OpenAI の Swarm で 画像認識したり、処理の移譲をするメモ
OpenAIが作成した実験的なマルチエージェントシステムのためのフレームワークですね。
詳細は、サンプル見たり、他の方の投稿記事を探してみると良いと思います。
実験的なサンプルフレームワークで、本番環境での使用は想定されていないそうです。
ちょっと残念👀
Swarmの雰囲気
ざっくり概要を言うと、複数のエージェントや関数を定義して、それら間で移譲しながら処理を進めるシステムみたいな感じですかね?
サンプルをちょっと改造して試してみた感じは以下↓
from swarm import Swarm, Agent
client = Swarm()
english_agent = Agent(
name="英語エージェント",
model="gpt-4o-mini",
instructions="あなたは英語エージェントです。英語だけで喋ってください。",
)
spanish_agent = Agent(
name="スペイン語エージェント",
model="gpt-4o-mini",
instructions="あなたはスペイン語エージェントです。スペイン語だけで喋ってください。",
)
chinese_agent = Agent(
name="中国語エージェント",
model="gpt-4o-mini",
instructions="あなたは中国語エージェントです。中国語だけで喋ってください。",
)
def transfer_to_spanish_agent():
"""スペイン語を話すユーザーならば処理を移譲する"""
print('スペイン語')
return spanish_agent
def transfer_to_chinese_agent():
"""中国語を話すユーザーならば処理を移譲する"""
print('中国語')
return chinese_agent
english_agent.functions.append(transfer_to_spanish_agent)
english_agent.functions.append(transfer_to_chinese_agent)
messages = [{"role": "user", "content": "Hello. how are you? what is your name?"}]
response = client.run(agent=english_agent, messages=messages)
print(response.messages[-1]["content"])
実行結果↓

messages = [{"role": "user", "content": "Hola. ¿Como estás? ¿Cuál es su nombre?"}]
response = client.run(agent=english_agent, messages=messages)
print(response.messages[-1]["content"])
実行結果↓

messages = [{"role": "user", "content": "你好。你好吗?你叫什么名字?"}]
response = client.run(agent=english_agent, messages=messages)
print(response.messages[-1]["content"])
実行結果↓

移譲先はエージェントだけじゃなくて、関数にもできるようです(移譲と言うかFunction Calling)
from swarm import Swarm, Agent
client = Swarm()
def get_weather_mock(location) -> str:
return "{'temp':67, 'unit':'F'}"
agent = Agent(
name="エージェント",
instructions="あなたは親切なエージェントです。",
functions=[get_weather_mock],
)
messages = [{"role": "user", "content": "NYCの天気はどうですか?"}]
response = client.run(agent=agent, messages=messages)
print(response.messages[-1]["content"])
実行結果↓

GPT4o が(現時点で)苦手な位置検出処理等を移譲したい
GPT4o(or GPT4o mini)の画像認識の性能は凄いですが、まだまだ苦手な認識内容もあります。
一例をあげると、詳細な座標の取得などです↓
(下の例はそもそも座標の質問に答えてないやんけ。。。というツッコミもありますが。。。)
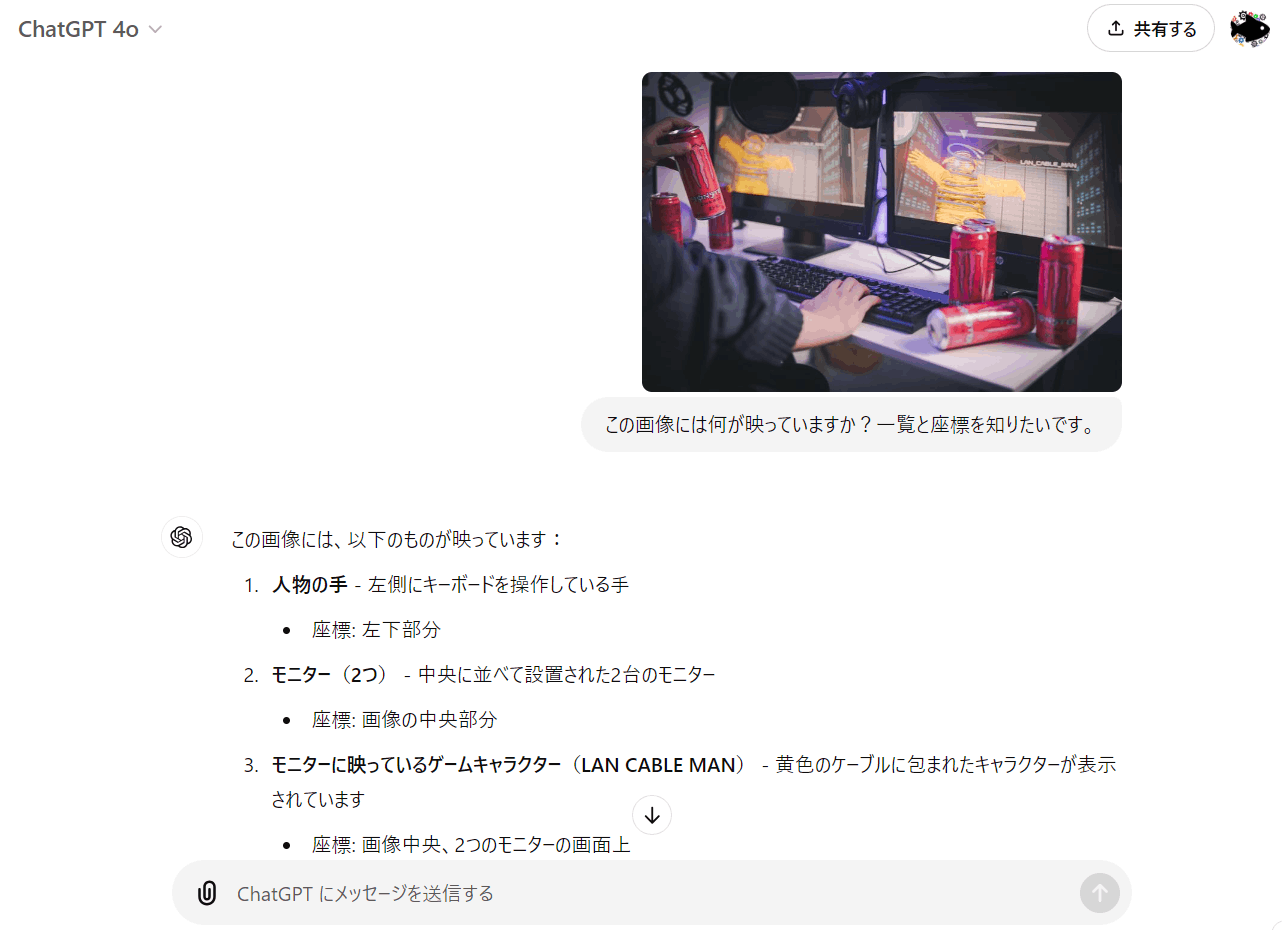
今回はお試しで、座標取得系の処理を依頼されたときは、物体検出が得意なVLMのFlorence-2に処理を移譲したいと思います。
Florence-2で検出した例↓

この手の小細工も、そのうち必要なくなるくらい性能向上するかもですが👀
以降の処理はColaboratoryで動くノートブックとして公開しています
試してみたい方はノートブックを開いて、上から順に実行していってください。
パッケージインストール
!pip install -q git+https://github.com/openai/swarm.git
!pip install -q -U transformers flash_attn timm
1行目はSwarmのインストールですね。
2行目はFlorence-2に必要なパッケージのインストールです。
OpenAIキー設定
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
Swarmは内部的にOpenAIのAPIを呼び出すため、Colaboratoryのシークレットにキーを設定してください。
サンプル画像ダウンロード
(コード省略)
今回は、ぱくたそ様の ゲームしながらピンモンがぶ飲み をお借りしています。

Florence-2 準備&動作確認
(コード省略)
Florence-2 の準備とか動作確認をしています。今回の本筋じゃないのでZennでは、コードは省略します。必要があればノートブックを確認してください。
Swarmを用いた画像認識の処理移譲サンプル
def get_dense_region_caption(context_variables):
'''バウンディングボックスの座標が必要な場合に処理を移譲する'''
print('【GPT-4o miniからFlorence-2に処理を移譲します】\n')
base64_image = context_variables.get("base64_image", None)
# Base64データを取り除く部分を削除してデコード
base64_image_str = base64_image.split(',')[1] # 'data:image/jpg;base64,'を除く
image_data = base64.b64decode(base64_image_str)
# バイナリデータをNumPy配列に変換しデコード
np_array = np.frombuffer(image_data, np.uint8)
bgr_image = cv2.imdecode(np_array, cv2.IMREAD_COLOR)
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
# 推論
prompt = "<DENSE_REGION_CAPTION>"
result = run_inference(florence_2_model, florence_2_processor, rgb_image, prompt, device=device)
return result
Florence-2での詳細物体検出を行うための関数定義です。
エージェントから必要に応じて、この関数へ処理が移譲されます。
画像を受け渡す方法がイマイチ思いつかなかったため、context_variablesと言う仕組みで渡しています。
from swarm import Swarm, Agent
# クライアント準備
client = Swarm()
# エージェント準備 & 関数追加
gpt_4o_mini_agent = Agent(
name="GPT-4o-mini Agent",
model="gpt-4o-mini",
instructions="画像を説明するエージェントです",
)
gpt_4o_mini_agent.functions.append(get_dense_region_caption)
Swarmクライアントとエージェントを準備しています。
1つ前で準備した get_dense_region_caption() を処理移譲先として追加しています。
import cv2
import base64
# 画像をBase64化
_, imencode_image = cv2.imencode('.jpg', bgr_image)
base64_image = base64.b64encode(imencode_image)
base64_image = f'data:image/jpg;base64,' + base64_image.decode('ascii')
GPT4o miniに渡すために画像をBase64化しています。
いくつかの動作確認結果です↓
まずは、座標などを聞かずに画像説明をしてもらっています。
この場合、Florence-2への処理移譲は行われていません。
import textwrap
query = 'この画像には何が映っていますか?'
messages = [{
'role': 'user', 'content': [
{'type': 'text', 'text': query},
{'type': 'image_url', 'image_url': {'url': base64_image}},
]
}]
response = client.run(
agent=gpt_4o_mini_agent,
messages=messages,
context_variables={"base64_image": base64_image},
)
print(textwrap.fill(response.messages[-1]["content"], width=60))
処理結果↓

次に座標も問い合わせています。
Florence-2に処理が移譲され、処理結果を解釈して回答してくれています。
from IPython.display import display, Markdown
query = 'この画像には何が映っていますか?一覧と座標を知りたいです。'
messages = [{
'role': 'user', 'content': [
{'type': 'text', 'text': query},
{'type': 'image_url', 'image_url': {'url': base64_image}},
]
}]
response = client.run(
agent=gpt_4o_mini_agent,
messages=messages,
context_variables={"base64_image": base64_image},
)
display(Markdown(response.messages[-1]["content"]))
処理結果↓

import textwrap
query = '''
この画像には何が映っていますか?一覧で座標と詳細を知りたいです。
json形式で出力してください。
label, bbox, detailのキーで表現してください。labelは一般的な名称で1単語にしてください。
'''
messages = [{
'role': 'user', 'content': [
{'type': 'text', 'text': query},
{'type': 'image_url', 'image_url': {'url': base64_image}},
]
}]
response = client.run(
agent=gpt_4o_mini_agent,
messages=messages,
context_variables={"base64_image": base64_image},
)
print(response.messages[-1]["content"])
処理結果↓

以上。
Discussion