👨🎨
WebUIではなく素のDiffusersでLora(safetensors)もLCMもやる
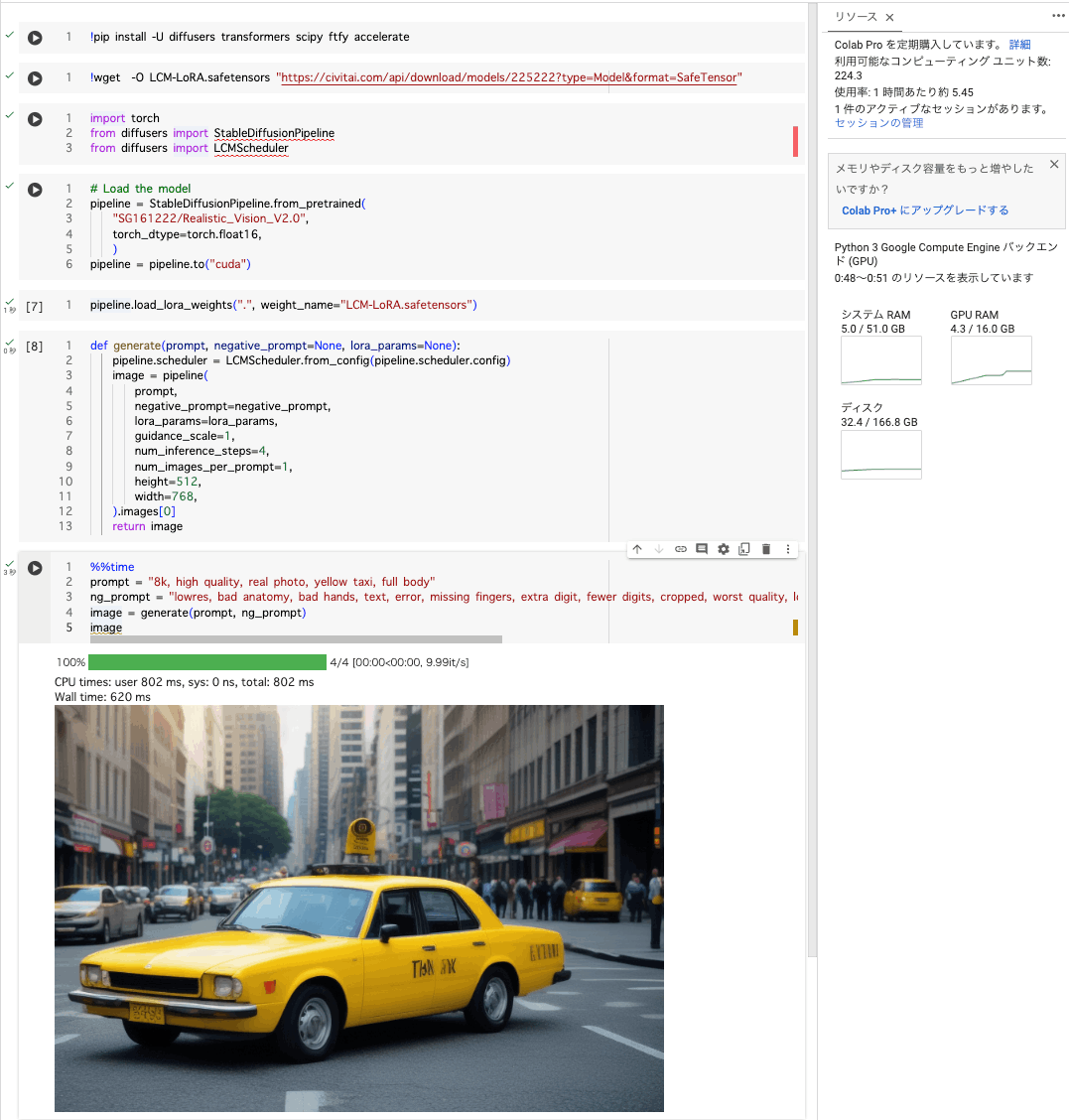
ざっくりこんな感じになります。V100で620msecで生成できます。
Setup
!pip install -U diffusers transformers scipy ftfy accelerate
LoRA modelのロード
今回はsafetensorsをダウンロードします。これはLoraとして指定すると数ステップで画像が生成できるようになります。
!wget -O LCM-LoRA.safetensors "https://civitai.com/api/download/models/225222?type=Model&format=SafeTensor"
モデルをロードする
import torch
from diffusers import StableDiffusionPipeline
from diffusers import LCMScheduler
# Load the model
pipeline = StableDiffusionPipeline.from_pretrained(
"SG161222/Realistic_Vision_V2.0",
torch_dtype=torch.float16,
)
pipeline = pipeline.to("cuda")
pipeline.load_lora_weights(".", weight_name="LCM-LoRA.safetensors")
以前はsafetensorsのままのLoraをロードするのは大変だったと思うのですが、今は1行でスッキリ書けます。
生成用の関数を定義
def generate(prompt, negative_prompt=None, lora_params=None):
pipeline.scheduler = LCMScheduler.from_config(pipeline.scheduler.config)
image = pipeline(
prompt,
negative_prompt=negative_prompt,
lora_params=lora_params,
guidance_scale=1,
num_inference_steps=4,
num_images_per_prompt=1,
height=512,
width=768,
).images[0]
return image
スケジューラーにはLCMを指定しています。stepsも4にしてます。
画像生成する
promptを渡して生成してみましょう。
prompt = "8k, high quality, real photo, yellow taxi, full body"
ng_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"
image = generate(prompt, ng_prompt)
image

わずか4stepsでそれなりの画像が生成されたことがわかります。
はっや!
以上です。
参考
Discussion