週刊AWSキャッチアップ(週刊AWS/週刊生成AI 2025/1/20週)
Amazon EventBridge announces direct delivery to cross-account targets
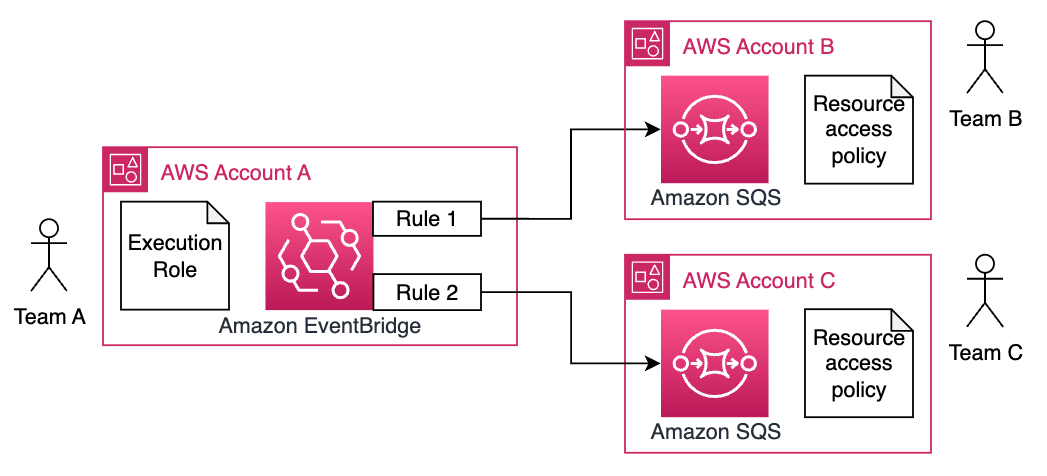
- EventBridgeのEvent Busから別のアカウントのAWSサービスへイベントを直接配信できるようになりました
- 従前は他アカウントへのイベント配信には、受信先アカウントのEventBusを経由させる必要がありました
- 今回のアップデートではEventBusを経由させる部分が省略され、送信側のIAMロール/受信側のリソースポリシーの双方でAPIの許可をすれば他アカウントへのAWSサービスが利用できるようになりました
- 通常のクロスアカウント利用と同じように双方のAPI認可で利用できるということです
- ドキュメントによるとクロスアカウントのイベント配信に対応しているリソースは、リソースポリシーに対応している5つです
- Amazon API Gateway APIs
- Amazon Kinesis Data Streams streams
- Lambda functions
- Amazon SNS topics
- Amazon SQS queues
- EventBridgeにはRuleとEvent Busの2つがあります
- Rule: EventBridgeが発行するイベントの設定。event-based/time-basedの2つがある
- Event Bus: 実際にイベントを受信するルーターの役割、0個以上のターゲットにイベントを配信
参考: アップデート前後の比較(AWS Blogより)
AWS Blogからの抜粋になりますが、アップデート前は下記のようにEventBusを経由させていました。

今回のアップデートでは、リソースポリシーに対応した一部リソースに限りEventBusの省略ができるようになりました。
参考リンク
Sending events to an AWS service in another account in EventBridge - Amazon EventBridge
Introducing cross-account targets for Amazon EventBridge Event Buses | AWS Compute Blog
[アップデート]Amazon EventBridgeで別のアカウントのリソースに直接イベントを配信できるようになりました! | DevelopersIO
【初心者向け】Amazon EventBridgeについてまとめてみた - サーバーワークスエンジニアブログ
Amazon Corretto January 2025 quarterly updates
- Amazon Correttoの長期サポート(LTS)/機能リリース(FR)にて4半期ごとのセキュリティアップデート/クリティカルアップデートが発表されました
- Amazon CorrettoはAWSが提供するOpenJDK
関連リンク
Amazon Neptune now supports open-source GraphRAG toolkit
- GraphRAG Toolkitが公開されました
- GraphRAG ToolkitはGraphRAGのワークフローを構築できるOSSのpythonライブラリです
- AWS Blogによると、インデックス作成とクエリの2つの機能があるとのこと
- インデックス作成: 非構造化および半構造化のテキストコンテンツを取り込みGraphRAGを構築する
- クエリ: Vector Store/Graph Storeから関連情報を取得、その情報をモデルへ提供して、モデルからの回答結果を返す
- その他サンプルのCloudFormationも提供されています
- GraphRAGとはグラフデータベースを用いたRAGの技術です
参考: RAGとGraph RAGの違い(AWS Blogより)
ベクトル検索だと質問内容と言語的に似た内容は抽出できるが、質問内容と類似しない関連情報は取得できない。
Graph RAGだとこういった情報も取得できるとのこと。

参考: インデックスの例(AWS Blogからの抜粋)
GraphRAG Toolkitでは、LexicalGraphIndexを使って構築をしています。(ブログ掲載サンプルの下5行)
from graphrag_toolkit import LexicalGraphIndex
from graphrag_toolkit.storage import GraphStoreFactory
from graphrag_toolkit.storage import VectorStoreFactory
from llama_index.readers.web import SimpleWebPageReader
import nest_asyncio
nest_asyncio.apply()
doc_urls = [
'https://docs.aws.amazon.com/neptune/latest/userguide/intro.html',
'https://docs.aws.amazon.com/neptune-analytics/latest/userguide/what-is-neptune-analytics.html',
'https://docs.aws.amazon.com/neptune-analytics/latest/userguide/neptune-analytics-features.html',
'https://docs.aws.amazon.com/neptune-analytics/latest/userguide/neptune-analytics-vs-neptune-database.html'
]
docs = SimpleWebPageReader(
html_to_text=True,
metadata_fn=lambda url:{'url': url}
).load_data(doc_urls)
graph_store = GraphStoreFactory.for_graph_store(
'neptune-db://my-graph.cluster-abcdefghijkl.us-east-1.neptune.amazonaws.com'
)
vector_store = VectorStoreFactory.for_vector_store(
'aoss://https://abcdefghijkl.us-east-1.aoss.amazonaws.com'
)
graph_index = LexicalGraphIndex(
graph_store,
vector_store
)
graph_index.extract_and_build(docs)
参考: クエリの例(AWS Blogからの抜粋)
GraphRAG ToolkitではLexicalGraphQueryEngineを使ってクエリを実行しています
from graphrag_toolkit import LexicalGraphQueryEngine
from graphrag_toolkit.storage import GraphStoreFactory
from graphrag_toolkit.storage import VectorStoreFactory
import nest_asyncio
nest_asyncio.apply()
graph_store = GraphStoreFactory.for_graph_store(
'neptune-db://my-graph.cluster-abcdefghijkl.us-east-1.neptune.amazonaws.com'
)
vector_store = VectorStoreFactory.for_vector_store(
'aoss://https://abcdefghijkl.us-east-1.aoss.amazonaws.com'
)
query_engine = LexicalGraphQueryEngine.for_traversal_based_search(
graph_store,
vector_store
)
response = query_engine.query('''What are the differences between Neptune Database
and Neptune Analytics?''')
print(response.response)
関連リンク
awslabs/graphrag-toolkit: Python toolkit for building GraphRAG applications
Introducing the GraphRAG Toolkit | AWS Database Blog
CloudWatch provides execution plan capture for Aurora PostgreSQL
- Amazon CloudWatch Database InsightsがAurora PostgreSQLで実行されている上位SQLクエリの実行計画を収集し、保管できるようになりました
- パフォーマンスの低下等の原因分析を実行計画を元に特定できるようになります
- CloudWatch Database InsightsのAdvancedモードを有効化させる必要があるのが注意点です
- Database Insightsは今年のre:Invent 2024で登場した機能で、Performance Insight、CloudWatch Logs、CloudWatch Application Signalsなどを統合した機能になります
- 従前はPerformance Insightを確認して、CloudWatch Logsでログを見てといったことが必要だったのが、ダッシュボードでまとめて確認できます
参考: 東京リージョンでのDatabase Insightsの料金(1/30時点)
| # | データベースインスタンスの設定タイプ | コスト (1 時間あたり) |
|---|---|---|
| 1 | モニタリング対象のプロビジョンドインスタンス (vCPU-時間) | USD 0.0125 |
| 2 | モニタリング対象の Aurora Serverless v2 インスタンス (ACU-時間) | USD 0.003125 |
関連リンク
CloudWatch Database Insights - Amazon CloudWatch
[アップデート] Amazon Aurora のモニタリング機能に「CloudWatch Database Insights」が登場しました | DevelopersIO
Amazon Redshift announces support for History Mode for zero-ETL integrations
- Amazon Redshift ゼロETL統合にhistory(履歴)モードが追加されました
- 今回のアップデートでコードを記述することなく、Zero-ETLデータソース(Amazon Aurora、RDS、DynamoDB etc...)のSlowly Changing Dimension Type 2(SCD Type2)テーブルを作成できます
- 簡単に言うと、開始日と終了日を付与したデータ変更履歴を保存して分析ができるようになりました
- SCD Type2: Dimension Tableの値が変化した際に、新しいレコードを追加して、レコードに開始日と終了日を入れることで、データの変更履歴を保存する形式
- Dimension Tableに対しての更新方法の違いで、Type0~Type4と2種類のHybrid SCDsがある
- Dimention Table: 分析の切り口となるマスターテーブル
- 簡単に言うと、開始日と終了日を付与したデータ変更履歴を保存して分析ができるようになりました
- データソースと重複したコピーを保持せずに、データ変更履歴を保存できるため、ストレージと運用の手間を削減しながら履歴データを扱えます
- 今回のアップデートでコードを記述することなく、Zero-ETLデータソース(Amazon Aurora、RDS、DynamoDB etc...)のSlowly Changing Dimension Type 2(SCD Type2)テーブルを作成できます
関連リンク
History mode - Amazon Redshift
データ分析を支える技術 データモデリング再入門 - Speaker Deck
[アップデート] Amazon Redshift Zero-ETL 統合の History Mode による SCD Type2テーブルの自動生成を試してみた | DevelopersIO
AWS Client VPN announces support for concurrent VPN connections
- AWS Client VPNが複数VPNへの同時接続をサポートしました
- これまでは一度に1つのVPNプロファイルにしか接続できなかった関係で、別のネットワークに接続したい場合は都度切断/再接続が必要だっ
- 今回のアップデートで複数のVPN接続ができるようになりました
- Client VPNクライアントのバージョン5.0以降で利用可能
Amazon CloudWatch allows alarming on data up to 7 days old
- Amazon CloudWatchのメトリクスデータ評価期間が24時間から7日間に延長されました
- 下記のユースケースで活用ができます
- 複数日のデータを評価してアラームを出す
- 実行時間の長いプロセス、実行頻度の低いプロセスの監視
- 下記のユースケースで活用ができます
関連リンク
Using Amazon CloudWatch alarms - Amazon CloudWatch
Amazon EC2 I7ie instances now available in AWS Europe (Frankfurt, London), and Asia Pacific (Tokyo) regions
- Amazon EC2 i7Ie インスタンスが東京、フランクフルト、ロンドンで利用可能になりました
- i7Ieインスタンスはre:Invent 2024で登場したインスタンスタイプ
- AWS Blogによると、下記の特徴があるとのこと
- TB あたりのリアルタイムストレージパフォーマンスが最大 65% 改善
- I/O レイテンシーが最大 50% 低減し、レイテンシーの変動が最大 65% 低下
- コンピューティングパフォーマンスが最大 40% 改善
- 最大 2 倍の vCPU とメモリ
- 料金パフォーマンスが 20% 改善
参考: 東京リージョンの料金(1/30時点)
| # | Instance name | On-Demand hourly rate | vCPU | Memory | Storage | Network performance |
|---|---|---|---|---|---|---|
| 1 | i7ie.large | $0.31 | 2 | 16 GiB | 1 x 1250 NVMe SSD | Up to 25 Gigabit |
| 2 | i7ie.xlarge | $0.61 | 4 | 32 GiB | 1 x 2500 NVMe SSD | Up to 25 Gigabit |
| 3 | i7ie.2xlarge | $1.22 | 8 | 64 GiB | 2 x 2500 NVMe SSD | Up to 25 Gigabit |
| 4 | i7ie.3xlarge | $1.84 | 12 | 96 GiB | 1 x 7500 NVMe SSD | Up to 25 Gigabit |
| 5 | i7ie.6xlarge | $3.67 | 24 | 192 GiB | 2 x 7500 NVMe SSD | Up to 25 Gigabit |
| 6 | i7ie.12xlarge | $7.34 | 48 | 384 GiB | 4 x 7500 NVMe SSD | Up to 50 Gigabit |
| 7 | i7ie.18xlarge | $11.01 | 72 | 576 GiB | 6 x 7500 NVMe SSD | Up to 75 Gigabit |
| 8 | i7ie.24xlarge | $14.68 | 96 | 768 GiB | 8 x 7500 NVMe SSD | Up to 100 Gigabit |
| 9 | i7ie.48xlarge | $29.37 | 192 | 1536 GiB | 16 x 7500 NVMe SSD | 100 Gigabit |
関連リンク
提供を開始: ストレージ最適化 Amazon EC2 I7ie インスタンス | Amazon Web Services ブログ
Amazon EC2 ストレージ最適化タイプの新世代インスタンス I7ie が一般提供開始されました #AWSreInvent | DevelopersIO
Amazon Aurora PostgreSQL Limitless Database now supports PostgreSQL 16.6
- Aurora PostgreSQL Limitless DatabaseにてPostgreSQL version 16.6をサポートしました
- 16.6になったことでの変更点は、ドキュメントをご確認ください
- Aurora PostgreSQL Limitless DatabaseはAuroraの機能の1つ。データベースワークロードを複数の Aurora ライターインスタンスに分散しながら、単一データベースとして使用する機能を維持させることで、従来のAuroraで課題だった書き込みスループット/ストレージを拡張できるのが特徴です
参考: Aurora Limitless Databaseの仕組み(AWS Blogより)
AWS Blogによると、DBシャードグループ内の複数のデータベースノード(ワークロードに基づいてスケールするルーターまたはシャード)で構成される2層アーキテクチャーになっているとのこと
- ルーター: クライアントからのSQL接続を受け入れ、SQLコマンドをシャードに送信し結果を返す
- シャード: ルーターからのクエリを受け付けるノードで、Tableのサブセット/データのコピーを保存している
- シャードテーブル、参照テーブル、標準テーブルの3つのテーブルがある
- シャードテーブル: 複数のシャードに分散して配置されている。シャード間のデータの分散は、シャードキー(テーブル内の指定された列の値)によって分割される
- 参照テーブル: 製品カタログや郵便番号など、あまり変更されない参照データで利用されるテーブルで、すべてのシャードのデータを完全コピーするため不要なデータ移動がなく結合クエリを高速に実行できる
- 標準テーブル: 通常のAuroraのテーブルに似たもの。標準テーブルはすべて 1 つのシャードにまとめられる。標準テーブルから、シャードテーブルと参照テーブルを作成できる。

関連リンク
Amazon Aurora PostgreSQL Limitless Database の一般提供の開始 | Amazon Web Services ブログ
Aurora PostgreSQL Limitless Database architecture - Amazon Aurora
Amazon Aurora Limitless Database 内部アーキテクチャ詳解 〜 スケーラビリティと高可用性の秘密 〜(AWS-40) - YouTube
AWS、「Amazon Aurora PostgreSQL Limitless Database」を正式提供開始 | DevelopersIO
Amazon Q Businessにて、チャットでアップロードされた画像のインサイト抽出機能に対応
- Amazon Q Business にて、チャットでアップロードされた画像に関する質問への回答とインサイトの抽出機能を提供開始
- 請求書の画像をアップロードして経費の分類を依頼したり、アーキテクチャ図を共有して設計に関する質問するといった用途に活用できるとのこと
関連リンク
[アップデート] Amazon Q Business のチャット上のファイルアップロード機能が画像ファイルをサポートしました | DevelopersIO
Amazon BedrockにてLuma AIのRay2ビデオモデルが利用可能に
- Luma AI の新しいビデオ生成 AI 基盤モデルである Ray2 が、Amazon Bedrock で利用可能になりました
- Luma Ray2は、自然な動きを持つリアルな映像を作成できるビデオ生成モデル
- 540pもしくは720pの解像度、5秒もしくは9秒のビデオ生成をサポート
参考: AWS CLIから実行する場合のコマンド例
aws bedrock-runtime start-async-invoke \
--region us-west-2 \
--model-id luma.ray-v2:0 \
--model-input "{ \"prompt\": \"a humpback whale swimming through space particles\", \"duration\":\"5s\", \"resolution\": \"540p\", \"aspect_ratio\":\"16:9\"}" \
--output-data-config "{\"s3OutputDataConfig\": {\"s3Uri\": \"s3:\/\/testing-bucket-ais-region-us-west-2\/\"}}"
関連リンク
Luma AI’s Ray2 video model is now available in Amazon Bedrock | AWS News Blog
Amazon Bedrock にて、Cohere Embed 3 Multilingual と Embed 3 English のマルチモーダルサポートを開始
- Cohere Embed 3 MultilingualとEmbed 3 Englishにてマルチモーダルサポートを開始しました
- マルチモーダルは「画像」と「テキスト」の両方を指す
- マルチモーダルサポートにより、画像コンテンツを含むデータから重要な情報を引き出すことができるとのこと
関連リンク
BedrockにCohereのマルチモーダル埋め込みモデルが来た!で、何に使うの? #AWS - Qiita
Amazon Bedrock Flows にて、複数ターン会話のサポートを発表(プレビュー)
- Amazon Bedrock Flowsにて複数ターン会話がサポートされました
- Amazon Bedrock FlowsはLLM・エージェント・ナレッジベース・その他のAWSサービスのワークフローを作成できるサービス
- 今回のアップデートで一連の処理に必要な情報が不足していた場合に、ユーザーに要求して引き出すことができるようになりました
関連リンク
Introducing multi-turn conversation with an agent node for Amazon Bedrock Flows (preview) | AWS Machine Learning Blog
[アップデート] Amazon Bedrock Flows が複数ターンの会話をサポートしました | DevelopersIO
Discussion