FP8 trainingを支える技術 1
はじめに
東京科学大学(Institute of Science Tokyo)の藤井です。
本記事では、FP8を利用したモデル(LLM)の学習の仕組みを理解するうえで必要な基礎的な知識を紹介します。
私は普段、Swallow LLMの研究開発などを行っているのですが、大規模な学習を支える低精度計算、分散並列学習に主に興味があり、LLM開発はあくまで、それらの技術の応用先に過ぎないと考えています。そこで今回は、普段執筆している技術記事とは異なり、私が主に研究対象としている学習を支える技術、特にFP8 trainingに関して解説を行います。
本記事では解説対象として、pytorch/aoを採用します。
FP8
FP8とは、数値精度の1つでありHopper世代のGPUからサポートされた数値精度になります。
FP8という1つのdatatypeが存在するのではなく、以下に示すようにE4M3とE5M2と呼ばれる2つの数値精度から構成されています。

上の図が示すように、正負を示すsign bit以外のexponent bitとmattissa bitに着目するとE4M3, E5M2という名前の由来が分かります。その名の通りE4M3は、Exponent bitを4つ、Mantissa bitを3つ持ちます。またE5M2はExponent bitを5つ、Mantissa bitを2つ持ちます。
以下では低精度学習を理解するために欠かせない数値表現についてそれぞれのdatatypeごとに説明します。
E4M3
FP8のような低精度datatypeを利用する上で難しいことの1つはExponent bitが小さいため大きな数字を表すことが出来ないことです。E4M3で表現できる最大値について考えてみましょう。
浮動小数点の値は

ここで、仮数部もすべて1で埋めたくなりますが、E4M3の仕様により指数部がすべて1であり、かつ仮数部もすべて1のときはNaNにすると決まっています。そのため、仮数部の最大は110となります。

また、E4M3のExponent biasは7と仕様により定められているので、
同様に最小値はsign bitを反転させた-448となります。
E5M2
E4M3のときと同様に最大値、最小値を算出します。
Exponent bitをすべて1で埋めると以下のようになりますが、E5M2は少し特殊な仕様になっています。

E4M3には定義されていなかったInfinitiesが定義されているのですが、Infinitiesは以下のようにmantissa bitsをすべて0で埋めつつ、exponent bitsをすべて1で埋めた表現になっています。
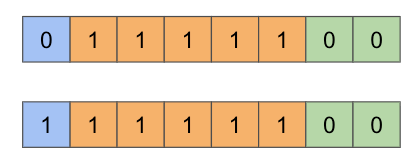
また、NaNの表現として3つの表現があります。(正負を含めると6通り)
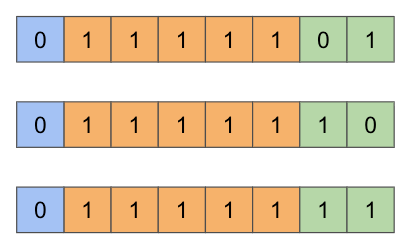
そのため、最大値はexponent bitsをすべて1で埋めた場合ではなく、以下のように1つ以外はすべてを1で埋めた以下のような形式になります。

mantissa bitsには特に制約はないので、すべて1で埋めた以下の形式が最大値になります。

よって最大値は
また、subnormal numberを利用しない場合の最小値も以下のように表せるので、

このようにE5M2はE4M3よりも、広い範囲の値を表現することが可能です。
ではE5M2の方が常に優れているのでしょうか?そうでもありません。
E5M2は、広範囲を表現できるようにExponent bitsを増やした結果Mantissa bitsが2つしかありません。そのため、表現可能な数値が非常に粗くなります。すなわち、underflowによる0への切り捨てや、表現可能なrangeを超えたことによるclipping等は発生しにくくなりますが、代わりに値がかなり粗く近似されることになります。
FP8を利用する理由
FP8を利用する理由は様々存在しますが、大きく分けて3つの理由が存在します。
- parameter等を低精度化することで保存する際のストレージコストを低減するためや、推論時に消費するHBMのメモリサイズを削減することで低リソース環境でモデルを利用することができるようにするため
- モデルの推論時などメモリバウンドな状況において、HBMから計算ユニット(Tensor Core)に供給するスピードを上昇させるために、parameterやactivationを低精度化することで速度向上を実現するため
- FP16 Tensor Coreよりも高速なFP8 Tensor Coreを利用することで計算ボトルネックな処理をより高速化するため
FP8を用いたLLM、VLMなどのモデルの学習は主に3つ目のFP8 Tensor Coreを利用した処理高速化を期待して研究されています。そのため、ひとえにFP8量子化と言っても、1, 2の目的で研究開発している場合と3目的で研究している場合では、取り得る手段などが大きく異なり、似て非なるものとなっています。
FP8 Scaling
Overview
FP8を利用したLLMの学習では、forwardではactivation, weightに比較的より細かな精度が要求されるためE4M3を、backwardではgradientが比較的数値精度へ敏感性が低いとされているのでE5M2を利用するhybrid方式が利用されています。
FP8が表現可能な領域を下図のように灰色で表すとすると、activationやweightの分布が灰色の領域からはみ出ている場合、FP8では表現できなくなってしまいます。それを防ぐためにPer Tensor Scalingではテンソルごとに、axis wise scalingでは行または列ごとにscalingを行い、下図のように分布を灰色の範囲に移動する操作を行います。これをscalingと呼びます。
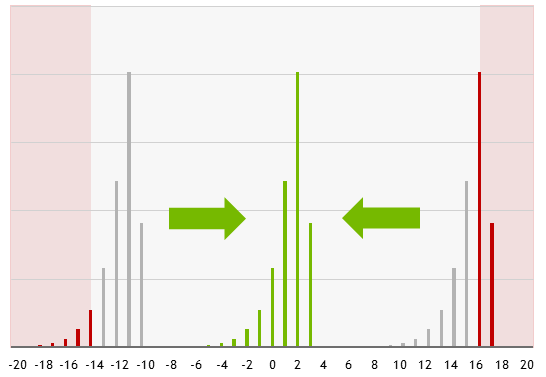
なぜscalingが必要なのか
FP8を利用した学習を行うときには、なぜscalingが必要なのでしょうか?
すでに簡単には説明していますが、一度、きちんと補足させてください。
FP8(E4M3, E5M2)は、表現可能なdynamic rangeがFP32, BF16と比較すると狭く、naiveにFP32, BF16などの高精度(High Precision)のTensorをFP8にcastすると表現可能な領域から外れてしまい、overflowが発生してしまいます。overflowを防ぐためにE4M3.maxやE5M2.maxなどにより値を置き換えることも可能ですが、ただでさえFP8化したことで精度が犠牲になっている上に、大きな値をclampすることはモデルの精度を悪化させかねません。そのため、FP8 trainingでは、あらかじめFP8に変換する対象のテンソルから絶対値の最大値(=absolute max (amax))を取得し、そのamaxでもってFP8の表現可能なdynamic rangeに変換後のテンソルの各elementが収まるようにscaling factorを決めています。これにより、FP8化するときに生じるのは一部の場合を除き、数値精度の低下だけになり、モデルの精度を維持しつつ推論、学習が可能になるという仕組みです。
下図は、これを分かりやすく示しています。
最初は灰色のFP8が表現可能な領域になかった値たちをscalingすることで表現可能な領域に移動させています。また、分布特性が異なるテンソルごとにscaling factor 1、scaling factor 2と別々のscaling factorを設けることで、分布している値がFP8 dynamic rangeよりも大きすぎた場合も、小さすぎた場合も、表現可能な領域に収めることができています。

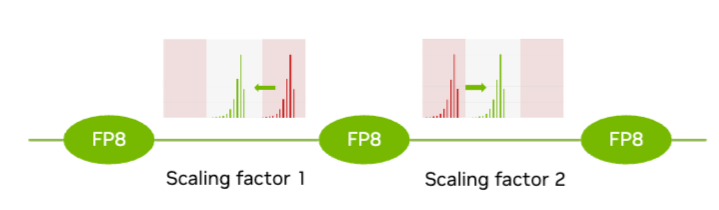
GTC24 What's New in Transformer Engine and FP8 Trainingより
Granularity
以下のようにFP8テンソルをscalingして、FP8が表現できる値の範囲内(dynamic range)から値がはみ出ないようにするためのscaling方法には大きく分けて2つの粒度があります。
class ScalingGranularity(enum.Enum):
"""
Defines the granularity of scaling strategies for casting to float8
"""
# A single scaling factor for the entire tensor
TENSORWISE = "tensorwise"
# Scaling factors computed along one axis of the tensor, reducing it to
# size 1.
AXISWISE = "axiswise"
1つ目が Tensor Wiseと呼ばれる方法です。
1つのテンソルごと、すなわちbatch_sizeをsequence_lengthをhidden_sizeをffn_hidden_size(= indermediate size)を
2つ目は、Axis Wiseと呼ばれる方法です。
基本的には、column wiseまたはrow wiseにscaling factorを適用する範囲を決めて、その範囲ごとにscalingを行います。
図で表すと以下のようになります。

Tensor wiseは、activationの場合は
また、縦軸、横軸という単位ではなく、さらに細かくscalingする対象を絞った以下のようなscalingも可能です。

細かい単位でscalingを行うことで、より繊細なscaling factorを設定できるようになり、非常に大きな値のような、対象とする範囲に含まれる外れ値(outlier)の存在のせいで、scaling factorの値が大多数の要素(tensor elements)にとって不適切になる事態を緩和することが可能です。
そのため、細かい単位でscalingを行うfine-grained Quantizationが精度の面では好まれます。しかし、細かい単位でscalingを行うとなると実装がかなり複雑化するだけでなく、scaling factorの計算や、scalingの適用などにかかるoverheadの存在を考慮する必要が出てくるため、細かくすればよいという訳でもないのです。
Scaling
実際に入力された高精度(BF16, FP32)テンソルをFP8に変換する処理の実装は以下のようになっています。
実際に行われる処理について理解するために引数について説明します。
tensorは、これからscale後、FP8に変換される高精度テンソルです。scaleは、FP8で表現可能な範囲に収めるために高精度テンソルに掛け合わせる値になります。float8_dtypeは、FP8の表現方法として前述のようにE4M3とE5M2の2つがあるため、どちらを利用するのかを指定するargumentになります。
受け取った値を以下のようにscaling後、FP8に変換しています。
to(torch.float32)で一度FP32にcastしているのは、eagerモードとtorch.compileによるcompileモードの値が数値精度の問題でズレることを防ぐためです。
tensor_scaled = tensor.to(torch.float32) * scale
bits_fp8 = to_fp8_saturated(tensor_scaled, float8_dtype)
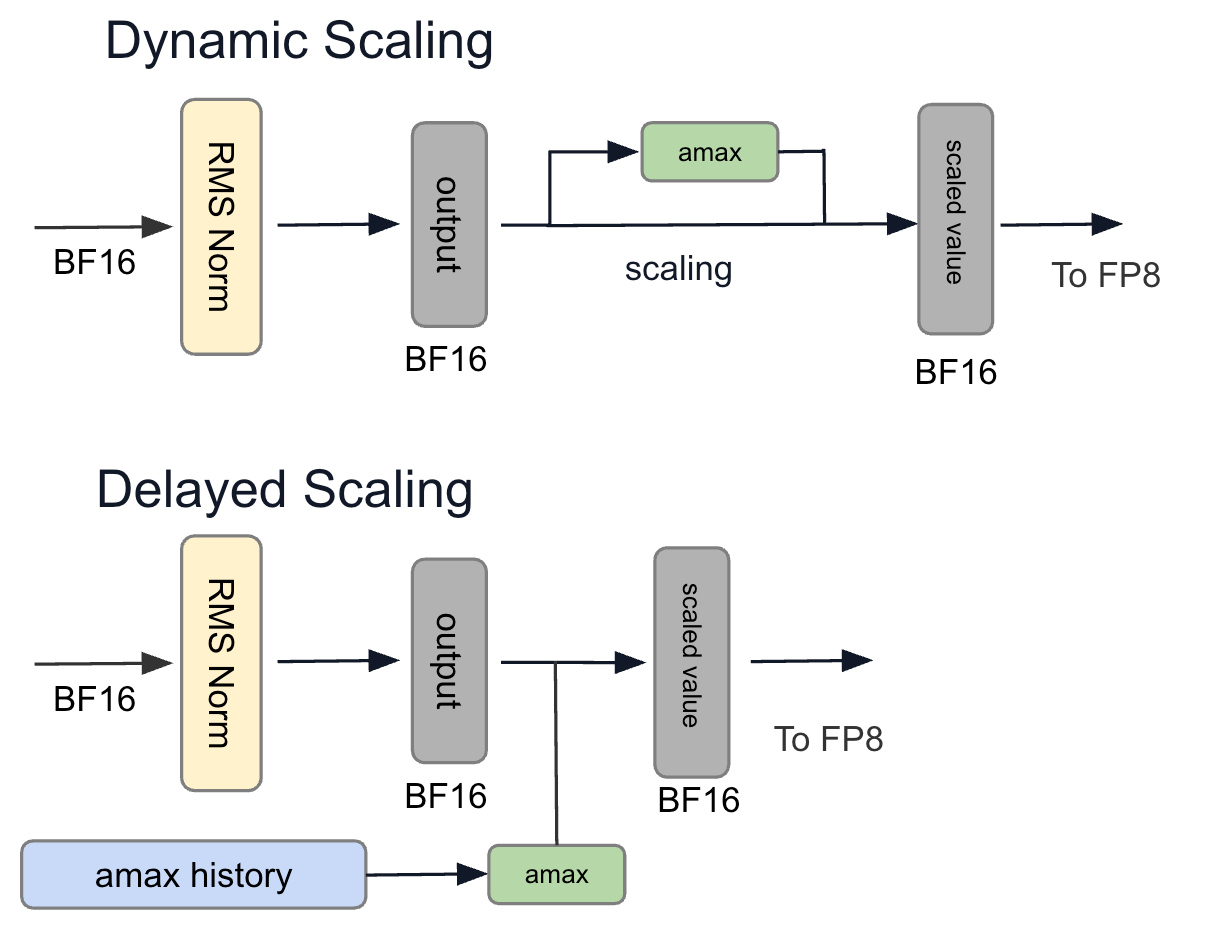
DelayedScaling
config
DelayedScalingのconfigはこちらに実装されています。
configとしては以下のように、保存しておくamax historyの長さと、scalingを行うときの決定方法が記載されていますが、absolute max以外を想定していないため実質、変更可能なのはamax historyの長さだけとなります。
# Controls the history length of amax buffers
history_len: int = 16
# Controls the way to calculate current scale from amax history
scale_fn_name: str = "max"
amax history
amax historyを更新するための実装は以下のようになっています。
new_amaxがその名の通り、新しく計算されたamaxの集まりを表し、amax_history_stackが過去の履歴を指します。hisotory lengthの長さだけamax historyを保存しておく必要があるので、torch.rollにより右に1つ履歴を移動します。最も古い履歴であり、次に更新により消される履歴は最も左側のnew_amax_history_stack[:, 0]に移動します。ここに、新しいamaxであるnew_amaxで以下のように上書き後、new_amax_history_stackで上書きを行うと完了です。
new_amax_history_stack[:, 0] = new_amax.squeeze(-1)
amax_history_stack.copy_(new_amax_history_stack)
DynamicScaling
ScalingType dynamicとして実装されているdynamic scalingは、Delayed Scalingとは異なり、FP8に変換する対象からscaleを算出し、FP8へのQuantizeを行います。
FP8 Linear matmul
torchao実装
Transformer LayerにおけるMLP層におけるMatrix Multiplication(行列積)においてFP8を利用する実装はこちらに実装されています。
(Llama-2, 3におけるモデル構造)
順にどのような手順で演算が行われているか解説を行います。
weight_maybe_fp8_t = self.weight.t()
weightは(out_features, in_features)の形式で保存されているため転置をして後段の処理に備えます。次に_get_weight_scaleにより、FP8化していないweightをFP8化するためにscaling factorを求めます。以下のように、内部実装はtensor_to_scale関数に移譲されています。
def _get_weight_scale(
weight: torch.Tensor,
scaling_type_weight: ScalingType,
config: Float8LinearConfig,
) -> Optional[torch.Tensor]:
if tensor_already_casted_to_fp8(weight):
return None
assert scaling_type_weight is ScalingType.DYNAMIC
return tensor_to_scale(weight, config.cast_config_weight.target_dtype)
tensor_to_scale関数の実装は以下のように、入力されたweightの中からamaxを求め、そのamaxを元にscaleを計算しています。
amaxを求めるtensor_to_amaxのロジックは非常に単純であり、Tensor wise scalingの場合は
amax = torch.max(torch.abs(x))
により計算されています。(実装通り x の中のabsolute maxを求めています)
またscaling_granularityがAixs wiseの場合は、以下のように、行方向(row)または列方向(column)方向ごとにabsolute maxを求めるように実装されています。
amax = torch.amax(torch.abs(x), dim=axiswise_dim, keepdim=True)
計算されたamaxと、これから変換する数値精度から、以下のように scaling factorを計算します。
res = torch.finfo(float8_dtype).max / torch.clamp(amax, min=EPS)
torch.finfo(dtype)で、その数値精度が取りうるmax, min等にアクセスできます。これを利用して、amaxが変換予定の数値精度の最大値になるようにscaling factorを計算しています。
得られたscaleを利用し、_cast_weight_float8_tにより以下のようにweightをFP8に変換します。
FP8にQuantizeするために呼び出されている_cast_weight_float8_tは以下であり、内部挙動を理解するには、こちらで呼び出されている_ToFloat8ConstrFunc.applyの内部実装を確認する必要があります。
この_ToFloat8ConstrFuncですが、見覚えがないでしょうか?
そうです、すでにscalingの章で解説した実装になります。こちらで、scalingが行われ、以下のようにreturnされます。
tensor_scaled = tensor.to(torch.float32) * scale
bits_fp8 = to_fp8_saturated(tensor_scaled, float8_dtype)
...
return Float8Tensor(
bits_fp8,
scale,
tensor.dtype,
linear_mm_config=linear_mm_config,
gemm_input_role=gemm_input_role,
axiswise_dim=axiswise_dim,
)
weightがFP8にQuantizeできたので次に行われる処理は、input(activation)のQuantizeかと思いきや呼び出されているのは、以下のようにmatmulです。
しかし、inputはBF16なので、BF16からFP8に変換せずにmatmulを行うわけにはいきません。matmul_with_hp_or_float8_args.forwardの中で、きちんとinputのfp8へのQunatizeが行われています。
matmul_with_hp_or_floa8_argsの中身を追っていきましょう。
forwardを確認すると、以下のように、inputテンソルのdtypeの確認があります。
そのため、まだQuantizeしていないinput_hpはこのタイミングでhp_tensor_to_float8_dynamicによりFP8に変換されます。
if tensor_already_casted_to_fp8(input_hp):
input_maybe_fp8 = input_hp
elif c.cast_config_input.scaling_type is ScalingType.DISABLED:
input_maybe_fp8 = input_hp
else:
input_maybe_fp8 = hp_tensor_to_float8_dynamic(
input_hp,
c.cast_config_input.target_dtype,
linear_mm_config,
gemm_input_role=GemmInputRole.INPUT,
scaling_granularity=c.cast_config_input.scaling_granularity,
axiswise_dim=get_maybe_axiswise_dim(
-1, c.cast_config_input.scaling_granularity
),
round_scales_to_power_of_2=c.round_scales_to_power_of_2,
)
なお、ここでのFP8への変換処理は、weightのときに実装を確認したように、scaleを計算するためにamaxを取得し、変換するFP8の型からscaleを計算後、activaitonをFP8に変換という流れをたどるため、ここでは省略します。
これで、weight, activationともにFP8(E4M3 or E5M2)にQuantizeすることができました。
あとは、これらをmatmulするだけです。以下のように実装されています。
orig_shape = input_maybe_fp8.shape
input_maybe_fp8_reshaped = input_maybe_fp8.reshape(-1, orig_shape[-1])
res_bits = torch.mm(input_maybe_fp8_reshaped, weight_maybe_fp8_t)
res_bits = res_bits.reshape(*orig_shape[:-1], res_bits.shape[-1])
return res_bits
PyTorchでの挙動
PyTorch実装では、入力の数値精度と出力の数値精度が異なる形式のmatmul(torch.mm)が定義されていないようです。実際に確かめると以下のようになります。
import torch
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
res = torch.mm(mat1, mat2)
print(f"mat1.dtype: {mat1.dtype}, mat2.dtype: {mat2.dtype}, res.dtype: {res.dtype}")
print(f"mat1 @ mat2 = {res}")
mat1_bf16 = mat1.to(torch.bfloat16)
mat2_bf16 = mat2.to(torch.bfloat16)
res_bf16 = torch.mm(mat1_bf16, mat2_bf16)
print(f"mat1_bf16.dtype: {mat1_bf16.dtype}, mat2_bf16.dtype: {mat2_bf16.dtype}, res_bf16.dtype: {res_bf16.dtype}")
print(f"mat1_bf16 @ mat2_bf16 = {res_bf16}")
mat1_fp8_e4m3 = mat1.to(torch.float8_e4m3fn)
mat2_fp8_e4m3 = mat2.to(torch.float8_e4m3fn)
res_fp8_e4m3 = torch.mm(mat1_fp8_e4m3, mat2_fp8_e4m3)
print(f"mat1_fp8_e4m3.dtype: {mat1_fp8_e4m3.dtype}, mat2_fp8_e4m3.dtype: {mat2_fp8_e4m3.dtype}, res_fp8_e4m3.dtype: {res_fp8_e4m3.dtype}")
print(f"mat1_fp8_e4m3 @ mat2_fp8_e4m3 = {res_fp8_e4m3}")
上記のように実装し、結果を確認すると常に入力テンソルと出力テンソルの数値精度(dtype)が同じになっています。
mat1.dtype: torch.float32, mat2.dtype: torch.float32, res.dtype: torch.float32
mat1 @ mat2 = tensor([[-0.4191, -3.7308, 0.6051],
[-1.5369, 2.1383, -3.8442]])
mat1_bf16.dtype: torch.bfloat16, mat2_bf16.dtype: torch.bfloat16, res_bf16.dtype: torch.bfloat16
mat1_bf16 @ mat2_bf16 = tensor([[-0.4199, -3.7344, 0.6094],
[-1.5312, 2.1406, -3.8438]], dtype=torch.bfloat16)
mat1_fp8_e4m3.dtype: torch.float8_e4m3fn, mat2_fp8_e4m3.dtype: torch.float8_e4m3fn, res_fp8_e4m3.dtype: torch.float8_e4m3fn
mat1_fp8_e4m3 @ mat2_fp8_e4m3 = tensor([[-0.4062, -3.7500, 0.5000],
そのため、Tensor Coreからの出力としては、以下のようにFP32、FP16、BF16、FP8から精度を選択できるはずが、少なくともPyTorch 2.5.1では入力テンソルと同じFP8しか選べなくなっているようです。

(NVIDIA Developerより)
おわりに
本記事では、FP8学習を支えている技術のうち本当に基礎的なところに絞って解説を行いました。
低精度学習の奥深さを少しでも感じていただければ、幸いです。
続編では、さらにより踏み込んだ、より具体的な話や、低精度計算において、どのようなことが問題になっているのかなどについても解説する予定です。
Discussion