Scala の処理の性能を計測し、改善を目指す


概要
GraphDB のデータを RDB のデータに変換する、 GraphDB2RDB という OSS を開発しています。
このスクリプトの走査対象は GraphDB に格納されているデータ (Vertex/Edge) になるため、実行環境によっては超大量のデータを取り扱う必要があります。
本稿では、 GraphDB2RDB の性能改善を目指す上で確認した内容を紹介致します。
対象読者
以下のような方を想定しています。
- Scala で実装された処理の性能改善に取り組んでいる方
注意
本記事は Scala で実装された処理に焦点を当てており、その他の要素( GraphDB など)の性能改善は取り扱っておりません。
また、紹介しているアプローチは全て実際に利用しているわけではなく、有意な改善差が認められなかったり逆に悪化したものは導入しておりません。
予めご了承ください。
今回の改善対象の設計
GraphDB2RDB では GraphDB から Vertex や Edge を取得する方法 (ユースケース) はいくつか実装しておりますが、今回は下記ロジック(UsingSpecificKeyList)の改善を目指しております。
- 特定の vertex を取得し、辞書に登録します。
-
- で取得した vertex に紐づく edge を全て取得し、辞書に登録します。
-
- で取得した edge に対して、紐づく vertex を全て取得し、辞書に登録します。
-
- で取得した vertex のうち、辞書に登録されていない vertex に紐づく edge を全て取得し、辞書に登録します。
-
- で取得した edge のうち、辞書に登録されていない edge に紐づく vertex を全て取得し、辞書に登録します。
- 以下、 4. と 5. を、新規に取得する結果がなくなるまで繰り返します。
以下に、シーケンス図をまとめております。
その他の設計資料は wiki にまとめております。
シーケンス図
現状の認識
性能改善を目指す上で第一に行ったことは、現状を正確に認識することでした。
具体的には、下記を実施し「開発環境構築直後から性能改善への取り組みができる状態になること」を目指しました。
- 性能改善が必要な環境の構築 (大量のテストデータの自動生成)
- ボトルネックの特定 (プロファイラの取得)
大量のテストデータの自動生成
GenerateTestDataというスクリプトを実装し、ランダムな Vertex および Edge を生成できるようにしました。
生成するデータ量の目安を関数で渡せるようにすることで、検証したいケースに合わせて生成するデータ量を調整できるようにしております。
% docker compose up -d
% sbt "runMain GenerateTestData"
プロファイラの取得
GraphDB2RDBを開発する際、 IntelliJ IDEA で開発しています。
こちらの IDE では実行時や実行中にプロファイラを取得する機能があります。
例えば、画像中の "Profile 'Main' with 'IntelliJ Profiler'" を選択すると、他に特別な手続きをせずに実行時のプロファイラを取得することができます。

処理実行後、処理したメソッドごとの実行時間やメモリ使用量を確認できます。
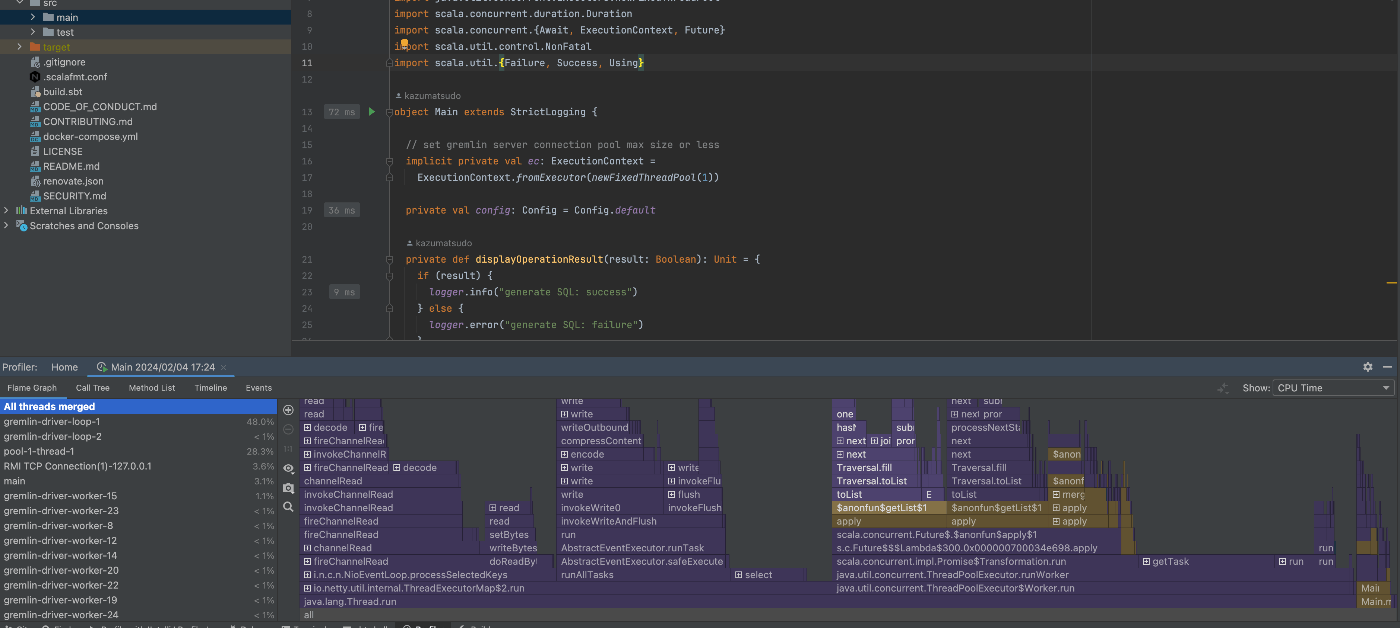
以降、性能改善のアプローチを実施後にプロファイラを比較して、有意な改善が認められるかを確認します。
確認内容
メソッドごとの実行時間を確認した際、概ね以下のいずれかまたは両方が理由になっているケースが多いと思います。
- 時間のかかる処理の呼び出しがある
- 扱う要素数が多い
それぞれのケースごとに対策を検討します。
時間のかかる処理の呼び出しがあるケースでの対処
時間のかかる処理として、例えば DB にアクセスする処理が挙げられます。
こういった処理は非同期処理にすることができると、処理が完了するまでに他の処理を進行させることができるため、処理が改善する可能性があります。
非同期処理を実現する簡単なアプローチは、 Future を使用することです。
// 何らかの処理に対して非同期処理を実現したい場合
val resultFuture: Future[T] = Future {
// 時間のかかる処理
// T という型を返却する、としています。
}
// 何らかのリストの各要素に対して非同期処理を実現したい場合
val resultFuture: Future[List[T]] = Future.sequence {
xxxList.map { xxx =>
Future {
// 時間のかかる処理
// T という型を返却する、としています。
}
}
}
上記のように Future で囲まれた処理は非同期に実行され、実行結果を待つ間に他の処理を進行させることが可能です。
なお Future で定義されている非同期処理は、渡される ExecutionContext の定義に従い実行タイミングが決定されます。
(ExecutionContext に関連する話題 (スレッドプールなど) は、ここでは割愛致します)
扱う要素数が多いケースでの対処
複数の要素をまとめて扱うデータ構造のことを「コレクション」と言います。
1つ1つの処理時間は大したことがなくても、コレクション内の要素数が増えることで実行時間が大きくかかるケースがあります。
これについて、下記のような対策をそれぞれ検討します。
- 要素数、使用するメソッドに適したコレクションを選択する (適切なコレクションの使用)
- 何度もコレクションを加工する場合、都度コレクションを構築せず最後に1度構築する (ビューの使用)
- コレクションのメソッドを並列に実行する (並列コレクションの使用)
適切なコレクションの使用
コレクションには大まかに、順序付きの要素を表現する「Seq」、一意の集合を表す「Set」、一意のキーに対する値の集合を表す「Map」があります。
これらはそれぞれ trait であり、それぞれ複数種類の実装が存在します。
例えば、 「Seq」には「Vector」、「NumericRange」、「Range」、「List」、「Stack」、「Stream」、「Queue」といったような実装が存在します。
// Seq の型名を返却します。
def printType(target: Seq[_]): String = target match {
case indexedSeq: IndexedSeq[_] =>
indexedSeq match {
case _: Vector[_] => "Vector"
case _: NumericRange[_] => "NumericRange"
case _: Range => "Range"
case _ => "IndexedSeq のその他の実装"
}
case linearSeq: LinearSeq[_] =>
linearSeq match {
case _: List[_] => "List"
case _: Stream[_] => "Stream"
case _: LazyList[_] => "LazyList (2.13.0 から Stream の代わりに LazyList を使用することが推奨されています)"
case _: Queue[_] => "Queue"
case _ => "LinearSeq のその他の実装"
}
}
val vector = Vector.empty
// Vector と表示されます。
println(printType(vector))
val seq = Seq.empty
// List と表示されます。 Seq のデフォルトの実装は List になります。
println(printType(seq))
それぞれの実装によって、コレクションへの処理に対する性能特性 (計算量) が異なります。
例えば、 Seq の実装に「List」と「Vector」がありますが、コレクション内の末尾に要素を追加する際、「List」はコレクションサイズに比例した実行時間になりますが、「Vector」は実質定数時間に完了します。
以下に、効果がある例を示します。
// 末尾に1を追加する際にかかった時間(単位はミリ秒)を返却します。
def calculateTime(target: Seq[Int]): Long = {
val startTime = System.nanoTime()
val _ = target.appended(1)
val endTime = System.nanoTime()
(endTime - startTime) / 1000000
}
// 要素数が1億の List を生成します。
val seq = Seq.fill(100000000)(0)
// 2120 (実行環境によって異なった値が返却されます。)
val milliseconds = calculateTime(seq)
// 要素数が1億の Vector を生成します。
val vector = Vector.fill(100000000)(0)
// 0 (実行環境によって異なった値が返却されます。)
val milliseconds = calculateTime(vector)
そのため、コレクションに含まれる要素数がどのくらいになるか、どのような操作を行うかを想定して、適切なコレクションを選択することが重要です。
それぞれのコレクションの操作に対する実行時間は 性能特性 をご確認ください。
ビューの使用
コレクションの処理には、新たなコレクションを構築するものがあります(例: map や filter など)。
このコレクションの構築に対して「ビュー」というコレクションを用いることで、その場で新たなコレクションを構築せず必要に応じて構築することが可能になります。
コレクションの操作を複数のメソッドの呼び出しで行う場合、毎回新たなコレクションを構築せずに各処理を合成して1度だけコレクションを構築することで、不必要な処理を実行せずパフォーマンスが改善することがあります。
以下に、効果がある例を示します。
// 全要素に1を加算し、先頭10件の値の合計を算出する処理の時間(単位はミリ秒)を返却します。
def calculateTime(target: Iterable[Int]): Long = {
def addOneAll(t: Iterable[Int]): Iterable[Int] = t.map(_ + 1)
def getFirstTen(t: Iterable[Int]): Iterable[Int] = t.take(10)
val startTime = System.nanoTime()
val processedTarget1 = addOneAll(target)
val processedTarget2 = getFirstTen(processedTarget1)
val _ = processedTarget2.sum
val endTime = System.nanoTime()
(endTime - startTime) / 1000000
}
// 要素数が1億の Vector を生成します。
val vector = Vector.fill(100000000)(0)
// 435 (実行環境によって異なった値が返却されます。)
val vectorMilliseconds = calculateTime(vector)
// 要素数が1億の Vector のビューを生成します。
// コレクションに対して .view を呼び出すことで、コレクションのビューの生成が可能です。
val vectorView = Vector.fill(100000000)(0).view
// 1 (実行環境によって異なった値が返却されます。)
val vectorViewMilliseconds = calculateTime(vectorView)
注意点として、ビューの各要素はコレクションの構築が行われるまで処理されないため、コレクションの構築後の値を使用してさらに処理を行う場合、新たな処理を行う前にコレクションを構築する必要があります。
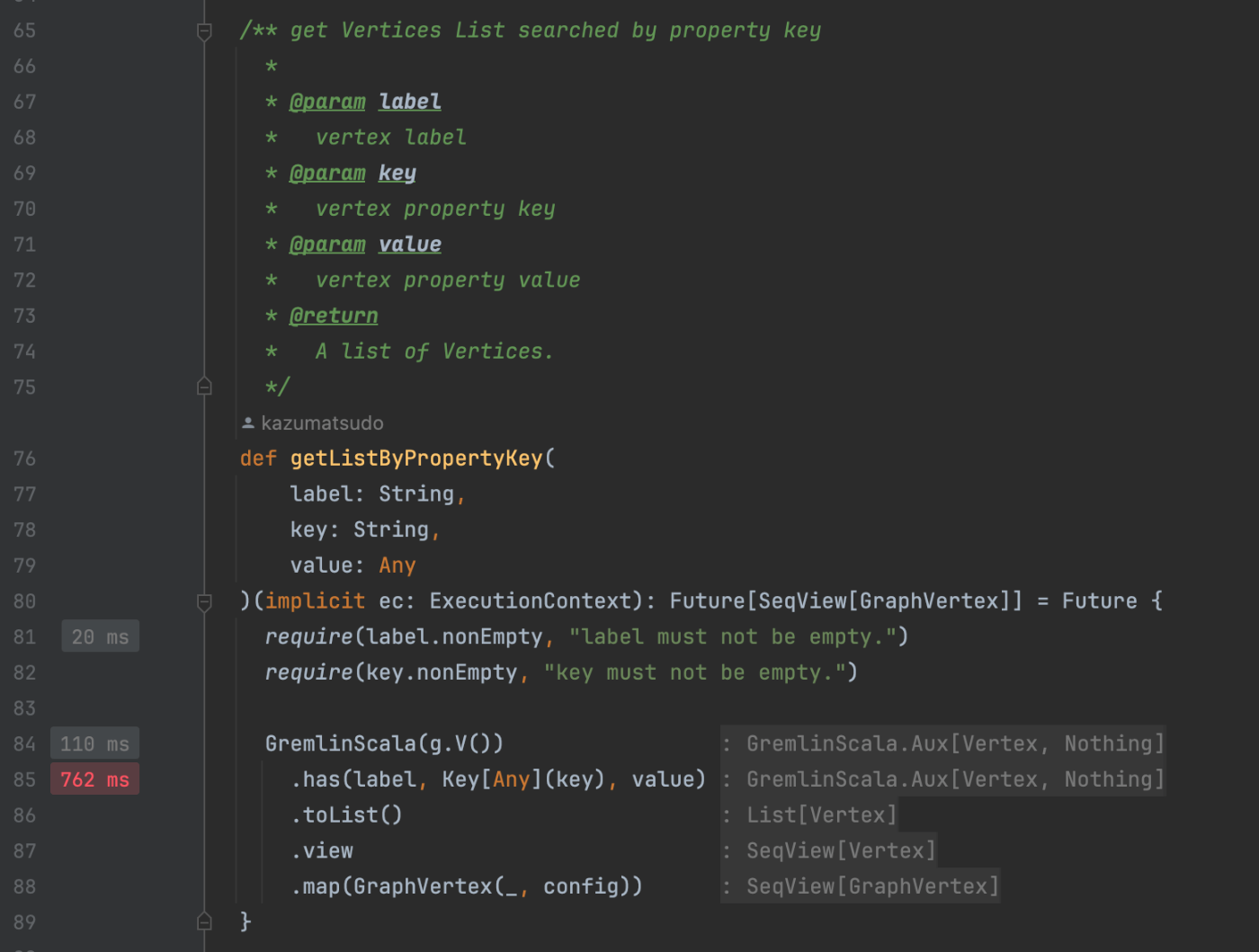
例として、 GraphDB2RDB にて Vertex と Edge を再帰的に取得する実装にて、ビューのコレクション構築を強制している実装があります。
ここでビューのコレクション構築 (リンク先の L57 および L63 の.toIndexedSeq) を呼び出さないと、 Vertex を再帰的に取得する処理が呼び出されず、処理が終了してしまいます。
並列コレクションの使用
Scala3 や Scala2.13 では、Scala parallel collectionsというモジュールを追加すると、並列コレクションを使用することができます(Scala2.10 から 2.12 では標準で含まれています)。
並列コレクションを利用すると、コレクションに実装されているメソッドを並列に処理することができます。
以下に、効果がある例を示します。
// 全要素の合計を算出する処理の時間(単位はミリ秒)を返却します。
def calculateVectorTime(target: Vector[Int]): Long = {
val startTime = System.nanoTime()
val _ = target.sum
val endTime = System.nanoTime()
(endTime - startTime) / 1000000
}
// 全要素の合計を算出する処理の時間(単位はミリ秒)を返却します。
def calculateParVectorTime(target: ParVector[Int]): Long = {
val startTime = System.nanoTime()
val _ = target.sum
val endTime = System.nanoTime()
(endTime - startTime) / 1000000
}
// 要素数が1億の Vector を生成します。
val vector = Vector.fill(100000000)(2)
// 696 (実行環境によって異なった値が返却されます。)
val vectorMilliseconds = calculateVectorTime(vector)
// 要素数が1億の ParVector を生成します。
import scala.collection.parallel.CollectionConverters.VectorIsParallelizable
val parVector = Vector.fill(100000000)(2).par
// 183 (実行環境によって異なった値が返却されます。)
val parVectorMilliseconds = calculateParVectorTime(parVector)
注意点として、並列処理により計算の順序が保証されないため、結合則が成立しない処理の結果は毎回異なります。
val parVector = Vector.fill(100000000)(2).par
// 0 (実行ごとに異なった結果が返却されます。)
println(parVector.reduce(_ - _))
// 28124984 (実行ごとに異なった結果が返却されます。)
println(parVector.reduce(_ - _))
// 31249980 (実行ごとに異なった結果が返却されます。)
println(parVector.reduce(_ - _))
並列コレクションの処理は、結合則が成立する処理に限定して実行する必要があります。
終わりに
本稿では、 GraphDB2RDB の性能改善を目指す上で確認した内容を紹介致しました。
Scala で実装された処理の性能改善に取り組んでいる方にとってこの記事が参考になりましたら、これ以上の喜びはありません。
また、上記に紹介した改善アプローチ以外の内容をご存じの方は、コメントいただいたり GraphDB2RDB に修正提案の PR を実装くださいますと幸甚に存じます。
Discussion