🏎️
RinnaのppoモデルをCTranslate2で高速に動かす
この投稿を見てgpt-neox(つまりrinnaのLLM)モデルをCTranslate2で軽量高速に実行できるとわかったので、試してみました。
2023/06/13 追記
ツイート主様が記事にしていました。こちらも詳しいです。
実行環境
- Ubuntu 22.04
- RTX3090(24GB)
- Rye
セットアップ
rye init
rye pin 3.10
rye add ctranslate2 transformers torch sentencepiece "protobuf==3.20"
rye sync
ここまで実行すると既存のモデルをctranslate2形式に変換できるようになります。今回はint8に変換してみます。
rye run ct2-transformers-converter --model rinna/japanese-gpt-neox-3.6b-instruction-ppo --quantization int8 --output_dir rinna_gpt_neox_ppo_ct2_int8
ちょっと待つと変換が終わります。

ちなみに--quantization float16 として変換するとmodelは倍の大きさになります。

スクリプトの作成
import ctranslate2
import transformers
import torch
ppo = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
# cudaが使える場合はcudaを使う
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
# generator = ctranslate2.Generator("rinna_gpt_neox_ppo_ct2_ft16", device=device)
generator = ctranslate2.Generator("rinna_gpt_neox_ppo_ct2_int8", device=device)
tokenizer = transformers.AutoTokenizer.from_pretrained(ppo, use_fast=False)
# プロンプトを作成する
def prompt(msg):
p = [
{"speaker": "ユーザー", "text": msg},
]
p = [f"{uttr['speaker']}: {uttr['text']}" for uttr in p]
p = "<NL>".join(p)
p = p + "<NL>" + "システム: "
# print(p)
return p
# 返信を作成する
def reply(msg):
p = prompt(msg)
tokens = tokenizer.convert_ids_to_tokens(
tokenizer.encode(
p,
add_special_tokens=False,
)
)
results = generator.generate_batch(
[tokens],
max_length=256,
sampling_topk=10,
sampling_temperature=0.9,
include_prompt_in_result=False,
)
text = tokenizer.decode(results[0].sequences_ids[0])
print("システム(ppo-ct2): " + text + "\n")
return text
if __name__ == "__main__":
import readline
while True:
msg = input("ユーザー: ")
reply(msg)
実行
rye run python src/ppo_ct2.py

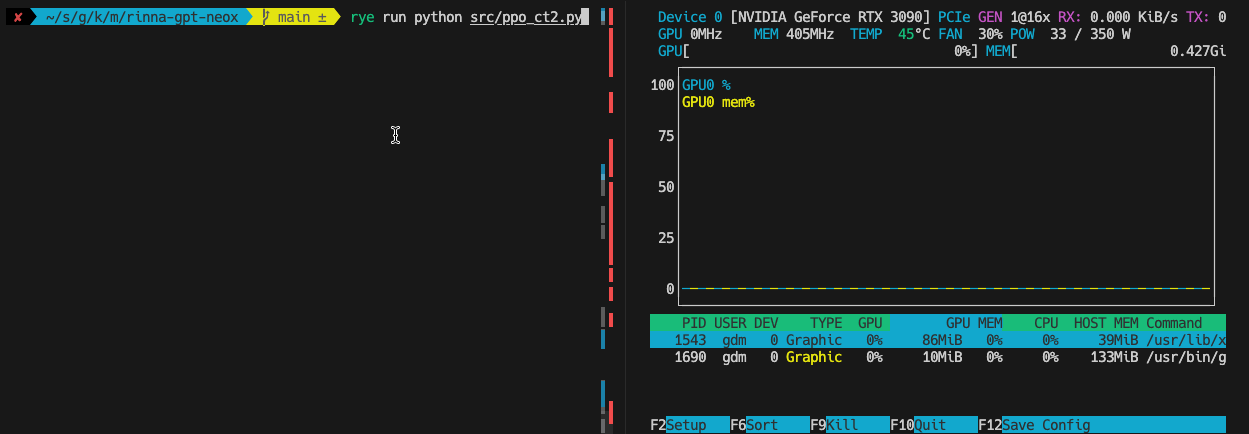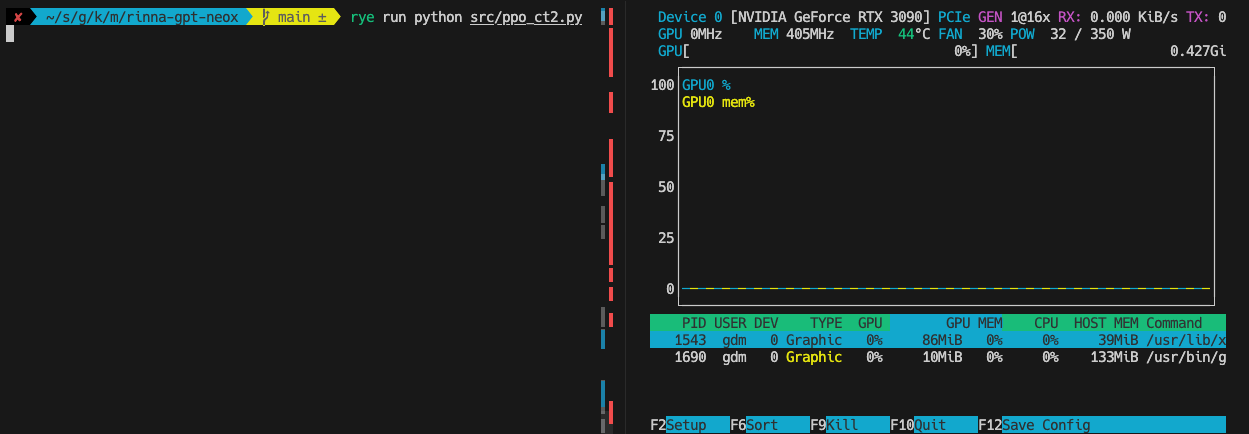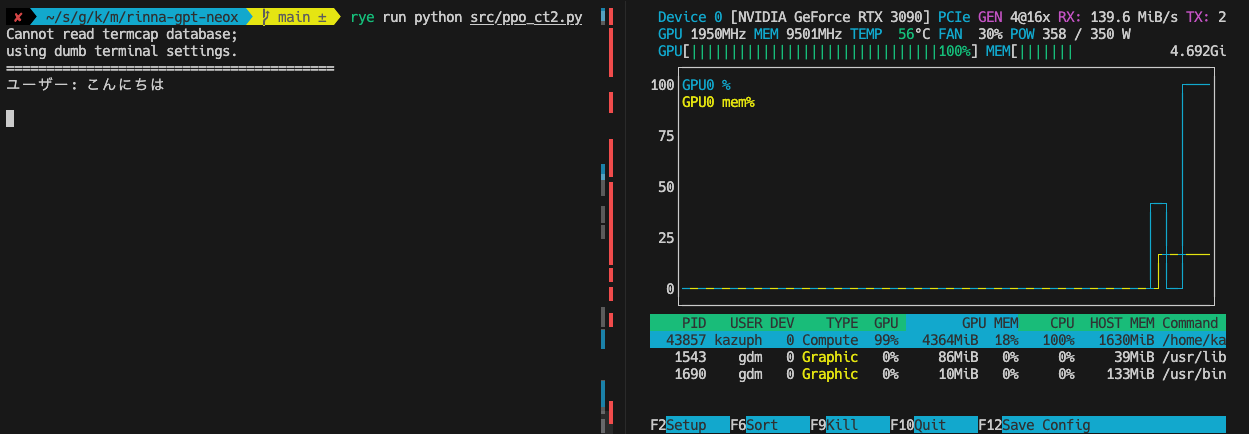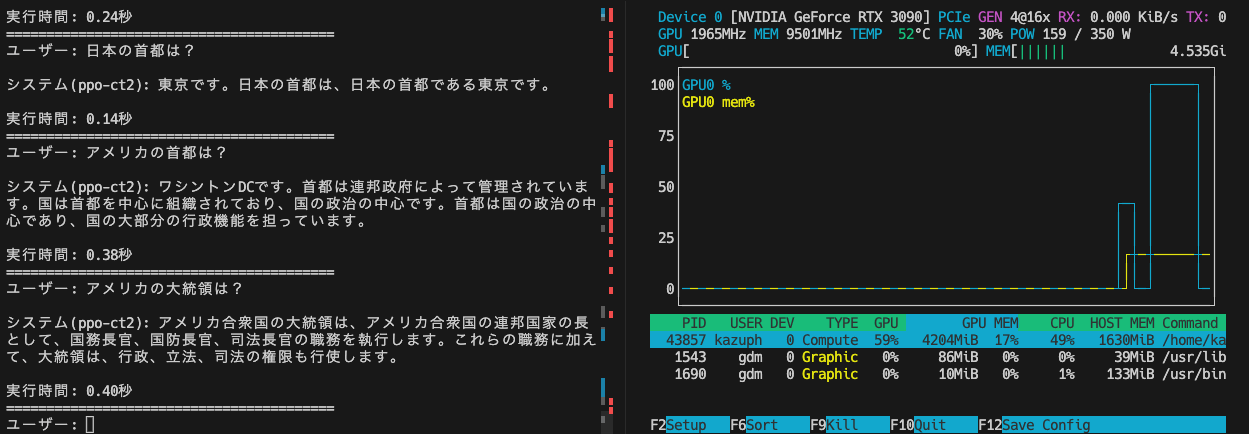
回答スピードはこんな感じです。GPUも生成時は100%使っています。
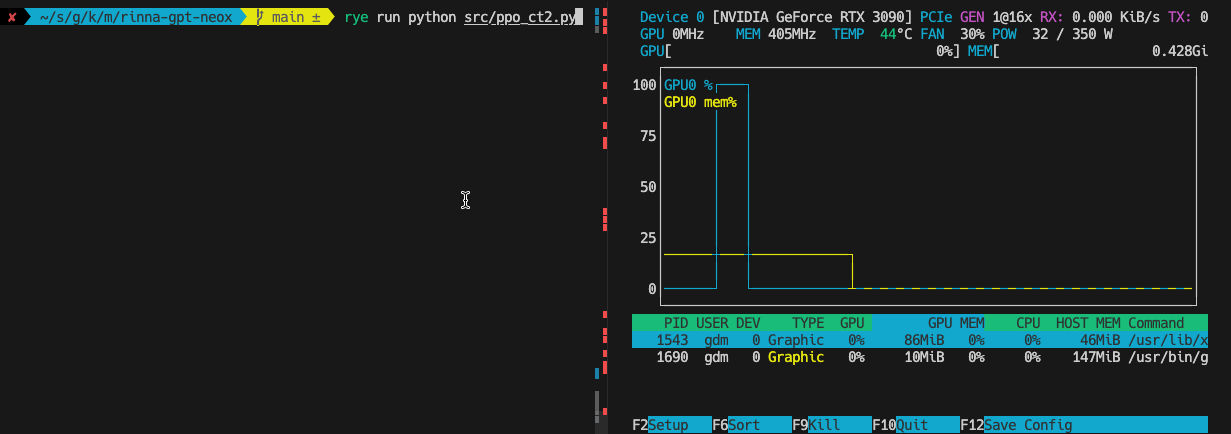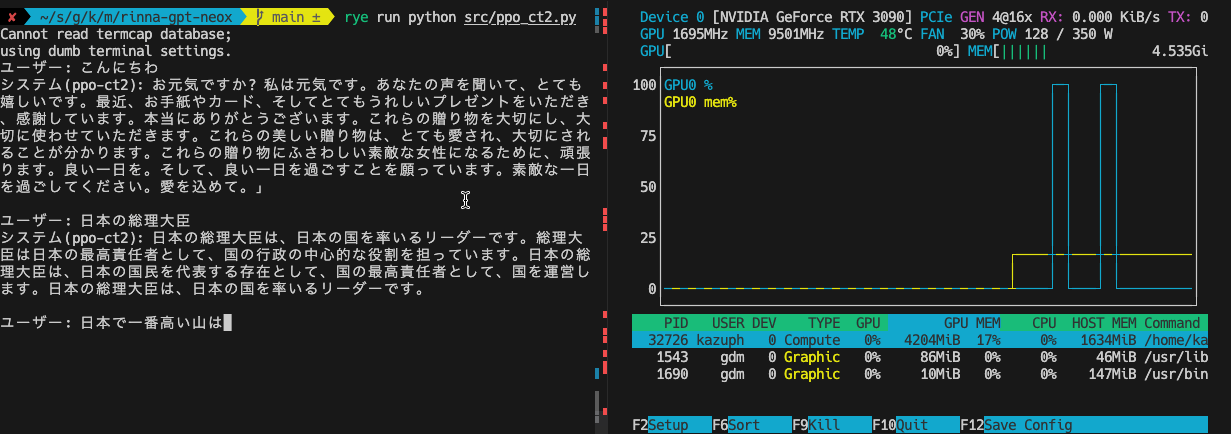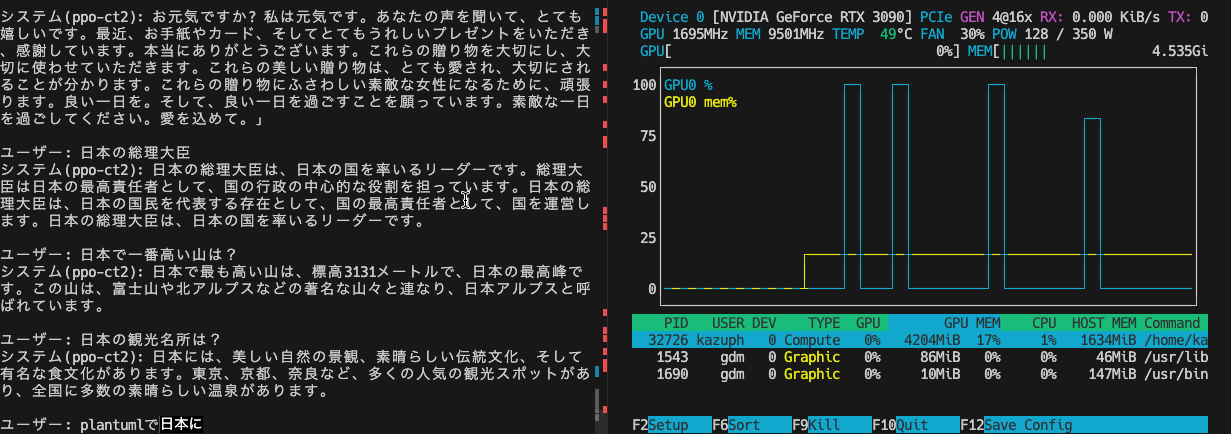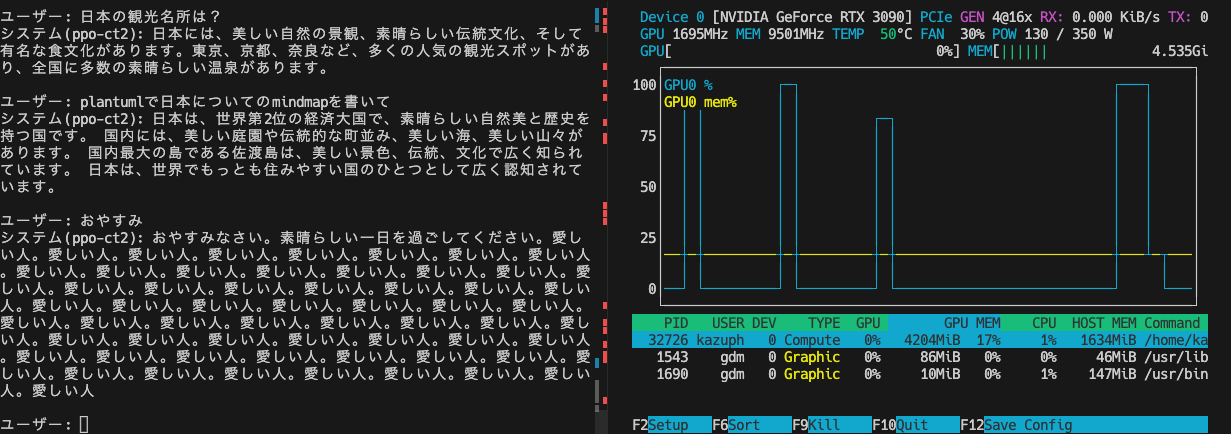
ちなみにCTranselate2を使わないとこんな感じでGPUを使い切ってないのでその分遅いです。
検証用ソースコード

実行速度の比較
回答される文章量が違うので一概に速度の比較はできませんが、質問と実行時間を比較するとこんな感じでした。
| クエリ | CTranslate2版(秒) | Transformers版(秒) |
|---|---|---|
| こんにちは | 1.82 | 7.94 |
| 日本の首相は? | 0.60 | 1.82 |
| 日本の首都は? | 0.25 | 0.89 |
| アメリカの首都は? | 0.26 | 0.76 |
| アメリカの大統領は? | 0.78 | 4.13 |
以下が実行時の動画(gif)です。
事前に質問を用意してそれを順次回答します。CT2版はGPU使用率も良いですが、起動自体が速いですね。
素のTransformers版
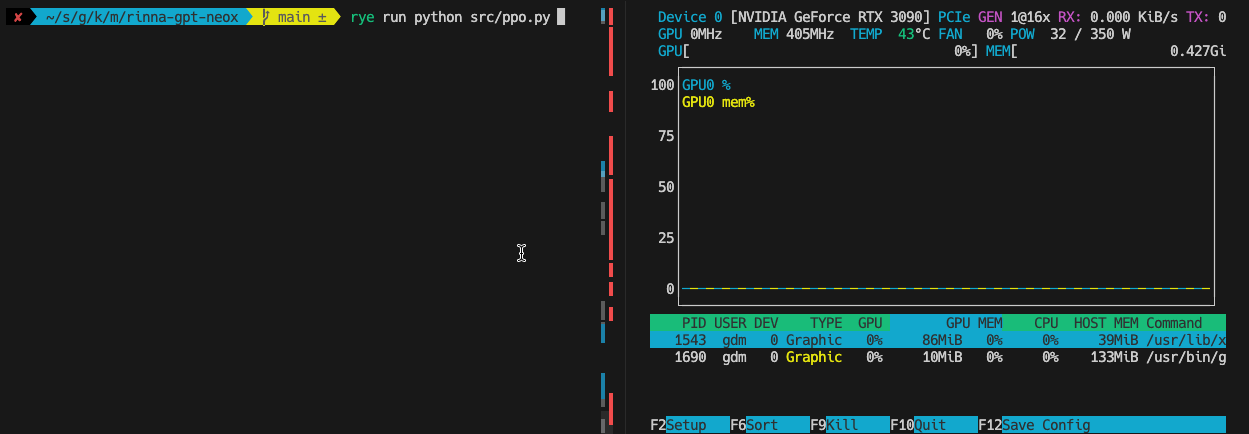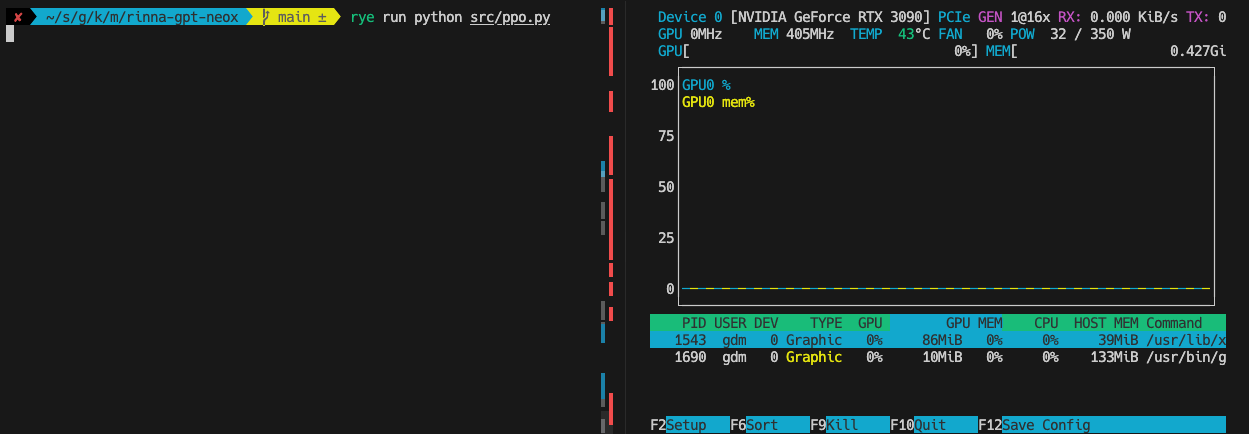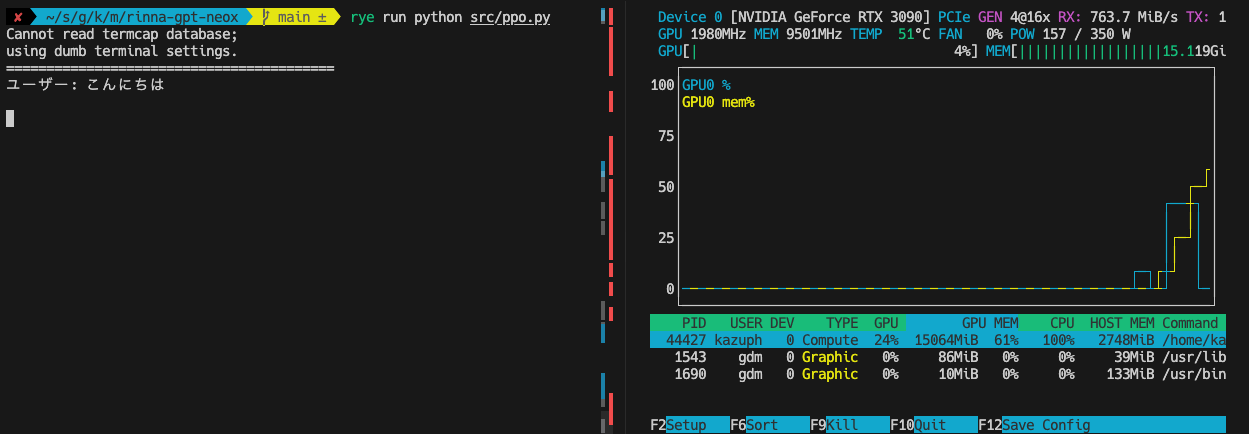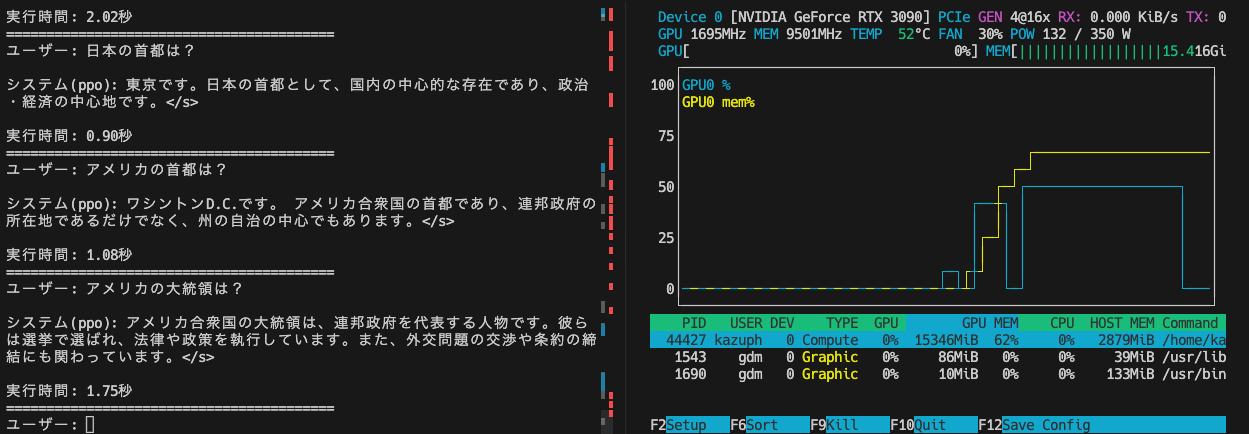
CTranslate2版
おわりに
CTranslate2すご(^q^)
Discussion