👨💻
koboldcppを使ってコーディングつよつよモデルのMPT-30BをRTX3090(VRAM24GB)環境で動かす
今日はこれを動かします。
基本的には上記の冒頭の注意事項に従えば実行までできるのですが、ローカルGPUをできるだけ使うオプションに試行錯誤が必要だったので、その備忘録です。
koboldcppの構築
sudo apt install -y libclblast-dev libopenblas-dev
git clone https://github.com/LostRuins/koboldcpp.git
cd koboldcpp
make LLAMA_OPENBLAS=1 LLAMA_CLBLAST=1
モデルのダウンロード
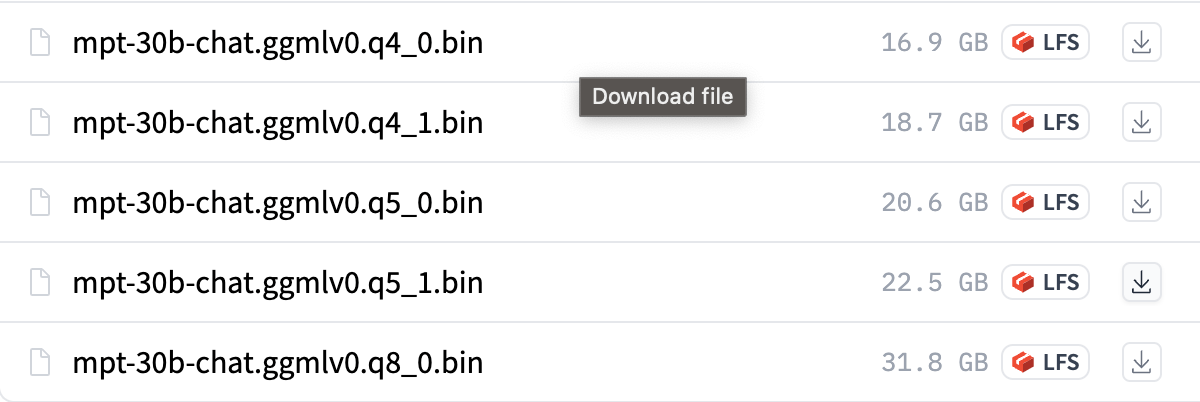
ここから選択します。今回は q4_0 を利用しました。
sudo apt install aria2
mkdir models
cd models
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M -d . https://huggingface.co/TheBloke/mpt-30B-chat-GGML/resolve/main/mpt-30b-chat.ggmlv0.q4_0.bin -o mpt-30b-chat.ggmlv0.q4_0.bin
cd ../
実行する
ここのためだけに記事を書いています。
ただこれが最適化はわかりません。
python3 koboldcpp.py --port 7861 --host 0.0.0.0 --highpriority --threads 8 --blasthreads 4 --contextsize 2048 --smartcontext --stream --blasbatchsize -1 --useclblast 0 0 --gpulayers 120 models/mpt-30b-chat.ggmlv0.q4_0.bin --forceversion 500
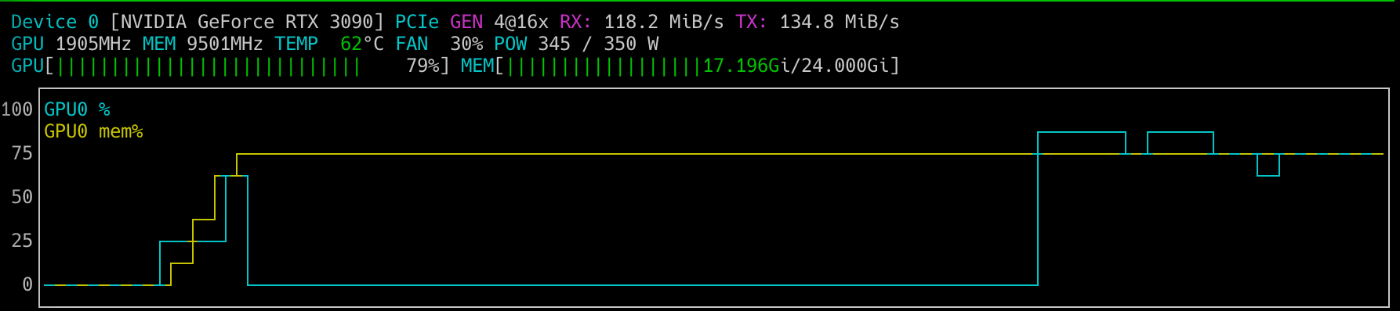
生成中はGPU使用率が最大80%、RAMとVRAMは安定して18GBをキープという感じでした。
肝心のコーディングですが、ブラウザUI上だとインデント等がちゃんとでないので、標準出力の画像を以下に貼ります。

って思ったら、ブラウザUIの設定をいじるとちゃんとマークダウンを解釈してインデントも効くようになりました。
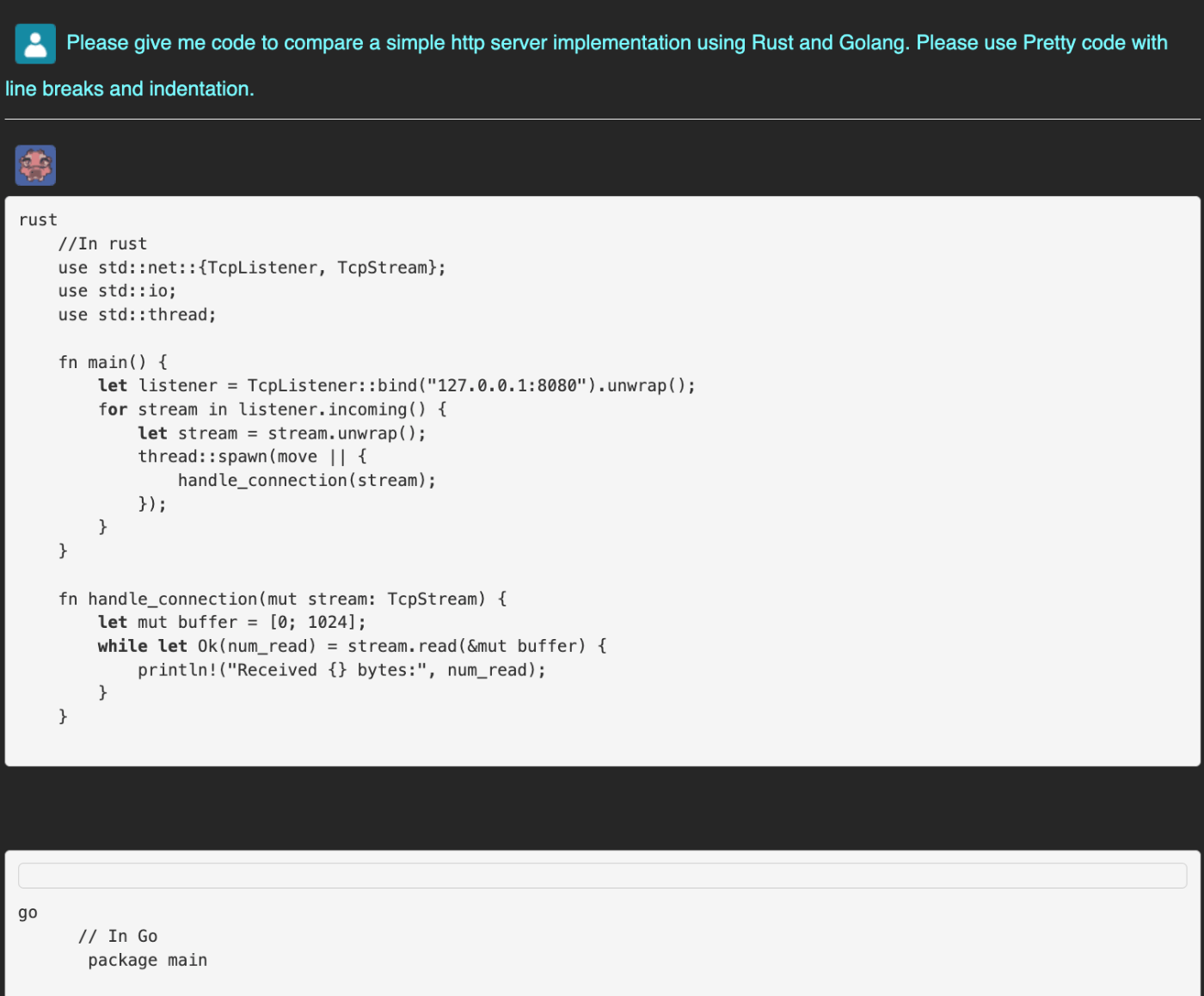
超見づらいですが、Settingの一番したのチェックボックスです。

良いのでは?
おわり
Discussion