Open20
light gbm
それっぽい使い方
LabelEncoder()は,文字列や数値で表されたラベルを,0~(ラベル種類数-1)までの数値に変換してくれるものです.機械学習で分類系のタスクを扱う場合,正解のラベルが文字列で表されることはよくあります.このようなとき,LabelEncoder()を使うと簡単に数値に変換できるという感じです.
- 要は種類数にマッピングするやつ
- ラベル -> ラベルIDだけじゃなくて逆も行ける(エンコーどだけでなくデコーども)
pandasのdtype=category(categorical data)
- 固定種の変数に使われる
- gender/血液型とか
- 統計的カテゴリ変数と違ってcategorical dataはorderをたまに持つ
- strongly agree > agreeとか
- でもnumerical opsはできない
- categorical dataは何らかのcategooriesかnp.nan
- 役に立つとき
- 種類の少ないstring(メモリの省略になる
- lexical orderとlogical orderが違うとき(logical orderが使用される
- 他のライブラリにカテゴリ値であることを伝えるとき
パラメタチューニング
- 目的
-
回帰・分類において 「複雑な推定」を「未知のデータでも推定性能が上がるよう調整」
- モデルの複雑さをますと学習データへフィットしすぎる
- 正則化で複雑さをペナルティにする
- ハイパーパラメタは非線形の程度とか過学習と未学習のバランスを調整する
- チューニングはテストデータで性能が出るようにする
- チューニングのフロー
-
ホールド・アウト検証とクロスバリデーション
ホールドアウトのほうがシンプル
Datasetのreference引数の意味
- validation用のデータとtrainデータに同じ処理を施すための参照
- すべての機械学習アルゴリズムにおいて、validation用のデータとtrainデータに対して同じ処理を施すべき
early_stopping_roundsは評価指標がこの回数分連続で改善しなくなったら学習をやめる
fit_paramsの引数

one hotエンコーディング
カテゴリーをそうであるかないかの0/1で表現するように変換する
カテゴリー分のカラムができる
パラメタのチューニング
Tune Parameters for the Leaf-wise (Best-first) Tree
- light gbmはleaf-wiseなツリー構成アルゴを使用
- 他の奴らはdepth-wise
- leaf-wiseはdeapth-wiseに比べてだいぶ早く収束する
- ただし適切にパラメタを設定しないとover fitしやすい
- 重要なパラメタたち
- num_leaves
- ツリーの複雑度を調整する
- num_leaves=2^max_dapthにすればdepth-wiseなツリーと同じリーフの数を作れる
- だけどこの変換はあまり良くない
- なぜなら同じリーフの数に対してleaf-wiseはdepth-wiseより深くなる
- これはover fitにつながる
- そのためmax_depth=nにしたときはnum_leavesは2^nより小さく設定しなければならない
- min_data_in_leaf
- leaf-wiseにおいてover-fitを防ぐために重要なパラメタ
- 最適値はtraining sampleとnum_leavesに依存
- 大きくすればするほどover-fitを防げるけど逆にunder-fitしやすくなる
- デカ目のデータセットに対して大体100とか1000のオーダーくらいで十分
- max_depth
- 設定すれば明示的にツリーの深さを制限できる
- num_leaves
For Faster Speed
Add More Computational Resources
- light gbmは内でOpenMPを使用して並列化している
- スレッドの最大数はnum_threadsで制御できる
- CPUコアと同じ数に設定すれば最良パフォーマンス
- distributedなトレーニングでも早くなる
Use GPU-enabled version of LightGBM
- gpu使えばはやくなる
Grow Shallower Trees
- ツリーのノード数を減らせばトレーニングは早くなる
- 以下のパラメタたちでノード数を制御できるけど精度を犠牲にするかも
max_depthをへらす
- 減らせば早くなる
num_leavesをへらす
- leaf-wiseなのでmax_depthだけだと複雑性を抑えるのに直接的じゃない
- num_leavesまで制御すればノードの数を制御できる
- 減らせば早くなる
min_gain_to_splitを増やす
- light gbmはgainが大きいノードから深くしていく
- min_gain_to_splitのデフォルト値は0
- この意味はどんな小さなgainの改善でも拾うという意味
- 僅かなgainの改善がそんなに意味がないときもある
- そんなときはmin_gain_to_splitを増やせば早くなる
min_data_in_leafとmin_sum_hessian_in_leafを増やす
- データセットのサイズによってはノードを通るデータが少ない時がある
- これはover-fitの兆候
- max_depthとnum_leavesで間接的にこれを制御できるが微妙
- min_data_in_leafはそのノードを通るデータの最低数
- min_sum_hessian_in_leaf
- あるノードを通るhessian=目的関数の二階微分値の合計値の最小値
Grow Less Trees
num_iterationsをへらす
- boostingの回数をコントロールしている
- ツリーの数ともみなせる
- これをいじるときは同時にlearning_rateをいじるべき
- learning_rateは時間に影響しないが精度に影響する
- num_iterationsをへらすときあlearning_rateをいじるべき
- 正しい組み合わせはdataとか目的関数によるのでハイパーパラメタチューニングで最適化するのがいい
Use Early Stopping
- early stoppingとは継続して精度向上が起きなかったときに学習をやめること
- セットしとけば学習が早くなるかも
Considef Fewer Splits
- 今まではツリーとノードがどの程度作られるかの話だった
- ツリー、ノードをモデルに組み込むのに必要な時間を短縮することでも学習の効率化は可能
- ただ精度が落ちるかも
Enable Feature Pre-Filtering When Creating Dataset
- lightgbmのDatasetオブジェクトを作成するときにmin_data_in_leafから逆算して役に立たない特徴量をフィルターアウトする機能
- 例えば1000個のデータを含むデータセットがあって、そのうちの一つの特徴量が995:5でバリエーションを持っていると仮定する
- min_data_in_leaf=10のときこの特徴量はノードでの分岐を起こさない
- なぜなら常に比率995側の判定をくだされるから
decrease max_bin or max_bin_by_feature When Creating Dataset
- light gbmは連続値を離散値に変換する
- これはDataset構築時に一度だけ行われる
- ノード追加時に考慮される分割は(#feature * #bin)だけある
- つまりbinsの数を減らすと評価されるsplitの数をへらすことができる
- max_binはbinの最大値を制御
- max_bin_by_featureで特徴量ごとのmax_binを制御
- これらを減らすと学習時間が減る
Increase min_data_in_bin When Creating Dataset
- binによっては含むデータ数が少ないこともある
- このbinの評価を頑張ってもモデルの精度に影響しないかも
- min_data_in_binで最小値を指定
- これを増やせば学習時間が減る
Decrease feature_fraction
- デフォでlight gbmはDataset構築中に全ての特徴量を考慮する
- feature_fractionでどの程度の割合の特徴量を考慮するかを制御
- 特徴量が減るとsplitが減る
- これを減らすと学習時間が減る
Decrease max_cat_threshold
- light gbmはカテゴリ値を分割する最適値を探す
- 二グループに分割する点をk-vs.-restとか呼んだりする
- max_cat_threasholdは分割するグールプの数を増やす
- これを減らせば学習時間が減る
Use Less Data
Use Bagging
- デフォでlgbmはすべての学習データをイテレーションごとに使用
- ランダムに使用することも可能
- 複数回の非復元抽出で学習することをバギングと呼ぶ
- bagging_freqが何イテレーションごとにサンプルし直すか
- bagging_fractionがサンプルごとに何割のデータをサンプルするか
- bagging_fractionをへらすと学習時間が減る
Save Constructed Datases with save_binary
Leaf-wise (Best-first) Tree Growth
- 大体のツリーアルゴリズムはlevel(depth)-wiseに成長する
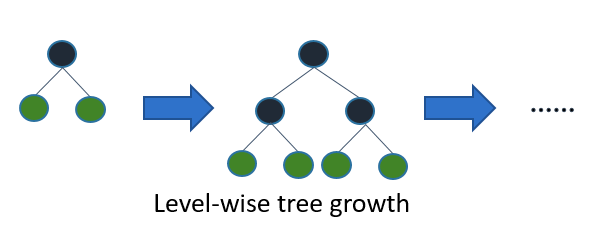
- light gbmはleaf-wise(best-first)に成長する
-
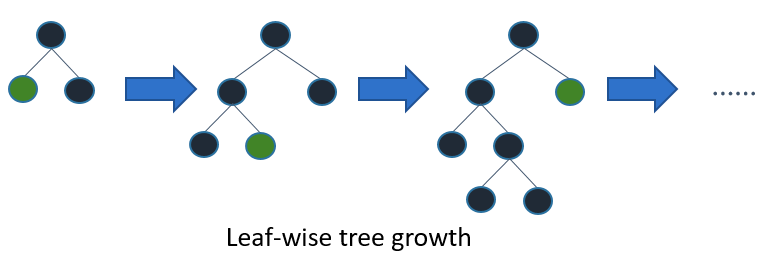
- これは損失の減少が最も大きいリーフから深くしていく
- 同じleafの数に対してlevel-wiseより損失が小さくなり月
- leaf-wiseはdataが小さいとover-fitしやすくなる
- そのためmax_depthで深さを制限できる
Optimization in Speed and Memory Usage
presorted-basedアルゴリズムとhistogram-basedアルゴリズム
- pre-sorted
- 予め特徴量ごとに特徴量の値でソートしたデータへの参照を作成
- 深さごと&特徴量ごとにソートされたデータを操作して葉の分割点を決める
- histogram-based
- 予め特徴量ごとにヒストグラムを作成
- 各データがどのbinに属するかを求める
- 深さごと&特徴量ごとにヒストグラムを作り、そのヒストグラムに基づいて分割点を決定
- 計算量メリット
- 深さごとに以下の計算量がかかる
- ヒストグラム作成部分の計算量=O(特徴量*データ数)
- 分割点の計算部分の計算量=O(特徴量*ビンの数)
- ヒストグラム作成部分が支配的=全体としてO(特徴量*データ数)のオーダー
- pre-sortedの分割点作成のオーダーと同じだけどヒストグラム作成の処理のほうが早い
- 分岐時に左の葉のヒストグラムが求まったら右側のヒストグラムは親の葉のヒストグラムからの引き算で求めることができる
- このオーダーはO(特徴量データ数)でなくO(特徴量ビンの数)で無視できる
- 全体としてpre-sortedと同じオーダーだが定数倍部分でhistogramのほうが早いらしい
- 深さごとに以下の計算量がかかる
- 多くのBoostingではpre-sortedなアルゴリズムを使用している
- これはシンプルだが最適化しづらい
- light gbmはhistogram-basedなアルゴを使用している
- これは連続値の特徴量を離散値に変換する
- 学習速度向上&メモリサイズの減少をもたらす
- histogram-basedなアルゴリズムのメリット
- splitごとのgain計算量が小さくなる
- pre-sortアルゴの計算量はO(#data)
- ヒストグラム作成の計算量もO(#data)
- ただし高速な足し合わせ処理のみ行われる
- ヒストグラムを構成したあとはO(#bins)の計算量ですみ、#binsは#dataより十分小さい
- 方葉のヒストグラムから逆側のヒストグラムを逆算できる
- 片方の葉のヒストグラムを作成したら親のヒストグラムからの引き算でO(#bins)のコストで逆側のヒストグラムを作成できる
- メモリサイズが小さい
- 分散学習のための通信コストが低い
- splitごとのgain計算量が小さくなる