📝
GPU VRAM 24GBでギリギリ動く40BのLLMがあるぞ!(falcon-40B-3bit)


やり方を説明するとTheBlokeさんが書いた手順と一緒になるだけなので手短に。
以下の3bitモデルが24GBでも動かせるように実験的に作ったものだそうなので、試してみた、という記事です^^
モデル
- TheBloke/WizardLM-Uncensored-Falcon-40B-3bit-GPTQ · Hugging Face
- TheBloke/falcon-40b-instruct-3bit-GPTQ · Hugging Face
実行環境
text-generation-webuiという、stable-diffusion-webuiのLLM版を目指して作られたツールがあるので、今回はこれを使いました。
簡単ですが、インストール方法は以下です。
git clone https://github.com/oobabooga/one-click-installers.git
cd one-click-installers
OOBABOOGA_FLAGS="--chat --listen --listen-host 0.0.0.0" bash ./start_linux.sh
<中略>
2023-06-15 10:05:46 INFO:Loading the extension "gallery"...
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
はい、簡単です(^o^)
モデルのダウンロード
起動したら、「Model」タブに移動し、下段にある「Download custom model or LoRA」にhugginface上の名前を入力しダウンロードボタンを押します。
コピペ用
TheBloke/WizardLM-Uncensored-Falcon-40B-3bit-GPTQ
or
TheBloke/falcon-40b-instruct-3bit-GPTQ

ダウンロードが終わったら、まずtrust_remote_codeをONにしてください。
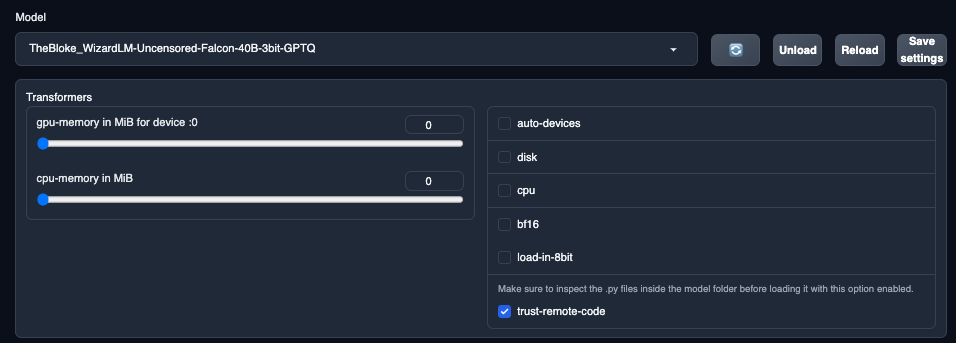
そして更新ボタンを押してモデルを選択してください。

実行する
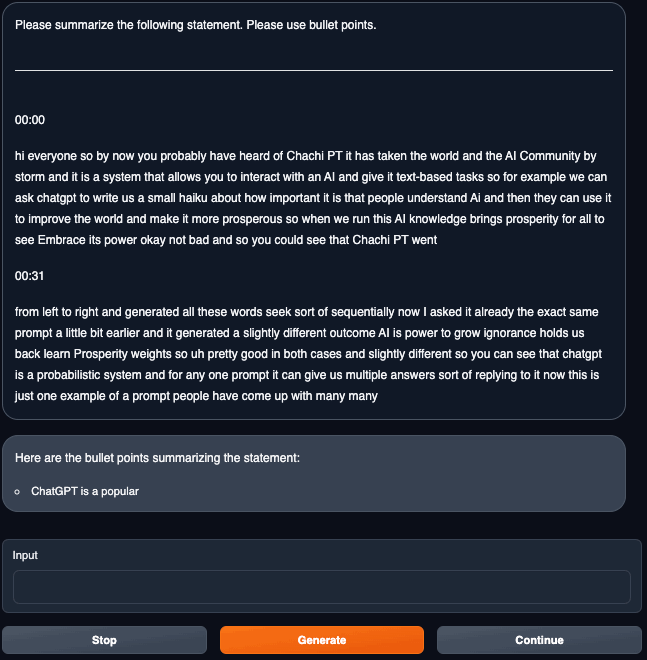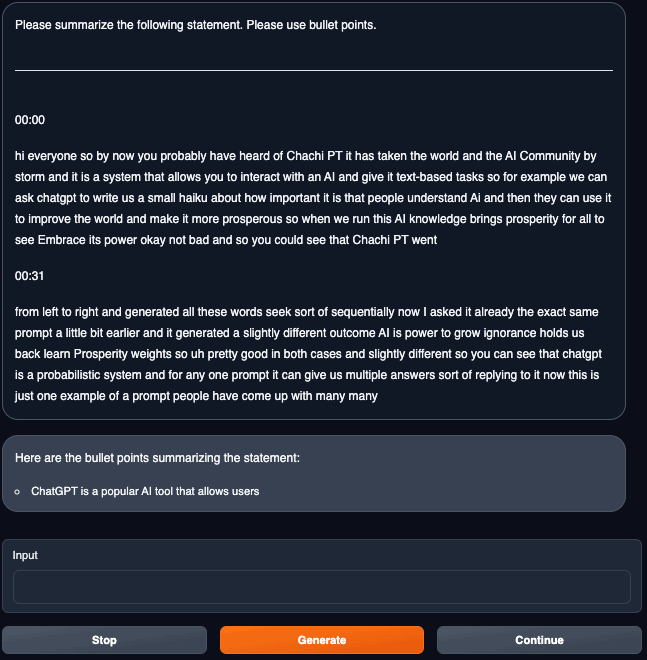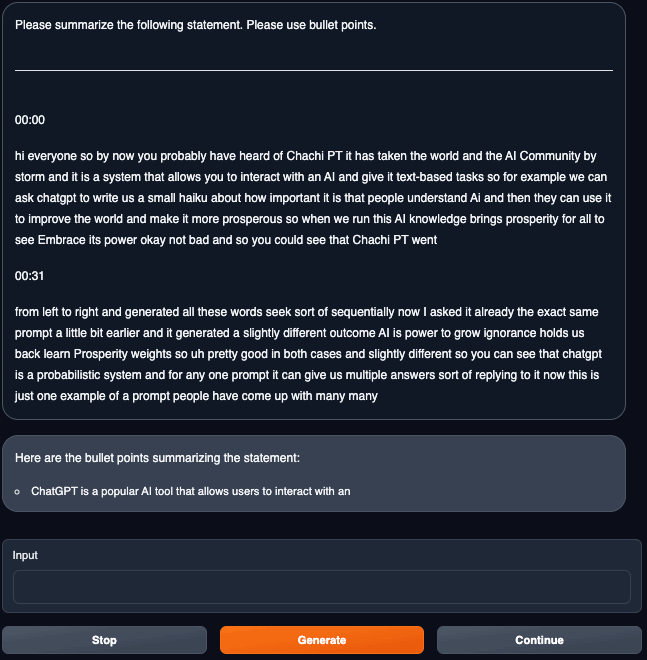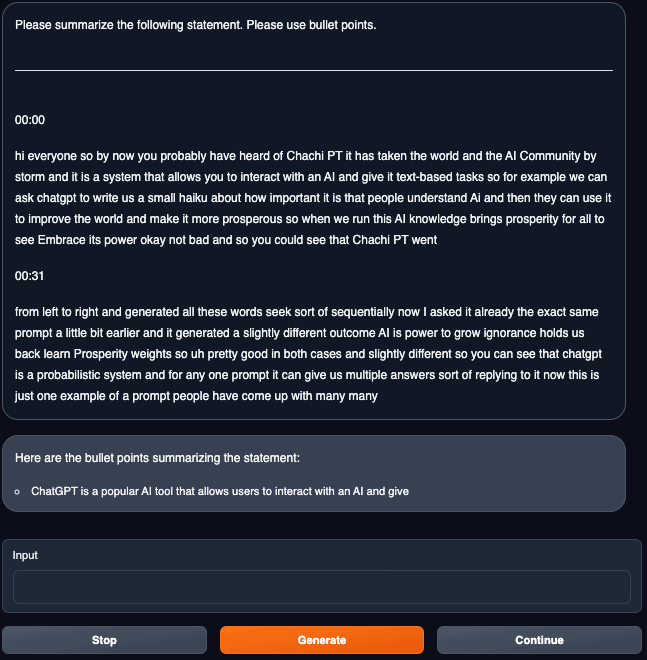
「Text generation」タブに戻って、推論を実行します。
VRAMですが、24GBギリギリかと思ったら19GB台で安定します。
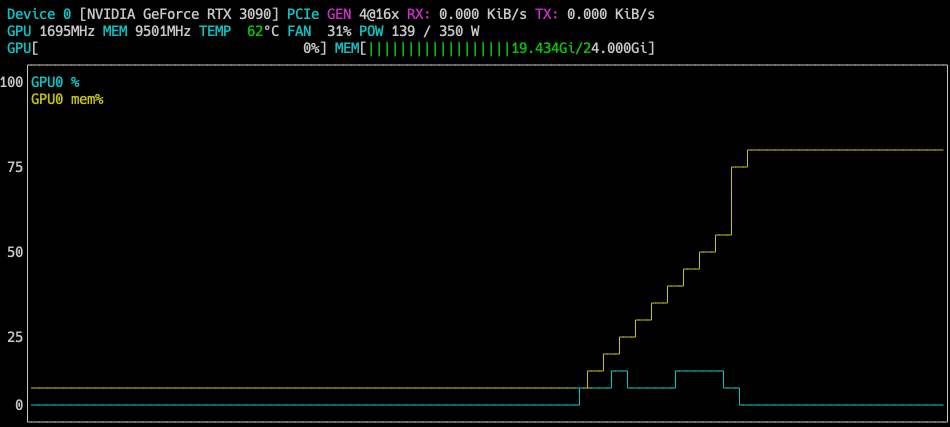
推論中はほぼGPUを100%使います。
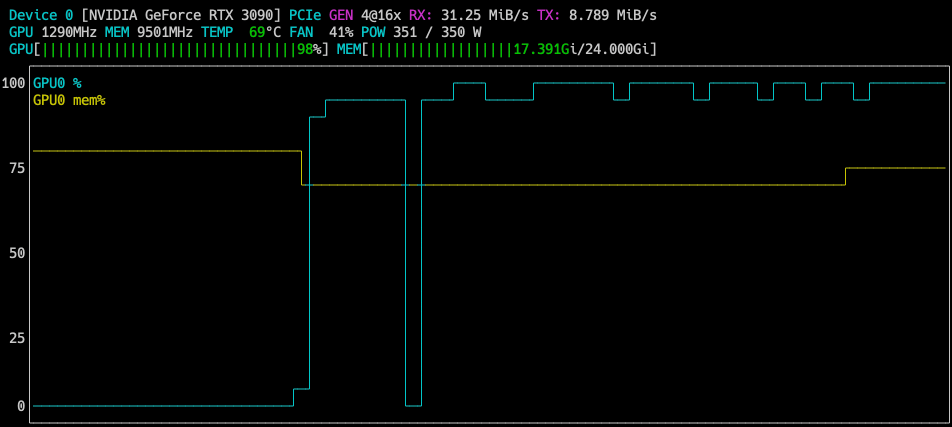
推論は遅いですが、パラメータが40Bのものがご家庭GPUで動いている時点ですごいです(↓一瞬止まっている様に見えるかもですがgifアニです)。
おわり
Discussion