc name=src is-live=true block=true format=TIME do-timestamp=true "
+ f" ! video/x-raw,format=I420, width={self.WIDTH}, height={self.HEIGHT}, framerate={self.FRAMERATE},interlace-mode=progressive "
+ f" ! nvh264enc preset=low-latency zerolatency=true min-force-key-unit-interval=30"
+ f" ! video/x-h264,profile=baseline "
+ f" ! rtph264pay config-interval=1 pt=96 "
+ f" ! udpsink host=janus port=8004 sync=false"
)
self.output_pipeline.set_name("output_pipeline")
src = self.output_pipeline.get_by_name("src")
src.set_property("format","time") # ←重要(つけないとワーニングが出続ける)
# input_pipelineのappsinkの設定
sink = self.input_pipeline.get_by_name("sink")
sink.connect("new-sample", self._on_new_sample, src)
# バスの設定
input_pipeline_bus = self.input_pipeline.get_bus()
input_pipeline_bus.add_signal_watch()
input_pipeline_bus.connect("message", self._handle_bus_messages, self.loop, src)
output_pipeline_bus = self.output_pipeline.get_bus()
output_pipeline_bus.add_signal_watch()
output_pipeline_bus.connect("message", self._handle_bus_messages, self.loop, src)
def connect(self):
# パイプラインを開始
self.input_pipeline.set_state(Gst.State.PLAYING)
self.output_pipeline.set_state(Gst.State.PLAYING)
print("pipeline started")
return self.loop
def close(self):
# パイプラインを停止
self.input_pipeline.set_state(Gst.State.NULL)
self.output_pipeline.set_state(Gst.State.NULL)
print ('close pipeline ')
# バスメッセージを受信した際の処理
def _handle_bus_messages(self, bus, message, loop, src):
t = message.type
src_name = message.src.get_name()
if t == Gst.MessageType.EOS:
print(f"{src_name} received End-Of-Stream")
if src_name == "input_pipeline":
src.emit('end-of-stream')
elif src_name == "output_pipeline":
loop.quit()
# フレーム加工
def _frame_processing(self, frame):
# フレーム加工(物体認識の実行)
results = self.model(frame,verbose=False,conf=0.4,max_det=10)
if len(results) > 0:
# 認識結果を書き出す(枠をつけるなど)
frame2 = results[0].plot()
else:
frame2 = frame.copy()
return frame2
# パイプラインから映像フレームを受信した際の処理
def _on_new_sample(self, sink, src):
sample = sink.emit('pull-sample')
inp_buf = sample.get_buffer()
result, map_info = inp_buf.map(Gst.MapFlags.READ)
if result:
# 映像フレーム取得
frame_bgr = np.ndarray(shape=(self.HEIGHT, self.WIDTH, 3), dtype=np.uint8, buffer=map_info.data)
# フレーム加工
frame_proc = self._frame_processing(frame_bgr)
# output_pipelineに加工した映像フレームをプッシュ
frame_i420 = cv2.cvtColor(frame_proc, cv2.COLOR_BGR2YUV_I420)
out_buf = Gst.Buffer.new_wrapped(frame_i420.tobytes())
out_buf.pts = inp_buf.pts
out_buf.duration = inp_buf.duration
out_buf.dts = inp_buf.dts
src.emit('push-buffer', out_buf)
inp_buf.unmap(map_info)
return Gst.FlowReturn.OK
if __name__ =="__main__":
proc = ProcCntl()
loop = proc.connect()
try:
print("loop run")
loop.run()
except KeyboardInterrupt:
print("--- keybord interrupt --")
pass
print("exit loop")
proc.close()
上記をfilterフォルダ下にfilter.pyという名前で保存して以下を実行します。
$ docker exec -it filter python forward.py
pipeline started
loop run # <-- 5010/UDPで動画ストリームを待っています。
5010/UDPで動画ストリームを待っている状態になりますので、上のテストで実行したように、別のウィンドウから以下のコマンドで動画を流すと物体認識された動画が流れると思います。
$ ffmpeg -re -i test_movie.mp4 \
-c:v h264_nvenc -pix_fmt yuv420p \
-s 1280x720 -an -r 25 -bitrate 2000 -preset fast \
-f rtp rtp://filter:5010
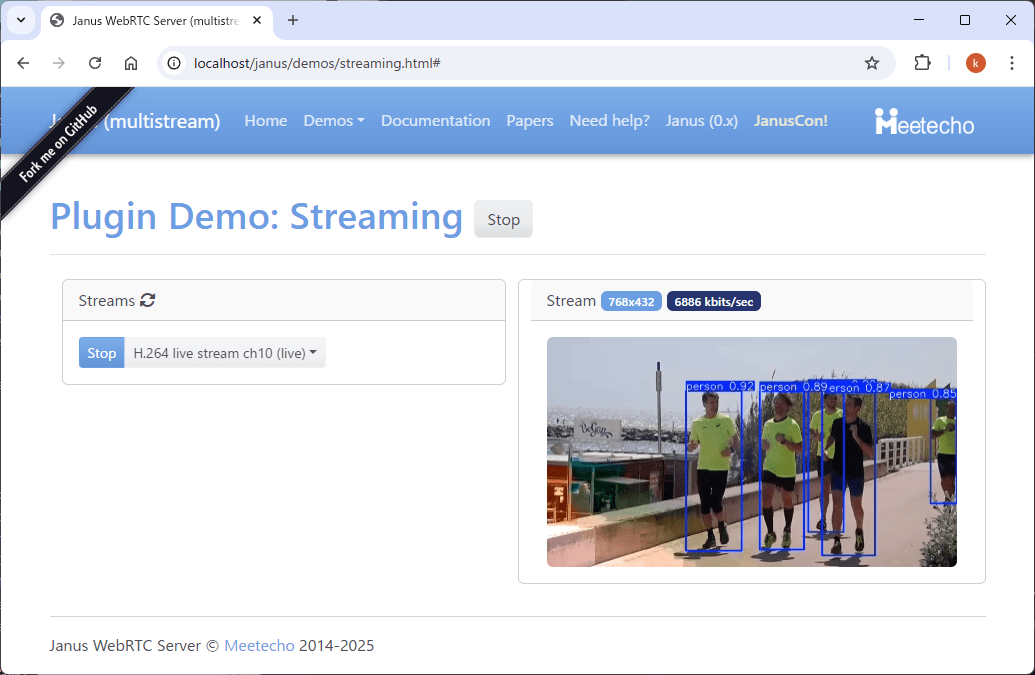
<!-- ### プログラムの説明
動画の各コマ毎に、
sink.connect("new-sample", self._on_new_sample, src)
で、_on_new_sample()が呼び出されます。
_on_new_sample()では、以下の箇所でYOLOを使った画像認識を行っています。
frame_proc = self._frame_processing(frame_bgr)
結果はgstreamerのパイプラインに従って、udpsinkへ送られます。 -->
Discussion